基于AdaBoost和分类树的北京市高血压患者就诊机构选择的影响因素分析
2017-03-09代晓彤谢学勤康晓平陈卓然刘福荣
代晓彤 谢学勤 康晓平△ 陈卓然 刘福荣
基于AdaBoost和分类树的北京市高血压患者就诊机构选择的影响因素分析
代晓彤1谢学勤2康晓平1△陈卓然1刘福荣3
目的 通过对2013年“北京市第五次国家卫生服务调查”中高血压患者两周就诊数据的分析,探讨高血压患者两周就诊机构的选择及影响因素。方法 使用AdaBoost和分类树组合分类器对高血压患者两周首次就诊机构进行分类,获得变量相对重要性排序结果,利用十折交叉验证法计算错分率,错分率的可接受程度为0~0.3,选择错分率最小的模型进行结果解释。结果 本次1128例患者中,两周首次就诊选择基层医疗卫生机构的占75.7%。选用的AdaBoost和分类树组合分类器的模型错分率为0.177。经AdaBoost和分类树组合分类器对10个自变量按照相对重要性进行排序,其中排名最高的三个变量依次为受教育程度、家庭人均收入、家人常去医疗机构,并绘制能够分别说明这三个变量的分类树。结论 对于北京市两周就诊的高血压病患者来说,首诊选择基层医疗卫生机构的比例较高,受教育程度、家庭人均收入和家人常去医疗机构是影响其是否选择基层医疗卫生机构的最重要因素。
AdaBoost 分类树 高血压 两周患病率 就诊机构 影响因素
高血压病是现今城市居民常见的慢性非传染性疾病(noninfectious chronic disease,NCD),也是北京市医疗卫生系统的一个重要负担。2008年中国大城市的高血压两周就诊率为30.5%[1],2013年北京市15岁以上人群高血压患病率为15.5%,位居北京市两周患病首位,其两周就诊率却仅为24.6%。明确高血压患者的就诊方式,了解影响其就诊机构选择的因素,有利于提出能够改善高血压病控制情况的政策,为促进医疗系统满足如此庞大的医疗需求提供借鉴。本研究利用2013年“北京市第五次国家卫生服务调查”中高血压患者两周就诊的数据,探讨高血压患者两周就诊机构的选择及影响因素,以期为针对性的政策指导提供理论依据。而AdaBoost和分类树组合分类器,是一种不必对想纳入的自变量进行特征筛选,能够直观获得变量重要性排序情况的方法,适用于该卫生政策管理问题的研究。
对象与方法
1.对象
本研究选取2013年“北京市第五次国家卫生服务调查”数据,研究对象为:调查前两周内患有高血压病,且因该病首次前往医疗机构接受过医生的诊断和治疗的北京市15岁以上常住居民,有效样本共1128例。
