软件仓库挖掘领域:贡献者和研究热点
2016-12-22张静宣韩雪娇徐秀娟
江 贺 陈 信 张静宣 韩雪娇 徐秀娟
(大连理工大学软件学院 辽宁大连 116024)(jianghe@dlut.edu.cn)
软件仓库挖掘领域:贡献者和研究热点
江 贺 陈 信 张静宣 韩雪娇 徐秀娟
(大连理工大学软件学院 辽宁大连 116024)(jianghe@dlut.edu.cn)
随着时间的推移,软件不断地更新和演化,软件仓库中累积了海量的数据,如何有效地收集、组织、利用软件工程中涌现的软件大数据是一个至关重要的问题.软件仓库挖掘(mining software repositories, MSR)通过挖掘软件仓库中繁杂多变的数据中蕴含的知识来提高软件的质量和生产效率.虽然一些研究工作详细阐述了MSR的背景、历史和前景,但现有的研究工作并未系统地呈现MSR领域中最有影响力的作者、机构、国家以及最受欢迎的研究主题和主题变迁等领域知识.因此,结合已有的经典的文献分析框架和算法来分析MSR相关文献,并呈现一些MSR基本领域知识.为了实现MSR 文献分析,建立了一个包含3个组件的MSR文献分析框架(MSR publication analysis framework, MSR-PAF),这3个组件分别被用来创建数据集、执行基础文献分析、实施合作模式分析.基础文献分析结果表明:最高产的作者、机构、国家地区分别是Ahmed E. Hassan,University of Victoria和美国,最有影响力作者是Ahmed E. Hassan,最频繁的关键词是software maintenance.合作模式分析的结果显示Abram Hindle是MSR领域最活跃的作者,open source project和software maintenance是最流行的研究主题.
文献分析;合作模式分析;数据挖掘;软件仓库挖掘;大数据
在互联网的推动下,软件工程正经历重大变革,软件的规模和复杂性急剧增加.为了方便软件管理,一些工具如版本控制系统、缺陷追踪系统等已被广泛应用到软件开发活动中,记录软件的每一次测试活动、每一次代码变更、每一次缺陷修复等[1].随着时间的推移,软件仓库中积累了海量的、不同类型的数据,包括开发过程中的源代码、需求文档;软件测试时的测试实例、bug报告;系统运行时的日志文件、事件记录等[2].这些数据呈现出体量(volume)、增速(velocity)、多样(variety)、价值(value)、真伪(veracity)、可验性(verification)、可变性(variabi-lity)以及临近性(vicinity)等多“V”特点[3],对软件工程提出了重大挑战.因此,如何有效地收集、组织、利用这些大数据来帮助改善软件的质量和生产效率已成为大数据背景下软件工程中一个至关重要的问题.
软件仓库挖掘(mining software repositories, MSR)是一个新兴的软件工程领域,通过数据挖掘技术分析软件仓库中海量的数据,来提高软件的质量和生产效率[4-6].我们引入一个典型的软件仓库挖掘任务——开发者优先级识别,来详细呈现软件仓库挖掘过程.开发者优先级识别是指根据开发者的贡献大小,确定开发者的优先级序列[7],辅助软件开发工作.Xuan等人[7]首先以Eclipse和Mozilla 的bug仓库为数据源,收集2011年之前的所有报告.然后,预处理每个bug报告,抽取报告中的标识、提交者、修复者、摘要、描述、创建时间以及评论信息,生成2个实验数据集.之后,在能够识别开发者优先级的领导力网络[8]的基础上进行改进,为所有开发者增加一个虚拟的开发者,并建立原始开发者和虚拟开发者间双向链接,提出一种新的领导力网络,能够识别基于组件和基于产品的开发者优先级.最后,将改进的网络应用于收集到的数据集,并调研4个研究问题来验证开发者优先级的有效性.
综上,软件仓库挖掘一般流程为:收集数据、预处理数据 (特征提取)、寻找改进设计合适的数据挖掘算法、运用数据挖掘算法解决软件工程问题[6,9-10],如图1所示,其中软件工程数据(software engineering data)在软件仓库挖掘中起着关键作用.软件工程数据种类繁多,可以分为序列(如执行路径)、图(如程序依赖图)、文本(如bug报告、e-mail)[5].这些数据常常涉及3个因素,即人(people)、过程(processes)和产品(products),可以称为“3P”因素[5].人包括软件开发者、测试者、工程管理者和终端用户;过程包含软件活动的各个阶段,如软件测试、软件维护等;产品包括结构化产品(如代码)和非结构化产品(如文档).为了促进软件仓库挖掘领域的发展,2004年第1届国际软件仓库挖掘研讨会(international workshop on mining software repositories, WMSR)在苏格兰首府爱丁堡举行,之后软件仓库挖掘在学术界和工业界受到了广泛的重视和研究.
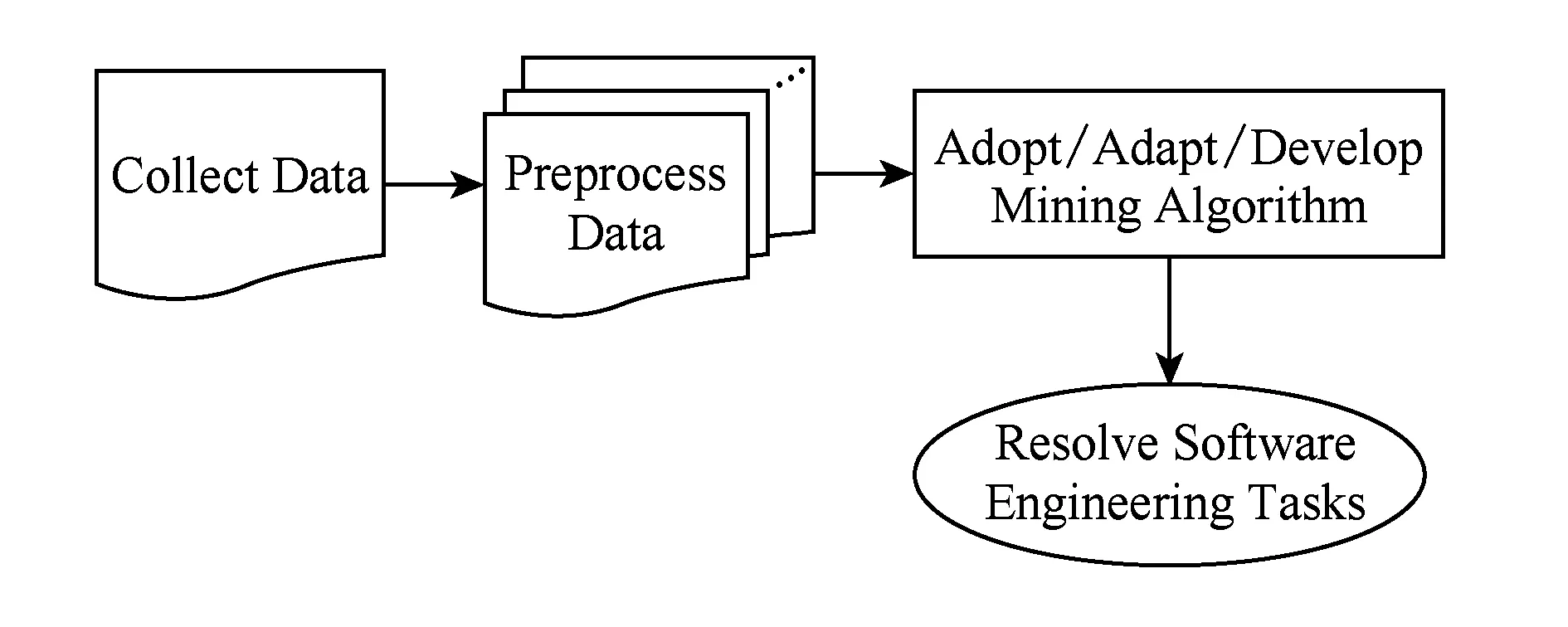
Fig. 1 The procedure of mining software repositories.图1 软件仓库挖掘流程
虽然MSR吸引了大量研究者,但现有的研究工作并未为这些研究者系统地呈现该领域的最有影响力的作者、研究机构、国家地区,以及最热门的研究主题和主题变迁等领域知识.一些综述性的研究只是概括性地总结了MSR的背景、历史和值得研究的问题[9-10],并没有量化的方法来揭示MSR丰富的领域知识.随着专业知识的提高,研究者更希望对MSR领域进行深入挖掘,了解MSR论文作者间的合作关系,掌握MSR领域的研究主题动态变化趋势,从而合理地推断出未来的发展方向.WMSR作为MSR领域内一个重要的国际会议,在MSR领域有着很大的影响力,其收录的MSR相关论文无论是数量还是质量都具有很强的代表意义,研究WMSR上的文献信息能够帮助我们了解一些有价值的MSR领域知识.因此,本文主要工作是分析WMSR中文献信息,识别最高产的作者、机构、国家地区、最频繁的关键词、最有影响力的作者和论文,并分析作者间的合作关系、热点研究主题以及作者的研究兴趣,帮助研究者深入了解MSR领域知识.在后续章节中出现的MSR文献分析特指WMSR文献分析,从而得出的结论主要适应于WMSR上收录的论文.
