基于多特征的视频关联文本关键词提取方法
2017-03-01王万良
王万良,潘 蒙
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
基于多特征的视频关联文本关键词提取方法
王万良,潘 蒙
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
针对互联网多媒体视频数量的爆炸式增长导致快速获取视频的内容变得非常困难问题,提出了一种基于多特征的关键词提取算法TFL-WS算法.通过分析视频包含丰富的相关文本信息的特点,建立了基于改进TF和多特征的候选词权重计算公式,该公式将候选词的统计特征与位置权重动态结合起来,并考虑候选词的词性、词跨度等属性,借助扩展的同义词词林来提取关键词,通过提取到的关键词来表述视频的内容信息.实验结果表明:改进后的算法所提取的关键词效果更好,在准确率和召回率方面都有一定的提升,并且能够很好的表示视频的内容.
关键词提取;视频内容;TF;特征词权重
随着互联网的快速发展以及国务院对三网融合的大力推进,网络中的多媒体业务得到了高速增长.面对互联网视频的爆炸式增长,由于目前多采用人工标注的方法对视频内容进行标注,这种方式存在人为主观因素,同时视频内容的自动获取和监管也面临严峻的挑战.因此,通过大量分析互联网视频内容的特点,发现视频本身包含了丰富的文本信息,通过获取这些文本信息并提取关键词,从而能够快速获得视频内容概要,进而可以得到视频内容.
目前,关键词提取算法主要分为4类:1) 基于统计的方法,主要通过词语的统计信息来提取文档的关键词,这种方法相对简单,并且无需训练集,其中典型的算法有TF,TF-IDF[1-2]和PAT-tree等,李静月等[3]考虑将文本结构和词性等属性结合词频来提取关键字,从而提高算法的提取精度;2) 基于机器学习的方法,如KEA[4],SVM[5]和神经网络[6]等,这类方法将关键词提取问题转化为分类问题,从而提取文档关键词,白晓雷等[6]在研究和抽取词语特征的基础上,提出网络隐层节点数式子和词语特征表达式来构建网络,实现关键词抽取;3) 基于语义的方法[7],这种方法将语义特征融合到提取过程中以提高算法性能,王立霞等[8]构建词语语义相似度网络,将词语的语义特征应用于关键词提取中;4) 基于复杂网络的方法[9-10],这类方法是根据文本特征词之间的关系构建文本的复杂网络模型,提取网络中重要的结点作为关键词,谢凤宏等[10]提出基于加权复杂网络的提取算法,其根据候选项间的关系构建复杂网络,通过加权系数来计算候选项权重值.本研究提出的关键词提取算法针对的是视频关联文本信息,且是从单个视频关联文本信息中直接提取关键词.
1 改进的预处理技术
视频包含了丰富的关联文本信息,包括标题、内嵌文字和评论等,这些文本信息是与视频内容直接相关的,因此提取这些文本信息的关键词可以表示视频的内容.但爬取的文本信息不能直接分析,因为其中评论包含了一些没用的垃圾评论,这些评论如果没有被过滤掉,将直接影响关键词提取的准确性,因此需要对初始文本进行预处理后才能用于关键词提取.针对获取到的视频文本内容格式与传统的中文分词所分析的文档有所不同,故将视频的标题、内嵌文字、有效评论三部分作为一个文档进行处理.同时利用垃圾评论过滤方法来过滤掉无效评论,以提高视频文本信息对于视频内容描述的准确性.
首先采用基于规则的过滤方法对垃圾评论进行过滤.其基本思想是设置一些过滤规则,对于符合其中的一条或多条的评论,判定为垃圾评论,将其过滤掉.规则如下:
1) 过滤短评论.通过大量分析评论发现,长度较短的评论对于视频内容的分析没有参考价值,并且多数是与视频内容无关的,因此当一条评论的长度小于6~8个字节,判定为垃圾评论.
2) 定义一个垃圾关键词词库.典型的垃圾评论中一般包含广告链接、QQ号、电话号码以及网络常用语等垃圾词语,因此通过分析建立一个垃圾关键词词库,如果评论中出现一条或多条垃圾评论关键词,则判定其为垃圾评论.
3) 去除重复评论.评论集一般会出现多条重复的评论,因此过滤掉重复的评论,只保留其中的一条作为有效评论.
4) 非规则字符.设置一个阈值,如果一个评论中的非规则字符的占比超过这个阈值,即将其判定为垃圾评论.
在预处理过程中,利用数据结构表示词语的相关统计数据.使用四元组
在垃圾评论过滤的基础之上,根据视频关联文本信息的结构和特点,结合定义的数据结构,对视频关联文本的具体预处理步骤如下:
步骤1 输入视频关联文本信息.