2.方法
(1) 变量定义
因变量为两周患病首次就诊地点,分为基层医疗卫生机构和区县级及以上医疗卫生机构。
基层医疗卫生机构指符合下列情况之一者:①诊所/村卫生室,②社区卫生服务站,③卫生院,④社区卫生服务中心。区县级及以上医疗卫生机构指符合下列情况之一者:①县/县市级/省辖市区属卫生机构,②省辖市/地区/直辖市区属卫生机构,③省/自治区/直辖市属及以上卫生机构。所有变量赋值情况见表1。

表1 变量赋值表
(2) AdaBoost组合分类器原理和步骤
AdaBoost是adaptive boosting的简写,是一种自适应Boosting算法,由Freund和Schapire在1995年提出[2]。R语言中的adabag包主要应用于对数据集进行的AdaBoost.M1和SAMME 算法。本文描述和调用的是AdaBoost.M1[3]。
分类与回归树(classification and regression tree,CART)的结果直观,易于解释,是卫生政策管理方向常用的一种分析方法。但是分类与回归树容易发生过拟合的情况。Adaboost.M1算法无需任何先验知识,具有自适应性[4],不仅能够避免过拟合的问题,还可以有效降低模型的错分率,提高模型的精度。
该组合分类器的分类过程为:

更新各样本的权重,加大分类错误的样本权重,减小分类正确样本的权重,进而生成新的CART。本研究按照程序默认,更新100次,产生100棵分类树。
所有训练完成后,采用加权投票机制将产生的若干个分类树进行组合,形成强分类器。变量重要性的计算考虑到最终分类树中变量的Gini系数和这个分类树的权重,也就是说某变量的相对重要性越大,其对选择就诊机构的影响就越大。因此本研究筛选出变量相对重要性最大的前三个变量进行结果解释,绘制能够分别说明这三个变量的分类树。
公式如下:
训练样本数记为N,第n个样本的权重为Wn,迭代次数记为M,第m个分类树记为Ym(xn)。
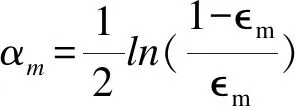

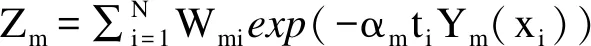

(3)模型评价
错分率,即测试样本中被模型错误分类的比例。根据不同的研究目的,错分率的可接受程度不同。本研究最终模型错分率的可接受程度为0~0.3。