在本文中,我们采用文献分析技术[11-15].最初的文献分析研究通常借助数理统计方法来揭示某一领域的基本信息,包括论文、作者、机构、国家组织[11-12].后来随着研究的深入,人们不再拘泥于简单的数据统计,而是采用数据挖掘等方法来分析文献内部蕴含的知识和关系,如特定主题论文分布情况、研究主题逐年变化趋势,以及作者之间的合作关系等,这些研究内容可以归结为基础文献分析(biblio-graphy analysis)和合作模式分析(collaboration pattern analysis).长期的研究也形成了一套行之有效的文献分析框架和技术[14-16],其主要步骤为:确定数据源、收集数据、预处理数据、执行相关文献分析.各种算法和度量标准也被应用到文献分析领域,如GN(Girvan-Newman)社区聚类算法[16]、文本处理技术、数据挖掘技术以及APS(adjusted productivity score)指数[17]、ACS(adjusted citation score)指数[18]、NCII (normalized citation impact index)指数[19].调研显示,现有的框架和技术能被广泛地应用到不同领域的文献分析研究中.
为了实现MSR文献分析,我们构建了一个MSR文献分析框架(MSR publication analysis framework, MSR-PAF),该框架包含3个组件:1)数据收集组件,用来建立文献分析所需的数据集.我们首先从WMSR上收集已发表的论文标题,然后利用网络爬虫工具从DBLP, IEEE Xplore, ACM上爬取作者全名、机构、国家地区、关键词、摘要等信息,最后从Google Scholar中抽取论文的引用次数.2)基础文献分析组件,通过实施产量分析和影响力分析,识别出最高产的作者、机构、国家地区以及最频繁的关键词,同时找到最有影响力的作者和论文.3)合作模式分析组件,通过构建3个关系网络,即作者合著网络(co-authorship network)、关键词共现网络(co-occurrence keyword network)和作者-关键词共现网络(author co-keyword network),分别分析作者之间的合作关系、主要的研究主题以及作者的研究兴趣,并使用NetDraw[20]工具可视化这3个关系网络.基础文献分析结果显示最高产的作者、机构、国家地区分别是Ahmed E. Hassan, University of Victoria和美国,最频繁的关键词是“software maintenance”,最有影响力的作者和论文是Ahmed E. Hassan和“When do changes induce fixes?”.另外,合作模式分析结果显示Abram Hindle是MSR领域最活跃的作者,open source project和software maintenance是最流行的研究主题.
本文的贡献有3点:
1) 为了实施MSR文献分析,我们构建了一个MSR 文献分析框架,即MSR-PAF,该框架包含3个组件,我们创建了一个完整的数据集用于MSR文献分析;
2) 在执行基础文献分析时,我们使用数理统计方法实施产量分析,同时引入H因子和NCII指数实施影响力分析;
3) 在执行合作模式分析时,我们生成3个关系网络,包含作者合著网络、关键词共现网络和作者-关键词共现网络,分析作者之间的合作关系、主要的研究主题以及作者的研究兴趣.
1 相关研究工作
本节详细讨论相关研究工作,主要包括2个领域:软件仓库挖掘和文献分析.
1.1 软件仓库挖掘
MSR研究覆盖软件开发的各个阶段,包括需求、设计、实施、测试、调试、维护和部署,其涉及到的软件工程数据可以划分为3类[5]:
1) 序列.这类数据通常是软件在执行过程中动态生成的结构化信息,包含执行路径、co-change等信息.比如,crash报告系统能够自动地生成crash报告,这些报告通常包含系统执行过程中的调用栈信息.许多研究通过抽取调用栈信息来计算crash报告的相似度并自动地实现crash报告分桶(crash report bucketing)[21-22],还有一些研究通过挖掘调用栈信息来帮助开发者识别crash根源[23].
2) 图.这类数据往往能够直观形象地呈现软件工件间的关系,包括动态静态调用图、程序依赖图等.例如程序依赖图是一种带标签的有向图、模拟程序或过程语句之间的依赖关系.通过挖掘程序依赖图,可以提取程序内在关系,从而发掘隐藏的信息[24-25].
3) 文本.这类数据通常是人工撰写的非结构化信息,包括bug报告、e-mail、文档等.例如,测试者通过执行软件测试为软件的异常行为撰写bug报告,这些报告往往包含较多的自然语言信息,然而,人工检测大量的bug报告是一项十分繁重的任务.因此,为了减少人工检测代价,研究者提出了一种典型的文本挖掘任务,即bug报告重复检测(duplicate bug report detection)[26-29].许多研究利用常见的文本挖掘方法,如自然语言处理技术(natural language processing, NLP)[26]、信息检索技术(information retrieval, IR)[27]、主题模型(topic modeling)[28]或机器学习(machine learning)[29]抽取特征或者建立向量空间模型来计算文本相似度,从而实现重复检测.
实际上,MSR文献分析研究也可以看作一种特殊的软件仓库挖掘任务,其使用的数据集是基于文本的.通过挖掘数据集中包含的信息来识别高产作者、机构、国家地区,并发现最频繁的关键词、最有影响力的作者和论文,同时,分析MSR领域作者间的合作关系、主要的研究主题以及作者的研究兴趣.
1.2 文献分析
文献分析(publication analysis)主要是采用数理统计和数据挖掘等方法对某个特定领域的文献进行深入地挖掘,使该领域的研究者能够系统地了解这个领域的研究背景、历史和现状,明确该领域内最流行的研究主题和方向[14].传统的文献分析通常简单地统计文献的基本信息,如论文标题、作者、机构、国家地区、关键词等.大量的文献分析研究聚集在智能交通领域,Wang[11]简单统计了2000年至2009年发表在T-ITS (IEEE Transaction on Intelligent Transportation System)期刊上的文献.Li等人[12]收集了T-ITS上10年的文献,并通过产量分析识别出该领域最高产的作者、机构、国家和地区.近年来,随着研究的深入,文献分析的内容不断扩充,延伸到影响力分析、社会网络分析、聚类分析、文章话题分析等各个方面,因此一些典型的数据挖掘方法也被引入到文献分析研究中.Tang等人[30]收集了T-ITS上2010年至2013年出版的所有文献,并对该领域的研究主题分类,识别出5个热点研究主题.Xu等人[16]收集了该期刊上所有的论文,并执行了全面的基础文献分析和合作模式分析,他们引入了GN聚类算法和3个关系网络对作者合作模式以及主题变迁进行深入分析.在推荐系统领域,Park等人[14]利用一些重要的关键词搜索几个主要数据库,从31个期刊中精心挑选出164篇论文,划分为8类,并使用数据挖掘技术检测这些论文,识别出推荐系统领域内流行的研究主题.在云计算领域,Heilig等人[13]从Elsevier数据库中收集了总计15 376篇论文,这些论文发表于2008年至2013年,他们主要执行了产量分析、影响力分析以及研究主题分析.
与上述任务类似,我们的工作是分析MSR文献信息,挖掘MSR领域知识.我们收集WMSR上文献并执行文献分析,主要分为基础文献分析和合作模式分析.
2 MSR文献分析框架
本节详细阐述MSR文献分析框架,由3个组件组成,如图2所示,包括一个数据收集组件、一个基础文献分析组件和一个合作模式分析组件.数据收集组件用来创建我们研究所需要的数据集;基础文献分析组件针对论文中的单一类别的信息执行统计分析,从而识别最高产的作者、机构、国家地区和最频繁的关键词,并分析作者和论文的影响力,主要包括产量分析和影响力分析;合作模式分析组件针对多种信息的关联关系来挖掘隐藏的知识,通过构造3个关系网络来研究作者间的合作关系、主要的研究主题以及作者的研究兴趣.
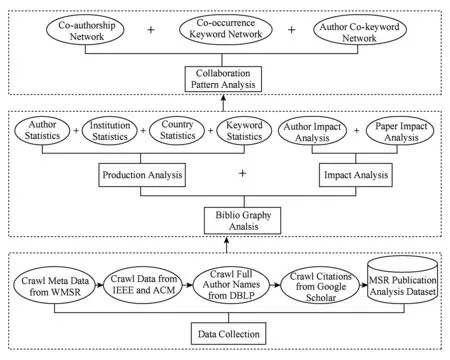
Fig. 2 The MSR publication analysis framework.图2 MSR文献分析框架
2.1 数据收集
为了实现MSR 文献分析,我们需要建立一个完备的数据集.我们选取WMSR作为我们的数据源,并收集2004年至2016年所有发表在WMSR上的论文标题.在我们的研究中,主要包括基础文献分析和合作模式分析.基础文献分析又包括产量分析和影响力分析,产量分析涉及到的信息包括作者、机构、国家地区、关键词;影响力分析涉及到的关键信息是论文的引用次数.合作模式分析研究作者间的合作关系、主要的研究主题以及作者的研究兴趣、涉及到的信息包括每篇论文的所有作者以及关键词.通过仔细调研,发现有些论文并没有提供关键词信息,因此我们试图从摘要和标题中抽取一些主题词来补充关键词.我们采用关键词抽取模型[31],其过程有3个步骤:
1) 移除停用词.对于一些如the,is,we等对关键词抽取来说毫无意义的词,我们建立一个停用词表[32],从摘要和标题中删除这些词.
