基于数据截断变换的主成分分析回归预测方法
2016-11-02苏嘉,关毅
苏 嘉,关 毅
(哈尔滨工业大学计算机科学与技术学院,哈尔滨 150001)
基于数据截断变换的主成分分析回归预测方法
苏 嘉,关 毅
(哈尔滨工业大学计算机科学与技术学院,哈尔滨150001)
针对DataCastle学生成绩排名预测任务:根据学生以往的在校信息预测下学期的成绩排名,结合现有的主成分分析方法以及多元线性回归模型,本文提出了基于数据截断变换的主成分分析回归预测方法,并与其它的方法进行了比较,结果表明:基于数据截断的主成分分析回归预测方法能够更好地预测学生下个学期成绩,预测准确率达到78.57%,优于对比的模型,在最终结果排行榜中排在前百分之十,因此可以较好地作为解决其它预测分析问题的工具。
截断变换;主成分分析;多元线性回归;预测
0 引 言
大数据分析、挖掘并在此基础之上的信息预测是当今信息化时代迫切面临的挑战和机遇。2014年巴西世界杯无疑是全世界足球爱好者的一场盛宴,而本次世界杯上另一新奇看点就是大数据的分析和预测。谷歌、百度、微软均各擅胜场地竞相给出了自家的赛事评测分析,就是分别根据以往比赛经验、球员技术、身体状况等信息成功预测了世界杯的16强。百度和微软甚至以100%的胜率预测了4强的名单,由此可见大数据的潜在价值。随着大数据时代的到来,基于事物以往信息的未来状态预测分析已经愈演愈热,预测分析在科学研究以及生活中具有广泛的优势发展空间,如天气预测[1]、经济走势预测[2]、健康疾病预测等[3-5]。
DataCastle也认识到了大数据的重要性,2014年发布了学生成绩排名预测任务:根据学生以往的在校数据,预测接下来一个学期的相对成绩排名。随之也公开了2组数据集:训练集数据和测试集数据。训练集数据包括某高校的538名在校大学生3个学期按学号递增排序的成绩排名、按日期递增排序的图书借阅记录、按日期递增排序的进入图书馆门禁记录、按地点代码递增排序的学生卡消费记录。测试集数据由另外某学院的91名学生3个学期的这4类信息组成,只不过没有给出该组学生第三学期的相对成绩排名。任务就是要根据训练集数据训练预测模型,以在测试集数据上预测测试集里91名学生第三学期的相对成绩排名。预测结果需要按91名学生的学号递增的顺序给出,并按照regression-SpearmanR算法计算预测结果和真实排名的Spearman相关性,相关性在[0,1]区间内,越接近于1,表示预测结果和真实排名越接近,具体计算公式如下:
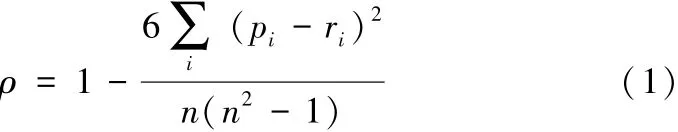
其中,pi,ri分别表示第i个学生预测的相对排名和真实的相对排名,n代表学生数,i=1,2,…,n。这里预测结果的Spearman相关性的计算是由DataCastle根据提交的结果进行的。
该评测的目的在于:一方面,就评测内容本身来说,通过预测结果,使得教育和学习更有目的性和针对性。首先,可以帮助学校制定合理的教学计划,对可能成绩下滑严重的同学提出警示,并开展有针对性的教育教学任务;其次,学生通过观察自己可能出现的成绩,自我调整,成绩好的可以保持现在的学习生活习惯,成绩不理想或有巨大下滑的可以通过改进现有的学习方法和调整生活作息安排来提高成绩,避免成绩下滑。另一方面,就评测长远意义来说,通过对数据的处理、预测、以及利用新的方法和技术手段来解决实际问题等过程,为大数据行业注入新的思想和方法以及优秀人才,这将会推动整个大数据行业的发展。
针对该评测,结合现有的主成分分析方法和多元线性回归模型,本文提出一种新的预测模型算法:基于数据截断变换的主成分分析回归预测方法,模型的具体构建过程见第二部分。同时,也对预测结果进行了提交,并就预测结果与其它5组预测方法进行了比较,实验结果证实了该模型的优异性。
本文第二部分为方法概述,详细描述了基于数据截断变换的主成分分析回归预测方法的理论。第三部分为实验部分,包括该模型的结果、与其它5组预测方法的比较以及结果分析。第四部分为总结部分。
1 方法概述
针对给出的数据形式,研究考虑对所给信息进行数据统计,并将统计得到的各学期每个学生的借书次数、进入图书馆次数、校园卡消费次数分别来代替图书借阅信息、进入图书馆门禁信息、学生卡消费信息。该方法的结构流程如图1所示。
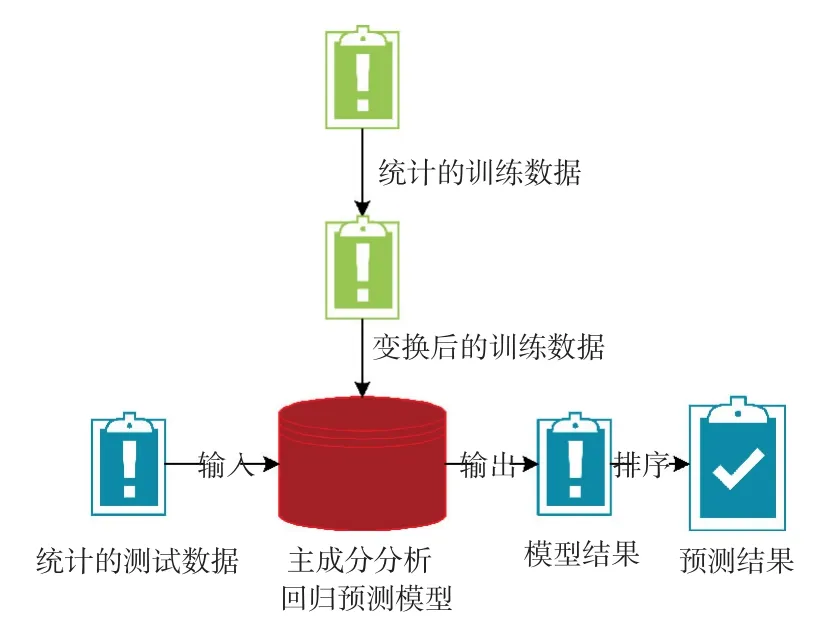
图1 方法结构图Fig.1 Structure of the model
由图1可知,将统计的训练集数据进行数据截断变换。之后,用得到的变换后训练数据对主成分分析回归预测方法进行训练,直至模型训练完毕。接着,对统计得到的测试集数据进行数据截断变换,并将变换后的测试数据输入已训练好的主成分分析回归预测方法,得到模型输出结果,再对结果进行相关排序,从而得到最终预测结果。下面详细介绍该方法的实现过程。
