分布式环境下ETL系统的优化策略研究
2016-10-26陈盛荣刘广钟
陈盛荣,刘广钟
(上海海事大学信息工程学院计算机系,上海201306)
分布式环境下ETL系统的优化策略研究
陈盛荣,刘广钟
(上海海事大学信息工程学院计算机系,上海201306)
ETL是将数据由不同数据源抽取到数据仓库的重要过程,ETL的过程设计、维护和修改直接影响数据仓库中数据处理的效率和数据的质量。通过分析ETL活动的模型特点,结合分布式计算的思想提出一种新的ETL系统模型,并提出基于该系统架构的满足ETL任务形态特征的优化方案,详细描述数据以及调度信息在系统中的周转过程。
数据仓库;分布式系统;抽取转换加载(ETL)
0 引言
在基于数据仓库的离线数据分析任务中,ETL过程(抽取-转换-装载)表示在对异构的数据源进行清洗、转换等处理后,以一种统一的模式(包括存储结构层面和逻辑语义层面)集中存储于数据仓库。作为商业智能BI、机器学习等数据分析任务的基石,ETL需要兼顾可靠性和性能,才能保证高效地将高质量的数据按时汇总到数据平台。据统计,ETL占据了总任务成本60%以上,且由于数据源多来自于数据库等基于实时更新的数据平台。考虑到ETL任务的特性(大数据量、可并行性),可以引入分布式计算的思想,通过合理均衡地调度集群计算资源,减少空置提升并行,来缩小运行ETL任务的时间成本。
1 任务建模和系统架构
1.1ETL逻辑建模
ETL的任务满足“多源单目标”的形态特征。如图1所示,将ETL的整体流程建模为有向无环图G(V,E),描述了ETL过程中涉及的各种实体以及任务流程之间的关系。节点集V表示与数据加载/转换相关的各种活动或存储模式,边E描述各节点的数据传递/依赖关系。ETL过程的逻辑建模包括如下要素:
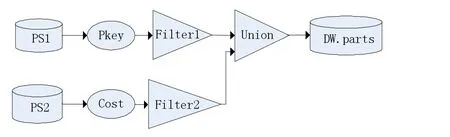
图1 ETL工作流图
记录集RS:由圆柱形表示,表示具有固定模式,并以结构化的方式存储于非易失性设备中的数据集。在ETL任务里作为数据源或目标集,表示源数据集或存储结果数据的数据仓库,例如表示关系型数据库的数据表或数据仓库中的维度表和事实表等。
属性:由椭圆表示。在ETL场景中,若只对数据集中的某几列元素感兴趣,可以使用椭圆表示从数据集中抽取需要的列数据,称为属性。
活动:由三角形表示,ETL过程包含了对数据的不同操作,如选择、连接、投影、排序、拆分、合并等,还包括空值检查、外键约束检查、键值转换、格式转换等。依据输入输出模式不同,将活动分为一元活动和二元活动。一元活动具有一个输入模式和一个输出模式,这种简单的线性结构通常表示某种转换活动,用以修改数据格式或执行某种函数操作。二元活动涉及两个输入模式和一个输出模式,这种活动需要对来自各个数据源的数据进行汇总及预处理,只有当所有依赖的数据源都输出完毕才进行后续的处理过程。诸如Join、Union等都属于这一类活动。二元活动具有阻塞式特征,即需要等待两个输入模式的数据都传达后才能执行该活动,容易成为阻碍ETL工作流的整体流程中的瓶颈节点,可以将此类活动视作整个工作流的边界节点,从而将整个工作流分割为多个互不存在依赖关系的子工作流,运用并行思想提升ETL过程的整体性能。
