基于同态加密的密文检索方案研究
2016-11-17吕文斌拱长青
吕文斌,拱长青
(沈阳航空航天大学 计算机学院,沈阳 110136)
基于同态加密的密文检索方案研究
吕文斌,拱长青
(沈阳航空航天大学 计算机学院,沈阳 110136)
现有的密文检索技术主要是采用的是布尔模型,它无法精确的计算出检索项与待检索文件的相关度,不能按相似度进行精确的排序;针对以上情况,结合同态加密技术和基于TF-IDF的向量空间模型技术,提出了一个基于向量空间模型全同态环境下的密文检索方案BVH(based vector space model and homomorphism ciphertext retrieval scheme),BVH主要分为3个步骤:第一是预处理阶段,主要对上传的文件建立倒排索引,生成文件向量集,计算各个文件向量的模,对文件向量集和要上传的文件加密以密文的形式上传到云端;第二个阶段是检索阶段,主要是将搜索词的向量密文和各个文件向量的密文相乘将结果以密文的形式返回给客户端;第3个阶段结果处理阶段,主要是对解密后的结果进行相应的计算处理,对最后的处理结果按相似度大小排序;经分析,该方案在准确率和检索效率方面都得到了较大提升。
同态加密;向量空间模型;倒排索引;密文检索;相似度
0 引言
云计算是一种通过网络以按需、易扩展的方式获取所需服务的在线网络服务交付和使用模式,它是分布式计算的一种形式,它是网络上的服务以及提供这种服务的数据中心的软硬件集合[1]。云计算是并行计算、分布式计算和网格计算的演进。云计算的实现形式包括软件即服务、效用计算、平台即服务、基础设施即服务[1]。
云计算的提出对那些数据量极大而且复杂的数据提供一个高效稳定的计算方法。首先要提供一个安全可靠的数据存储中心,一个可靠的方法就对用户要上传的数据加密,把数据以密文的形式存储到云端。但是随着云端数据量的增大,快速准确的从云端大量的密文数据中检索出用户需要的数据将是一个急需解决的问题。
密文检索技术已经发展多年,有很多已经比较成熟的算法,如线性搜索算法,基于关键词的公钥搜索算法,安全索引。这几种算法使用的是是布尔模型,布尔模型有一个局限性就是无法计算出关键词和待检索文档之间的相关度,既无法对检索出的多个文档进行排序。引入相关排序的搜索算法虽然引入了相关度这个概念,但是此算法只允许一次只查询一个词,还有就是此算法只使用了词频并没有使用文档频率,而在实际应用中,只有词频和逆文档频率共同使用才能得到合理的排序。在云端,待检索的文档数是巨大的,那么计算关键词和待检索文档之间的相关度就变得非常重要。而向量空间模型则可以很好的解决这个问题,它在目前的明文检索系统中应用已经非常广泛,它可以对搜索到的多个文档根据相似度进行排序。全同态加密技术是一种可以直接对密文进行操作的技术, 并且对密文操作的结果进行解密和直接对明文操作的其结果是一样的。因此采用全同态加密方式不仅可以保证用户数据的安全,而且可以直接对密文进行加法和乘法操作,这会大大提高在云端的检索效率。
1 全同态加密
