不相关匹配追踪的分段区分性特征变换方法
2017-01-10张连海李弼程
陈 斌,牛 铜,张连海,屈 丹,李弼程
(1.解放军信息工程大学信息系统工程学院,河南郑州 450001;2.西南电子电信技术研究所上海分所,上海 200434)
不相关匹配追踪的分段区分性特征变换方法
陈 斌1,2,牛 铜1,张连海1,屈 丹1,李弼程1
(1.解放军信息工程大学信息系统工程学院,河南郑州 450001;2.西南电子电信技术研究所上海分所,上海 200434)
为了提高基于分帧特征变换方法的稳定性,提出了一种基于分段的区分性特征变换方法.该方法将特征变换当成高维信号的稀疏逼近问题,采用状态绑定的方法训练得到基于域划分的线性变换矩阵(Region Dependent Linear Transform,RDLT)和基于最小音素错误准则均值补偿的特征(mean-offset feature Minimum Phone Error,m-fMPE)变换矩阵,将两者的特征变换矩阵构成过完备的字典;采用强制对齐的方式对语音信号进行分段,以似然度最大化作为目标函数,利用匹配追踪算法对目标函数迭代优化,自动地确定各语音信号段中的变换矩阵及其系数.为保证特征变换的稳定性,在选择变换矩阵过程中引入相关度测量,去除相关的特征基矢量.实验结果表明,相比于传统的RDLT方法,当声学模型分别采用最大似然和区分性准则训练时,识别性能分别可以提高1.63%和2.23%.该方法同时能应用于语音增强和模型区分性训练中.
特征变换;语音识别;区分性训练;语音增强;匹配追踪
1 引言
目前,主流语音识别系统中常对识别特征进行特征变换[1,2],以进一步得到具有鲁棒性和区分性的特征.其中,采用高斯混合模型(Gaussian Mixture Model,GMM)进行声学空间划分的特征变换方法应用较为广泛,如基于最小音素错误准则的特征变换(feature Minimum Phone Error,fMPE)[3]和基于域划分的线性特征变换(Region Dependent Linear Transform,RDLT)[4~6].在此基础上,陆续提出了结合高斯混元参数信息的均值补偿(mean-offset)m-fMPE[7]方法和状态绑定的(tied-state)RDLT[8]方法,并同时应用于深度神经网络(Deep Neural Network,DNN)[9,10]中,通过调整网络权值进行特征变换[11~13].
上述区分性特征变换方法中,训练阶段均是采用一段有限长信号求取变换矩阵,而在测试阶段却是对每一帧信号进行特征变换和补偿,这易造成训练和识别间不匹配.另外,由于语音信号具有短时平稳性,一帧信号往往较难得到稳定的参数信息.
为了有效地解决不匹配问题,得到稳定的解.在测试阶段,本文同样基于一段信号进行特征变换,即根据信号段的统计量信息,在训练得到的变换矩阵集合中,自动地选择特征变换矩阵.在这个过程中变换矩阵个数的选取是关键,当选择的变换矩阵较少时,将不能得到精确的变换参数;而当选择的矩阵过多时,会使得特征参数的稳健性不够.由于一次求解过程拥有的数据量有限,所选择的特征变换矩阵数相比于变换矩阵集合很小,是一个稀疏逼近问题.
本文将压缩感知理论引入到区分性特征变换中,在对语音信号分段的基础上,基于每一语音段求解其特征变换矩阵.先采用状态绑定的方式训练得到变换矩阵,结合RDLT特征变换矩阵和均值补偿fMPE偏移矢量构成过完备字典,在特征域进行特征变换相关参数的稀疏表示,利用匹配追踪算法自动地确定变换矩阵个数及其系数,得到最终的变换矩阵.为了保证变换矩阵的稳定性,在变换矩阵的选取过程中要求特征基矢量间不相关,并进一步讨论了不同分段方法对识别结果的影响.
2 基于语音分段的区分性特征变换
本文先采用状态绑定的方法得到RDLT变换矩阵和均值补偿fMPE偏移矢量,组成变换矩阵和偏移矢量集合,在此基础上结合压缩感知方法,采用最大似然准则进行特征变换矩阵和偏移矢量的选取.