2) 对剩下的词分别建立x-元词(x为单词个数,取值为1~4)权重矩阵,权重的值为单词或术语在标题和摘要中出现的次数.
3) 对所有的x-元词按权重进行降序排序,然后取权重最高的n(n≤10)个词作为关键词.
1) 收集2004年至2016年所有发表在WMSR上的论文的标题,作为数据集的元数据.
2) 利用网络爬虫工具从IEEE Xplore和ACM数据库中抽取一些重要的信息,包括作者、机构、国家地区、摘要、关键词.
3) 考虑到IEEE Xplore 和ACM数据库中提供的作者姓名通常是缩写,因此我们利用网络爬虫工具从DBLP中自动抽取作者的全名.
4) 利用网络爬虫工具从Google Scholar中抽取论文的引用次数.
通过以上这4个步骤,我们收集了MSR文献分析所需的相关数据,并构建了一个完整的数据集.该数据集包含不同类型的数据,呈现复杂而多相的特点.
2.2 基础文献分析
基础文献分析包括2个方面,即产量分析和影响力分析,主要针对单一类别的信息,采用统计分析方法来挖掘MSR基本的领域知识,如图2所示.本节详细介绍产量分析和影响力分析的实施方法.
2.2.1 产量分析实施方法
2.2.2 影响力分析实施方法
1) 作者影响力分析.在作者影响力分析中,我们引入H因子(H factor)[33]来度量单个作者的影响力.
H因子:又称为H指数,是Hirsch[33]于2005年提出的一种衡量作者影响力的指标,其综合考虑了作者发表的论文的质量和数量.对于一些作者,虽然发表的论文数量较多,然而论文的质量并不高,即所有论文的引用数量都较低.因此,H因子综合考虑论文的质量和数量,其主要思想为:如果一个作者发表了h篇论文,其被引次数不得少于h次.具体过程为:对某个作者在某个时段内发表的论文,按被引次数从高到低排列,排序后每篇论文会得到一个序号i,将每篇论文的序号i和被引次数进行比较,找到序号h的论文,使得该论文的序号h小于或等于它的被引次数,而下一篇论文,其序号h+1大于它的被引次数.
H因子已经被广泛接受并用于衡量不同领域作者的影响力.例如,Alcaide等人[34]通过H因子来评估生物医学中20个主要作者的科学研究的影响力;Oppenheim[35]使用H因子对信息领域的科学家进行排序;Bornmann和Daniel[36]也应用H因子到博士后奖学金申请人的评选工作中.在文献[37]中,Alonso等人对H因子的优点、缺点、应用以及各种改进版本进行了系统地总结.很多研究者的H因子能在Google Scholar中查询到,在本文我们并不直接使用Google Scholar中的H因子,因为其衡量的是作者在所有研究领域的影响力.我们需要计算所有作者在MSR 领域的H因子,然后根据H因子对作者排序.
2) 论文影响力分析.在论文影响力分析中,我们引入NCII指数[19]来度量论文的影响力.
NCII指数:通常情况下,论文的引用次数与其发表的时间有着很大的关系,也就是说,一篇论文发表的时间越早,其被引用的次数可能越多.从而导致不同时期出版的论文难以比较它们的影响力.因此,考虑到出版时间对引用数量的影响, Holsapple等人[19]提出了一个新的影响力计算标准,即NCII指数.其计算为

(1)
从式(1)可以看出,NCII指数实际上代表了论文每年的平均引用次数.相比较于总的引用次数,使用NCII指数作为论文影响力评价标准更加合理.目前,NCII指数已被广泛用于评估领域科研论文的影响力.例如,Serenko和Bontis[38]利用NCII指数来计算知识管理和智能资本相关文献的影响力;在智能交通领域,Xu等人[16]使用NCII指数对该领域的文章进行影响力排序;另外,基于NCII指数的思想,Cheng等人[39]提出了类似的标准化评分(normalized score),对人工智能领域的1224个期刊杂志的影响力进行了排序.在本文我们首先计算出每篇论文NCII指数;然后根据NCII指数排序,分析论文的影响力.
2.3 合作模式分析
合作模式分析研究作者间的合作关系、MSR领域主要研究主题以及作者的研究兴趣.通过分析信息之间的相互联系,挖掘MSR领域中一些隐藏的领域知识.为了完成这些关键问题的分析,我们构建3个重要的关系网络,即作者合著网络、关键词共现网络、作者-关键词共现网络.其中作者合著网络与关键词共现网络相互独立,分别基于作者间的依赖关系和关键词间的依赖关系,揭露作者间的合作关系以及流行的研究主题;而作者-关键词共现网络基于作者和关键词间的依赖关系,揭露作者研究兴趣.本节阐述合作模式分析的详细过程.
2.3.1 GN聚类算法
GN是一种经典的社区发现算法,属于分裂的层次聚类算法[40].基本思想是不断地删除网络中具有相对于源节点的最大边介数(edge betweenness)(一条边的边介数是指通过该边的最短路径的条数)的边,再重新计算网络中剩余的边相对于源节点的边介数,直到所有边被消除.然而,在不知道社区数目的情况下,GN算法无法确定选取哪种网络状态.因此,Clauset[41]引入了模块度的概念,提出了一种改进的GN算法.其基本步骤如下:
1) 计算网络中所有边的边介数;
2) 找到边介数最高的边并将该边从网络中删除掉,记录新网络状态下的模块度和网络状态;
3) 重复步骤1和步骤2,直到每个节点就是一个退化的社区为止,最后把模块度最大的状态作为分裂的结果.
模块度(modularity)Q是一种评价社区划分质量的标准[32],其计算公式为
(2)
其中,ei i表示网络中第i个社区中连接2个不同节点的边在所有边中所占的比例,ai表示与第i个社区中的节点相连的边在所有边中所占的比例.
2.3.2 作者合著网络
在一篇论文中,可能存在多个作者,这些作者相互合作共同完成论文的撰写.同一作者可能与不同的作者合作,具有不同的合作关系.作者合著网络使用GN算法对作者进行聚类,揭示作者间紧密的合作关系.
定义1. 给定一个关系网络N={A,B,W}.其中,A代表点的集合,即作者集合;B代表边的集合,即作者间的合作关系集合,B中的每一个元素bx y表示作者ax和作者ay共同完成了一篇论文;W表示权重集合,即作者之间的合作次数集合,其值是2个作者合作完成的论文数量.

(3)
(4)
2.3.3 关键词共现网络
一般情况下,论文会提供一些关键词来表明其核心研究主题,当几个关键词出现在同一篇论文中,意味着这些关键词有着一定的相关性.关键词共现网络使用GN算法对关键词聚类,找到网络中流行的研究主题.
定义2. 给定一个关系网络N={K,B,W}.其中,K是点的集合,即关键词集合;B是边的集合,代表关键词之间共现关系,B中的每一个元素bx y表示关键词kx和关键词ky之间的共现关系;W表示权重集合,其值为同时出现这2个关键词的论文的数量.
关键词共现网络分析.对该网络实行w(K′)操作,并使得模块度Q的值最大.标志w(K′)的定义与w(A′)相同.
2.3.4 作者-关键词共现网络
通常,作者完成1篇论文时都会使用一些关键词来表明该论文的研究主题,当2篇论文的作者使用相似或相同的关键词时,意味着这些作者之间可能有着相近或相同的研究兴趣.作者-关键词共现网络使用GN算法对作者聚类,每一类中的作者都有着相近或相同的研究兴趣.
定义3. 给定一个关系网络N={A,AK,T}.其中,A是点的集合,即作者集合;AK是边的集合,每一个元素akx y表示作者ax和作者ay使用过相同的关键词;T表示权重集合,其值为2个作者使用相同关键词的数目.
作者-关键词共现网络分析.对该网络实行w(A′)操作,并使得模块度Q的值最大.
