基于需求的三级映射管理的闪存转换层算法
2016-11-24韩晓军王举利南高会娟
韩晓军王举利,张 南高会娟
(1.天津工业大学电子与信息工程学院,天津 300378;2.北京兆易创新科技有限公司,北京 100083)
基于需求的三级映射管理的闪存转换层算法
韩晓军1王举利1,2张 南1高会娟2
(1.天津工业大学电子与信息工程学院,天津 300378;2.北京兆易创新科技有限公司,北京 100083)
使用NAND Flash作为存储介质的存储设备常需要闪存转换层(FTL)对NAND进行管理.页映射是一种常见的映射方式,但需要很大的内存存放页映射表.针对该问题,提出了基于需求的三级映射管理的闪存转换层算法(TFTL).映射表保存在NAND闪存块中,减轻SRAM的压力,采用页置换法把需求的映射表搬移到SRAM中.由TFTL算法与Page mapping FTL、FAST、DFTL的对比分析可知:NAND闪存块擦除次数均衡性较好,系统响应时间和系统响应时间的标准差与Page mapping FTL等算法差异小.
三级映射管理;NAND闪存;闪存转换层;地址映射;垃圾回收;磨损均衡
通常,闪存转换层[1-2]固化在控制器中,接收前段解析的命令和控制后端NAND闪存阵列.控制器作为主机和NAND阵列的桥梁,同时借助于其内部的闪存转化层,可以简化主机端文件系统的操作.文件系统访问嵌入式多媒体卡(eMMC)时,可以像访问传统机械硬盘一样.闪存转换层内部主要算法包括:地址映射[3]、垃圾回收[4]、磨损均衡[5]、数据恢复[6]等.地址映射实现逻辑地址到物理地址的映射;磨损均衡和垃圾回收平衡每个NAND闪存的擦除次数和搬移有效数据回收垃圾NAND闪存;数据恢复确保数据的稳定性和数据意外丢失的恢复.在eMMC内部软件架构中,主机端发送请求,控制器内部经过NVME、SATA、eMMC等协议解析主机的请求,闪存转换层接收到请求,执行请求的任务:读写或者擦除底层NAND闪存[7-8].主机端的每一个请求必须经过闪存换层的解析,因此闪存转换层在eMMC内部有着十分重要的作用.闪存转换层算法的复杂度和算法的运行速度对eMMC的性能有决定性的影响[9],但闪存转换层算法的保密性和特殊性,使得每个厂家生产出来的eMMC内部算法都不一样.所以在闪存转换层算法研究时需要模拟NAND底层,仿真实现和测试闪存转换层算法的性能,避免在真实的NAND闪存块中运行失败.
页映射是一种高效的映射方法,可以在逻辑页和物理页之间直接建立映射关系,每个映射关系建立一条映射条目.页映射逻辑简单,易于实现,但页映射需要很大的内存空间来存储完整的映射表,在内存较小的控制器中难以实现.为了更好地利用有限的SRAM空间,Gupta[10]提出了DFTL算法,可以较好地减少垃圾回收负荷,同时仅需要较小的内存空间.DFTL算法不像传统的方法将映射表存储在SRAM里面[11],而是把所有的映射表存储在NAND闪存里[12],根据负载访问方式动态的上传和下载映射表.本文基于DFTL设计TFTL,TFTL采用页映射算法用来管理逻辑页到物理页的映射关系.设计中通过root、segment、zone三级映射关系来管理逻辑页和物理页的对应关系.
1 三级映射管理的闪存转换层(TFTL)
1.1 TFTL映射算法
DFTL算法中,NAND闪存分为数据块和转换块,数据块只能存放用户数据,转换块只能存放映射表.在实际应用中,用户数据会经常更新,导致数据块的擦写次数下降的速度较快.转换块存放的映射表,更新速度慢,占用的NAND闪存的擦写次数下降的速度较慢.这必然会导致数据块和转换块擦写次数不均衡,数据块已经达到NAND闪存擦写的最大极限,但转换块擦写次数很少,没有达到NAND闪存擦写的最大极限.这种情况不论是动态磨损均衡还是静态磨损均衡都不能保持NAND闪存擦写次数的均衡性,致使NAND闪存的利用率较低.
为了改进DFTL在磨损均衡中的磨损均衡的缺陷,本文提出了TFTL算法,其如图1所示.
TFTL不区分NAND闪存数据块和转换块,数据和映射表可以共用所有可用的NAND闪存,但一个NAND闪存中仅保存一种数据,不可能既保存用户数据又保存映射表.NAND闪存在使用的过程中,用状态位标识NAND闪存块中存储的内容,映射表以TABLE作为标志,数据区以LOG作为标志.在NAND闪存写满数据时,转变为VALID状态.eMMC擦除NAND闪存时,NAND闪存的状态转变为初始状态INVALID.初始状态的NAND闪存,可以存放任何数据.映射表记录NAND闪存中逻辑页到物理页的映射关系.映射表的更新,仅在NAND闪存数据写满时.如果NAND闪存没有写满数据,建立一张位图表标识NAND闪存中存有数据.NAND闪存的最后一页,保存映射反表,记录物理页到逻辑页的映射关系.垃圾回收时,利用映射表和映射反表的映射条目一致性,判定数据的有效性.

