基于文本分类的电企舆情识别方案设计与实现
2017-03-02马志程顾凯成
马志程,顾凯成,杨 鹏
(1.国网甘肃省电力公司信息通信公司 甘肃 兰州730050;2.兰州理工大学 计算机与通信学院,甘肃兰州730050)
基于文本分类的电企舆情识别方案设计与实现
马志程1,顾凯成2,杨 鹏1
(1.国网甘肃省电力公司信息通信公司 甘肃 兰州730050;2.兰州理工大学 计算机与通信学院,甘肃兰州730050)
根据电力企业舆情管控工作的需要,设计了一种基于文本分类技术的企业舆情主题识别实验平台,技术人员只需根据需要设定文本分类中不同的基本参数,即可针对相应的舆情文本测试不同参数方案下主题文本的识别效果,最后利用JAVA实现了特定方案下舆情主题识别系统(原型)。实际应用表明,该实验平台和原型系统能够为本企业进一步深化舆情管控工作提供可靠的研究平台和应用系统,从而提升企业品牌建设和品牌维护工作的水平。
舆情主题;文本分类;电力企业;实验平台
随着国有企业改革的不断深入,电力企业也正处于改革的重要时期,舆情危机一旦出现将会对企业带来极大的危害[1-2]。因此,国网甘肃省电力公司所属各单位已开展舆情管控工作,由省公司组织各地市单位的舆情管理人员将各地的舆情信息进行搜集和反馈,然而,面对海量的网络以及现实舆情信息,因人员编制的问题,技术人员和舆情管理人员多为兼职工作,劳动量大、工作效率不高。为此,将文本分类技术应用于本公司舆情主题识别中,提出了舆情主题识别系统的关键设计方案,利用C++实现了基于文本分类技术的舆情主题识别实验平台,帮助技术人员针对不同的舆情主题样本进行测试,从而可以获得更好的舆情主题识别方案。由于C++的移植性和操作性较差,因此本文针对实验样本测试获得的最优方案后利用JAVA实现了舆情主题识别系统(原型)。通过本公司舆情主题识别实验平台和原型系统的实现,能够深化电力企业舆情管控工作,有效减轻企业舆情管理人员的工作量,抢占舆情管控时机,及时开展危机公关,维护公司品牌形象[3-4]。
1 实验平台设计
该实验平台结构如图1所示,分词模块对舆情训练文本进行分词等预处理,用户设定特征选择模块中相关实验方案后对预处理过舆情文本进行特征词选取,权重计算模块给予选取好的特征词对应的权重,继而对分类器进行训练。舆情测试样本经过同样的预处理后利用已训练好的分类器进行分类识别,并对结果进行测评。

图1 实验平台结构图
1.1 分词模块