1.2分布式ETL系统架构
分布式系统能充分利用计算资源,将不同的任务分配到不同的计算节点,从而将的ETL任务逻辑转化为多个并行处理的数据流。如图2所示,本节提出一种基于分布式系统设计的ETL框架模型,包括如下模块:客户端模块、语义解析模块、元数据库、调度单元模块和计算集群。
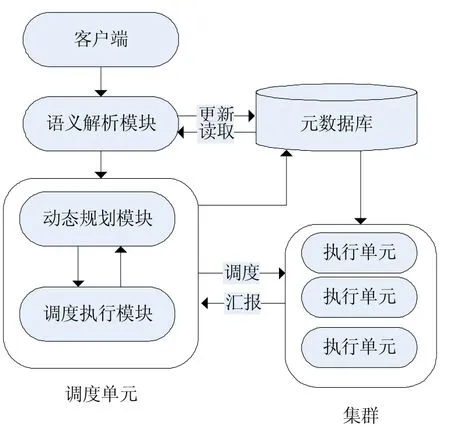
图2 基于分布式计算的ETL系统结构
客户端:接收来自用户的ETL任务。由于来自客户端的ETL需求可能遵循了不同的语义格式写成。客户端负责将ETL任务解析为满足统一格式的有向无环图结构的工作流图,由于客户端的ETL语义在执行逻辑上通常不是最优的,需要交由语义解析模块完成优化工作。
语义解析模块:对经由客户端格式化的ETL工作流图进行分析和优化,通过遍历图中的各节点,确定工作流中的活动属性,对工作流图进行转换,最后将优化后的工作流图送至调度单元执行。具体流程如下:①循环遍历工作流图的各节点。对入度为0的节点(数据源),确定数据源的数据量,将相关信息记录到元数据库中;对于出度为0的节点(目标数据集),记录相关的元数据到元数据库;对于出度和入度都大于0的节点(活动节点),判断其活动类型,对于用作分割工作流的二元活动节点,记录该活动的属性及所处位置。②遍历节点后,对工作流中的节点进行对调转换等优化操作,旨在减少活动节点间的数据交换。③将经过优化的工作流以二元活动为界分割为多个子工作流,将子工作流中的多个一元活动归为一组传送至调度单元准备执行,并标明组别,为调度单元动态优化工作流程提供参考。
调度单元:细分为动态规划模块和调度执行模块。在分布式环境下,因为集群节点的计算性能存在差异,可以将数据进行分割从而充分利用现有资源发挥并行计算的性能优势。动态规划模块按照划分规则水平地将数据分割为多个数据流。调度执行模块则将对应的ETL活动打包分配至各执行单元执行。调度单元接收来自执行单元的执行信息以实时跟进ETL活动节点的执行进度。动态规划模块与调度执行模块协调执行,前者对来自执行单元的执行信息进行汇总分析,从而得到最优化的数据分割策略;后者依据得到的实时最优化结果,将任务分配到执行单元。
元数据库:元数据是记录数据的数据,维护数据模式的完整性和正确性。系统执行流程中涉及的各模块都会与之发生交互。
执行单元:ETL任务的执行体,在分布式计算环境中执行经由调度单元分配的计算作业包。由于网络带宽的性能相对薄弱,执行模块通常将ETL中间结果缓存于本地。只有在需要汇集多个节点的输出数据时才动用网络带宽资源进行数据传输。
2 优化策略
2.1基于语义逻辑的优化策略
