浅谈基于Hadoop平台的大规模数据排序
2016-11-02吕书林
门 威,吕书林
(河南广播电视大学信息技术中心,郑州 450000)
浅谈基于Hadoop平台的大规模数据排序
门 威,吕书林
(河南广播电视大学信息技术中心,郑州450000)
据IDC统计,2011年全球处理的数据量达到1.8 ZB,预计到2020年达到40 ZB。如何对海量数据进行高效分析和有效管理已成为大数据时代亟需解决的问题之一。商业数据、科学数据和网页数据这3类海量数据的异构性(充满着非结构化、半结构化和结构化数据)进一步增加了海量数据的处理难度。海量数据排序是海量数据处理的基本内容之一。Hadoop曾利用3 658个节点的集群在16.25小时内完成1PB数据的排序,获得Daytona类GraySort和MinuteSort级别的冠军。本文在设计层面上对Hadoop平台上海量数据排序策略进行分析。
Hadoop平台;海量数据排序;基准排序;云计算
1 基准排序
Jim Gray基准排序包含若干种基准,每个基准由多个规则构成,用于度量不同记录排序时间。约定情况下,每条记录长度为100字节,其中前10个字节是键,后面部分是值。MinuteSort用于比较一分钟内执行排序的数据量大小,而GraySort用于比较100TB以上的大规模数据的排序速度(TBs/minute)。基准规则约定如下:
1)输入数据和生成数据匹配且输入/输出数据都是未压缩的;
2)任务开始前不允许在操作系统内缓存数据;
3)分发程序到集群上的时间和抽样时间都要计入总时长;
4)如果输出多个文件,就必须是有序的;
5)必须计算出每个Key/Value对的CRC32校验值(128位),保证输入输出相对应;
6)输出文件保存到磁盘上;
7)输出数据不能改写输入数据。
根据Yahoo!测试结果显示:利用Hadoop平台下3 658个集群节点排列1PB数据用了975分钟,具体如表1所示。
2 Hadoop排序策略
首先设计3个Hadoop应用程序用于数据排序:TeraGen、 TeraSort和TeraValidate。在此,给出概括分析论述如下。
1)TeraGen。用于生成数据,可根据待执行任务数目给所有map分配任务,每个map生成所分配的行数范围内的数据。TeraGen利用1 800个map任务产生100亿行数据并存储到HDFS中,每个存储块设定为512MB;
2)TeraSort。是map/reduce程序,用于数据排序。首先利用N-1个有序的抽样值为reduce任务分配待排序数据行数范围。比如,把键值在[sample[i-1],sample[i])范围内的数据分配给第i个任务,因此第i个任务任意输出数据比第i+ 1个任务输出数据小。这里采用两层索引树策略加速数据分配。由于数据不需要复制到多个节点,可以将副本数设成1。在本实验中,相应分配1 800个map和reduce任务进行排序,为防止中间数据溢出,需要为任务的栈分布足够的空间;
3)TeraValidate。用于验证输出数据,具体为每个输出文件分配一个map任务(如图1所示),用于检查当前值是否全部大于等于前面的值,同时验证第i个输出文件中的最小值是否大于等于第i-1个文件中的最大值,否则抛出错误。
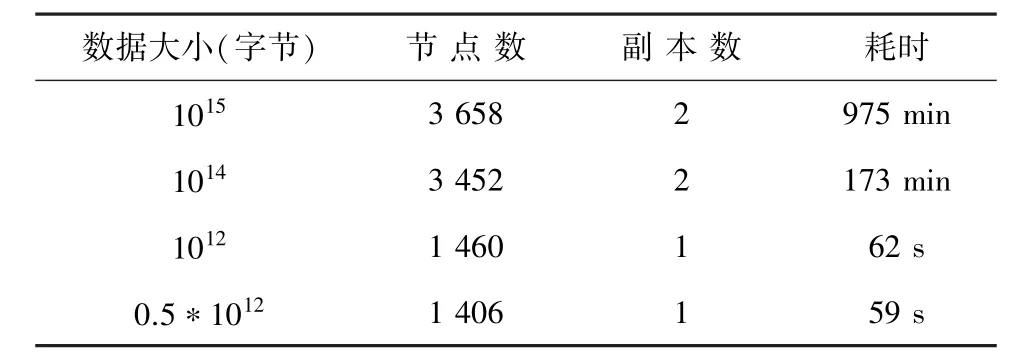
表1 排序时间和数据规模测验表Tab.1 Test results of sorting time and data size
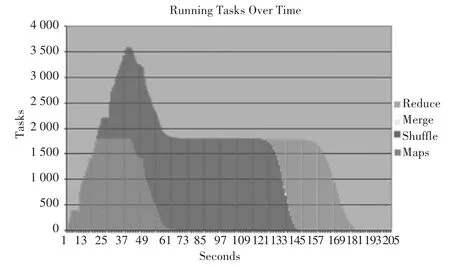
图1 各个阶段的任务量Fig.1 Number of tasks at each stage
该测试中,Hadoop集群配置如下:
1)910个节点;
