一种基于兴趣点分布的匿名框KNN查询方法
2016-12-08朱顺痣周长利
朱顺痣,黄 亮,周长利,马 樱
(1.厦门理工学院计算机与信息工程学院,福建厦门 361024;2.国家计算机网络应急技术处理协调中心,北京 100029;3.华侨大学计算机科学与技术学院,福建厦门 361021)
一种基于兴趣点分布的匿名框KNN查询方法
朱顺痣1,黄 亮2,周长利3,马 樱1
(1.厦门理工学院计算机与信息工程学院,福建厦门 361024;2.国家计算机网络应急技术处理协调中心,北京 100029;3.华侨大学计算机科学与技术学院,福建厦门 361021)
针对利用匿名框实现的兴趣点K近邻(KNN)查询带来的通信开销大、时延长等问题,提出了基于单一兴趣点Voronoi图划分和四叉树层次化组织的KNN查询方法.该方法根据兴趣点层次信息有针对性的构造查询匿名框用来获取详细查询信息,在保护位置隐私的同时,降低了查询通信开销,同时注入虚假查询保护了用户的真实查询内容隐私.最后分别采用模拟地理数据和真实地理数据进行理论分析和有效性验证.
位置隐私;基于位置的服务;匿名框;K近邻查询
1 引言
基于位置的服务(Location-Based Service,LBS)推动了移动智能终端各类型应用的快速发展.基于位置的查询服务是目前广泛被用户使用的服务类型之一,用户利用携带的智能终端获取所需的查询服务,典型的两种查询方式分别为K近邻(KNearest Neighbor,KNN)查询和R范围查询[1~3].然而,用户获取查询结果前必须提供自身位置信息,位置越精确查询结果质量越高,但用户的隐私也越容易暴露.移动用户隐私可以分为位置隐私和查询内容隐私两类[4~8],在查询过程中,理想查询状态是既不让其它任何实体知道其所在位置,也不让其它实体知道他的查询内容.位置k匿名[9~13]是实现位置隐私保护的有效方法之一,该方法构造包含k个不同用户位置的匿名框,用匿名框代替全部用户实际位置发起查询.对于查询内容隐私,用户利用匿名框查询时也需保证查询请求内容不少于l种[14],避免查询内容隐私直接泄露给如LBS服务器等其它实体.
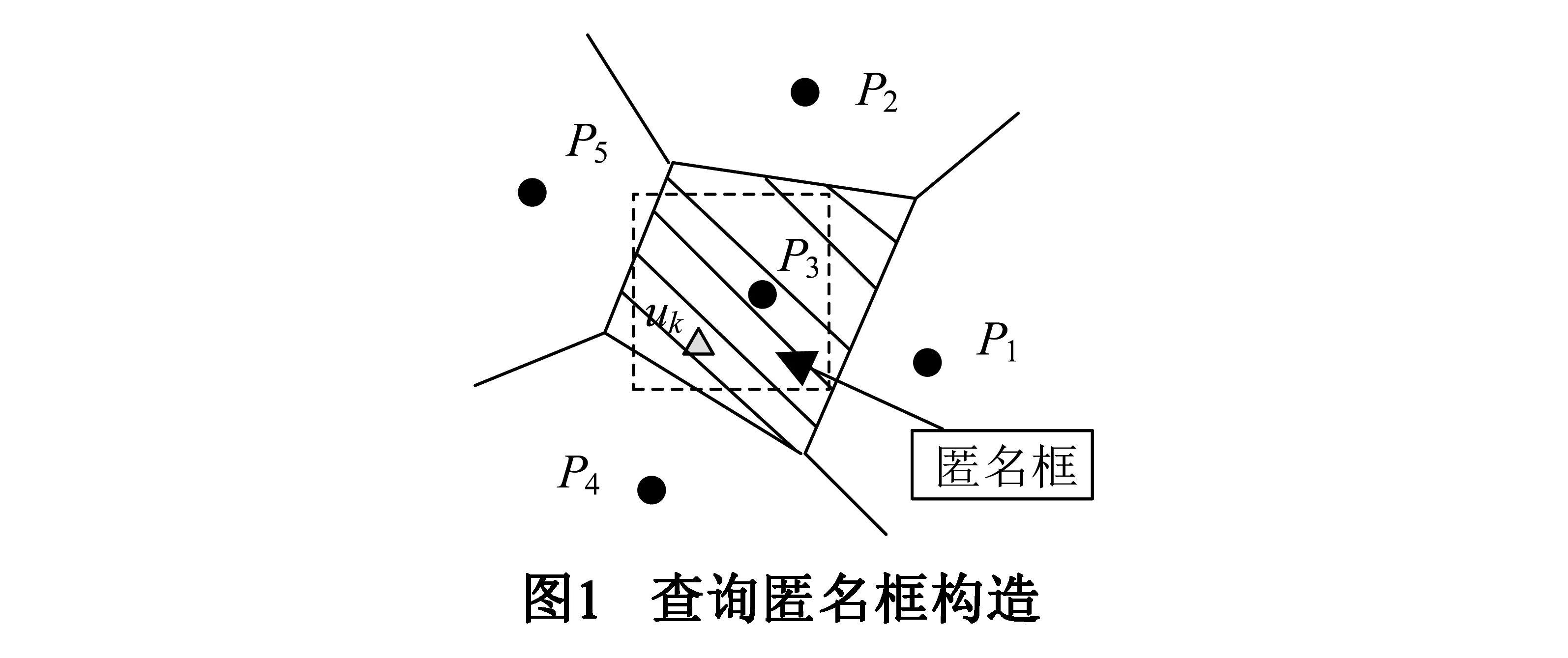
然而,匿名框查询需要返回匿名框内及其周围的多个兴趣点作为候选集合供用户选择,这会增大数据通信开销.这是因为上述传统的构造匿名框查询方法并没有考虑兴趣点的分布情况.如图1所示,用户构造了一个1NN查询匿名框(虚线矩形框),根据该匿名框LBS返回给用户uk的兴趣点不仅包括P3,还有P1、P2、P4和P5,这些兴趣点都可能是用户查询的目标.
Voronoi图[15]是一种平面空间目标点之间的中垂线分割方法,如图1实线划分所示,利用该图可以表示空间目标位置远近关系.位于兴趣点P3划分单元(实线凸多边形)内的用户uk一定距离P3最近.因此,在上述1NN查询中,如果用户知道兴趣点的Voronoi划分情况,则将目标兴趣点P3置于匿名框内,并要求LBS服务器只查询返回匿名框内兴趣点描述信息,因此无需返回传统匿名框查询要返回的其他兴趣点P1、P2、P4和P5的描述信息.
文献[16]提出了能够解决上述问题的一种方案2PASS,然而该方法在扩展到KNN查询过程中,由于将同一地图中多类不同兴趣点共同进行Voronoi图划分,使得用户需要对比更多的其他类型兴趣点来找到最近的K个目标兴趣点.因此,本文提出单一兴趣点Voronoi划分方法,并利用四叉树组织该图,便于用户快速找到KNN目标兴趣点并构造查询匿名框,该方法能够在降低通信开销的同时,保护用户位置隐私和查询内容隐私.
另一方面,用户在提交查询请求时为了保证身份信息与位置隐私的不可关联,通常使用假名来替代用户真实身份.史敏仪等[17]针对文献[18]中存在的假名失效的缺陷提出了敏感区域移动用户的位置隐私保护方法.Palanisamy B[19]和Freudiger J[20]分别针对文献[18]中存在的缺陷提出了相应的假名使用方法.Mano[21]等提出了一种动态假名更换方案,用来保护移动用户的轨迹隐私.Yu等[22]提出了一种扩展假名更换区域MixGroup,显著提高了假名在保护用户位置隐私时的效能.Lin[23]在其著作中详细论述了基于密码技术的假名更换方法,用以有效保护用户位置隐私.
