基于局部模块度社团划分算法的文本概念聚类新方法
2017-03-25刘绍海安娜祁越
刘绍海,安娜,祁越
(1.武警警种学院训练部,北京102202;2.装备学院航天装备系,北京101416)
基于局部模块度社团划分算法的文本概念聚类新方法
刘绍海1,安娜2,祁越1
(1.武警警种学院训练部,北京102202;2.装备学院航天装备系,北京101416)
提出一种将概念格和社团划分方法两种理论结合的文本聚类方法,首先将节点特征值权值按照从大到小的顺序映射到形式背景中,然后通过计算出形式背景中概念相似度的大小,构造L网络,最后根据局部模块度社团划分算法规则对待聚类文本进行聚类。
复杂网络;文本聚类;综合特征值;局部模块度
随着计算机网络的高速发展,导致信息量的激增,人们必须通过一种高效快捷的方法才能使这些海量数据为我所用。通过文本聚类的方法,可以从中挖掘和提取有用信息,提高信息检索的速度和效率。文本聚类方法较多,主要有划分的方法、基于密度的聚类方法、基于SOM神经网络方法等。这些方法在不同的领域都分别得到了成功的应用。
形式概念分析方法是将概念和概念层次用数学形式清楚地表示出来,是一种聚类分析方法。通过本文分析,由形式背景生成概念的过程本质上可看作概念聚类的过程,另外通过研究发现,寻找复杂网络[1]中节点的社团结构,也是一种聚类过程。基于形式概念分析和复杂网络的思想,本文提出了基于局部模块度社团划分算法的文本概念聚类新方法,在文本空间向量模型的基础上,应用局部模块度社团划分的思想,实现文本概念聚类,为文本聚类提供了一个新的思路和方法。
1 预备知识
1.1 概念相似度
形式概念分析本质上是一种概念聚类技术,它是通过概念格形式表现出来,可以分析概念间关系,挖掘语义关系,为了分析概念之间的关系,本文引用作者之前研究的概念相似度公式。
定义1:一个背景中的两个概念C1=(A1,B1),C2=(A2,B2),其概念相似度[2]定义如下:
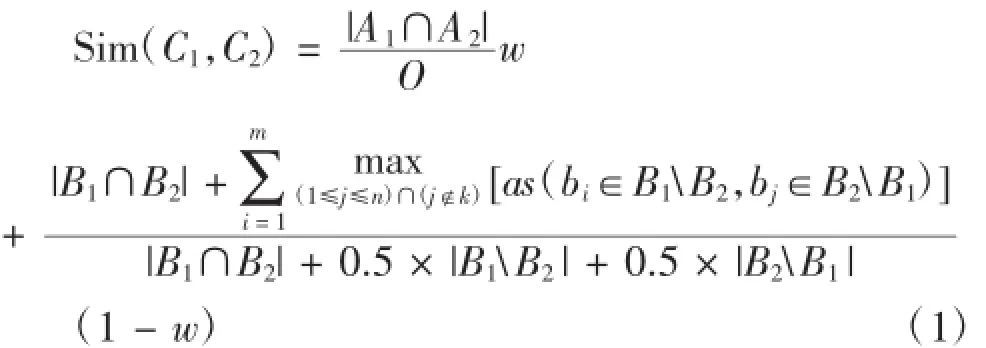
其中,|B1|=m;|B2|=n;O=max{|A1|,|A2|};k={j|as。其中,w是权值,它的取值范围是0≤w≤1,它表示概念中对象和属性重要程度。as()表示两个属性的自明相似度。
1.2 节点的综合特征值
定义1:节点的聚类系数[1]:是指与该节点相连的近邻节点之间互连的比例。
依据复杂网络中邻居节点的概念,ki个节点之间最多可能有ki(ki-1)/2条边。下式(2)为节点vi的聚类系数Ci:

其中,Ei表示ki个节点之间实际存在的边数。
