基于SVM主题爬虫的航天情报采集应用研究
2016-10-22郭颂边伟刘洋胡钛
郭颂,边伟,刘洋,胡钛
(1.中国科学院国家空间科学中心北京100190;2.中国科学院大学北京100149)
基于SVM主题爬虫的航天情报采集应用研究
郭颂1,2,边伟1,刘洋1,2,胡钛1
(1.中国科学院国家空间科学中心北京100190;2.中国科学院大学北京100149)
为了准确高效采集航天领域内的竞争情报,提出了基于SVM的主题爬虫采集方法。设计了航天领域情报采集总体框架,采用支持向量机分类算法,利用适量已有航天情报信息,强化特定领域特征权重,训练航天领域主题分类模型,使用该模型对网页信息进行主题判定后获取航天领域情报信息。实验表明,该方法能够有效且高效地采集航天领域内的竞争情报。
支持向量机;主题爬虫;分类模型;航天情报采集
在技术知识密集型的航天领域内,从业企业及科研机构在自身发展的同时,对行业科技情报有着强烈的需求,并且需求数量大、专业性强、新颖及时、完整准确。互联网作为一个巨大的信息库,富含可挖掘的潜在航天领域情报信息,但网络信息资源庞杂、异构多变,特定信息获取困难[1],传统方法收集竞争情报不能高效满足实际的需求。在这种背景下,引入主题爬虫技术,应用基于支持向量机(Support Vector Machine,SVM)的主题分类策略,对航天领域情报采集进行应用研究。
主题爬虫(Focused Crawler),按照一定策略,配合行业专有词汇、特定需求建立主题模型,自动抓取网页信息,常用于针对行业竞争情报的采集。主题爬虫最早由Chakrabarti[2]等人提出,随着主题爬虫技术的研究发展,目前已成为面向领域的开源信息分析和垂直搜索引擎信息采集的核心技术[3]。主题爬虫的核心部分主要包含爬行策略和主题相关度过滤算法:爬行策略决定URL的爬行顺序,高效采集页面信息,主要分为基于内容评价和基于链接关系等相关技术,不在本文研究范围内;主题相关度过滤算法判定页面内容是否为所需主题相关,主要包含基于关键词匹配、基于知识本体、基于主题模型和基于分类器等技术,作用于锚文本或者网页内容进行主题相关度判定,其中基于SVM分类器的算法由于效果优良、易于实现等特点,被广泛采用。Johnson等[4]最早在理论上探索用SVM算法监督指导主题爬虫,并进行了相关实验;祝宇等[5]将通过SVM分类器对爬行的网页进行打分,用于指导主题爬虫采集化学相关主题网页;吴世杰[6]设计了基于支持向量机分类算法的主题爬虫系统Percaspider,取得了不错的效果。
近年来,才开始有了极少数针对航天领域情报采集的Web挖掘技术的应用研究。北京航天长征科技信息研究所的曹志杰[1]分析了航天领域互联网信息获取需求,论证了将基于主题的Web挖掘技术应用于航天情报跟踪的可行性,初步设计了跟踪系统模块,但并没有在具体系统模块譬如爬行策略或者页面主题相关性判定方面进行深入研究。
文中将设计航天领域情报采集总体流程框架,着重引入SVM算法构建主题分类模型。
1 航天领域情报采集总体框架
根据航天领域的情报采集需求,本文设计的主题爬虫采集模型框架如图1所示:

