基于AVX指令集BWT算法在DNA序列比对中应用
2016-12-27孙红敏杜博雅郑萍李东野曹延杰侯星辰
孙红敏,杜博雅,郑萍,李东野,曹延杰,侯星辰
(1.东北农业大学电气与信息学院,哈尔滨 150030;2.武汉理工大学计算机科学与技术学院,武汉 430070)
基于AVX指令集BWT算法在DNA序列比对中应用
孙红敏1,杜博雅1,郑萍1,李东野2,曹延杰1,侯星辰1
(1.东北农业大学电气与信息学院,哈尔滨 150030;2.武汉理工大学计算机科学与技术学院,武汉 430070)
新一代高通量测序技术发展产生大规模DNA序列片段,快速准确地将短序列比对到参考基因组成为生物信息学重要研究课题之一。针对BWT索引技术序列比对算法研究,提出基于Intel微架构AVX指令集优化BWT算法,通过改进计算方式实现算法并优化。结果表明,应用AVX指令集可减少CPU访存次数,降低算法时间复杂度,提高序列比对效率,为基因数据分析提供更高效快速序列比对方法,加快对全基因组序列处理。
序列比对;AVX指令集;BWT算法;并行优化
随着新一代测序平台(NGS)广泛使用,测序通量高、时间和成本下降使DNA序列数据显著增加,产生TB级测序片段。快速准确地将大规模DNA序列比对到参考基因组上成为生物信息学亟待解决难题[1]。将短序列与参考基因组序列比对并在参考基因组上定位,根据比对结果分析预测序列间相似性,可为后续开展表达量分析、预测SNP位点、选择性剪接分析、疾病相关性、药物研发、鉴定基因组中功能基因等研究奠定基础[2]。DNA序列比对现已成为生物信息学重要内容之一[3]。
在常用比对算法中,根据索引结构不同,采用空位种子片段索引算法Maq时间效率较低,序列中插入缺失(Indel)处理困难[4];BFAST序列比对算法速度慢[5]。基于哈希表比对算法PASS[6]和SOAP[7]查找速度快,但内存消耗大;而采用Burrows-Wheeler转换基于后缀、前缀索引算法Bowtie[8]、BWA[9]、BWASW等即使采用BWT技术,可解决内存消耗问题,但访存次数多、计算量大,在数据规模较大时查找时间长。因此如何减少时间消耗成为优化改进BWT方法研究核心。本文针对BWT索引技术耗时问题,优化多次递归调用函数部分,引入AVX指令技术方法解决运算时耗问题,提高BWT算法序列比对速率,实现大量基因数据快速处理。
1 BWT算法
