一种有效的均值聚类初始化方法
2016-11-02张鲁营赵晓凡
张鲁营,赵晓凡
(北京交通大学计算机与信息技术学院,北京 100044)
一种有效的均值聚类初始化方法
张鲁营,赵晓凡
(北京交通大学计算机与信息技术学院,北京100044)
聚类算法是用来提取有用信息的重要技术,k均值聚类算法是其中应用最为普遍的聚类分析算法。然而,这种聚类算法的主要问题是,最终的聚类结果高度依赖于初始聚类中心。标准的k均值聚类算法使用随机初始中心会得到很差的聚类结果。因此,为了克服标准k-均值聚类算法的不足,本文提出一种基于贡献率的方法来优化初始中心的选择,以便得到一个好的聚类结果。将新提出的初始化方法应用到一些知名的数据集,将其与几种传统的初始化算法相比较,证明新提出的初始化方法具有良好的性能。本文所提出的方法不仅容易理解,而且聚类的迭代次数和执行时间也明显下降。本文的初始化方法可以保证得到一个比较好的聚类结果。
数据挖掘;k均值聚类;初始中心
0 引 言
数据挖掘是一种可在不同类型数据集上发现、并提取隐藏有用信息的过程。同时,聚类则是一种无监督的分类学习算法。而聚类分析即在数据挖掘中发挥着重要作用,已然广泛进入各种实际应用领域,如工程、生物学、心理学、医学和计算机视觉等[1]。聚类算法的主要任务是依据相似性进行分类,以便使得相似的数据在同一类,不相似的数据在不同类。一个优秀的聚类分析算法会产生比较合适的聚类结果,在这个结果中类内有很高的相似性而类间的相似性比较低。
近年来,聚类分析已成为学界研究热点[2]。因此,大量的聚类算法[3-5]即获提出,并用于数据分析,从而提取有用的信息。传统的聚类分析方法主要有以下几种:层次聚类算法,网格聚类算法、基于密度的聚类算法和基于划分的聚类算法。具体地,层次聚类是将数据集合进行层次的分解,建立一个层次结构,但层次聚类算法的时间复杂性太高。网格聚类算法则是使用有限数量的数据元素,最终形成一个网格结构。此外,基于密度的算法却必须定义参数的阈值,因而难以保证获得一个满意的聚类结果。然而,基于划分的聚类算法有较低的复杂度,不需要定义许多参数。因此,该算法随即成为具有高度普适性的实用聚类算法。
k-均值聚类分析算法是时下居于主导的常用划分聚类算法[6]。k均值聚类算法的主要优点是简单和快速,而且适用于大部分的数据集合。但k均值聚类算法也有如下缺点与不足。首先,必须预先确定集群的数量。然而,集群的数量确定通常来说却并不容易。其次,k均值聚类算法的结果受初始聚类中心的影响,不同初始值的选择将出现多重各异的聚类结果。因此有必要针对k均值聚类算法的缺点展开深入改进研究。本文主要讨论了如何选择有效的初始中心,基于此而使得k均值聚类算法能够获得最佳聚类结果。