分词模块主要功能是对舆情训练文本和舆情测试文本进行词条分割,并对停用词和常用词进行处理。在分词阶段常用的方法包括[5]:基于词典匹配的分词方法、基于理解的分词方法和基于统计的分词方法。中科院ICTCLAS分词系统结合了词典匹配、统计分析这两种分词方法,既拥有词典匹配法的速度快、效率高的优点,又发挥统计分析法结合上下文识别新词、消除歧义的特点,分词速度达500 kb/s,精度达98.45%,包含各种词典数据压缩后加起来不足3 MB的存储空间[6],并且开源,因此本模块通过调用ICTCLAS_Init接口进行分词系统的初始化,加载分词词典和停用词表,最后分析舆情训练文本,枚举出文本的主题数量和每个主题的文本数,对每个主题的舆情文本调用ICTCLAS_File Process接口进行文本分词操作,编程时参考ICTCLAS的设计文档就可以了。
1.2 特征选取模块
特征选取模块的功能是提取出一部分数量最具识别特征的词条,供文本分类模块进行分类识别。常用的特征选取方法有[7]:信息增益(Information Gain,IG)、互信息(Mutual Information,MI)、期望交叉熵(Expected Cross Entropy,ECE)、卡方检验 (x2-test,CHI)。另外特别重要的是特征词选择范围的方式分为两种即全类主题选择和单类主题选取,全类主题选取方式把所有主题的特征词构建成一个词空间,通过特征选取方法对每个特征词进行一个识别能力评估,最后按照评估值进行排序,再根据用户设定的特征词目筛选特征词。而单类主题选取是先在每个主题中进行评估、排序和选择,然后再总体选择,经过特征选择处理舆情主题文本就变成一个词空间的数据结构的数据[8]。采用何种特征词选择范围、何种特征选取方法以及预留多少特征词目,针对不同类型的舆情主题文本,需要采用反复的实验来验证哪种方案是最好的。因此本舆情主题识别实验平台分别编程实现了信息增益、互信息、期望交叉熵、卡方检验这四种特征选择方法,预留特征词目输入接口以及特征词按照全类还是单类选择接口。
1.3 权重计算模块
经过前面的特征选择方案选择出相应的特征词,但是不同特征词对每个主题的识别能力不同,所以要计算各个特征词的权重大小,TF*IDF权重计算是最为广泛应用的一种权重计算方法[9-10]:特征词在某类主题下某个样本中出现的频率越高,则该特征词对该类主题区分度越大,识别能力越强,相反特征词越广泛分布在所有的主题样本中,即在各主题类中该特征词出现次数比较接近,则该特征词对所有样本的主题区分度比较小,识别能力较弱,其计算如公式(1),文中通过编程实现TF*IDF特征词权重计算。

