基于统计的汉英机器翻译技术的研究
2016-11-21赵静
赵静
(咸阳师范学院 外国语学院,陕西 咸阳 712000)
基于统计的汉英机器翻译技术的研究
赵静
(咸阳师范学院 外国语学院,陕西 咸阳 712000)
随着互联网的大力普及,机器翻译彰显了其在未来的无可替代性。本文提出了一个汉英机器翻译系统,该系统是以统计为基础而发展的。文中先对统计机器翻译进行介绍,然后对汉英机器翻译系统进行详细介绍与说明,因为现今技术中,主要是以IBM对齐模型为基础的,而在这个IBM对齐模型中,以模型4最为有效,所以重点介绍模型4。最后提出了基于短语对齐模型的汉英统计机器翻译系统。
统计机器翻译;汉英机器翻译;翻译模型;对齐模型
机器翻译指的是将一种语言通过计算机的一系列处理以后翻译成为另一种语言的过程。随着现在科技的发展互联网的作用在人们生活中逐步提高,各个不同语言国家的交流也进一步拉近,可以预见的是,未来机器翻译一定会是生活当中必不可少的。现有的机器翻译系统中,以规则为基础的翻译技术已经非常成熟了,然而,即使现今设定了众多的规则库,对于语言而言还是远远不够的,毕竟语言是经过几千年的积累演变而成,而且对于不同的使用群体对语言的理解与运用也是不同的。所以,之后的机器翻译又进入了另一个阶段,逐步发展成为基于语料库的方法,该方法可分为两部分,分别是统计法和实例法,两者都是将语料库作为翻译的根本源,不同的是统计法中,语言是以统计数据的形式出现,而实例法则不是,基于此,目前为止,基于统计的方法是最具有代表性的[1-5]。
1 统计机器翻译方法
统计机器翻译方法主要分为3类,分别是平行概率法,信源信道模型法和最大熵法。其中,应用最广的方法是信源信道模型法,这种方法是把机器翻译过程认定为一种传输信息的过程,通过一个信源信道模型去解释机器翻译过程。该模型如图1所示。如图所示,对于目标语言P(T)中的随机信息T,通过信道转化后,转变为编程语言S,然后将该编程语言S进行解码,再转换为另一种语言的信息T1,即可完成翻译的过程[6-7]。

图1 统计翻译方法的信源信道模型
统计翻译方法的优点是[8]:
1)机器翻译是将给定的语言翻译成另一种目标语言,这个过程相对合理;
2)对于词组之间、短语之间联系较为模糊的对象,通过设定一定的规则将这些目标对象联系起来进而进行翻译;
3)对于所用的数据源,统计翻译方法易于扩展;
4)较为容易在其他系统中集成;
统计翻译方法的缺点是:
1)所需语料库资料较大,且翻译模型随资料库中资料数目而定;
2)翻译质量与翻译模型的好坏有关;
3)工作量较大,且与实际情况有关。
2 基于IBM对齐模型的汉英统计机器翻译
2.1汉英统计机器翻译的开发
汉英统计机器翻译的开发过程是一个循序渐进、不断改进的过程。首先要先对数据进行收集,收集过程可表现为将句子对齐,这些是需要人工进行操作的。数据收集齐以后就要开始训练数据,也就是说通过数据建立初步的数据模型,数据模型建立以后,要对该模型进行性能测试,在测试中,难免会发现一些错误信息,比如搜索信息错误、模型信息错误等,根据这些错误再对系统进行进一步的优化分析。开发过程如图2所示[9-10]。

图2 汉英统计机器翻译的开发过程
2.2IBM对齐模型和模型4
对齐模型指的是源语言与目标语言的关系,该模型可分为单词对齐和短语对齐两类,机器翻译的输出质量与单词对齐质量有关。短语对齐模型是非常复杂的,这是因为对齐形式包括了单词顺序、插入以及单词对应短语的变化关系,所以,本文只讨论单词对齐模型,同时,也规定在对齐模型中,源语言中的一个单词只能与目标语言中的单词对齐,也就是一一对应的关系。
IBM对齐模型主要分为5类,模型1主要针对单词之间的翻译质量,模型2重点在源语言的单词位置与目标语言的单词位置相互之间的关系;模型3则考虑一个目标单词与多种语言单词的关系;模型4是模型3的一种升级改进;模型5则添加了模型3和模型4两者间对空白单词处理不当的一些修正手段。文中采用模型4对汉英机器翻译技术进行研究,不采用其他模型是因为模型4相对其他模型而言,它的对齐效果较为理想,而且对目标语言的扭曲率也可以集成其他模型来改善[11-12]。
3 基于IBM对齐模型的搜索算法的设计与实现
IBM对齐模型总共可分为4种解决方法,分别是堆栈法、“贪心”搜索法、beam搜索解码法和A*搜索法,本文着重介绍beam搜索解码法和A*搜索法[13]。
3.1基于动态规划的beam搜索算法
对于给定的一个三元语言模型,暂定为 (e1,e,C,j),其中,e1,e表示这三元语言模型的最后两个词,C表示覆盖后的源语言集合。以e1,e的单词顺序被当作返回指针指向这部分的前驱内容,并将其存储下来,再按照这个顺序循环进行。图3表示基于动态规划的beam搜索算法。

