基于联合失真控制的子空间语音增强算法
2016-10-13叶琪陶亮周健王华彬
叶琪,陶亮,周健,王华彬
基于联合失真控制的子空间语音增强算法
叶琪1,2,陶亮1,周健1,2,王华彬1
(1. 安徽大学计算智能与信号处理教育部重点实验室,安徽合肥230031;2. 安徽大学媒体计算研究所,安徽合肥230601)
为提高低信噪比环境下的语音可懂度,提出了一种基于联合失真控制的子空间语音增强算法。由于误差信号中的语音失真和残余噪声分量不能被同时最小化,同时,由语音估计器引起的语音放大失真超过6.02 dB时会严重损害语音可懂度。为此分别对语音失真和残余噪声进行最小化处理,最小化时把语音放大失真控制在6.02 dB以下作为约束条件,通过求解两个约束最优化问题得到两个不同的估计器,再对这两个估计器进行加权求和,得到一种基于联合失真控制的语音估计器。实验结果表明,相比于传统的子空间增强方法,在低信噪比环境下所提出的算法能更有效提高增强后语音的可懂度。
语音可懂度;失真控制;子空间增强
0 引言
自语音增强技术被提出以来,该技术被广泛地应用到助听器、通讯设备以及自动识别等系统中。现有的增强技术主要分为四类,谱减法类[1]、维纳滤波类[2]、统计模型类[3]和子空间类[4-7]。子空间方法将估计误差分为语音失真和残余噪声两部分,并在这两部分之间进行权衡控制。相比于其他方法,经子空间法处理后的语音受到音乐噪声的影响较小。Ephraim等[4]假设背景噪声为白噪声,利用卡胡南-洛夫变换(Karhunen-Loeve Transform,KLT)变换将含噪语音空间分解为相正交的信号子空间和噪声子空间,最后将噪声子空间置零,从信号子空间中估计出语音信号。为了处理有色噪声的情况,Mittal等[5]将含噪语音帧按噪声帧和语音帧分类,并分别处理。Rezayee等[6]则利用语音信号特征向量近似对角化噪声协方差矩阵,得到次优估计方法。Yi Hu等[7]提出了基于广义特征值分解的方法,获得了有色噪声下的最优估计器。
传统算法的主要目的是改善语音质量,并不一定能提高语音可懂度。Yi Hu等[8]对4类不同的增强算法是否能提高语音可懂度进行了研究。研究发现,传统算法并不能提高语音可懂度,低信噪比的情况下甚至会降低可懂度。Loizou等[9]分析了传统算法不能提高语音可懂度的因素。研究发现,由增益函数引起的语音放大失真和语音衰减失真对可懂度的影响不同,超过6.02 dB的放大失真会严重损害可懂度,衰减失真对可懂度的影响却很小。为提高语音可懂度,有不少研究人员在增强算法的设计中引入了失真控制,直接或间接地找出对可懂度有害的放大失真区域,再将增强后语音的放大失真约束在6.02 dB以下[10-13]。也有学者利用非对称代价函数对衰减失真和放大失真给予不同的惩罚力度[14],以削弱放大失真的影响。
传统子空间增强方法在增强过程中只考虑最小化误差信号中的语音失真分量,也没有对衰减失真和放大失真进行分类控制。本文对基于广义特征值分解算法的估计器推导进行改进,由于语音失真和残余噪声不能被同时最小化,本文通过分别最小化语音失真和残余噪声,同时引入失真控制,将语音放大失真控制在6.02 dB以下作为约束条件,对求解出的两个语音估计器进行加权求和,得到最终的语音估计器。
1 基于广义特征值分解的子空间语音增强
在单通道子空间语音增强算法中,假设干净语音信号和加性噪声不相关,含噪语音表示如下:
其中,、、分别是维的含噪语音、干净语音、干扰噪声。令是干净语音的线性估计,是的线性估计器,由估计产生的误差信号为
(2)
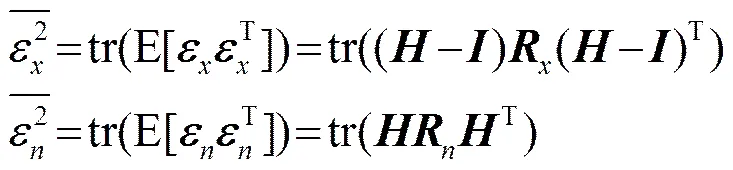
(4)
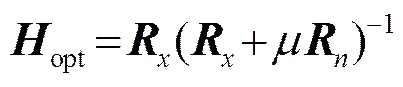
(6)
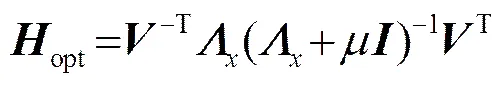
2 基于联合失真控制的子空间语音增强算法
