多核学习融合局部和全局特征的人脸识别算法
2016-12-08赵春霞
杨 赛,赵春霞,刘 凡
(1.南通大学电气工程学院,江苏南通 226019; 2.南京理工大学计算机科学与工程学院,江苏南京 210094;3.河海大学计算机与信息学院,江苏南京 210098)
多核学习融合局部和全局特征的人脸识别算法
杨 赛1,赵春霞2,刘 凡3
(1.南通大学电气工程学院,江苏南通 226019; 2.南京理工大学计算机科学与工程学院,江苏南京 210094;3.河海大学计算机与信息学院,江苏南京 210098)
提出一种基于词袋模型的新的人脸识别算法.该方法将词袋模型和词袋模型的全局模式分别作为人脸图像的局部特征和全局特征描述,最后使用多核学习方法将二者进行融合.AR、FERET、CMU PIE以及LFW公开人脸数据库上的实验结果表明,本文方法能够更好的解决小样本问题,并且对人脸的表情变化、姿态变化以及面部遮挡具有更优良的鲁棒性.
词袋模型;全局特征;多核学习;人脸识别
1 引言
人脸识别因其在身份验证、视频监控、疑犯追踪等领域的广泛应用而成为当前计算机视觉研究中的热点.人脸识别的核心步骤之一为人脸特征提取,可分为全局特征和局部特征.前者缺乏对局部变化的鲁棒性,而目前人脸识别中所使用的局部特征仅限于底层视觉特征,因此本文将更具有判别能力的中层语义特征—词袋模型(Bag-of-Words,BoW)应用到人脸识别领域.
全局与局部特征之间并不存在严格的界限,当局部表示中用于提取特征的图像区域变大时,局部表示的全局性逐渐变强.受此启发,本文提出词袋模型的全局模式(Global Bag-of-Words,GBoW),即将提取底层特征的区域扩展到整幅图像.相关研究表明,人类是综合利用全局和局部信息对人脸进行辨识,因而一些学者提出融合全局和局部特征的识别算法,通常是在决策层将二者融合,不可避免地会损失部分判别信息,为此本文提出一种基于多核学习(Multiple Kernel Learning,MKL)的局部和全局特征融合算法.
2 相关工作
如何对人脸模式进行有效表示是自动人脸识别的关键步骤.基于子空间的特征表示是目前的主流方法,主成分分析[1](Principal Component Analysis,PCA)是其中的典型方法之一,该方法寻找最小均方差意义下的最优主成分分量,通过这些主成分的线性组合重构原始样本,从而达到最大限度去除图像特征中冗余信息的目的;而Fisher线性判别分析[2](Fisher Linear Discriminative Analysis,FLDA)寻找最优投影方向使得同类样本的离散程度和不同类样本的交叠程度在新的坐标系内同时达到最小,从而取得最佳的分类效果.
近年来,稀疏表示理论在人脸识别中的优异性能引起了学者们的广泛研究兴趣.Wright等[3]提出了一种稀疏表示分类(Sparse Representation Classification,SRC)方法,该方法通过求解带l1范数的最小化问题,使用训练样本线性组合给定测试样本,根据系数向量的稀疏性对测试样本进行分类决策;Zhang等[4]提出协同表示分类(Collaborative Representation Classification,CRC)方法,该方法使用l2范数代替l1范数求解原问题,从而解决稀疏表示在人脸识别中的实时性问题;与上述方法使用所有训练样本构建冗余词典不同,Yang等[5]提出构建紧致稳健字典的Metaface学习算法,该算法在每类训练样本中学习一组字典向量,根据类别词典上的稀疏重构残差对测试人脸图像进行分类判别;Yang等[6]提出利用Fisher准则函数在训练样本中寻找一组最优字典基向量.然而此类人脸识别方法仍然以提取图像中的全局特征为基础.
由于局部特征对光照、表情和姿态变化具有很好的鲁棒性,近年来在人脸识别中得到了广泛应用.例如,Gabor函数与人类视觉皮层感受野具有一致性,对于提取图像局部变化特征具有良好的特性,然而多尺度、多方向的Gabor变换会使人脸特征的维数急剧增加,为此文献[7]同时使用下采样和PCA降低Gabor特征的维数,然后使用增强Fisher鉴别分析完成识别;针对上述方法会造成大量分类特征信息丢失的问题,文献[8]利用LBP算子对Gabor特征进行编码,计算直方图统计特征作为分类判别依据;为了最大化利用特征信息并得到人脸特征的紧致描述,文献[9]将图像划分为若干小区域,计算小区域内所有像素Gabor系数的均值和方差,然后将所有区域特征拼接起来描述人脸图像;最近,Yang等[10]采用多尺度LBP金字塔模型描述人脸图像,提出一种基于局部统计特征的鲁棒核函数(Statistical Local Feature based Robust Kernel Representation,SLF-RKR)度量图像之间的相似性计算重建残差,测试样本最终被判定为重建残差最小的训练样本对应的类别.