1978 年,R.Rivest、L.Adleman 和 M.Dertouzos 提出了“全同态加密”的概念,全同态加密即可以对密文进行任意深度的计算,然后对计算结果解密和对明文进行相应的计算其结果是一样的。几十年来,国内外的专家们对其进行不停的探索与研究,直到2009年, Gentry提出了首个全同态加密方案, 这一问题才有了突破性的进展, 该方案使用的数学工具是理想格。 Gentry的全同态加密思想框架如下: 构造一个部分同态方案,该方案不能处理任意次数的多项式或任意深度的电路,即它只能满足有限次的加法同态和乘法同态, 然后压缩解密电路,使得压缩后的解密算法的次数降低,能够正确用于密文的解密。最后利用自举转换技术,在对密文做完一次加法或乘法运算后,对运算后的密文进行重加密操作,此举的目地是降低密文运算过程中产生的噪声,使得此方案能满足任意次数的加法同态和乘法同态,最终得到一个全同态加密方案[2]。
基于理想格的全同态加密算法如下所示:
在此方案中,密文ψ表示为V+X,其中,V代表理想格,X代表加密明文时产生的噪声,它的含义就是将密文空间用多项式环Ζ[x]/f(x) 的元素的系数向量形式来表示,对密文的加法和乘法运算就变成了对多项式环上的向量空间的运算:如式(1)(2)所示[2]:
(1)
(2)
这种方案的缺陷在于加密过程产生的噪声会随着运算深度的增加而变大,尤其对乘法运算更是如此,噪声过大会影响解密的正确性,因此此方案只适合于运算次数较低的电路。为此Gentry提出了他的全同态思想框架来解决这一问题。除此之外,因为该方案要进行向量的加法和乘法运算,每次 Evaluate运算中加法和乘法的计算的时间复杂度为O(n6),可以看出此方案的效率不高。因此国内外的专家们对其进行了不同方向上的改进,如2010年由Dijk,Gentry等人提出了整数上的全同态加密方案(简记为DGHV方案),该方案不仅概念简单,而且在效率上有了一定的提高。
1.1 整数上的全同态加密方案
Dijk 和 Gentry 等人利用最基本的模运算构造了一个Somewhat同态加密方案,在该方案中舍弃掉了多项式环中的理想格,仅利用整数上的加法和乘法运算,从上可以看出,此方案相对于Gentry的基于理想格的全同态加密算法效率要高,并且它的计算复杂度低。
此方案先是构造一个对称加密方案,然后在将其改造成非对称的加密方案。
其对称加密方案如下[6-7]:
Kengen():选取比特长度的素数作为私钥
Encryption(p,m):密文c=m+2r+pq,q 和r是随机选取的,并且满足|2r|<|p/2|
Decryption(p,c):明文m=(c mod p)mod 2
如果m+2r
现在将其对称加密方案转换成非对称加密方案
Kengen():选取比特长度的素数作为私钥,公钥pk为集合,加密时随机选择该集合的一个子集S
Encryption(pk, m):密文
Decryption(p,m):明文m=(c mod p)mod2
由上可以得出,此方案加密过程会产生噪音,随着密文噪声的增大,解密时有可能得不到正确的明文,即只有对密文进行较低次的加法和乘法运算时,此方案才满足同态特性。如果想得到一个全同态加密方案,可以采用Gentry的全同态加密思想框架对上述方案改进。
1.2 本文的同态加密方案
本文所使用的同态加密算法也是基于整数的模运算,其具体过程如下:
Kengen:随机选取一P位的大素数作为密钥p
