用电信息采集系统非结构化数据管理设计
2016-11-12祝恩国葛磊蛟
祝恩国,刘 宣,葛磊蛟
(1.中国电力科学研究院,北京 100192;2.天津大学电气与自动化工程学院,天津 300072)
用电信息采集系统非结构化数据管理设计
祝恩国1,刘宣1,葛磊蛟2
(1.中国电力科学研究院,北京 100192;2.天津大学电气与自动化工程学院,天津 300072)
针对用电信息采集系统的非结构化数据具有海量、接入点多而分散等特点,本文提出一种用电信息采集系统非结构化数据管理设计方案。首先,对用电信息采集系统的非结构化数据进行分类。其次,提出了数据采集、数据存储和数据挖掘等3部分的管理设计方案:数据采集主要实现非结构化数据的收集;数据存储包括数据预处理和Hadoop两部分,完成海量数据的快速存储;数据挖掘按照文本、视频、音频3种类别分类处理,实现海量数据挖掘应用。该方案对用电信息采集系统的海量非结构化数据管理,有一定的参考价值。
用电信息采集系统;非结构化数据;框架设计;海量数据;数据挖掘
全覆盖、全采集、全预付费的用电信息采集系统在国家电网公司的推广应用,提高了国网公司的电力营销服务能力,提升了电网企业形象,但是当前实际投入营运的国-网-省-市-县等用电信息采集系统所采集的用户数据,仅仅是涉及电力营销核心业务的电力用户计量计费的结构化数据[1-3],具有格式多样、数据分散、海量、增速快、利用率不高等特征;随着电网用户侧双向互动化业务的开展,大范围的用户日志分析、用能习惯预测等电力营销相关的高级应用将成为一种趋势,并且这类应用的基础输入数据不仅需要传统结构化数据而且需要电力客户的文本、音频和视频等非结构化数据支撑,致使现有的运行系统不仅面临实施条件、运维成本等问题,也将面临非结构化数据的采集、存储和挖掘等管理问题。
与相对于可直接存入Oracle、MySQL等数据库的二维逻辑结构化数据,任何不便于用二维逻辑表存储的数据统称为非结构化数据,主要包括办公文档、文本、图片、视频、音频等。对于非结构化数据的管理,近年来国内外有很多学者进行过相关研究:文献[4]针对非结构化数据难搜索、不易管理等特点,提出了非结构化数据-半结构化数据-结构化数据的三步转化方法,实现对非结构数据的管理;文献[5]为了处理海量、异构、关联等特征的非结构化数据,设计了融合HDFS、HBase、XMLDB等存储设施的非结构化数据统一存储管理平台。
对于Hadoop的应用研究,国内外学者也进行过相关研究,文献[6]为解决海洋环境信息中对海洋流场可视化和特征可视化的大数据问题,提出一种GPU嵌入Hadoop云平台的并行计算框架,大大提高了计算速度和显示效果;文献[7]为解决海量用户登录的身份认证问题,设计了一种基于身份认证ID-CAP的Hadoop访问控制方案。
本文针对用电信息采集系统非结构化数据具有海量、接入点多而分散等特点,立足对用电信息采集系统非结构化数据的管理,从数据预处理、数据存储和数据挖掘3方面阐述用电信息采集系统非结构化数据管理框架设计方案。
1 用电信息采集系统非结构化数据
用电信息采集系统是由主站、通信信道和采集设备3部分组成,主要实现对电力用户用电信息的数据采集、数据管理、电能质量数据统计、线损统计分析等,达到对电力用户用电信息及时采集和掌握,以及准确发现电力用户的用电异常情况,对电力用户的用电负荷情况进行有效监测和控制,并为峰谷电价、阶梯电价、智能费控等营销业务策略的实施提供支撑[8-10]。