另外,子图像方法也是人脸识别中获得成功应用的局部特征.文献[11]将人脸图像分割为相等大小的子图像,然后使用基于子图像构建的分量分类器对测试样本的相应子图像进行判别,最后使用加权投票方式对分类结果进行集成形成最后决策;文献[12]利用类内散度最小类间散度最大原则训练Volterra 核函数建立子图像与类别之间的映射,以学习得到的映射作为相似性度量建立最近邻分类器对测试样本的相应子图像进行分类,最后使用多数投票方法融合所有分类结果;最近,Zhu等[13]提出基于协同表示的子图像分类方法(Multi-Scale Patch based Collaborative Representation Classification,MSPCRC),该方法提取若干尺寸不等的子图像表征尺度信息,并利用CRC方法对测试样本的相应子图像进行分类,最后使用多数投票方式融合分类结果,可以很好的解决小样本问题.
3 本文方法
本文提出的多核学习融合局部和全局特征的人脸识别算法的总体框架如图1所示,各个环节的具体描述如图1.
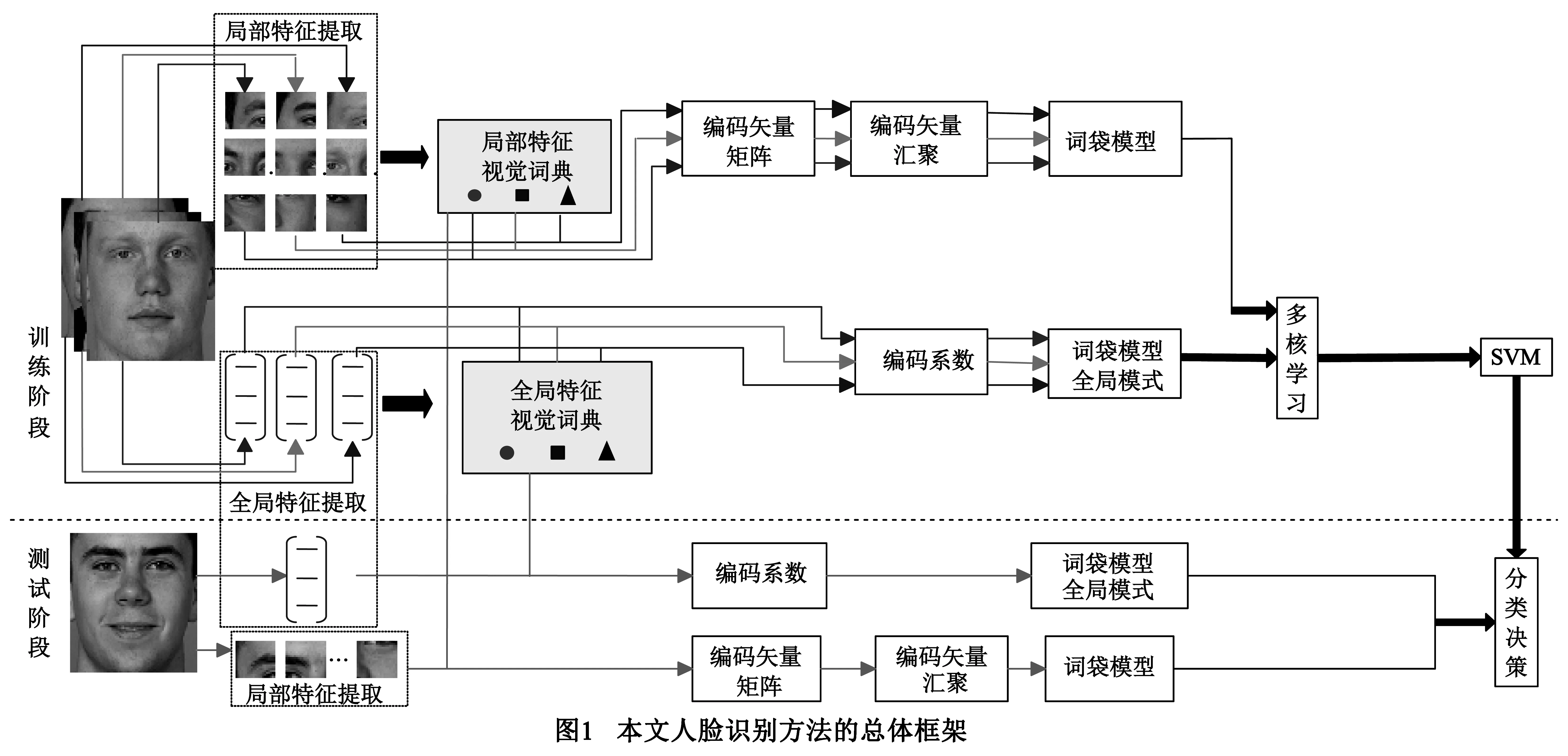
3.1 基于词袋模型的人脸特征描述
对于人脸图像数据集I={I1,I2,…,IN},经过局部特征提取之后,所有训练图像被表示为Y={y1,y2,…,yN},使用K均值算法对此局部特征集合Y进行聚类得到局部特征视觉词典VL=[v1,v2,…,vK]∈RD×K,vk∈RD×1,k=1,2,…,K表示第k个视觉单词向量,K为视觉单词数目,D为局部特征的维数.假设X=[x1,x2…,xT]∈RD×T表示数据集I中任意一幅人脸图像的局部特征集合,其中xt∈RD×1,t=1,2,…,T表示第t个局部特征矢量.在使用人脸数据库中所有图像的线性组合来表示一幅给定人脸图像时,其系数向量是稀疏的,其中同一类别图像的组合系数不为0,稀疏表示能够提供人脸图像合适的描述.同样对于人脸图像中的局部特征来说,稀疏编码也能够保证相似局部特征的组合系数不为0,对局部特征进行稀疏编码的表达式为:
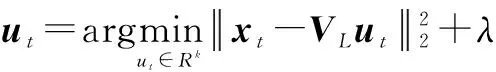
(1)

式(1)中,ut∈RK×1表示第t个局部特征的编码矢量,等式(1)右边第一项为拟合项,表示利用VL重构xt所产生的误差,第二项为稀疏惩罚项,保证对xt的表示是稀疏的,稀疏正则系数λ控制两项的比重,对其进行求解就得到xt在VL上的投影系数ut.
