基于混合类别标记新技术的小样本学习算法
2016-12-12李敏丹章东平殷海兵
李敏丹,沈 晔 ,章东平,殷海兵
(中国计量学院 信号与信息处理系,浙江 杭州 310018)
基于混合类别标记新技术的小样本学习算法
李敏丹,沈 晔 ,章东平,殷海兵
(中国计量学院 信号与信息处理系,浙江 杭州 310018)
针对计算机辅助诊断(CAD)中标记病例样本难以收集所引起的小样本学习问题,提出基于混合类别标记新技术(HCLT)的小样本学习算法.该算法分别基于几何距离、概率分布及语义概念对大量存在的未标记样本进行差异化标记,将有一致标记结果的样本加入样本集,以此扩大训练样本集.为了减少错误标记样本对学习过程造成的不利影响,提出样本伪标记隶属度并引入模糊支持向量机(FSVM)学习中,由隶属度控制样本对学习过程的贡献程度.基于UCI数据集的实验结果表明,采用该算法能够解决小样本学习问题的有效性.与单一类别标记技术相比,该算法产生的错误标记样本显著减少、学习性能显著改善.
计算机辅助诊断(CAD);小样本学习;混合类别标记;隶属度
为了提高诊断准确性,特别是降低真阳性病例的漏诊率及减轻医生工作强度,计算机辅助诊断(computer-aided diagnosis,CAD)被更多地应用于乳腺癌早期诊断中[1].根据实现原理CAD可以分成2类:1)采用机器学习生成分类器对待诊病例进行类别判断.支持向量机(support vector machine, SVM)在乳腺癌病灶检测中有良好表现[2-3];2)采用基于内容的图像检索技术,查询内容相似的已诊病例对待诊病例作出辅助诊断[4].由此可见,CAD技术的核心为学习技术,CAD问题某种程度上可以归结为学习问题.
标记病例样本须耗费大量时间与精力,标记样本往往难以收集,训练样本非常有限.笔者等[5]指出CAD面临小样本学习问题,即经典学习算法在CAD中得不到良好性能的重要原因,利用大量存在的未标记样本解决小样本学习问题是目前的研究热点.
Yap等[6]提出基于几何聚类的伪标记方法解决小样本问题,而错误标记样本明显损害学习性能.基于图正则化框架的半监督学习是近年来半监督学习研究的一个显著成就.Zhou等[7]基于样本间的相似性构造图,利用图的局部平滑性,将标记信息不断向邻近的未标记样本传播,直至全局稳定.Wang等[8]基于线性近邻模型提出新算法LNP,算法认为样本都可由其近邻线性重建.Tu等[9]提出基于图的概率学习框架PDL.首先基于图将标记样本的后验概率传播给未标记样本;然后基于所得的后验概率分布进行多元回归,可得最终的非线性分类模型.基于图的半监督学习方法有良好的理论基础,然而算法复杂度高,难以应用于大规模学习中.此外,图的构造方法及处理bridge-points等问题上值得我们进一步研究.协同学习为半监督学习的重要范例,Zhou等[10-11]首先将其引入CAD中.Kim等[12]在乳腺癌存活性预测中提出基于协同学习的半监督学习算法,但算法通过样本划分生成训练子集的方法无法保证子分类器间具有足够差异性.协同学习要求充分、冗余的特征属性对大部分应用来说过于严格,限制了它的应用.为了扩大适用范围,Zhou等[10]提出一种无约束条件的tri-training算法,可重复取样标记样本集得到3个样本子集,由此产生3个分类器.在伪标记过程中,算法采用少数服从多数投票来完成类别标记,提高了泛化能力.由于初始分类器的性能较弱,易产生错误标记降低学习性能.针对该问题,Zhou等[13]考虑到CAD中阴性样本远多于阳性,仅利用置信度最高的2个阴性样本,以此降低错误标记的可能.Zhou等[11]进一步提出Co-Forest算法,采用N个分类器来提高标记准确性.基于乳腺癌CAD的实验结果表明,该算法利用未诊断样本能够显著地提高CAD性能.