BWT算法通过对字符串循环移位得到字符矩阵排序和变换,将基因组序列压缩并建立索引,通过查找和回溯定位字符串DNA序列比对。传统BWT构造和查找具体过程如下:假定参数T为字符串‘ATGGACT’,定义$字典序小于其他字符。在轮转矩阵(Burrows-Wheeler matrix)中,最后一列第i个出现字符x,与第一列中第i个出现x是同一个,这是BWT算法LF Mapping性质,通过最后一列BWT(T)还原字符串T。BWT循环排序过程如图1所示。
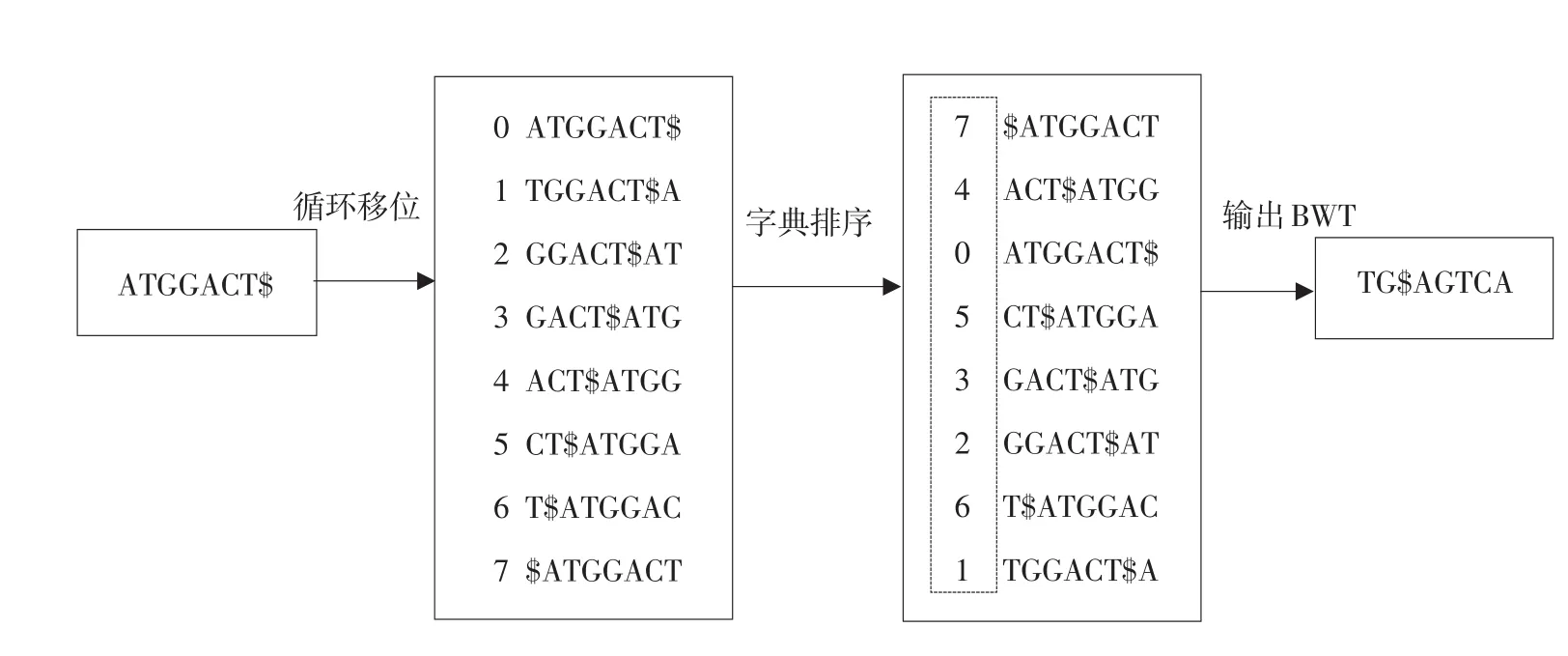
图1 BWT循环排序过程Fig.1Rotation sorting process of BWT
原串‘ATGGACT$’经循环排序得到最后一列BWT(T)=TG$AGTCA。生成后缀数组(Suffix Array)SA[r]={7,4,0,5,3,2,6,1}。BWT中定义两个参数C(c)和Occ(c,r),c代表碱基字符‘ATGC’,r代表矩阵行。C(c)表示字典序小于字符c所有字符个数,Occ(c,r)函数表示在BWT(T)中第r行之前出现字符c个数。Occ(r,c)固定不变,可将其保存在内存中供查找。LF(r)Matching算法过程:
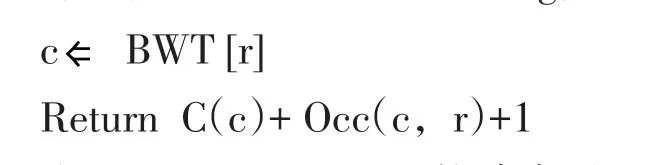
在LF mapping基础上构建索引,BWT字符串匹配。如图1所示第一列BWT(T)前添加数组SA[r]可以记录第r行在参考基因组中位置。利用BWT向后搜索(Backward)算法模拟前缀树自顶向下遍历实现字符串精确匹配。前缀树每条边表示一个字符,从树根结点到叶子节点构成参数T前缀。结点数字对应以此结点到根结点之间字符作后缀在右边排序后缀数组中范围,定义两个公式计算以参数T作为前缀后缀数组范围:

字符串匹配即为查找SA区间坐标位置,即求解后缀数组值。字符串‘ATGGACT’前缀树与反向文本‘TCAGGTA’后缀树相同,图2所示为反向文本T后缀树,其中符号^表示T起始位置。
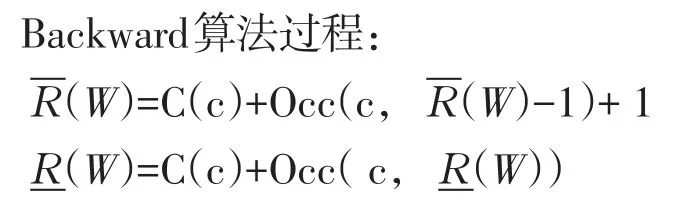
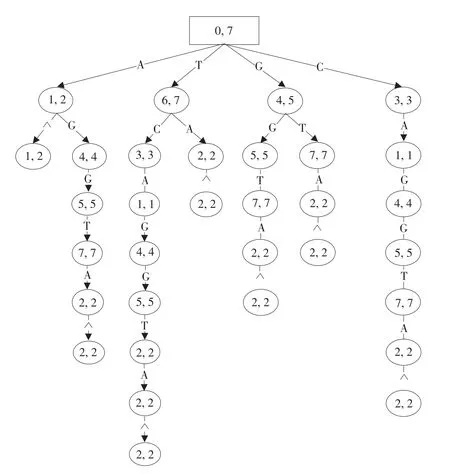
图2 字符串‘TCAGGTA’后缀树Fig.2Suffix tree of string‘TCAGGTA’
