基于Hadoop分布式平台的Web文本关键词提取方案
2016-11-26姚卫国张东波
姚卫国, 张东波
(1.南昌理工学院 计算机信息工程系,江西 南昌 330044;2.华南理工大学 土木与交通学院,广东 广州 510641)
基于Hadoop分布式平台的Web文本关键词提取方案
姚卫国1*, 张东波2
(1.南昌理工学院 计算机信息工程系,江西 南昌 330044;2.华南理工大学 土木与交通学院,广东 广州 510641)
针对海量Web文本的关键词提取问题,提出一种基于Hadoop分布式计算平台的关键词提取方案.首先,配置Hadoop平台,使其能够支持自然语言处理过程;然后,使用GATE工具对Web文本进行词句分割、词性标注和注释规则操作,得到候选关键词集;最后,利用单词位置和跨度重要性因子对传统TF-IDF算法进行加权,从而计算候选关键词与文档之间的相关性,最终获得该文档的关键词以标注文档属性.实验结果表明,提出的分布式关键词提取方案能够快速准确地提取Web文档的关键词.
Web文本;关键词提取;Hadoop平台;自然语言处理;分布式
为了提高信息获取的速度,从非结构化、无语义的Web[1]文档中准确提取出与Web文档主题紧密相关的关键词成为当前的研究热点[2,3].Hadoop[4,5]作为一种比较流行的分布式云计算框架,对于解决海量数据问题,比起价格昂贵的大型计算机,拥有十分明显的优势.
目前,有学者提出了一些基于Hadoop平台的自然语言处理(NLP)技术,例如[6]在Hadoop平台上设计了一种适用于大规模处理和查询的多语言NLP系统,支持文本标记、文本分析等应用.然而,该系统中Hadoop的分布式文件系统(HDFS)数据的读写量太大,严重影响了数据处理速度.
为此,本文提出一种基于Hadoop平台的Web文本关键词提取技术,首先,配置Hadoop平台,使其能够支持NLP过程;然后,使用GATE工具的ANNIE组件对Web文本进行词句分割、词性标注和注释规则操作,得到候选关键词集;最后,利用改进的词率-逆文档频率(TF-IDF)算法计算候选关键词和文档的相关性,最终获得该文档的关键词以标注文档属性.实验结果表明,关键词提取系统能够快速准确地提取Web文档的关键词.
1 Hadoop关键词提取架构
Hadoop作为一种分布式系统基础架构,在底层可以实现对集群的管理和控制,在上层可以快速构建企业级应用.其包括分布式计算编程模型MapReduce、分布式文件系统HDFS、分布式数据库Hbase等组件.
本文在分布式Hadoop平台上,实现真实语料库上的NLP应用,将开源GATE嵌入到Java APIs中,来执行NLP任务,并描述了从非结构文本中提取关键词的过程.为了提高计算架构的性能,并提高数据完整性和故障处理能力,本文选择Apache Hadoop 框架来实现高效可扩展的解决方案.在多节点集群中安装HDFS文件系统.集群中,主节点将任务分配给不同的数据节点,并监测它们的执行过程和处理数据故障.图1描述了本文Hadoop系统框架.其中,关键词提取模块中的Map和Reduce函数可由程序员定制.Map函数用来产生一个键-值对,其由每个分析文档的Web域组成.Reduce函数用来满足GATE程序的执行.
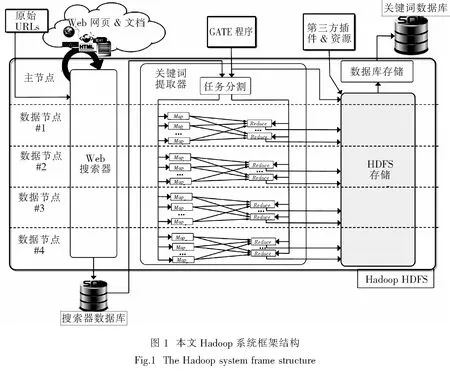
本文使用MapReduce编程模型来并行执行信息搜索工作和NLP任务,最后将输出写入外部SQL数据库.本文框架有两种文件输入途径:第一种为局部文件系统上的某个位置,此处储存着GATE应用和必备插件;另一个为一个文本文件,包含信息搜索模块的初始网址.其中,信息搜索阶段和关键词提取阶段可以独立执行.最终,将提取出来的关键词存储到外部SQL数据库中.
