基于场景分割的视频内容语义管理机制
2016-12-08胡金军
邢 玲,马 强,胡金军
(1.河南科技大学信息工程学院,河南洛阳 471023;2.西南科技大学信息工程学院,四川绵阳 621010)
基于场景分割的视频内容语义管理机制
邢 玲1,2,马 强2,胡金军2
(1.河南科技大学信息工程学院,河南洛阳 471023;2.西南科技大学信息工程学院,四川绵阳 621010)
针对视频内容管理在不同层面存在语义鸿沟的问题,提出基于UCL(Uniform Content Locater )的视频语义描述框架,该框架包含了三个层次的语义:内容语义、控制语义以及物理属性信息.而视频场景的分割则通过视频内容基于时空上的相似性实现.对于每个视频场景,结合局部纹理复杂度、背景亮度和场景复杂度,选择最佳参考帧(I帧)与非最佳参考帧(非I帧)以嵌入不同的语义信息:控制语义、物理属性信息嵌入I帧,内容语义嵌入非I帧.利用数字语义水印技术来实现视频内容的语义管理,完成语义信息和载体信号的一体传输和存储.实验中采用JM参考模型进行数字水印方法的验证,结果表明该方法鲁棒性强,且不会造成视频资源质量显著下降.
视频描述;语义管理;语义水印;场景分割;UCL
1 引言
作为互联网络中最主要应用之一的视频业务,由于其内容具有易复制、易分发、难管理、难监控等特性,视频内容的有效管理成为了近年来的研究热点.最早提出视频内容语义管理机制的是由ETSI等300多家工业组织制定使用的EPG(Electronic Program Guide),它为数字视频内容创建了一组特有的表格,且使用单独的TS流进行传输[1];后续的研究如基于内容情感选项的视频建模与检索方法[2]、基于网络对于视频内容的分发与存储管理[3]、体育视频内容标志镜头分类与管理[4].与EPG有类似的特点,这些方法都是将视频数据和语义管理数据进行单独传输和存储,无法实现高效地信息一体化传输.
数字视频内容管理的困难主要集中在三个方面:(1)无内容语义描述集,导致视频内容重复冗余度高;(2)无传输控制语义集,导致视频传播管控难度加大;(3)无安全语义集,造成了源端回溯不可信,缺乏认证安全性.视频数字水印技术的出现使得视频内容的版权信息得到了保证,且版权信息与载体同步传输,视频通信效率得以提高,如基于水印的开发式视频管理管理框架[5].但该方法输出端只能检测水印是否存在,以完成视频片段的认证,在无法获得水印原始信息的条件下,难以达到对视频内容的智能管理.由于视频资源仍然使用统一资源定位符(Uniform Resource Locator,URL)标识其引用,导致同一内容视频本体因无强制语义计算而得以重复冗余发布.因此,研究可靠的视频语义模型,结合数字水印技术,将提高视频内容的有效管理.
本文提出了一种基于语义水印的视频内容管理机制.在UCL(Uniform Content Locater,UCL)的基础上[6],结合视频检索、内容管控等要求,提出UCL视频语义描述框架,框架中包括内容语义、控制语义以及物理属性信息;结合H.264视频具体编码算法,采用基于场景分割的视频语义水印算法,将控制语义、物理属性信息和内容语义信息分别嵌入所选视频场景中不同的视频帧中,以提高水印嵌入容量和水印的鲁棒性.利用数字语义水印技术实现视频内容的语义管理,完成语义信息和载体信号的一体传输和存储.最后基于JM10.2参考模型,对语义水印方法可见性、和鲁棒性进行了验证.
2 基于场景分割的视频语义水印方法
2.1 基于UCL的视频语义描述框架
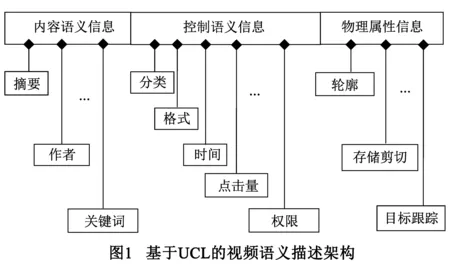
视频数字水印信息针对不同的应用有不同的语义要求,如针对视频检索,有根据节目内容提出的语义要求,有根据节目名称提出的语义要求;针对网络可控,有对发布者、接收者、节目分级等方面的语义要求.这些多样的语义需求,要求提出相对普适的语义模型,以实现内容识别、选择、以及业务监管的功能.结合语义的物理特征(如摘要等纯文本信息量大,且对控制语义等信息鲁棒性较低),构建基于UCL的视频语义描述框架,如图1所示.其中包括:内容语义,控制语义和可选的物理属性信息.
令视频的UCL语义模型为U{U1x,U2y,U3z},其中U1x属于内容语义,为纯文本信息,U2y为控制语义,为映射编码信息,U3z为可选的物理属性信息,为映射编码信息,x,y,z分别为信息的元素个数.U1x包括的语义信息有:摘要、作者、标题、出版者、日期、关键词、扩充项;U2y包括的语义信息有:分类、格式、时间、点击量、语言、类型、文件大小、权限、扩充项;U3z包括的语义信息有:轮廓、存储剪切、拷贝许可、目标跟踪、扩充项.语义模型U中元素的大小或多少,与视频的具体应用背景有关,但并不影响视频内容的语义管理机制.