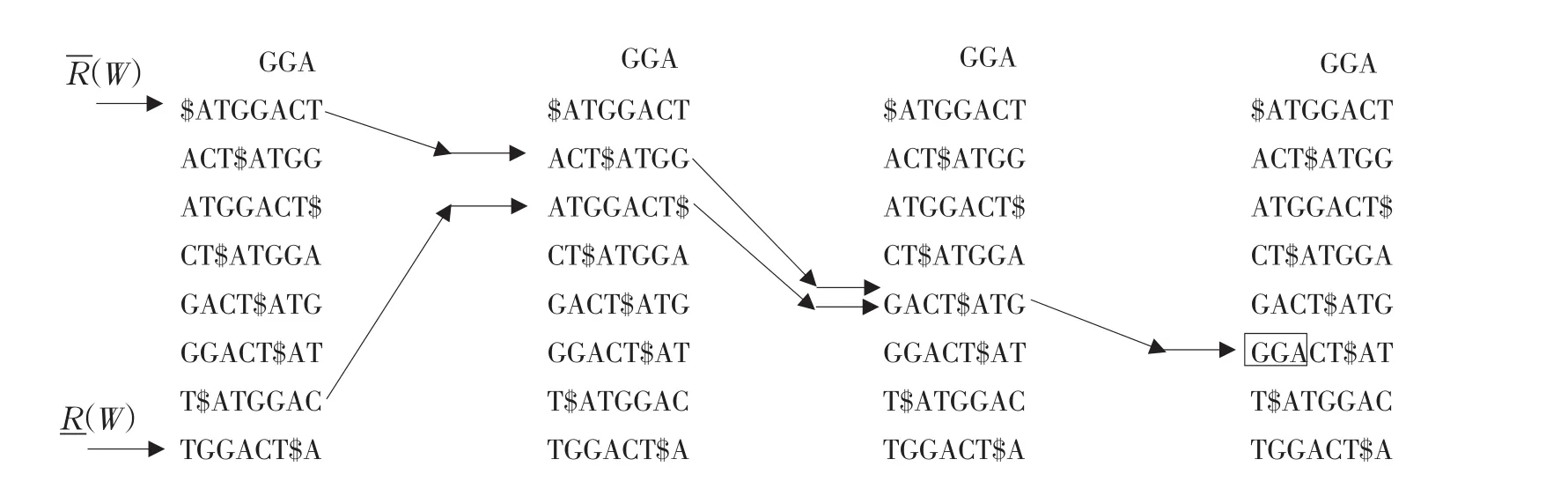
图3 [-R(W),-R(W)]字符串精确匹配步骤Fig.3[-R(W),-R(W)]String matching procedure
综上可知,LF(r)Matching算法和精确匹配Backward算法反复调用Occ(r,c),而Occ(r,c)函数计算密集、访问频繁、数据量大、计算过程时间长。应用AVX指令集改进该部分运算方式,对bwt_occ函数内部加法运算并改写,加快算法运算速度,提升算法效率。
2 AVX指令并优化BWT过程
全新指令扩展集AVX(Intel advanced vector extensions)是基于单指令多数据集(SIMD)技术思想设计实现[10],即一个CPU指令执行周期内同一指令下同时处理内存中多道数据,实现多数据处理,提高数据处理效率。AVX指令支持256位矢量运算,可以一次处理8个单精度浮点型数据,使浮点数运算速度提高近8倍。相比于传统指令,AVX指令节省访问时间,提高数据处理速度。
2.1 函数耗时统计
通过热点分析工具perf对程序分析,通过BWT算法中序列比对过程测试各函数耗时比例结果见图4。
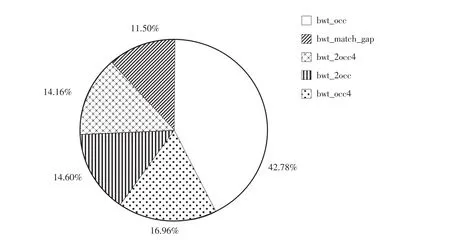
图4 Occ函数中各模块耗时情况Fig.4Time consuming of each module in Occ function
由图4可知,bwt_occ函数运算时间占比42.78%,耗时最多。为提高算法执行效率,采用结合AVX指令集求和计算思想,即每次计算8个数据,对bwt_occ函数运算部分优化。
2.2 AVX优化设计流程
256位AVX寄存器对应_m256数据类型,即256位单精度浮点型数据,该寄存器可一次并处理8个单精度浮点数或4个双精度浮点数。在实际编码过程中,occ每隔32行存储一次,将此Occ(c,r)值记为一个“checkpoint”,这样存储结构能减少内存开销。计算occ时需通过遍历BWT(T)字符串得到结果,直至得到BWT矩阵行数为32倍数时取出相应checkpoint值。在求解checkpoint过程中,需要判断并计算每次遍历位置值。将这些数值存储到数组avx_result中,当遍历到checkpoint后,使用AVX指令集计算数据,可充分发挥AVX指令集高速性,实现一个CPU指令执行周期内同一指令下同时处理多道数据。多数据处理,减少occ计算次数,减少程序运行时间。