2.1 基于状态绑定的特征变换矩阵
2.1.1 基于域划分的特征变换矩阵
RDLT[5]利用全局的GMM模型将声学空间分成多个域,每个高斯混元对应一个域划分,通过区分性训练得到一个变换矩阵集合,每个变换矩阵对应于声学空间中的一个域.用特征向量所属域对应的变换矩阵对其进行变换,特征所属的域由其在高斯混元的后验概率所决定,最终特征变换式(1)所示:
(1)
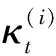
2.1.2 基于最小音素错误准则的特征变换
fMPE[3]方法将特征在高斯混元上的后验概率组成一个新特征,将这个特征映射为一个偏移矢量,加在原始特征上.fMPE方法中每个域对应一个偏移矢量,由于偏移矢量所含的信息量有限,常通过采用增大域的个数来保证其性能.而m-fMPE[7]通过加入所在域的高斯混元参数信息,进而提高了每一个域中的信息量,m-fMPE其变换式(2)所示:
Fm-fMPE(o(t))=o(t)+Mht
(2)
其中,ht由后验概率向量κt和均值补偿向量δt组成,需要求取变换矩阵M.
ht=[ηκt,δt]T
(3)
Fm-fMPE(o(t))
(4)
其中,Ma和Mb分别为m-fMPE均值补偿向量和后验概率向量所对应的变换矩阵,L是声学空间的域划分个数.基于状态绑定的RDLT和m-fMPE的求解过程相类似,只是求微分时针对的变量不同,以及确定迭代步长时有所差异,这里根据文献[8]分别进行求解.
2.2 基于分段区分性特征变换的一般形式
不同于传统方法中先验地设定所需变换矩阵的个数,再根据后验概率值的大小进行选择和加权.这里先对语音信号进行分段,对每一语音段根据其声学统计量信息,利用最大似然准则,采用一种可变变换矩阵个数的方式,得到区分性特征变换的一般表达式.
2.2.1 基于变换矩阵字典的特征变换
设经过域划分后总共有R个域,每一个域对应的变换矩阵为Ai,语音信号被分成S段,其中第s个语音段的特征变换可以描述为式(5):
(5)
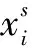
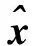
(6)
式中,T表示语音段s中含有的总帧数,声学模型采用隐马尔可夫模型,共含有M个高斯混元,μm和Σm分别为第m个混元的均值矢量及协方差矩阵,γm(t)表示第t帧特征矢量属于第m个高斯混元的后验概率,可采用Baum-Welch前后向算法计算得到.
令似然度函数
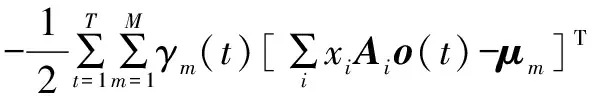
ξt=[A1o(t),A2o(t),…,ARo(t)] =[O1(t),O2(t),…,OR(t)],
(7)
由式(7)可知,基于分段的区分性特征变换是一个典型的二次优化问题,其求解方法为:对式(7)中的似然函数关于x求导,并令导数等于0,C是与变量x无关的常数项,可得式(8):
(8)
其中,
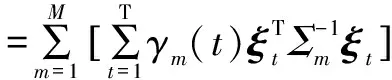
(9)
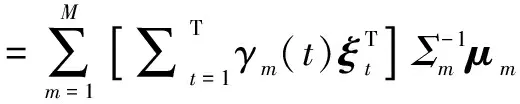
(10)
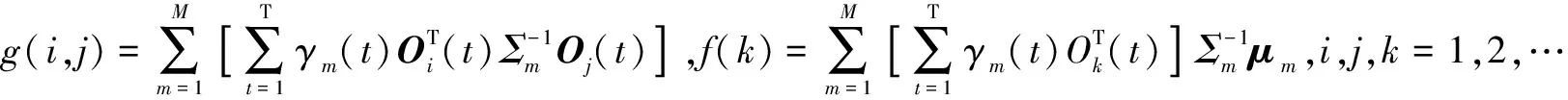
2.2.2 联合变换矩阵和偏移矢量字典的特征变换

(11)
可令ξc,t=[O1(t),O2(t),…,OR(t),b1,b2,…,bL],z=[x1,x2,…,xR,y1,y2,…,yL],则目标函数可以转换为式(12):
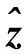
(12)
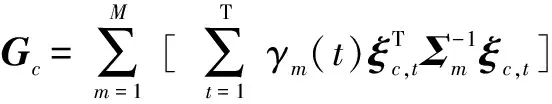
可得到解的类似表达形式(13):
(13)
由于本文构造的字典具有一定的冗余性,在对每一语音段进行特征变换时,相比于未知数所拥有的数据量很有限.在求解式(8)和(13)过程中,如何利用有限的数据从一个过完备的变换矩阵字典中,选取最佳的变换矩阵及其组合系数是本文的一个关键问题.压缩感知中的匹配追踪算法能较好地解决该问题,接下来将结合匹配追踪算法求解目标函数.由于式(8)和(13)求解过程相类似,下文中将主要介绍式(8)的求解过程,类似可以得到式(13)的解.