2.2 视频场景分割
场景指一个镜头所包含的视频帧序列.同一个场景,帧之间具有很强的相关性,因此可以利用这种时域和空域的相关性对一个场景进行压缩编码.另外,针对传输过程中的主动攻击,如帧删除、帧重组、帧平均,很难对整个场景进行完全删除或破坏的毁灭性的攻击.因此,论文通过利用场景分割技术来增强水印信号的鲁棒性,以提高针对时间同步攻击的自适应抵抗力.
目前,对于视频场景分割的研究,主要有像素比较、模板比较、直方图等方法,但他们有些共同的弊端,如算法复杂度较高,实时性不够强[7~11].考虑到视频数字水印实时性和视频解码同步的性能需求,论文提出了基于DCT系数变化量比较方法实现对视频场景的分割.由于图像的能量主要集中在变换域的DC系数上,相对离散的像素点具有更稳定的对应关系.结合视频编解码的子块结构,选择针对16×16宏块变换域DC系数做比较,如式(1):
(1)
其中D(i,a,b)表示第i帧图像宏块(a,b)的DC系数,Var(i)表示则第i帧图像相对于前一帧图像的DC系数改变量,其中N=(a+b)*16.由于DC系数表示子块图像像素点的均值,所以用宏块像素均值取代宏块的整数DCT变换,从而进一步降低算法的复杂度.
空间相似性Var(i)越小,表示相邻两帧属于同一场景的可能性就越大,而Var(i)值较大时,既可表示相邻两帧属于不同场景,也可表示同一场景中物体运动较为剧烈或背景变化较快,因此需要进一步计算他们的时间相似性.
Var(i)本身也可表示当前帧变化的剧烈程度,所以通过计算这种剧烈程度的放大或缩小的倍数来表示时间相似性,如式(2):
(2)
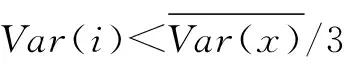
一个场景序列的第二帧相对于第一帧DC系数的改变量要小得多,Var(x,2)<β2,变换的剧烈程度显著下降,α(x,2)<-η;同理,下一个场景的第一帧相对于上个场景的最后一帧DC系数变化值很大,Var(x-1,1)>β1,变换的剧烈程度显著增加,α(x-1,1)>η,其中(x,2)为场景x第二帧的图像.因此,综合考虑空间相似性和时间相似性,一个场景分割过程的首帧Ff和末帧Fl的判断式如式(3)、(4),其中η表示时间相似性的阈值,β2表示场景中第二帧图像的空间相似性阈值,β1为下一个场景中第一帧图像的空间相似性阈值.
Ff={i-1|α(i)<-η||Var(i)<β2}
(3)
Fl={i-1|α(i)>η||Var(i)>β1}
(4)
根据人眼的视觉特性,为了提高水印的不可见性,选择图像纹理复杂度高和帧间变化比较剧烈的场景嵌入视频数字水印信息.将场景第二帧DC系数的梯度能量与第一帧DC系数改变量的乘积为场景复杂度P,如式(5),
P=T(i)×Var(i)
(5)
T(i)
(6)
其中式(6)为DC系数的梯度能量,D(i,a,b)表示第i帧图像宏块(a,b)的DC系数,即像素均值,根据P的定义,其中i=2,即为本场景序列中的第二帧,通过对P值与阈值的比较来选择适合嵌入水印的场景.
2.3 目标矩阵生成
由于人眼对嵌入水印变化域的敏感性较低,所以水印信息不仅和帧内纹理复杂度和背景亮度有关,帧间变化剧烈程度也同样影响着水印信息的不可见性.为了使水印信息更接近于噪声信号,具有更好的不可见性,论文引入了场景复杂度,即综合考虑背景亮度、帧内空间复杂度、场景复杂度三要素来决定水印嵌入强度S,形成一个目标矩阵M.
针对所选中的分割场景,首先计算图像中每个16×l6宏块的背景亮度、帧内纹理复杂度,得出宏块的局部图像复杂度H;然后,结合场景复杂度P得到水印嵌入强度Sa,b,判断与阈值Sth关系,当小于阈值时,水印的目标矩阵项Ma,b=0,表示在此宏块不适合水印信息的嵌入;相反,Ma,b=1.在视频解码端根据密钥再次生成目标矩阵,进行视频数字水印信息的检测与提取.
局部图像复杂度H的客观描述,来自于该宏块的灰度均值和纹理复杂度的加权组成的线性函数,如式(7):
(7)
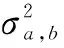
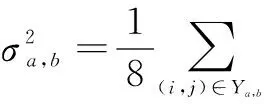
(8)
ϑ(ea,b)=(1/ea,b)β
(9)
其中ϑ(ea,b)为加权系数,它作为修正因子来使宏块的纹理复杂度和灰度均值在同一个数量级成线性关系,论文中取值范围为0.5~0.8.
