基于协同过滤算法的人力资源信息管理系统研究
2017-03-02张玙
张玙
(河海大学 商学院,江苏 南京211100)
基于协同过滤算法的人力资源信息管理系统研究
张玙
(河海大学 商学院,江苏 南京211100)
为了方便企业及时便捷的获得与追踪各种人事管理方面的信息,在Hadoop分布式构架平台的基础上,利用员工对企业的项目满意度构建行为记录矩阵,通过协同过滤算法分析和设计了一套适用于人力资源信息管理的系统,实现参数设定、分区管理、职员管理、用户管理和生产管理五大模块的综合管理。对人力资源信息管理系统进行了具体的实验分析,结果表明:当1 571名员工产生28 325条员工评分记录时,2个节点和3个节点的系统响应时间分别为7.4 s和4.8 s,且明显小于非分布式算法,同时协同过滤算法比非分布式算法的MSE与MPE分别小0.39%、0.52%,本研究的协同过滤算法可以胜任人力资源管理系统的数据分布式计算任务。
协同过滤算法;Hadoop分布式;信息管理;系统设计;人力资源
近年来协同过滤算法的发展较为迅速,已经发展成为一种较为成熟的推荐算法[1-3],与此同时,分布式推荐算法成为推荐算法研究中一个新的研究方向[4]。通过将协同过滤推荐算法与人力资源信息管理系统研究以及Hadoop平台融会贯通[5],探索协同过滤推荐算法在人力资源信息管理系统上的实现[6]。这既有分析协同过滤算法在Hadoop平台上对于人力资源信息管理系统的可行性的理论意义,又有利用解决Hadoop平台下系统模块优化与推荐的现实意义。在行政和管理方面通过将人力资源型信息管理系统应用到工作中,能够有效地提高人力资源部门乃至整个公司的工作效率,最终实现工作流造成的规范化,流程化,系统化以及自动化。因此,做好人力资源信息管理系统的研究与设计并通过协同过滤算法进行优化对于实际工作有着十分重要的现实意义。
1 协同过滤算法
协同过滤算法现被广泛用于管理系统平台,其主要根据过往的行为记录,为用户群推荐符合其行为偏好的选择[7]。协同过滤算法主要可以分为两类,一种是基于用户体验与参与的协同过滤算法,还有一种是基于不同的流程与项目内容的协同过滤算法。无论是属于前者还是后者,其本质都是优化行为选择[8]。协同过滤的算法主要通过对参与到平台系统的所有行为选择,自动的构建出I-U的历史行为记录矩阵,再根据项目与项目之间的相近程度,演绎出Item相邻近的N个周围用户行为选择。根据相邻近的N个周围用户行为选择以及被推荐预测到的所有基于项目或用户群的行为来对现有行为的I进行闲的评分并由此产生推荐选择列表与选择以此优化现有的流程与选择[9]。其主要的流程如下:
1)平台系统的项目内容或用户群对目标的浏览与操作进行评分,这成为获取数据信息偏好的第一次设计行为。行为的评分表明用户群对项目的偏好或项目内容与选择的吻合程度。在一颗星到五颗星的评价体系之内,一颗星表明用户群的偏好程度较低或者项目内容与吻合程度非常低,五颗星表明用户群的偏好程度较低或者项目内容与吻合程度非常高。这样的元素项目集合(Preference、Item、User)表明了设计流程中的一次对外界信息的实际获取过程,对于大量的同类型元素项目集合所构成的大规模数据信息文件就是协同过滤算法的初始输入。
2)在生成的I-U行为偏好矩阵IU=(Pij)m×n中,根据用户的选择与偏好和项目的内容在历史行为偏好矩阵中分别输入相互对应的U和I,矩阵的分布顺序与结构则以I为行,以U为列进行构建与输入以此构建出用户历史行为偏好矩阵。其中Ii表示项目,Im表示第m个I,Uj表示用户群,Un表示第n个U,Pij则表明了第i个用户群在系统平台上的操作对于项目的喜好程度或者项目j内容与推送选择的吻合程度[10]。
3)根据算法所自动构建的历史行为偏好I-U矩阵,演绎出I相邻近的N邻居用户行为选择,并且通过以余弦系数、Pearson系数等计算相近程度的算法来演绎出基于用户群和项目所有行为的相近度[11],以下是本文在计算Pearson系数时所采用的计算方法:

其中,S(Ii,Ij)表明了一般系统平台里面子项目的某i项与某j项间的相近程度。Uij则是对于Ii的历史行为偏好对于Ij历史行为偏好相互影响范围有所重合的交集。Pi表示项目的平均偏好。用户群对于项目i最终的推荐结果偏好预测值的计算公式如下[12]:

再依据演绎出的预测偏好值进行筛选过滤,最终形成最优选择。
2 人力资源信息管理系统
2.1 人力资源系统功能的划分
人力资源信息管理系统是为了方便企业及时便捷的获得与追踪各种人事管理方面的信息而应运而生的管理系统,它能够方便企业获得各种咨询的信息资料,人事资源管理,进行信息的筛选,过往数据的存取等种种多样化的服务[13]。本系统主要采用模块优化和筛选以及面向对象相结合的方法,在Hadoop平台上采用协同过滤算法对人力资源信息管理系统进行分析设计与研究,本系统最终实现的主要功能分为5大部分,如图1所示。

图1 系统的功能划分
2.2 系统的整体架构
通过对现有企业的人力资源信息管理的既定流程现状及存在的弊端进行细致的分析,将人力资源信息管理系统按照三层分错构架的流程模式进行构建。利用Hadoop分布式框架分布基础架构对外部的用户群提供优化的选择与Web服务,因而不仅满足了不同的用户群分布式的访问和流程操作以及推荐出最优化的可供选择[14]。Hadoop分布式框架分布基础构架能够处理大数据,对于企业繁杂的人事信息储存与处理占有优势,具有分布式的特点[15],方便操作系统的用户群方便快捷的对业务信息以及公司资料进行高效的查找与处理。人力资源信息管理系统中的用户群操作界面主要是利用一般的Web网页浏览器为媒介进行设定和操作,从而使得用户操作人员随时随地以不同的方式 (如Intranet、Internet、LAN、WAN等)进行不同的接入访问以及对共同的数据库进行控制[16-18],这都有利于保护数据库的安全,是操作高效有序。为了实现预设的人力资源型信息管理系统的目标,文中对人力资源信息管理系统构建了三层的结构从而对人力资源信息管理系统进行深入的研究与开发设计,其具体结构如图2所示。

图2 系统的结构设计
2.3 算法流程
为了优化人力资源信息管理系统的设计更好地为用户群推荐优化的行为选择,需要借助Hadoop分布式构架平台以及协同过滤算法,在完成了理念上的设计之后还需要将这样的流程结果转化为MapReduce分布式构架的可实际操作的MapReduce流程算码,这样才是在Hadoop平台上对进行的真正的协同过滤筛选,实现对人力资源信息管理系统的优化。具体实现步骤如下:
Step.1:首先就用户群和偏好生成特定的向量U=((I1,P1),(I2,P2), …,(It,Pt)。 在生成的特定向量中,所选择的用户向量仅仅包括有过历史行为的对选择表现出各种偏好的用户群,通过演变得到新的向量(n1k,n2k,…,nmk)是项目的共线矩阵,可得:



Step.3:在演绎的过程中得到了分向量Col"=((I1,Col1),(I2,Col2),…)。在协同过滤的分布式筛选推荐中,有上述的步骤自动生成了文件Tag,再由Reduce的流程计算出PkuRowIk,最终输出用户群的K值以及V值。具体的MapReduce操作流程如下:

Step.4:由上述的流程在演绎出预测向量U"=((I1,Col1),(I2,Col2),…)。其输入以分向量ColU"文件为准,其具体的MapReduce操作流程如下:

Step.5:按照流程结构生成以项目的内容费分类的预测向量I′=((U1,P1),(U2,P2),…,(Un,Pn))。通过将步骤2)和步骤4)相结合共同生成中间预测向量,再按照步骤3)的方法,利Isum以及U"为媒介,实现对U"向量中的实现演绎。选取GroupKey为项目连接键。具体的Map Reduce操作流程如下:

Step.6: 演绎出最后的预测向量 U′=((I1,P1),(I2,P2),…),根据上个流程的结果为输入的对象进行如下Map Reduce操作流程:

通过以 Hadoop平台为媒介,利用完整的MapReduce流程实现了协同过滤分布式筛选推荐算法。以上的6个步骤保证了MapReduce的作业文件按照顺序依次计算每一个流程环节的任务,环节中的每一项内容都是对之前流程环节输入的输出。
3 实验结果及分析
3.1 实验环境
人力资源信息管理系统选取SQL作为后台的数据库。选取SQL主要是考虑它作为Microsoft Back产品系列的重要组成部分,擅长一般服务器以及客户服务的大型关系数据库,并且利用一般的Web网页浏览能够满足大型的Web站点服务器以及和企业人事资源数据的处理。以Windows 7作为操作系统,Hadoop平台作为底层架构,Jave作为编程环境,实现分布式协同过滤算法的调试和运行。
3.2 结果分析
人力资源管理系统中的员工信息记录存储较小数据量条件下,通过伪分布式模式或小集群的Hadoop分布模式可以胜任完全分布式模式下的大数据分布式计算任务。人力资源管理系统项目利用内容或用户群对目标的浏览与操作进行评分,在五大部分功能下,共有28 325条员工评分记录,如表1所示。

表1 评分数据量
分别选取参数设定、分区管理、职员管理、用户管理和生产管理作为实验数据,当预测员工对人力资源管理的评分时,在不同条件下算法的响应时间,如图3所示。

图3 系统响应时间
由图3可知,包含两个节点和3个节点的Hadoop分布式系统下的人力资源管理系统响应时间显著的小于传统的非分布式算法的响应时间。其中,当员工数量为1 571时,2个节点和3个节点的系统响应时间分别为7.4 s和4.8 s。这是因为2个节点或者3个节点的Hadoop集群均包含一个主节点和一个从节点,主从两个节点除了负责计算任务外,还要负责数据集群信息资源的调度;而包含3个节点的响应时间明显优于两个节点的分布式协同过滤的算法。因此,若人力资源管理系统中的员工信息集群包含更多的节点,则计算几乎可以瞬间完成,这恰恰体现分布式协同过滤算法在系统管理中的即时性优势。
在算法的精确度方面,利用均方误差MSE、平均相对误差绝对值MPE作为衡量协同过滤算法的精度评价指标,其值越小,算法描述的人力资源信息数据则越精确,其计算公式为:
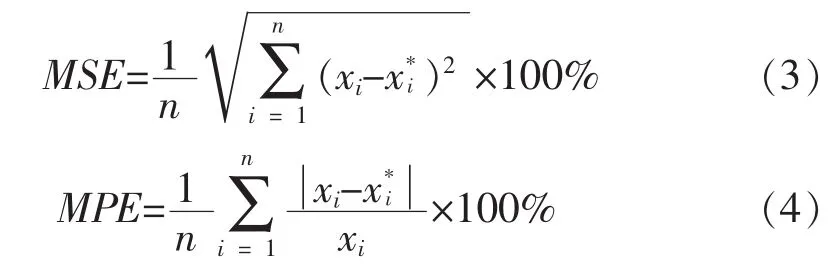
其中,n表示员工数量,xi表示实际评分,x*i表示预测分数。分布式协同过滤算法与非分布式算法的精度比较,如图4所示。