2.3.5 关系网络分析过程
关系网络分析主要是借助GN聚类算法对网络中的节点聚类,将网络的节点划分到不同的簇.然而,上述3个关系网络都是带有权重的网络,传统的GN聚类算法不能直接应用于这3个网络.因此,Xu等人[16]定义了一个新的概念,即边值(edge value),其值等于边介数除以权重.GN算法通过不断地删除边值最大的边,来寻找模块度最大的网络状态.使用GN算法聚类以后,在对每个簇评价时需要使用到一种指标,即平均节点度Ad(average degree)[16].下面,我们详细介绍这个指标:
平均节点度是社会网络中某个点所连接的边的权重的平均值[16].以作者合著网络为例,平均节点度是作者平均合作次数.假设存在一个子网络N′={A′,B′,W′},A′,B′,W′为A,B,W的子集,则有:

(5)

Fig. 3 The number of publications per year in WMSR.图3 WMSR每年文章数量
3 基础文献分析结果
本节主要介绍MSR文献分析数据集,并从2个方面即产量分析和影响力分析来呈现基础文献分析结果.
3.1 数据集
我们数据集的数据来源于2004年至2016年WMSR收录的所有论文.为了创建MSR文献分析数据集,我们首先从WMSR上抽取论文标题作为元数据,然后通过网络爬虫工具从DBLP, ACM, IEEE Xplore, Google Scholar中抽取作者全名、机构、国家地区、关键词、摘要以及引用次数.该数据集包含529篇论文和961位作者,这些作者来自35个国家地区,隶属于254个不同的机构.图3显示了WMSR每年收录的论文的数量,从图3中可以看出,在2012年(含)之前,每年WMSR收录的文章数量都在40篇以下,从2013年开始文章数量有所增加,这表明近年来更多的学者开始关注MSR领域.
3.2 产量分析结果
3.2.1 作者统计
我们的数据集中收集了所有论文的作者全名,为了识别最高产的作者,需要对作者信息进行预处理:
首先,由于一些特殊字符,需要统一作者全名,如“Yann-Ga⊇l Guéhéneuc”和“Yann-Gael Gueheneuc”应该表示同一个作者,我们用后者代替前者;然后,去掉重复的作者,并统计每个作者发表的论文数量.
我们的数据集中包含529篇论文,大多数论文的作者数量为1~6位,极少数作者数量超过7位,平均作者数量为3.29位,共涉及961位不同的作者,其中674位作者仅发表了1篇论文.表1显示了最高产的10位作者以及他们发表的论文数量.从表1中可以看出,排名第1的作者是Ahmed E. Hassan,在WMSR上共发表了23篇论文;排在第2位和第3位的是Abram Hindle和Daniel M. German,在WMSR上均发表了22篇论文;其余7位作者在WMSR上发表的论文数量都超过10篇.
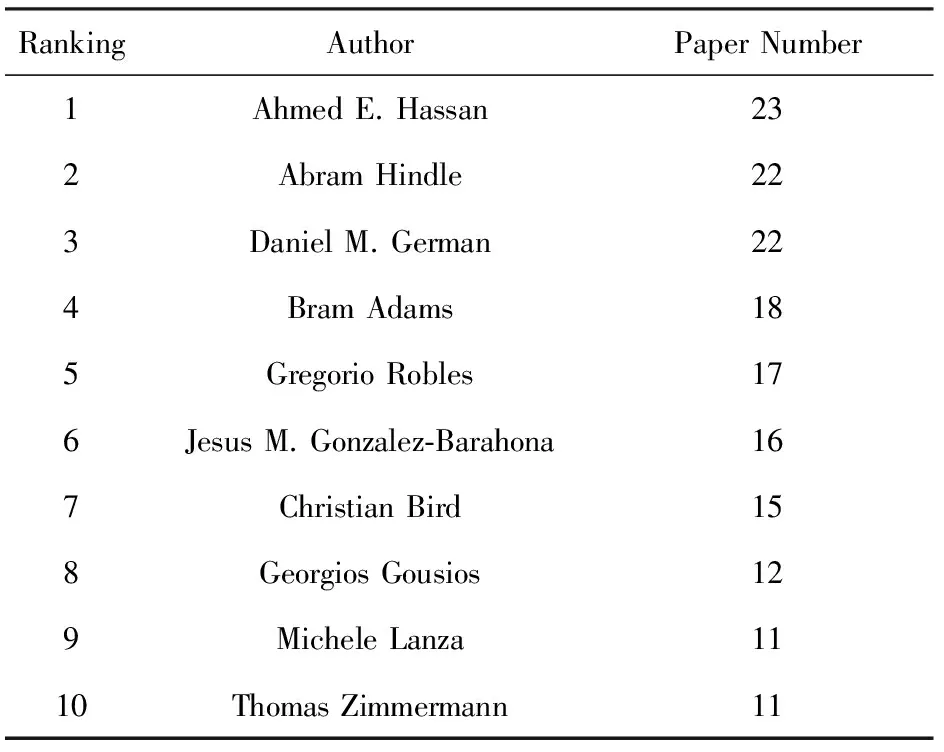
Table 1 The Information of the Most Productive Authors
3.2.2 机构统计
为了识别最高产的机构,我们需要对机构信息进行预处理:
1) 在数据集中,每一篇论文的每一个作者都对应一个机构,必然存在多个作者来自于同一个机构.因此同一篇论文中,同一机构仅统计一次.
2) 在不同的论文中,由于不同作者的表达方式或者写作习惯不同,同一机构可能有不同的名称.因此,需要人工统一机构的名称,比如Ecole Polytechnique de Montréal和Polytechnique de Montréal实际上表示同一机构.
3) 部分大学包含多个分校,比如加州大学(University of California)包含10个分校,这些分校间相互独立,即不共享研究成果.因此,需要区分这些分校.
4) 一些公司或企业的研究机构也会参与科学研究,这些研究机构可能分布在不同的国家地区,但共享研究成果.比如,IBM Watson Research Lab和IBM Haifa Research Lab分别位于美国和以色列.因此,我们不区分这些机构,即统一使用公司名称.
通过以上4个步骤,我们发现共有254个不同的组织或机构,其中135个机构仅发表了1篇论文.表2列出了前10的机构的名称、发表的论文数量以及它们所属的国家地区.从表2中可以看出,排名前3的大学是加拿大的University of Victoria, Queen’s University, University of Waterloo,分别发表了32,31,29篇论文,其他7所大学所发表的论文都超过10篇.在前10的大学中有5所大学位于加拿大,另外5所大学分别位于荷兰、美国、西班牙、瑞士和德国.可见,隶属加拿大的研究机构对MSR领域的发展有着一定的贡献.

Table 2 The Information of the Most Productive Institutions
1) 极少数论文中虽然提供了机构信息,然而缺失国家信息.因此,我们需要仔细核对这些机构所属国家地区.
通过上述预处理的2个步骤,我们统计出该数据集中包含35个国家地区,其中有9个国家地区仅发表了1篇论文,按照发表的论文数量对这些国家地区进行排序,图4显示这些国家地区发表论文的数量信息.从图4中可以看出,最高产的10个国家分别是美国、加拿大、荷兰、德国、瑞士、日本、英国、意大利、西班牙和法国;美国和加拿大分别发表了174和146篇论文,与机构统计结果相比,美国才是最高产的国家.这是因为美国有着更多的机构参与了MSR领域研究,而在加拿大,仅有几所大学参与MSR领域研究.另外,观察发现美国和加拿大发表的论文数量占总数量一半以上,主导着MSR领域的发展.中国作者参与了13篇论文的撰写,排名为11.

Fig. 4 The publication numbers of different countries.图4 各国发表的MSR论文数量
3.2.4 关键词统计
为了识别最频繁的关键词,我们需要对数据集中的关键词信息进行预处理:
1) 同样关键词中某个单词可能是复数也可能是单数.因此我们将复数变成单数,但仅考虑将结尾为“s”和“ies”的词转化为原型.
2) 在关键词中,存在一些对关键词统计毫无意义词,如software engineering,mining software repositories,data mining等,我们收集这些关键词并放入停用词列表[32],然后自动移除这些关键词.
3) 不同作者有着不同的写作习惯和表达方式,他们会使用不同的关键词来表示相同的主题,比如bug,defect,fault等.因此,我们建立了一个同义词表[32],将不同的词替换为同一个词,如将defect和fault替换为bug.
通过以上3个步骤,我们统计出所有的不同的关键词,并计算每个关键词的频率,根据它们的频率排序,表3显示了前10个最频繁的关键词.从表3中可以看出,“software maintenance”是最频繁的关键词,109篇论文使用过该关键词,这说明在软件仓库挖掘领域,软件维护是最主要研究方向.其原因是软件仓库挖掘所涉及到的数据大部分源于软件维护阶段;排在第2和第3的是“Open source project”和“Software configuration management and version control system”,频率分别为87次和58次.这2个关键词获得较高排名的原因是从开源工程获取数据最为容易,而软件版本演化是重要的研究主题.其他的频繁的关键词包括“Software post development issue”, “Java”, “Documentation”, “Software quality”,“Human factor”, “Performance”, “Public domain software”.

Table 3 The Information of the Most Frequent Keywords
3.3 影响力分析
本节呈现影响力分析结果,主要分为作者影响力分析和论文影响力分析2个方面.
