一种基于特征模型和协同过滤的需求获取方法
2016-10-13彭珍连何克清唐明董
彭珍连 王 健 何克清 唐明董
1(软件工程国家重点实验室(武汉大学) 武汉 430072)2(湖南科技大学计算机科学与工程学院 湖南湘潭 411201)
一种基于特征模型和协同过滤的需求获取方法
彭珍连1,2王健1何克清1唐明董2
1(软件工程国家重点实验室(武汉大学)武汉430072)2(湖南科技大学计算机科学与工程学院湖南湘潭411201)
(zlpeng@whu.edu.cn)
随着互联网和Web服务相关技术的快速发展,基于互联网进行软件开发越来越受到软件开发从业者的青睐.软件开发是一种多知识密集型过程,其中需求获取对软件系统的成功具有关键作用.基于互联网的软件需要满足大量地理位置各异、类型不同的客户需求,这增加了需求获取的难度;与此同时,互联网上相似类型的软件众多,这些具有大量相似功能的软件为软件需求获取提供了新的途径.为此,已有研究将推荐系统引入到软件需求获取过程中,借助于已有相似软件需求描述,为新软件推荐合适的缺失特征.为了提高推荐系统在软件需求预测和辅助获取过程中的准确率,提出了FM_KNN算法,利用特征模型中的特征类型以及特征间的关联关系,结合KNN(K-nearest neighbors)协同过滤推荐系统进行辅助需求获取.通过在真实数据集和仿真数据集上的实验和分析,验证了所提方法在预测准确率上具有更好的效果,从而为需求获取提供更好的支持.
需求获取;特征模型;协同过滤;推荐系统;特征推荐
随着互联网和Web服务技术的快速发展,基于互联网进行软件开发越来越受到软件从业者的青睐.与传统软件开发类似,基于互联网的软件开发开始于需求收集阶段,在此阶段中各行业分析师与项目利益相关者合作以获取软件系统的需求.软件需求获取的质量是软件成功与否的关键.一个众所周知的事实是在软件开发后期阶段纠正错误的代价将呈指数增长,如果在软件需求获取过程发现缺失或错误的需求,修改这些错误的代价将急剧降低[1].然而,在需求收集和获取阶段要检查和确定丢失或错误软件需求所要付出的努力是巨大、耗时且容易出错的,因此如何选取有效的软件需求获取技术成为软件开发实践者和研究者关心的问题.
软件需求获取是从软件用户、消费者和各利益相关者收集软件需求的过程.这是一个复杂的过程,因为它不仅是从软件消费者收集需求的实践过程,也需要软件消费者、各利益相关者和需求分析师的参与来收集良好和一致的需求集合以真正解决问题的过程.已有许多研究根据待开发软件系统的领域知识和(或)情景特点提出不同的软件需求获取方法或框架[1-4],这些方法在软件开发需求过程中能有效指导软件需求获取,减少需求过程中的工作负担和错误风险,同时领域知识构造常常需要付出大量人工操作.基于互联网的软件需要满足大量地理位置各异、类型不同的客户需求,这增加了需求获取的困难;同时,互联网上相似软件众多,这些具有大量相似功能的软件为软件需求获取提供了新的途径.为此,已有研究将推荐系统引入到需求工程领域.Laurent等人[5]探索利用网络论坛的方式进行供应商主导的开源项目需求工程任务.Castro-Herrera等人[6-7]使用组织者和发起者协同思想(organizer and promoter of collaborative ideas, OPCI)推荐系统来支持推荐领域专家(expert stakeholder)和需求主题,从而借助专家的领域知识辅助进行需求获取.这些方法能够指导面向网络的软件开发过程中需求组织者和分析师解决软件需求获取问题,但未充分利用已有相似软件的公共领域知识.Hariri等人[8]设计了一个推荐系统来降低执行领域分析时的人工操作负担,使用数据挖掘算法抽取在线产品描述的公共特征以及这些特征之间的关联关系,然后使用关联规则(association rule)挖掘和KNN方法(本文记为AR_KNN)为具有部分特征的新软件产品推荐其缺失的特征.该方法利用了特征之间的关联关系,然而该方法只是挖掘特征之间的共现关系,并未考虑特征之间存在的如多选一、多选多、互斥等关联关系,使得待开发软件难以拥有必需的初始特征作为特征推荐的基础,从而影响预测的准确率.
因此,如何快速准确地预测缺失特征成为软件需求获取过程需要解决的问题.为此,本文借鉴上述文献的思想,结合文献[9]中对特征的内涵和外延2方面的定义(就内涵而言特征是由一组相对紧密关联的单个需求构成的集合,就外延而言特征是一种具有用户价值的软件特点),利用已有的相似软件领域知识即软件特征模型辅助引导用户进行需求描述,使用推荐系统为具有部分特征的待开发软件推荐特征,从而进行需求辅助获取,以降低需求获取过程中复杂而繁琐的人工负担.具体而言,本文方法是在特征模型的基础上,将某一具体领域内各个已存在软件看作推荐系统中的历史用户,各个软件所拥有的特征看作推荐系统中的项目,充分利用特征模型中各个特征之间存在的关联关系,结合KNN协同过滤[10-12]推荐系统,通过预测可能的特征来补充待开发软件的需求.通过在真实数据集和仿真数据集上的实验分析,本文所提方法比普通KNN协同过滤预测算法和AR_KNN协同过滤算法准确率要高,最高提高了大约6%.
1 背景知识
1.1特征模型