Encryption:随机选取一个Q位的大素数q,且P>Q>明文分组长度,随机选取两个随机数r1,r2,N=pq,密文c=(m+pr1+pqr2)mod N
Decryption:明文m=c mod p
同态性分析:设有两个明文 m1,m2,其对应的密文分别为c1,c2,则
c1=(m1+pr11+pqr12)mod N
c2=(m2+pr21+pqr22)mod N
加法同态性分析:c1+c2=(m1+m2+p(r11+r21)+pq(r12+r22))modN=c(m1+m2),因此该算法,满足加法同态。
乘法同态性分析:c1*c2=(m1*m2+pm1r21+pqm1r22+pm2r11+p2r11r21+p2qr11r22)mod N,c1*c2modp=m1*m2,因此该算法满足乘法同态性。
综上所述,该方案既满足加法同态性,又满足乘法同态性。此方案也是基于整数的,其加密过程会产生噪音,随着运算电路深度的增加,该算法有可能不再满足同态性,即该方案为Somewhat同态加密方案,要想得到一个全同态加密方案,那么就要根据Gentry的全同态思想框架,采用解密电路压缩技术和重加密技术对上述方案改进得到一个全同态加密方案,但是其实现起来是非常复杂和困难的。
2 现有的密文检索技术
密文检索技术已经发展多年,有很多已经比较成熟的算法,如下面介绍的几种密文检索算法。这几种算法有一个共同的缺点,因为它们所用的模型是布尔模型,布尔模型有一个局限性就是它无法计算出关键词和待检索文档之间的相似度,既无法将检索出的多个文档根据相似度进行排序。在云端,待检索的文档数是巨大的,计算检索项和待检索的各个文件集之间的相关度并按相关度进行排序非常重要。
2.1 线性搜索算法
线性搜索算法是一种具有线性搜索特征的密文检索算法,它的核心就是以密码流为基础,把明文与密码流的逐个单词进行异或,这样就得到了相应的密文,在搜索时,把待搜索的关键字与密文进行异或,若异或结果满足密码流单词的结构特征,则搜索成功[9-10]。
线性搜索算法的优点是它只进行异或操作,因此加解密时速度会非常快,它的缺点就是检索时必须依次对照密文,当检索的文件量大时,其检索速度会非常慢。
2.2 安全索引
安全索引是一种采用Bloom Filter的密文检索技术,它的核心思想是保证索引的安全性,它为每一个文档建立一个索引,其索引就是关键字和文档的一个映射,在搜索时,可以通过这个索引找到要检索的文档,采用Bloom Filter的优势在于几乎不可能通过统计的方式从索引推出关键字,也就不可能得到明文的相关信息,但是安全索引的一个缺点就是它需要维护大量的密钥序列,因此它的计算效率是非常低的。
2.3 安全索引
它的核心思想如下:首先对文档中的关键词统计其词频信息,然后构建安全索引,其构建的索引中包含词频统计信息,然后采用顺序加密算法加密其词频统计信息,将索引和密文发到服务器端,检索时,输入要搜索的关键字,将得到拥有该词的所有密文文档,然后对这些密文文档根据词频进行排序,然后将排序的结果返回给客户端[9-10]。
排序搜索算法的缺点是只允许一次只查询一个词,还有就是此算法只使用了词频并没有使用逆文档频率,而在实际应用中,只有词频和逆文档频率共同使用才能得到精确的排序。
3 基于同态加密的密文检索方案
