加权LDA模型与SVM在垃圾邮件过滤中的应用
2016-10-22张帆
张帆
(四川大学计算机学院,成都 610000)
加权LDA模型与SVM在垃圾邮件过滤中的应用
张帆
(四川大学计算机学院,成都610000)
基于机器学习的垃圾邮件过滤方法相较于传统方法有更好的效果。文本表示方法的好坏会对分类算法产生影响。加权LDA模型在传统LDA模型的基础上引入词权重机制,通过这种方法获得的文本表示联合SVM分类器对邮件进行过滤,获得较好的分类效果。通过对比实验也验证这种方法的正确性和可靠性。
垃圾邮件;LDA;词权重
0 引言
从互联网诞生至今,垃圾邮件就一直是人们致力解决的问题之一。从个人角度来看,垃圾邮件或者包含大量含有商业性质的信息或者携带了对用户有害的病毒,而从整个邮件系统来看,垃圾邮件不仅占用了带宽还加重了邮件系统的负载。垃圾邮件过滤的方法是现在多数邮件系统通常使用的垃圾邮件过滤方法。基于机器学习的算法相比较于基于启发式规则和黑名单/白名单方法过滤时表现出了更好的效果[1]。
文本表示的方法在机器学习算法的分类器中会对分类效果造成影响。由于使用传统的向量空间模型(Vector Space Model)的文本表示会包含数以万计的特征,当数据量较大时,分类效果并没有达到工业应用的要求[2]。因此,使用特征选择技术降低数据的维数是非常重要的一个步骤。
使用LDA(Latent Dirichlet Allocation)模型选择特征,降低了数据的维数,再结合分类器可以取得较为满意的分类结果[3]。考虑到词的权重对于LDA模型中主题的影响,在LDA模型中引入了特征加权机制[4]。这种方法改善了LDA模型,在文本分析等相关领域已经得到了初步应用。支持向量机是一种被大家熟知的较为成熟的分类技术[5]。支持向量机的分类效果会因为数据表示方法的不同和核函数选择的不同而变化。支持向量机这种分类方法在垃圾邮件过滤领域已经得到了应用。
本文将结合词权重LDA模型与SVM,提出一种垃圾邮件过滤方法。
1 背景及相关工作
1.1LDA模型
LDA模型是在PLSA模型上加上了一层贝叶斯框架而形成的一种三层贝叶斯模型[3],由Blei等在在2003年提出[3]。
LDA模型中有两个假设,首先是文档集中的所有文档是相互独立可以交换的,其次是文档集中的所有单词也都是相互独立可以交换的,因此LDA模型也是一种词袋模型(bag of words)。LDA模型将整个文档集视为“文档”、“主题”和“词”三层结构。文档集中的每篇文档都拥有特定数量的主题,主题的组合比例由Dirichlet分布生成。而隐含的主题定义为一个在整个单词表的词的离散分布。因此三层结构中就包含了“文档-主题”和“主题-词”这两个分布。在这其中涉及到了贝叶斯、狄利克雷分布等知识。
LDA概率图模型如图1所示。
