基于改进两阶段法和自助法的寿命数据分析
2016-11-21王国东牛占文
王国东,牛占文,曲 亮,何 桢
(1.天津大学管理与经济学部,天津300072;2.航空经济发展河南省协同创新中心,河南郑州450015)
基于改进两阶段法和自助法的寿命数据分析
王国东1,2,牛占文1,曲亮1,何桢1
(1.天津大学管理与经济学部,天津300072;2.航空经济发展河南省协同创新中心,河南郑州450015)
加速寿命试验的样本量通常很小而且截尾会很严重,这样会使得求得的极大似然统计量产生很大的偏差,进而影响到估计的准确度和精度.本文对两阶段法做了较大改进:证明了当各组数据服从Weibull分布且数据类型为无截尾或type II截尾时,存在两个关于形状参数和尺度参数的枢轴量,并采用无偏因子法修正极大似然统计量;考虑到异方差性,用加权最小二乘法替代最小二乘法估计加速模型的系数.根据两阶段方法不能采用Fisher信息矩阵计算分位数置信区间的缺点,用自助法获得置信区间.本文通过一个实例阐述改进的两阶段法的分析过程.另外,本文用相对偏差和均方误差根作为评判分析方法的准则,将改进的两阶段法和极大似然法在不同的分位点处的寿命估计作了对比.仿真结果表明,改进的两阶段法在低分位点处的寿命估计更优.
加速寿命试验;自助法;无偏因子;加权最小二乘法;Weibull分布
1 引 言
随着产品性能的不断提升,可靠性已经成为质量的一个重要维度.产品的可靠性水平直接决定了售后维修策略以及在保证期所花费的费用.生产商在确定产品价格前要定量评估产品的可靠性,然而在有限的时间内,采用一般的寿命试验很难获得充分的可靠性信息,一些产品在规定时间内并没有发生失效.因此,生产商一般会采用加速寿命试验(accelerated life test,ALT)技术来获得更多的可靠性信息.加速寿命试验是在失效机理不变的基础上,通过寻找产品寿命与应力之间的数学关系-加速模型,利用加速应力水平下的寿命特征去外推评估正常应力下的寿命特征[1].
在有限的时间内,即使采用加速寿命试验也不能获得全部样品的寿命信息.在高应力水平下,安排的样本量很小且不能保证全部失效;在一些较低的应力水平下,样品截尾可能会十分严重.截尾的样品数据只是说明在这个时间点样品没有失效,并不知道确切的失效时间.另外,寿命数据一般不服从正态分布,而是服从一些偏态的分布,比如lognormal分布,gamma分布和Weibull分布.极大似然方法能够很好的处理截尾和偏态数据[2-4],但是在小样本或者样品截尾很严重的情况下,极大似然估计的偏差会很大.Freeman[5]用仿真方法研究分组数据Weibull分布形状参数极大似然估计的偏差.仿真结果表明,只有在每一组的样本量达到20~40的时候形状参数的极大似然估计才是近似无偏的.为了降低极大似然统计量的偏差,Yang等[6]用参数正交化的方法对分组数据情况下的极大似然统计量进行了修正.对于没有截尾和type II截尾的数据, Yang等[6]得到的统计量是枢轴量,这样可以用无偏因子法进一步降低统计量的偏差.单组情况的无偏因子法已经有很多学者进行了研究.Thoman等[7]证明在没有截尾情况下Weibull分布形状参数的极大似然统计量与形状参数之比是枢轴量,并用Monte Carlo方法计算无偏因子值.Ross[8]给出了在没有截尾数据情况下无偏因子的计算公式.Ross[9]给出了在type II截尾数据小于50%的情况下无偏因子的计算公式.然而,目前还没有文献对分组数据的无偏因子法进行研究.
钱萍等[10]提出用两阶段方法进行参数估计,即第一阶段用极大似然法获得分布参数的估计;第二阶段用最小二乘法估计加速模型系数.但是他们提出的两阶段法没有考虑极大似然统计量的偏差,也没有考虑到异方差性(heteroscedasticity).由于两阶段方法得到的参数估计并不是出自同一个似然函数,故不能用Fisher信息矩阵方法来推断置信区间.钱萍等[10]采用自助法(bootstrap method)获得置信区间.
本文对两阶段法进行了改进,通过一个实例阐述如何用改进的两阶段法进行数据分析,并通过仿真的方法比较两阶段法和极大似然法在不同分位点处的寿命估计结果.
2 假 设
本文考虑包括m个应力水平的加速寿命试验X=(X1,X2,...,Xm)T,其中第i组的应力水平是Xi.从一批产品中随机抽取N个样品,并分为m组样本,各组样本的样本量分别为n1,n2,...,nm,且n1+ n2+···+nm=N.将第i组样本放在应力水平Xi下进行试验.本文用到的假设有
1)每个应力水平下样品寿命都服从Weibull分布,其概率密度函数和分布函数分别为
其中ηi>0,βi>0分别是第i组的尺度参数和形状参数.tij>0是第i组第j个样品的失效时间.
2)尺度参数ηi的大小依赖于应力水平Xi,加速模型为ln(ηi)=Xiγ,其中γ为加速模型的系数向量.
3)不同应力水平下Weibull分布的形状参数值相同,即β1=β2=···=βm=β.
3 改进的两阶段法
3.1改进两阶段法的步骤
阶段1用极大似然法获得参数估计
令tij表示第i组第j个样品的寿命,则m组的联合似然函数可以表示为[2]