为了减低过多修正因子给算法带来额外的计算复杂度,故将局部图像复杂度Ha,b与场景复杂度P进行“×”操作得出水印嵌入强度,如式(10):
Sa,b=P×Ha,b
(10)
其中,Sa,b的值随α1、α2和β取值而各异,从而生成不同的目标矩阵M,因此可以将这三个参数作为水印算法中的密钥使用.
2.4 语义水印的嵌入与提取
H.264中一个宏块包括一个16×16亮度分量Y和两个8×8的色差分量Cb、Cr.由于人眼对视频的色度较敏感,故算法仅考虑亮度分量Y信息.首先,将视频图像的亮度分量Y分割成16×16块,则水印目标矩阵M的结构为N1/16×N2/16,其中Ma,b∈{0,1},1≤a≤N1/16,1≤b≤N2/16.当Ma,b=1表示Ya,b为水印信息的载体,然后,将Ya,b块划分为16个4×4子块,对每个子块进行整数DCT变换,如图2所示,左上角的DCT0为DC系数.
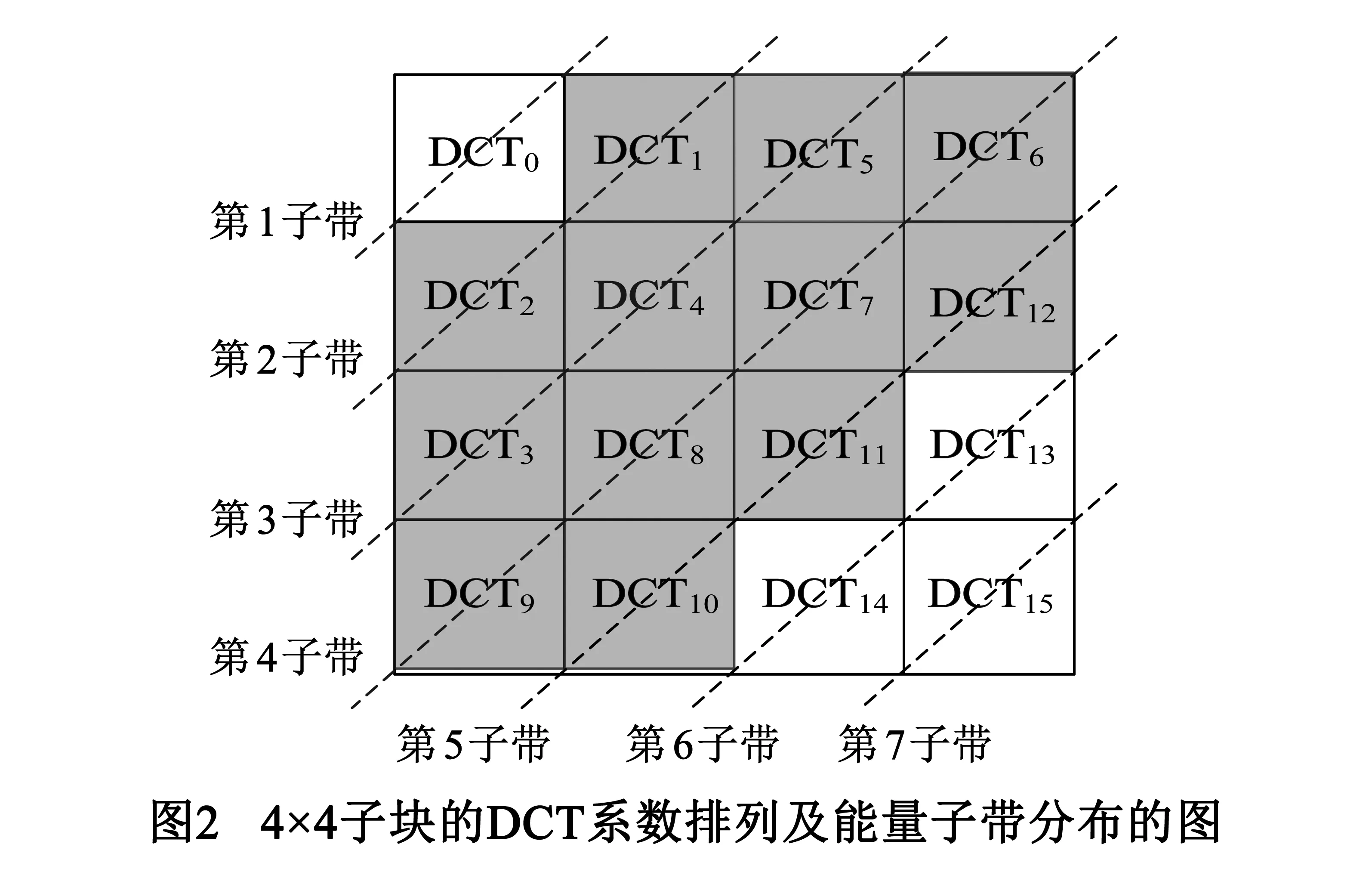
经过DCT变换后,4×4子块能量如图2中的第1子带到第7子带逐渐递减.其中AC高频系数(第6、7子带)多数为零不适合水印的嵌入,故选择第2子带到第5子带的12中频系数进行水印信息的嵌入,则嵌入规则如式(11)、(12)和式(13):
(11)
(12)
(13)
其中,DCTmean为12个中频系数的均值,DCTmean1为第3子带和第5子带6个中频系数的均值,DCTmean2为第2子带和第4子带6个中频系数均值,通过调整12个中频系数来改变DCTmean、DCTmean1和DCTmean2三者之间的关系进行水印信息(wx,y)的嵌入,即为水印信息的编码,如式(14)和(15):
DCTmean1>DCTmean>DCTmean2,wx,y=1
(14)
DCTmean2>DCTmean>DCTmean1,wx,y=-1
(15)
本文采用基于场景的语义水印算法,故将水印信息U中的U1x内容语义信息、U2y控制语义信息和U3z可选的物理属性信息,采用相同的水印嵌入方案在不同的嵌入点进行水印嵌入操作,所以即使采用相同的水印嵌入方案,其生成目标矩阵的参数P、α1、α2、β及其阈值Sth也不相同,这些都可作为密钥以提高水印的安全性.