2 预备知识
给定n个兴趣点,可以利用Voronoi图将其划分成n个单元,邻近单元间没有重叠区域,位于划分单元内的用户与该兴趣点位置最近.如图2所示,我们给每个顶点Pi赋予权值(Li,Ci),Li代表位置坐标,Ci代表兴趣点的类型,如医院、加油站等.

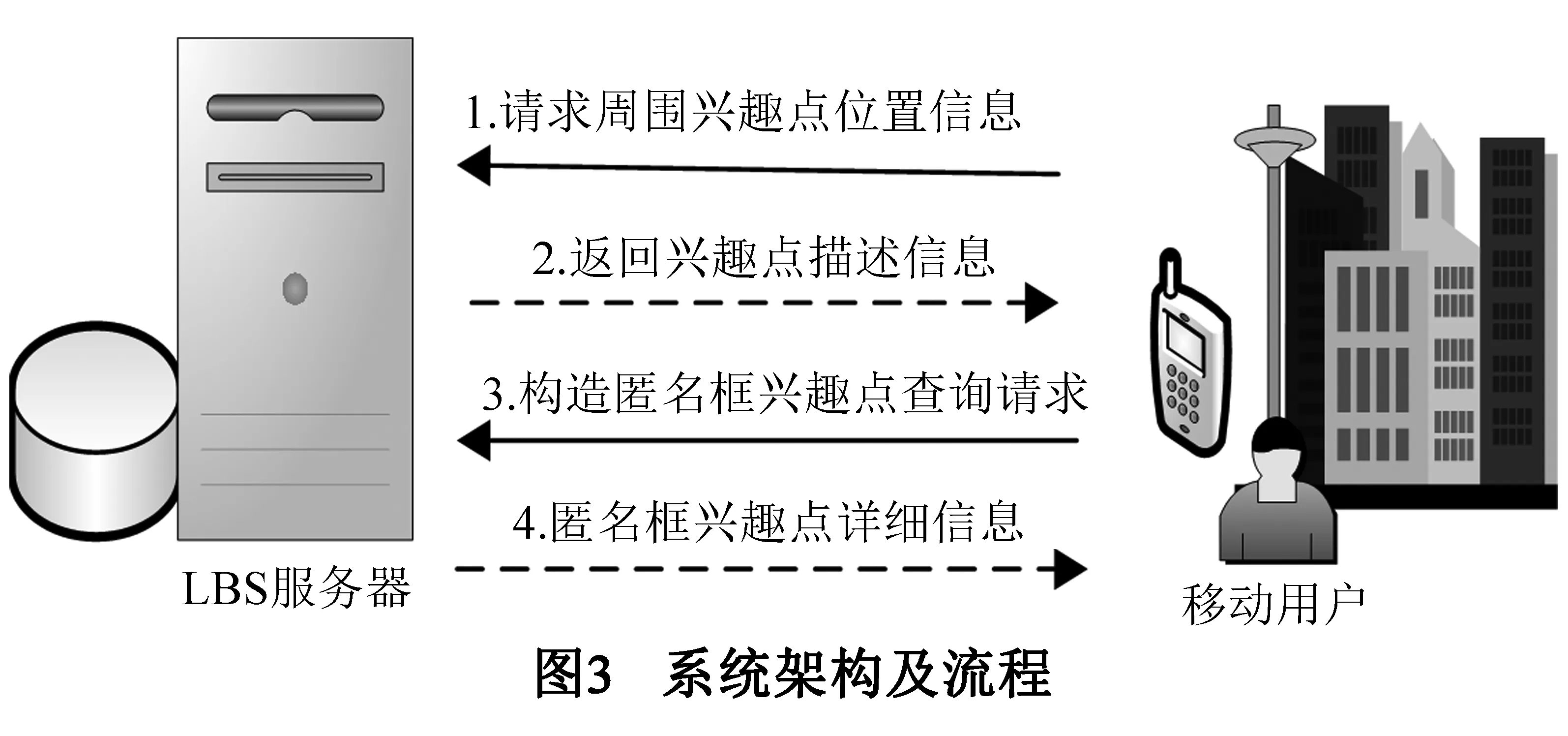
本文方法采用“用户-服务器”架构[20],该架构用户获取LBS服务流程如图3所示的四步.
如图3所示,用户首先请求轻量化兴趣点分布信息,然后根据返回的信息构造合适的匿名框,将要查询的目标兴趣点包含在匿名框内发起查询请求.用户通过第3步控制匿名框内兴趣点数量,从而控制第4步返回消息数量.
3 兴趣点KNN查询
对于兴趣点的1NN查询,用户只需要根据兴趣点分布信息即可快速构建匿名框,然而对于兴趣点的KNN查询则用户需要比对较多的其他兴趣点,K值越大比对的额外兴趣点数量就会越多.解决该问题的方法就是构造同类兴趣点Voronoi图划分,并组织成轻量化、层次化的结构发送给用户,便于用户快速查找到K个目标兴趣点及其分布情况,这个工作是由LBS服务器来完成的.
3.1 四叉索引树
对地理区域进行网格划分是描述兴趣点位置的有效方法之一,其中金字塔形的组织形式能够体现平面空间区域间的层次化结构[24].如图4所示,从全局地图出发,将地理空间每次划分成四个网格,如此迭代划分下去得到4h-1个网格(h是划分深度),直至满足一定的粒度,并建立层次化索引表.图4在全局地图上将同类兴趣点(如加油站)利用Voronoi图划分为4×4网格.

由此,每个兴趣点唯一属于一个网格,在网格划分粒度不同时,一个网格可能会包含多个兴趣点.通常情况下,在粒度较小时每个兴趣点的划分单元可能覆盖多个网格,这意味着处于不同网格内的用户,可能处于同一个Voronoi划分单元内,即在不同网格内的用户可能距离同一个兴趣点最近.
这样,每个网格都可以用和该网格有重叠部分的Voronoi划分单元来表示,以便处于该网格的用户能够知道距离自己最近的兴趣点是哪个.
由此,以金字塔形状组织的兴趣点可以表示成是一个四叉树型的索引结构,每层网格以顺时针方向为编号顺序,如图5描述了图4的四叉树结构,树的叶子结点就是最底层网格,每个底层网格用与之有重叠区域的Voronoi划分单元的兴趣点来描述,便于处在该网格内用户掌握兴趣点分布情况后构造查询匿名框.上述每类兴趣点四叉索引树可以用TreeCi表示,其中Ci表示兴趣点类型.
每一层的每个网格都用其左上角坐标(xlt,ylt)和右下角坐标(xrb,yrb)表示,用户确定自己所在最底层网格(即所在叶子结点),则执行如下算法1,搜索四叉树.
算法1 用户所在结点查询算法(用户端)
输入:以Ti为根结点的地图四叉树TreeCi,用户位置坐标locuk,叶子结点网格面积Sleaf
输出:四叉树TreeCi的某个结点ni
1. Procedure begins:
2. 获取根结点T的每个孩子结点ni
3. if孩子结点ni的面积>Sleafthen
4. for每个孩子结点ti∈Tdo
5. 由孩子结点范围坐标(xlt,ylt)和(xrb,yrb)找到locuk所在网格及表示该网格的结点ni
6. TreeCi←ni为根结点的子树
7. 调用算法1,参数为(TreeCi,locuk,Sleaf)
8. returnni
9. End Procedure
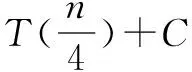
3.2KNN查询流程
对于每一类兴趣点,LBS服务器都为之构造一个上一小节描述的兴趣点分布四叉索引树,用户在第1步请求周围兴趣点分布信息时,在真实目标兴趣点请求中注入虚假兴趣点查询请求,比如用户目标兴趣点是查询周围最近的K个加油站,同时注入餐厅、医院兴趣点分布情况查询作为虚假请求.表1详细说明了图3中KNN查询完整流程.请求格式为(uk1‖CT‖sigkeyu(CT)‖Ekeylbs(Quk)),其中uk1是用户的一个假名,CT为当前时间,sigkeyu(CT)表示用户利用私钥keyu做的签名,以便LBS服务器来验证其合法性,Ekeylbs(Quk)表示用户以LBS服务器的公钥keylbs加密查询请求Quk发送给LBS服务器,Quk=(C1,C2,…,C3)主要为查询兴趣点类型Ci,Quk中有一个是用户真正要查询的目标兴趣点.