Chen等[14]研究表明,不合适的未标记样本会降低学习性能,标记的可靠性是影响半监督学习性能的关键因素.目前,仅少量研究[15-16]旨在解决标记可靠性问题.Le等[15]针对SemiBoost[17]算法中基于几何距离的置信度估计方法对分类面附近的未标记样本会产生明显错误的问题,在置信度准则中引入条件概率估计,以此提高标记可靠性.Li等[16]针对未标记样本降低学习性能的问题,提出 “安全”的S4VMs算法.该算法首先提出S3VM-us学习机,采用多级聚类确定未标记样本的分布结构.在低密度分类面的假设下,该算法通过集成多个差异化的低密度分类面提高算法性能.
综述过往研究可知,标记样本的可靠性及噪声问题是影响半监督学习性能的关键因素,也是目前研究的重点.此外,与标记样本有不同分布的未标记样本会降低学习性能,如何利用分布一致、避开不一致的未标记样本是另一个重要的研究方向.针对以上两个问题,本文提出混合类别标记新方法.该方法从几何聚类、概率分布及语义概念3个不同角度进行差异化标记,仅将有一致标记结果的未标记样本加入训练样本集.综合多个差异化标记方法能够显著地增强标记的可靠性,且在一定程度上保证了未标记样本与标记样本分布的一致性.为了进一步降低可能存在的误标记对学习机产生的不利影响,算法引入伪标记隶属度度量标记的置信度.将其引入模糊支持向量机(fuzzy support vector machine,FSVM)中,控制样本对学习过程的贡献度,进一步减少误标记产生的不利影响.
1 混合类别标记技术
类别标记是基于未标记样本与标记样本间“距离”相近的假设之上,标记的可靠性依赖于“距离”的合理性.几何距离被广泛用于度量样本间的相似性,但存在很大的局限性,如欧式距离仅适用于符合欧式空间分布的样本.合理的“距离”度量方法是准确标记的前提,而现实应用中样本分布结构无法先验获知,无法有针对性地设计合适的“距离”尺度.单一的“距离”度量方法往往无法适用各类具体应用,无法确保样本标记的准确性.仅与标记样本有相同分布的未标记样本有益于学习性能的改善,反之会降低学习性能.针对上述问题,分别基于语义、几何、概率设计“距离”尺度,3种尺度基于完全不同的判决原理,标记结果之间相互独立.综合3个差异化的标记方法在有效解决小样本问题的同时,抑制了噪声样本的引入,并间接解决了未标记与标记样本分布的一致性问题,达到优化学习性能的目的.
标记过程往往存在错误标记,也称为模糊标记或伪标记.模糊隶属度是伪标记类别与真实类别间一致性的定量表征,即伪标记可靠性的定量估计.本文将样本的模糊隶属度整合到学习过程中,由其控制该样本对学习机的贡献度,该策略可以进一步降低噪声对学习过程的不利影响.所有已标记样本的模糊隶属度统一设定为最高值1,默认其标记结果准确无误.伪标记技术与模糊隶属度估计为算法的2个关键技术.
2 基于几何距离的样本标记方法
基于同类样本呈现几何相似性的假设,算法采用两级聚类策略得到类别分布结构.采用减法聚类[18]确定样本集的聚类数及聚类结构,减法聚类具有无需先验获知类别数且运行速度快的优点;运用k均值算法迭代优化可得最终的聚类结果.针对阳性与阴性样本集,分别采用两级聚类得到各自的聚类结构.将与每个聚类中心最近的k个未标记样本进行类别标记,被标记类别与该聚类中心一致. 鉴于伪标记的模糊性,将伪标记样本xp的模糊隶属度设计为取值为0~1.0的映射函数g(xp):Rm→[0,1].
