基于农业的MVC设计模式的网络蜘蛛的实现
2016-11-19杨本辉
杨本辉
摘 要:利用PHP语言开发的基于农业的MVC设计模式的网络蜘蛛。可以实现采集,能够把各类的互联网信息或者数据采集到自己的数据库中,然后再进行一系列的处理。本文介绍的是整个网络蜘蛛从无到有的过程。利用MVC的架构思想开发出具有模块化、易于多人开发、易于维护性、易于拓展和易于二次开发的特性的农业网络蜘蛛。
关键词:PHP;MVC;农业网络蜘蛛
一、引言
农业(Agriculture)是利用动植物的生长发育规律,通过人工培育来获得产品的产业。农业属于第一产业,研究农业的科学是农学。农业的劳动对象是有生命的动植物,获得的产品是动植物本身。农业提供支撑国民经济建设与发展的基础产品。
传统农业发展到今天,生产力与生产资料已经不能匹配时代的发展。特别作为人类的精华,很多的农业相关宝贵的知识,不能够很好地传承与发展。而知识的传承性,关系到人类的兴衰。如果知识不能很好的传承,那么后世的人类就必须重新去研究、探索、总结。无疑,农业相关前人知识的研究不止要传承下去,而且还要很好的传承下去。
互联网是一种现今先进生产力的技术集,它集合了IT、网络、大数据、人工智能等各种技术。它是人类的先进生产力与生产资料。农业与互联网的结合将对传统农业带来全新的血液。结合互联网的高速处理、持久存储以及快速获取的能力,互联网将把农业知识进行极好的传承,最终将会在讲来把农业推向一个新的高度。
二、网络蜘蛛的定义与原理
网络蜘蛛即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。那么网络蜘蛛到底是做什么的呢?
其实网络蜘蛛就是一种获取互联网数据到特定数据库系统中的一种程序工具,它的作用就是不斷的获取互联网的内容,通过特有的过滤技术,最终把内容获取到数据库系统中,最终供用户来检索信息以及资源。
从架构层面上来说:网络蜘蛛是有很多种设计模式的,每种模式都有不同的应用方向。常见的设计模式可以分为几类。
1. 深度优先。深度优先是指网络蜘蛛会从 起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。这个方法有个优点是网络蜘蛛在设计的时候比较容易。
2. 广度优先。广度优先是指网络蜘蛛会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。
3.通用方式。网站内容多种多样,结构也是各有不同,如何做到精准抓取呢。这就需要一个通用的结构体系。通用方式的结构体系可以分为以下三个步骤:
(1) Url网址规则获取
(2) Listing列表页面获取
(3) Content最终内容页面获取
4.几种方式的对比。无论是深度优先,还是广度优先,在获取内容上通常是获取一个超链接地址后一个一个的爬行,在有些我们不得不对特定的网站进行内容抓取的时候就没有方法了。在这一种情况下,我们所需要的其实是精准的抓取而不是一个接一个的“爬取”。所以深度优先和广度优先在这一类型的情况下是不适用的。通用方式就是解决这种情况的。通用方式会按照用户需求有选择的获取内容。
三、农业网络蜘蛛程序国内外现状
1.国外情况。国外的IT水平相对较高,我们可以在国外看到一些不错的网络蜘蛛。
(1)Larbin。larbin是一种开源的网络爬虫/网络蜘蛛,由法国的年轻人 Sébastien Ailleret独立开发。larbin目的是能够跟踪页面的url进行扩展的抓取,最后为搜索引擎提供广泛的数据来源 。