LBS收到用户请求后,验证签名sigkeyu(CT)的合法性,据此解密出查询请求Quk,并返回Quk中所有兴趣点类型Ci的四叉索引树,返回信息可表示为(LBSid‖TreeC1,TreeC2,…,TreeCn),其中TreeCi为用户目标兴趣点的四叉索引树.
用户根据LBS服务器返回信息,找到自己目标兴趣点的四叉索引树TreeCi,执行算法1逐层搜索直至找到自己所在的网格,即叶子结点,根据叶子结点中存储的兴趣点权值Pi:(Li,Ci)信息找到距离自己最近的兴趣点Pk,并以此为出发点根据3.3小节中定义1和定理1,找到距离Pk最近的其他K-1个兴趣点,并构造包含这K个兴趣点的匿名框.

表1 KNN查询流程表
用户根据算法1返回的用户所在网格结点ni来构造匿名框,算法如算法2所示.
算法2K近邻兴趣点查找及匿名框生成算法(用户端)
输入:算法1返回的用户所在网格结点ni,KNN查询请求
输出:包含K个目标兴趣点在内的匿名框CRuk
1. Procedure begins:
2. for 每个Pi∈nido //依据图7找到ni内兴趣点
3. Array1←计算dist(uk,Pi)
4.p←min{Array} //用户在最近Pi的划分单元内
5. heap←AN1(p)// 参见定义1; 小顶堆heap
6. Array2←AN1(p)
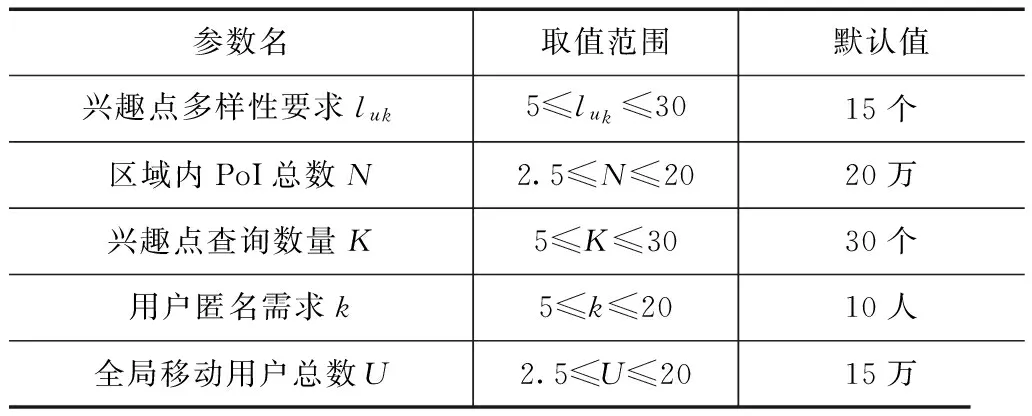
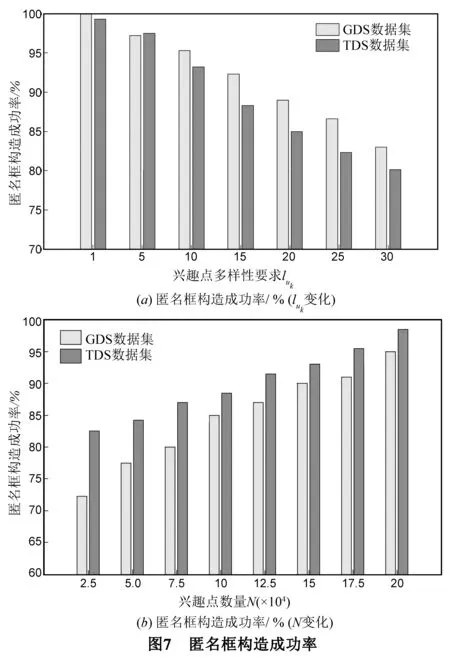
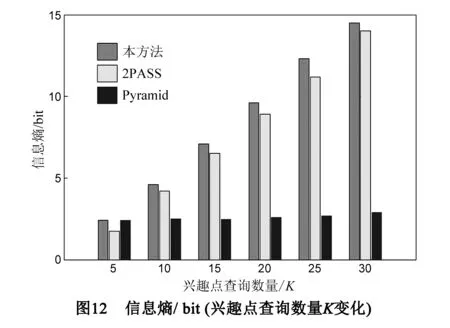
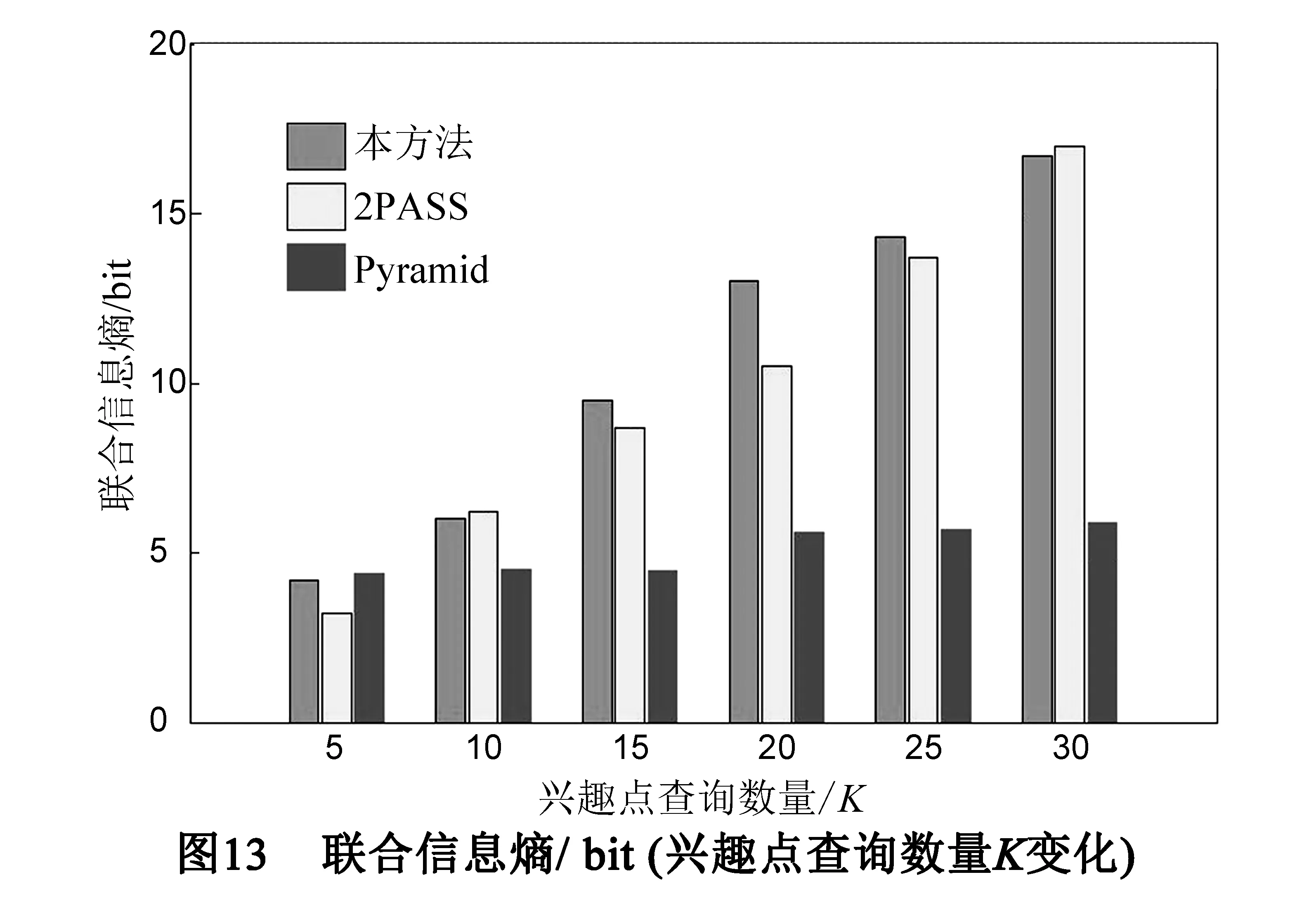
7. if |heap| 8. Array3←Array2 9. for 每个Pj∈Array3 do //下一阶兴趣点 10. heap←AN1(Pj) 11. Array4←AN1(Pj) 12. 清空Array2 //保存新找到的下一阶兴趣点 13. Array2←Array4 14. neighbor←在heap中找到前K个兴趣点 15. 构造包含neighbor中全部兴趣点位置的矩形匿名框CRuk 16. returnCRuk 17. End Procedure 算法2的主要思想是以用户所在Voronoi图划分单元的兴趣点为起始点逐阶搜索下一级兴趣点,直至找到距离用户最近的K个兴趣点.图4中的虚线框为根据算法2构造的5NN匿名框.用户在提交查询时,不仅给出要查询的匿名框内目标兴趣点,同时还要求返回几类虚假查询兴趣点的描述信息,保护用户查询内容隐私.在算法2的执行过程中,执行频度最高的语句为第3、10和11行,其时间复杂度为O(n).显然,空间复杂度也取决于问题规模n,为O(n). 3.3 性能分析 (1)查询准确性 用户根据自身位置确定所在网格(即算法1),然后根据所在网格找到所在兴趣点Voronoi图划分单元(即找到距离自己最近的兴趣点),并由此划分单元逐步扩展到邻近划分单元确定最近的K个兴趣点(即算法2)的过程中,需要保证两个算法的正确性. 首先,在算法1中,用户根据图5 的LBS服务器返回的网格划分信息及轻量兴趣点分布信息,结合自身位置不断缩小自己所在网格,直到满足阈值Sleaf要求.由于在该过程中,用户通过某一四叉树的每个网格左上角坐标(xlt,ylt)和右下角坐标(xrb,yrb)运算,算法1第5行可以精确计算出用户所在四个网格中的一个,然后以该网格为出发点迭代继续确定所在下一级网格,此过程相对简单. 然后,在算法2中,用户根据图5所示的网格和兴趣点Voronoi图层叠关系找到所在网格ni中的所有兴趣点,确定距离自己最近的目标兴趣点,并以此兴趣点为生成元的Voronoi图划分单元V(Pi)为出发点,找到其他K-1个目标兴趣点.在此过程中用户根据如下定义1和定理1可以确定周围1阶邻近兴趣点集合,如果不足K个,则在2阶邻近兴趣点集合继续找,直到找到K个兴趣点. 定义1 一般地,给定Voronoi图内任意兴趣点Pi,如果其1阶近邻兴趣点集合可以表示为:AN1(Pi)={Pk|V(Pi)与V(Pk)有公共边},那么Pi的n(n≥2)阶近邻兴趣点集为:ANn(Pi)={Pk|V(Pj)与V(Pk)有公共边,Pj∈ANn-1(Pi)}. 定理1[25]Voronoi图内任意划分单元V(Pi)内任意点q的第K个近邻兴趣点一定包含在集合AN1(Pi)∪AN1(Pi)∪…∪ANk-1(Pi)中. 定理2[25]Voronoi图内,每个划分单元平均有6个1阶邻近划分单元. 这个过程还存在一个问题,根据定理1,用户在找K个兴趣点的过程中,需要把V(Pi)的K阶邻近兴趣点都找到(算法2第5~14行),这会带来一定时延.通常情况下,由于多数用户设置KNN兴趣点查询时,K通常取值为1~30,由定理2可知,当V(Pi)的邻近单元及下一阶邻近单元数均约为6个时,则满足6n≥30的最小正整数n为2,即查找用户最近的K个目标兴趣点,最少可在其所在划分单元V(Pi)的2阶近邻兴趣点集合中找到. 