对于统计得到的各个变量数据:3个学期的借书量B1、B2、B3,进入图书馆的次数E1、E2、E3,校园卡消费次数C1、C2、C3,其中数值很小或者很大的点只有极少数。此处需要对每个变量的这些异常数据进行处理以使得这些极少的数据不会在较大程度上影响回归模型,从而提高预测结果的准确性。研究中利用上、下截断点作为判断数据异常的准则。要理解上、下截断点,首先得给出上、下四分位数Q3、Q1的概念。所谓上、下四分位数即为在一组从小到大的已经完成排序的数据中处在3/4位置和1/4位置的数据。在此概念基础上,上截断点T1就可以由以下公式得出:
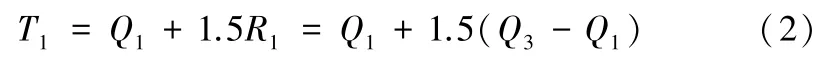
而下截断点T0则可以由以下公式得出:
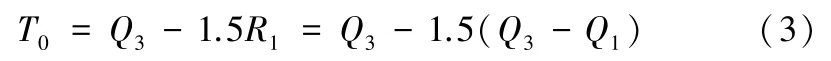
其中,R1=Q3-Q1表示的是四分位极差[6]。
计算得到了上、下截断点后,将对统计数据x(x∈B1,B2,…,C3)进行如下数据截断变换:

这里的T0、T1即为对应的x所取变量的下截断点和上截断点。
从所给变量来看,能影响第三学期成绩的预测因素有:前两学期的学生成绩S1、S2,3个学期的借书量B1、B2、B3,进入图书馆的次数E1、E2、E3,校园卡消费次数C1、C2、C3。考虑到影响因素众多,而研究中却希望能用较少的变量来尽可能详实地构建表达第三学期的成绩排名。降维的思想即已成为关键,这里采用的是主成分分析法[7-9]。主成分分析是多元统计学科中分析数据的一个重要方法,能够有效地减少影响因变量的因素,起到降低自变量维数的作用。同时,研究发现这些自变量中还有一些信息的重叠,如第一学期和第二学期的成绩排名,第一学期借书量和第二学期借书量等,用如上量值表达对第三学期成绩的影响时,重叠信息即会成为冗余性工作,只会增加计算量并可能会对结果形成负面的影响。而主成分分析则能够将自变量中有重叠部分的信息合并在一起,再通过线性变换将原来相关的变量转化为不相关的变量,合成后的新变量两两之间则彼此互不相关,并且新变量还能尽量地保留原来自变量的指示信息。变换的具体形式可如下所示:
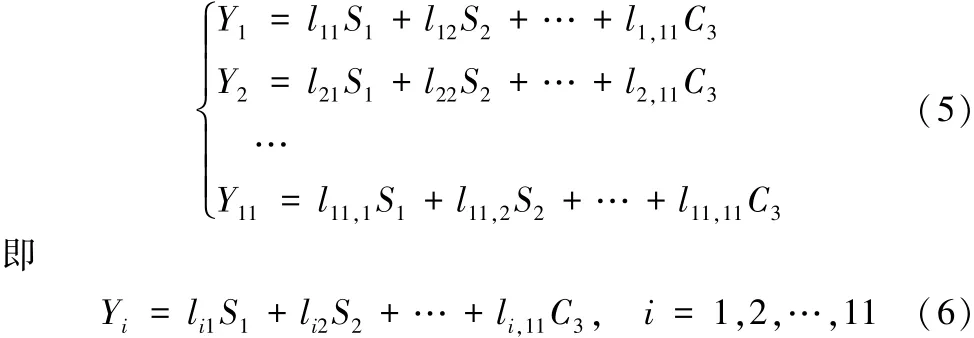