如果样品失效则δij=1;如果样品没有失效则δij=0.C是与数据截尾类型有关的常数.
对数似然函数为

似然方程组可以表示为

参数β和ηi的估计值可以通过最大化式(2)得到,也可以通过求解似然方程组(3)得到.
阶段2用加权最小二乘法获得加速模型系数的估计
由式(2)可以得出关于参数β和ηi的二阶偏导的负数为
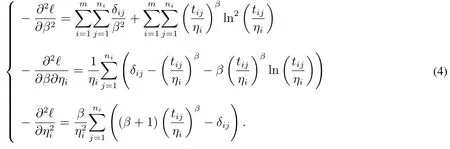
另外,关于ηi和ηj所有的二阶偏导均为0.
因此,观测Fisher信息矩阵可以写成
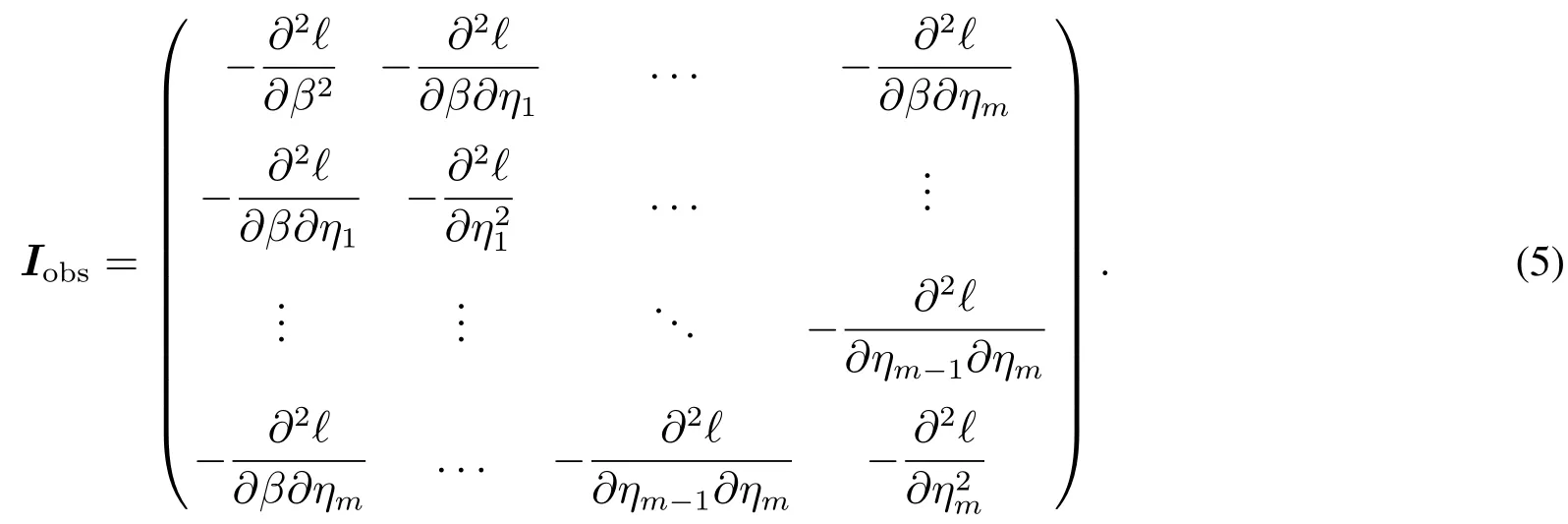
通过对观测Fisher信息矩阵取逆可以求得极大似然统计量的渐进协方差矩阵,从而可以对应得出i方差的估计值.这里用作为ln(i)方差的估计.
加速模型的参数估计公式为
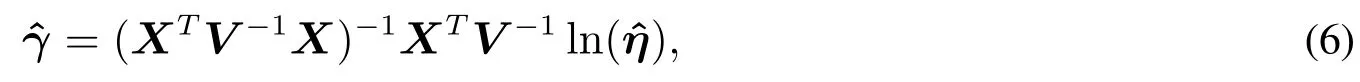
其中