综上,用户在可以根据算法1和算法2确定自己所在网格和所在兴趣点划分单元,并在下限值为2阶的邻近划分单元中找到K个目标兴趣点,由于是逐层搜索邻近兴趣点,因此可以在保证较少通信量的同时获得正确的K个兴趣点查询结果.然后构造包含这K个兴趣点的匿名框,发送给LBS服务器,LBS服务器返回匿名框中兴趣点的详细描述信息,因此查询是有目标的,有效降低通信量. (2)隐私安全性 和传统匿名框方法实现的k匿名性不同,本方法用户不必考虑匿名框中用户数量.这是因为用户在构造匿名框时,可能不在匿名框内.当K=3时,图6中的虚线匿名框可能是处于匿名框外用户uk构造的,因为匿名框只需覆盖距离P5最近的其他2个兴趣点P1、P3即可,不必考虑用户位置. 因此本方法的k匿名性取决于匿名框覆盖目标兴趣点Voronoi图划分单元内的用户数量,假设在没有注入虚假查询的情况下,则查询Qi来自该匿名框覆盖CRk的某个划分单元V(Pi)∈CRk的概率可以表示为pQi→V(Pi),则构造该匿名框发起一次查询Qi的信息熵可以用式(1)表示: (1) 则处于划分单元V(Pi)内的用户uk∈V(Pi)是提出该KNN查询Qi的用户的联合信息熵可以用式(2)表示: (2) 在现有文献中通常认为背景知识包括用户分布情况、用户提交的兴趣点查询请求集合及各类兴趣点四叉索引树.由式(1)和(2)可知,即使攻击者在掌握一定的背景知识情况下,能够根据构造的匿名框推断出用户真实查询内容,也很难将查询内容对应到划分单元内某个具体用户身份上. 本实验在Windows 7 平台采用JAVA语言实现上述算法,硬件环境为3.2GHz Intel Core i5处理器,内存大小为4GB.实验地图采用美国地名委员会提供的地理数据集GDS*http://geonames.usgs.gov/index.html,同时采用Thomas Brinkhoff路网移动节点数据生成器生成的模拟数据集TBS*http://iapg.jade-hs.de/personen/brinkhoff/generator/,数据集中包含15万条路网环境下的用户轨迹数据,用户均匀分布在每条路网上,每个用户的起点和终点均随机选取,行进速度受路段限制.LBS服务器与用户采用3G网络通信带宽为2Mbps,实际每次返回单个数据包为128字节,若每个兴趣点信息占用8个字节,除去40字节的包头,每个数据包包含兴趣点个数为 (128-40)/8=11个.当某一实验参数变化时,其他参数配置均采用默认值配置.本实验参数取值范围及默认值如表2所示. 表2 实验默认参数配置 4.1 匿名框构造成功率 本文首先考察匿名框构造成功率,即成功构造匿名框用户数量与用户总数量之比.本文考察两个参数对匿名框构造成功率的影响:兴趣点多样性luk和区域内PoI总数N. 如图7(a)~(b)所示,当用户为提高查询内容隐私保护强度而使兴趣点多样性参数luk不断增大时,匿名框需要覆盖更多类型的兴趣点,因此匿名框构造成功率随之降低,但成功率通常维持在80%以上,而luk越大,用户查询内容隐私保护效果越好.因此用户在提出较高查询内容隐私保护强度时,本方法能够保证较高的匿名框构造成功率. 同理,当区域内兴趣点分布较为密集时,用户更容易构造满足兴趣点多样性需求的匿名框.因此,当区域内兴趣点数量N不断增加时,匿名成功率不断提高,而TDS数据集的成功率总是高于GDS数据集,这是由于GDS数据集兴趣点分布不均匀,使得用户在特定区域内兴趣点类型不足造成的. 同时,匿名框构造成功率直接影响查询效率,这是由于LBS服务器需要根据用户提交的匿名框为用户查询目标兴趣点的详细信息,本文所提出的两个客户端算法能否正确、快速运行是快速构造高质量匿名框的关键.通过实验我们可以看出,匿名框构造成功率较高,在LBS服务器根据匿名框返回查询结果平均时间相同的情况下,本方法的查询效率同样较高. 4.2 平均数据通信量 数据通信量是指LBS返回查询结果的信息量,本节将本文所提出的方法与LBS中的隐私保护经典方法数据通信量进行比较.如图8(a)~(b)所示.当兴趣点多样性luk要求增大时,Pyramid方法[24]和P2P方法[26]都需要找到更多的兴趣点,并且由于没有考虑兴趣点的分布情况,查询过程中返回的兴趣点是盲目的,因此带来了通信数据包量较高.本方法在考虑了兴趣点分布情况后,使得查询目的性更强,虽然通信量也随着luk增长而增高,但本方法通信量明显低于传统方法. 同理,当用户数量快速增加时,传统方法数据通信量在数量增加后期快速增长,而本方法的平均数据通信量变化并不明显,其原因是本方法返回的兴趣点描述信息是固定的,数据通信量主要由定义的luk和K影响.此外,我们还对比了类似方法2PASS[16],如图9所示,本方法与其取得了类似的通信量变化,比2PASS方法稍低,这是由于本方法采用单一兴趣点Voronoi图构造方法,匿名框中虚假查询兴趣点类型用户数是可以掌控的,使通信量相对较低. 4.3 查询准确性 如前3.3小节所述,由于用户的算法1和算法2的查找方式为基于Voronoi图划分单元的逐层递进查找,当用户查找K近邻兴趣点时,最大会查找某个划分单元的K阶邻近单元,这会带来通信量的极大上升,进而使有效时间内获取的准确查询结果数量下降.