图3 基于动态规划的beam搜索算法
为了提高搜索速度,对于beam搜素算法必须采取剪枝措施。修剪的策略有两种,一种是集合修剪,也就是对每个集合都进行修剪;另一种是基数修剪,意味着对整体集合进行修剪。在对搜索算法进行集合修剪和基数修剪以后,接下来要决定如何能限制假设集合的数量,通常数量是由4个阈值所决定。
1)集合裁剪阈值tC;
2)集合直方图阈值nC;
3)基数裁剪阈值tC;
4)基数直方图阈值nC;
3.2A*搜索算法
以实例来描述A*搜索算法的执行过程。搜索目标确定为一个汉语句子,M表示该句子中词的个数,通过搜索为其找一个相对应的译文[14]。
在开始搜索前,要为句子中的每个汉语词组找寻一个较为合适的英语单词。虽然可以将词汇表中与该汉语词组对应的英语词汇全部汇总,但那样工作效率太低,所以必须要在一个确定的范围内找这个英文词汇。因此,可以采用反向翻译率来给每个词组找合适的单词。对于汉语句子“告诉他”,其中,“告诉”的英文词汇有“tell”、“told”、“tells”和“telling”,“他”的英文词汇有“he”、“him”和“his”。将这些词进行翻译,翻译图如图4所示。
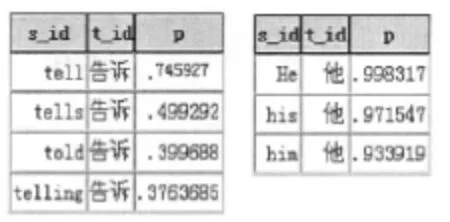
图4 "告诉"的分布,"他"的分布
这种方法的缺点是从最高点进行假设扩展时,若由后面的值改变的话,进行扩展的可能性就会变小,进而会对译文的质量有很大的影响。
4 基于短语对齐模型的汉英统计机器翻译
4.1将IBM对齐模型改为短语对齐模型
将IBM对齐模型改为短语对齐模型的过程如下[15]:
1)先通过GIZA++输入对齐文件,这个对齐文件包括汉译英文件和英译汉文件;
2)分为两个方面,一方面求这两个文件的Viterbi对齐集合,再求两个集合的交集,从而对单词对齐进行优化;另一方面输入由GIZA++得到的翻译率,并利用ISA法对单词进行对齐并且短语抽取;
3)将上述两个步骤所求的集合进行并集;
4)输入训练语料库的部分信息;
5)抽取短语和对齐模板。
过程如图5所示。

图5 IBM对齐模型改为短语对齐模型的过程
4.2使用词性标注信息构建对齐模板
使用词性标注信息的特点是该方法使用较为简便,免去了重复寻找词组间相互关系的繁琐步骤,同时这种方法对词的分类更加科学准确,同时在翻译过程中可以使用特定的规则提高对齐效率以及翻译准确率。表1为使用词性标注信息构建对齐模板的例子。
表中,对齐矩阵表示的是汉语与对齐的英语的位置。