3.1 现有的同态环境下的密文检索方案
同态加密技术可以直接对密文进行操作,因此可以将同态加密技术应用到云端的密文检索中,这样既可以保证用户数据的安全,也可以在一定程度上提高密文检索的效率。文献[12]提出的基于同态加密的密文检索技术主要分为以下几步[12]:
(1)用户上传文档之前先将文档M分成若干长度为L的分组,设M=m1,m2,m3…..mt,假设这里采用的加密算法为本文提出的同态加密方案,则ci=mi+pr11+pqr12,然后将各个分组密文合并得到文档密文,最后将文档密文上传到云端。
(2)客户端检索时,设要检索的关键词为mindex,首先将其加密得到其密文cindex=mindex+pr21+pqr22,然后将关键词密文上传到云端。
(3)计算设匹配结果为result,则result的值如公式(3) 所示:
result = (ci-cindex)qribmodN=
(3)
在云端检索时,要先向云端上传qri和N,其中N=pq,由上述公式可得,若result=0,则匹配成功,即检索到所需文件。
可以看出,文献[12]提出的同态环境下的密文检索方案,其在云端的密文检索操作主要还是线性匹配,它并没有计算检索项和各个文件的相似度,并按相似度对检索出的各个文件进行排序。
3.2 BVH
BVH是在上述的密文检索方案的基础上结合文献[9-10]对密文检索方案进行改进,得到一个基于向量空间模型全同态环境下的密文检索方案,其总体架构如图1所示。

图1 BVH的总体架构图
从以上可以看出BVH共分为客户端和服务器端(即云端)两部分,客户端主要进行文档集和检索项的预处理和对云端返回的结果的处理,服务器端主要进行的是存储和检索。下面详细分析这3个阶段。
3.2.1 文件和检索项的预处理
文件和检索项预处理阶段的主要工作如图2所示。
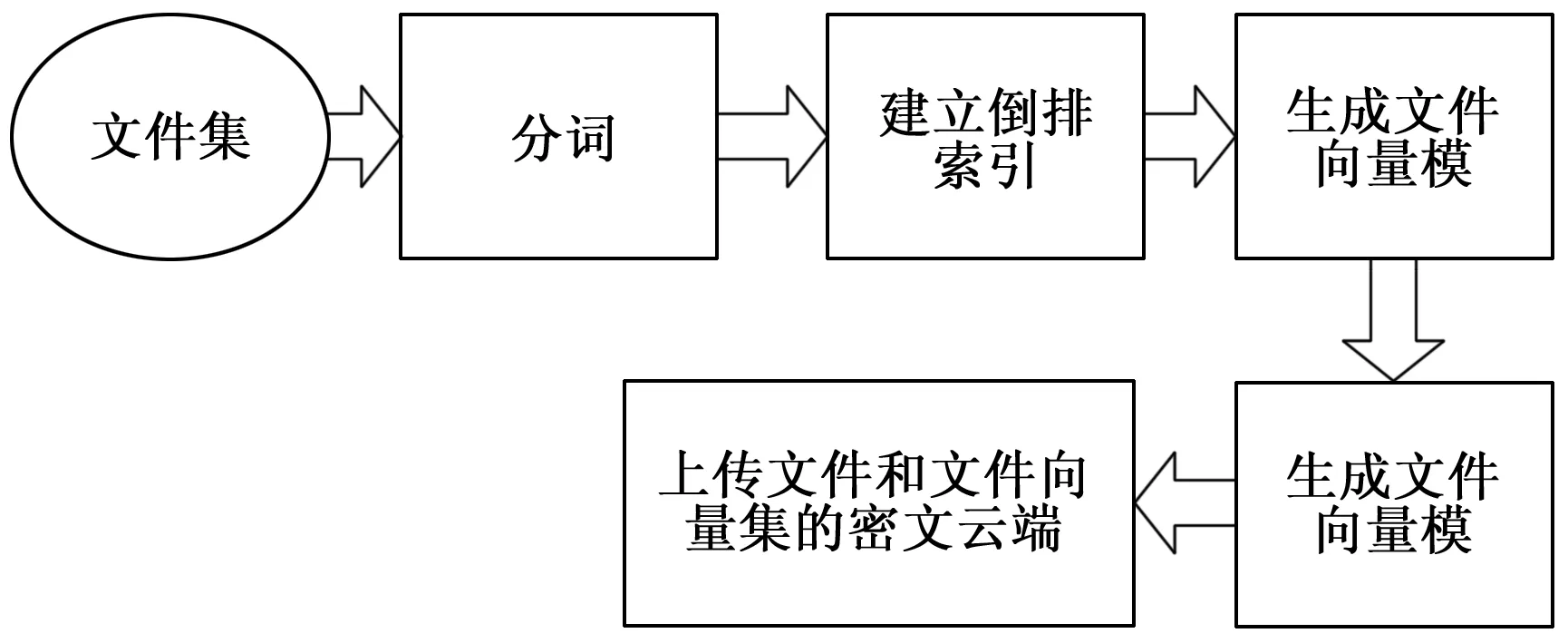
图2 预处理阶段架构图
建立倒排索引的第一步是文档分词,首先要过滤掉那些停用词,即那些没啥实际含义但出现频率很高的词,这些词对文档区分意义不大,所以要先把它过滤掉。
在很多检索系统中,倒排索引的建立一般是在服务器端进行,这样做虽然减少了客户端的压力,但是它有一个致命的缺点,就是它暴露了关键词的词频信息,考虑到安全等因素,在BVH中,倒排索引的建立放在客户端进行[9-10]。
假设文件集为test1,test2,…test5,最后形成的倒排索引表如下所示。
guide(test4,1)(test5,1)(test2,2)(test3,1)
perilous(test4,1)(test5,1)(test2,2)(test3,1)
others(test4,1)(test5,1)(test2,2)(test3,1)
hold(test4,1)(test5,1)(test2,2)(test3,1)
倒排索引表建立好以后,紧接着就是根据倒排索引表生成文件向量集,BVH所使用的权重框架是TF-IDF权重框架,其中TF代表的是关键词的项频,IDF代表的是关键词的反文档频率,设wij代表关键词ki对文档dj的TF-IDF权重。在BVH中,各个文档项和查询项所用的TF-IDF框架都如式(4)所示:
(4)