3.2用无偏因子法降低统计量偏差
极大似然统计量是渐进无偏的.当样本量很大时,模型参数统计量的偏差是可以忽略的,但是如果样本量很小或者截尾很严重,则必须考虑修正统计量的偏差.本小节介绍用无偏因子法降低统计量的偏差.
无偏因子法是依靠无偏因子来降低统计量的偏差.无偏因子是通过枢轴量获得的.Thoman等[7]证明对于未分组情况下,当数据类型为没有截尾或type II截尾时/β和β(log()-log(η))是枢轴量,即它的分布与参数β和η的值无关,只是依赖于样本量n和样品失效的个数r.本文将证明这个结论对于多应力水平的分组数据同样成立.

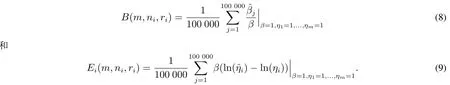

3.3分位数估计和置信区间
生产商关心的是低分位点产品寿命的估计值和置信区间.由于产品的寿命很长,通常不会在使用条件下进行试验,而是采用高于使用条件下的多个应力水平进行试验,并外推得到使用条件下产品的寿命特征信息.产品在使用条件下的寿命分布参数是通过加速模型估计得到的,而两阶段法并不能用统一的似然函数来获得这些参数估计.因此采用Fisher信息矩阵的方法获得分位数的置信区间并不可行.
Efron等[11]指出自助法(bootstrap method)是一种重抽样方法,用来估计很难用解析方法计算得到的统计性质.下面介绍用自助法获得置信区间的步骤并考虑到对统计量进行修偏.
4 实例
Zelen[12]设计了一个两因子的部分寿命试验来研究温度应力和电应力对电容器寿命的影响,其中温度应力有2个水平,电应力有4个水平,试验分为8组,每组有8个样品,试验终止条件采用type II截尾,当某组有4个样品失效时终止这组试验.试验的设计和寿命数据见表1.

表1 试验设计及寿命数据Table 1 Test design and lifetime data
4.1分析
现在许多成熟的商业软件可以对加速寿命试验数据进行分析,常用的软件有Minitab,R和SAS[13].这些软件都是用极大似然法进行参数估计.本小节将分析比较极大似然法和两阶段法的结果.
采用改进两阶段法对电容器寿命数据进行分析,仿真次数为10 000次.两阶段法的第一阶段分析结果见表2.

表2 阶段一分析结果Table 2 Stage one analysis results
两阶段法的第二阶段分析结果见表3;采用极大似然方法的分析结果见表4.
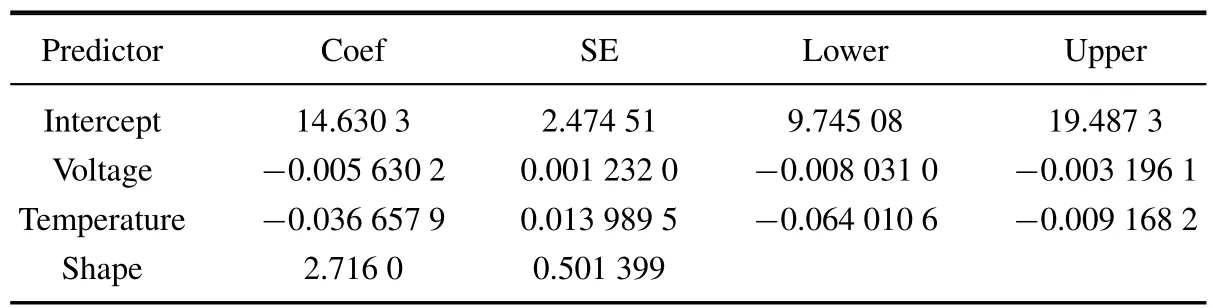
表3 阶段二分析结果Table 3 Stage two analysis results