本研究使用十折交叉验证法(ten-foldcross-validation)计算错分率,用来测试算法准确性。具体操作为,将1128例样本随机平均分成10份,将其中的1份(113例)作为测试样本,剩余9份(1015例)作为训练样本进行试验,共计算10次,计算出平均错分率。选取10次中错分率最小的最终模型的结果进行影响因素讨论。
(4) 统计软件
使用SAS9.3进行数据库的清理、单因素分析,使用R语言中的adabag、caret程序包进行分类树和AdaBoost的分析。
结 果
1.基本情况
在1128例高血压患者中,男性508人,女性620人;年龄在65岁及以上的人占46.9%,35~64岁的占52.1%,15~34岁仅占1.0%,年龄最小者为27岁;选择基层医疗卫生机构就诊的有854(75.7%)人,区县级及以上医疗卫生机构的274(24.3%)人。按不同就诊机构对人口统计学特征(年龄、性别、地区),社会经济特征(户口、受教育程度、职业、家庭人均收入),卫生服务可及性(到最近的卫生服务机构的时间),医疗保险情况、家庭就诊习惯等进行描述,见表2。
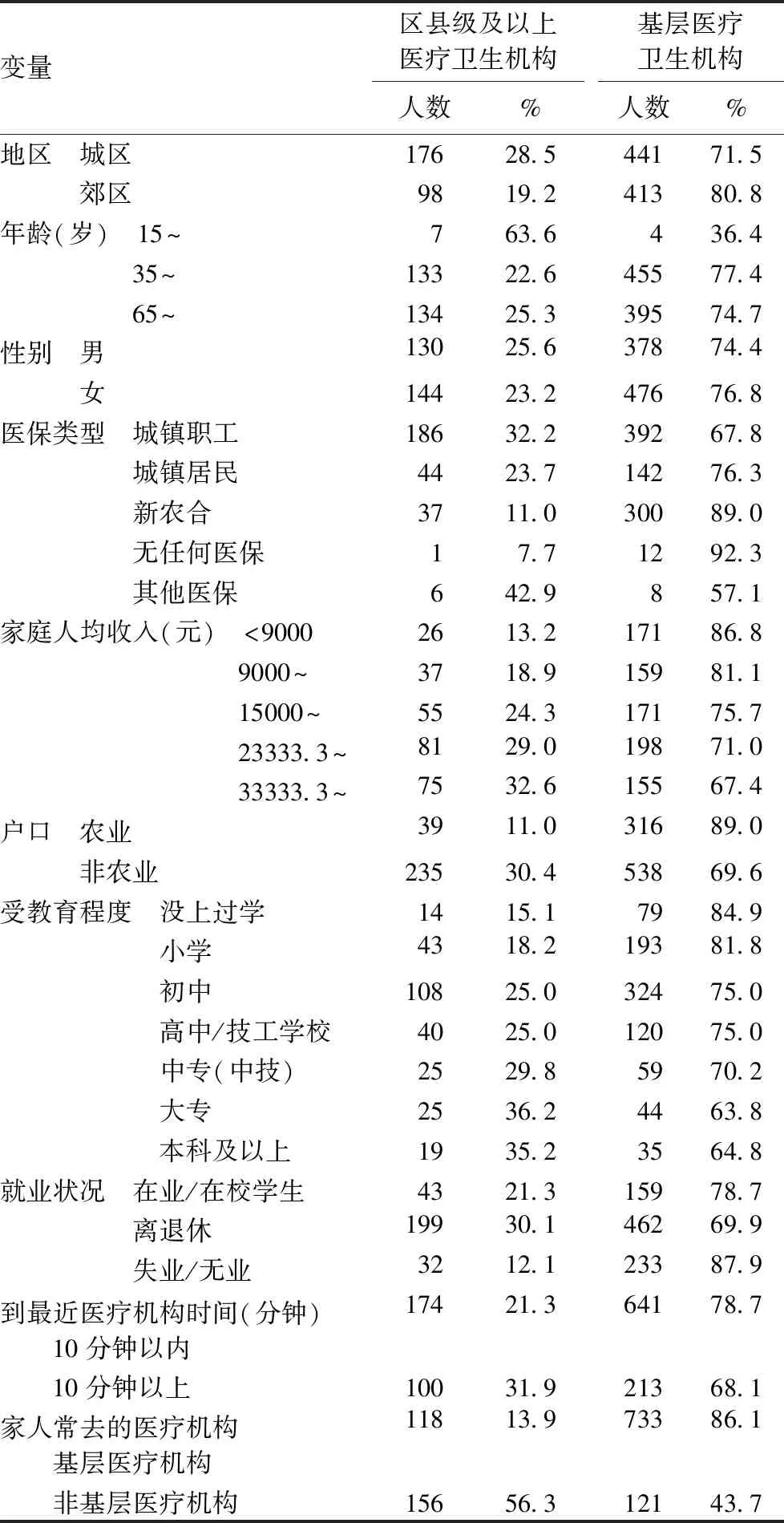
表2 高血压病患者选择不同就诊机构的基本情况
2.AdaBoost结果
对1128例样本使用十折交叉验证法计算出10次的错分率范围为0.177~0.274,均符合判定标准0~0.3,平均错分率为0.213,表示对本资料,使用该方法精确度较高,见表3。

表3 十折交叉验证法逐次错分率
选取错分率最小的模型进行结果解释。分类任务中每个变量的相对重要性见表4。结果显示:10个变量中相对重要性最高的三个变量依次为受教育程度。家庭人均收入、家人常去医疗机构。绘制能够说明受教育程度影响决策情况的第99棵树,显示当受教育程度为初中及以下或本科及以上时,患者选择基层医疗机构就诊的比例由原来的0.51增加到0.54(图1)。能够说明家庭人均收入影响决策情况的第92棵树,显示当家庭人均收入最低、适中、较高时,患者选择基层医疗机构就诊的比例由0.49增加到0.52(图2)。绘制能够说明家人常去医疗机构影响决策情况的第1棵树,显示当家人常去医疗机构为非基层医疗机构时,患者选择基层医疗机构就诊的比例由0.25增加到0.58(图3)。

表4 变量相对重要性

图1 第99棵决策树
讨 论