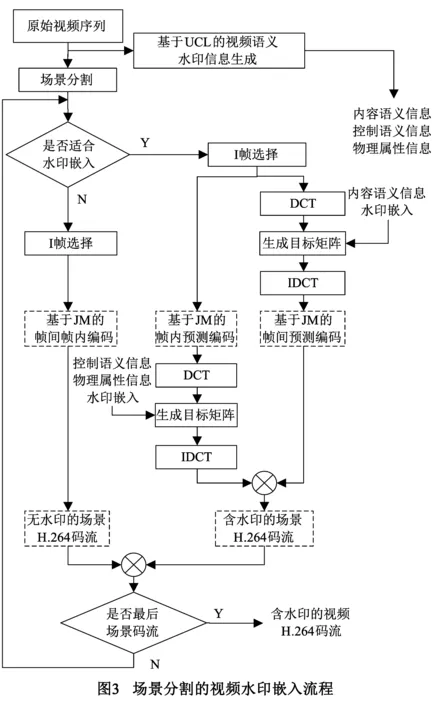
结合压缩域水印嵌入量小和原始域水印鲁棒性较差的各自弊端,针对H.264编码标准和JM实验的仿真平台,视频水印嵌入的流程为图3所示.
(1)对视频原始序列(YUV格式文件)进行UCL标引并采用扩频技术生成视水印语义模型信息集U,其中U1x属于内容语义,U2x是控制语义,U3x为可选的物理属性信息;
(2)对视频原始序列进行场景分割,形成基于场景的视频信息集F,元素F(i,j,k)中的i表示场景编号,j表示帧图像相对场景的序号,k表示在原始视频序列中帧编号;
(3)计算视频场景中场景复杂度,来选择适合进行水印嵌入的场景F′(i,j,k);
(4)将场景的第y′帧作为最佳参考帧(I帧),当一个场景的帧图像数大于15,按照GOP标准生成I帧,其中满足式(16),其中y表示场景中视频帧的数量.
y′=α*15,α∈0,1,2…,y″£y
(16)
(7)将含有水印信息的I帧和B、P帧重新组合生成含水印的场景H.264压缩码流;
(8)结合第(4)步的最佳参考帧选择算法,对第(3)步筛选出不适合水印嵌入的场景,借助JM编码器进行帧内和帧间编码,生成未含水印的压缩码流.
将第(7)步和第(8)步生成的压缩码流进行排序整合,生成基于H.264的视频压缩码流.
水印的检测与提取在H.264解码端完成,根据编码端对应的密钥生成目标矩阵M确定含水印的宏块位置,对含水印的宏块按照式(11)、(12)和(13)计算出DCTmean、DCTmean1和DCTmean2的值,以重构水印信息,如式(17):
(17)
3 实验结果
实验中在VS2008开发环境中完成JM10.2最佳参考帧选择算法的移植和优化、原始视频序列的场景分割、水印的嵌入和含水印的H.264码流的解码工作,由MatlabR2010b对原始视频序列和含水印的视频序列进行数据统计,最后针对数字水印的性能指标得对算法进行性能评估.视频采用标准视频序列News、Foreman和Akiyo,所有视频序列都是QCIF格式(176×144),YUV(4∶2∶0),序列长度均为300帧,视频场景分割时参数选择为η=2,β1=500,β2=50.
对于重构视频图像质量的判断,选择PSNR(Peak Signal to Noise Ratio)峰值信噪比作为评判标准.PSNR表示视频载体信号嵌入水印后的视频质量变化情况,其值越高表示其透明性越好,其计算过程如式(18):
(18)
其中max∀(x,y)f2(x,y)为原始视频图像f上所有像素点中的最大像素值,针对8bit的灰度图像,其最大值为255,则典型算法的PSNR值主要集中在20~40dB之间.
采用归一化互相关系数NC(Normalized Correlation)用来度量重构的水印和原始水印之间的相似程度,如式(19):
(19)
其中,W表示原始水印信息,W′表示提取出来的水印信息,N为水印信号的长度,通常情况下,当NC>0.9时,认为重构水印是可识别的.
3.1 水印的不可见性

视频数字水印的不可见性指确保人眼无法察觉,由于水印嵌入造成图像质量的下降.实验中对Akiyo视频第150帧和151帧图像的原始序列图像、压缩后的图像、含水印的视频图像量的质量变化进行展示,其中第150帧为H.264编码中的最佳参考帧I帧,前者采用基于压缩域的视频水印嵌入方案,后者为基于原始域的视频数字水印嵌入方案.从图4中很难察觉到由于压缩和水印的嵌入引起视频图像质量的变化.
