基于主题模型的(Aspect,Rating)摘要生成方法研究
2017-01-10罗宜元计春雷
吕 品,汪 鑫,罗宜元,计春雷
(上海电机学院电子信息学院,上海 201306)
基于主题模型的(Aspect,Rating)摘要生成方法研究
吕 品,汪 鑫,罗宜元,计春雷
(上海电机学院电子信息学院,上海 201306)
提出基于短语参数学习的主题模型TMPP(Topic Model based on Phrase Parameter )对在线评论中被评价实体的aspect和与之对应的rating进行抽取.TMPP具有三个特点:1)评论用“短语袋”表示;2)将标准的LDA中表示文档-主题的参数扩展为 (aspect,rating)集;3)融合了先验知识.介绍了TMPP模型参数的物理含义、模型的生成过程以及先验知识的获取和表示方法;阐述了在TMPP模型中引入方面集聚类使用先验知识的原因与好处、TMPP模型提取(方面,等级)对形成(aspect,rating)摘要的原理.以真实的在线产品评论数据集为实验对象,在实验过程中引入先验知识的方面识别分析和等级预测精度分析,列出了五类产品相关方面和对立的情感词的实验结果.通过与已有的基线方法比较,实验表明若评论集中每篇评论有一个总体等级,TMPP能产生高质量的(aspect,rating)摘要.
主题模型;(aspect,rating)摘要;短语袋;TMPP
1 引言
Web技术的发展使在线评论成为决策支持的有价值资源[1].然而,阅读者要从海量评论中找到所有不同甚至可能相反的观点几乎不可能.因此,对在线评论进行挖掘,生成(aspect,rating)摘要,方便用户对目标实体获得不同视角的评价必然成为情感分析研究不可或缺的一部分.Aspect(方面)指的是被评价实体的某个物理组成部分、功能或性质、亦可以是被评论事件的某一个特征等[2].Rating(等级)是用1到5之间的整数表示的情感满意度.一般,评论网站只要求用户对被评价实体给出一个用不同星号个数表示的总体评价(总体等级).尽管总体等级对潜在用户的决策有帮助,但提供的信息并不充分,因为不同用户可能有完全不同的需求.若能从在线评论中挖掘得到(aspect,rating)摘要,便能让潜在的购买者更深入的了解产品质量,通过对同类型的不同产品进行权衡,最终做出明智的购买决定.本文提出基于短语参数学习的主题模型TMPP对在线评论进行(aspect,rating)摘要挖掘.挖掘(aspect,rating)摘要由2项任务构成:1) 方面识别,即抽取被评价实体的相关方面集;2)等级预测,即为每一个方面分配一个整数,表示评论者对该方面的情感满意度.
2 相关研究工作
近年来,绝大多数观点文摘挖掘研究工作的重心是方面识别[1,3],只有极少数工作是在方面识别的同时给出方面的预测等级[4,5].方面识别的经典方法有2类:频率方法和主题模型方法.频率方法采用在高频率名词短语上应用一些约束识别被评价实体(产品)的方面[2,6~8].该方法的局限性在于:1)可能会丢失低频率的方面和它们的变化形式[9],并产生许多不是表示被评价实体方面的名词;2)需要人工调整各种参数,移植性差.主题模型方法能克服以上不足[5,10~12],但通常采用先识别方面,后再对方面进行等级预测的手段,方面识别和其相应的等级预测以串行方式进行,其结果会导致挖掘过程中的错误累积.
另外,评论文本有两种表示模型:“词袋”模型和“短语袋”模型.短语是对原始的评论经过预处理后得到的(t,s)信息对,t表示aspect,s表示与某一aspect对应的观点.研究工作[9~11,13,14]使用“词袋”模型表示评论,虽然它们也采用了一些技术挖掘评论中的局部主题或子主题(方面),但研究重心是将识别的方面按情感进行聚类.然而,(aspect,rating)文摘挖掘目标是识别方面和其对应的等级,即尝试从同一被评价实体的评论集合中推断出被评价实体的方面和其对应的评价等级.文献[4~5]使用“短语袋”模型表示评论,前者使用主题模型PLSA和Structured PLSA对短评论挖掘,产生(aspect,rating)文摘;后者提出了方面与其等级具有依赖关系的ILDA主题模型.然而,尽管主题模型能输出表示某一主题的词集,但词集中的词往往在语义上不相干,即主题的质量不高[1].
为了解决挖掘过程中的错误累积和主题质量欠佳问题,本文设计了主题模型TMPP,它用“短语袋”模型表示评论,将标准的LDA中表示文档-主题的参数θ扩展为(aspect,rating)集,对aspect和 rating同时建模,以减少错误累积;引入潜在聚类变量c表示领域先验知识,指导模型产生质量更好的方面.
3 TMPP模型
3.1 TMPP引入方面集聚类的原因与好处
对被评价实体进行评价,就是从在线评论中抽取评价实体的各方面(aspect),并基于评论的总体等级,用1到5之间的整数预测评价实体各方面的情感满意度(情感等级rating),于是产生了形成(aspect,rating)摘要的方面和与之相应的情感等级对.一个评价实体有许多(aspect,rating)对,故要进行方面聚类,这就是TMPP引入方面聚类的原因.为了克服总体等级的片面性,TMPP模型整合了一个方面聚类变量c,将总体等级分解成每个方面对应的情感等级,产生一个有利于潜在用户进行决策支持的(aspect,rating)摘要,体现了TMPP引入方面聚类的好处.
3.2 TMPP输出(aspect,rating)信息对的原理
TMPP模型获取(aspect,rating)信息对的原理简述如下:
(1) 利用整合了先验知识的TMPP寻找被评价实体中语义上更连贯的方面.
(2) 通过聚类算法对相同聚类的等级预测对数量和不同聚类的等级预测对数量进行分类.x表示相同聚类的等级预测对数量,y表示不同聚类的等级预测对数量.
(3) 引用等级预测的聚类相似度的度量标准公式来预测等级相似度值.
(4) 最终,获取如本文表3至表6的被评价实体的评论摘要表.
3.3 TMPP模型参数的物理含义
TMPP模型的盘子示意图如图1所示.