图1 情报采集模型框架
主题爬虫采集模型主要流程如下:
1)选择航天领域内相关门户网站专题页面以及企业和科研机构的网站页面作为初始URL种子,添加到URL库中。
2)URL管理器通过一定策略向爬虫采集器提供URL,具体策略有很多种,本文采用一种基于Best-First Search的优先级队列方式。
3)爬虫采集模块获取URL后,根据HTTP等网络协议解析对应网页,并下载HTML页面。
4)对下载的每个HTML页面内容进行抽取,提取出里面的URL添加到URL库中,以便后续持续不断获取新页面;过滤杂乱信息,识别并提取HTML页面中文章的实际正文内容。
5)利用训练好的SVM分类模型对正文内容进行主题分类预测,判定该网页所含内容是否是航天领域相关的情报信息,若是则将内容和对应URL添加到情报库中。该模型的构建在下一节进行详细介绍。
2 基于SVM的爬虫主题分类模型
航天情报主题爬虫的核心之一在于能否准确地判断网页是否为航天领域主题相关的,本文采用基于分类器的主题相关度评估策略,将网页主题判定问题转换为一个二类分类问题,即航天领域情报和其他信息。
分类算法有很多种,文中采用的是基于SVM算法的文本分类来构建爬虫主题分类模型,通过SVM算法对网页正文文本内容进行建模,不涉及网页链接和图片、音频、视频等多媒体信息。
最早由Vapnik[7]提出的支持向量机,基于小样本学习、结构风险最小化等统计学习理论,被公认为是性能优良、推广性能好的分类算法之一,是当下流行的一种典型的有监督的机器学习算法。
2.1SVM分类流程框架
基于SVM算法训练主题分类模型并进行网页文本分类预测的总体流程框架如图2所示。
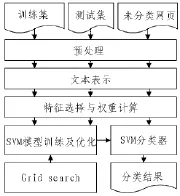
图2SVM文本分类流程
2.2文本预处理
首先,对已收集的航天情报文本信息集合和其他非航天领域内的文本信息集合进行类别标注,将打乱顺序后的语料样本集合按照适当比例分成训练集和测试集,用于后面的SVM分类器的训练和调优。
然后,引入ICTCLAS对所有文本进行中文分词,使得文本从字序列集合转换为词语序列集合,进而为后续的处理提供基础。考虑领域文档的特点,根据航天实际工程项目、科学研究中涉及的领域,加上相对丰富的专业领域用户词库,使得分词效果大幅提升,也为后续其他处理提供了保障。
分词完成后,对文本进行清洗数据、去除噪声,适当删除文本中出现的不包含有用信息的停用词和特殊字符、标点符号等,以提高计算效率和分类效果。
2.3文本表示与特征选择
文中采用当前文本分类领域最常采用的文本表示模型,即向量空间模型(Vector Space Model),用于将非结构化的文本转化成SVM算法所能识别和处理的形式。
构建向量空间模型主要有以下几步:
1)首先需要进行特征选择,本文选择将语料训练集Ω分词和去噪后出现的所有词条,构建特征集{t1,t2,…,tn},n表示训练集中出现的特征数量。
2)对每篇文档xi(1≤i≤N)出现的每个特征tj(1≤j≤n)进行权重评估,评估方法有很多种,譬如信息熵、互信息、信息增益、tfidf等,本文权重计算方法采用简便高效的TFIDF[8]方法:
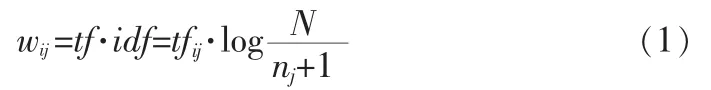
其中,tfij表示特征词条tj在文档xi中出现的频率;idf表示该词条tj的反转频率,N是训练集文档总数目,表示训练集合Ω中包含词条tj的文档数量。
在这个阶段,对出现在航天领域专业词库Φ里的特征词条tj,加大其权重,此处我们选择原权重值加上一个常数,权重修正为:

3)用特征集构建一个n维的向量空间,包含N个向量,每篇文档xi(1≤i≤N)被表示成为Rn中一个n维向量xi=(wi1,wi2,…,win)。
2.4分类模型训练与优化
SVM的思想是寻找最优的超平面,将两类样本正确的分开同时,尽量使分类间隔最大。分类间隔是指两类中离分类超平面最近的样本且平行于分类超平面的两个超平面间的距离。
对标注后的训练样本集:
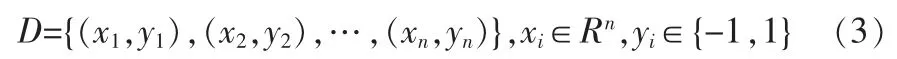
在线性可分条件下存在一个超平面


通过拉格朗日二次规划求解最优超平面相关参数,参数优化过程此处不再详解,最终得分类模型:

其中k()为核函数,用于将低维向量映射到高维,解决使线性不可分问题,ω*、b*为最优解,a*i为拉格朗日乘子。核函数根据不同情况由很多种选择,如径向基、多项式、线性核函数等等,由于我们并没有对特征进行降维,为加快训练速度,我们直接使用内积形式的线性核函数:

以标注后的向量空间模型D为输入训练SVM模型,并通过Grid search进行并行训练,优化相关参数,训练出最佳主题分类器,将分类器模型序列化为文件的形式保存,以便爬虫调用分类模型时直接读取模型文件。
2.5网页主题预测
对抓取到的网页进行主题预测时,将未分类的网页进行正文抽取后,按与训练集相同的方式进行预处理并映射到同样的特征向量空间模型中,通过训练好的SVM分类器进行分类,得到主题判定结果。
3 实验
开发环境:CPU Intel Core i3 2.13GHz,内存6G,Windows 7 64 bit,语言Python。
我们选取中国航天科技集团公司(http://www.spacechina.com/)、中国航天科技信息网(http://www.space.cetin.net.cn/)、中国网航天报道(http://news.china.com.cn/space/node_7152433.htm)、人民网航天瞭望站(http://scitech.people.com.cn/space/)等富含航天领域各类信息的企业网站、门户专题页等作为种子URL,以航天各型号工程项目为主题训练主题分类模型,并与基于朴素贝叶斯和纯关键词匹配进行网页主题过滤的方法,进行情报收集对比实验。
SVM主题分类模型训练时,选取预先手工收集的航天型号工程项目语料500篇,其他文档500篇,共1000篇文档,各随机抽取150篇共300篇作为测试集,其余为训练集。
对于主题分类模型算法的评估主要考察算法的查准率precision和召回率recall以及F1-Score三个指标。查准率是指正确分类到该类文档的数量与所有划分到该类的文档数量之比;查全率是指正确分类到某类文档的数量与该类所有文档的数量之比;F1-Score是Precision和Recall加权调和平均。