其中fij代表关键词ki在文档dj中的词频,N/ni代表关键词ki的反文档频率,从上述公式可以看出,关键词的词频越高,文档频率越低,其权重越高。设共有t个关键词项,且它们之间相互独立,定义文档dj为t维空间上的向量 ,则dj的值如公式(5)所示:
(5)
在方案BVH中,最终上传到服务器端的不是倒排索引表,而是文件向量集的密文,因为方案BVH采用的同态加密算法是基于整数的,所以在这里采用wij*10a(a取决于你要求的精度)将关键词的权重值转换为整数值。
文件向量集建好以后,按公式(6)计算文件向量的模:
(6)
然后将各文件名和对应的文件向量的模保存在客户端为之后的密文检索服务。最后把文件向量集和文件集加密以密文的形式存储到云端
文件向量集的密文形式如图3所示。

图3 文件向量集密文结构图
3.2.2 文件的检索
文件检索阶段的主要工作如图4所示。

图4 文件检索阶段架构图
在BVH中,用户只有登录验证成功以后,才能去云端检索文件。登录成功后,在客户端首先要对检索项做和文件集一样的预处理工作生成检索项权重向量,其中检索项中各关键词的权重按如下公式计算,设检索项中关键词的权重为wiq, fiq为关键词 ki在检索项q中的词频,ni为包含关键词ki的文档数,N为文档集总文档数,则wiq的值如公式(7)所示:
(7)
最后把检索项的权重向量密文上传到云端准备进行密文检索。
因为BVH所采用的检索模型为基于TF-IDF的向量空间模型,因此检索的过程就是计算文件集中各文件的向量与检索项向量的相似度,在服务器端的是文件集向量和检索项向量的密文,因为BVH所采用的加密算法满足加法同态和乘法同态,因此可以直接对文件向量集的密文和检索项向量的密文进行相似度计算,它并不会影响最终的计算结果。
(8)
首先,因为本方案所采用的同态加密算法基于整数,其加密过程会产生噪声,因此BVH所使用的同态加密方案能够处理的电路深度是有限的。其次,方案BVH采用的同态加密方案是基于整数的,其计算除法和开根号的效率很低,因为文件向量的模是不变的,所以可以在预处理阶段把文件向量的模还有检索项的模提前计算好保存在客户端供计算结果处理阶段使用,所以在此阶段无需计算文件向量集和检索项向量的模,也无需计算除法和开根号,只需计算两个向量的相乘,两个向量的相乘其加法和乘法的运算深度为一,可知其必定是满足同态特性。

(9)
检索阶段最后计算结果的格式如图5所示。

图5 检索阶段计算结果示意图
3.2.3 计算结果的处理
计算结果处理阶段的工作主要如图6所示。

图6 计算结果处理阶段架构图
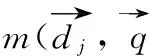
(10)
在计算出检索项和各个文件的相似度后,按相似度对各个文件从大到小排序,接下来就是到云端下载相应的文件返回给用户。
下载文件时,首先在客户端对文件名用本方案的同态加密方案进行加密得到其密文,然后将其密文上传到云端,再接着根据公式(11)(12)在云端找到要下载的文件进行下载,设待检索文件的文件名密文为cindex,云端文件的文件名密文为ci
(11)
(12)
在云端按公式(13)进行文件匹配,设匹配结果为result,则
result = (ci-cindex)qribmodN=
(13)