特征模型来源于软件工程学科,用来表示某一领域的软件系统中的共性和可变性.根据文献[13-15]的描述,特征图是特征模型的图形化表示,一般组织成树形结构,树的根节点称为根特征,表示一个领域概念,树的分支可以被定义成精化关系,即必选(Mandatory)特征、可选(Optional)特征、多选多(OR)关系和多选一(XOR)关系;另外,特征之间存在交叉树约束关系,如依赖(Requires)关系和互斥(Excludes)关系.图1显示了本文所用数据集中移动终端搜索引擎软件(Wiki软件)领域的特征模型示例(部分),图1中根节点为“Wiki Software”,代表一个软件族;根节点的子特征“Data Storage”和“Development Language”为必选特征,“Search Means”为可选特征;特征“Data Storage”的子特征“Database”和“File”与其父特征构成多选多关系,即“Data Storage”可以同时为“Database”和“File”;特征“Development Language”的子特征包括“Java”,“PHP”,“Python”,它们之间为多选一关系,即对某个具体的“Wiki Software”而言,“Development Language”只能是“Java”,“PHP”,“Python”中的一种;特征“File Name”依赖特征“File”,即“Search Means”为“File Name”时,必须确保“Data Storage”包含“File”.
本文引用文献[13-14]对特征模型、特征模型配置的定义如下:
定义1. 特征模型(feature model, FM).定义为一个七元组FM=(G,EMAND,EOPT,GXOR,GOR,RE,EX).其中,G=(F,E,r)是一个有根树,F=(Ffun,Fatt)是软件特征的有限集合,Ffun是软件功能特征,Fatt是软件非功能特征(也称属性特征),E⊆F×F是有限边集合,r∈F是根特征;EMAND⊆E定义必选特征与它们父特征的边集合;EOPT⊆E定义可选特征与它们父特征的边集合;GXOR⊆P(F)×F,GOR⊆P(F)×F定义特征组,表示儿子特征与它们公共父特征的值对集合;RE定义依赖关系,形式化为A⟹B;EX定义互斥关系,形式化为A⟹B,A∈F,且B∈F.
定义2. 特征模型配置.定义为一组选择的特征集合.它是在软件产品配置过程中可选方案的一种决策结果,它仅代表一个满足特征模型中语义约束的软件产品设计,可以充当软件产品实现的输入并记录软件产品设计决策.
图1中的特征模型示例,(“Wiki Software”,“Data Storage”,“Database”,“Development Language”,“Java”)是一个特征模型配置;而(“Wiki Software”,“Data Storage”,“Database”,“Search Means”,“File Name”)不是特征模型配置,因为它违反了依赖(Requires)关系.
1.2推荐系统
推荐系统是解决信息超载问题的有效办法.常用的推荐系统技术包括基于协同过滤(collaborative filtering,CF)推荐[10-12]、基于内容的(content-based,CB)推荐[10,16]以及矩阵分解(matrix factorization,MF)方法[17].根据文献[18]的研究,当推荐的数据为0-1矩阵时,KNN协同过滤推荐系统的效果要优于矩阵分解方法,由于特征模型的数据被表示为0-1矩阵,故本文不考虑矩阵分解方法.
KNN协同过滤推荐系统的基本思想是用户往往喜欢与其偏好和背景相似用户所喜欢的项目.在0-1矩阵数据中,KNN协同过滤算法往往针对一组(如m个)用户和一组(如n个)项目,用户对项目的偏好可以通过一个用户-项目矩阵R=(Ri j)表示,Ri j=1表示用户i对项目j有偏好关系,Ri j=0表示用户i对项目j无偏好关系.
本文要研究的问题可以转化为某0-1向量(待开发软件)缺失特征值的预测问题.本文采用的方法是需要根据KNN协同过滤算法计算最相似(最近)邻居,利用这些最相似邻居数据对包含部分特征的待开发软件的缺失特征值进行预测.为了提高预测准确率,针对待开发软件可能存在的特征数据稀疏性,采用特征模型中语义约束关系来扩充待开发软件的特征偏好信息.
2 基于特征模型和协同过滤的需求获取
2.1需求获取方法框架
本文提出的基于特征模型和协同过滤的软件需求获取方法假设领域专家已经收集相当数量相似软件的需求描述文档,方法框架如图2所示.需求获取过程分为以下4个阶段:
1) 领域专家首先收集并输入已有软件描述文档,然后利用领域分类算法将一些相关的描述文档分类到不同的领域.该阶段中涉及的领域分类算法采用本课题组前期工作提出的面向主题的领域分类算法[19],可以自动化完成.
2) 在与待开发软件相同的领域中,对于分类得到的需求描述文档,利用领域分析工具(如Screen-Scraper[15])结合领域专家的领域知识分析得到已有软件-特征的0-1矩阵.该阶段工作半自动化完成.
3) 根据前面得到的同一领域软件的0-1矩阵,领域专家利用文献[13]提出的特征模型提取算法,构建已有相似软件的特征模型.该阶段工作是自动化完成的.
4) 需求分析师输入具有部分特征的软件描述(表示为0-1向量),根据由以上步骤构建的特征模型和已存在的软件-特征0-1矩阵,利用基于特征模型的特征推荐算法,得到输出结果为具有补充特征的软件描述(表示为0-1向量),供需求分析师进一步进行需求获取操作.该阶段工作是自动化完成的.
由以上描述可知,前3个阶段的工作可以由需求领域专家利用现成的算法或工具实现,本文工作聚焦在最后一个阶段,即利用前面阶段得到的软件-特征0-1矩阵和软件特征模型,采用软件特征推荐算法,为需求分析师得到更加丰富的软件需求描述信息,减轻软件获取过程中的人工操作负担和尽量减少需求获取过程中出现的错误概率.