基于语义逻辑的优化在语义解析阶段完成,当遍历ETL工作流的所有转换活动节点后,语义解析模块会根据不同活动节点的属性,运用交换活动执行顺序、合并语义重复的活动等策略在不改变ETL工作流的执行结果的前提下修改ETL工作流程。经过优化的工作流减少了数据在不同节点间的周转量,从而减轻了单机/集群的I/O负载。例如对基于SQL脚本描述的ETL任务,ETL执行框架可以运用多种基于关系型数据库的优化策略。此外,这种优化策略是基于语义的静态优化,是从理论上减少工作流的数据量,而不会与下文数据动态分割的优化方式产生冲突。
2.2基于分组的优化策略
ETL工作流存在不同类型的活动节点,其中存在依赖允许并行的一元活动,定义为:
将数据源T水平分成T1和T2,则T=T1∪T2,将ETL过程的每一个活动Acti(1≤i≤m)看作对T的函数映射,那么如果Actm(Actm-1(…(Act1(T))))={F1,D1,D2,…,Dp},则应满足Actm(Actm-1(…(Act1(T1))))∪Actm(Actm-1(…(Act1(T2))))={F1,D1,D2,…,Dp}。即设M是对T的关系操作,须满足M(T)=M(T1)∪M(T2)。
如图3所示,若工作流中存在此类活动的串行序列,可以合并为一组。这样做的好处在于:①简化ETL活动的逻辑结构。②减少调度单元向执行单元分发计算任务的频率,执行单元在完成前一个转换任务后可以直接进入到下一个转换任务的执行过程中,不需要向调度单元再次申请计算任务,避免了申请任务产生的等待延时,保证了任务执行的连续性。③由于每个分组都是由可并行的一元活动组成,可以通过分割数据的方式将活动组分配到不同的执行单元异步执行,各执行单元的计算结果互不干扰,从而形成流水线的效果以提升ETL的性能。
以图3所述的活动组为例,由此会得到分组前后的工作流视图,前者从一个较细的粒度描述了工作流的任务逻辑,后者以粗粒度描述了工作流在分布式集群中的任务分配情况。
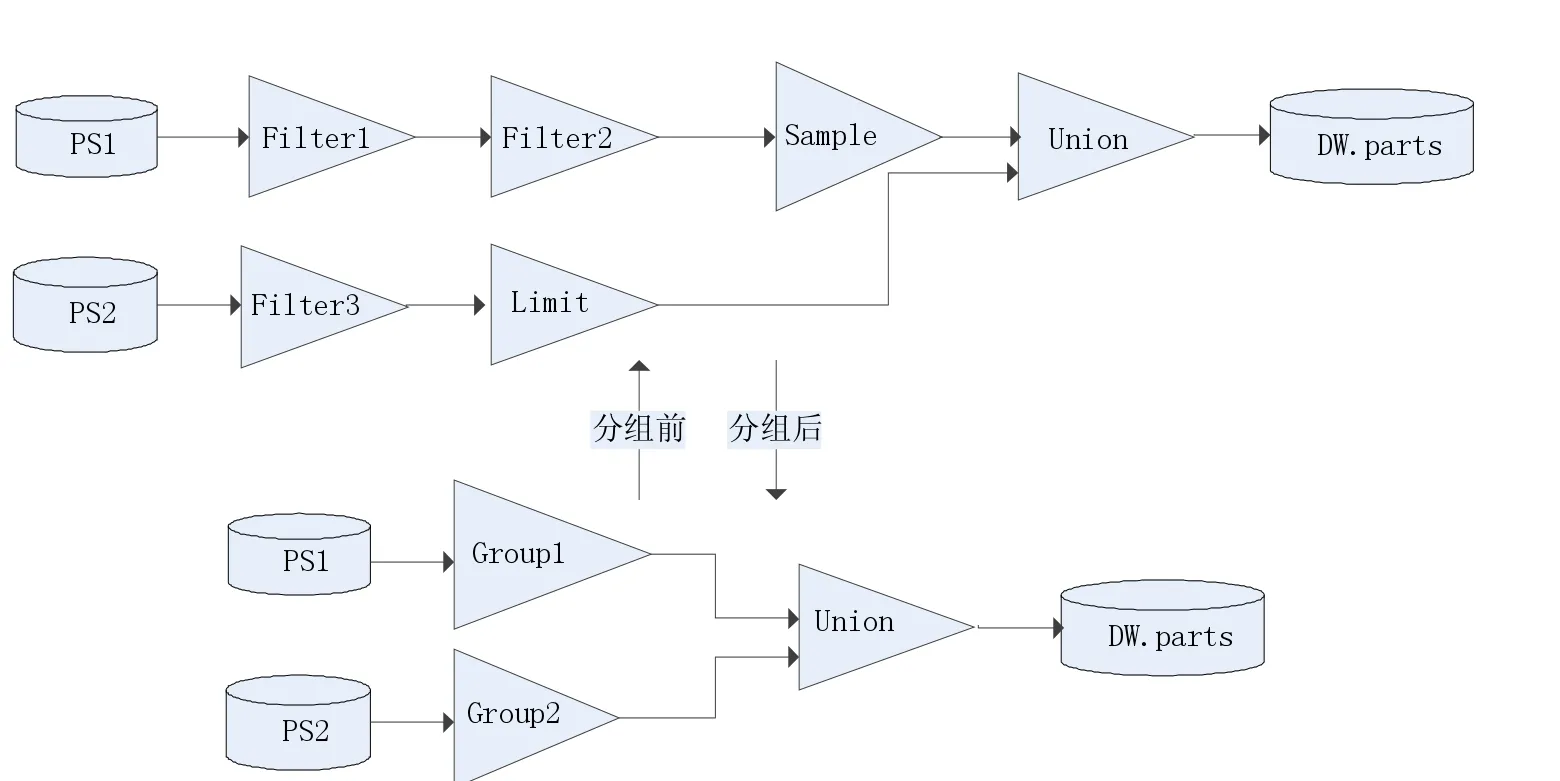
图3 分组前/后的工作流图
2.3基于动态数据分割的调度策略
对于并行执行的ETL工作流,可能存在数据分配与集群资源不匹配的情况。例如,如果为计算能力偏弱的节点分配了过重的数据量,可能出现部分高性能节点在完成计算任务后为了等待其余节点完成任务而产生闲置。此外,在大型集群式生产环境中,新节点的加入和节点发生故障的情况十分常见。事先分割数据的调度方案无法很好地应对这些场景。本节提出一种能适应上述异构集群环境的动态分割数据的ETL调度策略。
动态指的是数据分割发生在系统开始执行运算任务后,而非执行之前的调度阶段,分割的数据对象是针对执行时的低效处理机进行的,是否进行数据分割、分割的数据量大小依据当前系统运行进度计算得出。当集群中出现空闲节点时或处理机开始执行某个新的一元活动任务时,将发生数据分割。