但通过分析可以发现,由于Voronoi图的邻近单元平均数量特点,使得在实际查找近邻兴趣点过程中通常可以不超过2阶近邻单元就可以找到K个目标兴趣点. 如图10所示,当K值不断增大时,表明用户需要一次找到更多的邻近兴趣点,不同数量用户分布在地图空间时,查询的准确率并没有明显的下降,而是稳定在80%以上,这表明在K值不断增大的查询过程中,所有查询均没有查找K阶邻近单元,而是在2阶邻近单元内找到了K个目标兴趣点,从而使有效时间内的查询准确率保持稳定,符合分析的结果. 通过类似方法,我们将本文所提出的方法与经典方法2PASS、新近提出的类似查询方法KAWCR[27]和Singoes[28]进行了比较,如图11所示,发现本文方法具有同等较高的查询准确率,且略高于经典算法2PASS. 4.4 隐私安全性 信息熵是离散事件集合的平均信息量,通常,处在划分单元V(Pi)内的用户,当构造K=3的匿名框发起查询时,如图6所示,由划分单元面积占总面积的比计算可得,真实发起查询的用户处于匿名框P1,P3,P5的概率分别约为0.4,0.3,0.3,则由式(1)计算可知其信息熵值约为H(Qi)=H(0.4,0.3,0.3)≈1.57bit,由此进一步可知,当用户查询的兴趣点数量K增大时,其信息熵的变化如图12所示. 由图12可知,本方法构造匿名框查询的信息熵随用户查询兴趣点数量增大而稳步增大,攻击者对于匿名框查询的不确定性随之升高,隐私保护效果越好.导致信息熵升高的主要原因是,当K增大时,匿名框需要覆盖的划分单元数量增多,因此离散事件数量增大,并且更为重要的是,每个离散事件的概率分布相对均匀,使得攻击者的不确定性不断增加.而传统构造匿名框的方法Pyramid其信息熵基本保持稳定,这是由于该方法未考虑兴趣点分布,只构造包含用户在内的匿名框造成的. 联合信息熵是攻击者确定处于某个划分单元内的用户可能性的度量.由3.3节隐私安全性分析可知,从攻击者角度看,要进一步确定某个单元内用户是否为真实发起查询的用户,其联合信息熵值会进一步增加.这是由于处于某个划分单元内的用户有多个,因此进一步增大了攻击者的不确定性,使隐私保护性能更好.如图13所示:本方法联合信息熵值随兴趣点查询数量增加而稳步增加,符合性能分析的结果;Pyramid的联合信息熵也略有增加,但是在K增长过程中依然保持稳定,是此类方法没有考虑兴趣点分布所造成的缺陷. 为了提高KNN兴趣点查询效率,本文提出单一兴趣点Voronoi图划分方法,该方法首先将同类兴趣点划分成Voronoi单元,然后利用四叉树进行层次化组织,当用户需要该信息时,将层次化信息发送给用户,以便用户快速找到KNN兴趣点并构造匿名框.最终,用户向LBS服务器提交匿名框,并只返回匿名框内几类兴趣点详细描述信息.该方法一方面能够有效降低兴趣点返回数据包量、提高匿名框构造速度,同时能够保护用户的位置隐私和查询内容隐私,性能分析和对比实验表明,本方法具有良好的工作效率. [1]Palanisamy B,Liu L,Lee K,et al.Anonymizing continuous queries with delay-tolerant mix-zones over road networks[J].Distributed and Parallel Databases,2014,32(1):91-118. [2]周傲英,杨彬,金澈清,等.基于位置的服务:架构与进展[J].计算机学报,2011,34(7):1155-1171. Zhou Aoying,Yang Bin,Jin Cheqing,et al.Location-based services:Architecture and progress[J].Chinese Journal of Computers,2011,34(7):1155-1171.(in Chinese) [3]Ghinita G.Privacy for location-based services[J].Synthesis Lectures on Information Security,Privacy,& Trust,2013,4(1):1-85. [4]叶阿勇,林少聪,马建峰,等.一种主动扩散式的位置隐私保护方法[J].电子学报,2015,43(7):1362-1368. Ye Ayong,Lin Shaocong,Ma Jianfeng,et al.An active diffusion based location privacy protection method[J].Acta Electronica Sinica,2015,43(7):1362-1368.(in Chinese) [5]潘晓,郝兴,孟小峰.基于位置服务中的连续查询隐私保护研究[J].计算机研究与发展,2010,47(1):121-129. Pan Xiao,Hao Xing,Meng Xiaofeng.Privacy preserving towards continuous query in location-based services[J].Journal of Computer Research and Development,2010,47(1):121-129.