1 常用的初始化算法
k均值聚类算法的实现主要分为2个步骤:首先,必须选择k个中心,然后是把给定的数据集中每个数据点分配到与其关联的最近的聚类中心。但仍需指出,这种聚类算法的主要缺点是算法结果高度依赖于初始聚类中心的选择。k-均值聚类算法的关键是对初始聚类中心的选择。在这一部分中,则将重点介绍几种常用的初始化方法。
在数据挖掘中,k-means++是一个选择初始聚类中心的算法。这是一个基于密度的初始化方法,并于2007年由戴维亚瑟和谢尔盖首次提出[7]。该算法的设计实现过程是先随机选择第一个初始聚类中心,随后的每个聚类中心均是选择剩余的数据点的距离概率较大的点。实施此种改进的目的是避免选择2个彼此接近的聚类中心。但是,该初始化方法的缺点经过研究可知却是,聚类结果将是不唯一的,因为第一个初始聚类中心是由随机选择而得。如此,将无法保证每个初始化质心的聚类都能得到最佳结果。
另有一种选择初始中心的新方法叫做KKZ方法[8],这种初始化质心的方法选择最宽的距离作为第一个初始聚类中心的向量,然后计算剩余的训练数据集,并选择距离最小的、直至满足要求的K个初始聚类中心。这种方法具有相当的优势:一方面,这种初始选择质心的方法很容易理解,因而可以简捷实现这个初始化方法。另一方面,还可以适用于广泛的数据集。而且,这种方法并不需要定义阈值。只是,如果一旦使用这个初始化方法,可能会发现比较差的初始聚类中心,因为选择的数据集合有时会有离群数据向量。
不仅如此,拉赫曼等人[9]又介绍了计算k均值聚类算法初始中心的新方法。这是基于排序算法的初始化的方法。首先,计算数据集上的每个数据点每一行的总和,然后依据得分和的大小排列数据集合,将排序后的数据集合分成k个子集,计算每个子集中的均值作为初始质心,这种初始化的方法不仅可以得到优良的初始质心,而且时间复杂度也比较低。此外,依据最近邻来选择初始质心也是一种常见的方法[10],但是依据最近邻选择初始质心的时间复杂度比较高,并且对大量的数据集合也并不适用。
基于此,针对现有聚类中心初始化方法计算复杂度高、对离群点敏感等问题,本文提出了一种新的基于贡献率的聚类中心初始化方法:CRCC算法。这种初始化的方法时间复杂性比较小而且不会因为离群点而影响实验结果。该初始化方法可以帮助k均值聚类的算法得到一个更好的聚类结果。
2 优化初始质心k均值聚类
2.1相关分析
聚类分析是机器学习的经典问题之一[11]。k均值聚类分析算法更是当下最为典型的基于划分的聚类算法,具体是在1967年由杰姆斯等人[12]最初提出的。k均值聚类算法旨在划分N个数据点X={x1,x2,…,xn},分成k个子集S={s1,s2,…,sk},以减少平方误差和。平方误差和的定义可做如下表述:
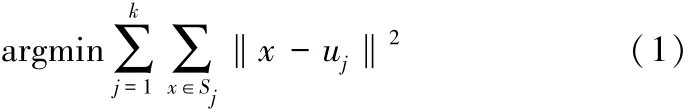
其中,uj是Sj的均值。k均值聚类算法性能的关键就是初始聚类中心的合理选取。但目前对于初始聚类中心的选择并未研发推出一个最佳方法来解决这个问题,即不能保证全局最优并且得到最好的聚类结果。同时,这是一个NP问题。在本文中,研究将引入一个新的启发式方法来选择初始聚类中心,并会产生更好的聚类结果。
综上研究可知,在已有的k-均值聚类算法中,使用初始聚类中心是随机的,而k-均值聚类算法的性能较差。为此,本文提出了一种基于贡献率的初始化新方法用来确定k均值聚类算法的初始质心,以便得到一个优质高效的聚类结果。新算法重点是基于排序,并且可以选择更好的初始聚类中心,而不是随机选择。
2.2优化初始质心k均值聚类
2.2.1CRCC算法
新方法的步骤为:首先对数据点的贡献进行排序,再将排序后的数据集分成若干个子集,并以此为基础计算每个子集的平均值,选择这些平均值作为初始聚类中心。
初始质心的选择算法执行流程可做如下概括描述:
输入:X={x1,x2,…,xn},k
输出:k个初始质心
1)计算数据集合中每一列的和,将数据点此列对应值除以这一列的总和获得单列贡献率;然后将这一行所有的贡献率的绝对值相加即获得这个数据点的贡献率;
2)根据贡献率的值将数据集合进行排列;
3)将排列好的数据集合分成k个子集;
4)计算每一个子集的均值;
上述算法主要是用于选择初始质心,该方法与已有的k均值算法选择初始质心不同,该初始聚类中心是根据排序算法计算所得。新方法的性能比已有的k均值聚类算法要更显优越,使用该方法进行聚类能够获得更快的收敛速度。此外,这是一个线性确定初始聚类中心的方法,相对于其他的初始化方法,时间复杂性将会显著降低。
在使用上述初始质心的选择算法得到初始质心之后,接下来数据点则要分配到对应的数据聚类中。分配后,每个数据点和对应类中的聚类中心有着最小的距离。因此数据点和聚类中心之间要根据距离来计算相似性,欧式距离是一种常见实用的聚类计算方法。假设有2个数据向量X={x11,x12,…,x1n},Y={y12,y22,…,yn2},欧式距离的计算公式如式(2)所示。
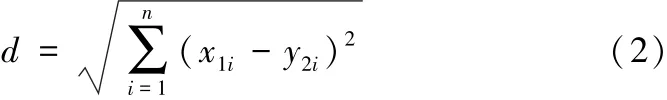
2.2.2分配数据点到聚类
分配数据点的算法[13]可以描述如下:
输入:X={x1,x2,…,xn},C={c1,c2,…,ck}(初始质心)
输出:S={s1,s2,…,sk}