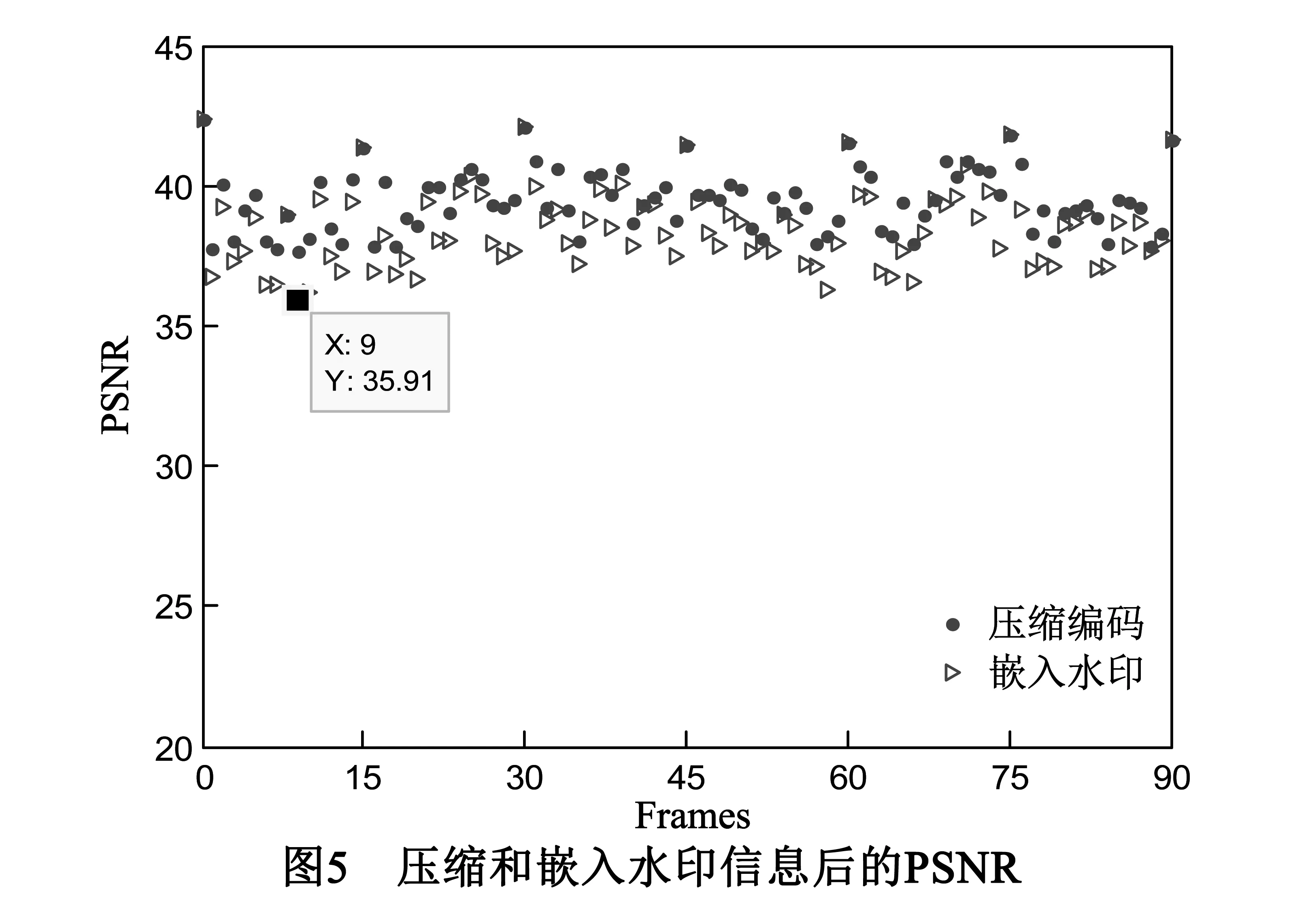
Akiyo视频序列压缩后和嵌入水印后的视频图像前90帧的PSNR值如图5所示.一般情况下,当PSNR值大于30dB以上,人眼就难以辨别两幅图像差别.从图5可见,Akiyo视频原始序列压缩后和嵌入水印后第y’(y=i*15)帧的PSNR值较高,主要是由于第y’帧在H.264视频编码中作为最佳参考帧,编码准确率最高.总体上两曲线非常接近,且PSNR最小值为35.91,说明本文提出的视频数字水印具有很好的不可见性.
3.2 水印的鲁棒性
实验中若NC>0.9,则认为该帧内含有水印信息,同一场景内有一幅图像含有水印信息,认为该场景为水印信号的载体.实验对象为Akiyo、News、Foreman、Sum四个视频序列,其中Sum为前三者视频拼接序列.对其分别统计视频序列的场景数(SC),含有水印信息的场景数(SCw),检测到水印载体场景数(DSCw),错误检测到的场景数(ESCw),如表1所示.