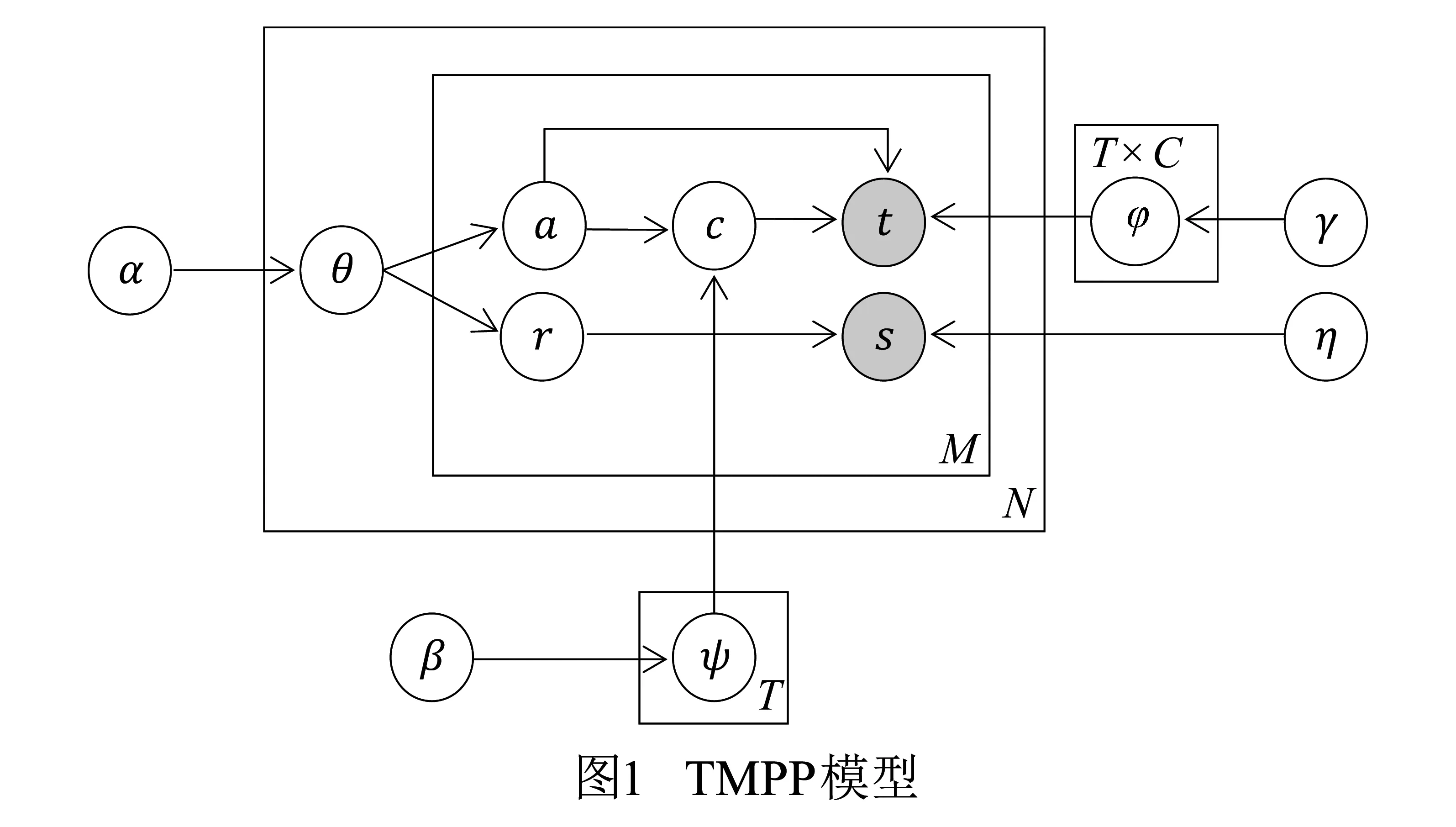
其中,模型参数的物理含义如下:
a:潜在方面(aspect);
r: 方面对应的潜在等级(rating);
c: 潜在的聚类变量;
t: 重要的方面词,是被观察变量;
s: 重要方面词所对应的情感词,是被观察变量;
(tm,sm): 第m对观点短语,m=1,2,…,M;
α,β: Dirichlet参数;
θ:服从参数为α的狄利克雷分布的随机变量,是文档层的(aspect,rating)集.对每一对(aspect,rating),θ包含了产生aspect和rating组合的概率,每一篇评论抽样一次θ。固定θ后,再为该评论产生观点短语,且假定潜变量am和rm被独立抽样;
T×C:聚类结果,T为方面的个数,C为聚类的个数;
ψ,η: 多项式分布参数;
ψ:对p(cluster|aspect)分布建模,ψ是服从参数为β的Dirichlet分布;
φ:对p(t|aspect,cluster)分布建模,φ是服从参数为γ的Dirichlet分布.
3.4 TMPP模型的生成过程
与文献[4]不同,TMPP整合了潜在聚类变量c连接潜在方面a和被观察词t,输入是N篇评论,T个方面,C个聚类,每一篇评论有M个短语.TMPP用随机变量ψ对p(cluster|aspect)分布建模;用随机变量ψ对p(t|aspect,cluster)分布建模,并把随机变量θ作为高层的(aspect,rating)集.对每一个 (aspect,rating)对,θ包含了产生aspect和rating组合的概率.TMPP为每一篇评论抽样一次θ,固定θ后,再为该评论产生观点短语,且假定潜在变量am和rm被独立抽样,其生成过程如下:
1.选择θ~Dir(α),ψ~Dir(β),φ~Dir(γ)
2.选择c~Multi(ψ)
3.对于每一对观点短语(tm,sm),m∈{1,2,…,M}
(a)选择am~P(am|θ)和rm~P(rm|θ)
(b)选择c~P(c|am)
(c)选择tm~P(tm|am,c,φ)和sm~P(sm|rm,η)
P(tm|am,c,φ)和P(sm|rm,c,η)分别是以am,c和rm为条件的多项式分布.因此,联合概率分布如公式(1)所示.