近年来,随着电网智能化、自动化、信息化程度的增加,用电信息采集系统所采集数据一方面包括传统用电数据,即用电度数、电价信息、用户缴费信息、客户资料,另一方面也包括实时用电信息、异常故障报警信息。在欧、美等智能电网发达的地区,还包括地理位置信息、天气交通数据、电动汽车数据等。
但是,随着电网用户侧的双向互动化业务的开展,分布式电源、微电网和柔性负荷等接入电力系统,以及用户需求响应等新型业务的开展,对于用户日志分析、广域负荷需求预测、用户能源特性分析等基于大数据技术的用电信息采集系统高级应用正成为一个热点研究课题。如果仅仅以当前的用电信息采集系统中所含有的大型专变用户A类、中小型专变用户B类、三相一般工商业用户C类、单相一般工商业用户D类、居民用户E类等5类不同电力用户计量计费的结构化数据作为其分析的基础数据,很难对用户用能趋势和特性进行准确预测,无法满足未来实际电力营销业务的高级应用需求,需要电力用户的视频、文本、音频等非结构化数据的支撑。
A~E 5类不同用户的客户网络web页面资料数据、电子图片和视频信息、音频信息等非结构化数据,是用户用电特征抽取、用能影响因素深入分析,以及电力营销业务预警和预判的重要基础数据,根据其对用户用电预测和故障预判趋势分析的重要程度,按照其不同层次组成和5类不同用户所包含的数据内容,依据5类用户数据从A至E的逐层包含关系,可以大致分为基础类、普通类、专用类和特殊类等4种,如图1所示。
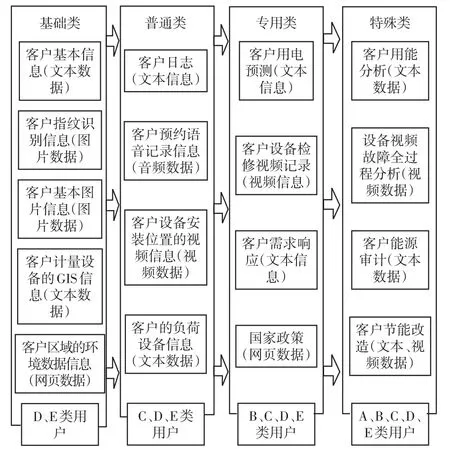
图1 用电信息采集系统非结构化数据组成Fig.1 Unstructured data of the electrical information acquisition system
然而,用电信息采集系统的非结构化数据具有海量(每年达到PB级别)、更新速度极快、分布地域广泛等实际的客观条件,当前非结构化数据管理技术、大数据的存储和分析技术均处于研究阶段,分析技术手段还不够完善、针对大数据的快速分析算法还不够成熟;同时,当前的硬盘、磁带、磁盘阵列等存储物理设备在内存容量、硬盘容量和处理器速度,以及性价比、异构的兼容性等方面也存在一些实际问题。因此,对用电信息采集系统非结构化数据的管理进行顶层设计非常必要。
2 系统架构
用电信息采集系统的非结构化数据一方面具有不同用户类型,其数据的大小和种类均不同,且从这些数据海量中难以快速发现有价值的规律性;另一方面,其的确具有很多内在的数据规律,符合大数据的特征信息,具备很大的挖掘空间;如果可合理利用有效的大数据分析工具对客户基本信息、客户日志、客户用电预测、客户用能分析等数据进行分析,对区域范围内的能源需求进行有效预测和预判,可为未来营销业务的拓展提供新思路。下面从顶层设计的思路,从数据采集、数据存储和数据挖掘3个方面进行用电信息采集系统非结构化数据管理的框架设计;数据采集负责完成前端数据的感知和收集;数据存储负责将非结构化数据进行结构化存储,主要包括数据预处理和Hadoop两部分组成;数据挖掘实现非结构化数据的利用。3部分层层递进,相辅相成,其最终的目标是实现用电信息采集系统的非结构化数据管理。其架构如图2所示。
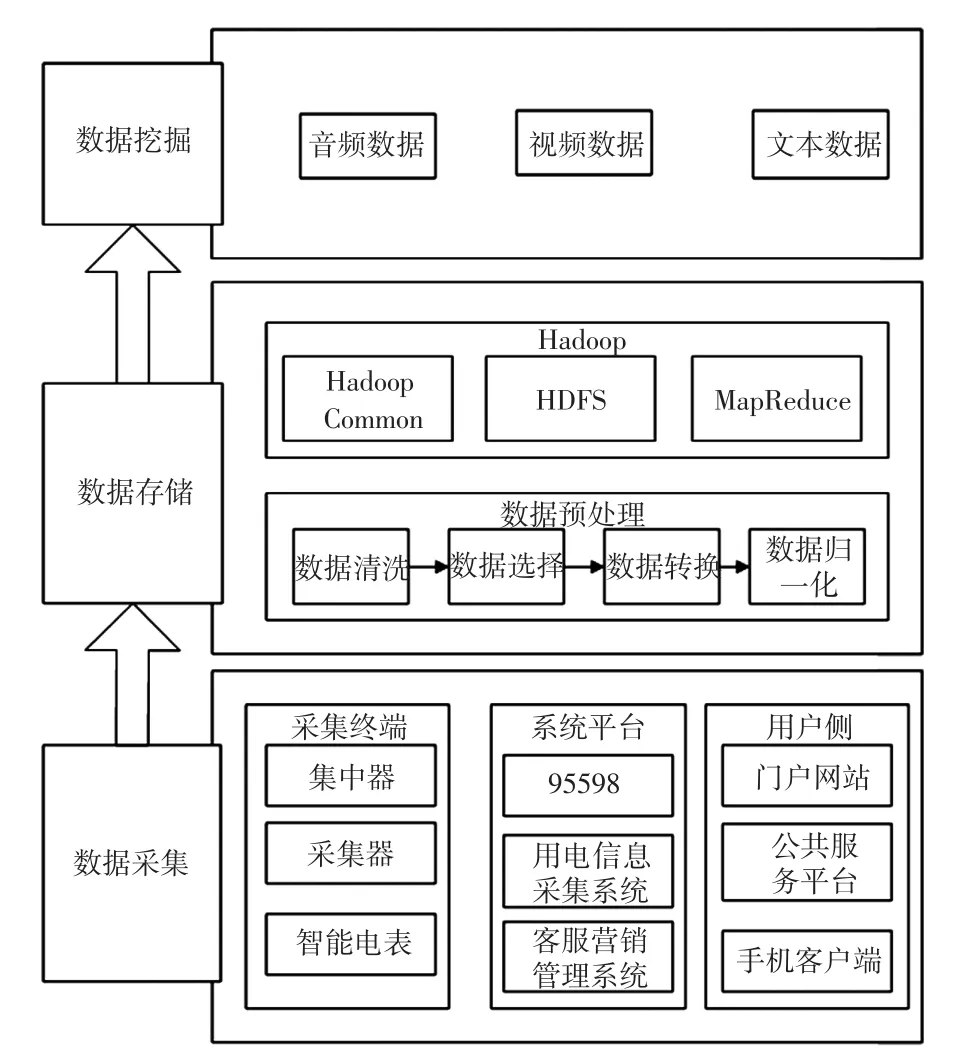