3.3.1 作者影响力分析
MSR文献分析数据集收集了所有论文的引用次数,我们根据引用次数计算所有作者的H因子,然后根据H因子对作者进行排序,表4记录了前10位作者的信息.从表4中可以看出,排名前3的作者是Ahmed E. Hassan, Daniel M. German, Abram Hindle,H因子分别为14,14,11,他们均来自加拿大,所在的机构也是高产机构;其他7位作者均来自加拿大、西班牙、荷兰等高产国家,可见,来自高产国家地区的作者往往有着较大的影响力.
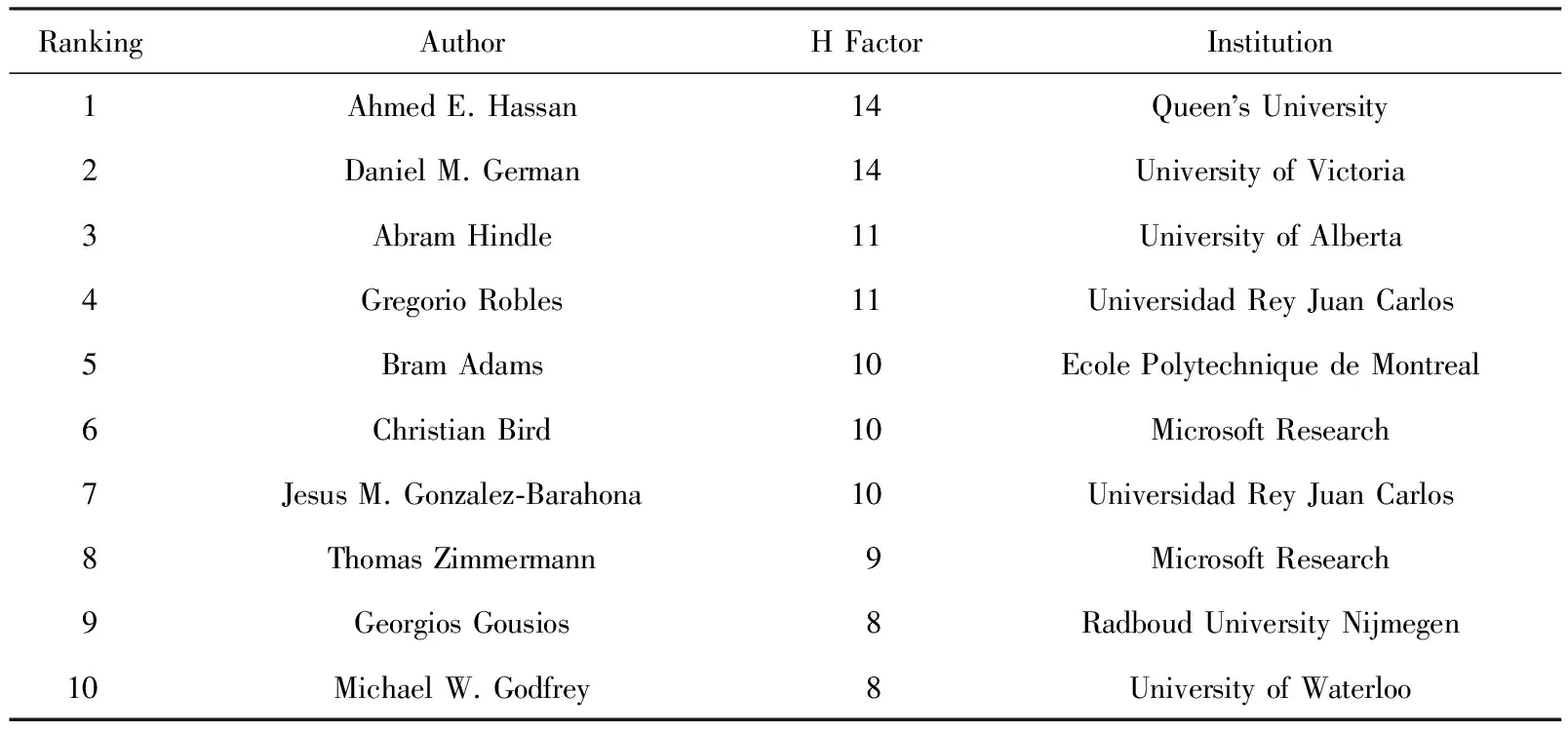
Table 4 The Information of 10 Authors with the Highest H Factor
3.3.2 论文影响力分析
我们收集了每篇论文的引用次数,表5呈现了引用次数最高的10篇论文的标题、引用次数、作者、国家和年份信息.从表5中可以看出,引用次数最高的论文大多发表于2004年至2007年,仅有2篇论文分别发表于2009年和2010年.可见,引用次数和发表年份有着很大的关系.排名前3的论文分别被引用了489,442,253次,其他7篇论文的引用次数均在100次以上.这些高引论文的作者大多数来自德国、美国和瑞士.很明显,高产国家参与MSR研究更早,所发表的论文引用次数自然更高.
我们计算所有论文的NCII指数,然后根据NCII指数对论文进行排名.表6呈现了NCII指数最高的前10篇论文标题、引用次数、NCII指数、作者、国家和年份信息.排名前10 的论文中发表于2013年和2014年各有2篇,其他发表于2005年、2006年、2007年、2009年、2010年、2012年各有1篇.NCII指数最高的3篇论文分别是“When do changes induce fixes?”, “Mining email social networks”, “The promises and perils of mining GitHub”,其值均超过40.实际上,NCII指数最高的论文“When do changes induce fixes?”也有着最高的引用次数.

Table 5 The Information of the 10 Most Cited Publications
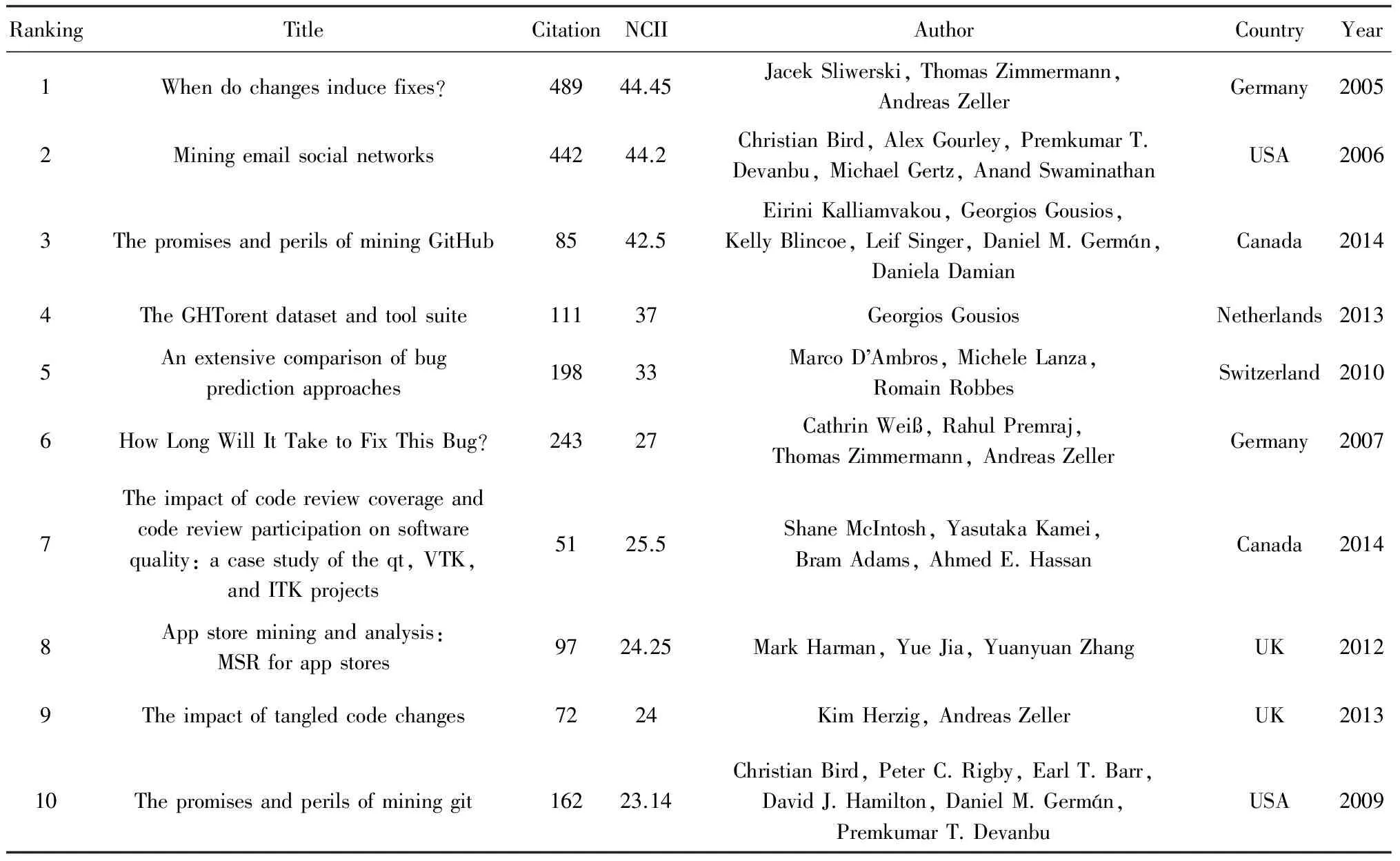
Table 6 The Information of 10 Publications with the Highest NCII
另外,这些论文的作者基本上来自于德国、美国、加拿大、荷兰、英国、日本等一些高产国家.可见,高产国家的论文有着较大的影响力.实际上,NCII指数平衡了论文的引用次数和发表时间关系,即论文发表的时间越早,并不代表论文的影响力就越高,在一定程度上能更准确地反映出论文的影响力.