1)计算聚类中心和数据集合中数据点之间的欧式距离;
“S就是这样跟小说家说的。现在,他们的婚姻进入了倒计时,却在身体上放纵如世界末日之前的狂欢。S很心虚,不敢拒绝,担心激怒曲,又怜惜她。婚姻大厦的柱础已断裂,墙基在下陷,屋瓦在抖落,随时都会分崩离析,而她还要在大厦将倾之际,醉生梦死,一丝不苟地完成性事。曲说,你不是喜欢这个吗?把欠你的全补上。”
2)将数据向量分配给对应的聚类,在该聚类中数据向量和聚类中心有最小距离;
3)重新选择聚类中心;
4)重复步骤2)和3),直到满足误差平方和最小。
3 实验结果
在这一节中,主要是仿真实现本文提出的初始化新方法,并将这种初始化方法的聚类结果与其他几种较为常用的初始化方法聚类结果进行比较。其中,使用的实验工具是MATLAB R2008a,实验数据是UCI上频繁选用的实验数据集合。在实验中,首先,必须定义数量集群的量值,无论是标准的k均值聚类算法还是优化的初始质心的聚类算法,下面将通过逐步分析验证提出的初始化质心新方法的有效性。
3.1数据集合的介绍
本文中,数据集是用来比较初始化算法的有效性。主要是将新提出的初始化算法和其他常用的初始化算法形成结果参照。如表1所示,即将本文算法中使用的数据集给出了一个整体介绍,重点列出了4个方面来描述数据集合:数据集的名称、数据点的个数、属性的数目和类别数目。
3.2实验结果和讨论
在本节中,研究将使用不同的初始化方法实现聚类结果的比较。具体来讲,k均值采用了随机初始聚类中心的聚类算法、k-均值++算法、SSE方法、最近邻的方法还有新提出的初始化方法。对于原始的随机算法则将采用10次的平均值作为实验的结果,因为初始质心的随机性使得若采用平均值,就可以提升实验结果的准确性。实验结果如表2所示。
下面,研究又用Rand Index的值来验证新的初始化方法的有效性,实验结果如表3、表4所示。
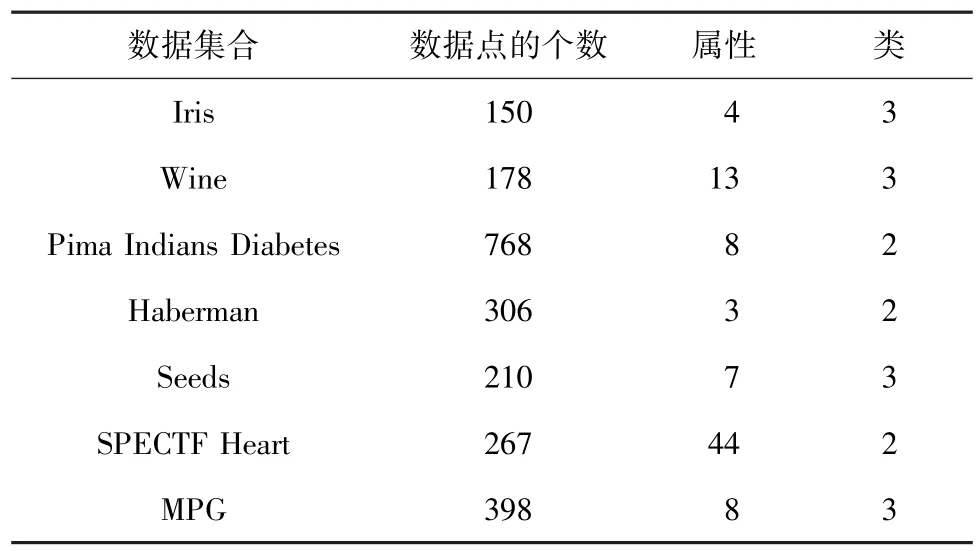
表1 数据集合Tab.1 Dataset
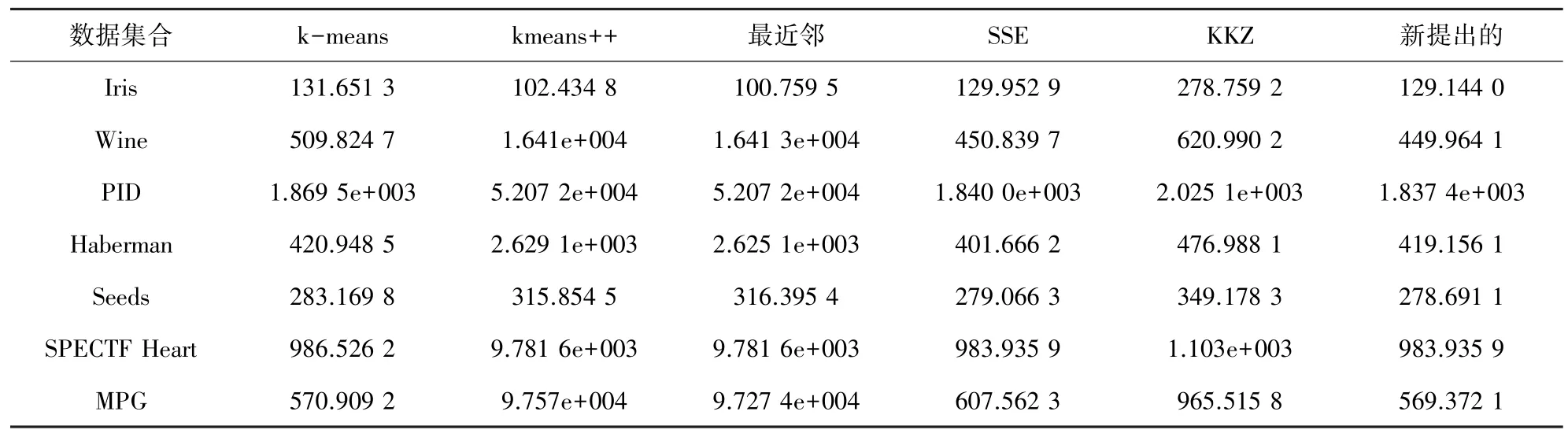
表2 误差平方和的结果Tab.2 Sum of squared errors
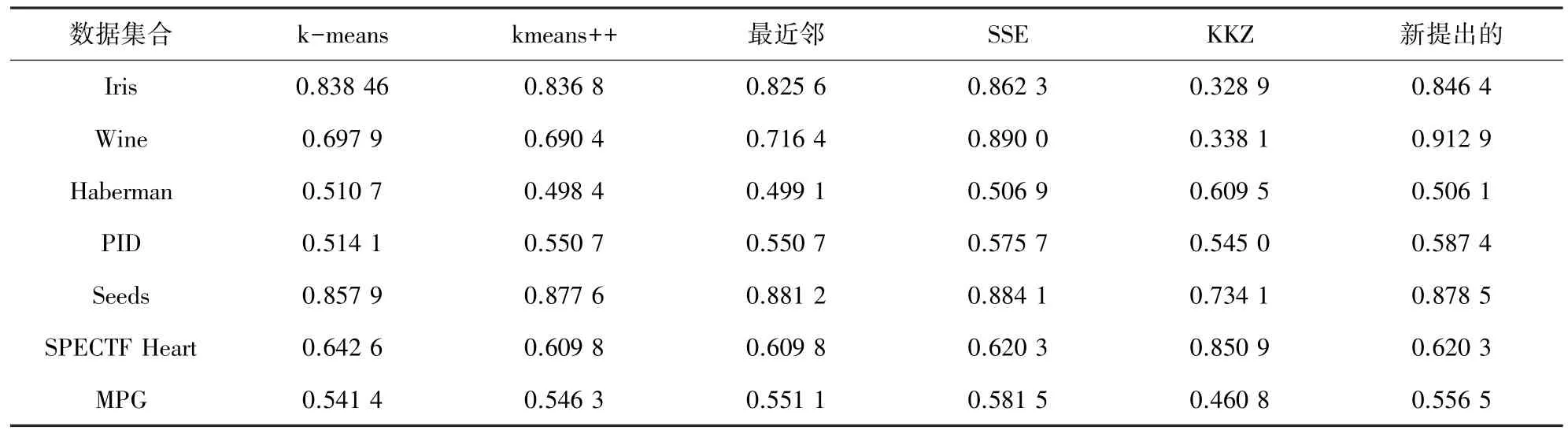
表3 指数Tab.3 Rand Index
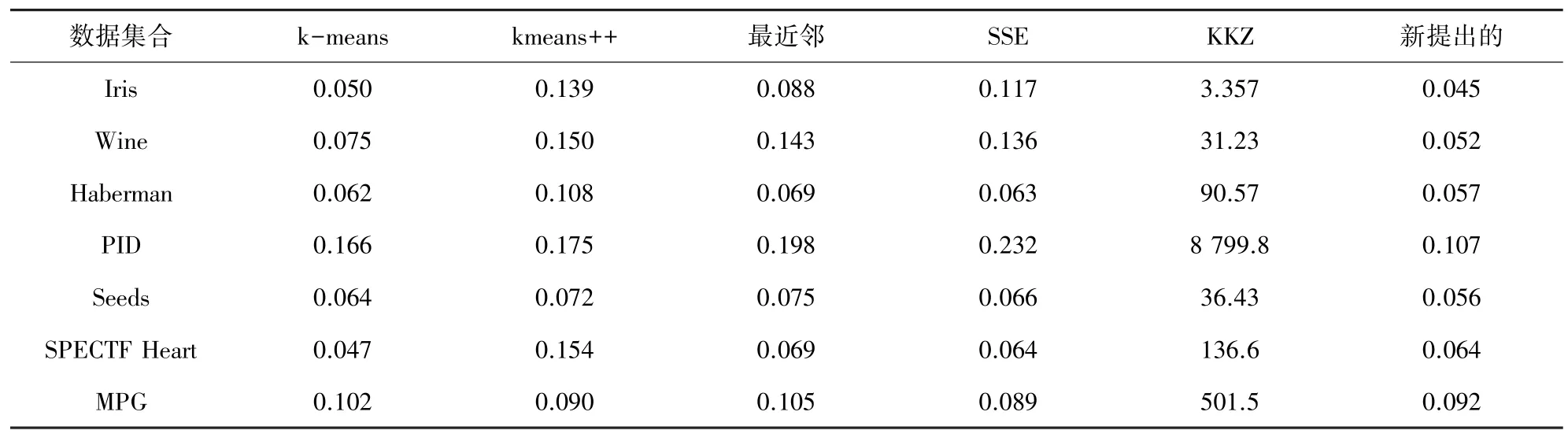
表4 执行时间Tab.4 Execution time