经估计器处理得到的估计语音和干净语音间会存有误差,当误差为负值时,说明由估计器引起了衰减失真,相反,则是放大失真。文献[9]研究发现,设和分别是干净语音和估计语音的幅度谱,则当,即放大失真超过6.02 dB时,语音可懂度损失严重。为提高可懂度,将放大失真控制在6.02 dB以下,即需使,将其转化为下式:

转化式(8)得到下式:
(9)
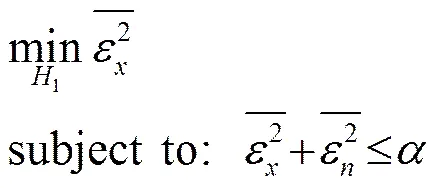
(11)
由式(11)解得的估计器为:
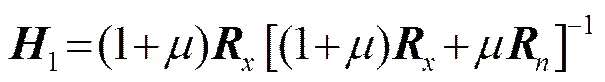
将式(6)代入式(12),可将估计器化简为
(13)
其中,设
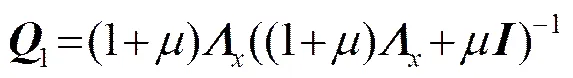
上述估计器在最小化语音失真的基础上推出,由于语音失真和残余噪声不能被同时最小化[4],但在增强后语音中,两者同时存在,并共同影响增强后语音的质量和可懂度。为减小两种失真对增强后语音可懂度的影响,本文通过最小化残余噪声推出另外一个估计器,最后利用和加权求和,得到基于联合控制的估计器。
(15)
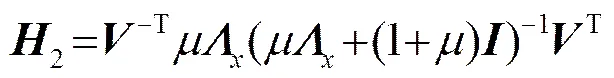
其中,设
(17)
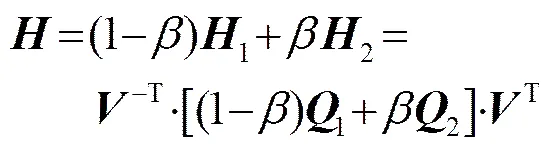
(19)
(20)
根据上述思路,本文改进算法实施步骤如下:

3 实验仿真及结果分析
为验证本文算法对语音可懂度增强的有效性,使用Matlab进行实验仿真。采用选自IEEE句子语音库中的50句语音作为干净语料。噪声数据选用Noisex92数据库[16]中的White高斯白噪声、m109坦克噪声和Babble噪声。实验中,干净语料和噪声数据使用的采样率为8 kHz,帧长设为32 ms,帧间重叠率为50%。
首先,在50句干净语音中选一句加入0 dB的m109噪声作为带噪语音,语音内容为“A rod is used to catch pink salmon.”,共8个单词,采用传统子空间算法和本文算法得到的增强后语音的波形图和语谱图如图1、2所示。从图1、2可以看到,增强语音的图形与干净语音非常接近,本文算法可以保留更多语音信息,在提高可懂度的同时,也能有效去除背景噪声。
采样点数/(×104)
(a) 干净语音
采样点数/(×104)
(b) 含噪声语音(0 dB m109噪声)
采样点数/(×104)
(c) 传统子空间算法
其次,用4种信噪比将干净语音和噪声进行混合,信噪比分别为:-6、-3、0、3 dB。采用4种处理方式:加噪未处理、文献[7]时域估计器TDC(Time Domain Contraints)、文献[7]频域估计器SDC(Spectrum Domain Contraints) 和本文算法去噪处理。实验取50个测试语音评测值的平均值作为语音增强后可懂度的评价值。使用可懂度衡量指标信噪比损失值SNRLoss[17]和STOI(Short-Time Objective Intelligibility)[18]对4种不同处理方式处理后语音可懂度性能进行评价。SNRLoss算法通过比较增强前后语音的各子带激励谱信噪比丢失的方法进行可懂度测试,信噪比损失值越大,语音的可懂度越小。STOI算法给出一个(0,1)范围内的值,STOI值越大,表示增强后的语音可懂度越高。SNRLoss评测结果见图3,STOI评测结果见图4。
(a) 干净语音
(b) 含噪声语音(0 dB m109噪声)
(c) 传统子空间算法
(d) 本文点数
图2 语谱图
Fig.2 Speech spectrograms