步骤2 利用基于规则的过滤方法对垃圾评论进行过滤,从而得到有效的评论信息.
步骤3 对经过垃圾评论过滤后的视频关联文本信息进行中文分词.
步骤4 去除停用词.根据给定的停用词表对停用词进行过滤.
步骤5 词性过滤.对语气助词、连接词、副词、介词等不能很好反映视频文本信息并且对关键词提取结果的准确性有影响的词性过滤掉.
步骤6 统计词在各部分出现的词频以及出现的部分数,得到四元组
步骤7 输出预处理后的文本统计信息.
2 关键词提取
传统的基于统计的关键词提取算法如TF和TF-IDF算法只是简单的从统计学的角度进行分析,并没有考虑到候选词的特征属性以及候选词在文档中分布的情况,所以关键词提取的准确性不是很好.因此,考虑视频关联文本的特点,以及在词频统计的基础之上,结合候选词的位置、词性以及词跨度等属性进行定量分析.
2.1 候选词词性选择
文档经过分词系统分词操作后,会出现很多如“而”、“其”、“且”、“与”、“之”等词,如果不考虑词性而只从统计角度分析的话,那么这些词很有可能被提取为关键词,然而这些词对文档并没有任何意义,因此,必须将这些词过滤掉.
系统经过分词后的结果包括候选词及其词性,格式为“候选词/词性”.Hulth[11]认为将名词短语作为候选词进行关键词提取,将名词短语作为关键词提取比直接从分词结果直接提取效果更好.同时结合ICTCLAS 2015分词系统的特点和分词后的结果,将选择名词、名词词组以及动名词作为候选词,考虑到这些词性更能准确的表述视频的内容.
同时,对于一个对象,不同的人、不同的时间可能会有不同的描述,这就出现了同义词的情况,如果不合并同义词,那么将会影响关键词提取的结果,比如“鲁迅”和“周树人”是两个词,而这两个词指的是同一个人,因此有必要将人名、机构名等短语,只考虑这些词的词性而不考虑词性的变化,以提高关键词提取的准确性.
2.2 候选词权重计算
候选词权重计算是整个关键词提取算法中最重要的一步,其作用是计算选取的词相关的特征权重,得到候选词的权重结果,以便获取关键词.
1)候选词的频率和位置特征.词频(TF)是一种统计方法,表示候选词在一篇文档中的次数,其公式为
(1)
式中:分子为候选词在文本中出现的次数;分母为文本中所有词出现的次数总和.然而候选词频率的计算公式中并没有考虑候选词所在的位置对候选关键词提取的影响,对于一篇文章而言,在首段和尾段出现的候选词更能表示文章的内容,因此也更应该赋予更高的权重.同理,对于视频相关文本而言,可以分为三部分:标题、内嵌字幕以及有效评论,标题中的候选词是最能反映视频的内容,内嵌字幕次之,评论信息相对表示能力更弱,因此必须对各个部分赋予不同的权重,这样提取的关键词才能更加准确.
根据上面传统词频统计方式的缺点,将词频(TF)和位置两个词特征动态结合起来,在计算各部分的候选词词频的同时就考虑位置权重对候选词的影响,然后对三部分的统计结果进行累加.因此改进了之前的词频公式,改进后的公式为

(2)
其中:tfi为候选项w在第i部分中出现的频率,候选项在每部分的出现频率用式(1)计算;pi为候选词在第i部分中的位置权重值,pi对应的取值为
(3)
其中:pi的取值参照文献[12].p1为候选词在标题部分出现的位置权值;p2为候选词在内嵌字幕部分出现的位置权值;p3为候选词在有效评论部分出现的位置权值.
2)词跨度权值.对于一个文档而言,一个候选词可能只出现在某一部分,也可能在多个部分都有出现.因为候选关键词所跨部分越多,其更能反映该文档的内容,也更能概括视频的内容,因此其越适合提取作为关键词.因此,在计算候选词的权值上也考虑了词跨度属性,相应的词跨度权值计算式为

(4)
其中:sw为候选词w在视频文本文档中出现的部分数;s为视频文本文档的部分总数,取值为3.
2.3 改进后的算法
综合上面词性选择和词相关特征的权重计算,最终得到的改进的关键词提取权值计算公式为

(5)
式(5)计算出的结果为候选词的综合权值.对于任意一篇视频文本文档,经过预处理操作后,计算文档中各候选词的权重值,并对候选词权重值的计算结果进行排序,选择前K个候选词作为该文档的内容,以描述该文档对应的视频的内容.