本文通过节点的度和聚类系数Ci计算节点的综合特征值CFi:
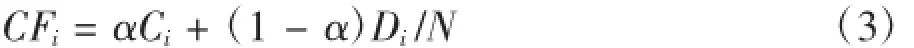
其中,0<α<1,N为节点的个数。
1.3 局部模块度
2001年,Girvan和Newnan提出GN算法,它是一个基于边介数的社团发现算法,虽然GN算法有很多优点,但其需要大量的计算,因此,为了规避该这个缺点,clauset将局部模块度的思想引入到GN算法中,通过大量的实验验证,该方法不仅大大降低了算法的时间复杂度,其聚类效果也非常理想。局部模块度[3]定义为:

Lin指若将节点加入该社团内,社团内部边的数目;Lout指若将节点加入该社团内,该社团内节点与不属于该社团的节点连接的边的数目;本文提出算法的主要思想是对候选集中的每个节点vk,假如将节点vk是加入到社团C中,计算将vk加入到社团C后社团C的Q值,则将使Q值最大的节点加入到社团C中,同时更新节点候选集合,当节点局部模块度值不再改变,表明社团C形成,不会再有节点属于该社团,其它社团形成也采用上述方法,直到所有节点都有所归属的社团,则网络的社团结构形成。
本文的初始节点CFi选取节点最大的节点。如图1表示,网络的节点分为三部分。点集C表示属于某个社团的节点集合;点集β表示并未属于到任何社团但与C中的点与β中的点有连接的点的集合,点集β作为社团的候选集合;点集μ表示与C中的点无连接边且不属于任何社团的点的集合。
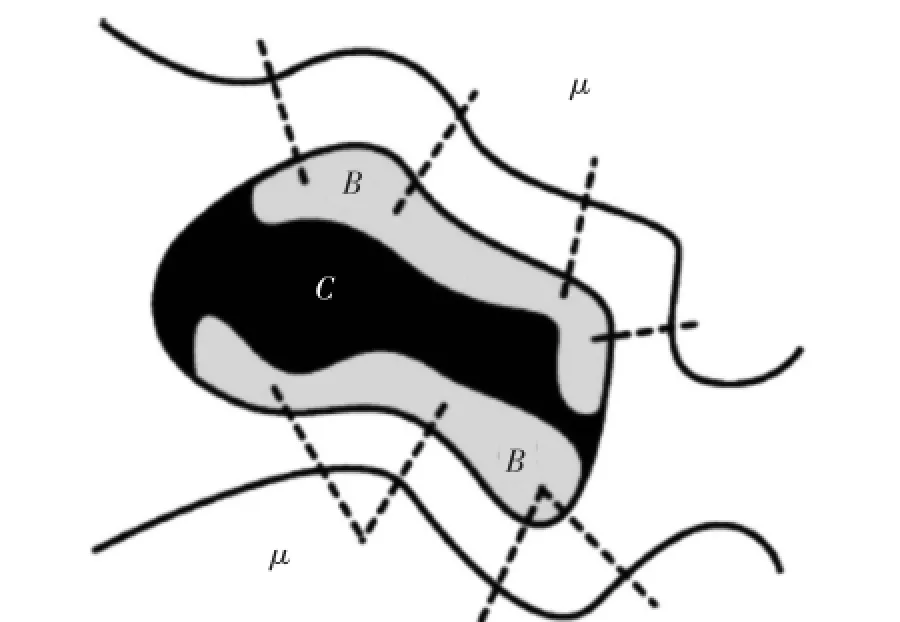
图1 节点分析方法
2 基于局部模块度社团划分算法的文本概念聚类新方法
本文基于概念格的相关理论和局部模块的思想提出了一种基于局部模块度社团划分算法的文本概念聚类新方法。首先对待聚类的文档集进行预处理;然后根据概念格构造理论,构造形式背景,其方法是将节点特征值按照从大到小的顺序完成形式背景的建立,采用作者之前的研究成果相似度公式,计算形式背景中概念相似度,构造特征概念相似度矩阵;最后,应用局部模块度社团划分方法进行文本聚类。
该算法描述如下:
输入:待聚类的文档及阈值λ;
输出:聚类结果;
Step1:提取每篇文档各关键词并计算关键词的特征词权值;关键词的自明度as()从专家库中读取;
Step3:应用建格算法构造概念;
Step4:构造相似矩阵。采用公式(1)计算各概念间的相似度Sim(C1,C2),构造相似矩阵;
Step5:构造矩阵L.将Sim(C1,C2)大于θ的转化为1,Sim(C1,C2)小于θ的转化为0,形成新的矩阵L=(Sim(Ci,Cj))n×n;
Step6:扫描矩阵L,对每个节点都建立一个线性动态链表T.