模糊隶属度设计思路如下:从几何角度考虑,伪标记样本与同类别聚类中心越近,标记结果的置信度越高,即伪标记隶属度越高;反之,与相反类别的聚类中心越近,则伪标记隶属度越低.基于以上思想,提出指数形式的模糊隶属度函数:
ω1(xp)=
(1)
式中:vsi为与伪标记样本xp同类别的第i个聚类中心点,voj为与xp相反类别的第j个聚类中心点.mini(xp-vsi)T(xp-vsi)与minj(xp-voj)T(xp-voj)分别表示xp到同类、相反类最近聚类中心点间的距离.a1为常数比例因子,a1>0.式(1)中的第一种情况是xp距离同类别最近聚类较相反类最近聚类更近,即两者距离比例小于1,此时由该距离比例决定模糊隶属度.距离比例越小,模糊隶属度越大,即标记结果越可靠,反之模糊隶属度越小.另一种情况是距离比例大于1,此时xp距离最近相反类别聚类比最近同类聚类更近,此时认为xp被错误标记,将模糊隶属度置于0.
3 基于概率分布的样本标记方法
该类方法将样本所属类别的概率看作一组缺失参数,采用最大期望算法(expectation maximization,EM)对生成模型的参数进行极大似然估计.各类方法间的区别在于选择不同生成模型作为基分类器,如混合高斯模型、混合专家、朴素贝叶斯等.基于生成模型的半监督学习方法概念清晰,特别是在小样本环境下有更好的分类性能.当模型假设与数据真实分布不一致时,该方法的适用性会大幅降低.数据的真实分布很难先验得知,因此单独应用该方法往往得不到良好的性能表现.
算法采用的生成模型为高斯混合模型(Gaussian mixture model, GMM).GMM能够简单、有效地表征类内数据在特征空间中既具有分散性、又具有聚合性的分布特点.该模型由多个高斯模型构成:
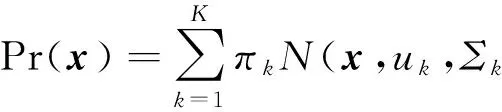
(2)
式中:N(x;uk,Σk)为高斯分布,K为GMM所包含的高斯模型组成数,πk为所对应高斯子模型的权值.当K足够大时,GMM可以逼近任意连续概率密度分布.
算法首先通过标记样本得到GMM模型,即条件概率密度函数;再按最大后验概率准则判断未标记样本的所属类别,以此完成伪标记任务.样本所属类别的后验概率能够定量地表征样本与类别之间的相关性,故将样本的后验概率定义为该标记算法的伪标记模糊隶属度:
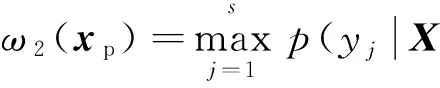
(3)
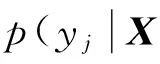
4 基于语义概念的样本标记方法
几何距离与概率分布同为描述样本的底层特征,无法表征类别所包含的高层语义.该方法通过机器学习建立语义模型,由学习所得分类器完成伪标记任务.该方法基于类别的高层语义,得到与以上方法完全独立的标记结果.
类别所隐含的语义概念需要充足的训练样本来定义.在小样本学习情况下,训练样本无法提供学习机足够的语义概念,此时学习生成的都为弱分类器.随着半监督学习的进行,更多的伪标记样本被陆续添加到训练样本集中,学习机性能将逐渐得到改善.SVM学习机因具有良好的小样本学习性能而被该方法所采用.SVM判决函数输出为样本与分类界面间的距离,该距离可以表征样本所属类别的置信度.由此,算法的模糊隶属度定义为
(4)
式中:a>0为一比例因子;γ为样本xp距离分类界面的距离,即SVM判决函数输出值.式(4)分为以下2种情况:1)样本被分类为阳性,此时γ为正值.样本离分类面越远,γ越大,该样本归属阳性类别的概率越高,对应的模糊隶属度越大.2)γ为负值,负值越小,表示样本距离分类界面越远,归属于阴性类别的概率越高,对应的模糊隶属度越大.