完成上述编码环节后,图像此时被表示为一个由T个K维矢量组成的集合,需要计算编码矢量的汇聚特征才能使用传统分类器对图像进行分类.人脸图像中的内容是按照一定的规律组织的,图像子区域之间的空间关系对于分类来说是有用的信息,因此使用空间金字塔模型对局部编码矢量进行汇聚.记l=0,1,…L为此模型的层次,总层数为L+1,则第l层在水平和竖直方向都将图像分成2l块,图像子区域的总数为2l×2l=4l块.图2展示的是使用划格方法得到金字塔的第0,1,2层,此模型能够实现各子区域之间的匹配,即使图像出现光照、表情、姿态以及遮挡等变化,也能够保证不变区域之间的匹配,因此能够进一步提高词袋模型对各种变化的鲁棒性.假设第l层金字塔模型的第i个子区域内有Ti个编码矢量,此区域内编码矢量的最大统计值的计算公式为:
(2)
3.2 基于全局特征的人脸特征描述
本文将词袋模型的全局模式作为人脸图像的全局特征描述,即将此模型提取底层特征的区域扩展到整幅图像,并利用人脸识别中经典的子空间特征表示方法对其进行描述,例如PCA、FLDA、ICA、LPP等.本文对上述四种经典全局特征进行了测试,其中FLDA引入了鉴别信息,性能最优,故本文均采用FLDA作为整幅图像的底层特征提取方法.
对于大小为p×q的人脸图像,通过首尾连接每列像素将其转换为向量,使用FLDA对其进行变换后,所有训练图像被表示为Z={z1,z2,…,zN}.与词袋模型一致,使用K均值算法对此全局特征集合Z进行聚类得到全局视觉词典VG=[v1,v2,…,vM]∈RC×M,M为视觉单词的数目,vm∈RC×1,m=1,2,…,M表示第m个视觉单词向量,dG∈RC×1表示相应的编码矢量,C是FLDA特征的维数,对特征z进行稀疏编码的表达式为:
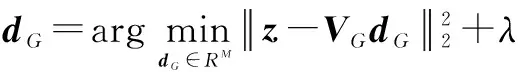
(3)
式(3)右边第一项为拟合项,表示利用VG重构Z所产生的误差,第二项为稀疏惩罚项,保证对Z的表示是稀疏的,常数λ控制两项的比重,对其进行求解就可以得到z在VG上的投影系数dG.
3.3 基于多核学习的局部与全局特征的融合
对于3.1得到人脸图像特征dB,假设所使用的核函数为KB,相应的权系数为hB,对于3.2得到人脸图像特征dG,假设所使用的核函数为KG,相应的权系数为hG.此时任意第i幅与第j幅人脸图像之间的相似性度量为:
K(i,j)=hBKB(dBi,dBj)+hGKG(dGi,dGj)
(4)
式(4)中,dBi、dGi分别表示第i幅图像的局部特征和全局特征,dBj、dGj分别表示第j幅图像的局部特征和全局特征,如果分类器选用支持向量机,二分类的情况下,多核学习方法的目标函数为:
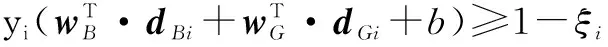
(5)
ξi≥0,i=1,2,…N
hB,hG≥0,hB+hG=1
式(5)中,yi为图像的类别标号,C为惩罚系数,ξi为松弛变量,wB、wG为分类器的参数,N为图像样本数目.采用分块协调下降算法求解式(5),首先固定hB和hG,式(5)转化为关于ξi、wB、wG的带线性约束的二次规划问题;然后固定参数ξi、wB、wG,式(5)转化为关于hB和hG的带线性约束的非线性最小化问题.交替求解上述两个问题,直到满足收敛条件就可以得到s个系数不为0的支持向量以及hB和hG的值,则对第j幅测试图像的分类判决函数为:
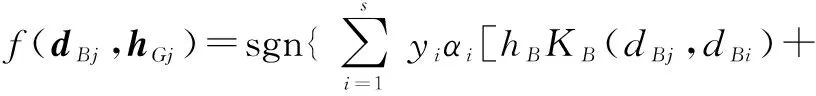
hGKG(hGj,hGi)]+b*}
(6)
式(6)中,αi,i=1,2,…,s表示第i个支持向量对应的系数,b*为分类阈值,可以用任一个支持向量求得.