2)节点配置:8 GB内存、1 GB以太网带宽,4个2.0 GHz双核处理器和4个SATA硬盘;
3)40节点/rack,rack到核心有8 GB带宽的以太网;
4)Red Hat Enterprise Linux Server 5.1操作系统;
5)JDK1.6.0,整个排序使用209 s。
依托910个节点的集群,Hadoop在209 s(3.48 min)完成了对1TB数据的排序。
3 Hadoop在GraySort基准排序中的改进
为适应于GraySort基准排序时,研究员在原map/reduce程序的基础上,对Hadoop进行适应性修改,将整个程序划分成4个模块:TeraGen、TeraSort、TeraSum和TeraValidate。各模块实现功能如下:
1)TeraGen利用map/reduce方法生成数据;
2)TeraSort负责数据取样,并使用map/reduce进行数据排序;
3)TeraSum负责计算每个Key/Value对的CRC32校验和,用于检查排序输出的正确性;
4)TeraValidate负责验证输出数据是否有序,计算校验和之总和。
本次基准排序测试运行在Yahoo!的Hammer集群上,集群配置如下:
1)3800个节点(大规模集群下需要冗余节点);
2)每个节点配备4个SATA硬盘、2.5 GHz的Xeons CPU、8 GB内存、1 GB以太网;
3)每个rack放置40个节点,rack到核心以太网带宽8 GB;
4)采用Red HatEnterprise Linux Server Realease 5.1操作系统;
5)采用Sun Java JDK 1.6.0 05(32 or 64 bit)。
在Hadoop平台方面的改进主要呈现在如下研究设计中:
1)重新构建Hadoopshuffle阶段的reducer部分,提高了shuffle性能,增加了代码的可维护性和易读性;
2)重构后shuffle过程可以从某一个节点获取多个map结果,减少了连接和传输开销;
3)允许配置shuffle连接建立时超时时间。小规模排序时减少shuffle超时时间,减少任务延迟时间;
4)把TCP设置成无延迟,增加JobTracker和TaskTracker之间的频率(配置成默认值的2倍,2秒/1 000节点),减少延迟时间;
5)增加用于检测shuffle数据正确性的代码块,防止reduce任务的失败;
6)在map输出时采用LZO压缩;
7)在shuffle阶段,在内存聚集输出map结果集的时候实现内存到内存的聚集,减少reduce运行工作量;
8)使用多线程进行抽样并建立一个基于键平均值的分配器;
9)JobTracker为TaskTracker分配任务的默认策略时先来先服务(FCFS),这种贪心算法不能很好地适应分布式数据。TeraSort实现了一次性分配的全局调度策略;
10)删除硬编码等待循环,禁用Hadoop 0.20的自动安装/清除任务功能以减少开始和结束的任务延迟;
11)日志级别设置成WARN以减少日志内容,提高系统性能。
实验表明,Hadoop经过改进后可以在更短时间内处理更多的数据。小规模的数据需要更快的网络和更短的延迟,因此使用集群的小部分节点进行计算;小规模计算过程短、集群规模小,节点故障率低,因此可以把计算输出副本数量设置为1。对于大规模计算,节点故障率高,需将输出副本数量设成2,且放置在不同节点上,保证某个节点出现故障时,数据不致丢失。
图2显示了不同时间点下的任务数量。maps只有一个阶段,reduces有shuffle、merge和reduce3个阶段.其中,shuffle用于从maps中转移数据,reduce负责将聚集数据写入到HDFS中。在图1中,Hadoop每次心跳只能建立一个任务,所有任务的建立需要40 s,而现在每次心跳可以设置一个TaskTracker,明显降低了任务开销。与图1比较发现,任务建立的速度明显变快了。