(in Chinese) [6]刘华玲,郑建国,孙辞海.基于贪心扰动的社交网络隐私保护研究[J].电子学报,2013,41(8):1586-1591. Liu Hualing,Zheng Jianguo,Sun Cihai.Privacy preserving in social networks based on greedy perturbation[J].Acta Electronica Sinica,2013,41(8):1586-1591.(in Chinese) [7]唐科萍,许方恒,沈才樑,等.基于位置服务的研究综述[J].计算机应用研究,2012,29(12):4432-4436. Tang Keping,Xu Fangheng,Shen Caiheng,et al.Survey on location based service[J].Application Research on Computer,2012,29(12):4432-4436.(in Chinese) [8]陈丹伟,邵菊,樊晓唯,等.基于MAH-ABE的云计算隐私保护访问控制[J].电子学报,2014,42(4):821-827. Chen Danwei,Shao Ju,Fan Xiaowei,et al.MAH-ABE based privacy access control in cloud computing[J].Acta Electronica Sinica,2014,42(4):821-827.(in Chinese) [9]Hashem T,Kulik L,Zhang R.Countering overlapping rectangle privacy attack for moving kNN queries[J].Information Systems,2013,38(3):430-453. [10]Ngo C N,Dang T K.On efficient processing of complicated cloaked region for location privacy aware nearest-neighbor queries[A].Proceedings of Information and Communication Technology[C].Berlin Heidelberg:Springer,2013.101-110. [11]Chow C Y,Mokbel M F,Liu X.Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments[J].GeoInformatica,2011,15(2):351-380. [12]王丽娜,彭瑞卿,赵雨辰,等.个人移动数据收集中的多维轨迹匿名方法[J].电子学报,2013,41(8):1653-1659. Wang Lina,Peng Ruiqing,Zhao Yuchen,et al.Multi-dimensional trajectory anonymity in collecting personal mobility data[J].Acta Electronica Sinica,2013,41(8):1653-1659.(in Chinese) [13]徐建,徐明,林欣,等.路网限制环境中基于匿名蜂窝的位置隐私保护[J].浙江大学学报(工学版),2011,45(3):429-439. Xu Jian,Xu Ming,Lin Xin,et al.Location privacy protection through anonymous cells in road network[J].Journal of Zhejiang University (Engineering Science),2011,34(5):865-878.(in Chinese) [14]Pingley A,Zhang N,Fu X,et al.Protection of query privacy for continuous location based services[A].Proceedings of IEEE INFOCOM[C].USA:IEEE PRESS,2011.1710-1718. [15]朱良,孙未未,荆一楠,等.基于Voronoi图的路网k聚集最近邻居节点查询方法[J].计算机研究与发展,2011,48(z2):533-540. Zhu Liang,Jing Yinan,Sun Weiwei,et al.Voronoi-based aggregate nearest neighbor query processing in road networks[J].Journal of Computer Research and Development,2011,48(z2):533-540.