图1 TFTL设计原理图Fig.1 Schematic of TFTL
1.2 TFTL映射算法设计
TFTL采用页映射算法用来管理逻辑页到物理页的映射关系.设计中通过root、segment、zone三级映射关系来管理逻辑页和物理页的对应关系.设计32个root管理32个segment,每个segment管理2 000个zone,每个zone管理250个映射条目,总共有16 000 000条映射条目.如果每一个物理页存放的数据是8 kB,则eMMC最大容量是64 GB.root、segment、zone三级管理层次关系如图2所示.

图2 三级管理映射关系Fig.2 Management of three-level mapping
图2 中:segment和root记录页映射的映射信息,zone实现最基本的页映射.root一级管理,记录最新的segment位置;segment二级管理,记录zone的序号,实现zone条目的管理;zone三级管理,记录逻辑页到物理页的映射条目,实现基本的页映射.
映射表保存如图3所示.图3中,32个segment中有1个segment常驻SRAM中,其他的segment保存在NAND闪存中,同时SRAM中常驻8个有效的zone映射表.这种做法类似其他闪存转化层中的Cache机制,如果在SRAM中的zone中有记录映射表的信息,可以快速地查询到逻辑页和物理页之间的映射关系,加速数据的读取.

图3 映射表保存Fig.3 Save mapping table
1.3 TFTL映射算法寻址
逻辑地址到物理地址的寻址,核心是找到逻辑页对应的zone表里存储的物理页.闪存转换层中,逻辑地址以扇区为单位,逻辑页由若干(标记为count,论文中以0×10为例)扇区组成.在TFTL映射算中,逻辑地址线性的分布在逻辑页中,逻辑地址对count取摸可以得到逻辑页.root表记录最新的segment表,且root表保存在segment结构体中.在segment结构体中,当segment表自身结构体的索引号与root表记录的segment表相同时,此时的segment表就是最新的segment表;segment结构体中同时包含有zone表地址,逻辑地址对应的zone表,记录着逻辑页对应的物理页信息.以逻辑地址0×75 400寻址到物理地址0×830为例,介绍具体的寻址方式,图4为具体的寻址过程.
1.4 TFTL数据流
TFTL数据流如图5所示.
数据在eMMC协议层和SRAM之间传输,需要乒乓缓冲区自动在2个缓冲区之间切换搬移数据. SRAM与乒乓缓冲区数据由DMA搬移.SRAM数据传输到NAND Flash主要由TFTL负责,TFTL内部的地址映射等算法把底层NAND Flash模拟成虚拟的块设备,以页为传输单元传输数据.