Fig. 2 Framework for requirements elicitation method based on feature model.图2 基于特征模型的需求获取方法框架
2.2需求获取算法流程
本节主要介绍本文需求获取算法的实现流程.图3显示了该流程,主要包含3部分:1)FM语义关系条件转换.利用FM特征的类型与特征之间关联关系对当前用户的初始特征偏好向量补充一部分缺失特征值,得到中间特征向量.2)推荐系统.采用KNN协同过滤算法,根据中间特征向量和历史软件数据,先寻找到K个最近邻的邻居用户,然后利用K个最近邻的邻居用户对特征的偏好值对当前用户中缺失特征值进行预测(0或1),得到具有补充值的软件特征偏好向量.3)软件-特征矩阵数据库.主要功能是为推荐系统提供历史软件描述数据.新得到的向量可以作为一条新的软件描述数据加入软件-特征数据库以更新历史数据,以实现历史数据的迭代式生成.
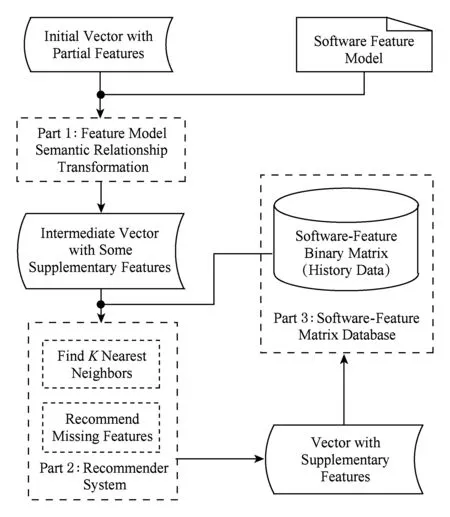
Fig. 3 Process of requirements elicitation algorithm.图3 需求获取算法流程
2.3示例
首先通过一个示例阐述本文方法的基本思路.假设图4所示为一个简单的软件-特征矩阵示例,其中,Si表示软件集合中第i个软件,Fj表示特征集合中第j个特征,如果第i行第j列单元格内容为1表示第i个软件Si拥有第j个特征Fj;反之,如果该单元格内容为0表示第i个软件Si不拥有第j个特征Fj.图4中S1~S4为历史软件,S5为待开发软件;F1~F9为软件特征;符号“?”表示软件S5中表达不清楚或不确定的软件特征.
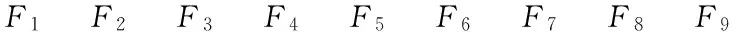
F1F2F3F4F5F6F7F8F9