4 实验与分析
在公开人脸数据库将本文方法与目前主流的PCA[1]、FLDA[2]、CRC[4]、FDDL[6]、RKR-SLF[10]、Volterrar[12]、MSPCRC[13]方法进行对比,使用作者提供的源代码和参数设置进行仿真实验.同时实验还给出单独使用词袋模型(BoW)和全局特征(GBoW)进行分类的性能.实验过程中通过尝试不同的参数设置得到最优结果.建立词袋模型过程中,实验结果显示图像小块的尺寸越小,其表征性能越优,然而太小不足以提取SIFT特征,因此将小块的尺寸设为8×8;并且密集采样步长越小,局部特征数目越多,其表征性能越优,因此将采样步长设为1;将视觉单词数目和空间金字塔模型的层数分别选定为1500和3,这是因为视觉单词的数目过少,不能充分编码图像中的局部特征,金字塔模型的层数过少,不能充分利用图像的空间信息,然而当单词数目大于1500以及层数大于3时所带来的计算复杂度的代价将远大于其分类正确率增加所带来的性能改善;另外,参数λ为0.5~1之间,性能相差无几,因此将稀疏正则系数设为0.5.多核学习过程中,基核函数为线性核函数,惩罚系数C设为10以上,性能相差无几,将外层和内层循环的迭代次数设定为200,足以求解多核学习模型的最优解.
4.1 AR数据库上的实验结果
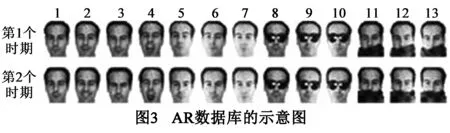
AR数据库包含126个人不同时期拍摄的26幅图
像,尺寸为50×40像素,如图3所示,不同时期的图像被归为不同的组,第1张为无表情变化图像,第2~4张为表情变化图像,第5~7张为光照变化图像,第8~10张为太阳镜遮挡图像,第11~13张为围巾遮挡图像.
首先验证不同训练样本数目下识别算法的性能.分别随机选取每个人的2,3,4,5幅图像作为训练数据,剩余的图像作为测试数据,重复选取10次.由表1中的结果可知:(1)在不同的训练样本数目下,本文方法的识别率最高,分别高于SLF-RKR方法1.80%、0.32%、0.76%、0.10%,说明本文方法可以很好的解决小样本问题;(2)本文方法的识别率高于BoW和GBoW,说明多核学习能够有效地将互补的局部和全局特征进行结合.
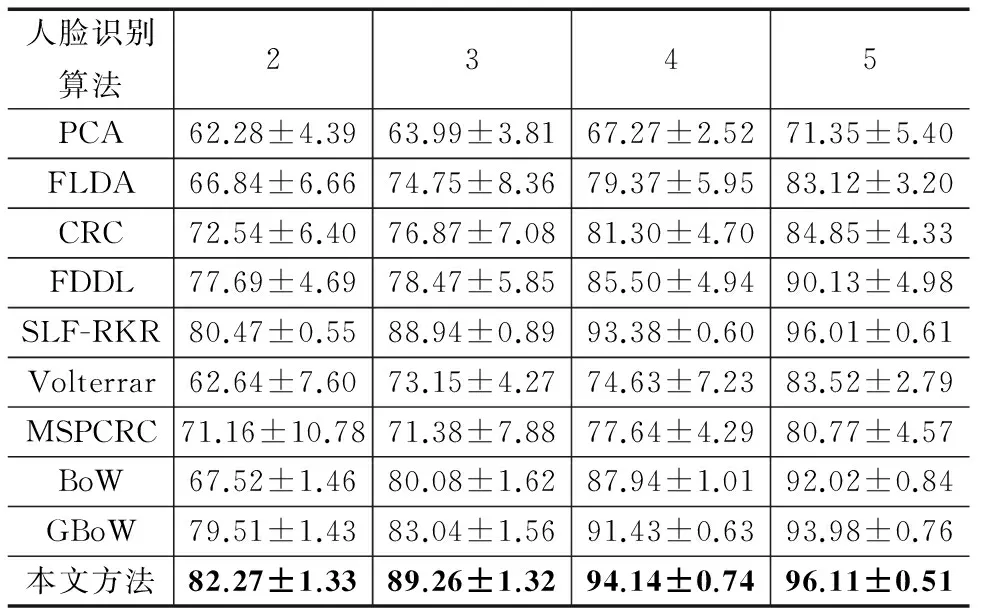
表1 AR数据库上不同训练样本数目下各种方法的 识别率±标准差(%)
使用文献[14]中的实验设置验证表情变化对识别算法的影响.将第1个时期拍摄的前7幅图像作为训练数据,将第2个时期拍摄的第2~4张表情变化的图像作为测试数据.由表2中的结果可知:(1)本文方法的识别率最高,高于SLF-RKR方法0.55%;(2)BoW的识别率高于GBoW,说明局部特征比全局特征在表情变化中起到更重要的作用.