图2 用电信息采集系统非结构化数据管理系统架构Fig.2 Architecture of data management system of unstructured data for electrical information acquisition system
2.1数据采集
数据采集是用电信息采集系统非结构化数据处理的基础和最前端,也是其来源,所有的用户数据经采集完成后,经通信设备上传至数据中心,为数据存储做好前期准备;根据非结构化数据的不同来源,可以分为采集终端、系统平台和用户侧3个方面;其中,采集终端是指安装在用户计量现场的不仅可以采集传统计费计量结构化数据而且可以采集视频、音频等非结构化数据的采集设备,实时实现对用户信息采集、上传等,主要有集中器、采集器和智能电表;系统平台是指电网企业为了用电营销业务开展所建设的客服、运维、收费等系统,主要有95598、用电信息采集系统和客户营销管理系统;用户侧是指电力用户为了追踪、查询其自身的电费、设备报修等情况所使用的信息渠道,主要有门户网站、公共服务平台和手机客户端等。
2.2数据存储
用电信息采集系统的非结构化数据有以下几个特点:①视频、音频、文本等非结构化数据格式不同,导致存储的空间范围和元数据的内存划分尺度不同;②相同数据格式,不同的用户其数据的容量大小和属性不同;③不同的数据格式和不同的数据属性组成混合文件属性。如此多样性的非结构化数据,从前端采集进入管理系统后,给数据存储、分析和挖掘均带来诸多不便,因此,首先在硬件层面上,利用Hadoop的分布式架构,从国-网-省-市等各层级现有的用电信息采集有关的计算机资源,进行主从式虚拟化,完成基础构建,由于此部分是Hadoop平台的基本功能,这里不再赘述[11-18];然后进行数据预处理,最后利用Hadoop技术进行存储管理。
2.2.1数据预处理
针对用电信息采集系统的非结构化数据特征,拟采用的数据预处理主要包括数据清洗、数据选样、数据变换和数据归一化4个部分,最终实现用电信息采集系统非结构化数据的分类管理,提炼含有数据检索信息的元数据,形成以半结构化数据的Xml格式表示实际数据存储地址的元数据库,为下一步数据存储Hadoop提供前期的准备,从而完成数据预处理工作。其过程如图3所示。
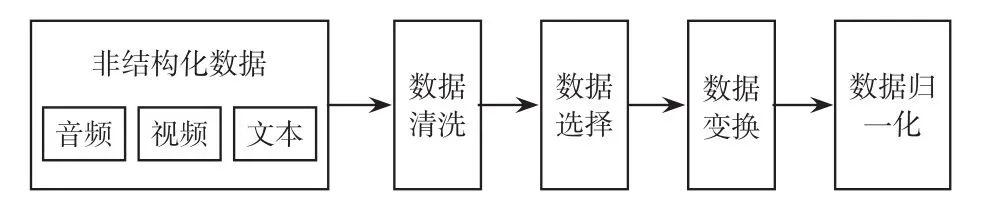
图3 用电信息采集系统非结构化数据预处理Fig.3 Data preprocessing of unstructured data for electrical information acquisition system
数据清洗:数据清洗是一种同一实体可能对应多条记录信息的信息处理技术,常采用的方法是基本近邻排序算法SNM(stored neighborhood method),其主要的思想是将数据集合中的记录按照指定的关键字(key)、特征格式(txt、rm等)等特征值进行排序,然后在排序后的数据集合上依次移动一个固定大小的窗口,通过检测窗口内的记录,判定它们是否与相关关键字或者特征格式相匹配;一般分为抽取特征值、数据排序和合并3个步骤。
数据选样:数据选样是根据预设的特征值从数据集合中选取数据;其选样的标准是数据集合中被选中数据在特征上应与特征值数据一致或者接近;主要的方法有简单随机选样、分层选样、逐步向前选样。
数据变换:数据变换是将已经选样好的数据,根据用户设定形成xml格式的元数据过程,一般是根据不同数据,决定选样不同的数据变换方法;常用的变换方法有简单函数变换、规范化[19-24]。