Fig. 4Software-feature matrix sample.
图4软件-特征矩阵示例
采用文献[13]的特征模型提取算法,构建其对应的特征模型如图5所示:

Fig. 5 An example of feature model.图5 特征模型示例
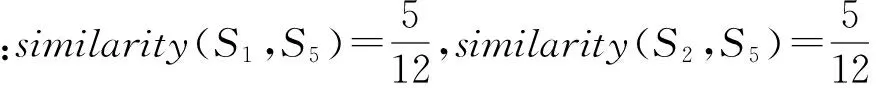
2.4FM语义约束条件转换规则
如1.1节所述,FM关联关系主要有精化关系如必选、可选、多选多和多选一,约束关系如依赖和互斥.在为当前用户扩充特征偏好信息过程中,特征模型的精化关系和约束关系可以转换为一系列条件规则.
定义3. FM语义关系转换规则.该规则指的是在具体的软件需求应用领域,FM语义关系可以转换为以下规则对软件缺失特征值进行预测:
1) 如果特征Fi为Mandatory特征,则所有的软件都拥有该特征,即所有软件中Fi=1.
2) 如果特征Fi为Optional特征且包含若干子特征,某软件中其子特征至少有一个值为1,则该软件中Fi=1.
3) 如果特征Fi,Fj,Fk有共同的父特征并且满足OR关系,则Fi,Fj,Fk在每一个软件中至少有一个值为1,即Fi,Fj,Fk的值不能同时为0.
4) 如果特征Fi,Fj,Fk有共同的父特征且满足XOR关系,则Fi,Fj,Fk在每一个软件中有且仅有一个值为1,其他的值为0.
5) 如果特征Fi和特征Fj满足FiRequiresFj,在每一个软件中,若Fj=0,则Fi=0;若Fj=1,则Fi=1或者Fi=0.
6) 如果特征Fi和特征Fj满足FiExcludesFj,在每一个软件中,若Fi=0,则Fj=1;若Fi=1,则Fj=0.
7) 如果特征Fi为特征Fj的子特征,且Fj=0,则在每一个软件中,Fi=0.
2.5寻找最近邻居
对于待开发软件的中间向量,我们采用KNN协同过滤算法,先通过相似度计算在历史软件-特征数据中寻找最近邻居.有许多方法用来计算待开发软件数据和历史软件数据之间的相似度如Pearson相关度、余弦相似度、Spearman相似度和Tanimoto(即Jaccard)相似度[12].本文数据是0-1矩阵,因此使用Tanimoto相似度来计算待开发软件与历史软件之间的相似度:
(1)其中,Sa表示待开发软件,Si表示某历史软件,|Sa∩Si|表示待开发软件与该历史软件中特征值相等的数目,|Sa|表示待开发软件中特征值已知的数目,|Si|表示该历史软件中特征值已知的数目.通过计算待开发软件与历史软件之间的相似度,并按降序排列,就可以选择出待开发软件的最近邻居.
2.6缺失特征值预测
为了预测待开发软件缺失特征值,我们通过计算prefer值来确定待开发软件是否拥有缺失特征,用式(2)表示:
prefer(Sa,Fj)=
(2)
其中,Neighbor(Sa)表示待开发软件Sa的邻居软件集合,Fj表示待开发软件Sa中的某个缺失特征,Vj表示Si中的Fj特征的值.设定一个阈值α(本文取值0.5),如果该预测值小于α,说明大多数邻居软件在该特征上的取值为0,因此该缺失特征预测值取值为0,否则取值为1.
2.7需求获取算法
本文提出了软件需求获取算法FM_KNN(feature model andK-nearest neighbors),如算法1所示.
算法1. 软件需求获取算法FM_KNN.
输入:历史软件集S(|S|=m)、软件特征集F(|F|=n)、软件特征模型FM、具有缺失特征值(标记为Null)的待开发软件(标记为Sa)特征偏好向量μ(1×n的0-1向量)、最近邻居数K、阈值α;
输出:预测的具有补充值的待开发软件特征的偏好向量λ(1×n的0-1向量).
① 调用算法FMSCF(μ)并将结果更新到μ;
② for eachSi∈S
③ 根据式(1)计算similarity(Sa,Si)的值;
④ end for
⑤ 按降序排序similarity(Sa,Si)的值;
⑥ 寻找Sa的K个最近邻居Neighbor(Sa)⊆S;
⑦ for eachFj∈F
⑧ if (μ(Fj)=Null)
⑨ 根据式(2)计算prefer(Sa,Fj)的值;
⑩ if (prefer(Sa,Fj)≥α)




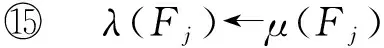



算法1中调用了特征模型语义约束过滤(feature model semantic constraints filter, FMSCF)算法,为待开发软件的初始偏好向量μ进行初步预测,补充部分缺失特征值.算法2描述了FMSCF算法的过程.
算法2. 特征模型语义约束过滤算法FMSCF.
输入:软件特征模型FM、软件特征集F、具有缺失特征值的待开发软件特征偏好向量μ;
输出:补充部分缺失特征值的向量ν(1×n的0-1向量).
① for eachFj∈F
② if (μ(Fj)=Null)
③ if ((Fj.par,Fj)∈EMAND&&
μ(Fj.par)=1)*Fj.par为Fj的
④μ(Fj)=1;
⑤ end if
⑥ if ((Fj.par,Fj)∈GOR&&μ(Fj.par)=
⑦ if (∀F′((F′≠Fj) && (Fj.par,
F′)∈GOR&&μ(F′)=0))
⑧μ(Fj)=1;
⑨ end if
⑩ end if

μ(Fj.par)=1)*Fj,Fj.par满足

F′)∈GXOR&&μ(F′)=1))