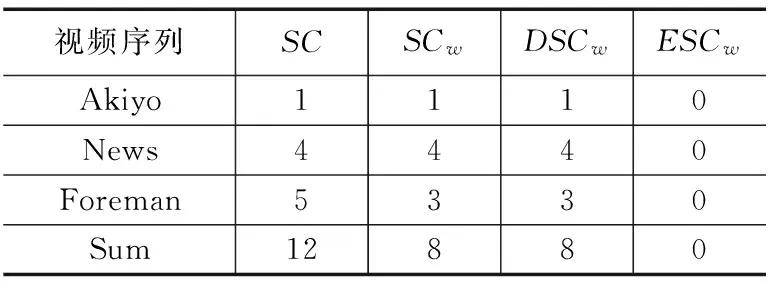
表1 嵌入水印的场景检查
从表1中可看出,在未受攻击的状态下,实验中嵌入信息的场景都能准确的检查出来.由于在同一场景中嵌入相同内容,故实验中采用的水印场景检测标准(NC>0.9)足以重构出原水印信息.且由于采用原始域与压缩相结合的水印算法,所以为了进一步说明一个场景中关于内容语义水印信息的鲁棒性,以News视频序列为例,统计其前90帧(第90帧为第2个场景头帧)的NC值,如图6所示.
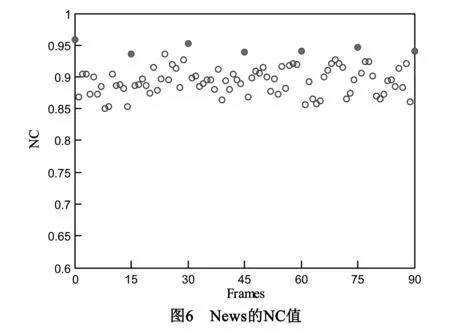
从图6中可知,第y′(y=i*15)帧图像的NC值要明显高于其他图像,这是由于y帧为编码参考帧(I帧),其量化后的非零DCT系数较多,且采用基于压缩域的水印方案,避免了由于视频信息的频繁解压缩,造成的水印信息丢失.虽然非I帧域的NC值相对较低,但该域采用基于原始域的水印嵌入方案大大增加了水印信息的嵌入量,且该域的纯文本水印信息(摘要、关键词等)在NC>0.7的情况下不会对语义理解造成歧义,一般情况下,NC>0.6就可以重构出水印信息.
3.3 抗噪声攻击能力
视频载体信号在传输和处理的过程中,最常见的攻击方式就是噪声攻击,因此水印算法抗噪能力是其性能评判的重要指标.实验同样对Foreman视频序列的前90帧图像分别加载了密度为0.005、0.01、0.03的椒盐噪声,计算出重构视频图像的PSNR值和重构水印信息的NC值,其中PSNR值如图7所示.可以看出,相对密度为0.005、0.01、0.03的椒盐噪声,水印信息对视频帧质量的影响反而更小,说明该算法对视频原始图像的影响几乎忽略不计.在密度为0.03的椒盐噪声下PSNR最小值为31.21,故重构的视频图像相对于原始图像的变化在人眼察觉范围之外.