从总体来看,本研究显示高血压患者选择基层医疗卫生机构就诊的比例较高(75.7%)。国内外研究表明,对于高血压病的控制,最有效的方法就是社区防治[5]。朱梅等研究显示,社区就诊的高血压居民服药依从率,血压控制率均高于二、三级医院[6]。按照中国医疗保险报销政策,慢性病、常见病在基层医疗卫生服务机构的报销比例要高于二、三级医院。充分发挥基层卫生服务的作用,是现今慢性病控制卫生政策的导向。本研究提示,北京高血压患者选择基层医疗卫生机构就诊的情况在现有水平可持续发展。
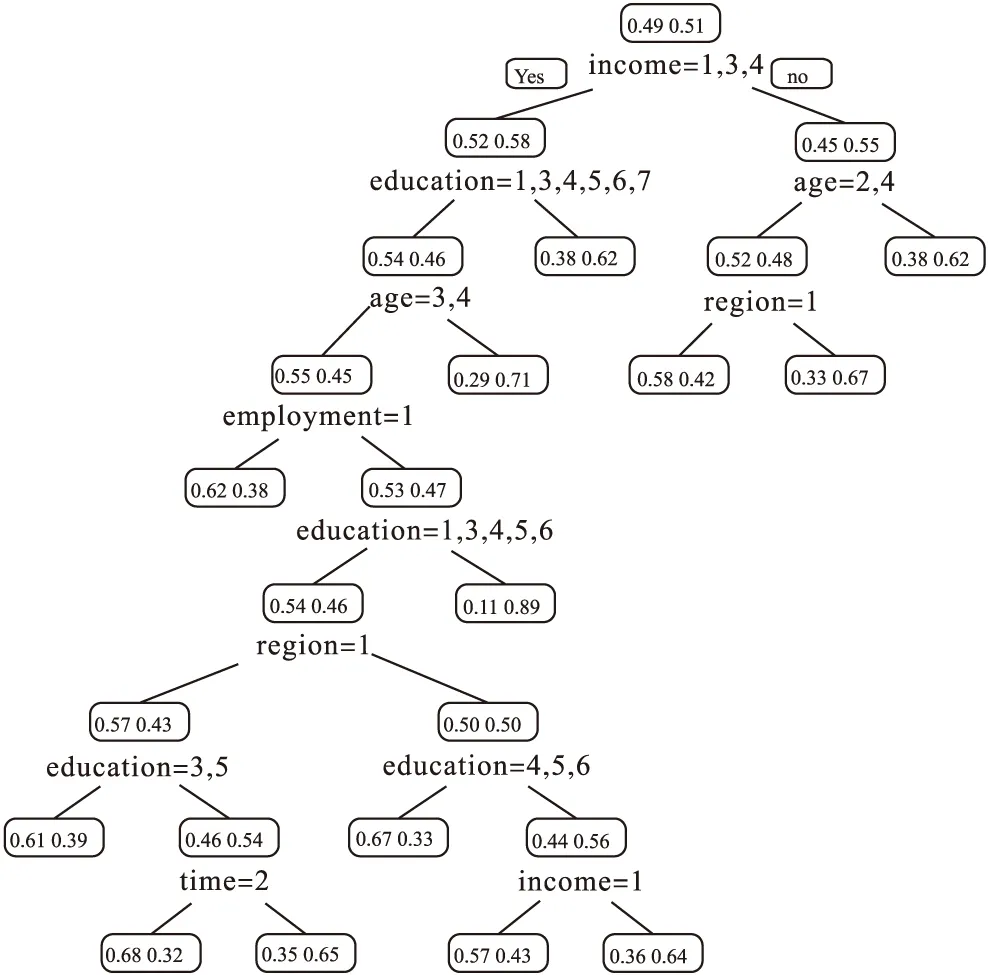
图2 第92棵决策树
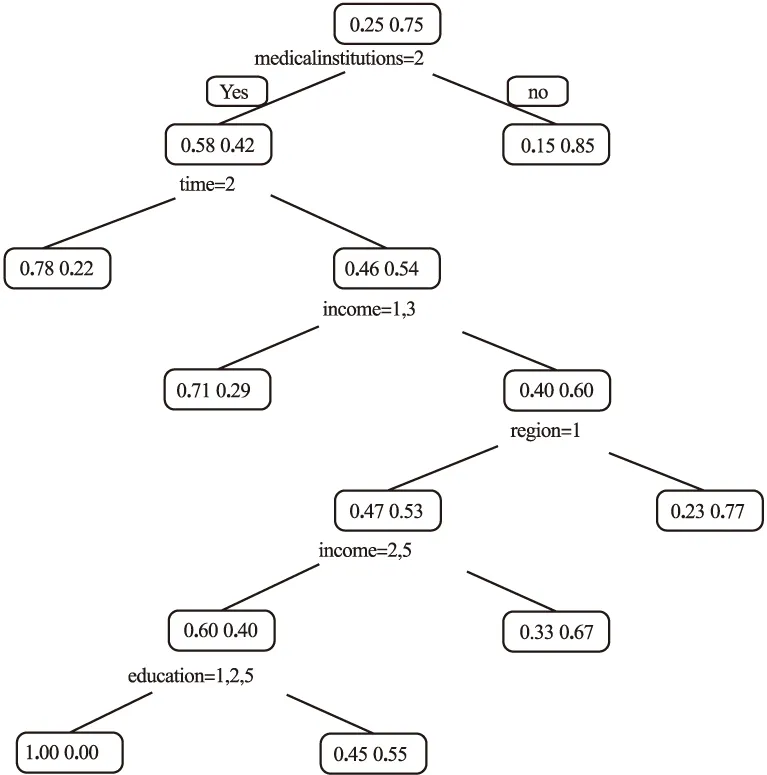
图3 第1棵决策树
表2显示,不同特征的北京市高血压患者两周首次就诊选择基层医疗卫生机构的比例均较高,但还是有差别的,AdaBoost与分类树组合分类器的方法可以在对自变量进行排序的过程将这些差别展示出来,找出影响高血压患者就诊选择的最重要因素。
在以往研究中,经济因素始终是影响卫生服务利用的关键因素[7],收入越低的患者更多地选择医疗费用更低的医疗机构。本次研究的部分结果与之一致。如图1所示,没上过学、小学、初中和本科及以上学历的高血压患者基层医疗卫生机构就诊的比例增加。图2中家庭人均收入最低、适中和较高的患者,选择区县属医疗卫生机构的比例增加。家庭人均收入和受教育
程度具有交互作用,受教育程度较低的人家庭人均收入也较低。本科及以上学历和家庭人均收入较高的高血压患者,倾向于选择基层医疗卫生机构就诊,这可能与其较高的健康素养有关。Dennison等的研究提示,更高的受教育水平有利于高血压病的治疗[8]。受教育程度越高,具备健康素养的比例也越高[9]。健康素养的高低也会影响劳动人口对卫生服务的利用[10]。这是受教育程度影响就诊机构选择的一条途径。高学历的高血压病患者似乎更倾向于选择基层医疗卫生机构就诊,这在一定程度上反映了健康素养较高的居民对基层医疗服务的利用更加充足。本研究结果表明,北京市常住居民高血压病就诊机构的选择在基层导向还是有空间的,深化基层卫生服务对于高血压病管理的作用,健康教育是必不可少的。
家人常去基层医疗卫生机构就诊,患者也更多地选择基层医疗卫生机构,这体现了家庭就诊的习惯也会影响高血压患者的就诊倾向。培养就诊习惯,对于贯彻卫生政策的实施,有着积极的推动作用。
综上,对于北京市有两周就诊的高血压病患者来说,首诊选择基层医疗卫生机构的比例较高,受教育程度、家庭人均收入和家人常去医疗机构是影响其就诊选择的最重要因素。
[1]卫生部统计信息中心.2008中国卫生服务调查研究第四次家庭健康询问调查分析报告.第1版.北京:中国协和医科大学出版社,2009.