AVX指令优化分四部分:①变量定义与初始化。②AVX批量处理。③合并,将__m256上多个数值合并到求和变量。④处理剩余数据,对剩余数据采用基本逐项相加。算法优化流程如图5所示。
代码优化具体实现如下:
①定义一个浮点型数组存放整型数据_occ_aux值,对这些值求和运算。
②使用AVX数据类型存放浮点型数组地址。AVX指令集在通过load指令加载数据时,需指针加减操作,通过Load指令加载pp指针,将指向存放_occ_aux值数组指针pp加载到yfsLoad中。AVX指令为_mm256_load_ps();表示对ymm寄存器中内容单精度浮点数加法运算。
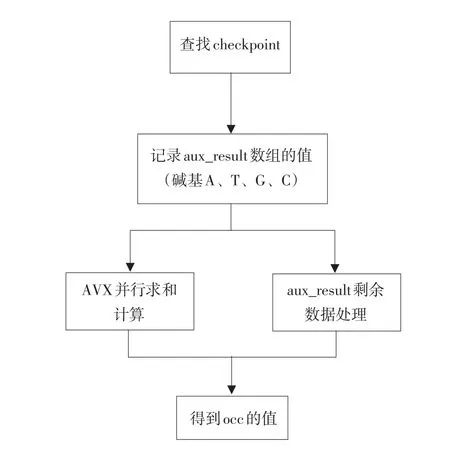
图5 AVX改进算法流程Fig.5Flowchart of improved algorithm by AVX
③通过add指令求和:使用AVX指令_mm256_ setzero_ps();将yfsSum数值置零。其中yfsLoad中存放occ值,yfsSum中存放yfsLoad中值和。AVX求和运算指令为_mm256_add_ps()。
④将每一步骤计算结果存放在浮点型变量中,通过强制类型转换将该浮点型变量值赋值回原始int型变量。
AVX过程共用到三个函数:
①_mm256_setzero_ps:将__m256中每一个单精度浮点数均赋值为零。伪代码:for(i=0;i<8;++ i)C[i]=0.0f;
②_mm256_load_ps:从内存中对齐加载8个单精度浮点数到__m256变量。伪代码:for(i=0;i<8;++i)C[i]=_A[i];
③_mm256_add_ps:相加指令,对2个__m256变量8个单精度浮点数垂直相加。伪代码:for(i=0;i<8;++i)C[i]=A[i]+B[i]。
将原有bwt_int数据类型转换为AVX数据类型_m256并行运算。加法运算通过AVX指令集load加载指令和add求和指令实现并行运算优化。计算bwt_occAVX指令集实现具体操作为:
yfsSum=_mm256_setzero_ps();
yfsLoad=_mm256_load_ps(pp);
yfsSum=_mm256_add_ps(yfsSum,yfsLoad);
AVX指令加法运算工作模式如图6所示。