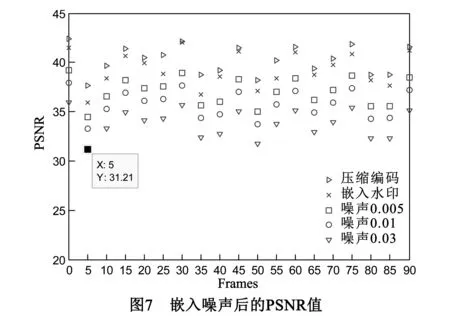
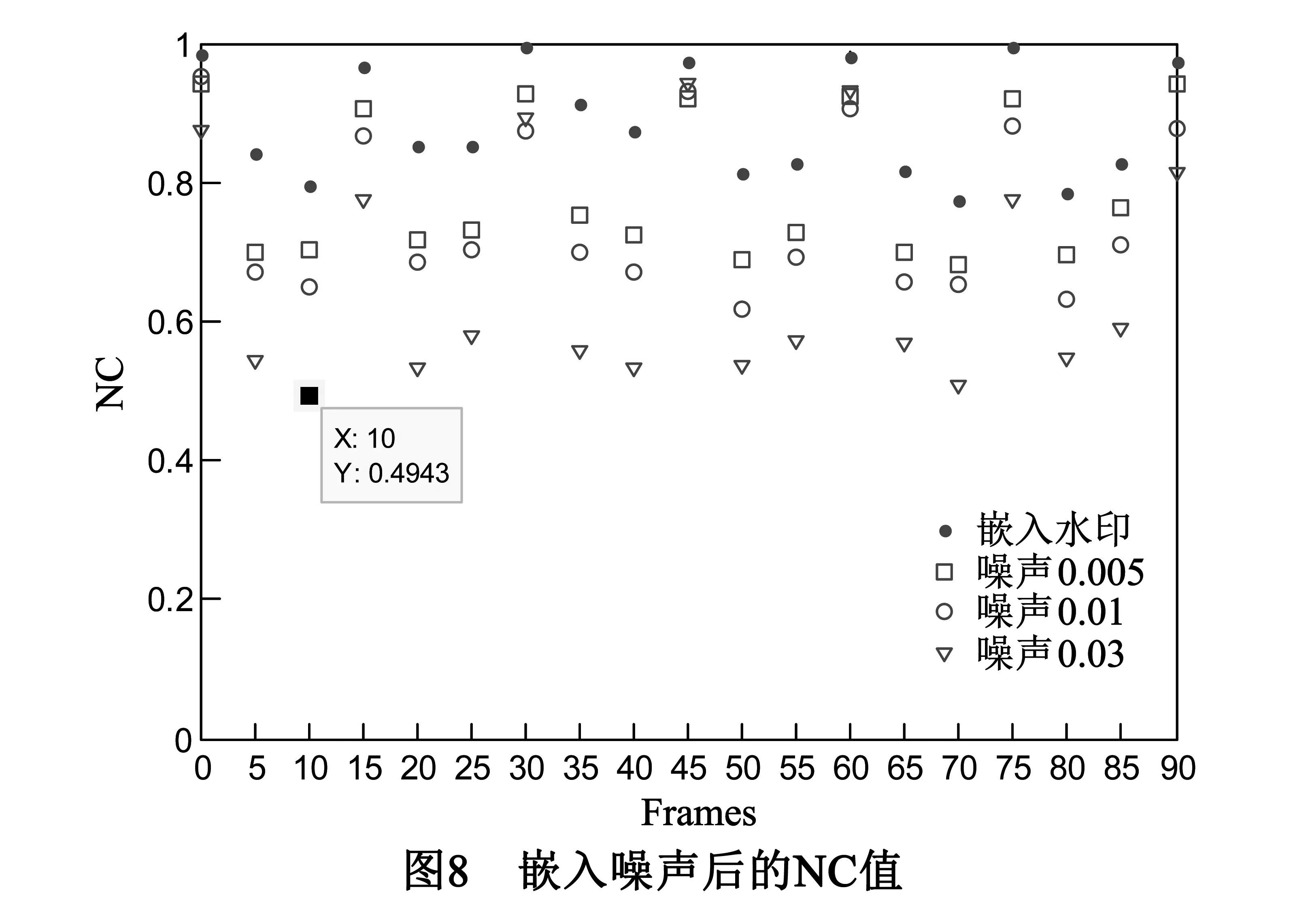
视频数字水印信息受到不同程度的噪声攻击后,NC值变化情况如图8所示.NC值出现很大程度的衰减,特别是非I帧(y≠i*15)中的水印信息.由于非I帧采用帧间预测编码,只保留部分残差信息,且该域水印信息经过JM10.2的重压缩编码,使该域水印信息的NC值衰减的相对比较厉害.如在密度为0.03椒盐噪声下,最小NC值为第5帧(非I帧)的0.4943,但经过对数据的统计发现,在相同强度噪声攻击下该场景中非I帧的最大NC值为0.6357,由于同一场景内嵌入相同的水印信息,所以即使在较高密度的噪声攻击下,仍然可以重构出不影响人们观看的水印信息.由此可见,对于噪声攻击,I帧的鲁棒性表现的比较满意,故将I帧作为控制语义信息和物理属性语义信息的载体.
3.4 抗其它主动攻击能力
同时对Akiyo、News、Foreman三个视频分别进行重量化、中值滤波和帧删除攻击,视频数字水印受到攻击后的NC值如表2所示,结果为三段含水印的视频序列前300帧中,有效NC的均值.由于同一场景中嵌入相同的水印信息,当NC值<0.5时,视该帧水印信息为无效水印.
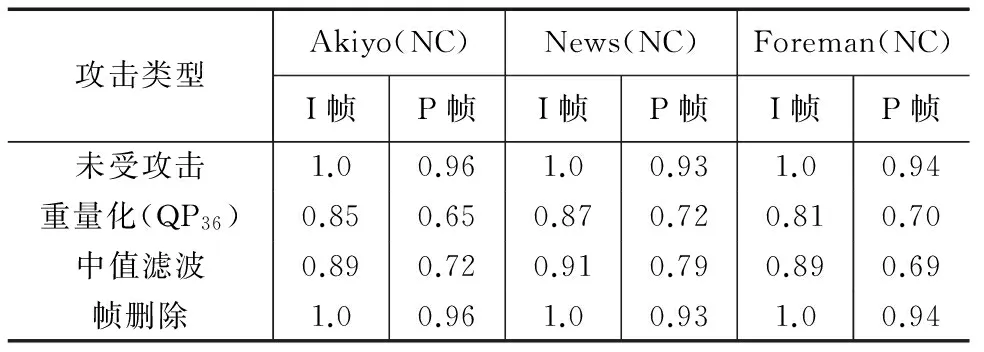
表2 水印信息鲁棒性分析
从表2中看出,I帧中水印信息在遭受重量化、中值滤波和帧删除等攻击时,表现出较好的鲁棒性.其中帧删除攻击对水印信息没有任何影响,主要是帧删除很难实现完全删除整个视频场景.