在图1中,K是每篇文档中主题的数目,M是整个数据集中文档的数量,Nm是文档集中第m篇文档中词的数目。α是“文档-主题”分布的Dirichlet先验参数,Zm,n是第m篇文档中第n个单词所属的主题,Wm,n是第m篇文档中的第n个单词,θm表示的是第m篇文档的主题概率分布,它是一个K维的向量,而φk是第K个话题的词分布,是个V维向量(V是整个单词表的词的数目)。
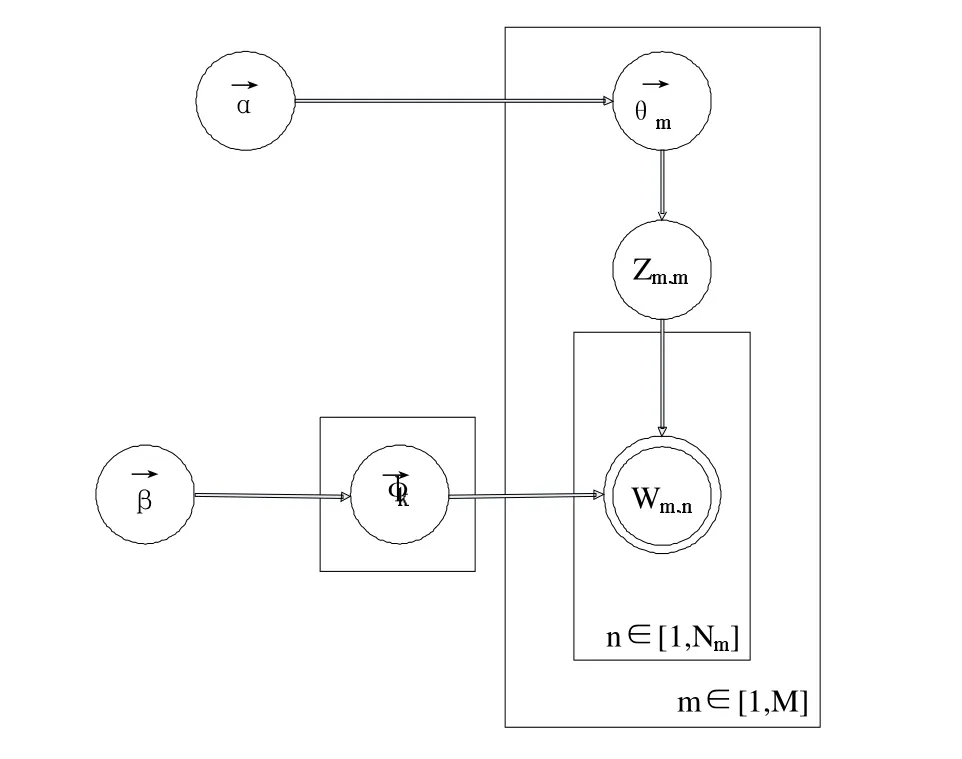
图1 LDA 主题模型图
对于一个文档集来说,Wm,n是可以直接观测到的已知变量,α和β则是给定的先验值,θm和φk是模型中未知的隐含变量,也是最终需要估计的变量。
LDA模型生成每个文本dm的过程就可以表示成:
(1)从整个文档库中选择一个文档dm,从参数为α的Dirichlet分布中得到该文档的主题概率分布θm;
(2)从参数为β的Dirichlet分布中得到多项分布φz,作为话题Z在词上的分布;
(3)对于文本dm中的第i个单词wd,I:
①根据多项分布Zd,i~Mult(θm),得到主题Zd,i。
②根据多项分布Wd,i~Mult(φz)得到词Wd,i。
LDA模型中的两个重要参数θ和φ需要通过估计来获得其值。在当前LDA模型中通常使用Gibbs采样来估计这两个参数的值[7]。Gibbs采样通过构造符合马尔可夫链的细致平稳条件的转移矩阵的方法,来使在采样过程中获得的”文档-主题”,”主题-词”分布最终收敛。经过计算后验概率得到的Gibbs采样的计算公式为:
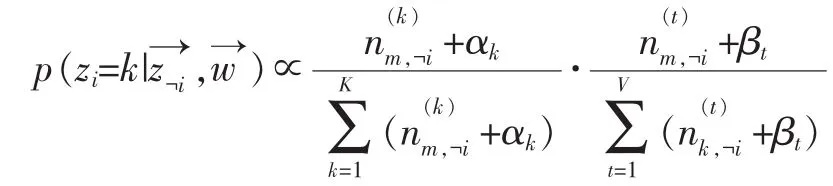
公式1的右边其实就是p(word|topic)和p(topic| doc),即θ和φ,所以θ和φ可以通过采样公式计算出来。θ和φ的计算公式可以表示为:
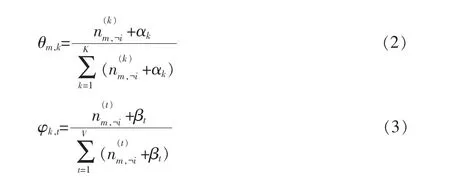
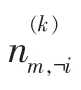
1.2支持向量机
支持向量机的主要解决的是二分类问题,它有着坚实的统计学理论基础[8]。支持向量机的主要思想就是在样本集中找到一个最优的分割平面来使得两类样本的分类间隔最大,通过这种方式可以使分类错误率降低,因此支持向量机相对于分类方法来说有着较高的分类准确率。
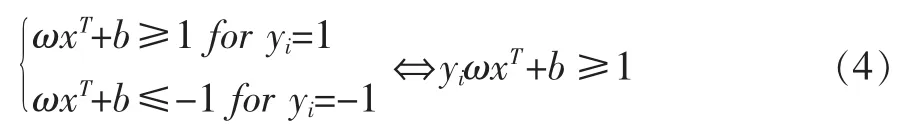
为了获得分类间隔最大的超平面H,该分类问题可以描述成一个二次规划问题:
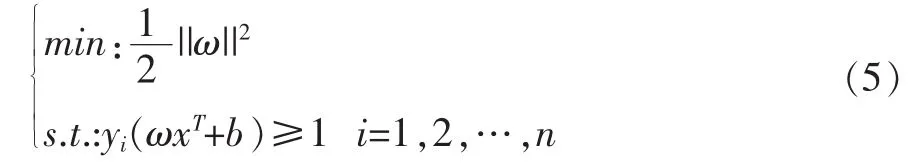
通过求解ω和b的值,获得判别函数和分类函数,如公式(6)和公式(7)所示:

因为文章的重点不在于支持向量机,对于其中参数问题的求解方法在这里不再赘述,具体可以参考相关文献[5]。
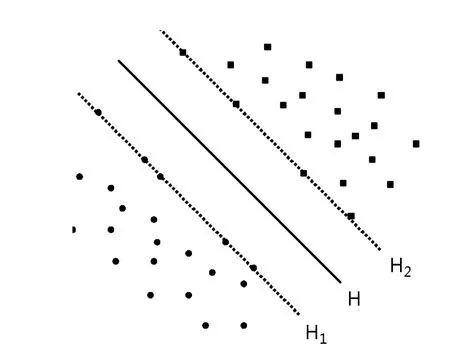
图2
1.3加权LDA模型