3 基于不相关匹配追踪算法的目标函数求解
借鉴正交匹配追踪(Orthogonal Matching Pursuit,OMP)[16,17]的算法思想,与最小化逼近误差作为目标函数不同,本文要使得似然度最大化,将似然度的变化率定义为误差,同时采用字典项间的相关性代替正交性,得到一种不相关的匹配追踪算法.这里字典项为变换矩阵Ai,其选取过程体现在特征o(t)经过矩阵Ai变换后的特征矢量Oi(t)上.同样采用迭代的方式求解目标函数,每次迭代包含三个步骤:第一步从大字典中选取一个使得似然度提升量最大的字典项加入到支撑集中;第二步判断所选的字典项是否与支撑集中的字典项相关;第三步更新支撑集中字典项所对应的系数.接着给出每一步骤的推导和求解过程.
3.1 最大似然字典项选取
支撑集选取过程为每次加入一个新字典项,所加入的字典项需使得似然度的增量值最大.第一次选取时只需满足似然度最大即可,此时xi=[g(i,i)]-1f(i),i=1,2,…,K,K为字典的大小.将xi代入目标函数Q(x)中,得到特征经过第i个变换矩阵后的似然度式(14):
(14)
根据Q1(xi)使之最大,确定第一个基矢量Or1(t)的序号r1为式(15):
(15)
接着,每次在已选的支撑集中加入一个变换矩阵字典项,根据其权重系数进行加权组合特征变换,使得变换后的特征能获得最大的似然度提升.假设第k次迭代后所得到的支撑集为Dk={O1(t),O2(t),…,Ok(t)},其对应的加权系数为xk,构成子空间Γk=span{O1(t),O2(t),…,Ok(t)}.在字典D剩下的变换矩阵中进行第k+1次迭代,选取字典项Ol(t)∈DDk,其对应的系数为xl,此时似然度目标函数为式(16):
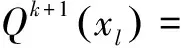
(16)
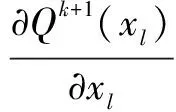
(17)
将[xk,xl]代入似然度目标函数中,可得第k+1次迭代后似然度的提升量ΔQk+1(xl):
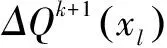
(18)
其中,Qk(xk)为第k次迭代后得到的似然度.为使得似然度提升量最大,则第k+1次所选择的字典项Or(k+1)(t)其相应的序号为式(19):
(19)
3.2 相关基矢量的去除
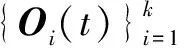
(20)
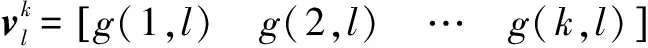
(21)
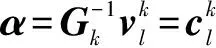
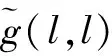
3.3 变换矩阵权重系数的更新

(22)
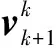
(23)

4 测试评估
4.1 实验设置
将本文分段区分性特征变换方法应用到连续语音识别中.实验语料采用中文微软语料库Speech Corpora(Version 1.0),其全部语料在安静办公室环境下录制,采样率为16kHz,16bit量化.训练集共有19688句,共454315个音节,总时长约为33小时,测试集共500句,约为0.7小时,说话内容来自新闻报纸,对中文音节全覆盖.文中选择声韵母作为模型基元,零声母(-a、-o、-e、-i、-u、-v),加上静音(sil)以及常规的声韵母,一共有69个模型基元,在此基础上将模型基元扩展为上下文相关的交叉词三音子(cross-word tri-phone).基于HTK 3.4.1建立基线系统,声学模型采用3状态的隐马尔科夫模型,通过决策树对三音子模型进行状态绑定,绑定后的模型有效状态数为2843个.利用SRILM工具根据语料库中自有的标注文件训练得到语言模型.文中均采用有调音节的识别准确率进行识别性能的评估.