图4 寻址过程Fig.4 Process of addressing

图5 TFTL数据流Fig.5 Data path of TFTL
2 TFTL算法仿真和结果分析
在仿真实验中[13],选择系统响应时间[14]、系统响应时间的标准差[15]和功耗作为主要性能指标.
2.1 系统响应时间
系统响应时间,是指从主机端发送请求到设备端响应主机命令之间的时间,是评估闪存转换层的一个重要参数.它包括地址转换消耗的时间、eMMC读写消耗的时间、垃圾回收消耗的时间.
系统响应时间(Financial Trace)如图6所示.
在不同的工作负载下系统响应时间不同.由图6可见,运行工作负载Financial时,TFTL的系统响应时间接近page mapping FTL的系统响应时间.与pagemapping FTL算法对比,TFTL减少了整个NAND块的擦除次数,同时减少了大约额外的3倍页读的运行次数.图6的运行结果表明,TFTL提升了设备服务的时间,减少了队列等待的时延.与混合映射FAST算法对比,TFTL又提升了大约78%的整体I/O系统响应时间.对于以读为导向的工作负载,TFTL会带来更大的附加地址转换开销.在性能表现方面,与page mapping FTL算法比较偏差较大.系统响应时间(TPC-H Trace)如图7所示.

图6 系统响应时间(Financial Trace)Fig.6 System response time(Financial Trace)

图7 系统响应时间(TPC-H Trace)Fig.7 System response time(TPC-H Trace)
由图7可见,当运行工作负载TPC-H时,FAST算法系统响应迟缓,根本原因是消耗在完全的映射合并和潜在的等待请求I/O队列时的时间.即使FAST算法可以提升大约95%的请求服务,但相对于TFTL算法,系统响应时间会因潜在的剩余I/O请求队列出现长时间等待.
综合图6和图7的结果可以看到,TFTL算法在2个工作负载下,性能都能与最优算法相匹配:在工作负载Financial下,page mapping FTL算法性能最优,但TFTL算法的性能表现可以接近于page mapping FTL算法,都可以在4 ms左右响应系统请求;在工作负载TPC-H下,FAST算法性能最优,同样的TFTL算法的性能表现可以接近于FAST算法.3种算法系统响应时间接近,TFTL算法和page mapping FTL算法在前期响应较快,呈现出逐步增加的趋势.
2.2 系统响应时间的标准差
系统响应时间的标准差是指请求的系统响应时间与请求平均响应时间之间的标准差,用于表示各个请求之间的波动性.值越小,表示请求之间的差距越小,紧密性越好.图8所示为系统性响应时间的标准差.

图8 系统响应时间的标准差Fig.8 Standard deviation of system response time
由图8可以清晰地看出,无论运行工作负载Financial还是运行工作负载TPC-H时,FAST算法的标准差都较大,性能最差.FAST算法采用数据项和日志项存放数据,由于日志项占用的NAND闪存较少,且使用频率较高,即数据的写入都要用到日志项,又由于NAND闪存的写之前必须擦除特性,导致FAST算法垃圾回收比较频繁.垃圾回收要搬移数据,耗时严重,严重影响了系统的响应时间,导致系统响应时间的标准差升高.Page mapping FTL算法使用一级页映射,没有额外的地址转换开销,请求的服务时间差别不大,而且在进行垃圾回收时能取得全局最优,所以使得各个请求的系统响应时间差别最小,标准差最小. TFTL算法与Page mapping FTL算法对比,标准差大一点,是因为TFTL算法的映射表都存储在NAND闪存块中,是一种基于需求的页映射算法.映射表和数据一样保存到NAND闪存中,提升了做垃圾回收的频率,延缓了系统响应时间,导致标准差较Page mapping FTL算法相比增大.
2.3 功 耗
eMMC内部垃圾回收时产生的功耗,可以作为衡量eMMC内部固件算法性能的一个重要参数.不同于读和写的操作,垃圾回收对eMMC整体的功耗会产生一个重要影响,一个给定的工作负载,对于不同的FTL算法,内部的垃圾回收运行的平率差距较大.图9显示了运行工作负载Financial和TPC-H时不同的FTL算法产生的功耗.
工作负载Financial主要以随机写为主,工作负载TPC-H主要以读为主,在考虑垃圾回收产生的功耗时,工作负载Financial要远高于工作负载TPC-H. TFTL是基于需求的FTL算法,当映射表不在内存中时,TFTL需要额外的读写操作搬移映射表到内存中,导致在2种负载中产生比page mapping FTL更多的功耗.混合FAST算法,需要经常运行垃圾回收搬移数据从日志项到数据项,同时需要擦除日志项,因此,混合FAST算法功耗最大.