在LDA模型中引入特征加权机制的想法来自己于Wilson等在2010年发表的论文中[5]。在LDA模型中,认为每个词的权重对于主题的影响是相同的,但是在实际情况中,这种假设并不经常成立。在文档中,某些词对于主题的影响相对于文档中的其他词来说明显有着更加重要的作用,所以将词的权重机制引入LDA模型中是与实际相符的。
词的权重通过计算词和文本间的点互信息(Pointwise Mutual Information:PMI)来获得。词的权重的计算公式表示如下:
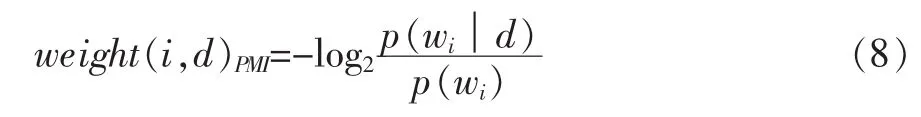
公式8中(wi|d)表示在文档d中单词wi出现的次数,而p(wi)表示的在整个文档集中单词wi出现的次数。
点互信息通常用于词对中,用来表示词对中的词的相关程度。Wilson将其用于词和文本来计算词的权重。通过上述公式计算到每个词的权重后,再将权重引入到Gibbs采样的过程中。
在Gibbs采样的过程中,当每次把文档d中的一个词d分配给主题k后,它的值不再增加1,改为增加这个词的权重。用公式表示为:
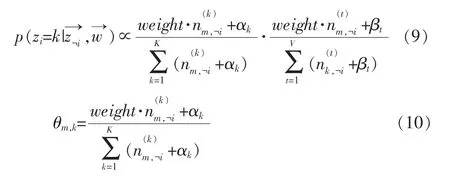
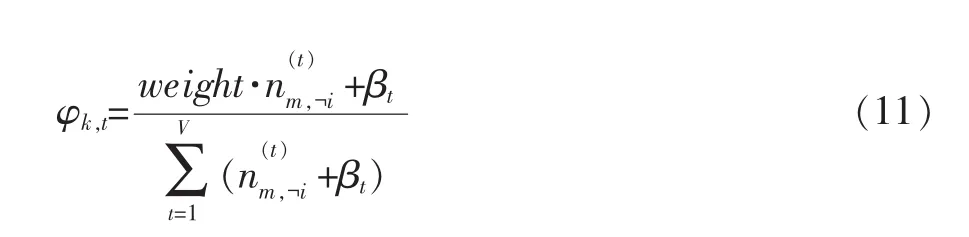
公式(9)中weight就是特征词的权重。从上面的公式中也可以看出,原始的LDA模型中的参数计算公式就是把每个词的权重都默认为1的情况,因此可以把原始的LDA当做是加权LDA模型的特例。
2 实验与分析
2.1数据集
实验使用了5个著名的公开的数据集Enron[9]。在Enron1、Enron2和Enron3中,正常邮件的比重大,在Enron4和Enron5中垃圾邮件占的比重大。5个数据集的具体组成如下表。
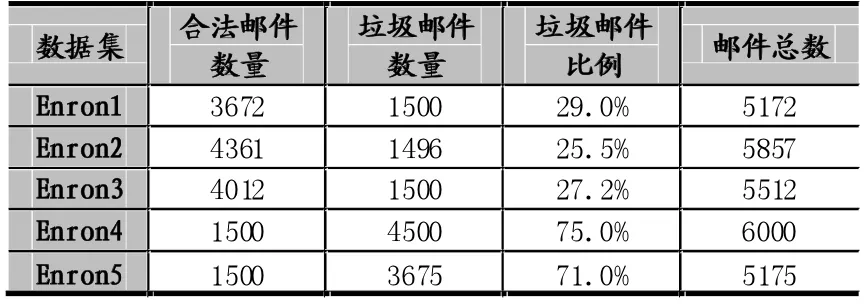
表1 Enron数据集说明
2.2数据集预处理
由于在英文文档中词与词之间有空格相连,所以对于这5个数据集省去了分词的步骤。按照下面的顺序对数据集中的文档进行处理:
(1)由于英语中存在时态、语态和词性等多种变化形式,一个词可能会有多种变形形式。所以利用词根还原技术(Steming)将文档集中的词都还原成为原始词根,减少了整个单词表中的词的数目。
(2)文档中还会有一些例如“a,an,the,of”等类似的词语,这些词被称为停用词,在预处理的过程中将这些停用词去掉,减少算法的时间。
(3)分别从垃圾邮件夹和合法邮件夹,按照30%的比例选取文件,然后合起来作为测试集,剩下的70%作为训练集。
2.3实验性能测量标准
确定加权LDA模型中的隐含主题参数k的个数是整个模型参数设置的主要工作,主题数目对于整个实验的影响也十分重要。对于隐含主题数k的确定,常使用统计语言模型中常用的评价指标标准困惑度(Perplexity)来进行选取[3]。标准困惑度是概率图模型中常用的一种指标,用来反映数据的不确定度。标准困惑度越小,意味着模型的性能越好。加权LDA模型中的标准困惑度的计算公式如下:
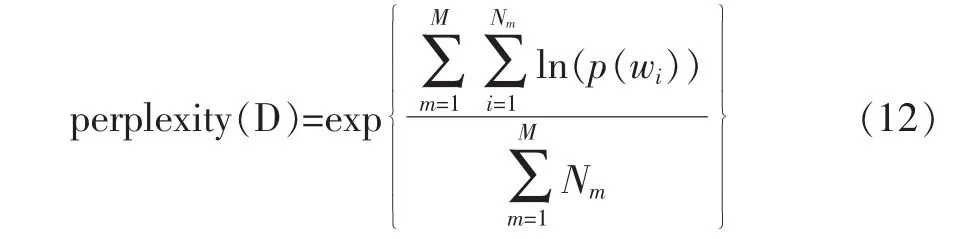
Nm表示的是文档集中第m篇文档的单词的数量,wi则是这一篇文档中的第i个词。
在对数据集中的邮件进行分类时,将合法邮件的类标设置为1,将垃圾的类标设置为-1。在相关文献中指出,马修斯相关系数是对于分类问题最好的评价指标之一[10]。马修斯指数的计算公式表示为:
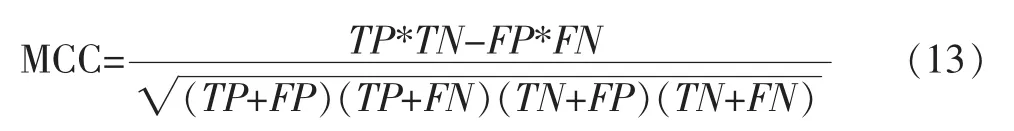
公式中的各项表示的含义如下表所示:
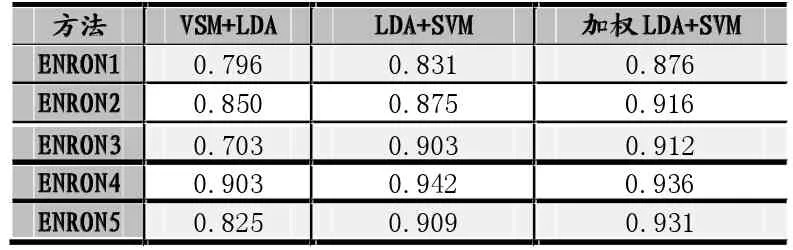
表2 分类混合矩阵
2.4实验结果与分析
实验首先通过找到较低的标准困惑度确定隐藏的主题的个数,再训练加权LDA模型,将从模型中得到的主题参数作为每篇文档的特征表示,达到降低维度的目的。最后再运用支持向量机作为分类器进行分类。
在实验过程中对k取不同的值,我们100为间隔,统计标准困惑度的变化,如图2所示,为了方便表示,纵坐标取的是标准困惑度的对数。
可以看出,标准困惑度在主题数目大概在300左右时达到最低,之后随着主题的增多而变大,因此我们设定k的值为300。
加权LDA模型中的其他参数设置为α=50/K,β为0.01,迭代次数设置为200次。然后将主题参数作为支持向量机分类算法的输入。为了体现该分类方法的效果,在五个数据集上的分类效果分别同LDA+SVM,VSM+LDA分类方法进行对比,实验结果如表3所示。
从上表中可以看出,加权LDA模型结合SVM作为分类器的效果在Enron1、Enron2、Enron3和Enron5上的效果要比普通的LDA模型结合SVM的分类器效果好。在Enron4上虽然分类效果稍逊,但是也没有相差很多。总体上来看,加权LDA模型在五个数据集上的整体效果也很好,MCC值都高于了0.87,这说明了加权LDA模型结合SVM是一种相对来说合理的预测,在实际应用中可行的。
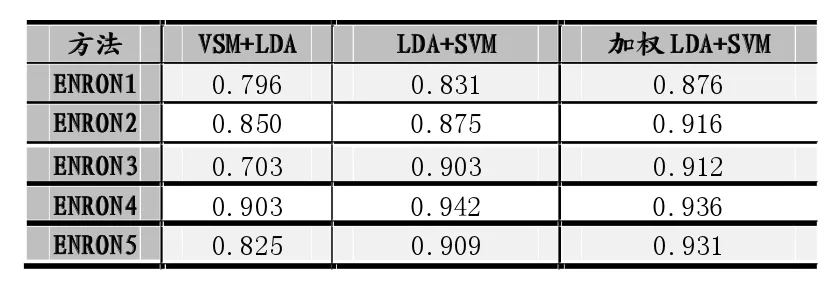
表3 分类器实验结果
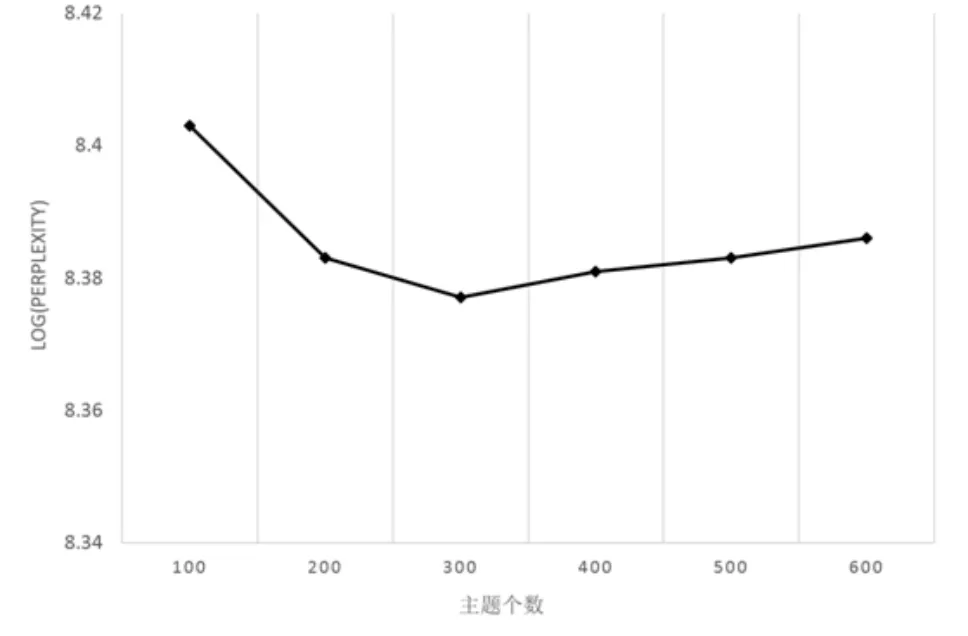
图2 标准困惑度随主题数目变化情况图
3 结语
本文将加权LDA模型与支持向量机的知识相结合,提出了一种新的分类器。在5个公开的数据量较大的数据集上进行了测试,并同过去的一些传统分类器的分类结果进行了比较。通过实验的结果可以发现,本文提出的这种分类方法具有更好的效果,表明了将这种方法运用到垃圾邮件过滤中是可行的。