5 算法的具体实现
5.1 算法基本思想
采用以上3类完全差异化的标记方法得到3个完全独立的标记结果.为了确保样本标记的准确性,仅将取得一致标记结果的伪标记样本加入训练样本集.将3类模糊隶属度进行算术平均得到伪标记样本的软相关度:
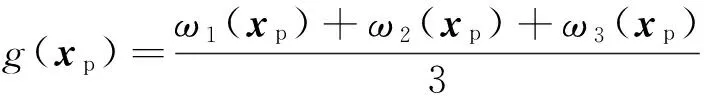
(5)
由软相关度定量地表征伪标记类别的真实性与可靠性.
该算法将伪标记样本的软相关度引入FSVM学习过程中,由软相关度决定该样本对学习机的贡献程度.软相关度反映了标记类别与真实类别间的保真度,软相关度越大,表明所属的类别越可靠,对学习机贡献的权重越大;反之,伪标记类别的可靠性低,对学习机的贡献权重越小.由此进一步减少可能引入的误标记样本对学习过程产生不利影响.算法认为原标记样本的类别有最高置信度,对应的软相关度为最高值1,对学习过程的贡献度最大.
5.2 FSVM
FSVM在SVM的基础上,考虑了不同训练样本对学习过程有不同的重要性.每个训练样本都有对应的隶属度μi∈[0,1]来表征该样本对学习机的贡献度.μi=1,意味着该样本对学习机的重要性最大;μi=0,意味着该样本的重要性最小.在两类FSVM学习情况下, 寻找最优分类面问题等价为

(6)
且满足如下约束条件:
γi(ωT·xi+b)≥1-ξi,ξi≥0,i=1,…,n.
(7)
式中:ω为分类超平面法向量,b为超平面偏移量;n为训练样本数;γi为样本xi的类别标号,γi=+1对应类别1,γi=-1对应类别2;ξi为误判松弛变量,为xi的分类误差;C为惩罚系数,控制分类间隔最大化与分类误差最小化之间的折中.由式(6)、(7)可知,FSVM是在SVM的目标函数中加入隶属度控制,软惩罚项中的ξi由μi进行加权,此时μi的大小直接增强或减弱对应样本xi在优化过程中的重要性.该算法将样本xi的软相关度作为模糊因子μi.
FSVM的优化问题可以转化为对偶问题,使如下拉格朗日函数最大化:
(8)
并满足以下约束条件:
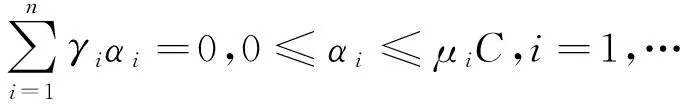
(9)
式中:αi为拉格朗日乘子,取值非零时对应样本为支持向量;K(xi,x)为核函数,常用的核函数有Gauss径向基核函数、多项式核函数、Sigmoid核函数等.
FSVM与SVM有相同的判决函数形式:
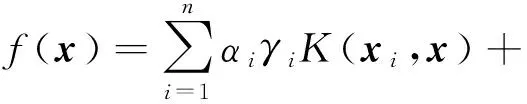

5.3 算法具体实现
混合类别标记算法的具体实现如下.
1)基于原始训练样本集进行SVM学习,得到起始的语义类别分类器.
2)选择任一未标记样本,分别采用以上3种标记方法进行类别标记.
3)当3个标记结果不一致时,将该样本丢弃,跳至2);反之跳至4).
4)分别计算该样本所对应的3种标记方法的模糊隶属度,生成软相关度.将该样本与软相关度一同加入训练样本集,并更新语义分类器.