用原来11个变量的线性组合形成的新变量来代替旧变量,并且新变量要尽可能多地涵盖所有旧变量的信息,也就是新变量的方差越大、整体实现效果越佳。选取方差最大的新变量Yk1(k1∈{1,2,…,11})为第一主成分,如果第一主成分所涵盖的信息不足以代表原来的11个变量信息,则在剩下的新变量中再选取方差最大的Yk2(k2∈{1,2,…,11}/{k1}),作为第二主成分,以此类推,直到选取的所有主成分信息足够涵盖原来旧的变量信息(在90%以上即可)。同时为了避免有如旧变量一样的信息重复,主成分之间必须是线性无关的,故在做变量的线性组合(5)时,选择的系数就必须满足一定条件以使新变量两两之间均能呈现为线性无关。下述引理即已给出了主成分选择的方法。
引理1[6]当总体X=(X1,X2,…,Xp)T的协方差矩阵∑=(aij)p已知时,设协方差矩阵∑的特征值是λ1≥λ2≥…≥λp≥0,对应的单位正交特征向量为e1,e2,…,ep,则X的第k个主成分为:

结合以上引理,通过求解原来11个影响变量的协方差矩阵、协方差矩阵的特征值以及单位正交特征向量,就可以得到满足条件的主成分。此时再根据对应的主成分所包含的原来变量的信息,选取所需要的主成分。在主成分选取完成后,就可基于主成分变量进行多元线性回归模型的训练。回归模型训练结束后,对测试集数据实施预测[10-12]。
2 实验设计与结果分析
在这一部分,研究拟定将该模型与其它5组预测模型进行比较,并对该模型的优劣性质及表现展开分析。
2.1基于数据截断变换的主成分分析回归预测方法
该实验采用未变换的统计数据与经过数据截断变换(4)的数据进行主成分分析回归预测分析,并将结果进行比对以判定模型优劣。其中以3个学期的借书量为例,分布结果如图2所示。
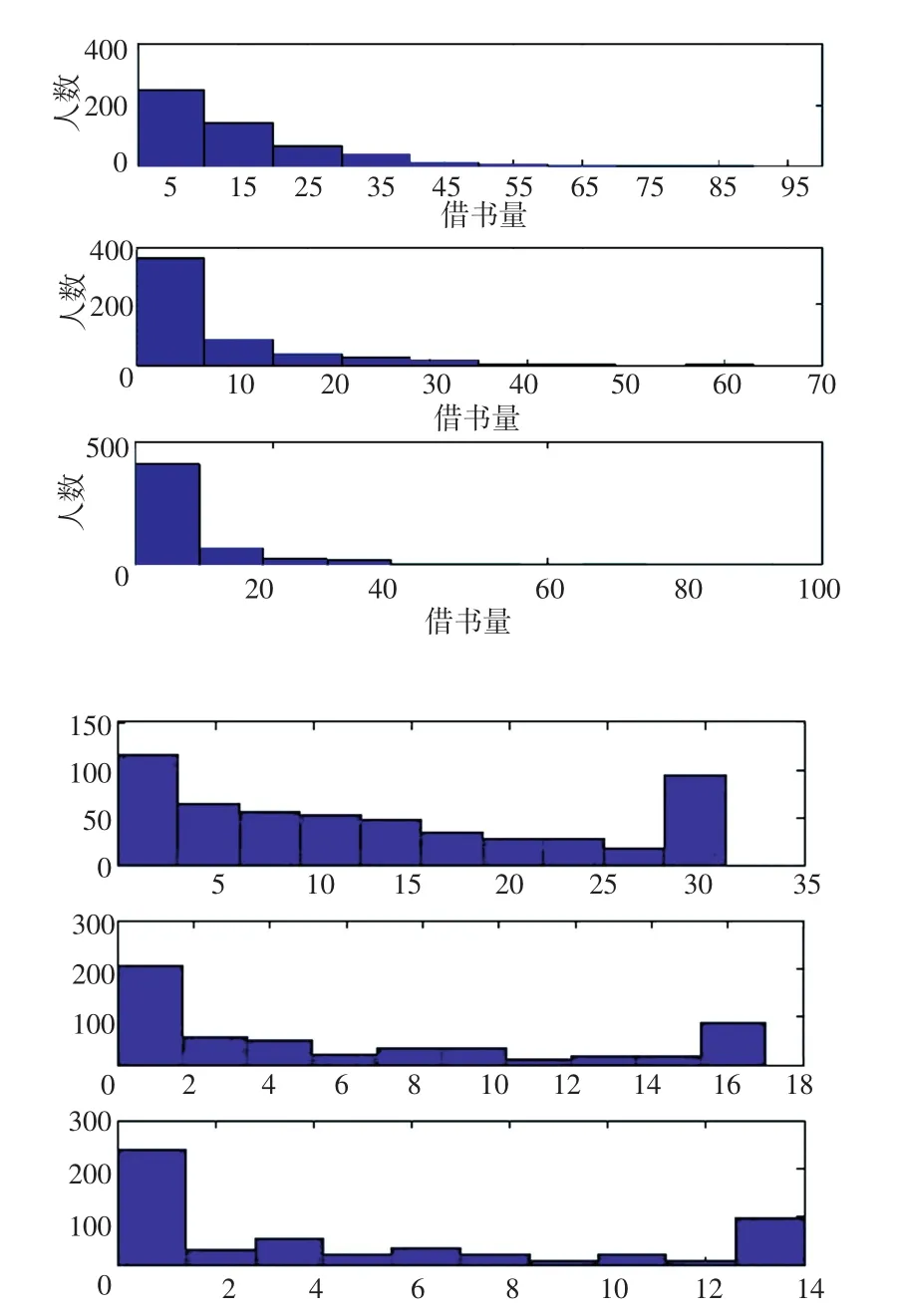
图2 未变换数据与变换后数据Fig.2 Untransformed data and transformed data
图2中上面3幅为3个学期的借书量与人数的分布图,而下方3幅为经过数据截断变换之后的借书量与人数的分布图。从图中可以看到经过数据变化之后两端的数据都变少了(大于上截断点的数据以及小于下截断点的数据均被缩小和放大了)。同时,研究中也对其余的几个统计变量进行同样的变换处理。利用处理过的数据(训练集和测试集)进行主成分分析回归预测方法的训练以及预测,得到结果如表1所示。
通过提交2组结果,对比预测准确率可以看出,经过数据截断变换的主成分分析回归预测方法比基于未变换数据的主成分分析回归预测方法的预测准确率要更显优越,由此证明了数据截断变换的有效性。