未来的工作将主要集中在以下两个方面:(1)如何能够更准确地计算词的权重。加权LDA模型中提出的权重机制并不适用于所有类型的文本,如果像微博一样的短文本中,仅仅考虑词频,并不能区分不同的文本。(2)在更大的数据集上进行实验,诸如TRE05,TRE06等,并同开源的一些商用垃圾邮件过滤器进行比较。
[1]CORMACK G V.Email Spam Filtering:a Systematic Review[J].Foundations and Trends in Information Retrieval,2007,1(4):335-455.
[2]Dasgupta A,Drineas P,Harb B,et al.Feature Selection Methods for Text Classification[C]/KDD 07 Research Track Papers.ACM Press,2007:230-239.
[3]Blei DM,Ng AY,Jordan M.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[4]Wilson AT,Chew PA.Term Weighting Schemes for Latent Dirichlet Allocation[C].Human Language Technologies:the Conference of the North American Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2010:465-473.
[5]N.Cristianin,J.Shawe-Taylor.An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods[M].Cambridge University Press,2000.
[6]CHOUHAN S.Behavior Analysis of SVM Based Spam Filtering Using Various Kernel Functions and Data Representations[C].Proceedings of the 2013 International Journal of Engineering Research and Technology.Gandhinagar:ESRSA Publications,2013:3029-3036.
[7]Wang H,Cao L Y,Yao H L,et al.A Local Gibbs Sampling Automatic Inference Algorithm Based on Structural Analysis[J].Pattern Recognintion&Artificial Intelgience,2013,26(4):382-391.