从图3中可以看到,在不同噪声的不同信噪比下,本文算法的SNRLoss评测值要明显低于加噪未处理和文献[7]中TDC和SDC的评测值,即便输入信噪比为-6 dB情况下,SNRLoss值远小于其他三种处理方式。信噪比丢失值越小,说明语音的可懂度效果越好。图4显示的本文算法的STOI值要明显高于其他三种处理方式。本文算法通过将放大失真控制在6.02 dB以下,在信噪比较低时,以更多地抑制误差信号中的残余噪声成分,降低由估计器引起的放大失真,在信噪比比较高时,语音能量能对噪声能量起掩蔽作用,以抑制误差信号中的语音失真成分为主。SNRLoss和STOI的评测结果表明,本文算法可取得更好和更稳定的可懂度效果。
最后,为进行主观听辨实验,挑选2男2女共4名听力正常测试者进行词语听辨测试,被试听的语音包括加噪未处理和经TDC估计器、SDC估计器和本文算法去噪处理后的增强语音,其中UN表示加噪未处理的情况。分别在上述4种信噪比和3种背景噪声下进行听辨实验。表1给出了不同算法增强后语音听辨实验中的平均词语识别率。从表1中可以看出,在三种不同噪声背景下,本文算法的词语识别率明显高于改进前的算法,进一步证实了本文算法可懂度增强效果的有效性。
(a) 高斯白噪声
(b)m109坦克噪声
(a) 高斯白噪声
(b) m109坦克噪声
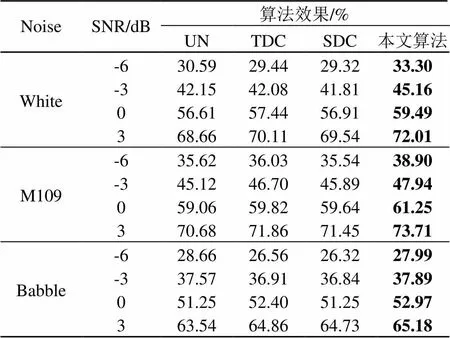
表1 不同背景噪声下不同算法的词语识别率比较
4 结论
本文提出了一种基于联合失真控制的子空间语音增强算法。将对超过6.02 dB的放大失真的控制结合到约束最优化问题中,即在最小化语音失真的同时,将语音失真和残余噪声同时进行约束,得到基于语音失真的估计器。另外,由于误差信号中存在的语音失真和残余噪声不能被同时最小化,在信噪比不同区域,语音失真和残余噪声的含量又各不相同,所以推出基于残余噪声的估计器,即最小化残余噪声,并同时约束语音失真和残余噪声。最后将上述两个不同的估计器加权求和得到新的估计器,信噪比低时,以最小化残余噪声为主,信噪比高时,以最小化语音失真为主。本文算法通过对放大失真的控制,减少由放大失真对语音可懂的损害。实验结果表明,相比于加噪未处理和YiHu提出的子空间算法,本文算法有更有效、更稳定的可懂度增强效果。
[1] Boll S. Suppression of acoustic noise in speech using spectral subtraction[J]. Acoustics Speech & Signal Processing IEEE Transactions on, 1979, 27(2): 113-120.
[2] Scalart P, Filho J V. Speech enhancement based on a priori signal to noise estimation[C]//IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Atlanta, 1996, 2: 629-632.
[3] Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator[J]. Acoustics, Speech and Signal Processing, IEEE Transactions on, 1984, 32(6): 1109-1121.
[4] Ephraim Y, Van Trees H L. A signal subspace approach for speech enhancement[J]. Speech and Audio Processing, IEEE Transactions on, 1995, 3(4): 251-266.
[5] Mittal U, Phamdo N. Signal/noise KLT based approach for enhancing speech degraded by colored noise[J]. Speech & Audio Processing IEEE Transactions on, 2000, 8(2):1847-1850.