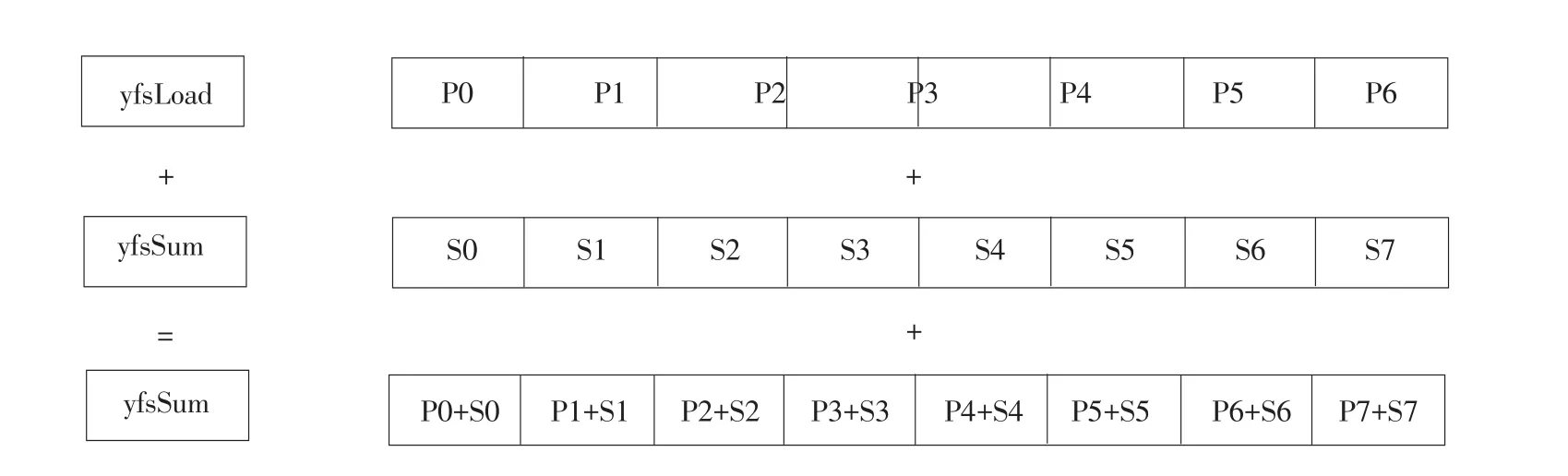
图6 单精度浮点型AVX加法工作模式Fig.6Single-precision floating-point addition AVX mode
通过整合上述参数,就可得到BWT算法计算occ值AVX编程,算法具体实现如下:
Begin
设置avx块宽,赋值broadwidth
计算块数,赋值cntBlock
计算剩余数量,赋值cntRem
计算所需内存空间,赋值aux_result
for p到end
把__occ_aux4(bwt,*p)保存到aux_result
end for
for i=0到cntBlock
使用avx指令计算
end for
将avx指令处理后数据合并
for i=0到cntRem
处理剩余数据
end for
应用AVX指令BWT算法,减少主循环次数和occ计算次数,提高occ函数运算速率,使数据处理速度显著提升。理论上能使算法复杂度降低至0(n/8),其中n为遍历次数。但在实际代码实现中,由于每次均需初始化AVX指令并保存遍历数据,因此实际算法时间复杂度降低至0(n/2)。改进后算法性能稳定,在使用不同数据规模测试时,不会使时间复杂度随数据规模变化而改变,时间复杂度稳定趋近于0(n/2)。
3 结果与分析
测试平台为:Intel(R)Core(TM)i7-3770 CPU@ 3.40GHZ,4核,内存8 G,Ubuntu13.04 OS。试验使用BWA(Burrows-Wheeler aligner)软件对BWT算法优化对比验证。使用BWA需要两种输入文件,参考基因组数据Reference genome data(fasta格式为. fa、.fasta、.fna)和短序列数据Short reads data(fastaq格式为fastaq、.fq)。
为确定方法有效性,采用真实数据集测试。试验中采用Illumina/Solexa测序平台大豆基因数据——ensemble数据库参考基因组序列文件ftp.ensemblgenomes.org,该物种测序序列为Glycine max.dna. genome.Fa.gz,短序列数据为NCBI数据库下载大豆高通量数据sra格式文件。通过sratoolkit工具转换为序列比对可识别单末端测序序列数据(Single-end)fastq文件。序列比对到基因组后通常采用SAM(SequenceAlignment/Map)格式存储。