4.2 基于帧特征变换方法的识别性能
这里采用13维的MFCC特征联合当前帧及其前后各4帧共9帧,并采用MLLT+LDA作为初始的变换矩阵,进行最大似然声学模型的建立.特征变换中全局GMM模型是由声学模型状态中的高斯聚类得到,最终共有800个高斯.在此基础上,分别得到了基于词图信息和基于状态绑定的fMPE、m-fMPE、RDLT特征变换方法的识别性能,并进一步讨论了当声学模型分别采用最大似然和区分性训练(Boosted Maximum Mutual Information,BMMI)时,各种特征变换方法的识别性能,具体识别结果表1所示.
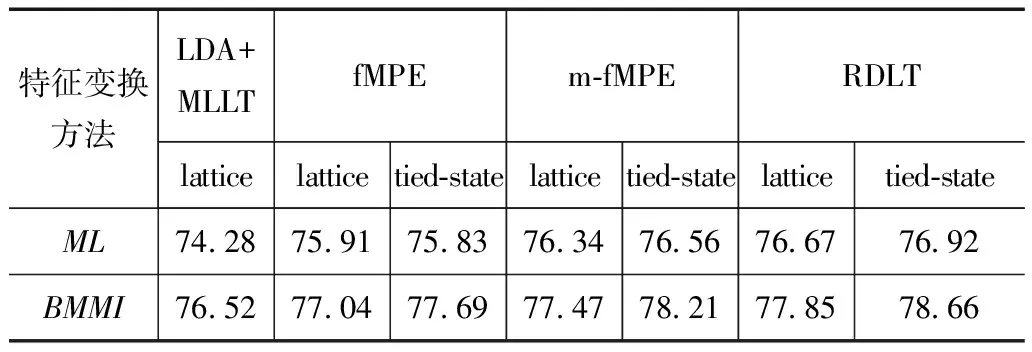
表1 不同特征变换方法的识别准确率(%)
由表1中的识别结果可知,区分性特征变换方法的识别性能均较为明显地优于线性判别分析方法.基于词图信息和状态绑定的fMPE方法得到的识别结果相当.为了保证fMPE的性能其所需的高斯混元数为12000个,所得到的特征变换矩阵为其他方法的15倍左右,这主要是因为其每一个域中所含有的参数和信息量较小,需要增大域的个数以保证信息量.由于它利用前后相关的后验概率信息进行特征变换,采用状态绑定的方式会在一定程度上影响这种前后相关性的获取.m-fMPE,RDLT采用状态绑定的方式得到识别结果会优于采用词图信息的方式.在特征变换的基础上,对声学模型区分性训练后识别性能得到进一步提升,且基于状态绑定的特征变换方法其优势更为明显.这说明采用状态绑定方法进行特征变换时,可以有效地克服声学模型对特征变换的影响,在求解优化过程中侧重于寻找区分性特征.