P(a,r,t,s,θ,c|α,β,γ,η)=
p(tm|am,c,φ)p(sm|rm,η)]
(1)
已知一篇评论有M个短语,关键的推断是计算式(2)所示的潜在变量的后验概率.
(2)
4 先验知识
4.1 先验知识的获取
领域先验知识可从Web上中获取,因为通过调查发现,尽管评论文本的领域不同,但不同领域上许多被评价实体的方面是相同的.因此,可把从不同领域集中挖掘出的相同方面作为主题模型的先验知识,让这些先验知识指导TMPP模型产生高质量的方面.算法1给出了先验知识获取的具体方法.
算法1 先验知识获取方法
Input:
多个领域的评论语料
Output:
知识K
方法:
1. for eachDi∈DLdo
2.Ai←LDA(Di); //在每一个评论语料Di上运行LDA,并将得到的主题集赋给方面集Ai
3. endfor
4.A←∪iAi;
5.TC←k-means(A); //对所有领域产生的方面集A执行k-means聚类,产生一些连贯的主题簇
6. for eachTj∈TCdo
7.Kj←FPM(Tj); //对每一个聚类Tj执行频繁项集挖掘产生频繁2-模式集表示知识
8. endfor
9.K←∪jKj;
算法1包含3个步骤:1)在每一个领域的语料上运行LDA[15];2)对LDA运行得到的主题集进行聚类;3)从每一个聚类中挖掘出频繁模式.第1步执行后,算法1获得一个主题集,选取每一主题下概率较高的词表示主题.由于质量高的知识应该跨领域共享主题,所以可利用频率方法识别频繁出现的词作为先验知识,以保证知识的质量.但是,对于先验知识,还存在2个需要解决的问题:1)特定的方面可能仅出现在该方面所在领域.如果在频率方法中简单使用一个频率阈值,将无法区分一般的方面和特定的方面;2)词在不同的领域可能具有不同的含义.算法的第2步是对每一个主题执行k-means算法,得到主题聚类.为了实现第3步中的知识挖掘,采用了频繁模式挖掘[16],其目标是找到所有满足最小支持度计数的模式.一个模式就是一个词集合,所有模式组成了先验知识集合,简称先验知识基.
4.2 先验知识的表示方法
由于知识从每一个主题聚类中抽取,所以把经过频繁模式挖掘得到的先验知识基表示为聚类的集合.每一个聚类由一个频繁2-模式集组成.例如:聚类1:{电池,寿命},{电池,小时},{电池,长} 聚类2:{服务,支持},{支持,顾客},{服务,顾客}
实验中挖掘了频繁2-模式和频繁3-模式,在利用它们指导主题模型生成方面的连贯性评估中发现,频繁2-模式的性能优于频繁3-模式.与此同时,人工观察发现若属于相同主题的两个词出现在同一集合中,则更能体现词的语义关系.这也说明模式越长,包含错误的可能性越大.
5 先验知识的使用
TMPP使用阻塞式Gibbs进行推理[17].对文档中的每一个词wi,Gibbs能自动减少方面a和聚类c的关联.基于Gibbs的条件分布(式(6))能同时抽样方面am和包含了wi的聚类c.除了考虑am与词wi之间的匹配外,在计算该条件分布的过程中,还考虑了如下两个问题:
(1)聚类c的作用
聚类变量的作用:1)判定c是否是词wi的先验知识;2)控制词w和w′概率的增加.已知某一领域的评论语料,c是wi的先验知识意味着:包含wi的聚类c中的频繁2-模式也是实际领域评论语料的先验知识.如果c是wi的先验知识,则认为c中的先验知识有用,且能被提供给TMPP模型用于指导生成较高质量的am;否则,对于wi,c不是合适的先验知识,不能用于指导TMPP模型.基于共文档频率[18],度量了c中wi之间的共现,如式(3)所示.
(3)
其中,(w,w′)表示聚类c中的频繁2-模式.D(w,w′)表示同时包含词w和w′的评论数量,D(w)表示只包含词w的评论数量.公式(3)中分子与分母同时加1平滑是避免共文档频率为0的情况.
此外,给wi分配方面am和聚类c不仅增加了am和c与wi相关的概率,而且还可能使am和聚类c与w′有关联.本文利用Generalized Plya urn(GPU)模型表示语义相关的词[19].w′与c中的wi共享了一个频繁2-模式.概率增加量由公式(4)定义的矩阵Αc,w′,w来确定[20]:
(4)
观察公式(4)中的w,值1控制了w的概率的增加;值δ控制了w′的概率增加.
(2)c与am的一致性
c和am的一致性表示聚类c中所有频繁2-模式是否反映方面am.如果c和am一致,那么c中所有频繁2-模式中的词应该是方面am中的热点词.本文使用对称的KL-Divergence作为聚类c分布Distc和方面am的分布Dista之间的一致性度量.对于Distc,由于c中的词没有先验偏好,所以对c中的所有词都使用均匀分布.对于Dista,使用排名前15的词表示方面am.一致性计算如公式(5)所示.
(5)
Distc和Dista差别越小,c和am之间的一致性越高.
式(3),(4)和(5)一起形成阻塞式Gibbs,如式(6)所示,它能在确定先验知识有用性的同时对TMPP模型产生较好质量的方面提供指导.
P(am=a,cj=c|a-j,c-j,w,α,β,γ,Α)∝
(6)
其中,n-j表示除am和cj的当前分配以外的计数,例如:a-j和c-j.nm,a表示方面a被分配到评论m中的词的次数.na,c表示聚类c出现在方面a中的次数.na,c,v表示词v同时出现在方面a和聚类c中的次数.α,β,γ是预先定义好的超参数.
尽管以上阻塞式Gibbs能区分有用的知识和不合适的知识,但可能存在对于某一特定词,该词不在任何一个聚类中,即该词没有任何对应的先验知识.为解决这种问题,定义单一聚类概念,即为词w增加一个只有频繁1-模式的聚类{w,w}.由于单一聚类并不包含任何知识,仅仅只有词本身,所以式(3)和式(5)不成立.实验中就使用所有非单一聚类的共文档频率的平均值和一致性平均值作为单一聚类的式(3)和式(5)的计算值.