表1 主成分分析回归预测方法准确率对比Tab.1 Spearman accuracy of PCA
2.2不同预测方法的比较
为了验证本方法的有效性,本节将考虑其他参赛者使用的数据变换—拉依达变换,和预测模型—BP神经网络预测模型。
所谓拉依达法又称拉依达准则、3σ准则,是指对于一个变量x的一组样本数据x1,x2,…,xn,记其平均值为,标准差为σ,则对于这组数据中的点xi,如果满足:

即可判定点xi是误差粗大值的坏点,应将其剔除[13]。对于统计变量B1,B2,…,C3,可以采用拉依达法进行误差粗大值的剔除,去除数据中不好的那些点。同时在选取样本时,实际选取了所有这些学生,学生的各种统计变量的值都没有被剔除,也就是其各项指标都不是误差粗大值的坏点,研究中就将用拉依达法剔除坏点,并选取剔除之后的样本的过程叫做拉依达变换。
BP神经网络是一种误差反向传播的神经网络[14],通过梯度下降法使传递误差达到最小值,进而反向调整神经网络中链接的权值,使得模型得到的实际结果和真实结果误差达到最小。该模型是一种有监督的学习模型,具有现实鲜明的自组织和自适应能力,在很多领域中都有广泛的应用[15-17]。对于最简单的隐含层只有一层的BP神经网络,具体的网络拓扑结构可如图3所示。

图3 BP-神经网络拓扑图Fig.3 Topological graph of BP-neural network
对于经过拉依达变换的数据,对应的BP神经网络预测模型训练则如图4及图5所示。
图4为用经过拉依达变换的数据进行神经网络预测模型的效果预测时,误差和训练时间的关系图,可以看出误差逐渐趋向于一个恒定的值,在一定时间之后基本保持误差在极小值的一个最佳区间范围内,此时已达到训练的目的。图5为用经过拉依达变换的数据进行网络训练之后的拟合程度,从中能够看到网络输出值和真实值的拟合度已高达0.957 47。此时,网络中的各个参数已训练完毕。

图4 基于数据拉依达变换的神经网络训练过程Fig.4 Training process of BP-neural network based on Pau Ta transformation

图5 基于数据拉依达变换的神经网络训练拟合结果Fig.5 Fitting result of the BP-neural network based on Pau Ta transformation