表4 极大似然法分析结果Table 4 Maximum likelihood method analysis results
对比表3和表4,不难看出对于加速模型的系数估计差别并不大,但极大似然估计的标准误差更小.由于标准误与β成反比[2],而极大似然法过大的估计了β,这使得表4中标准误差的值过小.另外,表4中各系数估计的置信区间长度也较短.这一方面是由于标准误差值较小;另一方面是由于得到的置信限是基于样本量充分大的假设,而这在本例中显然并不可取.表3得到的置信限则不需要有关样本量的假设.
改进的两阶段法和极大似然法的分位点寿命估计和置信区间分别见表5和表6.本文选取的分位点p=0.01,0.05,0.10和0.50.从表5和表6看出,极大似然法在低分位点得到的估计值比两阶段法在低分位点的估计值要大.这主要是由于极大似然法没有对统计量降偏造成的.极大似然法估计p分位点寿命的公式为,其中(p)表示标准最小极值分布分布函数的逆.当估计低分位点产品的寿命时,的值是负数,而极大似然法过大的估计了β,这样得到的p就会偏大.另外,极大似然法得到的置信区间也较短,这是因为极大似然法求解置信区间的一个假设是分位点处的寿命估计的标准差已知,显然这在本试验中并不满足.如果样本量很大,也可以认为标准差已知.但是在本试验中每组只有8个样品且有50%截尾.在这种情况下,如果使用极大似然法计算置信区间,会使得置信区间长度变短.表5中的置信区间结果是通过自助法获得的.自助法不需要满足上面提到的假设,故结果更可信.

表5 改进的两阶段法的分位数参数估计和置信区间Table 5 Improved two-stage analysis percentile estimates and confidence intervals
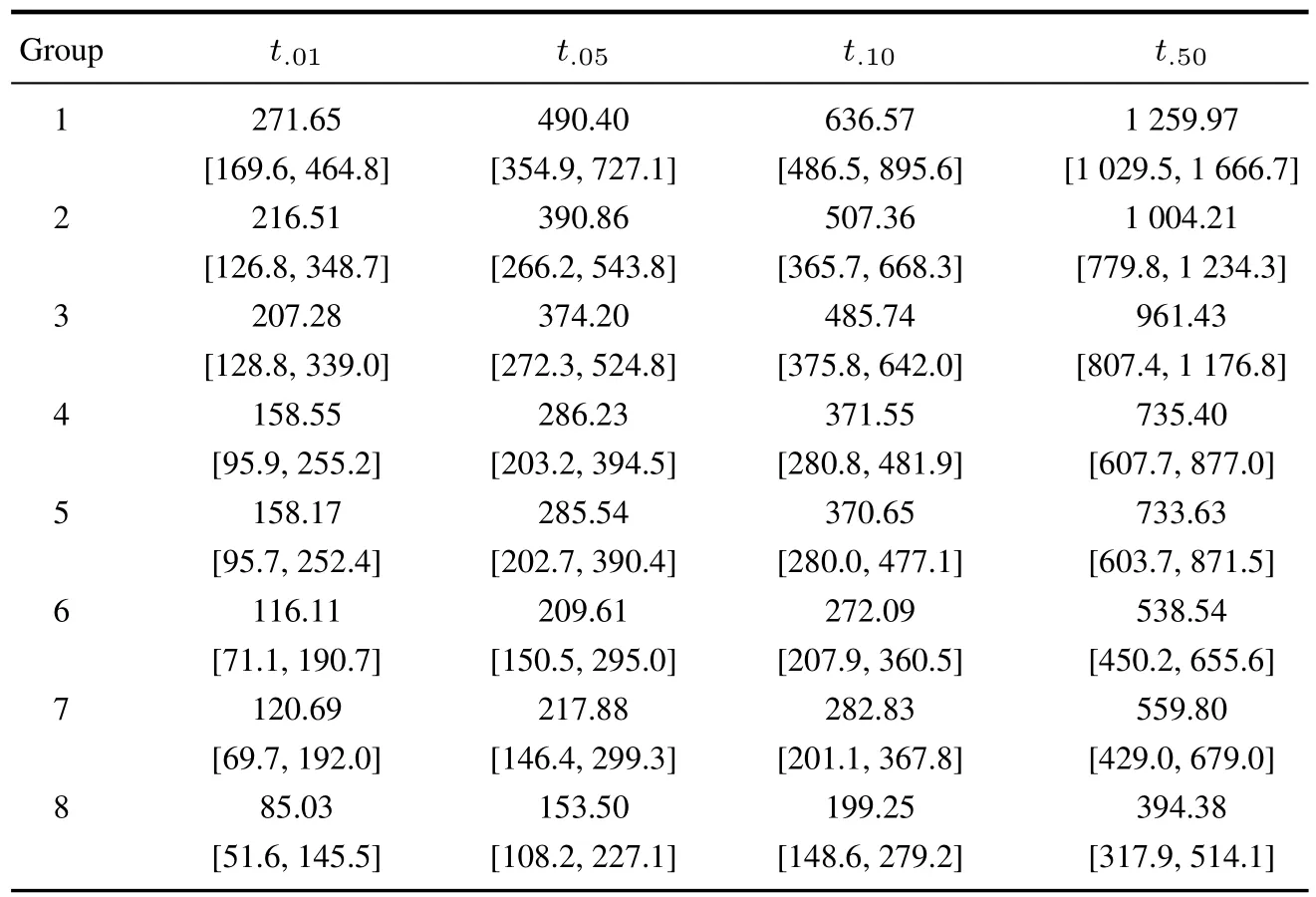
表6 极大似然法的分位数参数估计和置信区间Table 6 Maximum likelihood analysis percentile estimates and confidence intervals
4.2仿真