5)若未标记样本集没有标记结束,则跳至2);否则跳至6).
6)扩展所得的新训练样本集,采用FSVM学习生成f(x).
6 实验结果与分析
针对混合类别标记(hybrid class labeling,HCL)与基于几何距离的类别标记(geometric class labeling,GCL)、基于概率模型的类别标记 (probabilistic class labeling,PCL)、基于语义概念的类别标记 (sematic class labeling,SCL)3种单一标记技术,进行详尽的性能比较.
实验采用UCI(University of California Irvine)的Breast-cancer数据集[19],具体信息如表1所示.表中,ns为样本总数,nm、nf分别为阳性样本数和阴性样本数,d为特征维数,c为类别数.数据集分为阴性(良性)、阳性(恶性)两类.表征乳腺肿块的9维特征分别为:块厚度、细胞大小均匀性、细胞形态均匀性、边缘黏附力、单上皮细胞尺寸、裸核、Bland染色质、正常核仁、核分裂.首先从阳性与阴性类中分别随机抽取n个样本构成标记样本集Ulab,在剩余样本中每类分别随机抽取50个样本构成未标记样本集Uunl.最后将剩余样本作为测试样本集Utes.为了全面地测试该算法在不同标记样本数下的性能表现,分别构建n=2、n=10与n=25三种学习环境.为了保证伪标记后训练样本集的平衡性,将同等数量的阳性与阴性伪标记样本加入训练样本集.该策略是避免由非平衡学习引起性能评价失真,更客观、真实地评价该算法对小样本学习的改善效果.上述实验重复进行10次,取10次实验结果的平均值作为最终的实验结果.该实验在Matlab环境下进行,SVM与FSVM采用高斯RBF核,参数设定为 σ=0.01、C=100.

表1 Breast-cancer测试数据集
混合类别标记与3类单一标记方法的性能对比结果如表2所示.表中,Acc为分类准确率,nmis为误标记样本数.其中SVM学习方法是基于原始训练集的小样本学习机,也是评价算法解决小样本学习有效性的基准.实验采用分类准确率评价半监督学习的性能,将伪标记过程中累积的误标记样本数用来评价标记算法的有效性.
表2中,n=2时标记样本稀缺,无法建立准确的判别模型.单一的标记方法出现较多的错误标记,SCL算法的表现尤为明显,所产生的错误标记样本最多.在引入较多噪声样本的情况下,采用单一标记技术的学习性能有不同程度的改善.原因可能是在标记样本极度稀缺的情况下,伪标记样本在带入噪声的同时也为学习机提供更充足的类别信息.HCL算法在该学习环境下表现最突出,能够显著地减少噪声的发生,学习性能大幅提升.随着标记样本数的增加,当n=10时单一标记方法产生的错误标记样本数明显减少,但学习性能只有小幅提升,其中SCL算法性能出现下降.该趋势在n=25时表现更突出,除HCL算法微幅改善学习性能之外,其余3种学习机性能都出现了不同程度的下降.这主要是由于随着标记样本数的增加,学习机得到的类别信息越来越完备.此时,正确伪标记样本为学习机提供的有用类别信息减少,而噪声样本对学习机的不利影响依然存在.当n=25时SCL的性能优于GCL与PCL,这由于在标记样本数相对充足的情况下,初始语义分类器的性能得到大幅提高.与GCL算法相比,PCL有更优的样本标记及学习性能.可能因为数据集分布不符合欧式分布,如处于类别重叠区域的未标记样本,按几何距离进行类别标记往往会得到错误的标记结果,而概率模型更适合表征样本集的分布结构.