6 实验
与TMPP模型比较的两种基线方法分别是LDA[4]和 ILDA[4].这3个模型都使用“短语袋”模型表示评论,不同的是TMPP模型增加了领域先验知识.因此,比较的目的是观察主题模型使用先验知识是否能产生更高质量的方面.
6.1 实验设置
为获得先验知识,从淘宝上采集了30个领域的评论,如表1所示.每一个领域包含1000篇评论.使用中国科学院计算机所的中文分词与词性标注工具ICTCLAS对评论语料进行分词与词性标注,并利用哈工大中文停用词表过滤了评论中的无关词.由于获取先验知识的评论语料是在标准的LDA模型上运行,所以不需要将评论文本预处理为观点短语集.对于LDA模型,设置参数α=1,β=0.1,T=15,潜在变量θ和z的后验估计共执行了1000次迭代,得到的每一个主题(方面)只取概率排序在前15的词.在运用k-means聚类算法对得到的方面集进行划分时,设置的聚类数目为30,即评论领域的数量.利用频繁模式挖掘先验知识时,最小支持度设置为min(5,0.4×#T)[1],#T表示一个聚类中事务的数量.本文中的事务是指所有领域的主题数量.

表1 30个领域名称
为了比较基线方法与TMPP模型,实验只从30个评论语料中选取了笔记本,手机,数码相机,平板电脑和MP4这五种类型产品的评论语料作为测试语料集.由于3个模型都以“短语袋”表示评论,所以首先要对这五类产品进行预处理.预处理后得到的观点短语数量分别是:17540,7852,14320,4317,6591.对于这三个模型,潜在变量的后验估计执行2000次迭代.并且设置α=1,β=0.1,T=15,σ=0.2,对于每一个主题聚类,γ设置为这个聚类中词数量的比例.
6.2 引入先验知识后的方面识别分析
(1)主题连贯性评估
主题模型的评估常采用困惑度评价,但困惑度并不能反映语义连贯性.近年来,主题连贯性度量已成为一个实际的评估标准[18,21].主题连贯性的评估值越高,意味主题的可解释性越好.因而本文也采用主题连贯性度量来观察使用了先验知识的TMPP模型产生的方面在质量上是否优于两个基线方法.针对15个主题分别计算了主题连贯性之后的平均值,其中LDA模型在评论语料上的运行作为初始的迭代(即第0次迭代).
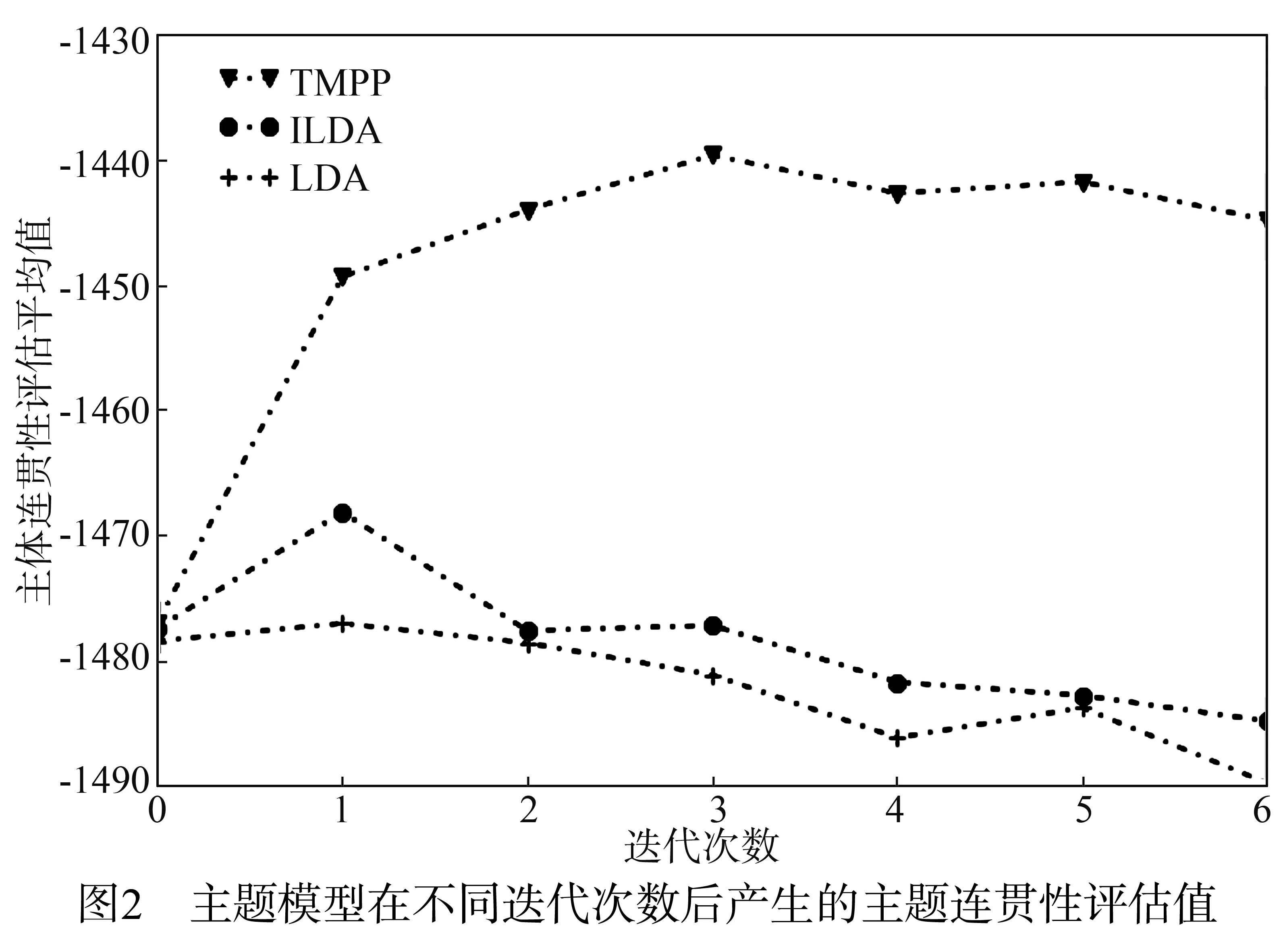
图2给出了三个模型的在五类数据上运行后得到的主题连贯性评估曲线.从图2能观察到:1)用领域先验知识指导的TMPP模型具有最高的主题连贯性.这表明TMPP找到了最具有解释性的方面;2)ILDA的主题连贯性优于LDA,这说明尽管ILDA没有使用先验知识,但由于对方面及相应的等级之间的依赖进行了建模,所以可能更有利于发现语义上连贯的主题.