对于改进后的算法,首先对于候选词的词性,直接选择能表述视频文本内容的词性作为候选项,减少不必要的统计计算;然后将候选项的词频和位置属性动态结合起来,每个候选项在每部分统计词频后都将其和位置权重值进行计算,所有部分都统计结束才是候选项这两个属性的加权权重值,这种动态结合的方式更能体现位置权重值的特性;最后在统计词频的同时记录候选项的跨度值,将在多个部分出现的候选项赋予更高的权重值.
2.4 算法流程
关键词提取的流程图如图1所示.
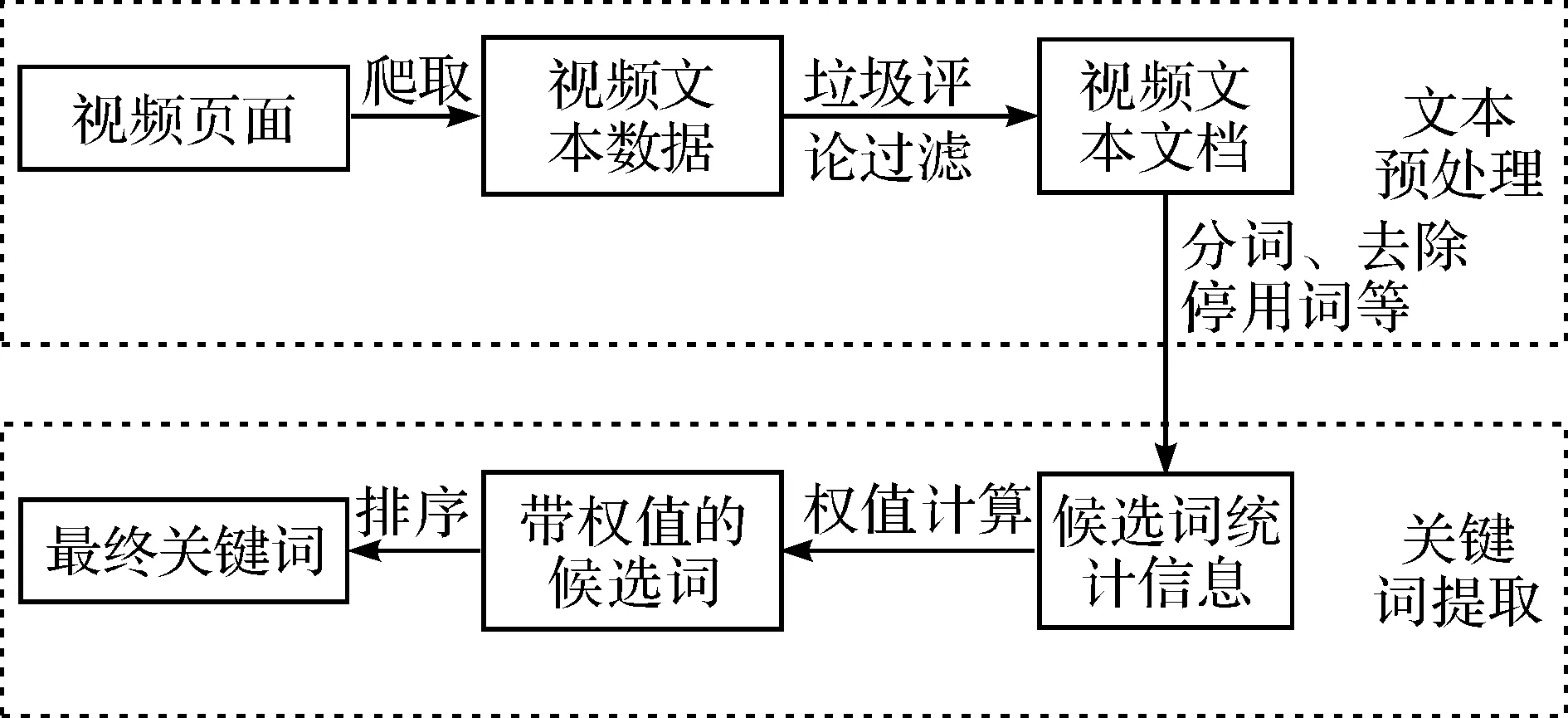
图1 关键词提取流程图Fig.1 Keyword extraction flow chart
关键词提取流程主要分为两个部分:
1)视频相关文本预处理.采用第一部分的预处理方法来处理数据集.
2)关键词权重计算和排序.根据预处理得到的文本,运用改进后的算法,对候选词的权重值进行计算,得到带有权重值的候选词后再进行排序,最后获得关键词.