此后,还进行了一系列组合对比试验,可得实验结果如表2所示。
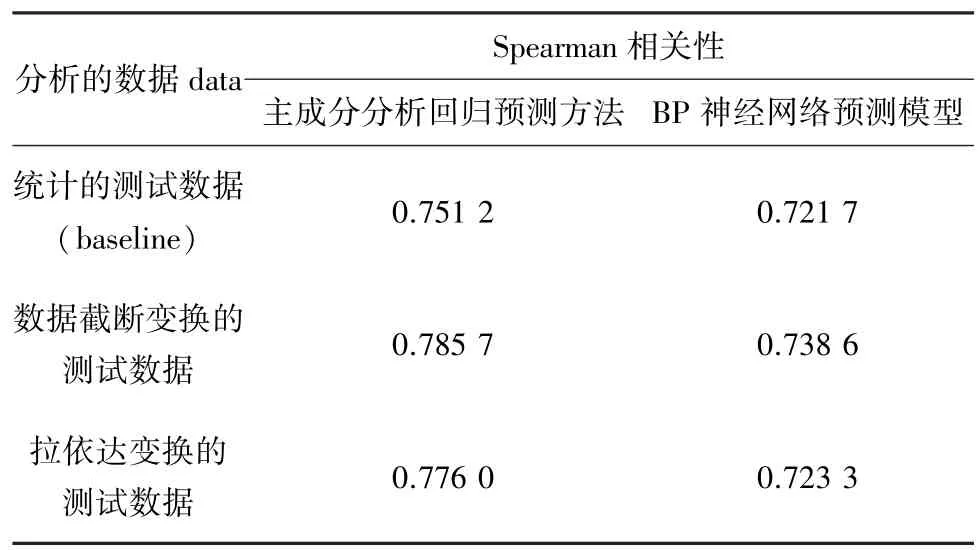
表2 各预测模型预测准确度Tab.2 Spearman accuracy of models
通过分析表2可以得出,基于数据截断变换的主成分分析回归预测方法具有最高的预测准确度。无论是基于哪类数据,主成分分析回归预测方法的结果比BP神经网络预测模型预测结果都要表现出更高的准确度;而基于数据截断变换的测试数据预测结果在准确度上则要明显超出基于统计的测试数据以及基于拉依达变换的测试数据的实验效果。
2.3结果分析
在第二部分方法概述里所介绍了主成分分析回归预测方法的构建,这也可以映射得出其具备的特点,将有关联的变量转化为独立的变量,在做回归分析的时候就能够训练出更精确的回归模型,最终结果中也证明了主成分分析的优异性。
对于BP神经网络的不佳表现,则是因BP神经网络的特性所致。对于训练集数据,拟合程度可以很高,这既是优点,也已成为缺点。过度拟合的模型对测试集的数据进行预测,将不会得到理想中的预测准确度。为了得到更好的准确度,就需要不断地调试与训练集相关联的目标模型,从而使得对于测试集预测结果能达到最优,这将会是一项费时费力的工作。
另外,分析基于拉依达变换的预测准确度要比基于数据截断变换的预测准确度略低这一结果事实可知,则是由于在涉及拉依达变换进行样本的剔除过程中,一些“重要”的数据点信息被删除了,而利用这些残缺的数据信息训练出来的模型将无法完整表达变量内部之间的联系,用测试集数据做预测时预测准确度就不会高。而经过数据截断变换的数据则因没有剔除掉这些异常样本,而只是在原有的数据基础上进行了一定的压缩,相比较拉依达变换而言,过程中保留了所有的原始样本,因而信息继承较为完好。
3 结束语
本文针对的问题是:预测学生未来成绩排名,结合现有的一些方法和手段提出了基于数据截断变换的主成分分析回归预测方法,并在实验部分对预测准确度进行了讨论,对比了其它5组预测方法,实验结果证明基于数据截断变换的主成分分析回归预测方法比其它5组方法的预测准确度要高。得到的模型可以对其它相关问题进行预测分析,同时下一步的工作即是需对数据处理和预测模型做进一步的改进,以提高预测准确率。
[1]凤英.现代气候统计诊断与预测技术[M].北京:气象出版社,1999.