(2)Spiderman。Spiderman 是一个基于微内核+插件式架构的网络蜘蛛,它的目标是通过简单的方法就能将复杂的目标网页信息抓取并解析为自己所需要的业务数据。
(3)OpenWebSpider。OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
2.国内情况。国内的爬虫程序一般数量不多,质量也不好,大多数程序是对于国外开源程序的引用,以及二次开发,所以不做多讲。
四、程序具体实现(程序设计简介)
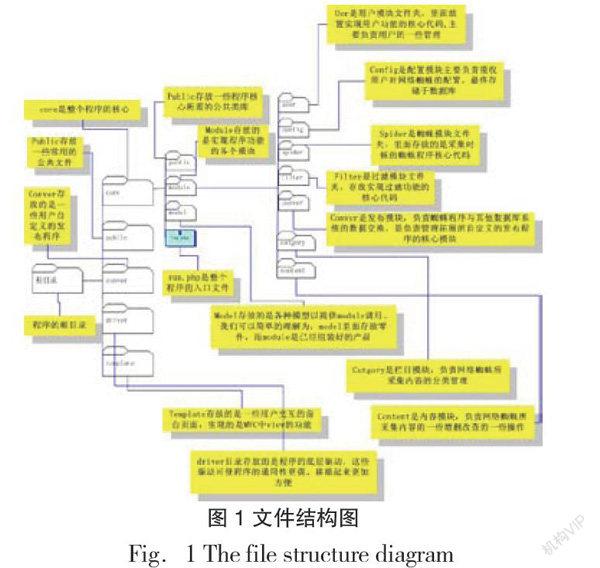
1. 文件结构。对于一个程序的实现,文件结构是十分重要的。良好的文件结构常常意味着程序功能的合理。本程序的文件结构图如图1所示:
图1 文件结构图
Fig.1 The file structure diagram
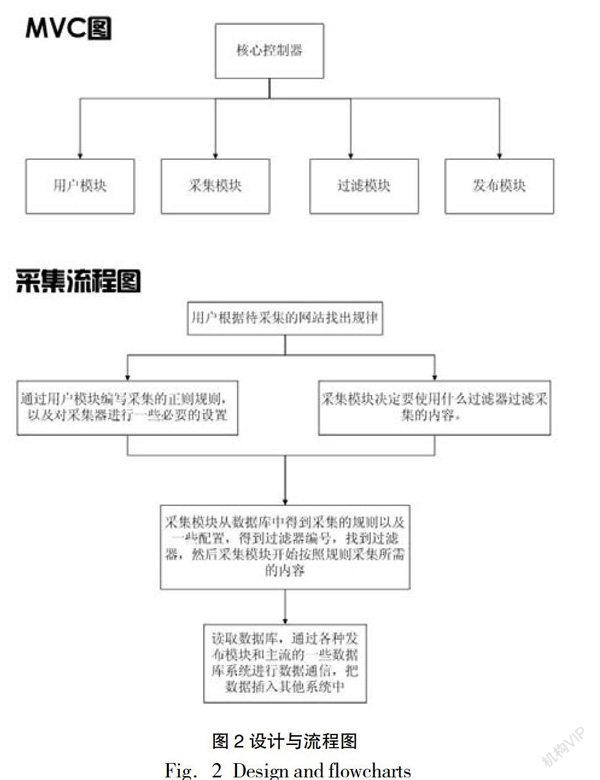
2. 网络蜘蛛的设计与流程。此农业网络蜘蛛是一个通用的采集程序,采用的是通用方式,基于MVC开发思想,基于语言PHP,所需要的数据库是开源的轻量级数据库sqlite,运行的宿主操作系统是Linux。由于考虑到程序的通用性,所以每一个基础的模块是独立封装的,好比一个一个的零件。这样的好处就是用户可以根据自己的需求来组装功能,这样可以使得程序更加通用。程序的设计图如图2所示:
程序总共分为4个模块,分别会在下一段说明。
(1)用户模块。用户模块主要负责管理整个程序的登录用户,比如用户的增删改查。还有密码以及权限的配置。
(2) 配置模块。配置模块主要负责把用户的一些设置信息存储起来以方便供后续程序使用。
(3)采集模块。采集模块是整个网络蜘蛛的核心模块,整个蜘蛛的采集性能都是由这个模块实现。其中这个模块中有几个核心问题的处理方式如下:
① 采集重复怎么办。采集重复在网络爬虫中是普遍存在的。由于我们获取源网站的数据的数据量都不小,而大多数时候我们在采集listing列表的url的时候的时候,由于源网站的数据库可能会有一些插入操作别人在同时进行。所以这个时候取出的数据难免会和之前的数据想重复,这个其实是一个很正常的问题。
解决采集重复的方法需要我们利用数据库的一些特性,把一些字段设置为unique,最终用replace into(sqlite的sql语句)进行插入。
②采集出错、中断怎么办。采集过程中出错或者中断是正常的,原因有很多,可是很多时候就只是仅仅由于网络的不问题,或者我们采集的源服务器不稳定。而无论什么原因,这样肯定会造成数据的丢失。而这个时候怎么办呢。
解决方法实际上是在数据表里面添加一个字段专门来记录数据写入是否成功。成功就为1不成功就为0。
(4)过滤模块。由于各种原因,我们可能要对现有的一些采集数据进行一些过滤,或者一些替换。在这种情况下,可能就要使用到过滤模块,过滤模块常常用于一些非法内容的替换,或者一些无用内容的过滤。
(5)发布模块。等到数据从采集模块获取了以后,数据是存放在网络蜘蛛的数据库中。但是这样的数据是无法直接导入到现有的一些主流的建站程序的。我们还必须要开发一个中间件来适应相应的cms,从而达到可以把数据导入其他开源程序的目的。
(6)插件模块。由于程序的功能很多时候不可能一下子考虑的十分全面,并且在程序开发中我们十分有必要使程序能够拓展第三方的程序以使程序更加强大、健壮。所以特别多出一个插件模块,主要负责整个程序新功能的拓展。而这个拓展一般由其他开发人员按照本程序提供的接口实现。