4 合作模式分析结果
本节主要通过3个关系网络,包括作者合著网络、关键词共现网络、作者-关键词共现网络来呈现合作模式分析结果.
4.1 作者合著网络
一个人对某个领域的影响力大小,与他和该领域其他作者合作次数有着很大的关系.另外,影响力越大的作者,对整个领域的贡献也就越大,与他合作的作者就可能越多.通过使用GN算法对作者合著网络中的节点(即作者)聚类,分析作者之间的合作关系.在我们的研究中,为了深入地挖掘作者间的合作关系,仅考虑那些发表论文数量超过2篇的作者.在构建的作者合著网络中,共包含404个节点和2 536条边.在这个网络中,由于一些作者与另外一些作者可能没有合作关系,因此该网络通常由一些连通子图(社区)组成.我们借助NetDraw工具[20]可视化作者合著网络中最大的2个连通子图.

Fig. 5 The largest connected subgraph.图5 最大的连通子图
第1个连通子图的模块度为0.719,平均节点数是6.173 6,如图5所示.在这个连通块中共包含288个节点、1 778条边,分属16个簇.由于每个作者的合作次数不同,我们用不同大小的点来区分合作次数的多少,用不同的颜色来区分这些簇.在这个连通块中,拥有合作次数最多的作者是Ahmed E. Hassan,共参与合作35次,其所在簇的作者大多数来自加拿大;排名第2的是Bram Adams,其参与合作的次数为34次;接着是Christian Bird,合作次数为32次.
第2个连通子图的模块度为0.649,平均节点数是6.903,如图6所示.第2个连通块中作者的平均合作次数要高于第1个连通块的作者平均合作次数.在这个连通块中共包含93个节点、642条边,分属8个簇.在这个连通块中,合作次数最多的作者是Abram Hindle,达到60次,也是MSR领域参与合作次数最多的作者,即最活跃的作者;接着是Daniel M. German和Katsuro Inoue,参与合作的次数分别达到50次和28次;另外,Jesus M. Gonzalez-Barahona也有着较多的合作次数.
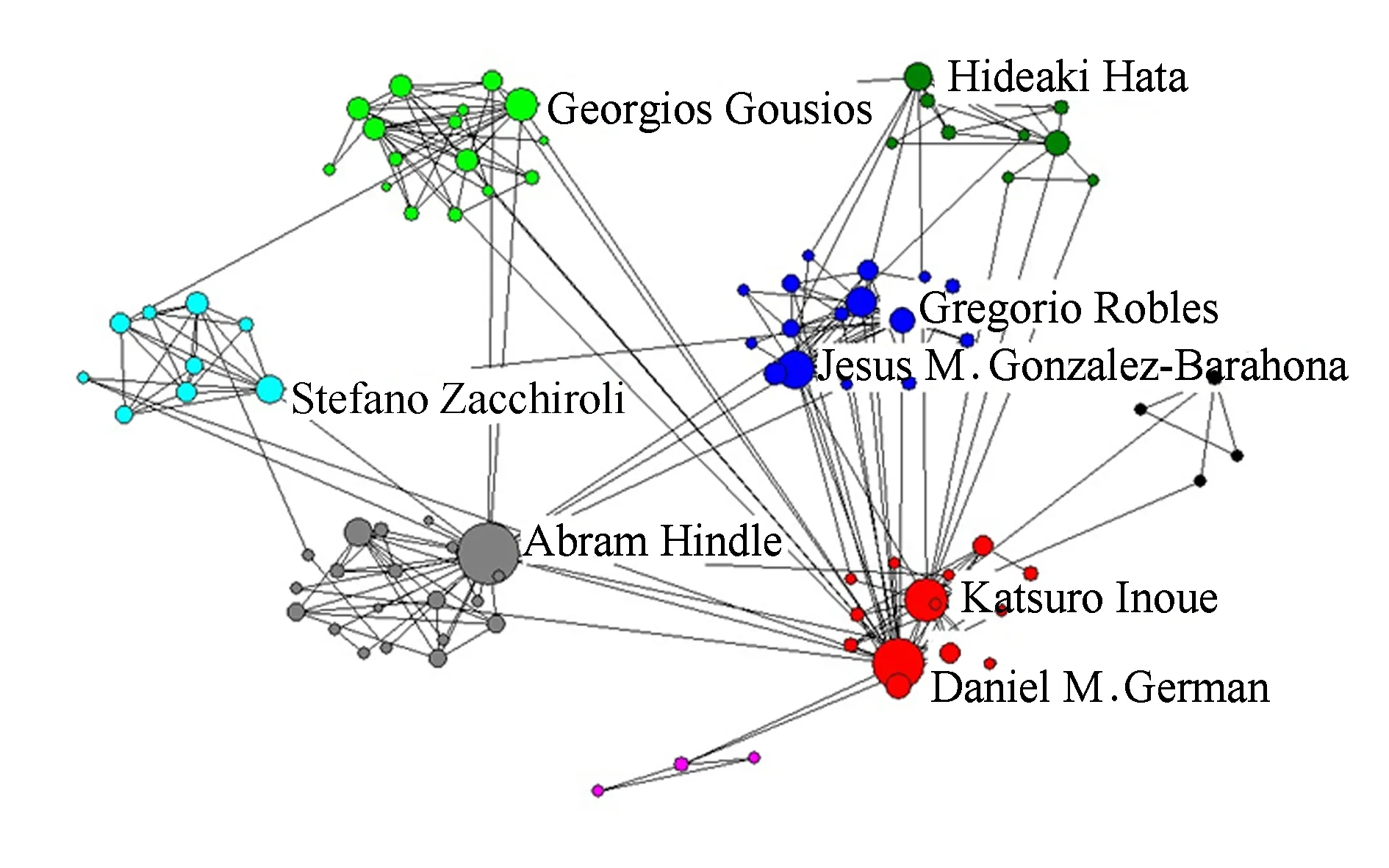
Fig. 6 The second largest connected subgraph.图6 第2大连通子图
4.2 关键词共现网络
在1篇已发表的论文中,一般会提供3~5个关键词作为标签,标注该论文的研究主题.同时出现在一篇论文中的关键词可能围绕着同样的研究主题.通过使用GN算法对关键词共现网络中的节点(即关键词)聚类来分析MSR领域中热点研究主题.为了准确地分析出主要的研究主题,我们考虑移除那些在论文中出现次数少于5次的关键词.这是因为当出现次数较小时,该关键词所代表的研究主题可能不是热点研究主题.在生成的关键词共现网络中,包含93个节点、340条边,每2个节点之间的边表示2个关键词在不同论文中出现的次数总计超过5次.我们借助NetDraw工具[20]可视化关键词共现网络.
图7是生成的关键词共现网络,其模块度为0.473,所有的关键词被划分为12个簇,分别用红色数字标出.划分在同一簇中的关键词有着一定的关系,比如 “information retrieval”和“duplicate bug report detection”被聚集在簇11中,这是因为信息检索技术是解决重复bug检测的一个重要方法.“data acquisition”和“data analysis”被聚集在簇6中,这2个主题分别表示数据采集和数据分析,有着很强的相关性.我们把节点数最高的节点作为主题词,每个簇代表了一个研究主题.通过聚类我们发现,最大的4个簇,即簇1,2,3,4分别围绕“open source project”, “software maintenance”, “performance, test”, “documentation”四个主题词.这些主题词是MSR领域最热门的研究主题,同时,也是软件工程领域最常见的研究主题.因此,关键词共现网络能够解析出MSR领域热门研究主题.