在上述实验过程中,k均值使用新提出的初始化方法与原方法及其他的初始化方法展开了结果比较和处理分析。k均值聚类算法和k均值++算法运行10次取均值作为实验结果,保证了聚类算法在实验过程中的准确性。在表2~表4中,分别通过不同的聚类标准针对新提出的方法进行了有效性验证,从实验结果表中可以看到新提出的初始化方法进行k均值聚类所得的实验结果比其他的初始化的方法得到的实验结果要呈现明显优势,不仅可以减少聚类时间降低时间复杂度,还可以得到更好的聚类结果。由此可知,新提出的k均值聚类质心的选择方法是有效、且可行的。
从实验过程的发生和完成中,能够发现新的初始化方法的优点。首先,原始k均值聚类算法的初始质心是随机选择的,并不能保证实验的稳定性,但新算法的初始聚类中心的选择是自动计算的,而且又是唯一的,从而提高了k均值聚类算法实验结果的稳定性。其次,新初始质心的实验过程简洁易懂,降低了时间复杂性,同时更能保证获得较好的实验结果。此外,新提出的初始化方法不需要任何参数作为输入得到的结果,因此,这就可以提高k均值聚类算法的实验结果的准确性和稳定性。最后,以新提出的方法来选择初始聚类中心在实现上具有高度可行性,而其特性呈现则是一个线性方法。总之,新提出的初始化算法是非常有效的,可以精准选择并确定k均值聚类的初始中心。
4 结束语
本文给出了一个新的初始化算法,k均值聚类分析算法是一种在数据挖掘中成功、且普及常用的聚类算法。标准的k均值聚类的初始聚类中心是随机选择的,使得聚类结果高度依赖于初始聚类中心,因此,标准的k均值聚类算法的性能仍有待提升。需要研制提出新的方法来选择初始聚类中心得到了学界高度重视,也必将提高k-均值聚类算法的有效性并获得良好的聚类结果。在本文中,提出了一种新的基于贡献率的方法来寻找聚类中心。利用该方法选择不同的数据集合进行测试,并采用不同的评价标准分析实验结果,结果表明所提出的初始化方法对聚类结果实现了明显改进,而且新提出的初始化的方法还表现了诸多优点,主要有复杂性比较低、简单易懂、不受离群点的影响等。
进一步地,后续工作主要是针对k均值聚类算法的另一个缺点,就是标准的k均值算法的结果受输入k值的影响而需要展开深入研究设计。在聚类过程中,研究必须预先定义k的值。预计未来将可找到一个新方法来计算k的值。
[1]KATHIRESAN V,SUMATHI P.An efficient clustering algorithm based on z-score ranking method[C]//International Conference on ComputerCommunicationandInformatics(ICCCI)2012. Coimbatore,INDIA:IEEE,2012:1-4.