[2]吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001,6(2008):4.
[3]李连弟,鲁凤珠,张思维,等.中国恶性肿瘤死亡率20年变化趋势和近期预测分析[J].中华肿瘤杂志,1997,19(1):3-9.
[4]孙秀娣,牧人,周有尚,等.中国胃癌死亡率20年变化情况分析及其发展趋势预测[J].中华肿瘤杂志,2004,26(1):4-9.
[5]杨玲,李连弟,陈育德.中国2000年及2005年恶性肿瘤发病死亡的估计与预测[J].中国卫生统计,2005,22(4):218-221.
[6]李柏年,吴礼斌.MATLAB数据分析方法[M].北京:机械工业出版社,2012.
[7]JOLLIFFE I.Principal component analysis[M].New York:John Wiley&Sons,Ltd,2002.
[8]WOLD S,ESBENSEN K,GELADI P.Principal component analysis[J]. Chemometrics and intelligent laboratory systems,1987,2(1):37-52.[9]ABDI H,WILLIAMS L J.Principal component analysis[J].Wiley Interdisciplinary Reviews:Computational Statistics,2010,2(4):433-459.
[10]AIKEN L S,WEST S G,PITTS S C.Multiple linear regression[J]. Handbook of Psychology,2003,4(19):481-507.
[11]KUTNER M H,NACHTSHEIM C,NETER J.Applied linear regression models[M].New York:McGraw-Hill/Irwin,2004.
[12]ANDREWS D F.A robust method for multiple linear regression[J]. Technometrics,1974,16(4):523-531.
[13]ZHANG L,QIN Y,ZHANG J.Study of polynomial curve fitting algorithm for outlier elimination[C]//Computer Science and Service System(CSSS)2011,International Conference on.Nanjing:IEEE,2011:760-762.
[14]MCCLELLAND J L,RUMEHART D E.Parallel Distributed Processing(Two Volumes)[M].Cambridge,Massachusetts:MIT press,1986.
[15]PATTERSONDW.Artificialneuralnetworks:theoryand applications[M].New Jersey:Prentice Hall PTR,1998.
[16]刘洪兰,张强,张俊国,等.BP神经网络模型在伏旱预测中的应用——以河西走廊为例[J].中国沙漠,2015(35):474-478.
[17]ZHANG G,PATUWO B E,HU M Y.Forecasting with artificial neural networks:The state of the art[J].International journal of forecasting,1998,14(1):35-62.
A new regression model of principal component analysis based on the data with truncated transformation
SU Jia,GUAN Yi
(School of Computer Science and Technology,Harbin Institute of Technology,Harbin 150001,China)
Combine with principal component analysis and multiple linear regression methods,a new regression model based on the data with truncated transformation is proposed in the prediction of students’future performance at school,one of the tracks of 2014 DataCastle.Experiments show that compared with other predict methods,the proposed model perform in an efficient way.The accuracy of the proposed model reaches highly as 78.57%,better than any others methods,and ranks in the top ten percent of the ranklist.This model not only has the availability in this area,but also can be used in other prediction researches.
truncated transformation;principal component analysis;multiple linear regression;predict
TP391
A
2095-2163(2016)03-0001-05
2015-12-13
苏 嘉(1991-),男,博士研究生,主要研究方向:医疗健康信息学、自然语言处理、机器学习;关 毅(1970-),男,博士,教授,博士生导师,主要研究方向:自然语言处理、医疗健康信息学、认知语言学等。