根据上面的描述,视频文本文档关键词提取算法可描述为:
输入:视频关联文本D.
输出:D的前K个关键词.
步骤1 对视频关联文本D进行预处理操作,得到候选项的特征值及其统计结果.
步骤2 根据式(2,3)计算候选词的TFL值.
步骤3 根据式(4)计算候选值的跨度权值WS值.
步骤4 根据式(5)得到候选词的综合权重值,对带有权重值的候选词进行排序,取前K个候选词作为该视频关联文本的内容.
改进后的算法是针对单个视频关联文本,即无需训练集就可以从单个视频关联文本中提取出关键词,而不需扫描整个待处理视频关联文本集,因此算法的时间复杂度为O(N),所以在时间效率上更优.
3 实验与分析
3.1 实验数据
为了验证关键词提取算法TFL-WS的有效性,在优酷、爱奇艺等国内知名视频网站随机抽取500个视频,并获取其页面的相关文本信息,将其作为获取关键词的实验数据集.同时,实验中使用的实现语言为Java,由于分词是算法的基础,分词的好坏将直接影响到关键词的获取准确性,因此,实验中采用中科院的ICTCLAS 2015分词系统对数据集进行分词.
3.2 评价方法
一般提取算法的评价标准都是将结果和人工标注好的进行对比.因此,实验也采用准确率、召回率和F1测试值来评价实验结果.
1)准确率(Precision)指人工抽取和自动抽取都判定为关键词的数目与自动抽取为关键词数目的比值,其反映了关键词提取的准确率.其计算公式为
(6)
2)召回率(Recall)指人工抽取和自动抽取都判定为关键词的数目与人工抽取为关键词数目的比值,其反映了关键词提取系统发现关键词的能力.其计算公式为
(7)
3)F1测试值(F1-Measure)是Precision和Recall的调和平均值.其计算公式为
(8)
其中:A为人工提取和自动提取都被判为关键词的个数;B为人工提取为非关键词而自动提取为关键词的个数;C为人工提取为关键词而自动提取为非关键词的个数.
3.3 实验结果分析
对于数据集进行人工标注关键词,每篇的关键词个数设置在5~10个之间,算法提取时默认抽取10个关键词.郭建波等[13]提出的TF-WF算法同样应用于单个文本文档,因此该实验选取传统的TF-IDF算法、TF-WF算法与改进后的算法TFL-WS作对比,实验数据表明算法TFL-WS在提取效果上更好.

图2 准确率Fig.2 Precision

图3 召回率Fig.3 Recall
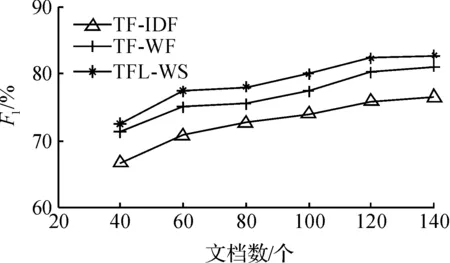
图4 F1测试值Fig.4 F1 test values
图2~4为传统的TF-IDF算法、算法TF-WF和算法TFL-WS的实验结果对比图,根据实验结果可以得出本研究提出的改进算法在这三个方面都有明显的提升.由于传统的TF-IDF算法仅考虑了候选词的统计信息,因此其性能相对是最差的,而TF-WF算法在词频的基础上考虑了候选词首次出现的位置,然而如果一个词在开头出现过但后面却再也没出现过,那么这个候选项有可能不是关键词,而如果通过词跨度属性,即如果候选词在几部分都出现过,这样的词会更有可能是关键词,因此改进后的算法在准确率、召回率以及F1评价指标上效果都更好.
同时,为了做对比实验,将关键词提取的个数分别设置为5个,8个和10个,然后将TFL-WS算法与传统的TF-IDF算法以及TF-WF算法作对比.
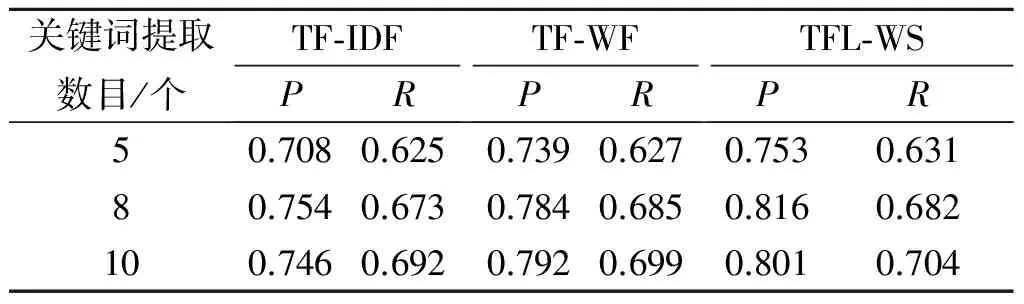
表1 实验结果对比
从表1中可以看出:当设置关键词提取的个数不同时,算法TFL-WS在准确率和召回率上都要优于传统的TF-IDF算法和TF-WF算法,说明改进后算法的稳定性.由于在统计词频的同时,动态结合候选词所在的位置赋予不同的权重值,同时将词性和词跨度考虑在内,因此改进后的算法更加有效.