1.1 MapReduce
MapReduce的基本思想是将执行过程划分为多个更小的任务,Mapper和Reducer分别用于实现Map和Reduce函数,以此定义在输入数据上执行特定的原子操作[7].Hadoop根据HDFS块的大小(默认设置为64 MB),将数据划分为固定大小的组件.MapReduce为每次分割分配一个Map任务.MapReduce的基本数据结构是键-值对,键-值对是由Map和Reduce函数的输入和输出组成.键-值对可以是数值、字符串,或更复杂的对象,如数组、列表等.Map函数生成一个中间输出,键-值对表示来自输入数据源的逻辑记录(例如,它可以是文本文件中的单一文本行,或者数据库中的一行记录).随后,Shuffle和Sort过程合并所有具有相同键值的中间值.将经过分类的键-值对作为Reduce函数的输入,Reduce函数在分割的输入数据上执行相应过程.上述整个过程可描述如下:
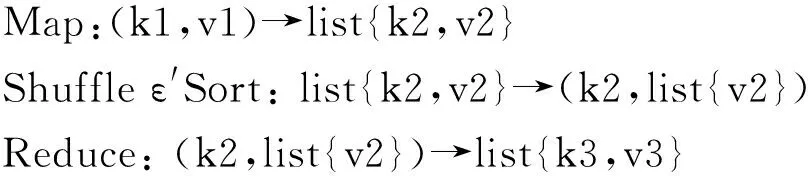
MapReduce具有一种复杂抽象的通用并行管理框架,这使得程序员只需要关注Map和Reduce函数的定义,无需考虑更低层约束(例如,并行化、工作划分和集群节点间的通信问题).总之,整个计算处理过程都可以视为用键-值对处理问题的过程.
1.2 网络信息搜索
本文系统的信息搜索引擎基于开源的Apache Nutch[8]工具设计.其初始化为一个包含商业公司、服务和研究机构网址的初始URL集合.Nutch工作流程由多个阶段构成:1) 注入阶段,注入初始URL进行初始化引导;2) 生成阶段,定义将要获取的URL集合;3) 获取阶段,获取并分割先前生成的URL集合为片段;4) 分析阶段,分析获取的划分内容;5) 更新阶段,利用导航URL和对应片段的解析内容更新外部SQL数据库.所有这些操作由一个单一MapReduce任务执行,且各阶段输出均存储到本地HDFS.最后,利用Apache Solr来索引所有收集的文档,并提供一个搜索界面.其中,Solr索引只安装在主节点上.
1.3 候选关键词提取器
该模块将信息搜索阶段获取的每个Web URL相关联的解析文本作为输入,并通过查询Solr索引进行恢复.本模块用于定义MapReduce模型,即设计合理的Map和Reduce函数,用以执行GATE程序.在本文中,Map和Reduce函数做如下定义:由于我们关注单一Web域级别上的注释关键词,所以设计的Map函数需要与键-值对进行关联.其中,从单页面的Web URL中提取key,在上述信息搜索中的Nutch阶段提取value.Reduce函数需满足配置和多语料库GATE程序的执行条件(每个语料库所包含的文本文件仅属于单个Web域),以及随后在Web域级上关键词的相关性估计.
1.4 GATE应用

这一模块负责依据输入文件(通常是a.xgapp或.gapp文件)中定义的输入配置参数和流水线,在MapReduce环境中执行GATE程序.为了满足GATE程序的需求,应用ANNIE(较新的信息提取系统)插件作为句子分割和标记工具,用于Web文本内容分割;应用TreeTagger插件用于词性标注.最后,应用JAPE(java注释图形引擎)插件来定义语法规则,用于过滤掉文本中不需要的部分和停留词.然后,标注普通名词和形容词作为潜在的候选关键词.最后,将候选关键词的逻辑组合作为最终关键词.GATE流水线的描述如图2所示.