表2 各种人脸识别算法在人脸表情变化子集上的识别率(%)
使用文献[10]中的实验设置验证遮挡对识别算法的影响.将第1个时期的前7幅无遮挡图像作为训练数据,将第1个时期的第8~10张图像(S1-Sunglass)、第11~13张图像 (S1-Scarf)、第2个时期的第8~10张图像(S2-Sunglass)、第11~13张图像(S2-Scarf)分别作为测试数据.由表3中的结果可知:(1)本文方法的识别率最高,分别高于SLF-RKR方法0.28%、0.28%、2.78%、0.44%;(2)只有BoW的识别率得到了提升并且高于GBoW,说明局部特征在遮挡情况下起到更重要的作用.
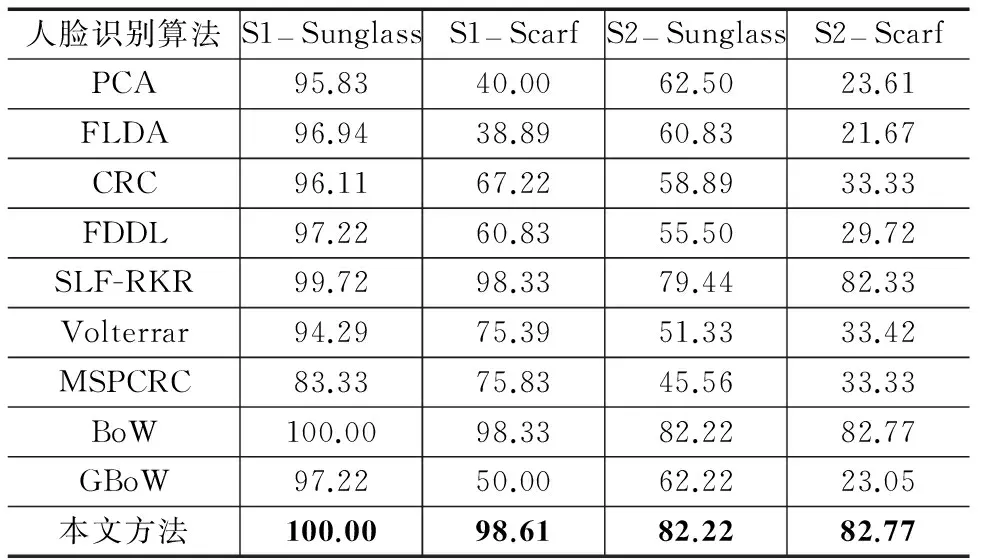
表3 各种人脸识别算法在遮挡变化子集上的识别率(%)
4.2 FERET数据库上的实验结果
FERET数据库包含1199个人的不同局部变化的图像.本文选择其中的一个姿态子库作为实验数据,该子库有200个人,每个人有7幅标号不同的图像,图像的尺寸为80×80像素,各种标号的含义如图4所示.

首先验证不同训练样本数目下不同人脸识别算法的性能.分别随机选取每个人的2,3,4,5幅图像为训练数据,剩余的图像为测试数据,重复选取10次.由表4中的结果可知:(1)在不同的训练样本数目下,本文方法的识别率最高,分别高于SLF-RKR方法12.07%、11.92%、8.71%、8.12%,说明本文方法可以很好的解决小样本问题;(2)本文方法的识别率高于BoW和GBoW,说明多核学习能够有效地将互补的局部和全局特征进行结合.