图9 Financial和TPC-H产生的功耗Fig.9 Power consumption of Financial and TPC-H
在垃圾回收时,除了因NAND闪存自身运行时的功耗外,eMMC内部的控制器产生的功耗也是不可忽略的一个因素.垃圾回收时,控制器需要寻找被搬移数据的NAND闪存,尽量去查收有效页最少的NAND闪存搬移,减少有效页的数据搬移时的功耗.图10显示了在运行工作负载Financial时,不同的FTL算法的垃圾回收的查询NAND闪存与系统响应时间之间的关系.
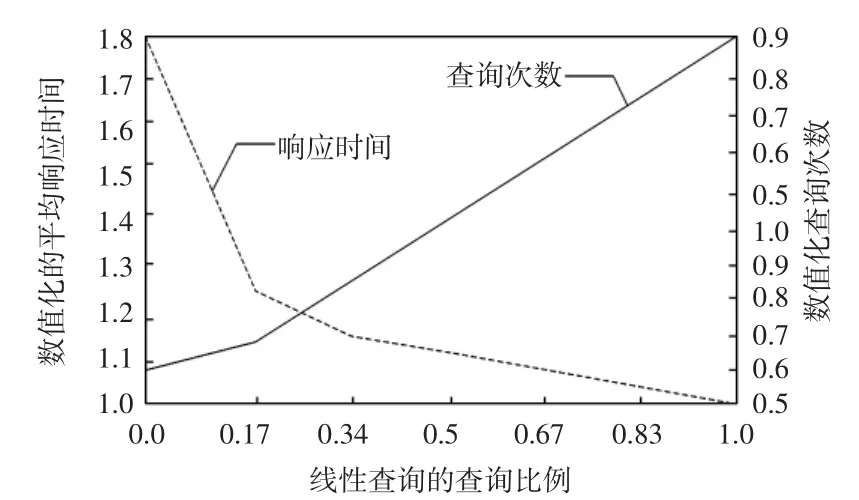
图10 NAND闪存与系统响应时间之间的关系Fig.10 Relation between the NAND flash and system system response time
从图10中可以看到,更高的搜索操作降低了响应时间,同时消耗更多的能量.原因为:①NAND闪存中的数据越少,数据搬移越少;②查询操作引起控制器和系统总线产生功耗.垃圾回收时,要权衡考虑查询操作和数据搬移之间的功耗问题.查询操作的不精确可能会增加系统响应时间,因为一个不完整的查询操作,可能会选择出一个有效数据页较多的NAND闪存块,进行数据的搬移.
片上内存RAM的功耗是另外一个需要考虑的因素.页映射与块映射对比需要更多的内存空间存储映射表,因此页映射会消耗更多的能量.混合映射FAST算法数据项使用块映射,日志项使用页映射,需要较少的内存空间,功耗也较小.TFTL与FAST类似,由于映射表主要存储在NAND闪存块中,需要的内存空间少,功耗也会随之减少.
3 结语
本文在DFTL算法的基础上提出了TFTL算法,不需区分数据块和转换块,可以较好地解决NAND闪存磨损均衡的问题.实验结果表明,TFTL算法比FAST算法系统响应时间快且垃圾回收功耗小,TFTL系统响应标准差比page mapping FTL的标准差稍大,原因是TFTL算法是基于需求的映射算法,映射表存储在NAND中,需要搬移映射到SRAM.
TFTL映射表的管理较复杂,但在数据恢复过程中,TFTL可以快速建立映射表.
[1]刘洋,王峰.Dual-FTL:一种基于MLC/SLC双模闪存芯片的闪存转换层[J].河南师范大学学报:自然科学版,2014,42(5):148-154. LIU Y,WANG F.Dual-FTL MLC/SLC dual flash memory chip based flash translation layer[J].Journal of Henan Normal University:Natural Science Edition,2014,42(5):148-154(in Chinese).
[2] KIM J,KIM J M,NOH S H,et al.A space-efficient flash translation layer for Compact Flash systems[J].IEEE Transactions on Consumer Electronics,2002,48(2):366-375.
[3]张琦,王林章,张天,等.一种优化的闪存地址映射方法[J].软件学报,2014,25(2):314-325. ZHANG Q,WANG L Z,ZHANG T,et al.Optimized address translation method for flash memory[J].Journal of Software,2014,25(2):314-325(in Chinese).
[4]JANG K H,HAN T H.Efficient garbage collection policy and block management method for NAND flash memory[C]//Mechanical and Electronics Engineering(ICMEE),2010,2nd.International Conference on.2010:327-331.
[5]JIANG A,MATEESCU R,YAAKOBI E,et al.Storage coding for wear leveling in flash memories[J].IEEE Transactions on Information Theory,2009,56(10):5290-5299.
[6]袁芳,刘伟,宋贺论,等.基于时间戳的FTL实现连续数据恢复方法[J].计算机工程与设计,2015,36(1):150-155. YUAN F,LIU W,SONG H L,et al.Continuous data recovery method based on FTL with timestamp[J].Computer Engineering and Design,2015,36(1):150-155(in Chinese).
[7]PARK D J,CHOI W K,LEE S W,et al.FAST:A log buffer scheme with fully associative sector translation for efficient FTL in flash memory[J].Kips Transactions Parta,2005,12A(3):205-214.
[8]PRATIBHA S,SUVARNA M.Efficient flash translation layer for flash memory[J].Emerging Directions in Embedded&U-biquitous Computing,2006,4097(4):879-887.