数据归一化:数据归一化是将变换后的数据集合进行xml格式元数据和实际数据映射关系标准化的统一表示,其主要的技术有维度归一化、属性选择和离散化技术等。
2.2.2Hadoop
Hadoop是从2004年出现的一个开源分布式计算框架,主要包括Hadoop Common、HDFS(hadoop distributed file system)和MapReduce 3部分,是由Yahoo支持研发,随后在百度、新浪、Amazon、Facebook、淘宝等大型IT企业都得到最为广泛应用的开源云计算软件平台之一。其主旨是构建一个具有高可靠性和良好扩展性的分布式系统,主要优点是扩容能力强、成本低廉、效率高、高可靠性、免费开源及良好的可移值性。
其中,Hadoop Common主要分为两个阶段,第一阶段是Hadoop0.20及以前版本,主要包含HDFS、MapReduce和其他项目的所有公共内容;第二阶段是从0.21版本开始,由于HDFS和MapReduce全部成为独立项目,于是HDFS、MapReduce以外的所有公共内容均为Hadoop Common。
HDFS和MapReduce是Hadoop的核心内容,均采用典型的Master/Slaves结构;其中,HDFS的Master/Slaves分别对应Namenode/Datanode进程;MapReduce的Master/Slaves则分别对应JobTrackers/TaskTrackers进程。
1)HDFS
HDFS是一个针对PB级大数据存储和管理的分布式文件系统,类似于Google的GFS(google file system),并能够管理非结构化数据,具有Master/Slaves架构,由Namenode和Datanode两个部分组成;其中,Master节点仅仅存在一个,并运行进程Namenode;而Slaves节点可以具有多个,每一个Slaves节点运行一个进程Datanode,并且Namenode与每个Datanode之间通过Heartbeat的方式进行通信和管理。
1939年生于吉林长春。1955年考入东北美专附中,1964年毕业于鲁迅美术学院中国画系。曾任辽宁画院院长。现任辽宁画院顾问,中国画学会常务理事,辽宁中国画研究会执行会长,中国同泽书画研究院终身名誉院长,中国当代画派联谊会常务副主席,中国国家画院研究员、国家画院赵华胜工作室导师,国家一级美术师,辽宁省文史研究馆馆员,辽宁省政协第六、第七、第八、第九届委员。关东画派领军人及代表性画家。享受政府特殊津贴专家。
同时,一般实际文件的元数据(FSImage信息和EditLog信息)存放在Master节点上,具体的文件内容存放在Slaves节点上。
而且,任意一个大文件均被拆分为64 M大小的多个文件块,分别存放在多个Slaves节点上;为了数据文件的安全性,每个文件块缺省有3个副本,其副本存放的具体位置按照Hadoop的放置算法自适应地计算所得。另外,一般HDFS中有默认的文件块大小和副本数,但是默认参数也支持手动设置,可通过设置Slaves节点上的dfs.block.size和dfs.replication两个参数,来设定设置文件块的大小和副本数。HDFS的组成情况如表1所示。

表1 HDFS的主要组件功能表Tab.1 Function table of main components in HDFS