[2]Freund YSRE.A decision-theoretic generalization of on-line learning and an application to boosting.In:Proceedings of IEEE Second European Conference on Computational Learning Theory.Barcelona,Spain:1995.
[3]Alfaro E,Gamez MAGN,Guo WCFL.Applies Multiclass AdaBoost.M1,SAMME and Bagging.https://cran.r-project.org/web/packages/adabag/adabag.pdf.
[4]吴杰法.基于整体特征的行人检测方法研究.湖南大学,2012.
[5]吴兆苏.我国高血压流行情况及如何开展高血压社区防治.心肺血管病杂志,1999,(3):18-20.
[6]朱梅,高俊岭,金桂勤,等.不同就诊方式的社区高血压患者血压控制效果及费用的比较研究.中国全科医学,2016,(1):96-99.
[7]卫生部统计信息中心.中国卫生服务调查研究第三次国家卫生服务调查分析报告.第1版.北京:中国协和医科大学出版社,2004.
[8]Dennison CR,Peer N,Steyn K,et al.Determinants of hypertension care and control among peri-urban Black South Africans:the HiHi study.Ethn Dis,2007,17(3):484-491.
[9]卫生部妇幼保健与社区卫生司,卫生部新闻宣传中心中国健康教育中心.首次中国居民健康素养调查报告.北京:2009.
[10]孙亚慧,谢兴伟,曾庆奇,等.健康素养对某高校部分劳动力人口基本公共卫生服务利用的影响研究.中国健康教育,2015,(3):243-246.
(责任编辑:刘 壮)
The Influencing Factors Regarding Choosing Medical Institutions among Hypertension Patients in Beijing on AdaBoost and Classification Tree
Dai Xiaotong,Xie Xueqin,Kang Xiaoping,et al
(SchoolofPublicHealth,PekingUniversity(100191),Beijing)
Objective By analyzing the two-week prevalence and outpatient service data of 2013 Beijing Health Service Survey,this study aims at clearing and defining influence factors of choosing hospitals at different levels among hypertension patients in Beijing.Methods The first medical institutions selection of hypertension patients in two weeks were classified using Ada Boost and classification tree combination classifier,and the variables were sorted according to the relative importance of the variables.The error rate was calculated by ten-fold cross-validation method.The acceptability of the error rate was 0~0.3.The model with the smallest error rate was explained.Results The patients who chose primary health care institutions as the first medical institution in two weeks from the 1128 cases of hypertension patients,was 75.7%.The error rate of the selected AdaBoost and classification tree combination classifier was 0.177.The 10 variables was sorted according to the relative importance.The 3 highest rank variables were education level,family income per capita and the medical institutions family often went to.The classification trees,which could illustrate the three variables,were drawn separately.Conclusion For the first medical institutions selection of hypertension patients in two weeks the city of Beijing,the proportion of primary health care institutions was high.Education level,family income per capita and the medical institutions family often went to were the most important factors that affected the choice of primary health care institutions.
AdaBoost;Classification tree;Hypertension;Two-week prevalence;Medical institutions;Influence factors
1.北京大学公共卫生学院(100191)
2.北京市公共卫生信息中心
3.郑州大学第一附属医院
△通信作者:康晓平