试验中分别截取1 G fastq序列比对文件中长度为200 bp 200~1 000 M不同大小序列片段比对试验。BWT算法与基于AVX改进算法时间对比如表1所示。

表1 BWT算法与AVX-BWT算法时间对比Table 1Time comparison between BWT algorithm and AVX-BWT
在同一序列规模情况下,BWT与AVX代码运行时间与序列大小间关系如图7所示。
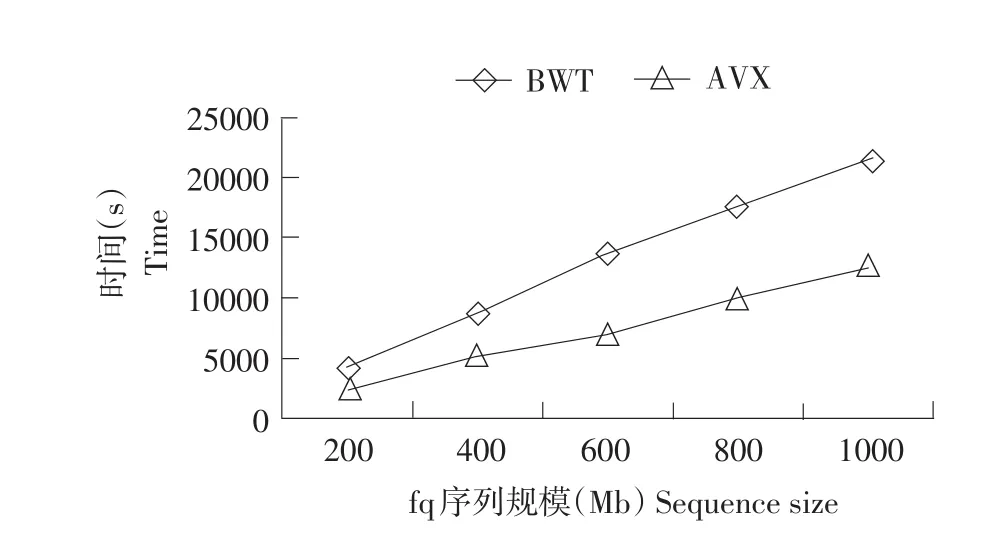
图7 BWT算法优化运算效率Fig.7BWT algorithm optimization algorithm efficiency
如图7所示,当fq序列大小为200 Mb时,BWT源码运行时间为4 246.14 s,AVX优化后运行时间缩减为2 533.39 s;当fq数据大小为1 000 Mb时,比对时间由21 331.92 s缩减至12 604.30 s。设BWT时间曲线斜率为k1,AVX时间曲线斜率为k2,两条曲线分别为y1=k1x+b1,y2=k2x+b2。BWT方法曲线函数为y1=4284.9x+264.42,AVX方法曲线函数为y2= 2520.2x-85.12。
如图7可知,随序列规模增加,两种方法运行时间均呈线性增加,逐渐趋近于0(n/2),该试验结果与给出时间复杂度理论分析结果接近,即两种方法时间复杂度与序列长度呈线性相关,AVX优化后时间复杂度趋近于0(n/2)。得出AVX指令优化后,耗时减少一半,序列比对时间明显减少。
4 讨论
对于BWT算法改进,采用AVX指令技术实现单线程内加速,而Intel采用Cilk工具对BWT算法存在负载失衡从多线程角度算法加速,但存在硬件条件限制,是否适于处理数据需深入研究。二阶BWT索引方法[11]与传统BWT方法中逐位索引查找不同,从算法结构角度优化,改进后BWT方法按双位索引查找,序列比对速度提高10%,而使用AVX指令从计算方式改进,优化提高40%~50%,速度提升优于二阶索引方法。
分别对C代码BWT源程序和AVX指令优化代码测试比较,验证优化后函数功能正确性。序列比对过程中AVX指令改写后程序将occ值输出时,同样需要将数值类型由整型转换为浮点型输出,否则无法将序列比对到SA后缀数组位置坐标输出为SAM格式。将输出文件与源码输出文件通过文本比对工具比较,2 000 000行数据存在约200行差异序列,即结果存在0.01%误差。