4.3 基于域划分变换矩阵字典项的识别性能
首先基于变换矩阵A构造字典,字典共有800个字典项,采用不相关匹配追踪算法进行特征变换.在这个过程中,语音信号的分段时长、匹配追踪算法中的似然度增量阈值δ直接决定着变换矩阵的选取,进而影响识别性能,因此分别讨论了上述参数在不同设置条件下的识别性能,所选字典数的上限N=200.通常语音分段以帧级单元为基础,通过某种分段方式来构造,常用的分段方式有两种:一是固定长度分段,即按照指定的长度进行分割;二是自适应长度分段,即对语音信号按照某种关联准则进行划分,例如,采用强制对齐的方式进行分段,这种分段考虑了语音特征空间内在的关联关系,是常用的分段对齐方法.这里将测试集强制对齐到前800个状态中进行分段,分段后语音分段时长均值为3.15s,方差为1.47,接着分别讨论了两种分段方式的识别性能.表2给出了不同分段时长、似然度增量阈值条件下,RDLT变换的连续语音识别率,其中加黑字体为除强制对齐外最好的识别结果,括号内为稀疏度,其度量方式为零系数占所有系数的比例.
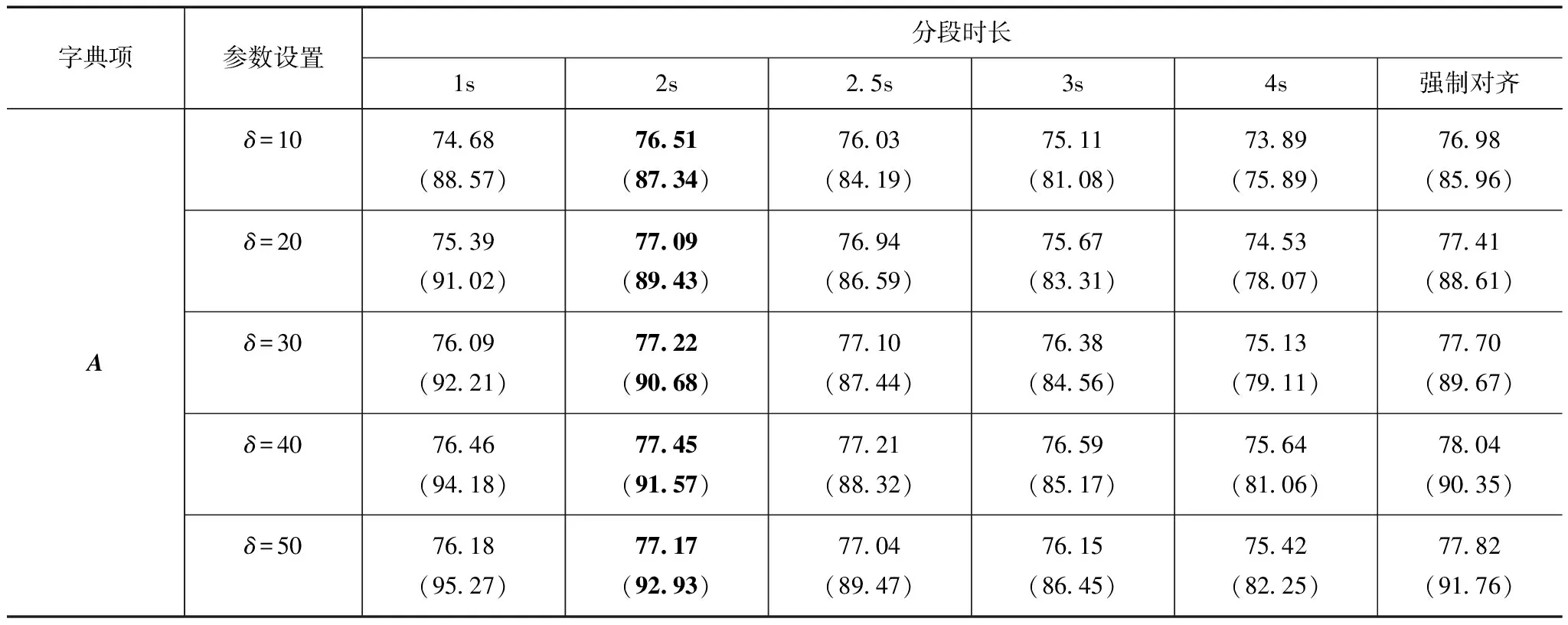
表2 不同分段时长、似然度增量阈值的识别准确率及其稀疏度(%)
由表2的识别结果可知,在相同的似然度增量阈值δ下,当数据分段较小时,稀疏度较大;随着数据量的增大,所选择的特征变换矩阵也会增多;在相同的数据分段长度下,δ值越大,稀疏度越大,所选择的变换矩阵越少,此时主要选择对识别性能影响较大的特征变换矩阵,这与前面的分析是相符的.稀疏度过大和过小都不能获得最佳的识别性能.同时由表中的识别结果可知,对语音采用不同的分段方式识别结果会有较大的差异.在对语音采用固定长度的分段方法中,将语音分成2s一段的方式能得到最优的识别结果,这主要是采用这一长度能得到相对稳定的统计特性,得到的参数信息较为准确.随着分段长度的增大,识别性能反而会开始下降,这主要是因为当数据分段过大时段内的声学性质会有较大的差异,即使是数据较为充分也难以获得较好的参数估计,来同时描述差异性较大的语音信号段,此时应该将语音信号段进一步细分,分别估计变换矩阵.采用强制对齐的分段方法能得到最高的识别性能,这主要是因为对齐到相同状态的数据具有相类似的声学特性,利用这些数据能估计得到稳健的参数信息.