仿真的结果见表7和表8,其中RB1和RB2分别表示极大似然方法和改进的两阶段方法的相对误差(百分比);RMSE1和RMSE2分别表示极大似然方法和改进的两阶段方法的均方误差根(百分比).从表7可以看出这两种方法的相对误差都随着分位点的增大而减小,而改进的两阶段法的相对误差在低分位点更小些;从表8可以看出均方误差根随着分位点的增大而增加,而两阶段法在低分位点的均方误差根要更小些.从表7和表8可以看出,两阶段法在估计低分位点产品寿命时效果更好.

表7 分位数估计的相对偏差Table 7 Relative bias of the percentiles estimates

表8 分位数估计的均方误差根Table 8 Root mean square error of the percentiles estimates
5 结束语
本文改进了加速寿命试验可靠性数据分析的两阶段法:采用无偏因子法降低极大似然统计量的偏差,并用加权最小二乘法替代最小二乘法来估计加速模型的系数.本文通过实例详细阐述了统计量的偏差对产品分位点寿命的影响.文章将相对偏差和均方误差根作为评判准则,并通过仿真方法来研究应用两阶段法进行分位点寿命估计的性质,并与极大似然法进行比较.仿真结果表明,两阶段法在估计低分位点的寿命时要优于极大似然法.而低分位点的寿命估计恰恰是工程技术人员最为关心的.
本文应用仿真对不同分位点两种方法寿命估计的结果进行了对比.但仿真的结果只是适用于特定的试验条件(试验包括8个应力水平,每个应力水平有8个样品,采用type II截尾,当某组有4个样品失效则终止这一组的试验).对于样品总量N以及每组样本量ni和截尾比例对统计量偏差的影响本文没有研究.这将是下一步要开展的工作.
企业的试验设备都很有限,一般都会把同一个应力水平的样品安排在同一台设备中进行试验.这就会有子抽样(subsampling)的问题[14].当存在子抽样时,极大似然法将不再适用,但本文提出的两阶段法仍然适用.Freeman等[15]和Liu等[16]都提到两阶段法过大估计了形状参数.本文通过无偏因子法很好的解决了修偏问题.但是如果寿命试验存在子抽样问题,就不能用文中提到的自助法直接求得置信区间.如何改进自助法,使其能够计算带有子抽样寿命数据分位数的置信区间,这也是下一步要开展的工作.
[1]姜同敏,王晓红,袁宏杰,等.可靠性试验技术.北京:北京航空航天大学出版社,2012. Jiang T M,Wang X H,Yuan H J,et al.Reliability Test Techniques.Beijing:Beihang University Press,2012.(in Chinese)
[2]Meeker W Q,Escobar L A.Statistical Methods for Reliability Data.New York:John Wiley,1998.
[3]Lawless J F.Statistical Models and Methods for Lifetime Data.2nd Edition.New Jersey:John Wiley,2003.
[4]Nelson W.Accelerated Testing:Statistical Models,Test Plans and Data Analysis.New Jersey:John Wiley,2004.
[5]Freeman L J.A cautionary tale:Small sample size concerns for grouped lifetime data.Quality Engineering,2011,23(2):134–141.
[6]Yang Z,Lin D K J.Improved maximum-likelihood estimation for the common shape parameter of several Weibull populations. Applied Stochastic Models in Business and Industry,2007,23(5):373–453.
[7]Thoman D R,Bain L J,Antle C E.Inferences on the parameters of the Weibull distribution.Technometrics,1969,11(3):445–460.
[8]Ross R.Formulas to describe the bias and standard deviation of the ML-estimated Weibull shape parameter.IEEE Transactions on Dielectrics and Electrical Insulation,1994,1(2):247–253.
[9]Ross R.Bias and standard deviation due to Weibull parameter estimation for small data sets.IEEE Transactions on Dielectrics and Electrical Insulation,1996,3(1):28–42.
[10]钱萍,陈文华,李星军,等.产品可靠性的Bootstrap回归统计分析方法.仪器仪表学报,2010,31(11):2549–2554. Qian P,Chen W H,Li X J,et al.Bootstrap regression statistical analysis method for product reliability.Chinese Journal of Scientific Instrument,2010,31(11):2549–2554.(in Chinese)
[11]Efron B,Tibshirani R.An Introduction to the Bootstrap.New York:Chapman and Hall,1993.
[12]Zelen M.Factorial experiments in life testing.Technometrics,1959,1(3):269–288.