另外,HDFS对应用程序的数据提供高吞吐量,并开放一些POSIX的必须接口,支持流式访问文件系统的数据;并且,HDFS将大规模数据按照默认的数据块进行分割、存储在多个不同数据节点组成的分布式集群中,具有较强的可扩展性;同时,每个数据块在不同节点中默认有3个副本,具有很高的容错性,以及在数据批处理方面具有很强的快速性能表现。
2)MapReduce
MapReduce适用于大规模PB级别数据计算,其主要思想来源于函数式编程语言,它由Map和Reduce两部分用户程序组成;Map负责将数据打散,Reduce负责将数据进行聚集;具有典型的Master/Slaves系统架构,一般在Master节点上运行Job-Tracker进程,在Slaves节点上运行TaskTrackers进程;并且,JobTracker进程作为控制主进程,会根据所处理数据的任务量,在计算机集群上运行多个TaskTracker进程实例来处理各个Map子任务,然后指派多个TaskTracker进程再对结果进行归并而完成Reduce子任务。
与传统关系型数据库相比,MapReduce具有处理数据规模大、数据更新速度快、数据集成度低等诸多优点,其对比情况如表2所示。
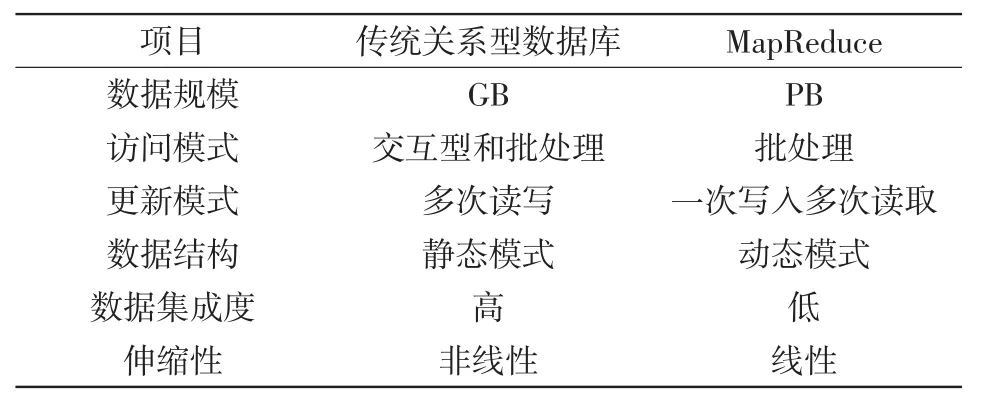
表2 MapReduce与传统关系型数据库对比Tab.2 Comparison between MapReduce and traditional relational database
3)Hadoop工作流程
非结构化的用电信息数据通过数据预处理后,形成了统一的标准xml格式元数据和实际数据两个部分数据,为基于Hadoop平台的数据处理提供了基础,基于Hadoop技术的用电信息采集系统非结构化数据管理工作流程如图4所示。
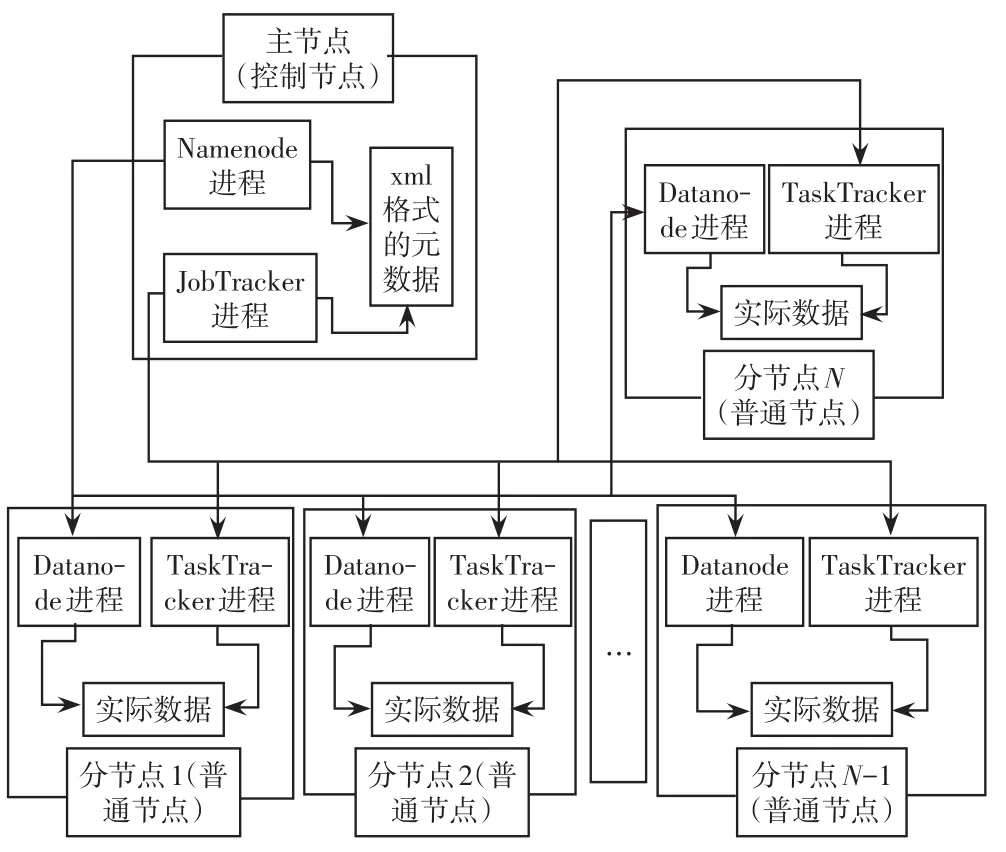
图4 Hadoop数据存储工作流程Fig.4 Workflow of Hadoop data storage
在主节点上,HDFS的Namenode进程对元数据的属性信息(FSImage信息和EditLog信息)进行备份、进程监测等管理;MapReduce的JobTracker进程对元数据的内容信息进行更新管理,例如一个大数据经过Map后,分散到下面具体分节点的节点号、数据表、字段等信息,被JobTracker及时计算出来,然后更新信息。在分节点上,HDFS的Datanode进程对实际数据的属性进行管理;MapReduce的TaskTracker进程对实际数据的分配进行管理,例如来自两个用户的实际数据,在分节点上分配、调度存入分节点的对应具体存储空间,由TaskTracker完成。
2.3数据挖掘
根据电网企业业务需求和电力客户需求,对海量的用电信息采集系统非结构化数据顺利进行及时、快速有效分析和挖掘,发挥其大数据的规模化效应,为企业和用户提供辅助决策支撑是数据挖掘的重要作用之一。
非结构化数据由于数据类型多样,差异性较大,无法按照处理传统结构化数据所采用的统一方式,其数据挖掘方法按照文本、视频和音频等3种不同类型分别进行,如图5所示。
数据挖掘的方法很多,且不同数据类型所适应的方法一般不同,关于文本数据,拟按照文本分类、分词和特征项抽取等方式进行处理;关于视频数据,一般采用可视化特征提取、对象识别、模型库比对等方法;关于音频数据,宜应用相关性分组、聚集和描述与可视化等技术。
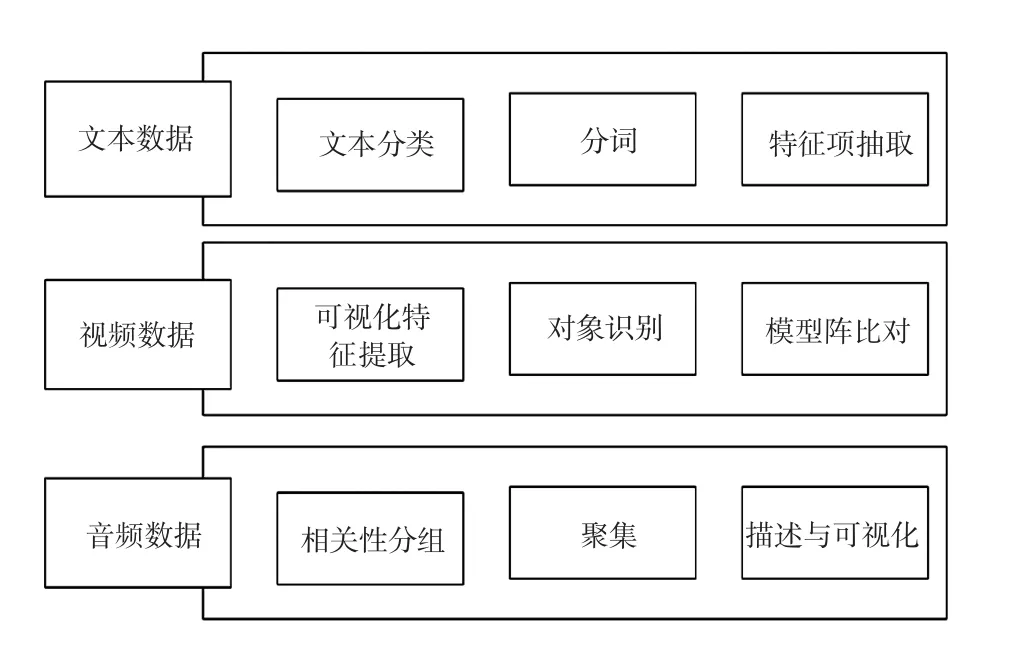