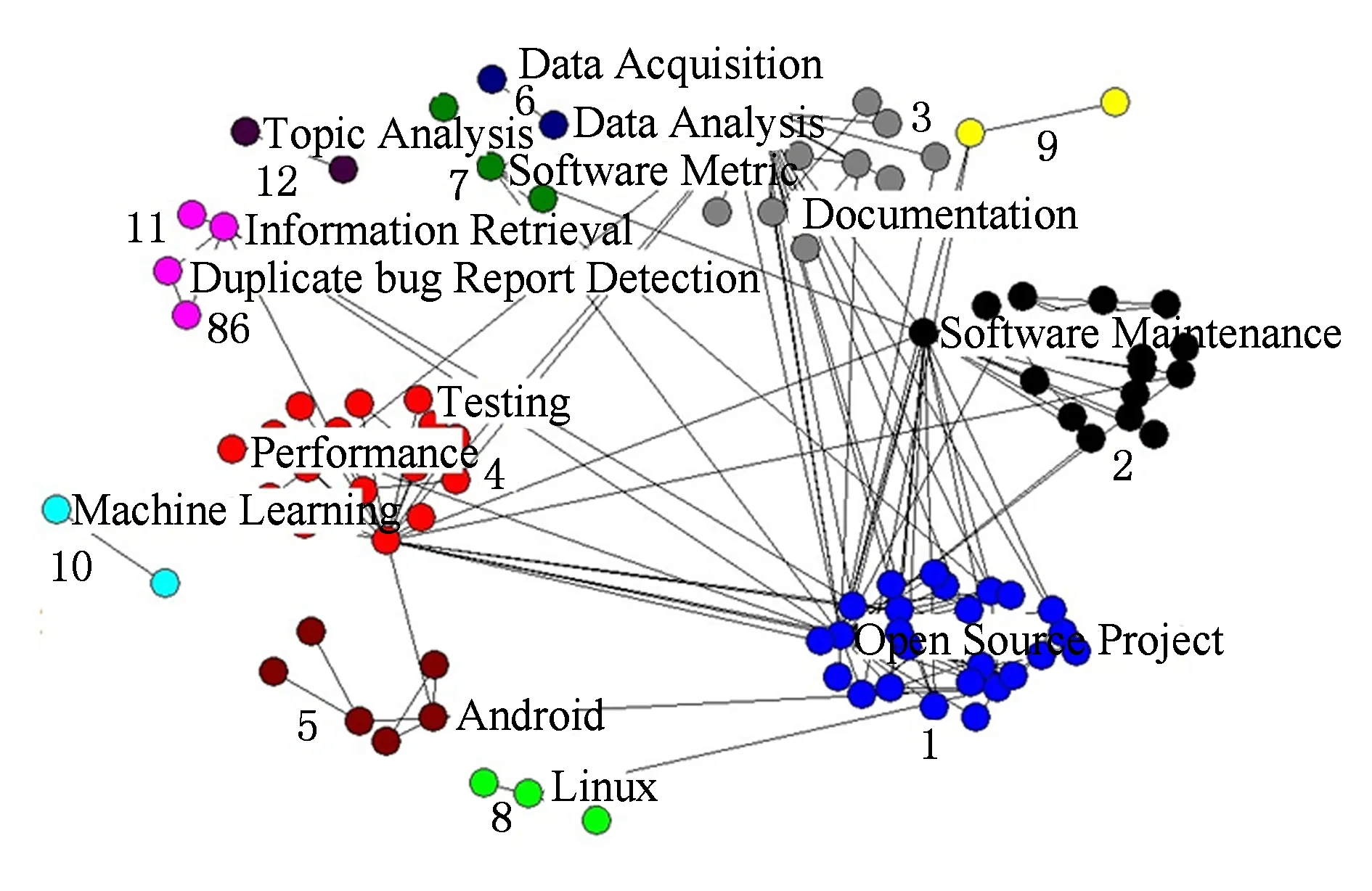
Fig. 7 The keyword co-occurrence network.图7 关键词共现网络
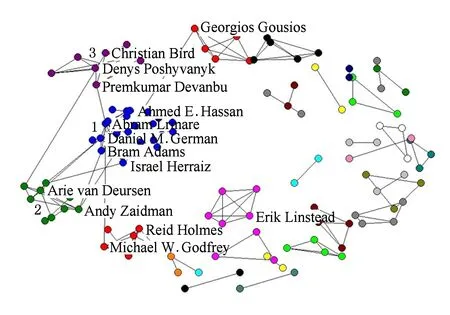
Fig. 8 The author co-keyword network.图8 作者-关键词共现网络
4.3 作者-关键词共现网络
在2篇不同的论文中,可能使用相同的关键词来描述论文的研究主题,这些相同的关键词表明这些作者可能具有相同或相近的研究方向.通过使用GN算法对作者-关键词共现网络中的点(即作者)聚类,来分析哪些作者有着相同的研究兴趣.在我们的研究中,为了重点研究一些具有代表性的作者的研究兴趣,我们过滤掉那些发表的论文数量少于2篇的作者,实际上,这些作者在MSR领域并不具有突出贡献.生成的网络包含126个作者、340条边.我们借助NetDraw工具[20]可视化作者-关键词共现网络.
图8是作者-关键词共现网络,其模块度为0.837,所有节点共被划分为30个簇,大多数簇中的节点都较少.我们详细分析其中最大的3个簇:
簇1. 这个簇是作者-关键词共现网络中最大的簇,以Ahmed E. Hassan和 Abram Hindle为主导,包括Daniel M. German, Bram Adams, Israel Herraiz等作者,实际上,在这个簇中的作者大多数都是高产作者.主要关注软件维护领域,包括软件演化、代码推荐等方向.
簇2. 这个簇也包含较多的作者,主要以Andy Zaidman和Arie van Deursen为主导.主要关注软件测试和软件开发领域,比如测试实例自动化生成和基于拉式的软件开发等方向.
簇3. 这个簇也有一定数量的作者,主要以Christian Bird, Denys Poshyvanyk, Premkumar Devanbu为主导.其主要的研究方向是开源工程和社交网络等.
5 结束语
本文主要工作是MSR文献分析研究,分为基础文献分析和合作模式分析.为了高效地完成这项工作,我们建立了MSR文献分析框架,即MSR-PAF.MSR文献分析框架由3个组件组成:
1) 第1个组件用来创建数据集.我们收集WMSR上的所有文献标题作为元数据,从IEEE Xplore和ACM数据库中爬取作者、机构、国家地区、关键词、摘要等信息,然后从DBLP中爬取作者的全名,最后从Google Scholar中爬取论文的引用次数,最终创建MSR文献分析数据集.
2) 第2个组件执行基础文献分析,我们使用数理统计方法识别最高产的作者、机构、国家地区、最频繁的关键词,同时引入H因子和NCII指数来检测最有影响力的作者和论文.
3) 第3个组件实施合作模式分析,我们利用3个关系网络,包括作者合著网络、关键词共现网络、作者-关键词共现网络来分析作者之间的合作关系、主要研究主题以及作者的研究兴趣.文献分析结果表明Ahmed E. Hassan是最高产的作者,open source project和software maintenance是最流行的研究主题.将来,我们会更多地关注MSR文献分析研究,扩展MSR文献分析数据源,更加深入地挖掘MSR文献中蕴含的知识.