表1 使用词性标注信息构建对齐模板举例
4.3实验与分析
为了能更好的对比本文所设计的基于短语的汉英机器翻译系统的性能,采用50826对语句,其中,大部分语句中词的数目不超过10个,又为了具备对比性,将该方法与A*搜索算法进行比较,评判的标准为翻译句子的关键词是否翻译,整体含义是否准确,句子结构的好坏。对比结果如表2所示。
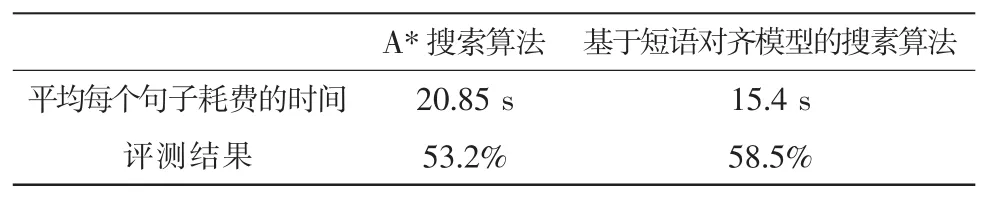
表2 A*搜索算法与基于短语模型的搜索算法结果对比
由表2可看出,基于短语对齐的搜索算法的性能还是不错的,无论句子耗时还是翻译效果,证明了该方法的实用性。
5 结束语
文中首先介绍了机器翻译的必要性,然后对统计机器翻译方法的分类、模型进行了详细的介绍,并且对齐优点和不足进行了一一分析,之后对IBM对齐模型的五大分类的特点进行阐述,确定了本文采用的模型是模型4,基于IBM对齐模型的搜索算法中,着重强调了beam搜索算法和A*搜索算法,为了进一步提高搜索算法的效率,本文将单词对齐模型改为短语对齐模型,并对其进行了深刻的分析和研究,最后将该方法与A*搜索算法进行性能比较,证明基于统计的汉英机器翻译技术是可实现并可利用的。
[1]PeterF.Brown,JolmCoeke,StephenA.DellaPietra,Vincent J. DellaPietra,FredrickJelinek,JohnD.Lafferty,RobertL.Mercer,Paul S.Roossin,A StatisticalApproachto Machine Translation[J].ComputationalLinguistics,1990.
[2]Peter.F.Brown,Stephen A.Della Pietra,Vincent J.Della Pietra,Robert L.Mercer,The Mathematics of Statistical Machine Translation:Parameter Estimation[J].Computational Linguistics,Vol 19,No.2,1993.
[3]Franz Josef Och,Hermann Ney,Discriminative Training and Maximum Entropy models for Statistical Machine Translation[C].ACL 2002.
[4]Papineni K A,Roukos S,Ward R T.Maximum likelihood and discriminative training of direct translation models[C].In Proc. Int.Conf.on Acoustics,Speech,and Signal Processing,Pages189-192,Seattle,WA,May,1998.
[5]Kishore Papineni,Salim Roukos,ToddWard,Wei-JingZhu,Bleu:aMethodfor Automatic Evaluationof MachineTranslation[R].IBMResearch,RC22176(WO109-022)September17,2001.
[6]Ulrich Germann USC Information Sciences Institute.Greedy Decoding for Statistical Machine Translationin Almost Linear Time[C]∥ Proceedings of HLT-NAACL 2003.Edmonton,Canada,May 27-June 1,2003.
[7]Tillmann C,Ney H.Word re-ordering and DP-based Search in statistical machine translation[C]∥ In COLING’00:The 18th Int.Conf.on Computational Linguistics,pp.850.856,Saarbrucken,Germany,July 2000.
[8]Tillmann C,Ney H.Word Re-Ordering and Dynamic Programming based Search Algorithms for Statistical Machine Translation[C]∥ Ph.D.thesis,Computer Science Department,RWTH Aachen,Germany,May 2001.
[9]Garcia-Varea I,Och F J,Ney H,et al.Renedlexicon modelsforStatisticalMachineTranslationusing amaximumentro pyapproach[C]∥InProc.ofthe 39th Annual Meetingof the Association for Computational Linguistics(ACL),pp.204.211,Toulouse,France,July2001.
[10]Franz Josef,Och.Statistical Machine Translation:From Single-Word models to Alignment Templates[C]∥ 2003,June.
[11]NieBen S,Ney H.Morpho:syntactic analysis for reor-dering instatistical machine translation[C]∥ In Proceeding,of the Machine Translation Summit VIII,pp.247.252,Santiago de Compostela,Spain,Sept.2001.
[12]Och,Franz-Josef,Nicola Ueffing,and Hermann Ney.2001. An efficient(A)*search algorithm for statistical machine translation[C]∥In Proceedings of the Data-Driven Machine Translation Workshop,39th Annual Meeting of the Association for Computational Linguistics(ACL),Pages55-62,Toulouse,France,July.
[13]周会平.基于中间语言的汉英翻译系统工CENT的研究与实现[D].长沙:国防科学技术大学,1999.
[14]刘群.统计机器翻译综述[J].中文信息学报,2003(4):1-12.
[15]Ying Zhang,Stphan Vogel and Alex Waibel.Integrated Phrase Segmentation and Alignment Model for Statistical Machine Translation[C]∥ Submitted to Proc.of International Confrerence on Natural Language Processing and Knowledge Engineering(NLP-KE),2003,Beijing,China.
Research on the technology of C-E machine translation based on statistics
ZHAO Jing
(Foreign Language College,Xianyang Normal University,Xianyang 712000,China)
Along with the popularity of Internet,machine translation has demonstrated its irreplaceable role in the future.In this paper,a Chinese to English machine translation system is proposed,which is based on the statistics.In this paper,we first introduce the statistical machine translation,and then introduce the C-E machine translation system,because the technology is based on the IBM alignment model,and the model 4 is the most effective,so it is important to introduce the model 4.Finally,a C-E statistical machine translation system based on phrase alignment model is proposed.
statistical machine translation;Chinese-English machine translation;translation model;decoder
TM933.4
A
1674-6236(2016)21-0069-03
2015-12-04稿件编号:201512046
咸阳师范学院科研项目部分研究成果(13XSYK043);陕西省社会科学基金项目部分研究成果(13K045)
赵 静(1977—),女,陕西高陵人,硕士,讲师。研究方向:语言学,翻译学。