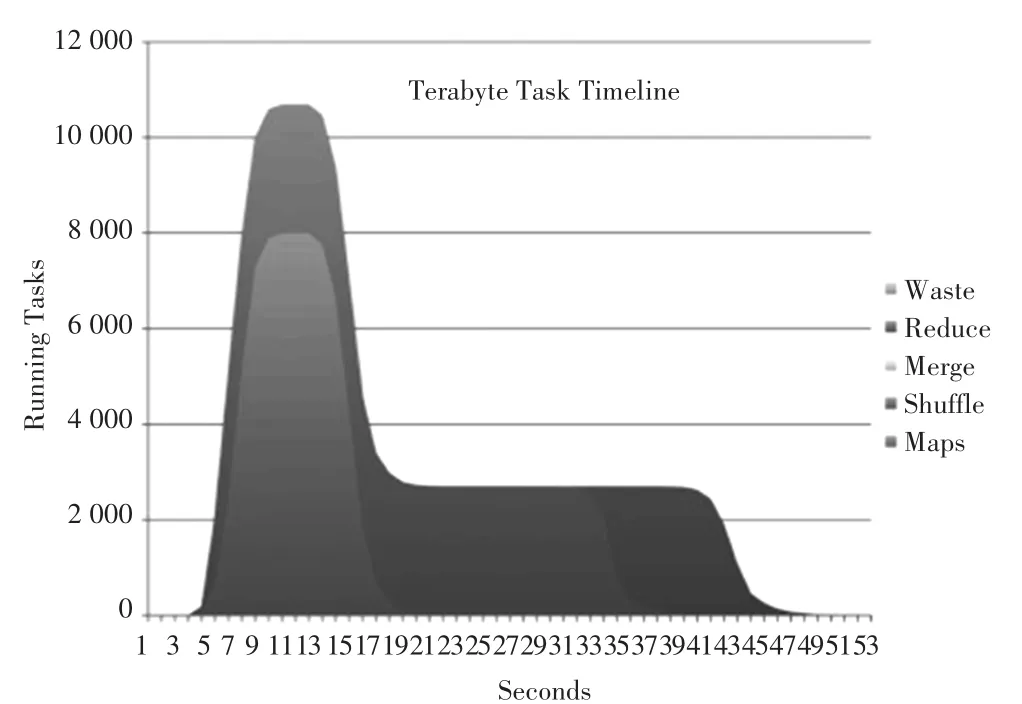
图2 不同时间段的任务数(1TB数据量)Fig.2 Number of tasks in different time periods
值得注意的是,数据传输规模和次数对数据排序性能的影响很大。例如在PB级别的数据排序中,把每个map处理的数据设成15GB,而不是默认的128 MB。因此,为了增加吞吐量,拓延每个块容量则至关重要。随着Hadoop的不断改进和优化,其在处理大规模数据排序方面的能力也将不断完善与增强。
[1]陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2011.
[2]Tom White.Hadoop权威指南[M].2版.北京:清华大学出版社,2011.
[3]蔡斌,陈湘萍.Hadoop技术内幕[M].北京:机械工业出版社,2013.
Research on large scale data sorting based on Hadoop platform
MEN Wei,LV Shulin
(Information Technology Centre,Henan Radio and Television University,Zhengzhou 450000,China)
According to IDC statistics,in 2011 the amount of data processing in the world has reached 1.8ZB,and is expected to reach 40ZB in 2020.It is an urgent problem how to analyze and manage the massive data efficiently during the time of big data.The heterogeneity of these 3 kinds of massive data,such as business data,scientific data,and web data(full of unstructured,semi-structured and structured data),has further increased the difficulty of processing massive data.The sorting of massive data is one of the basic contents of massive data processing.Hadoop has used the cluster with 3 658 nodes in 16.25 hours to complete the sorting of 1PB data,and gotten the champion of the Daytona class GraySort and Minutesort level.This paper designs and analyzes the massive data scheduling strategy based on Hadoop platform.
Hadoop platform;the sorting of massive data;benchmark sorting;cloud computing
TP391
A
2095-2163(2016)03-0130-03
2016-05-03
门 威(1988-),男,硕士,助教,主要研究方向:软件工程、云计算;吕书林(1987-),男,硕士,助教,主要研究方向:软件工程。