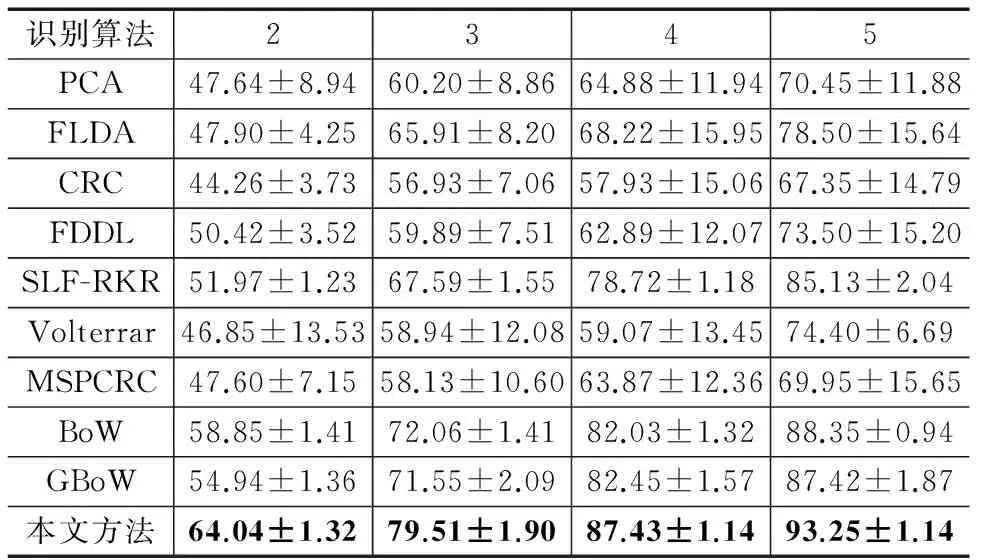
表4 FERET数据库上不同训练数目下各种方法的 识别率±标准差(%)
使用文献[10]中的实验设置验证姿态变化对识别算法的影响.将标号为‘ba’,‘bj’,‘bk’的图像作为训练数据,标号为‘bg’,‘bf’,‘be’,‘bd’的图像分别作为测试数据.由表5中的结果可知:(1)当姿态角从-25°变化到+25°,本文方法的识别率最高并且非常稳定,分别高于SLF-RKR方法49.00%、0.50%、11.00%、42.00%,表明本文方法对姿态的变化具有更好的鲁棒性;(2)BoW的识别率高于GBoW,说明局部特征在姿态变化时起到更重要的作用.
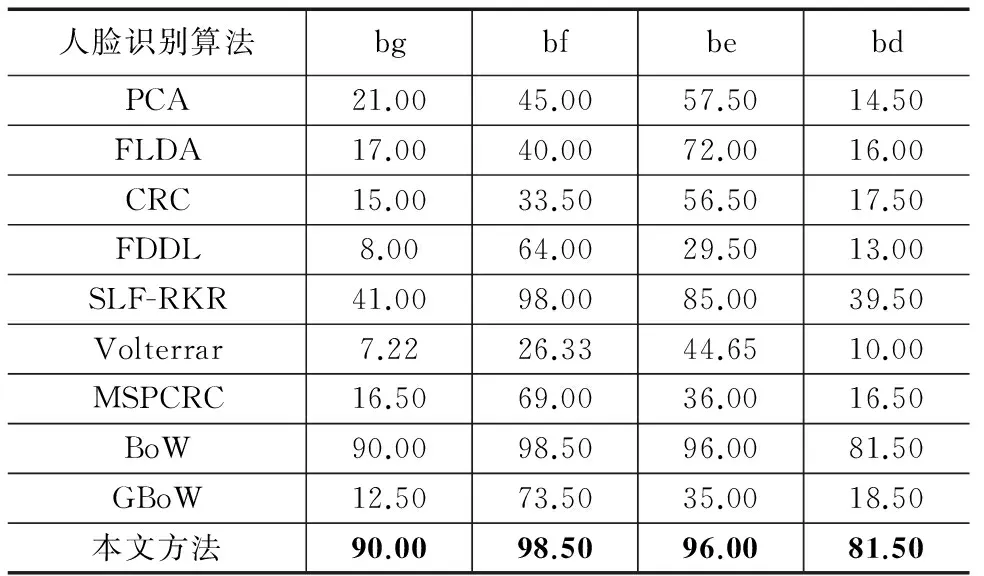
表5 各种人脸识别算法在姿态变化子集上的识别率(%)
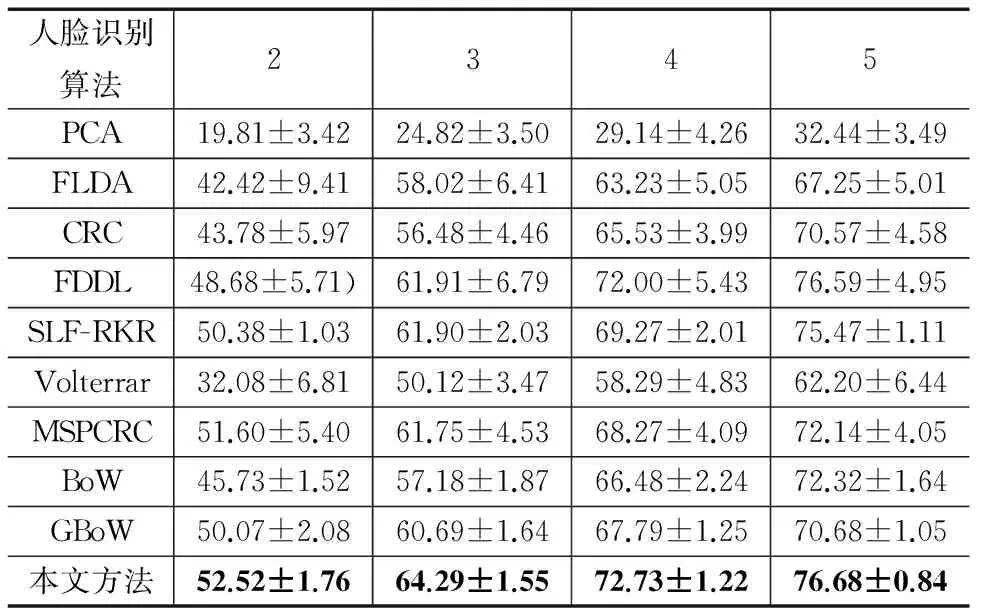
表6 CMU PIE数据库上不同训练数目下各种方法的 识别率±标准差(%)
4.3 CMU PIE数据库上的实验结果
CMU PIE包含68个人的不同局部变化的图像,本文使用文献[15]提供的五个子集进行实验,示例图像见图5.在此数据库上验证不同训练样本数目下人脸识别算法的性能,分别随机选取每个人的2,3,4,5幅图像作为训练数据,剩余的图像作为测试数据,重复选取10次.由表6中的结果可知:(1)本文方法的识别率最高,训练数目为2时,高于MSPCRC方法0.92%;训练数目为3、4、5时,高于FDDL方法2.38%、0.73%、0.09%,说明本文方法可以很好的解决小样本问题;(2)本文方法的识别率高于BoW和GBoW,说明多核学习能够有效地将互补的局部和全局特征进行结合.