(2)人工评估
人工评估阶段让两位研究生充当专家角色,对三个模型在五个领域上产生的主题是否具有连贯性进行了手工标注.如果专家一致认为大多数热点词是连贯的,且能表达现实世界,就将这个主题标记为连贯;否则,为不连贯.对于一个连贯的主题,如果热点词反映了主题所表示的方面,就将其标注为正确;否则,为不正确.
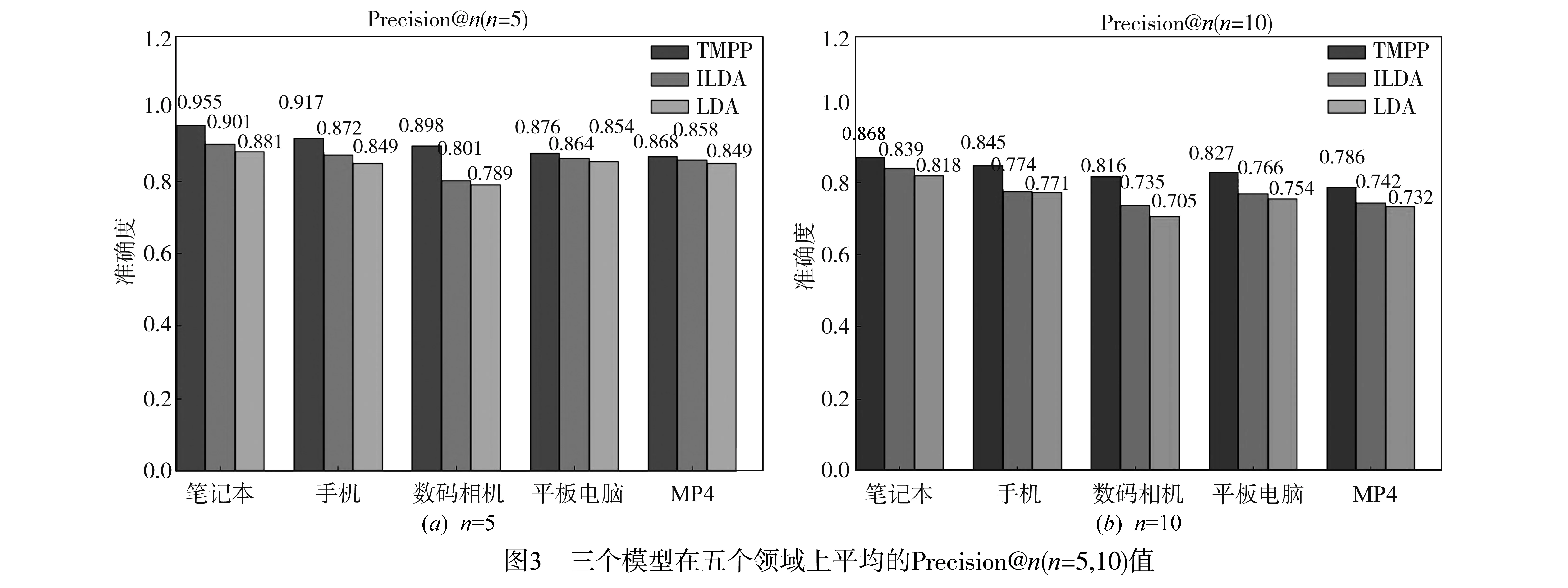
实验采用Precision@n度量人工评估结果.图3给出n=5和n=10的Precision@n值.从图3可观察到,相比于基线方法,TMPP在5个领域上都有改进.改进最大的是数码相机领域,最小的是MP4领域.这是因为先验知识中有较多的方面与数码相机领域的方面有重叠,而与MP4领域的方面重叠较少,即如果一个领域与许多其它领域共享了方面,那么利用先验知识就能较大程度地改进主题模型产生的主题质量;否则,改进较小.
表2以主题质量改进最大的数码相机领域和改进最小的MP4领域的评论语料为例,列出了由TMPP和2个基线模型产生的方面样例“电池”和该方面的前10个热点词.从表2可知,TMPP发现了更多正确的和有意义的热点方面词.表2中用粗黑体标注的词是方面样例“电池”中不符合语义的词.