4 结论
数字视频内容的有效管理有助于互联网中视频业务高效、可靠的开展.本文提出一种基于场景分割的视频内容语义管理机制,将语义模型从特性上分为三个子集:内容语义、控制语义以及物理属性信息;对视频内容按照时间与空间相似性,构建基于DCT系数变化比较方法来实现视频的场景分割;并且按照背景亮度、帧内空间复杂度和场景复杂度三要素来决定语义水印嵌入位置即目标矩阵,通过修改DCT中AC系数实现水印的嵌入.将内容语义信息嵌入到场景中的非最佳参考帧,语义信息、物理属性信息则嵌入到最佳参考帧,利用数字语义水印技术实现了视频内容的语义管理,完成语义信息和载体信号的一体传输和存储.
[1]Basic R,Mocinic M.User′s requirements for electronic program guide (EPG) in interactive television (iTV)[A].Region 8 International symposium on video/image processing and multimedia communication[C].Zadar :IEEE,2002.457-462.
[2]Alan H,Xu L Q.Affective video content representation and modeling[J].IEEE transactions on multi-media,2005,7(1),143-154.
[3]吴宣够,熊焰,印凤行.树形网络中的一种有效视频内容分发算法[J].小型微型计算机系统,2013,34(8):1728-1731.
Wu Xuan-gou,Xiong Yan,Yin Feng-hang.An Efficient video content distribution algorithm for tree networks[J].Journal of Chinese computer systems,2013,34(8),1728-1731.(in Chinese)
[4]朱映映,朱艳艳,文振焜.基于类型标志镜头与词袋模型的体育视频分类[J].计算机辅助设计与图形学学报,2013,25(9),1375-1383.
Zhu Ying-ying,Zhu Yan-yan,Wen Zhen-kun.Sports video classification based on marked genre shots and bag of words model[J].Journal of computer-aided design and computer graphics,2013,25(9),1375-1383.(in Chinese)
[5]刘宇驰,等.一种开放式视频管理框架[J].国防科技大学学报,2006(28),73-76.
Liu Yu Chi,et al.An open framework for video management[J].Journal of national university of defence technology,2006(28),73-76.(in Chinese)
[6]XING Ling,MA Qiang,ZHU Min.Tensor semantic model for an audio classification system.SCIENCE CHINA Information Sciences,2013,56(6):1-9.
[7]Yun Z,Mubarak S.A General Framework for Temporal Video Scene Segmentation[A].International Conference on Computer Vision[C].Beijing:IEEE,2005.1111-1116.
[8]Panagiotis S,Vasileios M,Ioannis K,et al.Temporal video segmentation to scenes using high-level audiovisual features[J].IEEE Transactions on Circuits and Systems for Video Technology,2011,21(8),1051-8215.
[9]Zhu S H,Liu Y C.Scene Segmentation and Semantic Representation for High-Level Retrieval[J].IEEE Signal Processing Letters,2013,15,713-716.
[10]Mostafa T,Mahmood K,Shohreh K.Event Detection and Summarization in Soccer Videos Using Bayesian Network and Copula[J],IEEE Transactions on circuits and Systems for Video Technology,2014,24(2),291-304.
[11]He Hu,Ben U.Automatic object segmentation of unstructured scenes using colour and depth maps[J],IET computer vision,2014,8(1),45-53.

邢 玲 女,1978年11月生,四川攀枝花人,河南科技大学信息工程学院教授,硕士生导师,主要研究方向为网络信息智能处理与主动服务技术.
E-mail:xingling-my@163.com

马 强 男,1982年9月生,四川绵阳人,西南科技大学信息工程学院讲师,主要研究方向为多媒体安全认证、语义计算.
E-mail:maqiang-my@163.com

胡金军 男,1986年6月生,河南信阳人,西南科技大学信息工程学院硕士,主要研究方向为视频编解码、视频质量评估.
E-mail:hujingjun-my@163.com
A Semantic Management Mechanism for Video Resources Based on Scene Segmentation
XING Ling1,2,MA Qiang2,HU Jin-jun2
(1.SchoolofInformationEngineering,HenanUniversityofScienceandTechnology,Luoyang,Henan471023;2.SchoolofInformationEngineering,SouthwestUniversityofScienceandTechnology,Mianyang,Sichuan621010,China)
To tackle video management problem of semantics gap existing in different aspects,a video semantic description framework based on UCL (Uniform Content Locator) is proposed.The semantic description framework consists of three levels,i.e.,content,control and physical.Video to be semantically managed is divided into different scenes based on spatial-temporal similarities of frames.For every scene,the most optimal reference frame (I-frames) and non-optimal reference frames (non I-frames) are selected based on local texture complexity,background luminance and scene complexity.Content semantic are imbedded into non I-frames while control and physical semantics are imbedded into I-frames.A semantic watermarking algorithm is incorporated into the management to realize the efficient storage and transmission of video content and its video semantics.JM reference model is adopted for experiments to verify the watermarking technique and results show that the method is robust and has little side effect on video quality.
video description;semantic management;semantic watermark;scene segmentation;UCL(uniform content locater)
2014-12-17;
2015-01-30;责任编辑:郭游
国家自然科学基金(No.61171109);四川省科技厅应用基础项目(No.2014JY0215);西南科技大学科研项目(No.2014JY0215)
TN911.7
A
0372-2112 (2016)10-2357-07
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.10.011