[2]CELEBI M E,KINGRAVI H A,VELA P A.A comparative study of efficient initialization methods for the k-means clustering algorithm[J].Expert Systems with Applications,2013,40(1):200-210.
[3]RUNKLER T A.Partially supervised k-harmonic means clustering[C]//Computational Intelligence and Data Mining(CIDM)2011. Paris:IEEE,2011:96-103.
[4]BEZDEK J C,EHRLICH R,FULL W.Fcm:The fuzzy c-means clustering algorithm[J].Computers&Geosciences,1984,10(2):191-203.
[5]SHI Na,LIU Xumin,GUAN Yong.Research on k-means clustering algorithm:An improved k-means clustering algorithm[C]//Third International Symposium on Intelligent Information Technology and Security Informatics(IITSI)2010.Jian,China:IEEE,2010:63-67.[6]FAHIM A M,SALEM A M,TORKEY F A,et al.An efficient kmeans with good initial starting points[J].Georgian Electronic ScientificJournal:ComputerScienceandTelecommunications,2009,2(19):47-57.
[7]ARTHUR D,VASSILVITAKII S.k-means++:The advantages of careful seeding[C]//Proceedings of the eighteenth annual ACMSIAM symposium on Discrete algorithms 2007.USA:Society for Industrial and Applied Mathematics,2007:1027-1035.
[8]KATSAVOUNIDIS I,KUO C C J,ZHANG Zhen.A new initialization technique for generalized lloyd iteration[J].Signal Processing Letters,IEEE,1994,1(10):144-146.
[9]RAHMAN M M,AKHTAR M N.A modified approach for selecting optimal initial centroids to enhance the performance of k-means[C]//NCICIT 2013.Bangladesh:CUET,2013:117-121.
[10]KETTANI O,TADILI B,RAMDANI F.A deterministic k-means algorithm based on nearest neighbor search[J].International Journal of Computer Applications,2013,63(15):33-37.
[11]ONODA T,SAKAI M,YAMADA S.Careful seeding method based on independent components analysis for k-means clustering[J]. Journal of Emerging Technologies in Web Intelligence,2012,4(1):51-59.
[12]MACQUEEN J.Some methods for classification and analysis of multivariate observations[C]//Proceedings of the fifth Berkeley symposium on mathematical statistics and probability 1967.Oakland:IEEE,1967:281-297.
[13]MARIAMMA D,GOWTHAMI M,SINDHUJAA N.New algorithm to get the initial centroids of clusters on multidimensional data[J]. IJREAT International Journal of Research in Engineering&Advanced Technology,2013,1(1):1-4.
An efficient initialization method for the K-means clustering algorithm
ZHANG Luying,ZHAO Xiaofan
(School of Computer and Information Technology,Beijing Jiaotong University,Beijing 100044,China)
Cluster analysis is one of the important data mining techniques to extract useful information and the k-means clustering algorithm is one of the most common used cluster analysis algorithms for many practical applications.However,the main problem of this clustering algorithm is that the final clustering result highly depends on the initial cluster centers.Standard k-means clustering algorithm using random initial centers has a poor performance.Hence,to overcome the sensible of standard k-means clustering algorithm,this paper proposes a new algorithm for optimizing the selection of initial centers to make the k-means clustering algorithm more effective.The new proposed initialization method of k-means clustering algorithm is tested on some well-known data sets which are taken from UCI machine learning repository.According to the comparision of experiment results between standard k-means clustering algorithm and new proposed method,it shows that the new proposed method has a good performance.The results of proposed method are not only easy to understand but also the number of iterations and the execution time have been significantly reduced.It proves that the new proposed initialization method makes the original k-means clustering algorithm more effective.
data mining;k-means clustering algorithm;initial centers
TP391
A
2095-2163(2016)03-0017-04
2016-04-04
张鲁营(1990-),女,硕士研究生,主要研究方向:数据挖掘;赵晓凡(1981-),女,博士研究生,主要研究方向:数据挖掘。