表2 三个模型在数码相机领域和MP4领域产生的方面样例“电池”
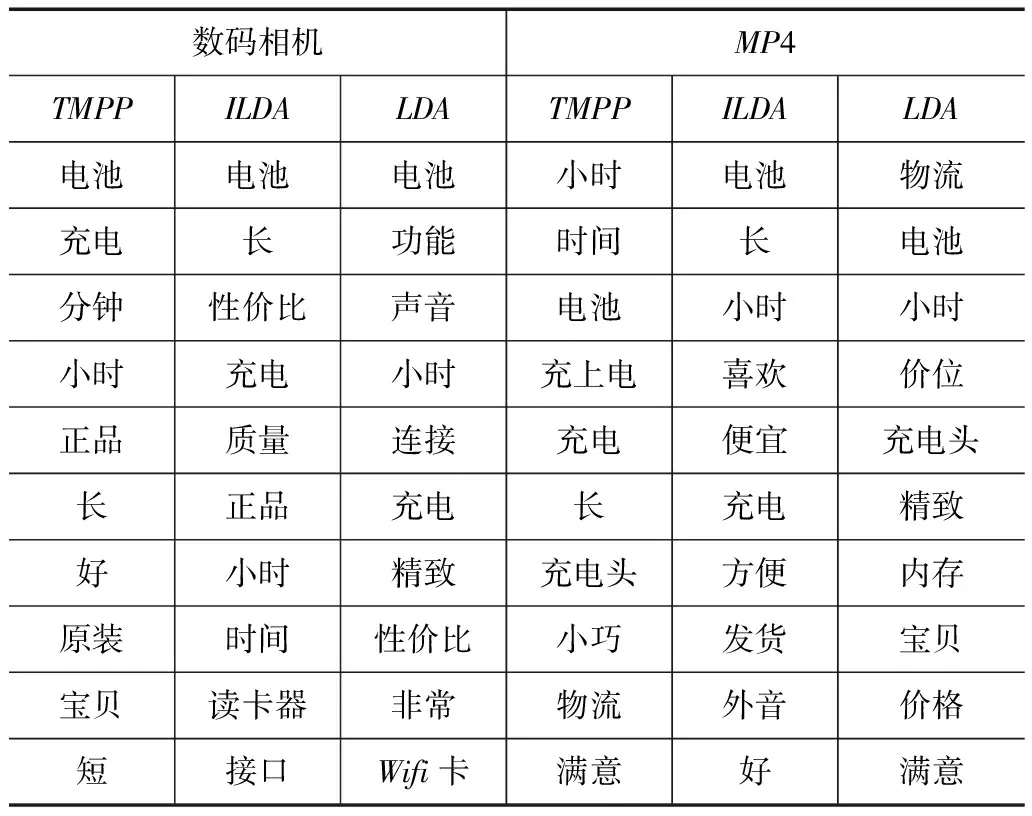
数码相机MP4TMPPILDALDATMPPILDALDA电池电池电池小时电池物流充电长功能时间长电池分钟性价比声音电池小时小时小时充电小时充上电喜欢价位正品质量连接充电便宜充电头长正品充电长充电精致好小时精致充电头方便内存原装时间性价比小巧发货宝贝宝贝读卡器非常物流外音价格短接口Wifi卡满意好满意
6.3 等级预测分析
(1)等级预测精度分析
采用公式(7)所示的聚类相似度衡量等级预测精度[4].对三个模型,k值固定为5,表示方面等级的聚类数量;Pi表示主题模型i产生的等级预测;Pm表示人工标注产生的等级预测.Pi与Pm的一致性要在k×(k-1)个等级预测对上进行检验.对每两个等级预测对,Pi和Pm可能把它分配到相同的聚类或不同的聚类.因此,公式(7)中的x表示在两个划分中,属于相同聚类的等级预测对数量;y表示在两个划分中,属于不同聚类的等级预测对数量.
(7)
TMPP模型具有将评论的总体等级分解为单个等级的功能,所以相同聚类的等级预测对数量x与不同聚类的等级预测对数量y均高;LDA模型的总体等级不能分解为单个等级,所以相同聚类的等级预测对数量x与不同聚类的等级预测对数量y均低;尽管ILDA模型也能将评论的总体等级分解为单个等级,但由于没有使用先验知识,只利用了方面与等级之间的依赖关系,所以相同聚类的等级预测对数量x与不同聚类的等级预测对数量y介于TMPP和LDA之间.对三个模型输出的每一个词聚类,人工标注Pm就是从词聚类中找出所有的形容词,根据褒贬形容词的个数确定方面的情感等级.褒义词越多,情感等级就越高.实验假定一个方面所在词聚类中有3个及以上褒义词就认为情感等级较高.针对以上五类产品,分别计算了三种不同模型的RandIndex值,并列于表3中.
从表3可知:TMPP的等级预测相似度值最高,这说明在语义更连贯的方面中,属于相同方面聚类的等级预测对数量较多.ILDA模型的等级预测相似度值比LDA高,原因是ILDA模型中方面和等级之间的潜在语义关联建模也有利于等级预测.此外,所有模型在数码相机这类产品数据集上等级预测精度最好,这是因为一方面先验知识中有较多的方面与数码相机的方面重叠,另一方面这类产品的训练数据集最大.
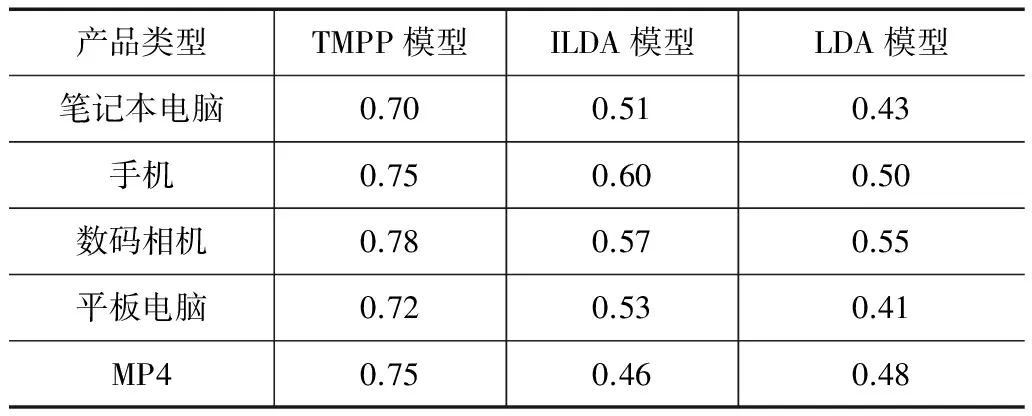
表3 等级预测的聚类相似度RandIndex值
(2)不同品牌数码相机的方面抽取和等级预测
表4和表5是不同品牌数码相机Canon/佳能PowerShot A23和Sony/索尼 DSC-W690的评级方面总结示例.TMPP模型能依据先验知识产生语义上更连贯的方面,根据这些方面把评论的总体等级分解为单个等级,以便用户能获得目标产品的不同视角.尽管两个不同品牌的数码相机有相同的总体等级3,但是Canon/佳能PowerShot A23有更好的“放大”,而Sony/索尼 DSC-W690有更好的“屏幕”和“声音”,为用户提供更详细的信息,相比于产品的总体等级,这种方式有助于用户做出购买决定.