其中,Wi指第i个特征词的权重,TFi(t,d)指特征词t出现在舆情文本d中的次数,N是舆情文本总数,DF(t)指某主题舆情文本中所有含有特征词t的舆情文本数。
1.4 分类模块
分类模块的功能是实现分类算法,利用舆情训练文本,为经过分词和特征选取以及权重计算后的舆情测试文本确定主题类别。常用的分类算法有贝叶斯分类算法,神经网络分类算法,决策树分类算法,近邻算法和支持向量机等[11],支持向量机相对于其他算法对于文本特征相关性和稀疏性不敏感,其处理文本向量高维数问题具有更大的优势,同时已有文献也表明支持向量机算法在文本分类中是最优算法[12],因此本实验平台的分类模块通过编程实现支持向量机作为分类模块。
2 实验平台应用
实验平台主界面和方案选择界面如图2所示。为了展示该平台的应用,文中通过人工和网络爬虫软件从天涯论坛、中国新闻网、新浪微博等网站上采集了其他几种舆情主题样本,而“国家电网”舆情主题样本从各地市公司反馈的舆情样本中筛选了200例,训练样本和测试样本按照1:1随机划分,样本的主题描述和样本划分如表1所示。
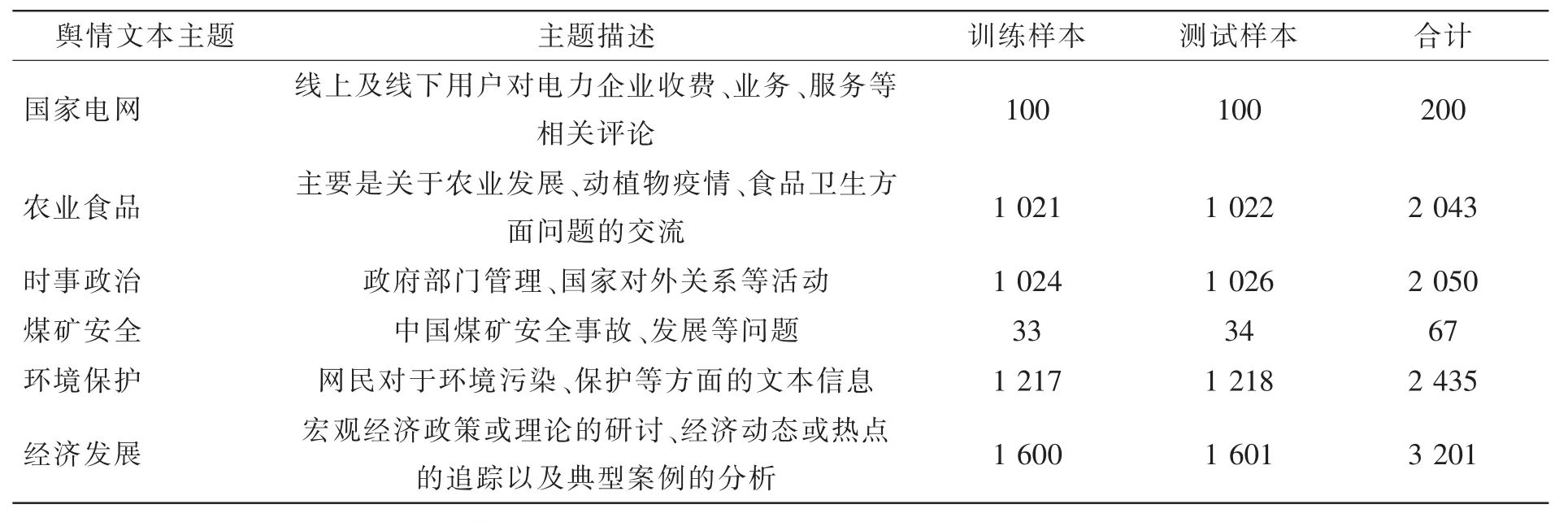
表1 主题描述和样本划分

图2 实验平台主界面和方案选择界面
在文本分类的研究中,采用查全率(Recall,R)、查准率(Precision,P)和F1值来测试文本分类的效果[13-15],因此本实验平台的识别结果测评同样采用的这3种评价指标对舆情文本的识别结果进行评估。
将上述舆情主题训练样本导入实验平台中,在方案选择界面选择期望交叉熵作为特征选择方式,特征词个数设置为1 000,分别选择全类主题和单类主题进行训练,训练完成后对舆情主题测试样本进行测试如表2所示。
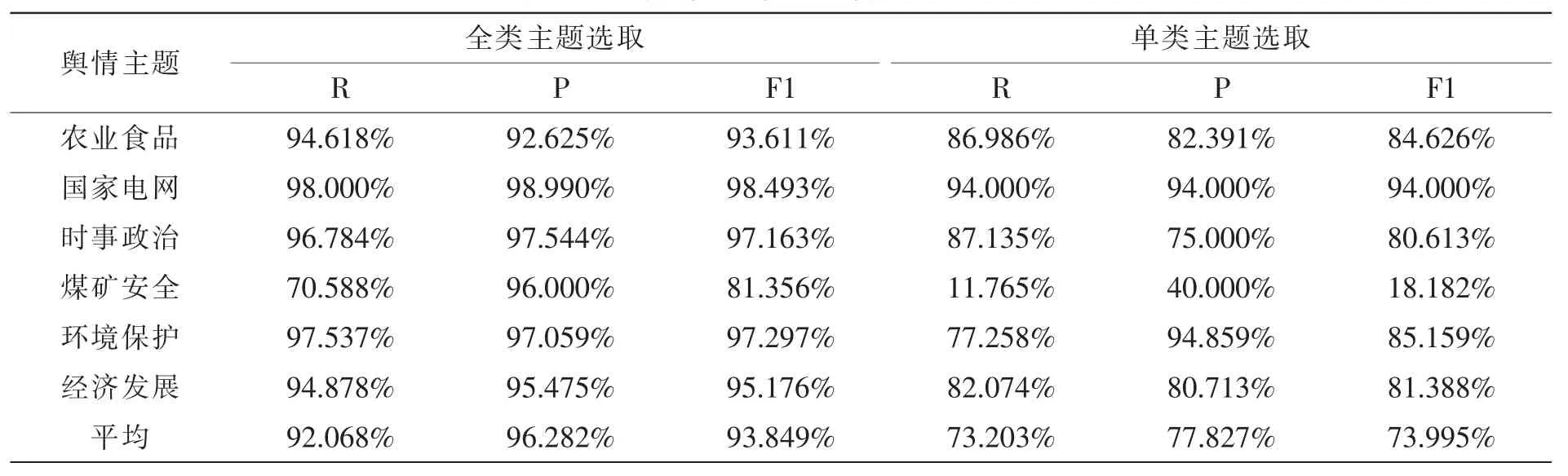
表2 不同特征选择词选择范围识别评测
对结果进行分析发现,全类主题的特征词选择方式下舆情主题识别的查全率、查准率、F1值都远大于单类主题的特征词选择,每一项评估指标平均值高出20%左右,故,技术员可认为,使用全类主题特征词选择方式更适用于所实验的舆情主题样本。
同样的,将上述舆情主题训练样本导入实验平台中,在方案选择界面将全类主题作为特征词选择方式,特征词个数设置为1 000,分别选择信息增益、互信息、期望交叉熵、卡方检验作为特征选择方式,篇幅原因只将“国家电网”主题实验结果罗列如表3所示。
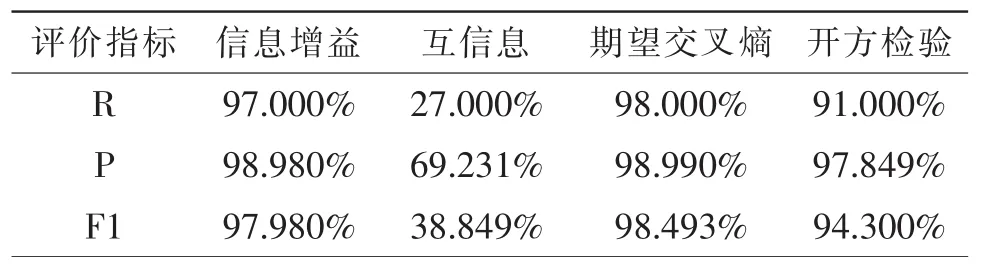
表3 不同特征选择方式识别评测