在MapReduce中执行GATE程序需要满足以下因素:主节点负载、运行时间、一个包含所有GATE API的文件压缩包、HDFS分布式缓存中的配置文件、应用文件、库和插件.这样,GATE程序可以一次性从内存中提取所需文件,并且所有数据节点都可以访问对应的分配内容.这是目前最有效的解决方案,因为不需要在每个节点上都安装插件和库文件.另外,正如前文所述,可以利用上述结构(具有NLP的所有特征和功能)在后台执行GATE程序,并提供xgapp应用程序文件和jape文件,用于标注规则和模式,以及输入ZIP文件中的资源和插件.
2 基于改进TF-IDF的关键词关联性分析
在计算文档关键词相关性之前,需要对文档进行预处理,过滤掉停留词和非相关术语,例如自然语言中高频率使用的冠词或连词,因为它们不包含有意义的信息.在预处理之后,本文利用一种改进型的TF-IDF (词频-逆文档频率)算法来计算关键词与文本的关联性.
本文提出一种位置和跨度加权的TF-IDF算法,用来计算从文档中提取出的候选关键词的相关性,且所有文档都只属于单一的Web域.传统TF-IDF值由两个函数组成[9]:词频(TF),表示为文章中候选关键词出现的频率;逆文档频率(IDF),表示候选关键词的普遍重要性,一般由出现关键词的文档数除以总文档数,再将商取对数获得.语料库D中文本d的候选关键词k的TF-IDF值,计算如下:
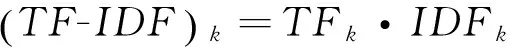
(1)

然而,传统TF-IDF只根据关键词的出现频率来计算相关性,没有考虑到关键词的其他权重度量[10].本文对传统TF-IDF进行改进,融入了位置加权和跨度加权两个因素.
位置加权:通常情况下,出现在文本标题中的词往往比出现在正文中的词更能表示文本主题,其作为全文关键词的概率较大.因此,本文设定mi表示关键词位置权重,当关键词出现在标题中时,设定mi=10,当关键词出现在正文中时,设定mi=1.

那么,改进后的TF-IDF算法表达式为:
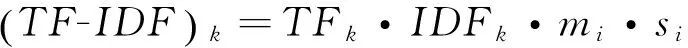
(2)
将高于设定TF-IDF阈值的候选关键词作为最终的关键词.然后,将提取的关键词,以及它们对应的TF-IDF值和源网站的域名URL,都存储在Hadoop上的HDFS文件系统中.
3 实验及分析
本文构建一个包含2 000个Web文本的数据集,来评估本文系统的有效性.Web数据集由本文分布式Web搜索模块获得.实验中,Hadoop集群结构采用了不同的测试配置,节点从2到5个不等.每个节点都是一个Linux 8内核工作站,并都配备HDFS.为了避免由于集群节点退役或重新服役导致数据完整性问题,设定Hadoop支持集群中活动节点的存储平衡.
MapReduce模型提供了任务的推测执行功能和容错处理功能.通过这种方式,JobTracker就可以重新安排失败的任务,但这会影响整个过程的执行时间.因此,为了公平比较,在每个节点配置时,为各个测试实例已选定了最佳处理时间.通过这种方式,试图重新执行失败任务的数量将会最小化.
本文系统在2 000个测试实例中共提取了近9万个关键词.表1中显示了本文系统在不同配置测试节点上的处理时间结果.可以看出,在不具备Hadoop平台的工作站上,在相同语料库上执行GATE程序的耗时约为18 h.而在Hadoop集群平台上的处理时间要远远小于前者,存在着显著的性能差距.这是因为在无Hadoop平台的工作站中,编写独立GATE程序的java代码没有做多线程优化.而本文Hadoop MapReduce自适应配置参数,能够最大数量地并行执行Map和Reduce任务.另外,从表1还可以看出,随着Hadoop集群中节点数量的增加,应用的处理时间也随之减少,当集群中具有5个节点时,只需要约2 h就能完成所有Web文本的关键词提取任务.