[1]Zhou Minghui, Guo Changguo. New thought of software engineering based big data[J]. Communications of the CCF, 2014, 10(3): 37-42 (in Chinese)(周明辉, 郭长国. 基于大数据的软件工程新思维[J]. 中国计算机学会通讯, 2014, 10(3): 37-42)
[2]Zhang Dongmei, Han Shi, Lou Jianguang, et al. Software analytics-key points and practice[J]. Communications of the CCF, 2014, 10(3): 29-36 (in Chinese)(张冬梅, 韩石, 楼建光, 等. 软件解析学——要点与实践[J]. 中国计算机学会通讯, 2014, 10(3): 29-36)
[3]He Keqing, Li Bing, Ma Yutao, et al. Key techniques of software engineering in the era of big data[J]. Communications of the CCF, 2014, 10(3): 8-18 (in Chinese)(何克清, 李兵, 马于涛, 等. 大数据时代的软件工程关键技术[J]. 中国计算机学会通讯, 2014, 10(3): 8-18)
[4]Xie Tao, Pei Jian, Hassan A E. Mining software engineering data[C] //Proc of IEEE ICSE’07 Compaion. Piscataway, NJ: IEEE, 2007: 172-173
[5]Xie Tao, Thummalapenta S, Lo D, et al. Data mining for software engineering[J]. Computer, 2009, 42(8): 55-62
[6]Li Xiaochen, Jiang He, Ren Zhilei. Data driven feature extraction for mining software repositories[J]. Computer Science, 2015, 42(9): 159-164 (in Chinese)(李晓晨, 江贺, 任志磊. 面向软件仓库挖掘的数据驱动特征提取方法[J]. 计算机科学, 2015, 42(9): 159-164)
[7]Xuan Jifeng, Jiang He, Ren Zhilei, et al. Developer prioritization in bug repositories[C] //Proc of IEEE ICSE’07. Piscataway, NJ: IEEE, 2012: 25-35
[8]Lü Linyuan, Zhang Yicheng, Yeung C H, et al. Leaders in social networks, the delicious case[J]. PloS One, 2011, 6(6): e21202
[9]Hassan A E, Xie Tao. Software intelligence: The future of mining software engineering data[C] //Proc of the 10th ACM FSE/SDP Workshop on Future of Software Engineering Research. New York: ACM, 2010: 161-166
[10]Eunjoo L E E, Chisu W U. A survey on mining software repositories[J]. IEICE Trans on Information and Systems, 2012, 95(5): 1384-1406
[11]Wang Feiyue. Publication and impact: A bibliographic analysis[J]. IEEE Trans on Intelligent Transportation Systems, 2010, 11(2): 250-250
[12]Li Linjing, Li Xin, Li Zhenjiang, et al. A bibliographic analysis of the IEEE Transactions on Intelligent Transportation Systems literature[J]. IEEE Trans on Intelligent Transportation Systems, 2010, 11(2): 251-255
[13]Heilig L, Voβ S. A scientometric analysis of cloud computing literature[J]. IEEE Trans on Cloud Computing, 2014, 2(3): 266-278
[14]Park D H, Kim H K, Choi I Y, et al. A literature review and classification of recommender systems research[J]. Expert Systems with Applications, 2012, 39(11): 10059-10072
[15]Li Linjing, Li Xin, Cheng Changjian, et al. Research collaboration and ITS topic evolution: 10 years at T-ITS[J]. IEEE Trans on Intelligent Transportation Systems, 2010, 11(3): 517-523
[16]Xu Xiujuan, Wang Wei, Liu Yu, et al. A bibliographic analysis and collaboration patterns of IEEE Transactions on Intelligent Transportation Systems between 2000 and 2015[J]. IEEE Trans on Intelligent Transportation Systems, 2016, 17(8): 2238-2247
[17]Lindsey D. Production and citation measures in the sociology of science: The problem of multiple authorship[J]. Social Studies of Science, 1980, 10(2): 145-162
[18]Ward P L. Foundations of Library and Information Science[M]. New York: Anmol Publications, 2006: 3287-3292
[19]Holsapple C W, Johnson L E, Manakyan H, et al. Business computing research journals: A normalized citation analysis[J]. Journal of Management Information Systems, 2015, 11(1): 131-140
[20]Borgatti S P. Netdraw network visualization[R/OL]. Cambridge: Analytic Technologies, 2002 [2016-08-01]. http://www.analytictech.com/netdraw/netdraw.htm
[21]Podgurski A, Leon D, Francis P, et al. Automated support for classifying software failure reports[C] //Proc of IEEE ICSE’03. Piscataway, NJ: IEEE, 2003: 465-475
[22]Dang Yingnong, Wu Rongxin, Zhang Hongyu, et al. ReBucket: A method for clustering duplicate crash reports based on call stack similarity[C] //Proc of IEEE ICSE’12. Piscataway, NJ: IEEE, 2012: 1084-1093
[23]Kim S H, Zimmermann T, Nagappan N. Crash graphs: An aggregated view of multiple crashes to improve crash triage[C] //Proc of the 41st IEEE/IFIP Int Conf on Dependable Systems & Networks (DSN). Piscataway, NJ: IEEE, 2011: 486-493
[24]Zimmermann T, Nagappan N. Predicting defects using network analysis on dependency graphs[C] //Proc of ACM ICSE’08. New York: ACM, 2008: 531-540
[25]Chang R Y, Podgurski A, Yang J. Discovering neglected conditions in software by mining dependence graphs[J]. IEEE Trans on Software Engineering, 2008, 34(5): 579-596
[26]Runeson P, Alexandersson M, Nyholm O. Detection of duplicate defect reports using natural language processing[C] //Proc of IEEE ICSE’07. Piscataway, NJ: IEEE, 2007: 499-510
[27]Wang Xiaoyin, Zhang Lu, Xie Tao, et al. An approach to detecting duplicate bug reports using natural language and execution information[C] //Proc of ACM ICSE’08. New York: ACM, 2008: 461-470
[28]Nguyen A T, Lo D, Nguyen T N, et al. Duplicate bug report detection with a combination of information retrieval and topic modeling[C] //Proc of IEEE ASE’12. Piscataway, NJ: IEEE, 2012: 70-79
[29]Sun Chengnian, Lo D, Wang Xiaoyin, et al. A discriminative model approach for accurate duplicate bug report retrieval[C] //Proc of ACM ICSE’10. New York: ACM, 2010: 45-54
[30]Tang Shaohu, Li Zhengxi, Chen Dewang, et al. Theme classification and analysis of core articles published in IEEE Transactions on Intelligent Transportation Systems from 2010 to 2013[J]. IEEE Trans on Intelligent Transportation Systems, 2014, 15(6): 2710-2719
[31]Hacohenkerner Y. Automatic extraction of keywords from abstracts[C] //Proc of the 7th Int Conf on Knowledge-Based and Intelligent Information and Engineering Systems. Berlin, Springer, 2003: 843-849
[32]OSCAR. The public-access stop word list[EB/OL]. 2016 [2016-10-22]. http://oscar-lab.org/chn/resource.htm
[33]Hirsch J E. An index to quantify an individual's scientific research output [J]. Proceedings of the National Academy of Sciences of the United States of America, 2005, 102(46): 16559-16572
[34]Alcaide G G, Gómez M C, Zurián J C V, et al. Scientific literature by Spanish authors on the analysis of citations and impact factor in biomedicine (1981—2005) [J]. Revista Espaola De Documentación Científica, 2008, 31(3): 344-365
[35]Oppenheim C. Using the H-index to rank influential British researchers in information science and librarianship[J]. Journal of the American Society for Information Science & Technology, 2007, 58(2): 297-301
[36]Bornmann L, Daniel H. What do we know about the h index? [J]. Journal of the American Society for Information Science & Technology, 2007, 58(9): 1381-1385
[37]Alonso S, Cabrerizo F J, Herrera-Viedma E, et al. H-index: A review focused in its variants, computation and standardization for different scientific fields[J]. Journal of Informetrics, 2009, 3(4): 273-289
[38]Serenko A, Bontis N. Meta-review of knowledge management and intellectual capital literature: Citation impact and research productivity rankings[J]. Knowledge and Process Management, 2004, 11(3): 185-198
[39] Cheng C H, Holsapple C W, Lee A. Citation-based journal rankings for AI research: A business perspective[J]. AI Magazine, 1996, 17(2): 87-97
[40]Girvan M, Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences, 2002, 99(12): 7821-7826
[41]Clauset A, Newman M E J, Moore C. Finding community structure in very large networks[J]. Physical Review E, 2004, 70(6): 066111

Jiang He, born in 1980. PhD, Professor and PhD supervisor at the School of Software, Dalian University of Technology, China. Member of the China Computer Federation and the ACM. His main research interests include search based software engineering, software testing and mining software repositories.

Chen Xin, born in 1987. PhD candidate. His main research interests include software testing and mining software repositories, etc.

Zhang Jingxuan, born in 1988. PhD candidate. His main research interests include mining software repositories and API document analysis, etc.

Han Xuejiao, born in 1993. Master candidate. Her main research interest is mining software repositories.

Xu Xiujuan, born in 1978. PhD and assistant professor at the School of Software, Dalian University of Technology, China. Her main research interests include applications of data mining, intelligent transportation systems, recommender systems, and social network.
Mining Software Repositories: Contributors and Hot Topics
Jiang He, Chen Xin, Zhang Jingxuan, Han Xuejiao, and Xu Xiujuan
(School of Software, Dalian University of Technology, Dalian, Liaoning 116024)
Software updates and evolves continuously over time, software repositories accumulate massive data. How to effectively collect, organize, and make use of these data has become a key problem in software engineering. Mining Software Repositories (MSR) aim to mine useful knowledge contained in complex and diversified data to improve the quality and productivity of software. Although some studies have elaborately summarized the background, history, and prospects about MSR, existing studies do not present systematically the most influential author, institution, and country as well as the major research topics and their transitions over time. Therefore, this study combines the existing classical publication analysis frameworks and algorithms to analyze the relationships among publications related to MSR, and presents some important domain knowledge for researchers in detail. To effectively tackle this task, we construct a framework named MSR Publication Analysis Framework (MSR-PAF). MSR-PAF consists of three components which can be used to create a dataset for the study, conduct a bibliography analysis, and implement a collaboration pattern analysis, respectively. The results of the bibliography analysis show that the most productive author, institution, and country are Ahmed E. Hassan, University of Victoria, and USA, respectively. The most frequent keyword is software maintenance and the most influential author is Abram Hindle. In addition, the results of the collaboration pattern analysis show that Abram Hindle is the most active author, and open source project and software maintenance are the most popular research topics.
publication analysis; collaboration pattern analysis; data mining; mining software repositories; big data
2016-08-24;
2016-10-24
国家自然科学基金项目(61370144);教育部新世纪优秀人才支持计划基金项目(NCET-13-0073) This work was supported by the National Natural Science Foundation of China (61370144) and the Program for New Century Excellent Talents in University of Ministry of Education of China (NCET-13-0073).
TP311