出现误差原因是AVX处理浮点型数据速度快,因此在优化过程中改写循环部分使用float型加法运算,而BWT源码中使用int64数据类型,整型与浮点型直接作加法操作会出现错误。因此在AVX加法操作结束后需将浮点型累加并转换为整型后与BWT中int64相加。float在计算机中二进制存储方式遵从IEEE规范,存储中分符号位(Sign)、指数位(Exponent)、尾数部分(Mantissa)。由于DNA序列中不存在负数情况,因此只需截取指数位和尾数位。将内存存储float二进制格式转化为整型,在数据类型转换时当数值超过float可存储32位时出现溢出现象,导致结果差异显著。对于大数据溢出现象而产生误差可采取分解存储解决方案,但移位和拆分操作耗费时间,使算法整体执行时间消耗未降低。考虑较大数据出现概率较小,故使用存在0.01%误差float数据类型AVX代码优化。
改写BWT中耗时比重较大、计算密集、访问频繁的bwt_occ函数AVX指令,在计算occ时将AVX指令应用在循环迭代中优化加法运算,减少函数计算次数,减少访问保存次数,使一个线程中一条指令并行做8次运算,提升算法执行效率。利用AVX指令集优化occ函数指令,可实现数据同步处理。在相同数据条件下,对比BWT源码,AVX优化后编码速率在原算法基础上平均提高2倍,AVX技术使BWT算法执行效率得到显著提升。
5 结论
本文在DNA序列比对算法BWT基础上,提出一种应用AVX指令技术改变数据运算方式方法。在相同数据结构下,应用AVX指令能够减少序列比对索引算法中函数内部循环次数和计算次数,使算法时间性能显著提升,提高序列比对过程查找效率。本文针对BWT算法中字符串查找部分指令优化,运算效率提升有限,后续研究可探讨构建索引运算部分优化及Occ函数其他模块AVX指令改写,进一步提高DNA序列比对速度。应用算法并行化将成为序列分析重要发展方向,AVX指令集可应用于数据压缩及数据分类等其他基因序列处理和研究领域,提高基因序列数据挖掘及全基因组序列处理效率。
[1]Kahn S D.On the future of genomic data[J].Science,2011,331 (6018):728-729.