对结果进行分析发现,期望交叉熵作为特征选择方式,“国家电网”主题识别的查全率、查准率、F1值都略优于其他特征选择方式,互信息效果最差最不适合该舆情实验样本,因此,技术员可优先使用期望交叉熵作为该舆情主题实验样本识别系统的特征选择方式,该方案下识别效果最好。
其他情况下的实验过程与上述类似,这里就不再一一赘述了。技术员只需要将舆情主题实验样本导入实验平台后,通过简单的选取操作就能分析不同方案组合下识别效果的优良,从而快速的确定最优识别系统的方案。在今后的实验平台使用中,技术员可以通过人工识别的电力企业关于服务评价、供电质量评价、收费评价、招投标评价等不同舆情主题实现主题识别测试从而确定识别方案[15]。
3 舆情主题识别系统
技术人员通过实验平台对相应的舆情文本进行测试分析后确定最优的识别系统方案,经过反复的对本文的实验样本进行测试,特征词选择范围采用全类主题、特征选择方式采用期望交叉熵、特征词目设定1 000个方案下舆情主题识别效果最好。但鉴于C++编程要求高、移植性和操作性较差,为了方便舆情管理人员对舆情样本进行自动化识别,文中利用JAVA实现舆情主题识别系统,开发包和系统界面如图3所示,系统结构设计与实验平台类似,只是特征选择模块中相关参数已经根据上述实验方案进行最优化设置, 技术员分别执行开发包中ProduceClassLabel、TrainProcess、UiMain对舆情训练文本进行主题标签生成、特征选取以及分类器训练等过程,形成相应舆情文本的识别模型,将模型文件分发给舆情管理人员。
舆情管理人员只需将模型文件导入识别系统对应文件夹内就能完成主题识别系统的配置,然后选择好未知主题的舆情文本信息后点击“开始识别”就能对这些舆情文本进行自动化识别,通过 “导出结果”按钮进行分类导出。
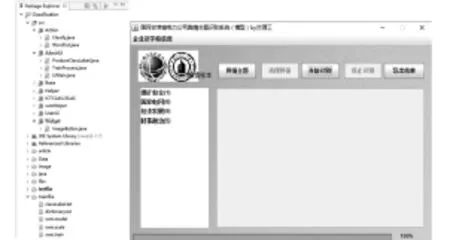
图3 舆情主题识别系统开发包和界面
在实际的测试应用过程中,该主题识别系统能够方便、快捷、直观地帮助舆情管理人员进行主题识别,大大的减少舆情管理人员工作量,帮助公司减少人员配置,更好地开展舆情管控工作。
4 结 论
利用文中设计的舆情主题识别实验平台,能够简化技术人员对主题识别方案设计的过程,通过简单、直观的选择就能轻松得到相应舆情主题文本的最优识别方案,而舆情主题系统能够形象、直观、方便的帮助舆情管控人员对舆情主题进行识别,大大减轻舆情文本识别的工作量,降低劳动力成本,提高工作效率,为提升公司品牌建设和品牌维护水平起到积极的作用。
[1]温超.电力企业舆情风险管理[J].中国电力企业管理,2015(3):93-94.