采用匹配追踪算法还能根据所拥有的数据量大小,自适应地确定变换基矢量的数量,有效地避免常用方法中需要对基矢量个数进行经验设定.由于本文是一个凸优化问题,初值的设置对识别结果的影响不大.匹配追踪算法具有很高的运算效率,这很适合于前端的特征变换,不会给识别系统中引入太多的耗时,减小对后端识别解码的影响.由于识别算法是一个非线性过程,较难直接得到其理论的计算复杂度,通过分别定性地统计特征变换和整个识别算法的耗时,得知特征变换的耗时占整个识别算法耗时的1%以下,对整个识别算法的影响不大.
4.4 联合变换矩阵和偏移矢量字典项的识别性能
由表1的实验结果可知,m-fMPE和RDLT能得到相对较优的识别性能,m-fMPE侧重于偏移矢量的求解,而RDLT能得到更好的变换矩阵,两者具有一定的互补性.由于匹配追踪算法具有较高的运算效率,接下来将两者变换矩阵结合起来,构造一个过完备字典,字典共有1600个字典项,采用强制对齐的方式进行数据的分段,利用不相关匹配追踪算法进行变换矩阵的选取及其系数的确定,实验结果表3所示,其中A是RDLT方法得到的变换矩阵,M是m-fMPE方法得到的变换矩阵,b是对矩阵M进行分解后对应的偏移矢量,括号内为稀疏度.
表3 联合不同变换矩阵和偏移矢量字典项的识别准确率及其稀疏度(%)
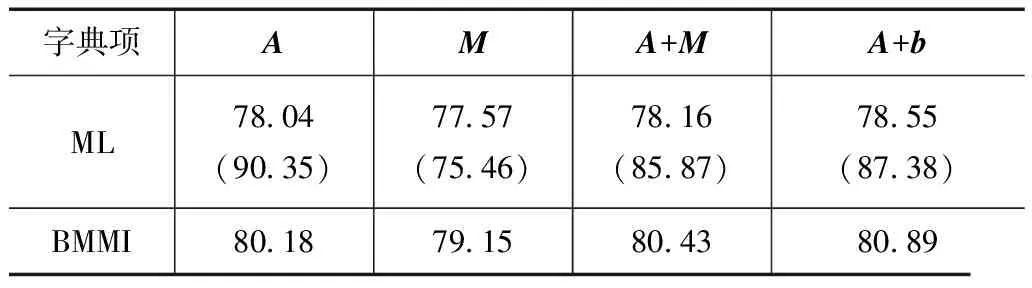
字典项AMA+MA+bML7804(9035)7757(7546)7816(8587)7855(8738)BMMI8018791580438089
由表3的识别结果可知,当只采用一组字典时,采用变换矩阵A能得到最好的性能,主要是由于变换矩阵A是矩阵M的一般化,其具有更强的描述能力,这同时说明在进行特征变换时,变换矩阵比偏移矢量能更好地保证性能.结合变换矩阵和偏移矢量构成过完备字典进行特征变换,其得到的性能会优于仅采用一组字典的方法,表明这两组字典具有一定的互补性,选择的变换矩阵和偏移矢量个数介于采用单组字典A和M之间.A+b的方法会好于A+M的方法,这主要是由于M矩阵中也含有变换矩阵,这与A中的变换矩阵会存在部分重复,而使得这部分变换矩阵的权值过大,造成过分重视,降低识别性能.仅利用其偏移矢量b结合A构造字典,能获得最高的识别性能.在特征变换的基础上,对声学模型区分性训练均能进一步提高识别性能.