表2 基于Breast-cancer数据集的学习性能比较
为了评测该算法对于不同实验数据集是否具有一般性,基于UCI的Diabetes数据集[19]开展上述实验.数据集的基本特性如表3所示,实验结果如表4所示.相比于Breast-cancer,Diabetes数据集的分布结构更复杂,给半监督学习提出了严峻考验.面对复杂数据集,单一标记技术的错误标记样本明显增加.除n=2的学习情况之外,单一标记算法性能都有不同程度的下降.HCL算法性能虽没有大幅提升,但始终有稳定的改善,这很好地体现了算法的“安全性”以及混合标记技术的优势.此外,GCL算法在该数据集中的表现最差,这是由于在复杂、非线性的数据分布下,几何距离无法准确地估计样本相似度.

表3 Diabetes测试数据集

表4 基于Diabetes数据集的学习性能比较
由Breast-cancer数据集的实验结果可见,3种半监督学习算法都有良好的表现.随着标记样本数的增加,半监督学习性能的提升幅度逐渐减少.在n=25的学习环境下,仅有HCL性能有所提升,MR性能相比SVM出现下降,S4VMs表现出较好的安全性,维持性能不变.综合n=25学习环境下的实验结果可得,当标记样本相对充足的情况下,利用未标记样本提高学习性能变得更加困难.样本标记的可靠性以及伪标记样本与已标记样本所提供类别信息的差异性可能是影响该学习情况下半监督学习性能的主要因素.由于Diabetes数据分布的结构复杂,准确标记样本变得更富有挑战性.3种半监督学习性能提升不显著,但表现出很好的安全性,在各类样本环境下学习性能均未降低.相比在Breast-cancer数据集中落后的性能表现,MR算法在Diabetes数据集中表现最优.这可能是由于流形学习善于获取非线性分布数据的内在结构特点,更适合于处理复杂数据集.
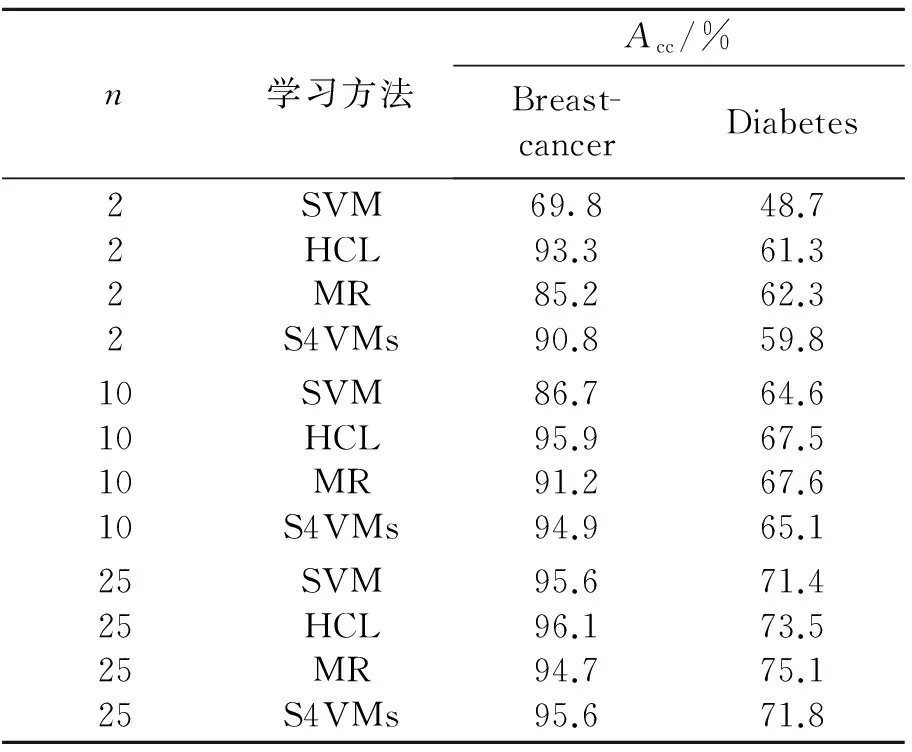
表5 HCL与先进学习算法的性能比较
综合上述实验结果,HCL算法在绝大部分实验中都有最优的分类性能,且在各种学习环境下利用未标记样本都能够改善学习性能,表现出最好的“安全性”.主要原因可能如下.