4.4 LFW数据库上的实验结果
LFW数据库包含5279人的13233张图片, LFW-a是利用商业校准软件进行校准之后的版本,与文献[13]一致,本文使用其中样本数目不少于10幅的158个人的图像进行实验,图像的尺寸为32×32像素,示例图像见图6.在此数据库上验证不同训练样本数目下人脸识别算法的性能,分别随机选取每个人的2,3,4,5幅图像作为训练数据,剩余的图像作为测试数据,重复选取10次.由表7中的结果可知:(1)本文方法的识别率最高,分别高于MSPCRC方法0.40%、0.58%、3.46%、5.70%,说明本文方法可以很好的解决小样本问题;(2)本文方法的识别率高于BoW和GBoW,说明多核学习能够有效地将互补的局部和全局特征进行结合.
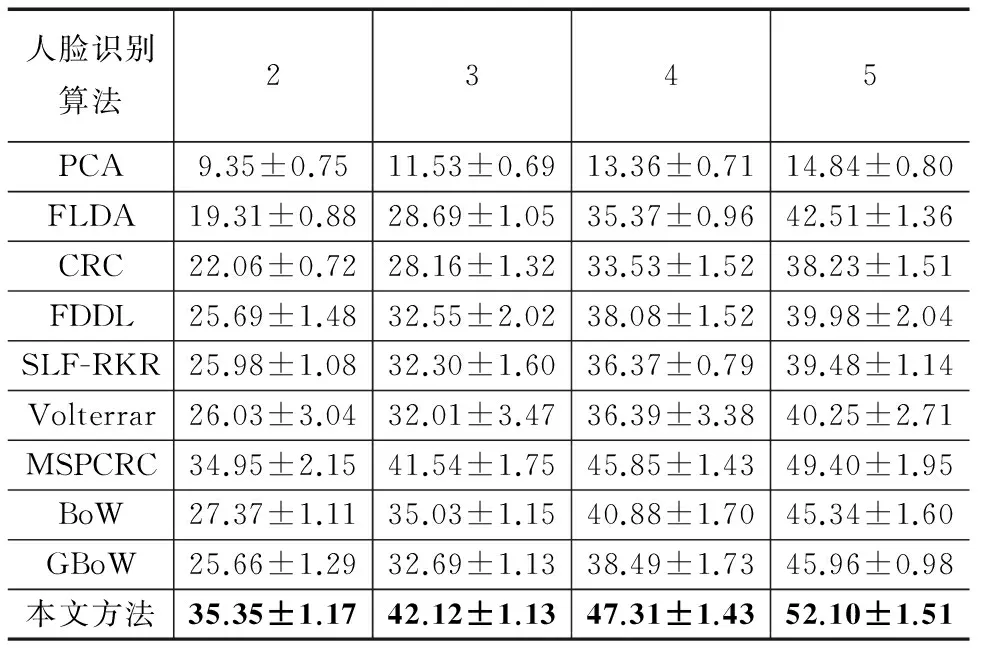
表7 LFW数据库上不同训练样本数目下各种方法的 识别率±标准差(%)

5 总结
本文提出将词袋模型作为人脸图像的局部特征描述,同时提出词袋模型的全局模式,并将其作为人脸图像的全局特征描述,最后使用多核学习方法将二者进行融合.公开人脸数据库上的实验结果表明:(1)本文方法能够很好地解决小样本问题;(2)多核学习方法能够有效地将互补的局部和全局特征进行结合;(3)本文方法对人脸的表情变化、姿态变化以及遮挡具有良好的鲁棒性.
[1]Lai Z H,Xu Y,Chen Q C,Yang J.Multilinear sparse principal component analysis[J].IEEE Transactions on Neural Networks and Learning Systems,2014,25(10):1942-1950.
[2]Wang H X,Lu X S,Zheng W N.Fisher discriminant analysis with L1-norm[J].IEEE Transactions on Cybernetics,2013,44(6):828-842.