IDCCFCw
I表示节点标号;D表示该节点的度;C表示节点的聚类系数;CF表示综合特征值,通过公式(3)计算;Cw表示节点所在的社团标号,当其值为0时,表示节点为候选集节点,未被分配到社团中。此时各节点的社团标号值设为0.
Step7:选取初始节点。首先在动态链表中对各节点的综合特征值按从大到小进行排序,新社团的初始点为社团标号为0且CFi最大的节点。
Step8:确定候选集合。
矫形方式为棒平移矫形,边界条件为约束T1椎体上部在X、Y轴方向上的自由度,同时约束骶骨和骨盆的自由度。矫形上棒时将棒预弯一定角度,凹侧上棒矫形。手术节段为T2 ~ L2。上棒矫形过程中没有考虑肌肉和胸廓对手术的影响。术后测量胸椎、胸腰段和腰椎曲度,同时测量螺钉对应的拔出力。
将在动态链表中的社团标号为0且与Cw中的点相连的点的集合作为候选集合B,若所有节点的社团标号均不为0,此时社团w己形成,执行步骤11;
Step9:社团结构的形成。
对于候选集合B中的每个节点vk,如果将点vk属于社团Cw,计算社团Cw的模块度qk;通过计算,得到加入新节点后,社团Cw最大的模块度qk;如果qk大于qc,则更新qc值(qc为未加入新节点时的社团Cw的局部模块度),并将相应的qk所对应的节点vk并入到社团Cw中,并将该节点的社团标号更改为w;如果qk小于qc,表示社团已形成,执行步骤11;
Step10:执行8、9;
Step11:得到社团w;
Step12:执行7、8、9、10、11;
Step13:得到聚类结果;
从Step6到算法结束,是应用局部模块度社团划
分方法进行文本概念聚类。
3 例子
本文通过实例给出了基于局部模块度社团划分算法的文本概念聚类新方法计算过程。图2表示本例的形式背景。

图2 21个文档的形式背景
根据算法,首先使用建格软件,将形式背景转化成Hasse图,Hasse图共有五层,产生95个概念。由于篇幅有限,本文节选出出现概率较大的10个概念:
x1(2 5 7 13,ack)x2(14 16,adj)
x3(15 16 20 21,afgj)x4(4 8 9,abei)
x5(1 9 11,abio)x6(1 3 11,adio)
x7(11 16,adfgo)x8(17 19,agjln)
x9(2 9,acfhi)x10(10 11 12,abdgn)
自明度为:as(eg)=0.9as(co)=0.7
as(dl)=0.9as(cd)=0.9as(fk)=0.8
as(fn)=0.9as(ki)=0.9as(ij)=0.9
as(eo)=0.8as(kj)=0.8.
由于相似度的计算要需要对象和属性的权重,属性的权重要大一些,因此假定属性的权值设为0.8,则对象权值为0.2.应用相似度公式(1)得到矩阵R=(Sim(Ci,Cj))1010;
本例设θ=0.52,对矩阵进行θ=0.52截处理得矩阵L.通过查看网络结点动态链表T(表1),节点1的综合征值0.5为最大,则选取节点1为初始节点,初始节点选取后候选集也确定了,候选集β为β= {2、5、6、7、9};在β中,找到使局部模块度最大的点并入到社团1中,这一步通过公式(4)计算,更新β,最后得到Q为0.556,此时Q值不再增加,根据算法的思想,第一个社团已经形成,更新社团内节点动态链表中的社团标号为1;从动态链表中社团标号为0的节点选出一个综合特征值最大的节点,本例中为节点8,重复上述步骤,当局部模块度为0.417时,Q值不再增加,第二个社团己形成,将这些节点动态链表中社团标号标识为2.此时动态链表中社团标号没有社团标号为0的节点,表明所有节点都归属于某个社团,网络的社团结构已经形成,因此10个概念的划分结果为:{x1x2x4x5x6x9}{x3x7x8x10}.