5 结论
本文提出了一种基于语音分段的区分性特征变换方法,在特征变换求解过程中,引入了压缩感知中的稀疏逼近相关理论.通过采用状态绑定的方式,求解变换矩阵和偏移矢量构造过完备的字典.根据不相关匹配追踪算法,将特征变换的似然度作为目标函数,在目标函数的优化过程中选择最佳的特征变换矩阵及其组合系数.实验结果表明,相比于传统基于帧的特征变换方法,本文方法能够有效地提高识别性能,通过采用强制对齐的方式进行语音分段能得到最好的识别性能.在特征变换的基础上,进行声学模型的区分性训练能进一步提升识别性能.后续的研究可以将本文方法应用于其它特征变换方法中.
[1]Abbasian H,Nasersharif B,Akbari A,et al.Optimized linear discriminant analysis for extracting robust speech features[A].Proceedings of International Symposium Communication Control and Signal Processing[C].Julians,Malta:IEEE,2008.819-824.
[2]Nasersharif B,Akbari A.SNR-dependent compression of enhanced Mel sub-band energies for compensation of noise effects on MFCC features[J].Pattern Recognition Letters,2011,28 (11),1320-1326.
[3]Povey D,Kingsbury B,Mangu L,et al.fMPE:Discriminatively trained features for speech recognition[A].Proceedings of the International Conference on Audio,Speech and Signal Processing[C].Philadelphia,United States:IEEE,2005.961-964.
[4]Zhang B,Matsoukas S,Schwartz R.Discriminatively trained region dependent feature transforms for speech recognition[A].Proceedings of the International Conference on Audio,Speech and Signal Processing[C].Toulouse,France:IEEE,2006.313-316.
[5]Zhang B,Matsoukas S,Schwartz R.Recent progress on the discriminative region-dependent transform for speech feature extraction[A].Proceedings of the Annual Conference of International Speech Communication Association[C].Pittsburgh,United States:ISCA,2006.1495-1498.
[6]Takashi F,Osamu I,Masafumi N,et al.Regularized feature-space discriminative adaptation for robust ASR[A].Proceedings of the Annual Conference of International Speech Communication Association[C].Singapore:ISCA,2014.2185-2188.
[7]Povey D.Improvements to fMPE for discriminative training of features[A].Proceedings of the Annual Conference of International Speech Communication Association[C].Lisbon,Portugal:ISCA,2005.2977-2980.
[8]Yan Z J,Huo Q,Xu J,et al.Tied-state based discriminative training of context-expanded region-dependent feature transforms for LVCSR[A].Proceedings of the International Conference on Audio,Speech and Signal Processing[C].Vancouver,Canada:IEEE,2013.6940-6944.
[9]Deng L,Chen J S.Sequence classification using the high-level features extracted from deep neural networks[A].Proceedings of the International Conference on Audio,Speech and Signal Processing[C].Florence,Italy:IEEE,2014.6894-6898.
[10]Ling Z H,Kang S Y,Zen H,et al.Deep learning for acoustic modeling in parametric speech generation:a systematic review of existing techniques and future trends[J].IEEE Signal Processing Magazine,2015,32(3):35-52.