[2]李丽文,朱延明,李杰.RNAi技术在植物功能基因组学中的研究进展[J].东北农业大学学报,2007,38(1):119-124.
[3]国宏哲,王亚东.基因组Mapping系统索引构建原理[J].智能计算机与应用,2012,47(4):3.
[4]Li H,Ruan J,Durbin R.Mapping short DNA sequencing reads and calling variants using mapping quality scores[J].Genome Res, 2008,18(11):1851-1858
[5]Homer N,Merriman B,Nelson S F.BFAST:an alignment tool for large scale genome resequencing[J].PLoS One,2009,4(11):7767. [6]Campagna D,Albiero A,Bilardi A,et al.PASS:a program to align short sequences[J].Bio-informatics,2009,25(7):967-968.
[7]Li R Q,Li Y R,Kristiansen K,et al.SOAP:Short Oligonucleotide Alignmen Program[J].Bio-informatics,2008,24(5):713-714.
[8]Langmead B,Trapnell C,Pop M,et al.Ultrafast and memoryefficient alignment of short DNA sequences to the human genome [J].Genome Biol,2009,10(3):1-10.
[9]Li H,Durbin R.Fast and accurate short read alignment with Burrows-Wheeler transform[J].Bio-informatics,2009,25(14):1754-1760.
[10]朱林,冯燕.基于单指令多数据技术的H.264编码优化[J].计算机应用,2005,25(12):2799-2802.
[11]赵雅男,徐云,程昊宇.序列比对算法中的BW变换索引技术研
BWT algorithm based on AVX instructions in the application of theDNA sequence alignment/
SUN Hongmin1,DU Boya1,ZHENG Ping1,LI Dongye2,CAO Yanjie1,HOU Xingchen1(1.School of Electrical and Information,Northeast Agricultural University, Harbin 150030,China;2.School of Computer Science and Technology,Wuhan University of Technology,Wuhan 430070,China)
The development of new generation of high throughput sequencing technology had produced large-scale DNA sequence fragments,how to quickly and accurately match to the reference genome had become one of the important research topics in bioinformatics.According to the sequence alignment algorithm of BWT index,new BWT algorithm based on Intel micro architecture was proposed to optimize the AVX instruction set,improved computation method to achieve parallel optimization algorithm.The results showed that the application of AVX instruction set CPU could reduce the number of memory accesses and reduced the time complexity of the algorithm,improved the efficiency of gene sequence alignment,data analysis to provide more efficient fast sequence alignment methods,to speed up the processing and analysis of the whole genome sequence.
sequence alignment;AVX instruction;BWT index;parallel optimization
TP399
A
1005-9369(2016)11-0093-07
时间2016-12-1 14:48:43[URL]http://www.cnki.net/kcms/detail/23.1391.S.20161201.1448.022.html
孙红敏,杜博雅,郑萍,等.基于AVX指令集BWT算法在DNA序列比对中应用[J].东北农业大学学报,2016,47(11):93-99.
Sun Hongmin,Du Boya,Zheng Ping,et al.BWT algorithm based on AVX instructions in the application of the DNA sequence alignment[J].Journal of Northeast Agricultural University,2016,47(11):93-99.(in Chinese with English abstract)
2016-08-14
国家“863计划”项目(2013AA10230304)
孙红敏(1971-),女,教授,硕士生导师,研究方向为生物信息技术。E-mail:sunhongmin111@126.com