其中:N=pq,使用上述公式时,向云端上传N和 qri,因为ri是检索时随机产生的,所以从N和qri是无法得出密钥p的,所以上述公式是安全的。从上述公式得出,若result=0,则mi-mindex=0,即在云端匹配到要下载的文件,然后从云端下载文件即可。
4 实验论证
4.1 与文献[12]的方案检索准确率对比
在此部分采用的待检索的文档为test2,test3,test4,test5,test6,检索时,输入关键词others,两个方案的实验结果如图7~8所示。

图7 文献[12]的方案

图8 BVH
由于这里采用的同态加密是基于整数的,为了保证同态性,在这里对相似度计算结果的精度作了限制,由实验结果得知,文献[12]提出的方案仅仅列出了包含关键词others的文档,它并没有对检索到的文档按相似度大小排序,因此相比文献[12]提出的方案,BVH在检索的准确率上有了一定的提升。
4.2 与文献[12]的方案检索效率对比
此部分选取了7组数据,其如表1所示。

表1 实验数据
其实验结果如图9所示。
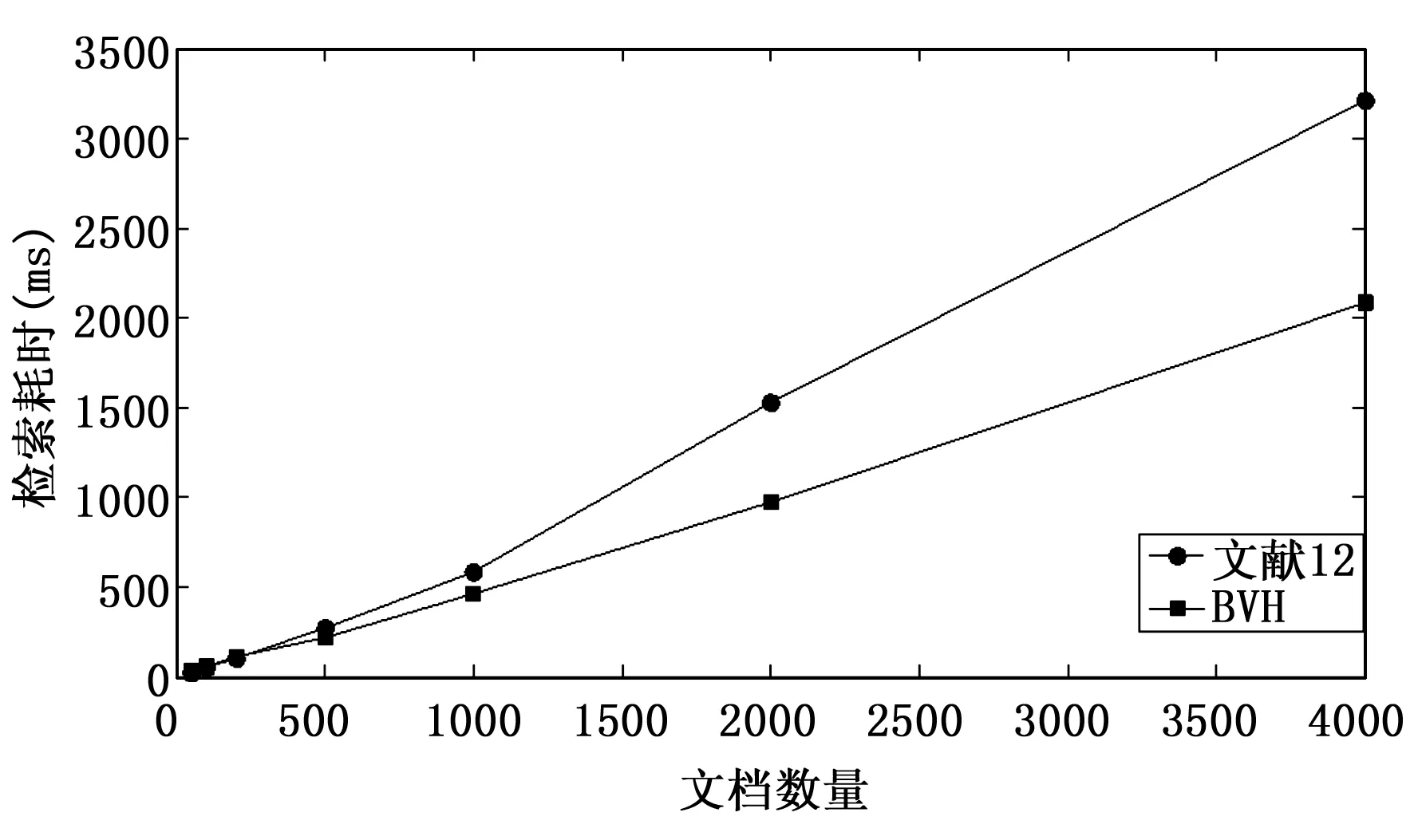
图9 BVH和文献[12]检索效率对比图
5 方案分析
由上述实验结果可得,BVH和文献[12]提出的同态环境下的密文检索方案其性能对比如表2所示。
表2 性能对比表BVH文献[12]提出的密文检索方案安全性高高准确率高低检索效率高低在BVH中,上传到云端的是文件集的密文和文件向量集的密文,其检索操作都是直接针对密文进行的,从以上可以看出,本方案很好的解决了云端数据的安全问题。
BVH所采用的模型为基于TF-IDF的向量空间模型,很好的解决了现有的密文检索技术不能按相似度对检索到的文件进行排序的问题,因此方案其BVH检索的准确率相比文献[12]提出的密文检索方案要高。
因为同态加密方案加密过程可能会产生噪音,即随着电路深度的增加有可能不满足同态特性,若要使它成为一个全同态加密方案,就需要采用解密电路压缩技术和重加密技术,这在实现起来是非常困难的,为了解决这个问题,BVH在计算相似度时,将计算过程分为多步进行,一部分在云端进行,一部分在客户端进行,以此保证在云端密文的计算满足同态性,由于在云端针密文计算的复杂度大大降低,而且在客户端文件向量的模预处理阶段已经计算好了,因此相比文献[12]提出的密文检索方案,BVH的密文检索效率会有所提高。
6 结论
本文首先分析了现有的全同态加密算法,然后再此基础上,提出了一个基于整数的同态加密算法。其次介绍了现有的一些密文检索技术并指出了它们存在的缺点。最后结合同态加密技术和基于TF-IDF的向量空间模型,提出了一个同态环境下的密文检索方案BVH,此方案有以下优点:首先,该方案采用同态加密技术对云端的数据加密,在云端都是直接针对密文进行操作的,这在一定程度上保证了云端数据的安全性。其次,该方案中采用了基于TF-IDF的向量空间模型,它会对检索到的文件按相似度从大到小进行排序,最后把结果返回给用户。综上所述,方案BVH既能保证云端数据的安全,又能保证检索数据的准确性,所以它更加符合云端数据检索的实际需求。
[1]冯登国,张 敏,张 妍,等. 云计算安全研究[J]. 软件学报,2011,22(1):71-83.