图5 用电信息采集系统非结构化数据挖掘技术Fig.5 Data mining of unstructured data for electrical information acquisition system
3 结语
本文根据用电信息采集系统所采集的A~E 5类用户数据逐层依次包含的特点,将其分为基础类、普通类、专用类和特殊类;为有效利用这些海量数据,提出了数据采集、数据存储和数据挖掘等3部分的系统框架,该设计框架在一定程度上解决了海量用电信息非结构数据管理问题。但是由于电力用户用电信息数据关系工业用户的能耗情况、商业用户的用能情况和居民用户的生活习惯,具有较强的隐私性或者商业秘密,对于在保障数据的安全、可靠的前提下,实现数据网络共享,发挥数据的实际作用,为管理节能、低碳电力提供实际的支撑是下一步的重点研究课题。
[1]陈驰(Chen Chi).基于用电信息采集系统的运行电表故障智能分析(Intelligent analysis on the malfunction meter based on the electric energy data acquisition system)[J].电测与仪表(Electrical Measurement&Instrumentation),2014,51(15):18-22.
[2]孔祥玉,房大中,崔凯(Kong Xiangyu,Fang Dazhong,Cui Kai).电力系统输电极限分析软件的设计与实现(Design and application of total transmission capability analysis software in power system)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2009,21(2):1-5.
[3]陆春艳,向兵,姜炜超,等(Lu Chunyan,Xiang Bing,Jiang Weichao,et al).用电信息采集系统中重复数据删除技术研究(Research on data de-duplication technologies in electric energy data acquisition system)[J].电测与仪表(Electrical Measurement&Instrumentation),2010,47(536A):87-90.
[4]万里鹏(Wan Lipeng).非结构化到结构化数据转换的研究与实现(Research and Implementation of the Transformation from Unstructured to Structured Data)[D].成都:西南交通大学电气工程学院(Chengdu:School of Electrical Engineering of Southwest Jiaotong University),2013.
[5]何颖鹏(He Yingpeng).非结构化数据统一存储平台的设计与实现(Design and Implementation of Unstructured Data Unified Storage Platform)[D].杭州:浙江大学电气工程学院(Hangzhou:College of Electrical Engineering,Zhejiang University),2013.