图4 精度比较
由图4可知,在员工数量相对较少的条件下,协同过滤算法的精度较差,而随着员工数量逐渐增大时,其包含的数据信息亦逐渐增大,其精度也逐渐提高并优于非分布式算法。其中,当员工数量为1 571时,协同过滤算法比非分布式算法的MSE与MPE分别小0.39%、0.52%。这是因为人力资源管理系统设计中,Preference值和Item值对外界信息的实际获取过程时,对于员工数量相对较少所构成的小规模数据信息文件,在Map阶段输出键值对较少,计算误差大。这说明,本研究提出的协同过滤算法比较适合大型企业中较多员工背景下的人力资源信息管理系统。
4 结 论
本研究通过协同过滤分布式筛选算法的演绎,基本能够满足企业的日常进行人力资源信息管理的需求。采用Hadoop分布式构架平台,以算法语言进行构建流程模型,通过对使用人力资源信息管理系统的用户群的历史行为记录进行有效地拟合与预测,筛选出最符合用户群行为偏好的选择,在协同过滤算法优化下的人力资源信息管理系统具有很强的规划性和高效性以及整体性,从而提高了人力资源管理部门在管理中的工作效率,对于系统后期的维护协同过滤推荐算法也能根据以往的筛选推荐记录以及修订方案快速给出最合适的项目方案,从而整体上优化了系统的性能。
[1]孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013(11):2721-2733.
[2]李改,潘嵘,李章凤,等.基于大数据集的协同过滤算法的并行化研究[J].计算机工程与设计,2012,33(6):2437-2441.
[3]肖强,朱庆华,郑华,等.Hadoop环境下的分布式协同过滤算法设计与实现[J].现代图书情报技术,2013(1):83-89.
[4]秦凯,吴家丽,宋益多,等.基于社会信任的协同过滤算法研究综述[J].智能计算机与应用,2015,5(4):55-59.
[5]吴泓辰,王新军,成勇,等.基于协同过滤与划分聚类的改进推荐算法[J].计算机研究与发展,2011,48(2):205-212.
[6]杨震,赖英旭,段立娟,等.邮件网络协同过滤机制研究[J].自动化学报,2012,38(3):399-411.
[7]贺桂和.基于用户偏好挖掘的电子商务协同过滤推荐算法研究[J].情报科学,2013(12):38-42.
[8]王鹏,王晶晶,俞能海.基于核方法的User-Based协同过滤推荐算法 [J].计算机研究与发展,2013,50(7):1444-1451.
[9]范波,程久军.用户间多相似度协同过滤推荐算法[J].计算机科学,2012,39(1):23-26.
[10]杨阳,向阳,熊磊.基于矩阵分解与用户近邻模型的协同过滤推荐算法 [J].计算机应用,2012,32(2):395-398.
[11]荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014(2):16-24.
[12]刘枚莲,刘同存,吴伟平.基于网络消费者偏好预测的推荐算法研究 [J].图书情报工作,2012,56(4):120-125.
[13]王亚洲,林健.人力资源管理实践、知识管理导向与企业绩效[J].科研管理,2014,35(2):136-144.
[14]陈曦,陈华钧,顾珮嵚,等.一种基于Hadoop的语义大数据分布式推理框架 [J].计算机研究与发展,2013,50(2):103-113.
[15]孙福权,张达伟,程勖,等.基于Hadoop企业私有云存储平台的构建 [J].辽宁工程技术大学学报:自然科学版,2011,30(6):913-916.
[16]何娣,马慧斌,韩凯旋.基于Delphi与Access的人力资源信息管理系统设计 [J].现代电子技术,2012,35(12):56-58.
[17]魏志静.就业服务信息化整体解决方案的设计与实现[J].电子科技,2013(8):180-182.
[18]翟国涛,洪增林,马天宇.城市老工业区产业转型系统动力学模型研究[J].西安工业大学学报,2015(1):70-76.
Human resource information management system based on collaborative filtering algorithm
ZHANG Yu
(Business School Hohai University,Nanjing 211100,China)
In order to facilitate timely and convenient access to business and tracking a variety of personnel management information,based on the Hadoop distributed architecture platform,the use of staff of the enterprise satisfaction with the program to build a matrix acts recorded by the collaborative filtering algorithm analysis and design a set of It applies to human resources information management system,parameter setting,partition management,staff management,integrated management of user management and production management of the five modules.Human resources information management system specific experiments,the results showed that:when 1 571 employees produced 28,325 employees score recorded two nodes and three-node system response time was 7.4 s and 4.8 s,and significantly less than non-distributed algorithms,collaborative filtering algorithm,respectively,while smaller than the non-distributed algorithm MSE and MPE 0.39%,0.52%,this research collaborative filtering algorithm capable human resources data management system for distributed computing tasks.
collaborative filtering algorithm;Hadoop distributed;information management;systems design;human resources
TN18
:A
:1674-6236(2017)03-0023-05
2016-05-12稿件编号:201605111
国家自然科学基金资助项目(61303005);国家社会科学基金资助项目(10bzx73)
张 玙(1991—),女,安徽淮北人,硕士研究生。研究方向:人力资源管理。