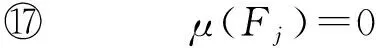










在时间复杂度方面,FM_KNN算法除了行①以外其他各步与KNN算法完全相同,KNN算法时间复杂度为O(mn+m2),而FM_KNN算法中行①为FMSCF算法的调用,该FMSCF算法时间复杂度为O(K′n),其中,K′为常数(表示单个特征关联关系数最大值),故FM_KNN算法整体时间复杂度仍为O(mn+m2).
3 实验分析
3.1实验准备
本节通过实验来检验该预测方法的有效性.我们分别在真实数据集和仿真数据集上开展实验,实验在MyEclipse 8.6中实现,所有实验运行于台式机,机器配置如下:操作系统为Win7_64旗舰版,CPU为intel CoreTMi7-4790 CPU@3.60 GHz(4 core),内存为8 GB.
当前公开的软件特征模型数据比较稀少,本文的实验数据之一来源于德国软件公司CosmoCode发布的针对移动专业人群的Wiki软件及其特征数据①,截至2014年12月31日,其发布页面已有141个Wiki软件,每个Wiki软件最多含有140个特征.我们利用页面数据爬取技术获取这些Wiki软件及其包含的特征数据.采用文献[13]提出的特征模型抽取方法,在本课题组2位博士研究生和2位硕士研究生帮助下,过滤去掉状态为正在编辑或特征不完全的Wiki,最终选取了92个Wiki软件,每个软件的特征数为130,在这组软件对应的特征模型中包括4个Mandatory特征、5个带子特征的Optional特征、4组XOR关系、5组OR关系以及3组Requires关系.考虑到上述真实数据集的规模相对较小,我们进一步随机生成了一组模拟软件数据,包含3 000个软件,每个软件的特征数为100,采用与Wiki数据同样的处理方法,在这组软件对应的特征模型中包括5个Mandatory特征、3个带子特征的Optional特征、4组XOR关系、5组OR关系、4组Requires关系和3组Excludes关系.2组数据都是采用0-1矩阵形式进行存储.
3.2评估指标
本文使用准确率以及运行时间作为方法有效性的评价参数.其中,准确率类似于推荐系统中的命中率hit-ratio[12],即推荐的项目与测试集中的项目的交集除以推荐项目的总数,常常与命中排序hit-rank[12]一起使用,考虑推荐的项目在项目列表中的位置.本文使用的准确率与推荐系统中的不同,不考虑命中排序,而只是考虑待开发软件中预测正确的缺失特征值数与需要预测的缺失特征总数的比值,用式(3)表示:
(3)
其中,1≤j≤n,n表示特征集数目;pre表示预测值;real表示实际值,其他符号如前所述.precision=1表示本文预测方法能够提供正确预测,而precision=0表示方法不能提供正确预测.
3.3实验结果与分析
考虑到应用场景及计算简便性,对于第1组数据(简称Wiki数据),我们采取随机抽取Wiki软件作为待开发软件,剩下的其他Wiki软件作为历史软件数据,随机重复实验,每次实验以不同的比率随机将待开发软件的特征值抽取出去设为缺失特征值(例如数据密度为10%表示随机去除90%的特征值),然后利用预测方法对其缺失的值进行预测.而对于第2组数据(简称Custom数据),为了消除数据敏感性,我们将数据分为3个子部分,随机从其中某子部分抽取软件随机处理后作为待开发软件,将另2个部分作为历史软件数据,然后采用与第1组数据类似的方法进行实验.
实验采用本文所提方法FM_KNN与KNN协同过滤算法以及文献[8]中关联规则的KNN方法AR_KNN进行比较,其中,AR_KNN最小支持度设为20%,最小信任度设为50%.共有3组实验进行评估:第1组实验是判断待开发软件的数据密度对预测准确率的影响;第2组实验是最近邻相似软件的数量对预测准确率的影响;第3组是3种方法在不同数据密度下运行时间的比较.
实验1. 待开发软件数据密度对准确率的影响.
待开发软件的数据密度依次从10%以5%的步长逐步递增到90%,Wiki数据每次计算重复实验10次取平均值,Custom数据每次交叉计算重复实验10次取平均值,2组数据下的实验结果分别如图6和图7所示.

Fig. 6 Comparison of precision under different data density (Wiki data). (K=20)图6 不同数据密度的预测准确率比较(Wiki数据) (K=20)

Fig. 7 Comparison of precision under different data density (Custom data). (K=200)图7 不同数据密度的预测准确率比较(Custom数据) (K=200)
从图6和图7可以看出,3种方法都远大于随机方法的平均值50%,说明利用相似软件的特征值来预测待开发软件的特征值是可行的;随着待开发软件数据密度的增加,3种方法的预测准确率呈线性增加,说明KNN预测随着待开发软件特征信息量的增加其预测性能不断提高;当数据密度比较低时,FM_KNN算法的准确率比AR_KNN和KNN提高更加明显,说明本文所提方法在待开发软件特征描述数据稀疏性扩充方面优势更加明显.
另外,AR_KNN的预测准确率要优于KNN,而 FM_KNN比KNN和AR_KNN的预测准确率平均值都要高.Wiki数据下分别平均提升1.4%和0.62%,最高提升了2.15%和1.08%;Custom数据下,分别平均提升了4.43%和1.79%,最高提升了5.24%和2.94%;进一步说明扩充待开发软件特征信息能够提高预测准确率,且FM_KNN算法充分考虑了软件的领域知识,而比AR_KNN算法对待开发软件特征信息的扩充更为充分.
实验2. 最近邻居数对准确率的影响.
Wiki数据集选定数据密度为70%,邻居数量依次从2以步长2逐步递增到30,每次计算重复实验10次取平均值;Custom数据集选定数据密度为70%,邻居数量从20以20的步长递增到300,每次交叉计算重复实验10次取平均值.2组数据下的实验结果分别如图8和图9所示.