[9]GUO X F,WANG Y P.Optimizing random write performance of FAST FTL for NAND flash memory[J].Science China,2015,58(3):1-14.
[10]GUPTA A,KIM Y,URGAONKAR B.DFTL:a flash translation layer employing demand-based selective caching of pagelevel address mappings[J].AcmSigplan Notices,2009,44(3):229-240.
[11]杨龙婴.一种对NAND闪存硬件和闪存转换层软件的形式化建模[D].合肥:中国科学技术大学,2015. YANG L Y.Formal modeling of NAND hardware and flash translation layer[D].Hefei:University of Science and Technol,ogy of China,2015(in Chinese).
[12]杜溢墨,肖侬,刘芳,等.一种可定制模块化的闪存转换层的设计与实现[J].西安交通大学学报,2010,44(8):42-47. DU Y M,XIAO N,LIU F,et al.A customizable and modular flash translation layer(FTL)[J].Journal of Xi′an Jiaotong University.2010,44(8):42-47(in Chinese).
[13]BUCY J S,GANGER G R.The diskSim simulation environment version 3.0 reference manual[J].Kwartalnik Historii Kultury Materialnej,2003,29(4):102-103.
[14]SCHELLHORN Q,ERNST G,PFSHLER J,et al.Development of a Verified FlashFile System[M].Berlin:Springer,2014:9-24.
[15]KELLER G,MURRAY T,AMANI S,et al.File systems deserve verification tool[J].ACM SIGOPSOperating Systems Review,2014,48(1):58-64.
Three-level mapping management flash translation layer algorithm based on demands
HAN Xiao-jun1,WANG Ju-li1,2,ZHANG Nan1,GAO Hui-juan2
(1.School of Electronics and Information Engineering,Tianjin Polytechnic University,Tianjin 300387,China;2.Beijing Zhaoyi Innovation Science and Technology Co Ltd(GigaDevice),Beijing 100083,China)
Flash translation layer(FTL)is always needed when NAND Flash is used in a memory device.Page level translation is the most popular,but needs a large RAM to store mapping table.A three-level mapping management FTL based on the requirement(TFTL)is presented.The mapping tables stored in the NAND block to relieve pressure for SRAM and the page displacement method is used to move the mapping table in NAND block to SRAM.Compared with Page mapping FTL,DFTL and FAST,TFTL has a better performance on the NAND wear leveling. The system response time,and the standard deviation of system response time of TFTL have little difference with those of Page mapping FTL.
three-level mapping management;NAND flash;flash translation layer(FTL);address mapping;garbage collection;wear leveling
TP333
A
1671-024X(2016)05-0066-06
10.3969/j.issn.1671-024x.2016.05.012
2015-12-15
国家自然科学基金资助项目(61405144)
韩晓军(1958—),女,教授,主要研究方向为图像处理与模式识别.E-mail:hanxiaojun@tjpu.edu.cn