[2]赵晶晶,刘婷.浅析电网企业对外舆情危机应对[J].中国电力教育,2013(2):213-214.
[3]栾霞,马晨辰.基于Single-Pass的部队医院网络舆情监控系统设计[J].电子设计工程,2015,23(4): 60-63.
[4]王鹏举,薛惠锋,张永恒,等.基于云服务的政府舆情监测平台架构的设计与实现[J].电子设计工程. 2015,23(6):78-81.
[5]陈之彦,李晓杰,朱淑华,等.基于Hash结构词典的双向最大匹配分词法 [J].计算机科学,2015,42(11):49-53.
[6]薛亮.基于SVM的中文文本分类系统的设计与实现[D].重庆:重庆大学,2012.
[7]石慧,贾代平,苗培.基于词频信息的改进信息增益文本特征选择算法[J].计算机应用,2014,34(11): 3279-3282.
[8]任永功,杨荣杰,尹明飞,等.基于信息增益的文本特征选择方法[J].计算机科学,2012,39(11):127-130.
[9]郭颂,马飞.文本分类中信息增益特征选择算法的改进[J].计算机应用与软件,2013,30(8):139-142.
[10]黄志艳.一种基于信息增益的特征选择方法[J].山东农业大学学报,2013,44(2):252-256
[11]平源.基于支持向量机的聚类及文本分类研究[D].北京:北京邮电大学,2012.
[12]Ping Y,Tian YJ,Zhou Y J,et al.Convex decomposition based cluster labeling method for sacpport vector clacstering[J].Journal of Computer Science and Technology,2012,27(2):428-442.
[13]巩军,刘鲁.一种K-NN文本分类器的改进方法[J].情报学报,2007,26(1):56-59.
[14]黄九鸣.面向舆情分析和属性发现的网络文本挖掘技术研究[D].长沙:国防科学技术大学,2011.
[15]叶智强.提高电网企业舆情应对能力[J].中国电力企业管理,2012(10):34-35.
Design of public opinion recognition scheme for power enterprise based on text classification
MA Zhi-cheng1,GU Kai-cheng2,YANG Peng1
(1.State Grid Gansu Information and Telecommunication Company,Lanzhou 730050,China;2.School of Computer&Communication,Lanzhou University of Technology,Lanzhou 730050,China)
According to the need of electric power enterprise management and control of public opinion,the experimental platform of public opinion was designed based on text classification,technicians set different parameters in text classification and test effect of different parameters,finally this paper used JAVA to realize the theme of public opinion system under the specific program.Practical application shows that this platform and system for the enterprise,further deepening the control provides reliable public opinion research platforms and application systems,thereby raising the standard of corporate brand building and brand maintenance.
public opinion topic;text classification;electric power enterprise;experimental platform
TN02
:A
:1674-6236(2017)03-0028-04
2016-01-27稿件编号:201601250
马志程(1969—),男,甘肃兰州人,硕士,教授级高工。研究方向:电力信息化、企业数据挖掘。