[2]张雪娇. 基于整数上同态加密的云存储密文检索系统[D]. 青岛:中国海洋大学,2013.
[3]Aderemi A. Atayero, Oluwaseyi Feyisetan. Security Issues in Cloud Computing: The Potentials of Homomorphic Encryption [J].Journal of Emerging Trends in Computing and Information Sciences, 2011,2(10):546-552.
[4]Craig Gentry, Palo Alto. Fully homomorphic encryption using ideal lattices[A]. STOC '09 Proceedings of the 41st annual ACM symposium on Theory of computing[C]. 2009,3(10): 169-178 .
[5]Yin L F. The Analysis of Critical Technology on Cloud Storage Security[A]. 2013 International Conference on Computer Sciences and Applications[C].2013,2(7):26-28.
[6]岳秋玲.有限素域上的全同态加密方案及其应用研究[D].哈尔滨:黑龙江大学,2014.
[7]汤殿华,祝世雄,曹云飞. 一个较快速的整数上的全同态加密方案[J]. 计算机工程与应用,2012,3(2):117-122.
[8]谭凯丽.飞行记录数据云存储安全通信研究 [D].沈阳:沈阳航空航天大学,2014.
[9]赵英明.基于同态加密的密文检索技术研究 [D].包头:内蒙古科技大学,2014.
[10]黄永峰,张久岭,李 觅. 云存储应用中的加密存储及其检索技术[J]. 中兴通讯技术,2010,3(4):33-35.
[11]Schmidt P. Fully Homomorphic Encryption: Overview and Cryptanalysis[D]. Diploma Thesis, Technische Universitat Dortmund, 2011.
[12]郭璐璐. 云存储密文检索方法的研究[J]. 技术研究,2013,4(9):6-8.
Cipher text Retrieval Technology Based on Homomorphic Encryption
Lü Wenbin,Gong Changqing
(College of Computer Science, Shenyang Aerospace University, Shenyang 110136, China)
The existing cipher text retrieval techniques mainly adopt the Boolean model and can not calculate accurately the related degree of the search terms and the retrieved documents, then it can not sort precisely. In view of the above situation, combined with homomorphic encryption technology and vector space model technique based on TF-IDF, the paper proposed a cipher text retrieval scheme BVH , BVH is divided into three steps: the first is preprocessing stage, it's main work is the establishment of inverted index file and vector set, and the calculation of each document vector module, then uploads the encrypted document vectors and files to the cloud. The second stage is the retrieval stage, it mainly multiplys key words vector cipher text and each file vector cipher text and returns the result cipher text to the client. The third stage is the result process stage, it mainly decrypts the returned results, processes the decrypted results, and then sorts the processing results according to the similarity. The results of analysis show that the scheme has greatly improved in the safety, precision and retrieval efficiency.
homomorphic encryption ; vector space modal ; inverted index; cipher text retrieval ;similarity
2015-08-26;
2015-10-26。
辽宁省教育厅科学基金(L2013064);中航工业技术创新基金(基础研究类)(2013S60109R)。
吕文斌(1988-),男,山西省运城市人,硕士研究生,主要从事同态加密方向的研究。
拱长青(1965-),男,内蒙古省赤峰市人,教授,硕士研究生导师,主要从事云安全,下一代网络方向的研究。
1671-4598(2016)03-0154-05
10.16526/j.cnki.11-4762/tp.2016.03.042
TP309.7
B