4 结 论
针对视频内容快速获取及监管的问题,结合关键词提取技术对视频内容进行分析,考虑视频文本信息的特点以及候选词的词性特征,在此基础上将候选词位置权值和词频相结合以改进传统的TF公式,并结合词性、词跨度等特征,定义了一个基于多特征的关键词提取公式.实验结果表明,TFL-WS算法在性能上比传统的TF-IDF算法等更好,也能很好地描述视频的内容.当然,该方法也有一些不足和需要改进的地方.对于未登录词的识别问题,因为互联网的快速发展,使得每天都会有大量新的词语产生,而现有的分词词典无法实时更新这些词语,使得新出现的词无法在分词过程中被正确切分,从而导致关键词提取算法无法提取这些表达视频文本文档的新词,这些也是今后进一步研究的地方.
[1] TURNEY P D. Learning algorithms for keyphrase extraction[J].Information retrieval,2000,2(4):303-336.
[2] EL-BELTAGY S R, RAFEA A. KP-Miner:a keyphrase extraction system for English and Arabic documents[J]. Information systems,2009,34(1):132-144.
[3] 李静月,李培峰,朱巧明.一种改进的TFIDF网页关键词提取方法[J].计算机应用与软件,2011,28(5):25-27.
[4] JONES S, PAYNTER G W. Human evaluation of kea, an automatic keyphrasing system[J]. Jcdl,2001(1):148-156.
[5] LOPEZ P, ROMARY L. HUMB: automatic key term extraction from scientific articles in GROBID[C] //Proceedings of the 5th International Workshop on Semantic Evaluation. Uppsala, Sweden: ACM,2010:248-251.
[6] 白晓雷,黄广君,段建辉.一种基于BP神经网络的关键词抽取方法[J].合肥工业大学学报(自然科学版),2014(7):808-811.
[7] 刘端阳,王良芳.基于语义词典和词汇链的关键词提取算法[J].浙江工业大学学报,2013,41(5):545-551.
[8] 王立霞,淮晓永.基于语义的中文文本关键词提取算法[J].计算机工程,2012,38(1):1-4.
[9] 刘通.基于复杂网络的文本关键词提取算法研究[J].计算机应用研究,2016(2):365-369.
[10] 谢凤宏,张大为,黄丹,等.基于加权复杂网络的文本关键词提取[J].系统科学与数学,2010,30(11):1592-1596.
[11] HULTH A. Improved automatic keyword extraction given more linguistic knowledge[C]//Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing Association for Computational Linguistics. Stroudsburg: Association for Computational linguistics,2003:216-223.
[12] 罗繁明,杨海深.大数据时代基于统计特征的情报关键词提取方法[J].情报资料工作,2013,34(3):19-20.
[13] 郭建波,谢飞.基于多特征的关键词抽取算法[J].合肥工业大学学报(自然科学版),2015(9):1215-1219.
An keyword extraction approach from video associated text based on multiple features
WANG Wanliang, PAN Meng
(College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China)
The explosive growth of multimedia video on the Internet leads to access the content of the video more and more difficulty, a keyword extraction algorithm TFL-WS based on multiple features is proposed in this paper. Through analyzing the characteristics of the video which contains abundant related text information, a word weight calculation formula which is based on improved TF and multiple features is established. The statistical characteristic of candidate words and location weight arecombined dynamically in this formula. Considering the part of speech, word span of candidate words, expanded synonym dictionary is used to extract keywords. So the content of the video information can be expressed by the key words. The experimental result shows that the improved algorithm of extracting the keywords has a better result. It has some improvement in the precision and recall rates, and it can represent the video content much better.
keyword extraction; video content; TF; term weight
(责任编辑:刘 岩)
2016-03-24
国家“十二五”科技支撑计划项目(2012BAD10B01);浙江省重大科技专项项目(2013C01113)
王万良(1957—),男,江苏高邮人,教授,博士,研究方向为人工智能和优化调度,E-mail:zjutwwl@zjut.edu.cn.
TP181
A
1006-4303(2017)01-0014-05