文中采用的SVM与朴素贝叶斯方法和关键词匹配方法进行了分类对比测试,由表1结果可见,两种机器学习分类模型F1-score均可达到90%以上,说明其对航天语料信息的辨别效果明显,而基于关键词匹配的分类方法效果较差。其中本文使用的SVM算法将航天情报从文本集中判定出来的准确率达98%,F1-score达97.6%,归因于本文对航天领域特征的强调,使得其配合SVM算法对航天领域文本有很好的区分度,因此该方法可以很好地对页面的主题相关性进行分类预测。

表1 分类模型测试结果
主题爬虫的评价指标用收获率来衡量,收获率是指与主题相关的已爬取网页数量与已爬取的网页总数之比,收获率越高,主题爬虫的情报主题过滤性能越好。
收获率对比结果如图3所示,可以看出基于SVM的主题判定方法能够一直保持较高的收获率,确保所采集的信息是航天领域相关的,干扰信息少;而随着爬取数量的增多,获取率开始降低,原因是所采用的训练模型基于小量样本,特征集合无法全面覆盖网上新增的航天领域特征词汇,使得模型分类效果下降。基于朴素贝叶斯的方法逊于SVM,而基于关键词匹配的方法主题判定效果本身很差,且随着爬取页面数量的增加收获率更低,使得非航天主题信息增多,不能满足航天情报获取的需求。

图3 主题爬虫网页收获率结果
爬取速度也是评价爬虫的一个指标,用于验证爬虫获取信息的高效性。实验结果如图4所示,可见基于SVM的主题爬虫要慢于基于朴素贝叶斯和关键词匹配的主题爬虫,原因是SVM每次要对网页正文进行分词、去噪并映射到向量空间模型等预处理,消耗了一定时间,但相对传统方法筛选信息的方式仍然比较高效。

图4 主题爬虫爬取速度结果
4 结论
文中采用支持向量机分类算法,通过强化航天领域特征权重,训练适用于航天领域的主题分类模型,通过所设计的爬虫总体框架,将基于SVM的主题爬虫应用于航天领域情报采集中,利用SVM主题分类模型对网页信息进行主题判定后,能较准确地获取航天领域情报信息。经过实验,主题分类模型能够达到很好的主题判定效果,爬虫总体框架能够有效且高效地采集航天领域内的竞争情报信息。
[1]曹志杰.基于主题的Web挖掘技术在航天情报跟踪中的应用研究[J].情报科学,2009(5):774-777.
[2]CHAKRABARTI S,VAN DEN BERG M,DOM B.Focused crawling:a new approach to topic-specific Web resource discovery[J].Computer Networks,1999,31(11):1623-40.
[3]田雪筠.网络竞争情报主题采集技术研究[J].图书与情报,2014(5):132-137.
[4]JOHNSON J,TSIOUTSIOULIKLIS K,GILES C L.Evolving strategies for focused web crawling[C].proceedings of the ICML,F,2003.
[5]祝宇,夏诏杰,聂峰光,et al.支持向量机在化学主题爬虫中的应用[J].计算机与应用化学,2006(4):329-332.
[6]吴世杰.基于支持向量机分类算法的主题爬虫的研究与实现[D].武汉:华中师范大学,2009.
[7]VapnikV N,VapnikV.Statistical learning theory[M].Wiley New York,1998.
[8]Salton G,Buckley C.Term-weighting approaches in automatictextretrieval[J].Informationprocessing& management,1988,24(5):513-523.
Research on the application of SVM-based focused crawler for space intelligence collection
GUO Song1,2,BIAN Wei1,LIU Yang1,2,HU Tai1
(1.National Space Science Center,Chinese Academy of Sciences,Beijing 100190,China;2.University of Chinese Academy of Sciences,Beijing 100149,China)
In order to collect the competitive intelligence,the intelligence collection method of SVM-based focused crawler is proposed.A general framework of space intelligence collection is designed.And a topic classification model of space field is trained by adopting the support vector machine classification method,using some existing aerospace intelligence and strengthening the weights of specific field features.The topic classification model is used to predict whether the topic of web contents are the space intelligences.The experiment shows that this method is of good efficiency and validity for space intelligence collection.
support vector machine;focused crawler;classification model;space intelligence collection
TN91
A
1674-6236(2016)17-0028-03
2015-09-15稿件编号:201509098
郭颂(1991—),男,山东青岛人,硕士研究生。研究方向:文本挖掘。