[6]张凯,秦勃,刘其成(Zhang Kai,Qin Bo,Liu Qicheng).基于GPU-Hadoop的并行计算框架研究与实现(Study of parallel computing framework based on GUP-Hadoop)[J].计算机应用研究(Application Research of Computers),2014,31(8):2548-2556.
[7]王志华,庞海波,李占波(Wang Zhihua,Pang Haibo,Li Zhanbo).一种适用于Hadoop云平台的访问控制方案(Access control for Hadoop-based cloud computing)[J].清华大学学报:自然科学版(Journal of Tsinghua University:Science and Technology),2014,54(1):53-59.
[8]Labrinidis A,Jagadish H V.Challenges and opportunities with big data[J].Proceedings of the VLDB Endowment,2012,5(12):2032-2033.
[9]Li Wei,Lang Bo.A tetrahedral data model for unstructured data management[J].Science in China Series F,2010,53(8):1497-1510.
[10]葛磊蛟,邢恩福,耿跃华(Ge Leijiao,Xing Enfu,Geng Yuehua).基于ATmega64云台板卡测试平台的设计(Design of the test platform based on ATmega64 for dome board)[J].微计算机信息(Micro Computer Information),2009,25(32):107-109.
[11]Abbasi A,Khunjush F,Azimi R.A preliminary study of incorporating GPUs in the Hadoop framework[C]//16th CSI International Symposium on Computer Architecture and Digital Systems.Shiraz,Iran,2012:178-185.
[12]Jungkyu Han,Ishii M,Makino H.A Hadoop performance model for multi-rack clusters[C]//5th International Conference on Computer Science and Information Technology.Amman,Jordan,2013:265-274.
[13]He Gang,Ren Siying,Yu Decheng,et al.Analysis of enterprise user behavior on Hadoop[C]//6th International Conference on Intelligent Human-Machine Systems and Cybernetics.Hangzhou,China,2014:230-233.