表4 Canon/佳能PowerShot A23
表5 Sony/索尼 DSC-W690的方面和相应等级的方面和相应选级

抽取的方面对应等级镜头焦距2价格4相片质量4电池寿命3屏幕2总体等级3
(3)五类产品的相关方面及对应的正情感词
通过设置不同的主题数目和10次交叉验证,按概率从高到低列出了五类产品中排名前八位的相关方面和与该主题相关的概率最高的正情感词,如表6所示.从表6中相关方面所对应的正情感词分析得知,淘宝网的用户对所评价对象的某一个方面有较好的购买体验时,使用频率最高的正的情感词分别是“好”、“高”等最简单,最常用的形容词.这形成了淘宝在线产品评论的一个显著特点.该特点为在线评论中情感词的抽取研究提供了一定的事实依据[22].
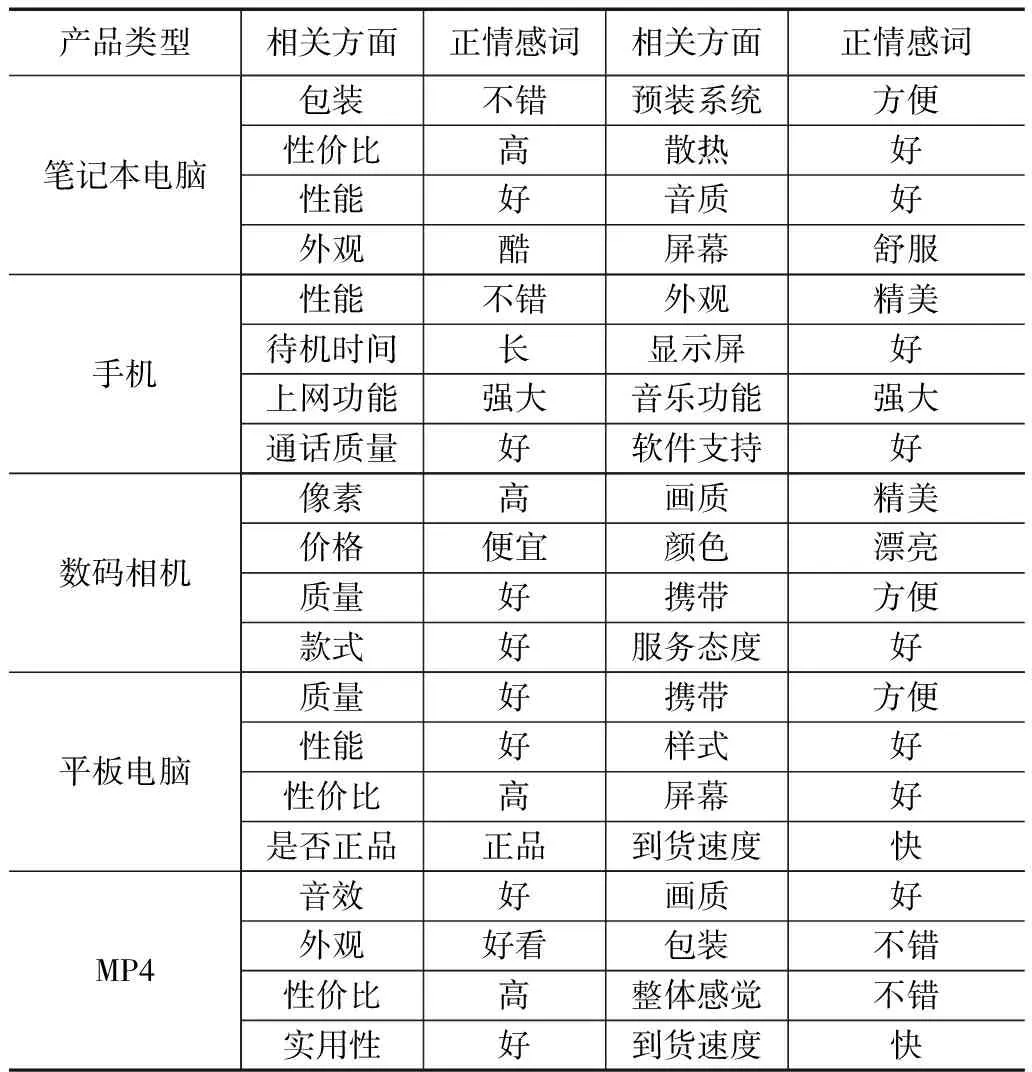
表6 产品的相关方面及对应的正情感词
7 结论
Web技术的发展使在线评论成为决策支持的有价值资源.本文提出基于短语参数学习的主题模型TMPP,它能同时抽取在线评论中被评价实体的aspect和其对应的rating.此外,TMPP还整合了一个潜在的聚类变量,用于指导产生更连贯的方面.聚类变量表示从大量已知领域中学习到的知识.这种知识是通过在已知评论语料上执行标准的LDA模型后,对其产生的主题进行分类,然后通过频繁模式挖掘得到的.在实际的评论语料上比较了提出的TMPP和基线模型,TMPP模型产生的方面质量高.通过等级预测的聚类相似度度量标准,发现TMPP模型方面的等级预测也优于基线模型.
[1]Zhiyuan Chen,Arjun Mukherjee,Bing Liu.Aspect Extraction with automated prior knowledge learning[A].In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics[C].Baltimore:ACL,2014.347-358.
[2]Hu Minqing,Bing Liu.Mining and summarizing customer reviews[A].Proceedings of the Tenth International Conference on Knowledge Discovery and Data Mining[C].Seattle:ACM,2004.168-177.
[3]吕品,钟珞,蔡敦波,吴云韬.基于CRF的中文评论有效性挖掘产品特征[J].计算机工程与科学,2014,36 (2):359-366. LÜ Pin,ZHONG Luo,CAI Dun-bo,WU Yun-tao.Effective mining product featuers from Chinese review based on CRF[J].Computer Engineering & Science,2014,36 (2):359-366.(in Chinese)
[4]Samaneh Moghaddam,Martin Ester.ILDA:Inerdependent LDA model for learning latent aspects and their ratings from online product reviews[A].Proceeding of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR 2011[C].Beijing,China:ACM,2011.665-674.
[5]Yue Lu,ChengXiang Zhai,Neel Sundaresan.Rated aspect summarization of short comments[A].Proceedings of the 18th International Conference on World Wide Web [C].Madrid:ACM,2009.131-140.