[8]HSU W C,YU T Y,Support Vector Machines Parameter Selection Based on Combined Taguchi Method and Staelin Method for E-mail Spam Filtering[J].International Journal of Engineering and Technology Innovation,2012,2(2):113-125.
[9]KLIMT B,YANG Y.The Enron Corpus:a New Dataset for Email Classification Research[C].Proceedings of the 15th European Conference on Machine Learning.Berlin:Springer,2004:217-226.
[10]BALDI P,BRUNAKS,CHAUVIN Y,et al.Assessing the Accuracy of Prediction Algorithms for Classification:an Overview[J].Bioinformatics,2000,16(5):412-424.
Application of Term Weighted LDA Model with SVM in Spam Filtering
ZHANG Fan
(College of Computer Science,Sichuan University,Chengdu 610000)
Spam filtering method based on machine learning has a better result than the traditional filtering methods.Text representation affects the result of classification algorithm.Adopts the term weighted LDA on the basis of LDA model,uses term weighted LDA model and SVM to filter spam,so as to get a good classification result.The contrast experiment also verifies the validity and reliability of the method.
Spam;LDA;Term Weight
1007-1423(2016)26-0009-05DOI:10.3969/j.issn.1007-1423.2016.26.002
张帆(1991-),男,河南安阳人,硕士研究生,研究方向为机器学习
2016-07-07
2016-09-10