[11]George S,Brian K.Discriminative feature-space transforms using deep neural networks[A].Proceedings of the Annual Conference of International Speech Communication Association[C].Oregon,United States:ISCA,2012.
[12]Paulik M.Lattice-based training of bottleneck feature extraction neural networks[A].Proceedings of the Annual Conference of International Speech Communication Association[C].Lyon,France:ISCA,2013.89-93.
[13]Liu D Y,Wei S,Guo W,et al.Lattice based optimization of bottleneck feature extractor with linear transformation[A].Proceedings of the International Conference on Audio,Speech and Signal Processing[C].Florence,Italy:IEEE,2014.5617-5621.
[14]Kuhn R,Junqua J C,Nguyen P,et al.Rapid speaker adaptation in eigenvoice space[J].IEEE Transactions on Speech and Audio Processing,2000,8(6):695-707.
[15]Ghoshal A,Povey D,Agarwal M,et al.A novel estimation of feature-space MLLR for full-covariance models[A].Proceedings of International Conference on Acoustics,Speech and Signal Processing[C].Texas,USA:IEEE,2010.4310-4313.
[16]Mallat S G,Zhang Z.Matching pursuits with time-frequency dictionaries[J].IEEE Transactions on Signal Processing,1993,41(12):3397-3415.
[17]Tropp J A,Gilbert A C.Signal recovery from random measurement via orthogonal matching pursuit[J].IEEE Transactions on Information Theory,2007,53(12):4655-4666.
[18]Needell D,Vershynin R.Signal recovery from incomplete and inaccurate measurements via regularized orthogonal matching pursuit[J].IEEE Journal of Selected Topics Signal Processing,2009,4(2):310-316.

陈 斌 男,1987年生于江西萍乡.现为解放军信息工程大学信息系统工程学院博士研究生,西南电子电信技术研究所上海分所工程师.主要研究方向为连续语音识别、区分性训练和机器学习.
E-mail:chenbin873335@163.com

牛 铜 男,1982年生于河南郑州.现为解放军信息工程大学信息系统工程学院博士研究生.主要研究方向为语音识别和语音增强.
E-mail:niutong0072@gmail.com
A Discriminative Segmental Feature Transform Method Based on Uncorrelated Matching Pursuit
CHEN Bin1,2,NIU Tong1,ZHANG Lian-hai1,QU Dan1,LI Bi-cheng1
(1.InstituteofInformationSystemEngineering,InformationEngineeringUniversity,Zhengzhou,Henan450001,China; 2.ShanghaiBranchofSouthwestElectronicsandTelecommunicationTechnologyResearchInstitute,Shanghai200434,China)
A discriminative segmental feature transform method is proposed to promote the stability of the frame based method.The feature transform is considered as the sparse high dimensional approximation problem.Firstly,a set of feature transform matrices are estimated by tied-state based training of RDLT (Region Dependent Linear Transform) and m-fMPE (mean-offset feature Minimum Phone Error),and the transform matrices are integrated into an over-complete dictionary.Then,the speech signal is segmented through force alignment.Finally,following the matching pursuit to optimize the likelihood objective function iteratively,the transform matrices of each segment are selected from the dictionary and the corresponding coefficients are automatic determined in the optimization process.Further,to guarantee the stability of the transform matrices,a correlation measurement is introduced to remove the correlated basis in the recurrence process.The experimental results show that,compared with the traditional RDLT method,when the acoustic model is trained with maximum likelihood and discriminative training criterion separately,the recognition performance can be improved by 1.63% and 2.23% respectively.The method can also be applied to speech enhancement and model discriminative training.
feature transform;speech recognition;discriminative training;speech enhancement;matching pursuit
2015-05-17;
2015-11-24;责任编辑:覃怀银
国家自然科学基金(No.61175017,No.61403415);国家高技术研究发展计划(863计划)课题(No.2012AA011603)
TN912
A
0372-2112 (2016)12-2924-08
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.12.016