Fig. 8 Comparison of precision under different neighbor number (Wiki data). (density=70%)图8 不同邻居数的预测准确率比较(Wiki数据) (density=70%)
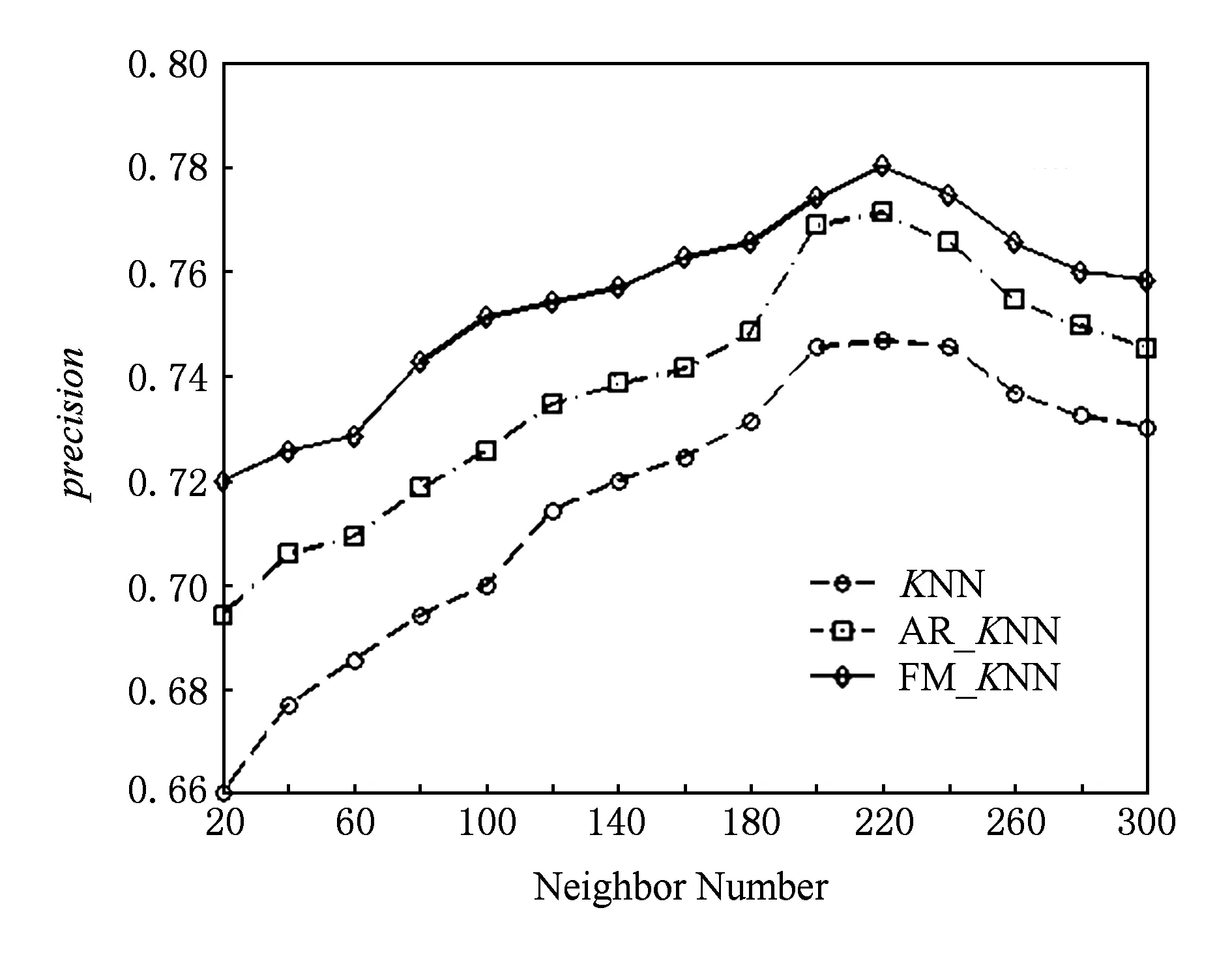
Fig. 9 Comparison of precision under different neighbor number (Custom data). (density=70%)图9 不同邻居数的预测准确率比较(Custom数据) (density=70%)
从图8和图9可以看出,随着邻居数的增加预测准确率逐渐提高,但是到了一定的临界值(Wiki数据下大约为20,Custom数据下大约为220)之后预测准确率不但不提高还有下降的趋势,说明选择合适的邻居数量能取得较好的预测准确率.另外,Wiki数据集下,3种方法的预测准确率在75%~87%之间, FM_KNN比KNN,AR_KNN方法的预测准确率平均值都要高,分别平均提升了1.51%和0.84%,最高分别提升了4.62%和1.43%;Custom数据集下,3种方法的预测准确率在65%~78%之间,FM_KNN比KNN,AR_KNN的预测准确率平均值要高,平均提升了3.85%和1.66%,最高提升了6%和2.58%.从而说明本文所提方法的有效性.
实验3. 不同数据密度下运行时间比较.
本文验证3种算法的运行时间,数据密度依次从10%以10%的步长逐步递增到90%,Wiki数据集每次计算重复实验10次取平均值,Custom数据每次交叉计算重复实验10次取平均值,2组数据下的实验结果分别如图10和图11所示.

Fig. 10 Comparison of execution time with different data density (Wiki data). (K=20)图10 不同数据密度的运行时间比较(Wiki数据) (K=20)