[3]Wright J,Yang AY,Ganesh A,Satry S S,Ma Y.Robust face recognition via sparse representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-226.
[4]Zhang L,Yang M,Feng X C.Sparse representation or collaborative representation:which helps face recognition[A]? Proceedings of the 13th IEEE International Conference on Computer Vision[C].Barcelona,Spain:IEEE Computer Society,2011.471-478.
[5]Yang M,Zhang L,Zhang D.Metaface:learning for sparse representation based face recognition[A].Proceedings of the 17th International Conference on Image Processing[C].Hong Kong,China:IEEE Computer Society,2010.1601-1604.
[6]Yang M,Zhang L,Feng X C,Zhang D.Sparse representation based Fisher discrimination dictionary learning for image classification[J].International Journal of Computer Vision,2014,109(3):209-232.
[7]Liu C,Wechsler H.Gabor feature based classification using the enhanced Fisher linear discriminant model for face recognition[J].IEEE Transactions on Image Processing,2002,11(4):467-476.
[8]张文超,山世光,张洪明,陈杰,陈熙林,高文.基于局部Gabor变化直方图序列的人脸描述与识别[J].软件学报,2006,17(12):2508-2517.
Zhang Wenchao,Shan Shiguang,Zhang Hongming,Chen Jie,Chen Xilin,Gao Wen.Histogram sequence of local Gabor binary pattern for face description and identification[J].Journal of Software,2006,17(12):2508-2517.(in Chinese)
[9]李宽,殷建平,李永,刘发耀.基于Gabor系数分块统计和自适应特征选择的人脸描述与识别[J].计算机研究与发展,2012,49(4):777-784.
Li Kuan,Yin Jianping,Li Yong,Liu Fayao.Local statistical analysis of Gabor coefficients and adaptive feature extraction for face description and recognition[J].Journal of Computer Research and Development,2012,49(4):777-784.(in Chinese)
[10]Yang M,Zhang L,Shiu S,Zhang D.Robust kernel representation with statistical local features for face recognition[J].IEEE Transactions on Neural Networks and Learning Systems,2013,24(6):900-912.
[11]Tan K R,Chen S C.Adaptively weighted subpattern PCA for face recognition[J].Neurocomputing,2004,64:505-511.
[12]Kumar R,Banerjee A,Vemuri B C.Volterafaces:discriminant analysis using volterra kernels[A].Proceedings of the 22nd Conference on Computer Vision and Pattern Recognition[C].Miami,USA:IEEE Computer Society,2009.150-155.
[13]Zhu P F,Zhang L,Hu Q H,Shiu S.Multi-scale patch based collaborative representation for face recognition with margin distribution optimization[A].Proceedings of the 12th European Conference on Computer Vision[C].Florence,Italy:Springer-Verlag,2012.822-835.
[14]朱玉莲,陈松灿.特征采样和特征融合的子图像人脸识别方法[J].软件学报,2012,23(12):3209-3220.
Zhu Yulian,Chen Songcan.Sub-image method based on feature sampling and feature fusion for face recognition[J].Journal of Software,2012,23(12):3209-3220.(in Chinese)
[15]Cai D,He X F,Han J W,Zhang H J.Orthogonal Laplacian faces for face recognition[J].IEEE Transactions on Image Processing,2006,15(11):3608-3614.

杨 赛 女,1981年出生,山东滨州人.2015年获南京理工大学博士学位,现为南通大学讲师,研究方向为计算机视觉与机器学习.
E-mail:yangsai166@126.com

赵春霞 女,1964年出生,北京人.1985年、1988年和1998年在哈尔滨工业大学分别获得工学学士、工学硕士和工学博士学位,现为南京理工大学教授,博士生导师.主要研究方向为地面智能机器人与复杂环境理解.
Fusion of Local and Global Features Using Multiple Kernel Learning for Face Recognition
YANG Sai1,ZHAO Chun-xia2,LIU Fan3
(1.SchoolofElectricalEngineering,NantongUniversity,Nantong,Jiangsu226019,China;2.SchoolofComputerScienceandEngineering,NanjingUniversityofScienceandTechnology,Nanjing,Jiangsu210094,China;3.CollegeofComputerandInformation,HohaiUniversity,Nanjing,Jiangsu210098,China)
A new face recognition algorithm via bag-of-words(BoW) is proposed.In specific,it uses BoW and the global pattern of BoW respectively as the local feature and global feature of face images.Multiple kernel learning is adopted to fuse the local and global features.Extensive experiments were carried out on four face databases,i.e.AR,FERET,CMU PIE and LFW.The results show that our method can effectively solve the small training size problem and is more robust to expression changes,position variations and occlusion.
bag-of-words;global feature;multiple kernel learning;face recognition
2015-03-20;
2015-07-21;责任编辑:李勇锋
国家自然科学基金面上项目(No.61272220);国家青年科学基金(No.61103059,No.61101197)
TP391.4
A
0372-2112 (2016)10-2344-07
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.10.009