该策略的执行流程如下:首先访问集群中正在执行运算任务的执行单元,选择其中完成时间最晚的活动作为分割数据的对象;之后访问集群中所有空闲的执行单元,判断是否满足执行条件,所谓的执行条件是指该处理机空闲的时间窗口大于被分割数据跨机传输时间及运算时间之和,否则数据分割是没有意义的,反而会增加工作流的总执行时间,将符合条件的执行单元记录下来;最后,系统计算发生数据分割的数据量,使这些数据在空闲的执行单元上完成传输和计算的时间跨度最短。
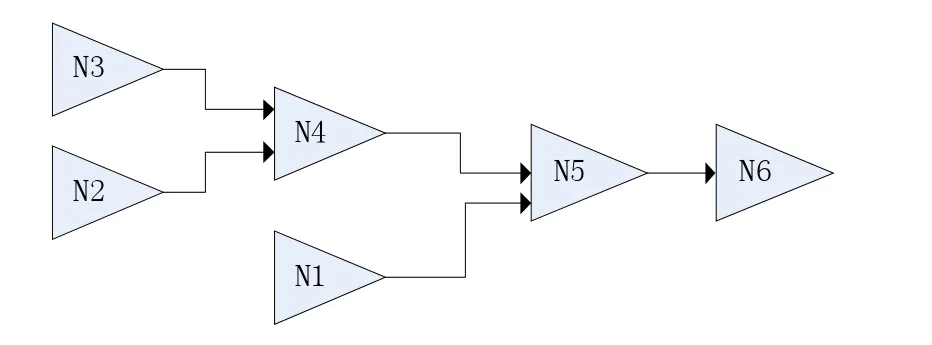
图4 ETL工作流图
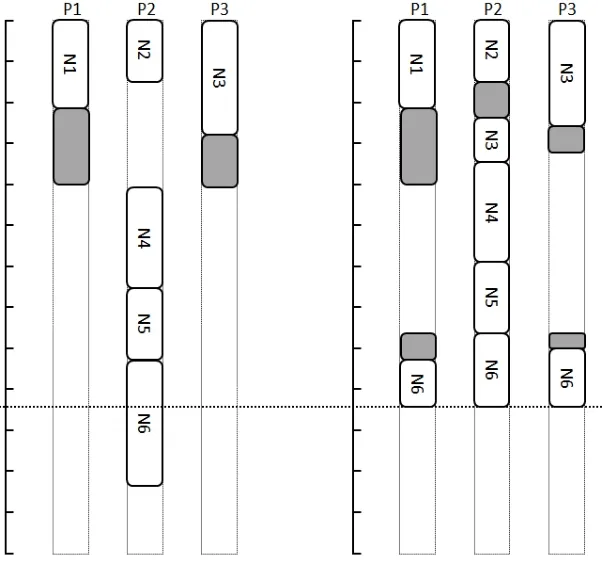
图5 应用动态数据分割策略前后的集群并行情况对比
当集群中出现空闲的执行单元或是有一元活动被调度时,系统会激活数据分割算法。二元活动本身存在特殊性,只能在某个执行单元以单机方式完成相关运算任务,不适合数据分割执行。
假设在三台单机组建的集群上执行图4所示ETL任务。由图5可以看到,P3的性能相对薄弱,当P2完成任务N2进入闲置状态后,系统将N3部分数据分割并传递至P2执行,灰色部分表示数据发生跨执行单元传输。类似的情况也发生在N6启动时,系统将数据分割并分配至P1和P3。由于集群资源被更合理地使用,ETL活动的总执行时间得以明显缩短。
3 结语
本文提出了基于分布式系统的ETL活动优化策略,能很好地适应目前被广泛应用的分布式计算框架。在保证计算准确率的同时,合理迅速地调度集群资源,保证各计算单元的负载平衡,提升执行复杂ETL任务的综合性能。
[1]徐俊刚,裴莹.数据ETL研究综述[J].计算机科学,2011,38(4):15-20.
[2]许力,牟晓光,马云存.并行ETL过程的研究与实现[J].计算机工程与应用,2009,45(13):170-172.
[3]尤玉林,张宪民.一种可靠的数据仓库中ETL策略和架构设计[J].计算机工程与应用,2005,41(10):172-175,229.
[4]Simitsis A,Vassiliadis P,Sellis T.Optimizing ETL Processes in Data Warehouses:Proceedings of 21st International Conference on Data Engineering(ICDE),2005[C].Tokyo,Japan,2005:564-575.
[5]Vassiliadis P,Simitsis A,Terrovitis M.A Framework for the Design ETL Scenarios:Proceedings of the 15th Conference on Advanced Information Systems Engineering(CAISE'2003),2003[C].Klagenfurt,Austria,2003:520-535.