(in Chinese) [16]Hu H,Xu J.2PASS:Bandwidth-optimized location cloaking for anonymous location-based services[J].IEEE Transactions on Parallel and Distributed Systems,2010,21(10):1458-1472. [17]史敏仪,李玲娟.移动用户位置隐私保护方案研究[J].计算机技术与发展,2014,51(10):151-154. Shi Minyi,Li Lingjuan.Study on location privacy protection scheme for moving objects[J].Computer Technology and Development,2014,51(10):151-154.(in Chinese) [18]Huang Leping,Yamane L,Mastsuura K,et al.Silent cascade:enhancing location privacy without communication QoS degradation[A].Proceedings of the 3rd International Conference on Security in Pervasive Computing[C].Berlin Heidelberg:Springer,2006.165-180. [19]Palanisamy B,Liu L.Mobimix:Protecting location privacy with mix-zones over road networks[A].Proceeding of IEEE 27th International Conference on Data Engineering(ICDE)[C].Hannover:IEEE PRESS,2011.494-505. [20]Freudiger J,Shokri R,Hubaux J P.On the optimal placement of mix zones[A].Privacy Enhancing Technologies[C].Berlin Heidelberg:Springer,2009.216-234. [21]Mano K,Minami K,Maruyama H.Privacy-preserving publishing of pseudonym-based trajectory location data set[A].The Eighth International Conference on Availability,Reliability and Security (ARES)[C].USA:IEEE PRESS,2013.615-624. [22]Yu R,Kang J,Huang X,et al.MixGroup:Accumulative pseudonym exchanging for location privacy preservation in vehicular social networks[J].IEEE Transactions on Dependable and Secure Computing,2015,PP(99):1-12. [23]Xiaodong L,Rongxing L.Vehicular Ad Hoc Network Security and Privacy[M].Wiley:IEEE Press,2015.71-89. [24]Mokbel M F,Chow C Y,Aref W G.The new Casper:query processing for location services without compromising privacy[A].Proceedings of the 32nd International Conference on Very Large Data Bases[C].USA:VLDB Endowment,2006.763-774. [25]郝忠孝.时空数据库新理论[M].北京:科学出版社,2011. [26]Chow C Y,Mokbel M F,Liu X.Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments[J].GeoInformatica,2011,15(2):351-380. [27]Gong Z,Sun G Z,Xie X.Protecting privacy in location-based services using k-anonymity without cloaked region[A].The Eleventh International Conference on Mobile Data Management (MDM)[C].USA:IEEE Press,2010.366-371. [28]Ma C,Zhou C,Yang S.A voronoi-based location privacy-preserving method for continuous query in LBS[J/OL].International Journal of Distributed Sensor Networks,2015,(2015):Article ID 326953.http://dx.doi.org/10.1155/2015/326953. 