文本蕴含问题简介
2016-10-28唐帅李青
唐帅,李青
(山东科技大学,山东 青岛 266000)
文本蕴含问题简介
唐帅,李青
(山东科技大学,山东 青岛 266000)
文本蕴含是自然语言处理中的一个重要概念。本文对文本蕴含问题本身以及其研究现状进行简单的介绍。
人工智能;自然语言处理;文本蕴含
1 文本蕴含
文本蕴含(Textual Entailment)是自然语言处理(Natural Language Processing)中的一个重要概念。它描述的是两个文本片段的有向性关系。当其中一个文本片段内容的真实性依赖于另外一个文本片段的真实性时,这种关系存在。文本蕴含没有纯逻辑蕴含(pure logical entailment)般的严谨性。非形式化地,如果一个阅读某文本片段的人类读者会推断另外一个文本片段中的内容极可能是真实的,那么这两个文本片段之间存在文本蕴含关系。可以记作:“t entails h” (t⟹h),其中t和h分别为蕴含和被蕴含的文本片段。文本蕴含关系是有向的。因为在t⟹h 成立的情况下,h⟹t 成立与否通常是不确定的。
文本蕴含在自然语言处理领域中的地位非常关键。因为它与自然语言的多样性(variability)(比如同一个语义可以对应多种不同的具体表达方式)紧密相关,而如何处理语言的多样性可谓自然语言研究领域中最大的难点。与此同时,有效处理自然语言的多样性问题是自然语言诸多重要应用领域中取得突破的基础。
2 RTE
人工智能与自然语言处理领域的研究者们越发意识到文本蕴含问题的重要性,RTE(Recognizing Textual Entailment)于2004年被作为一项一般性任务(generic task)被提出。自2004年到2013年,8界RTE挑战(RTE Challenges)成功举行,旨在为研究者们提供可以用来评估和比较他们的研究方法的具体数据集。历年来RTE的主要组织者包括巴伊兰大学(Bar-Ilan University),Fondazione Bruno Kessler 研究中心,美国国家标准与技术研究院(NIST),以及意大利的语言和通信技术评价中心(CELCT)。
3 解决文本蕴含问题的一个重要框架
在现阶段,语言多样化问题往往出现于一些实用性的系统中。而这些系统对语言多样化问题的处理通常是建立在比较“肤浅(shallow)”的语义层面。这是因为基于逻辑的含义层面(meaning-level)的表示是难以实现的。然而缺乏一种不限于具体应用的通用性框架,来对语言多样化进行建模。Ido Dagan等人在《PROBABILISTIC TEXTUAL ENTAILMENT: GENERIC APPLIED MODELING OF LANGUAGE VARIABILITY》一文中提出了一个肤浅语义层面的通用的语言多样化模型,并将其实现为一个可以投入到多种应用的实用性引擎。这个模型被广泛认可,并在很大程度上影响了人们对于文本蕴含问题的研究方法。
在文本蕴含的原始定义中,这种关系是确定性的。即t⟹h 要不成立,要么不成立。而在Ido Dagan等人提出的模型中采用了一种更加模糊的处理方法,给每一个文本蕴含实例分配一个概率,用以表示该文本蕴含关系成立的可能性。文章提出的重要概念如下:
样板(template):一个文本片段(language expression)以及与之对应的句法分析。其中的一些次结构可以用变量来替代。这些变量可以是根据句法结构分类的。(比如词类,词性,或者依赖性解析(dependency parsing)中的关系类型。)
蕴含式样(entailment pattern):一个蕴含式样包括由共享变量域的一个蕴含样板和一个被蕴涵样板组成的结构,以及式样相对应的概率(包括先验和后验)。例如:
X←subjbuyobj→Y⟹X←subjownobj→Y
推理机制:模型利用既有的蕴含式样库,通过不断对其运用概率推理逻辑的方式以获得更加庞大和复杂的文本之间的蕴含关系。推理模型中用到的核心推理规则如表1所示:
表1
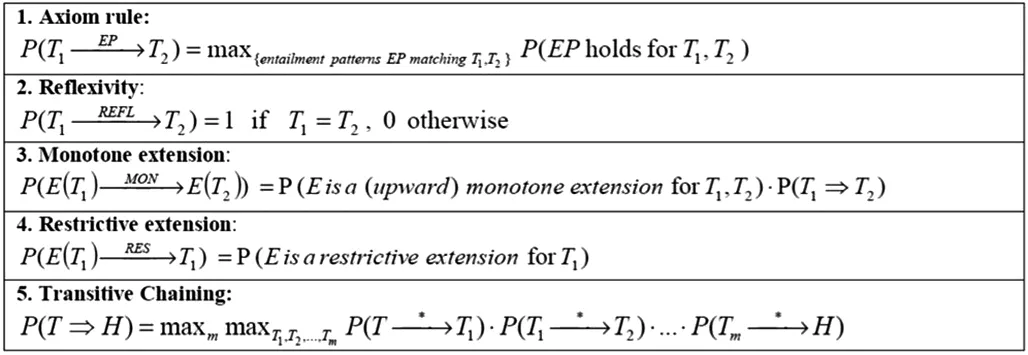
其中第一条规则计算所有匹配的蕴含式样中的最大概率。第三个第四条规则描述了两种在不影响蕴含关系的前提下,将前提和结论分别组成更复杂的文本的方法。
4 常见的方法举例
以下介绍一种比较有代表性的模型。
一种最简单和直接的处理方式是基于两个文本片段在词法层面上的相似度来评估二者之间的蕴含关系。通常利用两个文本片段中所含单词的重叠程度(word overlap)来建立二者的相似度计算方法。一种可能的计算方法如下:
首先提取文本h中的单词集合,以及其与文本t中单词集合的交集。然后用加权处理(比如采用TF-IDF进行加权)过后的交集比上加权后的h中单词的集合,以得到所考察的一对文本片段之间的单词重叠度,从而基于这个重叠度对二者之间的蕴含关系做出评估。
[1]Dagan,I.,and Glickman,O.Probabilistic textual entailment: generic applied modelingof language variability[C].Grenoble,France: PASCAL Workshop on Learning Methods for Text Understanding and Mining,2004.
[2]Marco,P.,and Fabio,Z.Learning Shallow Semantic Rules for Textual Entailment[C].Borovets,Bulgaria: Recent Advances in Natural Language Processing,2007.
[3]Yongmei,T.,and Junyu,Z.BUPTTeam Participation[C].TAC Recognizing Textual Entailment,2011.
唐帅(1987-),男,汉族,山东临沂人,山东科技大学在读硕士研究生,研究方向:人工智能、自然语言处理。
李青(1991-),女,汉族,山东济宁人,山东科技大学情报学在读硕士研究生,研究方向:信息系统工程、智能数据分析与处理。
TN929.53
A
1671-1602(2016)18-0251-01