[6] Rezayee A, Gazor S. An adaptive KLT approach for speech enhancement[J]. Speech & Audio Processing IEEE Transactions on, 2001, 9(2): 87-95.
[7] Hu Y, Loizou P C. A generalized subspace approach for enhancing speech corrupted by colored noise[J]. Speech and Audio Processing, IEEE Transactions on, 2003, 11(4): 334-341.
[8] Hu Y, Loizou P C. A comparative intelligibility study of single-microphone noise reduction algorithms[J]. The Journal of the Acoustical Society of America, 2007, 122(3): 1777-1786.
[9] Loizou P C, Kim G. Reasons why current speech-enhancement algorithms do not improve speech intelligibility and suggested solutions[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(1): 47-56.
[10] Li N, Bao C C, Xia B Y, et al. Speech intelligibility improvement using the constraints on speech distortion and noise over-estimation[C]//IEEE International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Beijing, 2013: 602-606.
[11] 郭利华, 马建芬. 具有高可懂度的改进的维纳滤波的语音增强算法[J]. 计算机应用与软件, 2014, 31(11): 155-157.
GUO Lihua, MA Jianfen. An improved wiener filtering speech enhancement algorithm with high intelligibility[J]. Computer Applications and Software, 2014, 31(11):155-157.
[12] Yang Y X, Ma J F. Speech Intelligibility Enhancement Using Distortion Control[J]. Advanced Materials Research, 2014, 912-914: 1391-1394.
[13] Ma Y, Nishihara A. A modified Wiener filtering method combined with wavelet thresholding multitaper spectrum for speech enhancement[J]. EURASIP Journal on Audio, Speech, and Music Processing, 2014, 2014(1): 1-11.
[14] 周健, 郑文明, 王青云等. 提高耳语音可懂度的非对称压缩语音增强方法[J]. 声学学报, 2014, 39(4): 501-508.
ZHOU Jian, ZHENG Wenming, WANG Qingyun, et al. An asymmetric attenuated speech enhancement approach for improving intelligibility of noisy whisper[J]. Acta Acustica, 2014, 39(4): 501-508.
[15] Montazeri V, Khoubrouy S A, Panahi I M S. Evaluation of a new approach for speech enhancement algorithms in hearing aids[C]// IEEE International Conference on Engineering in Medicine and Biology Society (EMBC), 2012: 2857-2860.
[16] Varga A, Steeneken H J M. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993, 12(93): 247-251.
[17] Ma J, Loizou P C. SNR loss: A new objective measure for predicting the intelligibility of noise-suppressed speech[J]. Speech Communication, 2011, 53(3): 340–354.
[18] Taal C, Hendriks R, Heusdens R, et al. An algorithm for intelligibility prediction of time-frequency weighted noisy speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 49(7): 2125-2136.
A subspace speech enhancement algorithm based on combined distortion control
YE Qi1,2, TAO Liang1,ZHOU Jian1,2, WANG Hua-bin1
(1.Key Laboratory of Intelligent Computing and Signal Processing of Ministry of Education,Anhui University, Hefei 230031,Anhui, China;2.Institute of Media Computing, Anhui University, Hefei 230601,Anhui, China)
In order to improve speech intelligibility in low signal-to-noise ratio environment, a subspace speech enhancement algorithm combined with distortion control is proposed. Due to the facts that the components of speech distortion and residual noise in the error signal can not be simultaneously minimized and that the amplification distortion of speech in excess of 6.02dB caused by speech estimator will seriously damage the speech intelligibility, the speech distortion and the residual noise are minimized respectively, and meanwhile the speech amplification distortion is kept below 6.02dB as a constraint condition. By solving these two constraint optimization problems, two different estimators are obtained, and then a weighted sum of these two estimators is made to get the speech estimator based on combined distortion control. The results show that the proposed approach can improve enhanced speech intelligibility more effectively in low signal-to-noise ratio environment, compared with the traditional subspace enhancement method.
speech intelligibility; distortion control; subspace enhancement
TN912.35
A
1000-3630(2016)-03-0254-06
10.16300/j.cnki.1000-3630.2016.03.014
2015-05-23;
2015-08-23
国家自然科学基金(61301295, 61372137)、安徽省自然科学基金(1308085QF100)、安徽大学博士启动资金资助项目.
叶琪(1990-), 女, 安徽宣城人, 硕士研究生, 研究方向为语音增强。
叶琪, E-mail:yeqi17@126.com