[14]Alam A,Ahmed J.Hadoop architecture and its issues[C]//International Conference on Computational Science and Computational Intelligence.Las Vegas,USA,2014:288-291.
[15]葛磊蛟,高波,周志超(Ge Leijiao,Gao Bo,Zhou Zhichao).用户侧用电安全检查技术浅谈(Discussion on inspection techniques of demand-side electrical safety)[J].供用电(Distribution&Utilization),2014(7):62-64.
[16]孙慧贤,张玉华,罗飞路(Sun Huixian,Zhang Yuhua,Luo Feilu).采用USB和CAN总线的电力监控数据采集系统(Data collection system for power monitor based on USB and CAN bus)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2009,21(1):99-103.
[17]张炳达,姚浩,张学博(Zhang Bingda,Yao Hao,Zhang Xuebo).数字化变电站过程层通信故障发生装置(Digital substation process layer communication fault generator)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2015,27(1):60-63.
[18]张少敏,李晓强,王保义(Zhang Shaomin,Li Xiaoqiang,Wang Baoyi).基于Hadoop的智能电网数据安全存储设计(Design of data security storage in smart grid based on Hadoop)[J].电力系统保护与控制(Power System Protection and Control),2013,41(14):136-140.
[19]Sadasivam G S,Selvaraj D.A novel parallel hybrid PSOGA using MapReduce to schedule jobs in Hadoop data grids[C]//Second World Congress on Nature and Biologically Inspired Computing.Fukuoka,Japan,2010:377-382.
[20]菅志刚,金旭(Jian Zhigang,Jin Xu).数据挖掘中数据预处理的研究与实现(Research on data preprocess in data mining and its application)[J].计算机应用研究(Application Research of Computers),2004(7):117-118,157.
[21]欧阳柳波,李学勇,杨贯中,等(Ouyang Liubo,Li Xueyong,Yang Guanzhong,et al).基于近似匹配模型的XML元数据检索(XML metadata retrieval based on approximately matching model)[J].计算机应用(Computer Applications),2005,25(4):820-823,826.
[22]王德文(Wang Dewen).基于云计算的电力数据中心基础架构及其关键技术(Basic framework and key technology for a new generation of data center in electric power corporation based on cloud computation)[J].电力系统自动化(Automation of Electric Power Systems),2012,36(11):67-71,107.
[23]曲朝阳,朱莉,张士林(Qu Zhaoyang,Zhu Li,Zhang Shilin).基于Hadoop的广域测量系统数据处理(Data processing of Hadoop-based wide area measurement system)[J].电力系统自动化(Automation of Electric Power Systems),2013,37(4):92-97.
[24]阿廖沙·叶,祝恩国,成倩,等(Aliaosha Ye,Zhu Enguo,Cheng Qian,et al).用电设备安全评估的改进区间层次分析法(Improved interval analytic hierarchy process method for electrical equipment safety assessment)[J].电力系统及其自动化学报(Proceedings of the CSU-EPSA),2015,27(1):32-36.
Management Design for Unstructured Data in Electrical Information Acquisition System
ZHU Enguo1,LIU Xuan1,GE Leijiao2
(1.China Electric Power Research Institute,Beijing 100092,China;2.School of Electrical Engineering and Automation,Tianjin University,Tianjin 300072,China)
According to the characteristics of massive quantity and numerous scattered points for unstructured data in the electrical information acquisition system,an unstructured data management framework is designed in this paper:first,the unstructured data are classified;second,a design scheme is put forward including data acquisition,data storage and data mining,where the first part realizes the collection of unstructured data,the second completes the fast storage of massive data by data preprocessing and Hadoop,and the third processes the massive data according to the categories of text,video and audio,respectively.This solution is useful for the management of massive unstructured data in the electrical information acquisition system.
electrical information acquisition system;unstructured data;framework design;massive data;data mining
TM727
A
1003-8930(2016)10-0123-06
10.3969/j.issn.1003-8930.2016.10.021
2015-03-116;
2016-01-10
国家电网公司基础性前瞻性科技资助项目(JL-71-14-001)
祝恩国(1978—),男,博士,高级工程师,研究方向为智能用电、电力需求侧管理技术、高级量测体系。Email:zhuenguo@epri.sgcc.com.cn
刘宣(1978—),男,硕士,工程师,研究方向为电力系统自动化、智能用电技术、用电信息采集技术。Email:liuxuan@epri.sgcc.com.cn
葛磊蛟(1984—),男,通信作者,博士,讲师,研究方向为智能配用电网和大数据等。Email:legendglj99@tju.edu.cn