Fig. 11 Comparison of execution time with different data density (Custom data).(K=200)图11 不同数据密度的运行时间比较(Custom数据) (K=200)
从图10和图11可以看出,KNN所耗时间最少,FM_KNN次之,AR_KNN的所耗时间最长.对于Wiki数据,KNN,AR_KNN,FM_KNN方法在各种密度下的平均运行时间分别为25 ms,80.1 ms和26.4 ms;对于Custom数据,分别为84.6 ms,166 ms和89.5 ms.这是由于AR_KNN寻找频繁项集,然后根据频繁项集产生简单关联规则,需要不断地扫描历史软件描述数据;而FM_KNN虽然比KNN多了条件过滤步骤,但在条件过滤步骤中可能会补充一部分缺失特征值,这些值就不需要在后面的预测过程中进行预测,从而节省了时间,故FM_KNN和KNN算法的运行时间相差不大.
4 相关工作
为了帮助需求分析师、各利益相关者和客户有效获取待开发软件需求,已有许多学者提出了各种软件需求获取技术.金芝[2]提出了一种基于本体的需求获取方法,利用企业本体和领域本体构造软件需求模型,指导软件需求获取.舒风笛等人[3]提出一种用户主导的需求获取方法,为用户提供领域需求资产推荐和对多用户协同需求获取的建议.王波等人[4]针对问题驱动的需求获取方法提出了协同的问题分析与解决方法,并进行了实例研究.这些方法在软件开发需求过程中能有效指导软件需求获取,减少需求过程中的工作负担和错误风险.我们课题组的前期研究提出一种面向服务的软件需求建模框架RGPS[20],即利用角色、目标、流程和服务4个要素对服务需求进行建模,在体现领域共性需求的领域模型的基础上对个性化需求进行定制建模从而指导软件的需求获取.Nguyen等人[21]提出了面向特征的Web服务定制方法,认为特征建模技术能提取用户需求的可变性(即用户的个性化需求)以简化Web服务定制过程.
基于互联网的软件需要满足大量地理位置各异、类型不同的客户需求,这增加了需求获取的困难;同时,互联网上相似软件众多,这些具有大量相似功能的软件为软件需求获取提供了新的途径.为此,已有研究将推荐系统引入需求工程领域.Laurent等人[5]探索利用网上论坛的方式进行供应商主导的开源项目需求工程任务.Castro-Herrera等人[6-7]考虑使用推荐系统OPCI来支持推荐专家利益相关者和需求主题,并可选地支持管理实际的讨论需求主题线程.这些方法能够很好地指导需求组织者和分析师集思广益,寻找到新的软件需求,解决软件的需求获取问题,然而这些方法主要从软件项目利益相关者的角度出发,没有考虑利用互联网上大量存在的已有软件的领域知识.Hariri等人[8]使用数据挖掘(关联规则挖掘)算法抽取在线产品描述的公共特征以及这些特征之间的关联关系,然后使用KNN协同过滤算法为具有部分特征的新软件产品推荐其缺失的特征,该方法考虑了需求之间的关联关系,然而该方法的思路是求解当一个特征出现时另一个特征出现的概率,反映的是特征之间的共现关系,未能考虑特征之间的多选多、多选一和互斥等其他关系,可能造成待开发软件仍然难以拥有必需的初始特征作为特征推荐的基础,从而影响缺失特征的预测准确率.本文提出了一种基于特征模型和协同过滤的软件需求获取方法,通过考虑特征之间必选、可选、多选多、多选一、依赖和互斥等关系,为待开发软件提供更多的初始特征,然后利用KNN协同过滤推荐系统推荐缺失特征.
5 结束语
针对软件需求获取过程中的复杂性和准确性问题,借鉴本领域已有相似软件的需求描述来预测和辅助获取待开发软件的需求为缓解这一复杂问题提供了一种新的思路.为了提高预测准确率,本文提出了一种基于特征模型和协同过滤的软件需求获取方法,辅助软件需求组织者和分析师进行软件需求获取.本文主要工作如下:提出了软件需求获取方法框架;引入了特征模型,利用特征模型的特征类型和特征之间的关联关系为待开发软件补充部分缺失特征信息作为推荐的基础.利用与待开发软件同一领域内已有历史软件数据,结合KNN协同过滤推荐系统,提出了软件需求预测算法FM_KNN,为软件需求预测和辅助获取提供自动化或半自动化支持;分别在真实和仿真数据集上设计了具体实验对软件需求预测算法进行了验证分析.下一步研究的工作主要包括:由于本文方法只能为待开发软件推荐已有软件特征列表中的特征,对于已有列表之外的新特征的推荐问题是值得研究的内容之一;在软件需求推荐过程中不同特征的重要性问题等也是值得进一步考虑的因素.
[1]Tiwari S, Rathore S S, Gupta A. Selecting requirement elicitation techniques for software projects[C]Proc of the 6th CSI Int Conf on Software Engineering (CONSEG). Piscataway, NJ: IEEE, 2012: 1-10[2]Jin Zhi. Ontology-based requirements elicitation[J]. Chinese Journal of Computers, 2000, 23(5): 486-492 (in Chinese)(金芝. 基于本体的自动需求获取[J]. 计算机学报, 2000, 23(5): 486-492)[3]Shu Fengdi, Zhao Yuzhu, Wang Jizhe, et al. User-driven requirements elicitation method with the support of personalized domain knowledge [J], Journal of Computer Research and Development, 2007, 44(6): 1044-1052 (in Chinese)(舒风笛, 赵玉柱, 王继喆, 等. 个性化领域知识支持的用户主导需求获取方法[J]. 计算机研究与发展, 2007, 44(6): 1044-1052)[4]Wang Bo, Zhao Haiyan, Zhang Wei, et al. An approach to analyzing and resolving problems in the problem-driven requirements elicitation [J]. Journal of Computer Research and Development, 2013, 50(7): 1513-1523 (in Chinese)(王波, 赵海燕, 张伟, 等. 问题驱动的需求捕获中问题分析与解决技术研究[J]. 计算机研究与发展, 2013, 50(7): 1513-1523)[5]Laurent P, Cleland-Huang J. Lessons learned from open source projects for facilitating online requirements processes[G]Requirements Engineering: Foundation for Software Quality. Berlin: Springer, 2009: 240-255[6]Castro-Herrera C, Cleland-Huang J, Mobasher B. Enhancing stakeholder profiles to improve recommendations in online requirements elicitation[C]Proc of the 17th IEEE Int Conf on Requirements Engineering. Piscataway, NJ: IEEE, 2009: 37-46[7]Castro-Herrera C, Duan C, Cleland-Huang J, et al. Using data mining and recommender systems to facilitate large-scale, open, and inclusive requirements elicitation processes[C]Proc of the 16th IEEE Int Conf on Requirements Engineering. Piscataway, NJ: IEEE, 2008: 165-168[8]Hariri N, Castro-Herrera H, Mirakhorli M, et al. Supporting domain analysis through mining and recommending features from online product listings[J]. IEEE Trans on Software Engineering, 2013, 39(12): 1736-1752[9]Zhang Wei, Mei Hong. Feature-oriented software reuse technology—state of the art[J]. Chinese Science Bulletin, 2014, 59(1): 21-42 (in Chinese)(张伟, 梅宏. 面向特征的软件复用技术—发展与现状[J]. 科学通报, 2014, 59(1): 21-42) [10]Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions[J]. IEEE Trans on Knowledge and Data Engineering, 2005, 17(6): 734-749[11]Deshpande M, Karypis G. Item-based top-nrecommendation algorithms[J]. ACM Trans on Information Systems, 2004, 22(1): 143-177[12]Herlocker J L, Konstan J A, Terveen L G, et al. Evaluating collaborative filtering recommender systems[J]. ACM Trans on Information Systems, 2004, 22(1): 5-53[13]Acher M, Cleve A, Perrouin G, et al. On extracting feature models from product descriptions[C]Proc of the 6th Int Workshop on Variability Modeling of Software-Intensive Systems. New York: ACM, 2012: 45-54[14]Benavides D, Segura S, Ruiz-Cortés A. Automated analysis of feature models 20 years later: A literature review[J]. Information Systems, 2010, 35(6): 615-636[15]Dumitru H, Gibiec M, Hariri N, et al. On-demand feature recommendations derived from mining public product descriptions[C]Proc of the 33rd Int Conf on Software Engineering (ICSE). Piscataway, NJ: IEEE, 2011: 181-190[16]Pazzani M J, Billsus D. Content-based recommendation systems[G]The Adaptive Web. Berlin: Springer, 2007: 325-341[17]Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems[J]. Computer, 2009 (8): 30-37[18]Castro-Herrera C, Cleland-Huang J. Utilizing recommender systems to support software requirements elicitation[C]Proc of the 2nd Int Workshop on Recommendation Systems for Software Engineering. New York: ACM, 2010: 6-10[19]Zhang Jia, Wang Jian, Hung P, et al. Leveraging incrementally enriched domain knowledge to enhance service categorization[J]. International Journal of Web Services Research, 2012, 9(3): 43-66[20]He Keqing, Peng Rong, Liu Wei, et al. Networked Software[M]. Beijing: Science Press, 2008 (in Chinese)(何克清, 彭蓉, 刘玮, 等. 网络式软件[M]. 北京: 科学出版社, 2008) [21]Nguyen T, Colman A. A feature-oriented approach for Web service customization[C]Proc of the 8th IEEE Int Conf on Web Services (ICWS). Piscataway, NJ: IEEE, 2010: 393-400