1)HCL算法通过语义概念、几何距离以及概率分布完成“安全的”伪标记任务,错误标记样本显著减少.
2)算法将有一致标记结果的伪标记样本加入训练样本集,在一定程度上保证了与标记样本在分布结构上的一致性,该类样本对学习性能有积极的改善作用.
3)在学习过程中考虑了伪标记样本的模糊隶属度,减少了噪声样本对学习机产生的不利影响.
7 结 语
数据集往往呈现出多样性的分布结构,采用单一的类别标记方法无法准确地完成伪标记任务,易引起错误标记.错误标记样本会使学习机性能显著降低,为此本文提出混合类别标记方法,从语义概念、几何聚类与概率分布的角度共同完成伪标记任务.三类完全差异化的标记结果保证了伪标记的准确性.为了进一步减少可能存在的误标记样本给学习机带来的不利影响,该算法将软相关度引入FSVM学习中,控制样本对学习机的贡献程度.实验结果表明本文算法的先进性,相比单一标记方法以及目前先进的半监督学习方法具有更优的学习性能.未来笔者一方面将会继续研究未标记样本与标记样本分布的一致性问题,提高未标记样本对小样本学习性能的改善效果;另一方面将研究在样本相对充足的情况下,如何有效地利用未标记样本进一步提高学习性能.
[1] 沈晔,李敏丹,夏顺仁.计算机辅助乳腺癌诊断中的非平衡学习技术研究[J].浙江大学学报:工学版,2013, 47(1): 1-7. SHEN Ye, LI Min-dan. XIA Shun-ren. Learning algorithm with non-balanced data for computer-aided diagnosis of breast cancer [J]. Journal of Zhejiang University: Engineering Science, 2013, 47(1): 1-7.
[2] GORGEL P, SERTBAS A, UCAN O N. Computer-aided classification of breast masses in mammogram images based on spherical wavelet transform and support vector machines[J]. EXPERT SYSTEMS, 2015, 32(1): 155-164.
[3] DHEEBA J, SELVI S T. Classification of malignant and benign microcalcification using SVM [C]∥Proceedings of ICETECT. Tamil Nadu: [s. n.], 2011: 686-690.
[4] JEYAKUMAR V, KANAGARAJ B R. A framework for medical image retrieval system using ant colony optimization and weighted relevance feedback [J]. Journal of Medical Imaging and Health Informatics, 2015, 5(7): 1383-1389.
[5] 沈晔,夏顺仁,李敏丹. 基于内容的医学图像检索中的相关反馈技术[J].中国生物医工程学报,2009, 28(1): 128-136. SHEN Ye, XIA Shun-ren, LI Min-dan. A survey on relevance feedback techniques in content-based medical image retrieval [J]. Chinese Journal of Biomedical Engineering, 2009, 28(1): 128-136.
[6]WU K, YAP K H. Fuzzy SVM for content-based image retrieval: a pseudo-label support vector machine framework [J]. IEEE Computational Intelligence Magazine, 2006, 1(2): 10-16.
[7]ZHOU D, BOUSQUET O, LAL T N, et al. Learning with local and global consistency [C] ∥Proceedings of NIPS. Whistler: [s. n.], 2003: 321-328.
[8]WANG Fei, ZHANG Chang-shui. Label propagation through linear neighborhoods [J]. IEEE Transactions on Knowledge and Data Engineering, 2008, 20(1): 55-66.
[9]TU E,YANG J,KASABOV N,et al. Posterior distribution learning (PDL): a novel supervised learning framework using unlabeled samples to improve classification performance [J]. Neurocomputing, 2015, 157: 173-186.