[13]Rigdon S E,Englert B R,Lawson I A,et al.Experiments for reliability achievement.Quality Engineering,2012,25(1):54–72.
[14]Freeman L J,Vining G G.Reliability data analysis for life test experiments with subsampling.Journal of Quality Technology,2010, 42(3):233–241.
[15]Freeman L J,Vining G G.Reliability data analysis for life test designed experiments with sub-sampling.Quality and Reliability Engineering International,2013,29(4):509–519.
[16]Liu X,Tang L C.Analysis of reliability experiments with blocking.Quality Technology and Quantitative Management,2013,10(2): 141–160.
Lifetime data analysis based on improved two-stage approach and bootstrap approach
Wang Guodong1,2,Niu Zhanwen1,Qu Liang1,He Zhen1
(1.College of Management and Economics,Tianjin University,Tianjin 300072,China 2.Cooperative Innovation Center for Avation Economy Development,Zhengzhou 450015,China)
When the sample sizes of accelerated life test are small and the data are heavily censored,the bias may be very serious and may affect the accuracy and precision of maximum likelihood estimates.In this paper,the two-stage approach is improved in two aspects:after proving that there are two pivotal quantities with shape parameter and scale parameters of Weibull distributions for complete data or type II censored data,Monte Carlo method is used to obtain the unbiased factors and reduce the bias of estimators;and least square method is replaced with the weighted least square method because of the heteroscedasticity.The two-stage approach cannot obtain confidence intervals of percentiles via Fisher information matrix.Therefore,the confidence intervals are predicted using bootstrap approach.After that,an example is provided to illustrate the procedures of proposed approach.Furthermore,the improved two-stage method is compared with maximum likelihood method based on relative bias and root mean square error criteria.The simulated results show that the improved two-stage method is better in the case of low percentiles.
accelerated life test;bootstrap method;unbiasing factor;weighted least square method;Weibull distribution
TB114.3
A
1000-5781(2016)05-0710-09
10.13383/j.cnki.jse.2016.05.015
2013-11-07;
2014-10-16.
国家自然科学基金资助项目(71402118;71071107);国家自然科学基金重点资助项目(70931004;71532008);国家自然科学基金杰出青年科学基金资助项目(71225006);航空科学基金资助项目(2013ZG55024;2014ZG55021);河南省高等学校重点科研资助项目(17A630072).
王国东(1981—),男,天津蓟县人,博士,讲师,研究方向:试验设计与可靠性改进,Email:gdwang@tju.edu.cn;
牛占文(1966—),男,内蒙古赤峰人,博士,教授,研究方向:精益生产和质量工程,Email:zw.niu@163.com;
曲亮(1982—),女,天津人,博士,讲师,研究方向:质量管理与可靠性分析,Email:qulucky@yahoo.com;
何桢(1967—),男,河南濮阳人,博士,教授,研究方向:质量工程与六西格玛管理,Email:zhhe0321@163.com.