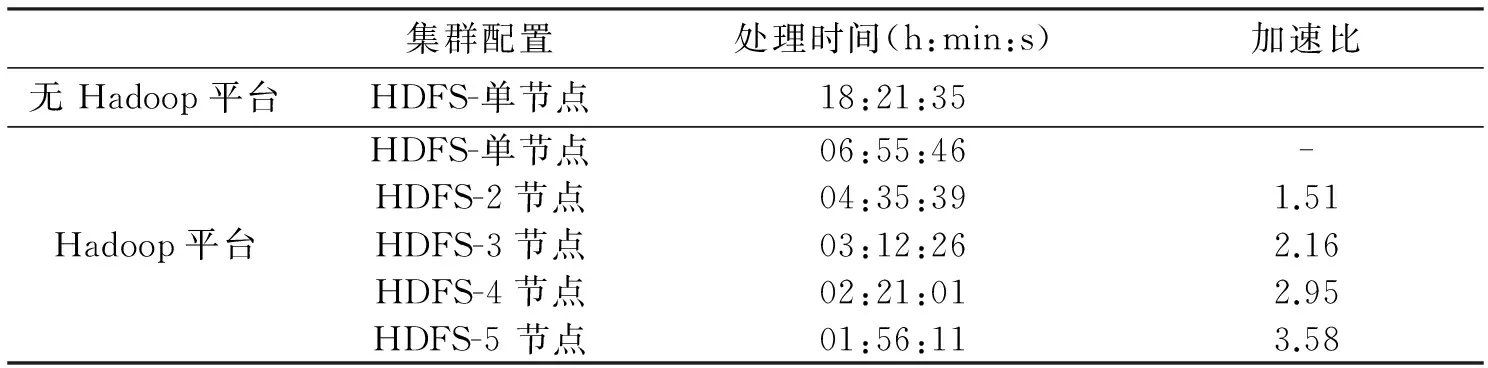
表1 在不同Hadoop集群配置上的执行时间
在同样的平台上,将本文系统与文献[6]系统在处理时间上进行比较,在不同节点数量下,实验数据集中的任务处理时间的加速曲线如图3所示,其中虚线为理想的加速度曲线.
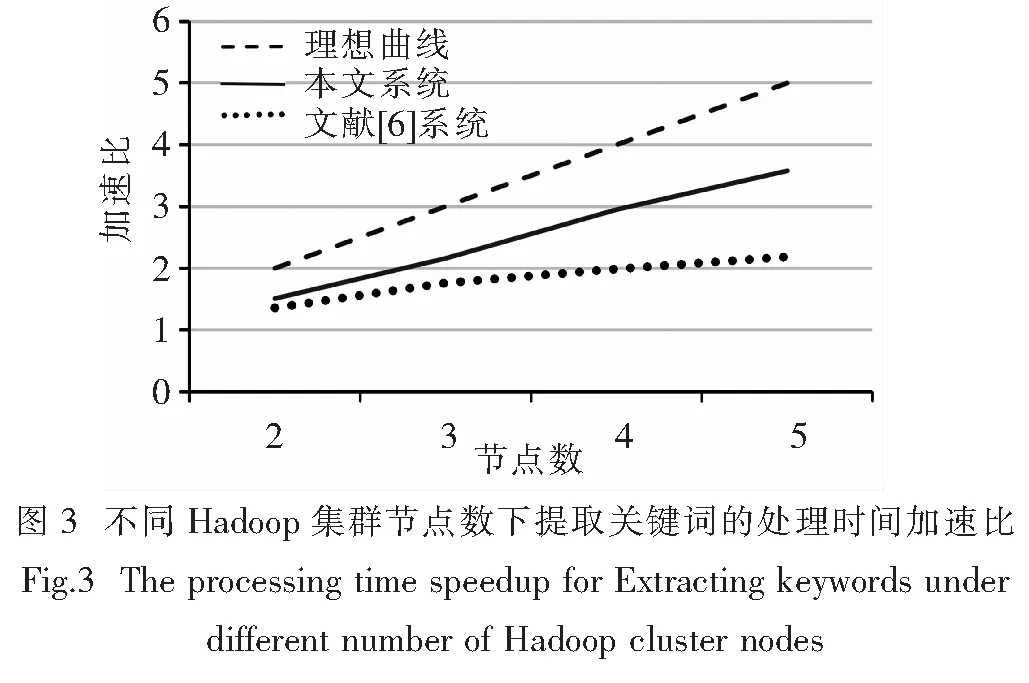
从图3可以看出,各系统的扩展性能随着Hadoop集群节点数呈线性增长,其中本文方案在不同节点数量下的加速比要明显优于文献[6]的系统,在节点数为5时,本文系统的加速度比文献[6]提高了1倍,处理时间比文献[6]减少了约1 h.这是因为HDFS上的每个同步过程中,每个节点都将在HDFS中读和写一些数据,增加网络负载,这是Hadoop集群的一个瓶颈问题. 然而,本文系统中关键词提取过程没有额外的网络访问,最大限度地减少了瓶颈问题.