[10]ZHOU Zhi-hua, LI Ming. Tri-training: exploiting unlabeled data using three classifier [J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 117(11): 1529-1541.
[11] LI Ming, ZHOU Zhi-hua. Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples [J]. IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, 2007, 37(6): 1088-1098.
[12] KIM J, SHIN H. Breast cancer survivability prediction using labeled, unlabeled, and pseudo-labeled patient data [J]. Journal of the American Medical Informatics Association, 2013, 20(4): 613-618.
[13]ZHOU Zhi-hua, CHEN Ke-jia, DAI Hong-bin. Enhancing relevance feedback in image retrieval using unlabeled data [J]. ACM Transactions on Information Systems, 2006, 24(2): 219-244.
[14]CHEN K,WANG S H. Semi-supervised learning via regularized boosting working on multiple semi-supervised assumptions [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(1): 129-143.
[15]LE T B, KIM S W. Modified criterion to select useful unlabeled data for improving semi-supervised support vector machines [J]. Pattern Recognition Letters,2015, 60-61: 48-56.
[16]LI Yu-feng, ZHOU Zhi-hua. Towards making unlabeled data never hurt [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(1): 175-188.
[17] MALLAPRAGADA P K, JIN R, JAIN A K, et al. SemiBoost: boosting for semi-supervised learning [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(11): 2000-2014.
[18] JAVED K, GOURIVEAU R, ZERHOUNI N. A new multivariate approach for prognostics based on extreme learning machine and fuzzy clustering [J].IEEE Transactions on Cybernetics, 2015, 45(12): 26-39.
[19]LICHMAN M. Machine learning repository [DB/OL]. 2013-04-04. http:∥archive.ics.uci.edu/ml/datasets.html.
[20]NIE Fei-ping, XU Dong, LI Xue-long, et al. Semisupervised dimensionality reduction and classification through virtual label regression [J].IEEE Transactions on Systems, Man, and Cybernetics, Part B: Cybernetics, 2011, 41(3): 675-685.
Small sample learning algorithm based on novel hybrid class-labeling technique
LI Min-dan, SHEN Ye, ZHANG Dong-ping, YIN Hai-bing
(DepartmentofSignalandInformationProcessing,ChinaJiliangUniversity,Hangzhou310018,China)
A small sample learning algorithm based on a novel hybrid class-labeling technique (HCLT) was proposed in order to address the learning problem resulting from the underrepresented labeled training set in computer-aided diagnosis(CAD). The abundant unlabeled samples were labeled by HCLT with three diverse class labeling schemes respectively from the view point of geometric similarity, probabilistic distribution and semantic concept. Only those unlabeled samples which get the unanimous labeling results from three different labeling schemes were added to the training set in order to enlarge the labeled training set. The memberships of pseudo-labeled samples were introduced to fuzzy support vector machine (FSVM) in order to reduce the adverse effects for learning performance resulting from the still existing labeling mistakes. The contributions of pseudo-labeled samples to learning task were determined by their memberships. Classification experiment results based on datasets in UCI show that the proposed algorithm can deal with the small sample learning problem. The algorithm has less mistakes and better classification performance compared with the other algorithms which adopt the single labeling scheme.
computer-aided diagnosis (CAD); small sample learning; hybrid class-labeling; membership
2015-06-23. 浙江大学学报(工学版)网址: www.journals.zju.edu.cn/eng
浙江省自然科学基金资助项目(LY13H180011);浙江省自然科学基金资助项目(LY15F020021).
李敏丹(1976-), 女, 讲师, 从事机器学习技术的研究. ORCID: 0000-0002-3737-3164. E-mail: limindan@cjlu.edu.cn 通信联系人:沈晔, 男, 副教授. ORCID: 0000-0001-9581-8734. E-mail: shenye1978@vip.sina.com
10.3785/j.issn.1008-973X.2016.01.020
TP 391
A
1008-973X(2016)01-0137-07