[6]Liu Bing,Minqing Hu,Junsheng Cheng.Opinion observer:Analyzing and comparing opinions on the web[A].Proceedings of the 14th International Conference on World Wide Web[C].Chiba:ACM,2005.342-351.
[7]Moghaddam Samaneh,Martin Ester.Opinion digger:an unsupervised opinion miner from unstructured product reviews[A].Proceedings of the 19th ACM Conference on Information and Knowledge Management[C].Toronto:ACM,2010.1825-1828.
[8]Ana-Maria Popescu,Oren Etzioni.Extracting product features and opinions from reviews[A].Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing[C].Vancouver:ACL,2005.339-346.
[9]Guo Honglei,Huijia Zhu,Zhili Guo,Xiaoxun Zhang,Zhong Su.Product feature categorization with multilevel latent semantic association[A].Proceedings of ACM International Conference on Information and Knowledge Management[C].HongKong:ACM,2009.1087-1096.
[10]Titov Ivan,Ryan McDonald.Modeling online reviews with multi-grain topic models[A].Proceedings of the 17th International Conference on World Wide Web[C].Beijing:ACM,2008.111-120.
[11]Hongning Wang,Yue Lu,Chengxiang Zhai.Latent aspect rating analysis on review text data:a rating regression approach[A].Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Washington:ACM,2010.783-792.
[12]Wong Tak-Lam,Wai Lam,Tik-Shun Wong.An unsupervised framework for extracting and normalizing product attributes from multiple web sites[A].Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval[C].Singapore:ACM,2008.35-42.
[13]Titov Ivan,R.McDonald.A joint model of text and aspect ratings for sentiment summarization[A].The 46th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies[C].Columbus:ACL,2008.308-316.
[14]Mei Qiaozhu,Xu Ling,Matthew Wondra,et al.Topic sentiment mixture:modeling facets and opinions in weblogs[A].Proceedings of the 16th International Conference on World Wide Web[C].Banff:ACM,2007.171-180.
[15]Blei David M ,Andrew Y Ng,Michael I Jordan.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003(3):993-1022.
[16]Jiawei Han,Hong Cheng,Dong Xin,Xifeng Yan.Frequent pattern mining:current status and future directions [J].Data Mining and Knowledge Discovery,2007,15(1):55-86.
[17]Michal Rosen-Zvi,Chaitanya Chemudugunta,Thomas Griffiths,Padhraic Smyth,Mark Steyvers.Learning author-topic models from text corpora[J].ACM Transactions on Information Systems,2010,28(1):1-38.
[18]David Mimno,Hanna M.Wallach,Edmund Talley,Miriam Leenders,Andrew McCallum.Optimizing semantic coherence in topic models[A].Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing [C].Edinburgh:ACL,2011.262-272.
[19]Hosam Mahmoud.Polya Urn Models.Chapman & Hall/CRC Texts in Statistical Science[M].USA:CRC Press,2008.
[20]Zhiyuan Chen,Arjun Mukherjee,Bing Liu,Meichun Hsu,Malu Castellanos,Riddhiman Ghosh.Exploiting domain knowledge in aspect extraction[A].Proceedings of EMNLP[C].Seattle:ACL,2013.1655-1667.
[21]Sanjeev Arora,Rong Ge,Yonatan Halpern,David Mimno,Ankur Moitra,David Sontag,Yichen Wu,Michael Zhu.A practical algorithm for topic modeling with provable guarantees[A].Proceedings of the 30th International Conference on Machine Learning[C].Atlanta:JMLR,2013.280-288.
[22]吕品,钟珞,唐琨皓.在线产品评论用户满意度综合评价研究[J].电子学报,2014,42(4):740-745. LÜ Pin,ZHONG Luo,TANG Kun-hao.Customer satisfaction degree evaluation of online product review[J].Acta Electronica Sinica,2014,42(4):740-745.(in Chinese)

吕 品 女,1973年3月出生,湖北鄂州人,现为上海电机学院副教授、博士,研究方向为数据挖掘、观点挖掘与情感分析.
E-mail:lvp@sdju.edu.cn

汪 鑫 男,1978年3月出生,安徽黟县人,现为上海电机学院讲师、硕士,研究方向为数据挖掘、云计算.
E-mail:wangx@sdju.edu.cn

罗宜元 男,1986年9月出生,河南信阳人,现为上海电机学院讲师、博士,研究方向为密码学与计算机安全.
E-mail:luoyy@ sdju.edu.cn

计春雷 男,1964年1月出生,上海人,现为上海电机学院教授、博士、硕士生导师,研究方向为大数据、数据挖掘.
E-mail:jicl@ sdju.edu.cn
(Aspect,Rating) Summarization Based on Topic Model
LÜ Pin,WANG Xing,LUO Yi-yuan,JI Chun-lei
(SchoolofElectronicandInformation,ShanghaiDianjiUniversity,Shanghai201306,China)
This paper proposes a topic model TMPP (Topic Model based on Phrase Parameter),which can extract the aspects and associated with their ratings for the evaluated entities in online reviews.TMPP has three characterisitcs:(1)It assumes the review is represented as a bag-of-phrase.(2)It extends the document-topic parameter from the standard LDA as a set of (aspect ,rating).(3)It incorporates the prior knowledge.We introduce the physical meaning of each parameter for the TMPP,the generative process for the TMPP and the representation of the prior knowledge.Furthermore,the reason and advantage of incorporating the aspect cluster into the TMPP are presented; the mechanism of obtaining the (aspect,rating) is also given by extracting the aspects and associated with their ratings from the online product reviews.We conduct extensive experiments on a very large real life dataset from taobao.com and find that TMPP can produce high quality (aspect,rating) summarization if each review has an overall rating by comparing the performance between existing baseline models and TMPP.
topic model; (aspect,rating) summarization; bag-of-phrase; topic model based on phrase parameter(TMPP)
2014-12-24;
2016-08-22;责任编辑: 郭游
国家自然科学基金青年基金(No.61402280);上海电机学院计算机科学与技术优势学科(No.16YSXK04);上海电机学院科研计划项目(No.B1-0227-16-032-031)
TN911
A
0372-2112 (2016)12-3036-08
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.12.032