朱顺痣 男,1973年7月出生,福建东山人,厦门大学博士,厦门理工学院计算机与信息工程学院教授、院长.主要研究领域为数据挖掘、信息推荐、隐私保护和系统工程. E-mail:szzhu@xmut.edu.cn 黄 亮 男,1982年6月出生,湖南隆回人,中国科学院计算技术研究所博士.目前工作于国家计算机网络应急技术处理协调中心,主要研究领域为无线资源管理、异构网络、集中式无线接入网络、移动互联网. 周长利 男,1985年3月出生,黑龙江省哈尔滨人,哈尔滨工程大学博士,华侨大学计算机科学与技术学院讲师.主要研究领域为位置隐私保护、网络与信息安全. E-mail:zhouchangli666@163.com 马 樱 男,1982年1月出生,湖南邵阳人,电子科技大学计算机系统结构专业博士,厦门理工学院计算机与信息工程学院讲师.主要研究方向为基于挖掘的软件工程、大数据、云计算. A Privacy-Preserving Method Based on PoIs Distribution Using Cloaking Region for K Nearest Neighbor Query ZHU Shun-zhi1,HUANG Liang2,ZHOU Chang-li3,MA Ying1 (1.SchoolofComputerandInformationEngineering,XiamenUniversityofTechnology,Xiamen,Fujian361024,China;2.NationalComputerNetworkEmergencyResponseTechnicalTeamCoordinationCenterofChina,Beijing100029,China;3.SchoolofComputerScienceandTechnology,HuaqiaoUniversity,Xiamen,Fujian361021,China) AchievingKNN query with traditional cloaking region brings higher communication cost and delay caused by useless points of interest (PoI) returned,a newKNN query method is proposed.Based on Voronoi diagram division of PoIs and hierarchical index quadtree structure,cloaking region can be constructed purposefully.Due to the targeted query request,the communication cost is decreasing compared with traditional cloaking region methods.And injecting fake query requests makes the query content privacy preserving work.We have verified the effectiveness of our proposal by analysis and experiments. location privacy;location based service;cloaking region;Knearest neighbor query 2015-04-14; 2015-11-28;责任编辑:孙瑶 国家自然科学基金(No.61373147,No.61502404);福建省自然科学基金(No.2016Y0079,No.2015J05132);福建省教育厅A类项目(No.JA14234) TP311 A 0372-2112 (2016)10-2423-09 ��学报URL:http://www.ejournal.org.cn 10.3969/j.issn.0372-2112.2016.10.021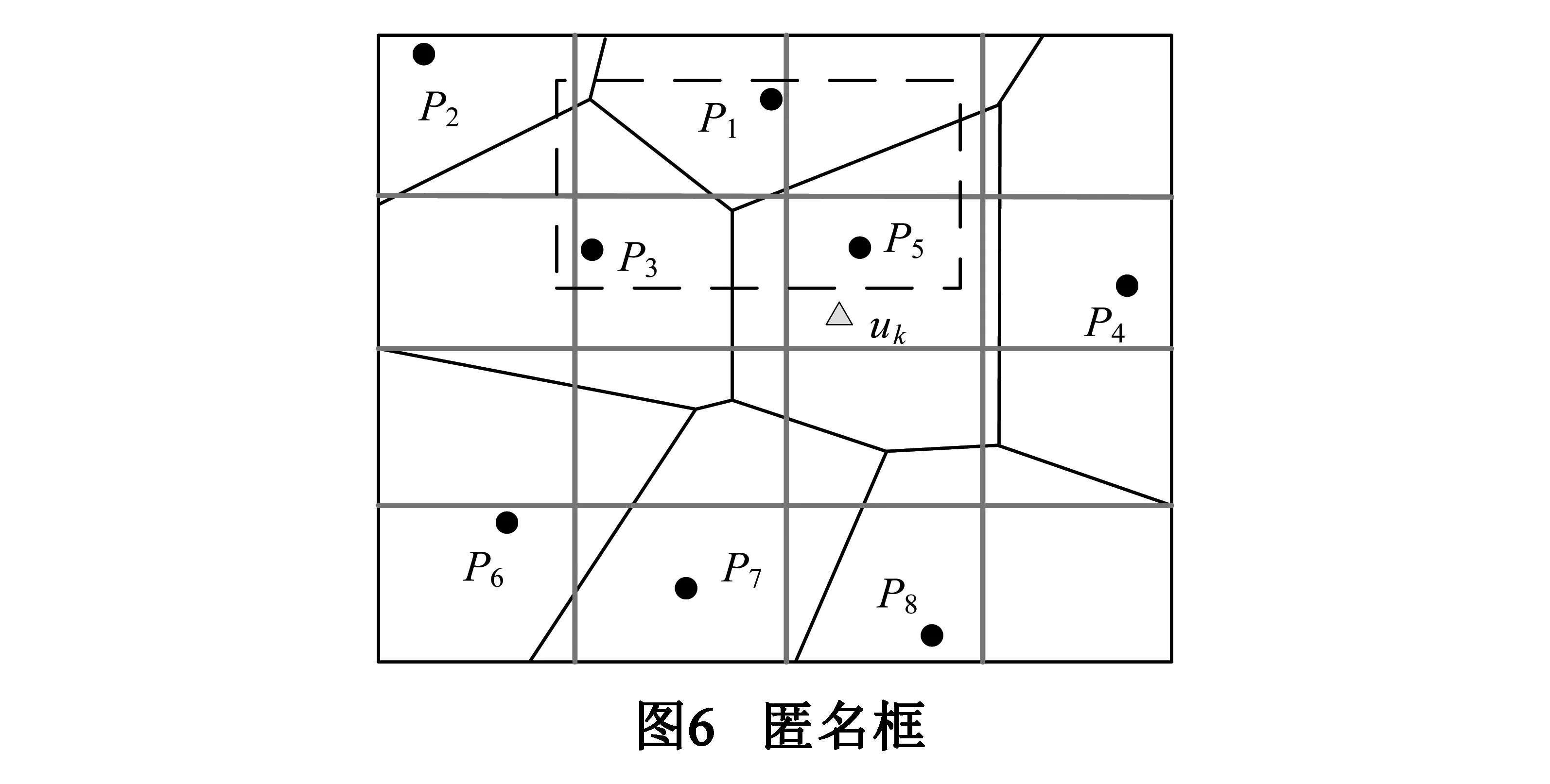
4 实验
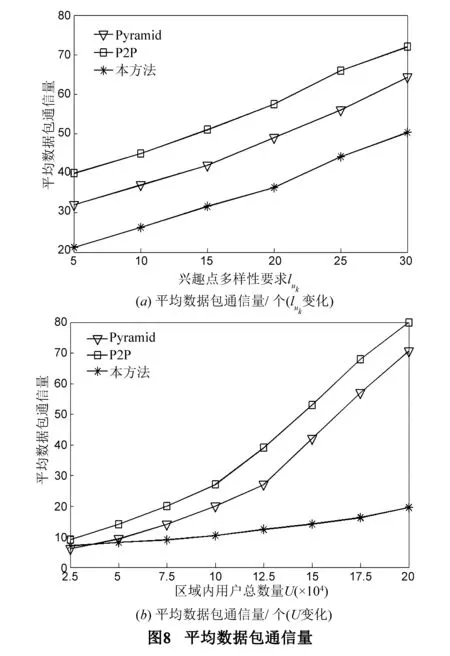
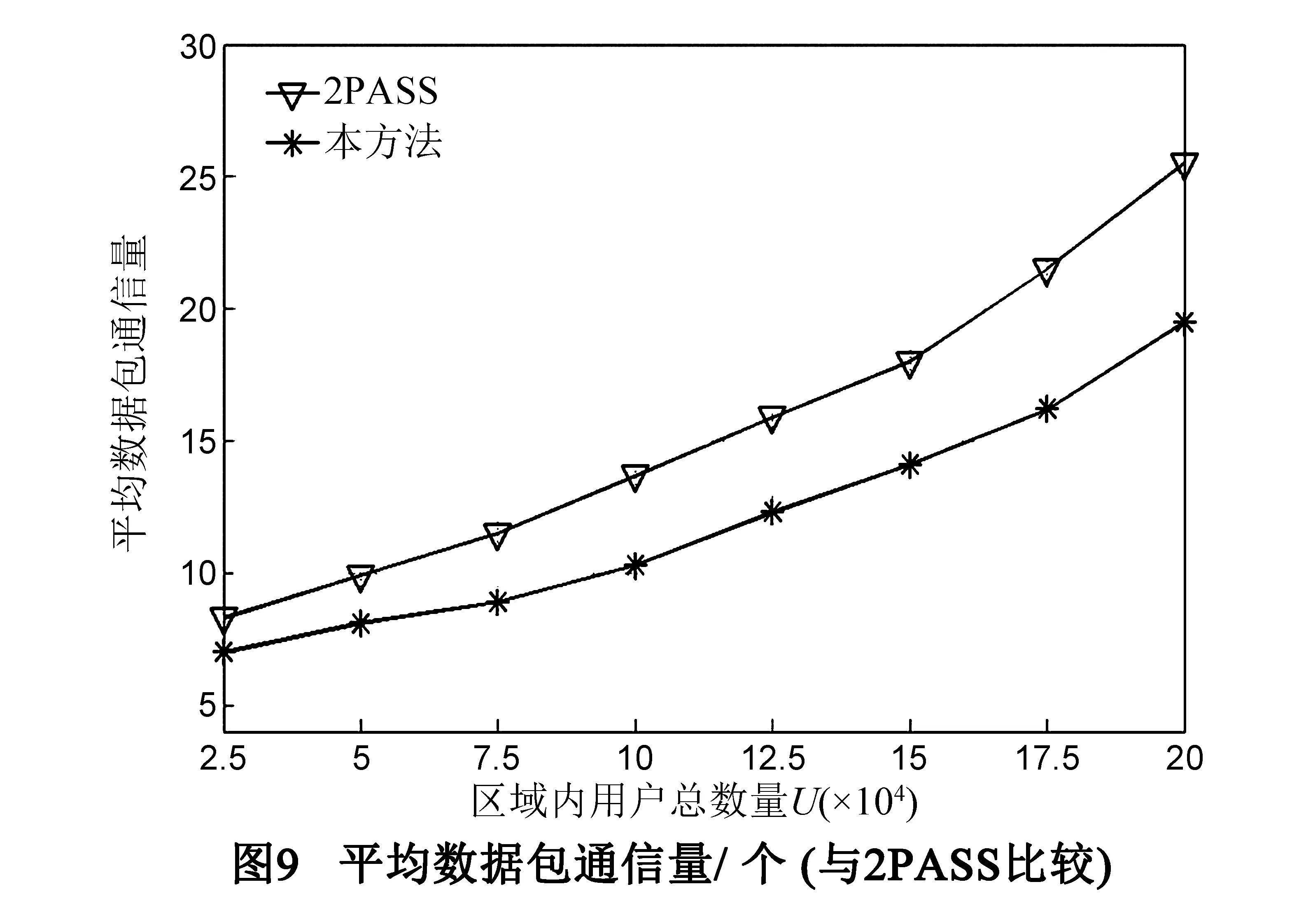
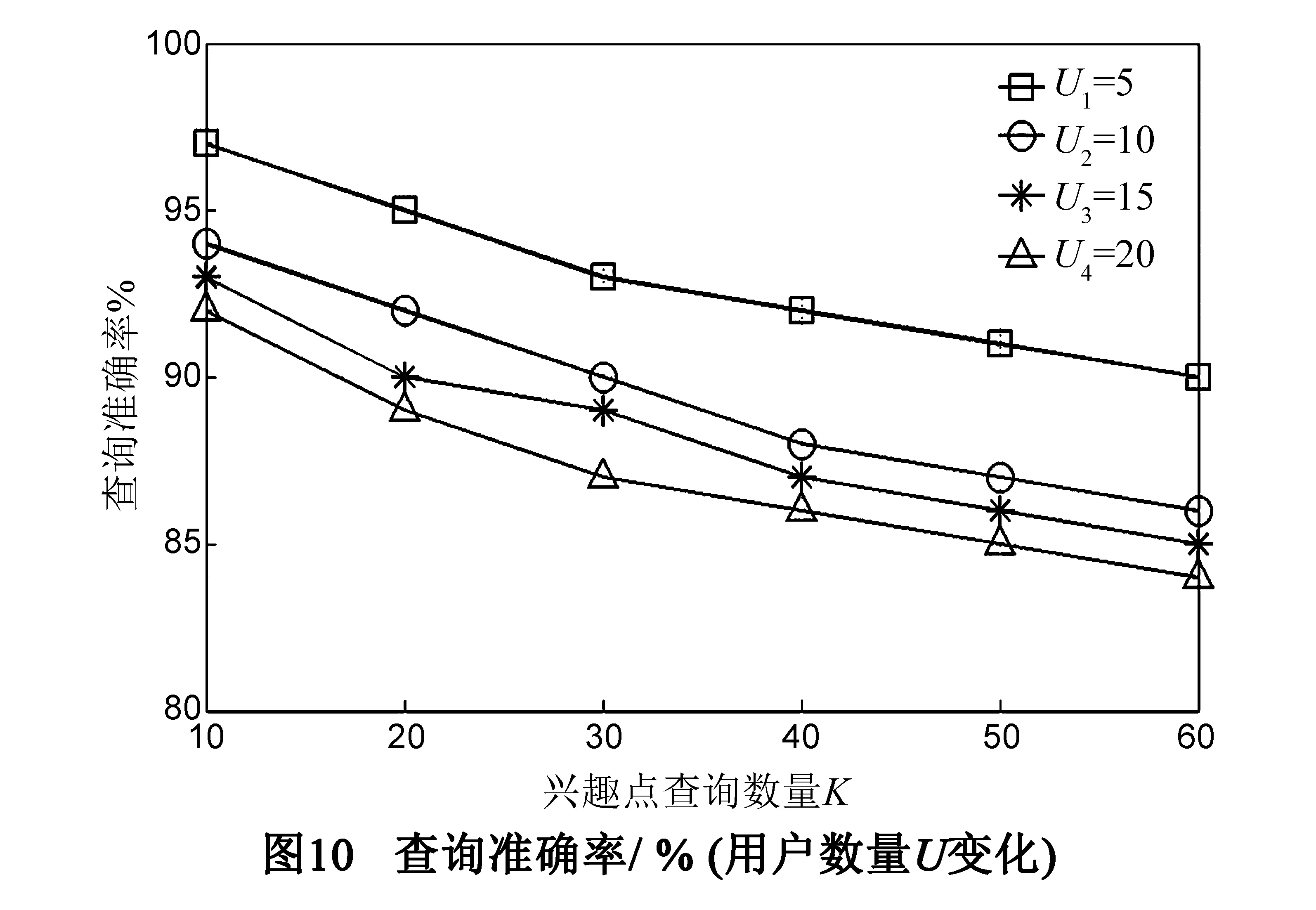
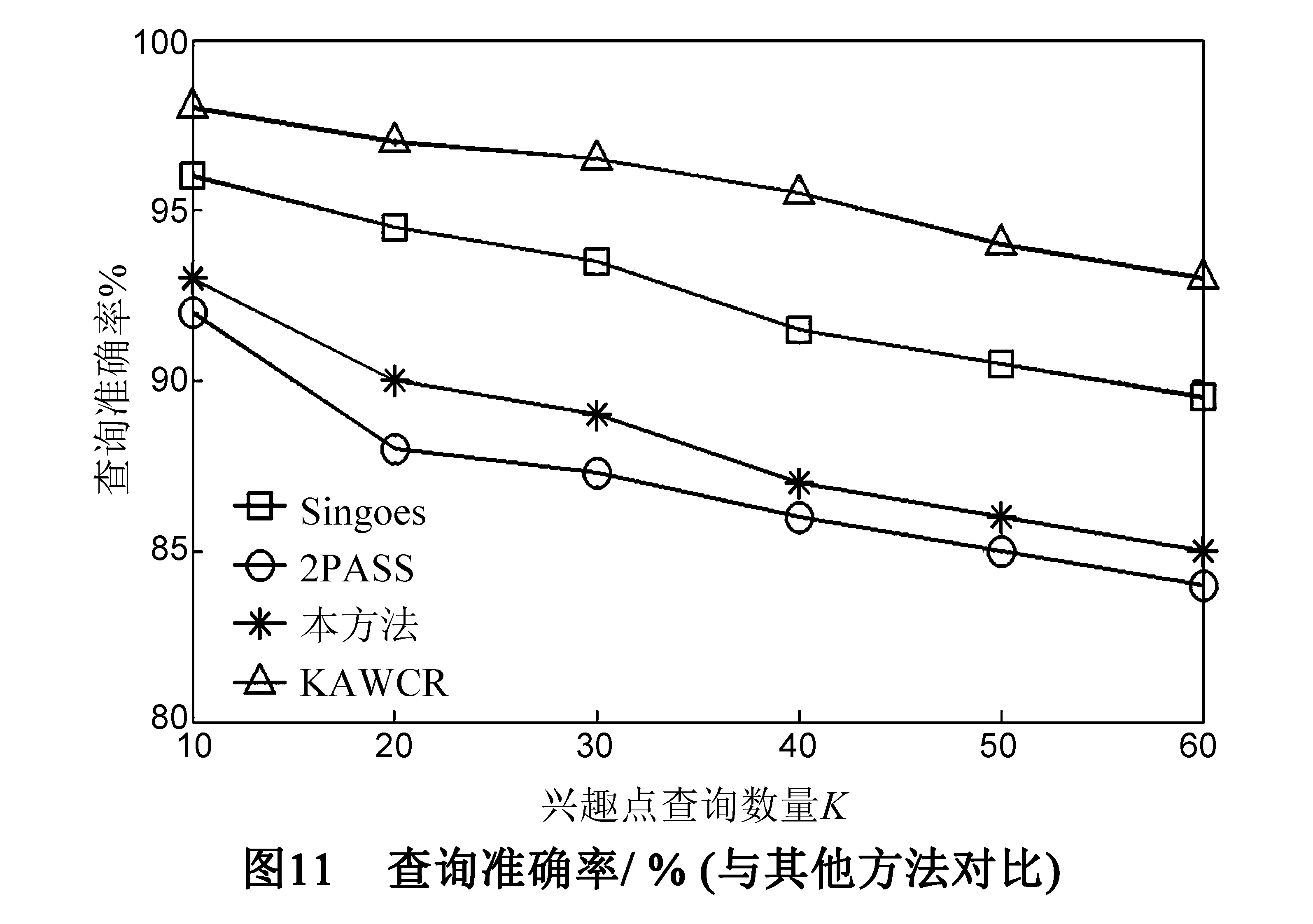
5 结论及展望