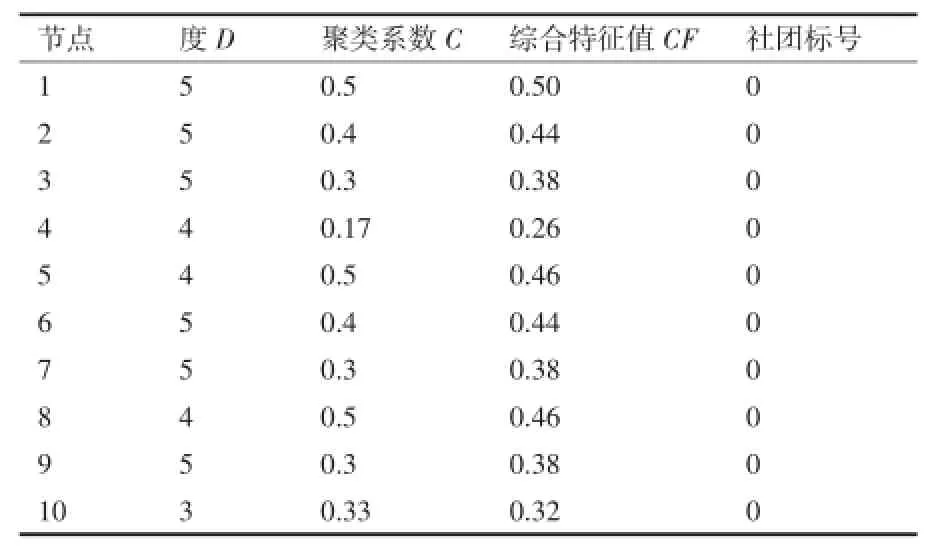
表1 网络结点动态链表T
4 结论
本文是作者在先前研究工作的基础上提出了改进的文本聚类的算法。将局部模块度社团划分算法应用到文本概念聚类中,衡量网络划分模块标准的提出,极大地降低了算法的复杂度;同时通过定义概念格相似度,将对象和属性同时应用到相似度计算中,使用文本相似度的计算方法更加全面准确,实验结果验证了聚类算法的正确性。本文提出的算法适用于海量文本这种高维数据,为文本聚类提供一个新的研究方法。
[1]汪小帆,李翔,陈关荣.复杂网络理论及其应用[M].北京:清华大学出版社,2006.
[2]谢福鼎,安娜,黄丹.一种基于内容相似度和推荐反馈的信息模型[J].计算机科学,2009,36(4):215-231.
[3]Xutao Wang,Guanrong Chen,Hongtao Lu.A very fast algo rithm for detecting community structures in complex networks [J].Physica A384(2007):667-674.
A New Method for Text Concept Clustering based on Detecting Community Structures by Local Modularity in Complex Network
LIU Shao-hai1,AN Na2,QI Yue1
(1.Training Department,Specialized Forces College of Capf,Beijing 102202,China;2.Department of Space Equipment,Equipment Academy,Beijing 101416,China)
This paper gives a new text clustering method which takes the advantages of concept lattice and complex network.The algorithm firstly computes the weights of the key words and then the formal context is constructed in terms of key words which have the proper weight.Secondly,building L network,the similarities between concepts are computed,clustering the text of cluster by detecting community structures by local modularity algorithm rule,clustering results can be received.
complex networks;text clustering;multifactor value;local modularity
TP391
:A
:1672-545X(2017)01-0012-04
2016-10-02
刘绍海(1978-),男,辽宁人,博士,讲师,研究方向:人工智能;安娜(1983-),女,辽宁鞍山人,硕士研究生,讲师,主要研究领域:人工智能。