[6]Vassiliadis P,Vagena Z,Skiadopoulos S,et al.Towards the Modeling,Design,Control and Execution of ETL Processes[J].Information Systems,2001,26(8):537-561.
[7]Vassiliadis P,Simitsis A,Skiadopoulos S.Conceptual Modeling for ETL Processes:Proceeding of the 5th ACM International Workshop on Data Warehousing and OLAP,2002[C],2002:14-21.
CHEN Sheng-rong,LIU Guang-zhong
(College of Information and Engineering,Shanghai Maritime University,Shanghai 201306)
ETL is an important process of extracting data from different data sources to Data Warehouse.Its process design,maintenance and modification directly affect the efficiency of data processing and data quality in the data warehouse.Combined with the concept of distributed computing,presents a new ETL System model,and furthermore puts forward an optimizing method that is based on the system architecture and satisfies the topological characteristics of ETL tasks,describes the data flow and scheduling process of the system in details.
Data Warehouse;Distributed System;Extract-Transform-Load(ETL)
1007-1423(2016)23-0039-05DOI:10.3969/j.issn.1007-1423.2016.23.010
陈盛荣(1992-),男,上海人,上海海事大学研究生,研究方向为计算机网络开发
2016-05-17
2016-08-10Research on ETL Scheduling Model in Distributed System