4 结束语
本文提出了基于Hadoop分布式计算平台的Web文本关键词提取技术,利用Hadoop平台提供并发结构,利用NLP开源平台GATE程序进行文本注释和候选关键词提取,利用改进的TF-IDF算法计算候选关键词与文档之间的相关性来确定最终关键词.实验结果表明,本文系统能够快速地提取Web文本关键词,在计算时间方面,比非Hadoop平台系统速度提高了3倍,并优于现有Hadoop平台的提取方案.
[1] 张新林, 尹向东. Web导航行为范畴模型一致性与安全性研究[J]. 湘潭大学自然科学学报, 2012, 34(2): 111-116.
[2] 徐戈, 王厚峰. 自然语言处理中主题模型的发展[J]. 计算机学报, 2011, 34(8):1 423-1 436.
[3] TABLAN V, BONTCHEVA K. Gate cloud.net: a platform for large-scale, open-source text processing on the cloud[J]. Philosophical Transactions, 2012, 37(3): 1 970-1 970.
[4] 王磊, 陈刚, 陆忠华. 基于云计算的高效科学计算应用软件框架[J]. 华中科技大学学报:自然科学版, 2011, 39(1): 166-169.
[5] 李宝禄, 张伟. 基于Hadoop平台的并行特征匹配算法研究[J]. 计算机应用研究, 2014, 31(11): 135-142.
[6] NESI P, PANTALEO G, SANESI G. A distributed framework for NLP-based keyword and keyphrase extraction from web pages and documents[C]// 21st International Conference on Distributed Multimedia Systems (DMS'2015). 2015:247-255.
[7] 王洁, 于颜硕, 周宽久,等. 基于MapReduce的Web标签SOINN聚类算法[J]. 计算机科学, 2014, 41(12): 197-201.
[8] 周世龙, 陈兴蜀, 罗永刚. Hadoop视角下的Nutch爬行性能优化[J]. 计算机应用, 2013, 33(10): 2 792-2 795.
[9] SHIGEMATSU R, UTSUGI T, KATO T. Automatic image classification using graphical features and keyword evaluation with Tf-idf method[J]. Human Brain Mapping, 2012, 33(2): 319-333.
[10] KHODAEI A, SHAHABI C, LI C. SKIF-P: a point-based indexing and ranking of web documents for spatial-keyword search[J]. Geoinformatica, 2012, 16(3): 563-596.
责任编辑:龙顺潮
Web Text Keyword Extraction Scheme Based on the Hadoop Distributed Platform
YAOWei-guo1*,ZHANGDong-bo2
(1.Computer Information Engineering Department, Nanchang Institute of Technology, Nanchang 330044; 2. School of Civil and Transportation, South China University of Technology, Guangzhou 510641 China)
For the issues that the keyword extraction of massive Web text, a web text keyword extraction scheme based on the Hadoop distributed platform is proposed. First, The Hadoop platform is configured to support natural language processing.Then, the GATE tool is used to perform words segmentation, part of speech tagging and annotation rules for Web text, and get a set of candidate keywords. Finally, the TF-IDF algorithm which weighted by the word position and span factor is used to calculate the correlation between candidate keywords and documents, and obtain the document keywords to indicate document properties. Experimental results show that the distributed keyword extraction system can quickly and accurately extract the key words of Web documents.
Web text; keyword extraction; Hadoop platform; natural language processing; distributed
2016-01-23
国家自然科学基金项目(61203164,61174184)
姚卫国(1975-),男,江西 新干人,副教授. E-mail:yaoweiguonclg@126.com
TP391
A
1000-5900(2016)02-0079-05