(7)栏目模块。由于采集的内容种类繁多,所以必须要有一个模块来使程序采集来的数据按照要求进行归类,进行管理。
(8) 内容模块。内容模块主要网络蜘蛛负责采集来的内容的增删改查操作。这样可以有效的管理采集来的资源。
五、本程序的优势
1.基于linux+nginx+PHP+sqlite。考虑到本程序的性能以及开发的便利性,本程序采用的编程语言是目前最为流行的网络编程语言PHP。
Sqlite是一个轻量级的数据库,存储效率高,数据以单文件的方式存储,节省系统资源占用,是一个十分优秀的开源轻量级数据库。本程序的开发所存储的数据都将使用sqlite数据库存储。
2.基于MVC。MVC是一种思维规范,没有明确的定义,只有一个需要遵循的思考方式,所以说,MVC是有不同的种类的,因为这取决于某一种MVC框架作者的思想。一般来说现在中国的互联网流行的MVC实际上可以概括为:模型(Model),视图(View)和控制Controller)。本程序的设计围绕以下几个方面作为思考:
(1) 各施其职,互不干涉。
(2) 有利于开发中的分工。
(3) 有利于组件的重用。
六、存在的客观问题
面向对象的设计思想注定程序是比较庞大的,效率相比面向过程偏低。
对于一个程序来说,性能是很重要的。不过对于面向对象的程序设计都会有一个致命的弱点就是程序的性能不高。因为良好的拓展性以及模块化的MVC开发思想多多少少都是会以损失一些程序性能为代价的。
七、结语
本网络蜘蛛基于MVC的开发思想,使用PHP开发语言,能够广泛应用于各个行业的信息以及资源获取,从而用作分析或者其它目的。本网路蜘蛛从编写到成熟历时3个月,中间大小修改大约50次。测试数据数目超过500万次。
参考文献:
[1] 开源中国. larbin. [EB/OL]. http://www.oschina.net/p/larbin. 2013-03-14.
[2] 开源中国.spiderman. [EB/OL]. http://www.oschina.net/p/spiderman.2013-3-14.
[3] 开源中国.openwebspider.[EB/OL].http://www.oschina.net/p/openwebspider. 2013-3-14.
[4] 开源中国.snoopy. [EB/OL].http://www.oschina.net/p/snoopy.2013-03-14.
[5] ChoJ,Garcia-MolinaH,PageL.Efficient crawling throughURL ordering. Proceedings of the7thACM-WWW InternationalConference . 1998.
[6] 郭海燕.搜索引擎中网络爬虫技术研究[D]. 西安电子科技大学 2009.
[7] 李学勇,谭义红,田立军,欧阳柳波,李国徽.ε-贪婪策略在网络蜘蛛搜索策略中的应用[J].湖南工程学院学报(自然科学版). 2004,(02).
[8] 李学勇,欧阳柳波,李国徽.基于模拟退火机制的网络蜘蛛搜索策略[J].湖南理工学院学报(自然科學版).2004,(02).
[9] 龙宇巍,王永成,许欢庆.定题搜索引擎Robot的设计与算法[J].计算机仿真.2004,(04).
[10] 华伟臣,张秀琼.网络蜘蛛搜索研究[J].乐山师范学院学报. 2006,(05) .