Peng Zhenlian, born in 1979. PhD candidate. Member of China Computer Federation. His current research interests include software engineering and service computing.

Wang Jian, born in 1980. PhD and lecturer. Member of China Computer Federation. His current research interests include software engineering and service computing.

He Keqing, born in 1947. PhD, professor and PhD supervisor. Senior member of China Computer Federation. His current research interests include software engineering and service computing.

Tang Mingdong, born in 1978. PhD and associate professor. Member of China Computer Federation. His current research interests include computer network and service computing.
A Requirements Elicitation Approach Based on Feature Model and Collaborative Filtering
Peng Zhenlian1, 2, Wang Jian1, He Keqing1, and Tang Mingdong2
1(StateKeyLaboratoryofSoftwareEngineering(WuhanUniversity),Wuhan430072)2(SchoolofComputerScienceandEngineering,HunanUniversityofScienceandTechnology,Xiangtan,Hunan411201)
With the rapid development of Internet and Web service related technologies,developing software system on Internet is increasingly popular. Software development is a multi-knowledge-intensive process in which requirements elicitation plays a key role. Software systems deployed on Internet need to meet the needs of various kinds of customers and users who are geographically distributed,which increases the difficulties of software requirements elicitation. Meanwhile,more and more software systems that share similar functions are deployed on Internet,which provides a new way to elicit software requirements. Toward this end,recommender systems have been leveraged in the requirements elicitation to recommend missing features for software products by comparing the requirements descriptions of existing similar software systems. In order to improve the prediction accuracy of the recommended features of the software system,a requirements elicitation approach based on feature model andKNN (K-nearest neighbors) collaborative filtering recommendation system is proposed in this paper. An algorithm named FM_KNN is presented by utilizing constraint relations between features inKNN collaborative filtering recommendation system. Experiments conducted on a real data set and a simulated data set, by comparing the proposed FM_KNN with two existing methods, i.e.,KNN and an approach that combines association rule mining withKNN, show that the proposed approach can achieve higher precision.
requirement elicitation; feature model; collaborative filtering; recommender system; feature recommendation
2015-06-01;
2015-12-16
国家“九七三”重点基础研究发展计划基金项目(2014CB340404);国家自然科学基金项目(61373037,61202031,61572186,61562073)
王健(jianwang@whu.edu.cn)
TP311
This work was supported by the National Basic Research Program of China (973 Program)(2014CB340404) and the National Natural Science Foundation of China (61373037,61202031,61572186,61562073).
