一种适用于异构存储系统的缓存管理算法
2016-10-13李勇王冉冯丹施展
李 勇 王 冉 冯 丹 施 展
1(中国电子科技集团公司第二十八研究所 南京 210007)2 (武汉光电国家实验室(筹)(华中科技大学) 武汉 430074)
一种适用于异构存储系统的缓存管理算法
李勇1王冉1冯丹2施展2
1(中国电子科技集团公司第二十八研究所南京210007)2(武汉光电国家实验室(筹)(华中科技大学)武汉430074)
(liyong01@hust.edu.cn)
当前数据中心广泛采用虚拟化、混合存储等技术以满足不断增长的存储容量和性能需求,这使得存储系统异构性变得越来越普遍.异构存储系统的一个典型问题是由于设备负载和服务能力不匹配,使得存储系统中广泛使用的条带等并行访问技术难以充分发挥作用,导致性能降低.针对这一问题,提出了一种基于负载特征识别和访问性能预测的缓存分配算法(access-pattern aware and performance prediction-based cache allocation algorithm, Caper),通过缓存分配来调节不同存储设备之间的IO负载分布,使得存储设备上的负载和其本身服务能力相匹配,从而减轻甚至消除异构存储系统中的性能瓶颈.实验结果表明,Caper算法能够有效提高异构存储系统的性能,在混合负载访问下,比Chakraborty算法平均提高了约26.1%,比Forney算法平均提高了约28.1%,比Clock算法平均提高了约30.3%,比添加预取功能的Chakraborty算法和Forney算法分别平均提高了约7.7%和17.4%.
异构;存储系统;缓存;预取;固态盘;性能预测
当前存储系统广泛存在存储设备异构性,主要有2个原因:1)新的存储设备会因为扩容、替换故障设备等原因不断加入存储系统,随着电子技术的快速发展,新存储设备往往比旧存储设备具有更高的性能.同时,因为存储空间的碎片化、机械结构等原因,磁盘的性能随着使用时间而不断降低.2)新型存储设备不断出现,比如当前存储系统已经广泛使用固态盘,以固态盘为代表的新型存储设备在性能等诸多方面和磁盘存在较大的差异.另外,随着存储系统规模的扩大,通过网络连接存储设备越来越普遍,比如存储区域网络(storage area network, SAN)[1],存储设备的性能因为网络延迟变得更加不稳定.
存储系统一般使用条带等技术将数据分布到多个存储设备中,以提高数据访问的并行性.在并行存储系统中(如磁盘阵列),一个较大的IO请求通常会被分成多个子请求,并同时访问多个存储设备.但是,在异构存储系统中,存储系统的并行访问技术存在着性能瓶颈问题.在异构存储系统中,IO请求在不同存储设备的访问延迟不一样,性能较好的存储设备的访问延迟要小于性能较差的存储设备的访问延迟,因此,性能较差的存储设备往往决定IO请求的最终性能.下面通过一个简单的例子进一步阐释这个问题,在这个例子中,同构和异构磁盘阵列都由4块磁盘组成,如图1所示.IO请求被分成4个子IO请求,并分别访问阵列中的4个磁盘.在同构磁盘阵列中,4个磁盘的访问延迟是一样的,都是5 ms,因此,IO请求在同构磁盘阵列中的访问延迟是5 ms.在异构磁盘阵列中,3个磁盘的访问延迟是5 ms,另外一个磁盘的访问延迟是10 ms.因为不同磁盘的访问延迟不一样,所以异构磁盘阵列必须等访问延迟为10 ms的磁盘完成IO操作才能够完成整个IO请求,因此,IO请求在异构磁盘阵列中的访问延迟是10 ms,大于同构磁盘阵列的访问延迟.从这个例子中可以发现:在异构存储系统中,性能最差的存储设备是系统的性能瓶颈.

Fig. 1 Comparison of access delay.图1 访问延迟对比
针对异构存储系统的设备负载和其服务能力不匹配所导致的性能降低问题,本文提出了一种基于负载特征识别和访问性能预测的缓存管理算法(access-pattern aware and performance prediction-based cache allocation algorithm).Caper算法的主要思想是通过优化缓存调度来平衡IO请求在异构存储设备上的性能差异,减少甚至消除性能最差的存储设备在异构存储系统中的性能瓶颈问题.Caper算法采用缓存分区策略,为了合理设置缓存分区的大小,Caper算法用CART(classification and regression trees)模型预测IO请求在存储设备上的性能,并结合性能预测结果分析不同访问特征负载的缓存需求.此外,Caper算法还改进时钟缓存替换算法以进一步提高缓存效益(缓存效益是指单位缓存增减对性能的影响).实验结果表明,和Clock算法[2]、Forney算法[3]以及Chakraborty算法[4]等相比,Caper算法整体上有较明显的性能提升.
1 相关工作
缓存替换算法主要的出发点是利用数据访问的局部性原理提高存储系统性能.自从计算机体系结构采用层次结构以来,缓存替换算法一直都是研究的热点领域.这里主要对当前的热点算法进行介绍,并侧重异构存储系统中的缓存算法研究.
有些研究利用应用隐示实现进一步提高缓存预取的准确率[5].也有研究利用数据热度提高缓存命中率,罗德岛大学的杨等人[6]提出了一种基于热点的LPU算法,将访问频率扩展到访问热度,优先保留与其他缓存块相似度高同时访问频率也高的缓存块,从而避免虚拟机或者云计算中的热点数据的重复读取.也有研究者利用缓存解决系统的某一方面问题,比如中国人民大学的柴等人[7]提出了PLC-Cache缓存算法,在重复数据删除的存储系统中,延长了固态盘的使用寿命,同时提高了性能.
也有很多工作研究异构存储系统中的缓存算法,比如威斯康星大学麦迪逊分校的Forney等人[3]根据累积延迟周期性调整缓存逻辑分区大小,实现不同设备之间的性能平衡.Chakraborty等人[4]则进一步改进Forney算法,通过一种基于有向无环图的方法实现缓存逻辑分区的实时分配.其他的还比如ARC-H[8],hStorage-DB[9]等算法都是通过缓存提高异构存储系统的性能.
2 问题分析
下面分析存储设备异构性对性能的影响,以及缓存在其中的作用.首先是没有缓存时的情况,也就是说IO请求不经过缓存直接访问存储设备,如图2(a)所示.为方便描述,这里有n个存储设备,分别标识为{D1,D2,…,Dn},其访问延迟分别为{T1,T2,…,Tn}.IO请求R在各个存储设备上的子请求分别标识为{R1,R2,…,Rn}.性能最差的存储设备将决定IO请求的访问延迟T,可以用式(1)表示:

(1)
假设Tn为最大的访问延迟,那么在异构存储系统中,大部分IO请求的访问延迟都是Tn.
(2)
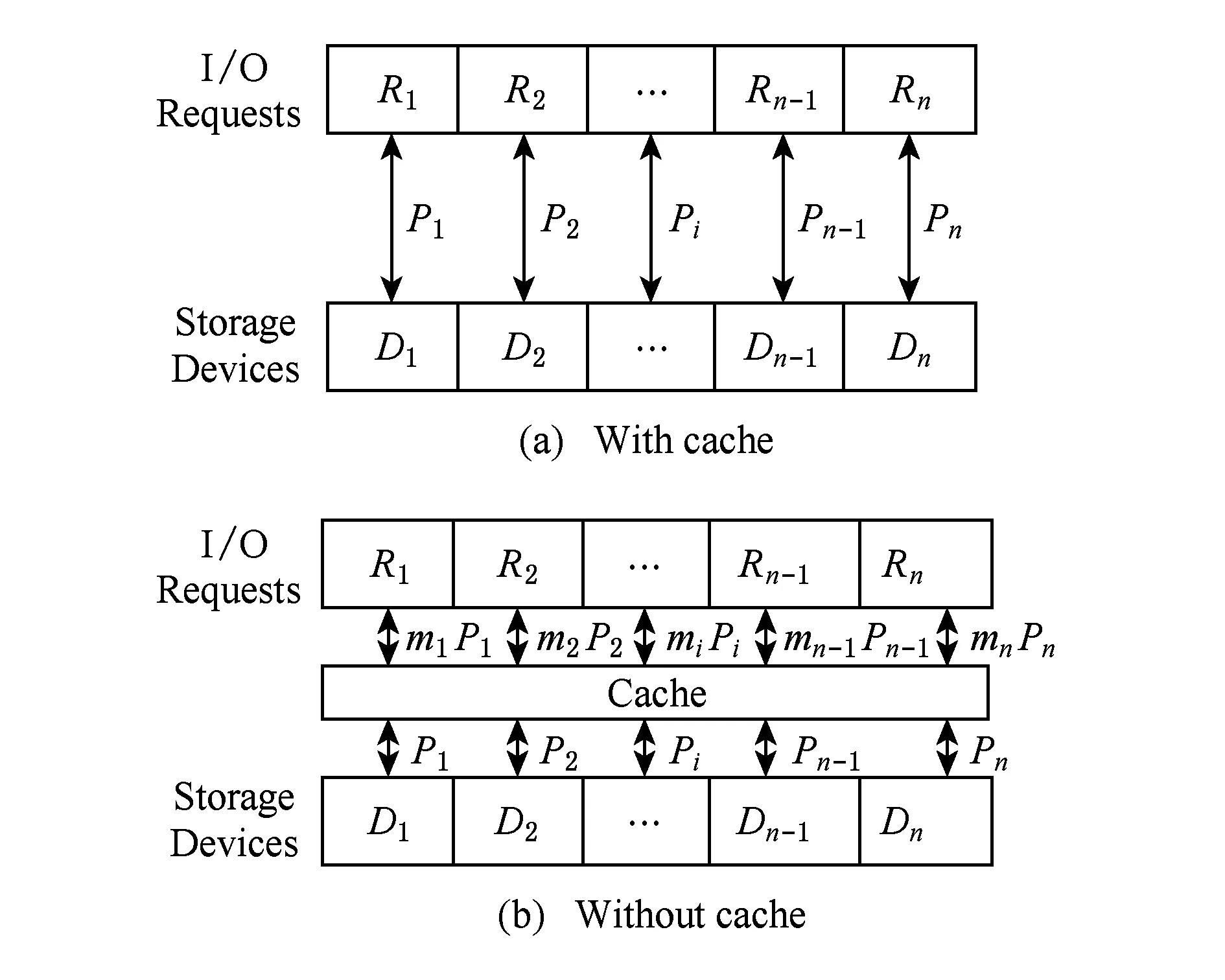
Fig. 2 The utility of cache for access performance.图2 缓存对访问性能的作用
3 算法描述

Fig. 3 The architeture of Caper algorithm.图3 Caper算法结构
Caper算法使用CART模型[10]建立存储设备的性能预测模型.CART是一种被广泛使用的机器学习方法,可用于性能预测,和其他机器学习方法一样,CART首先需要在训练阶段建立性能预测模型.基于CART的性能预测模型可以形象地表示为一棵决策树,如图4所示.Caper算法使用4个属性描述一个IO请求,分别是逻辑地址Li、请求大小Si、读写操作类型Ti,以及和上一个请求的逻辑地址距离Bi.因此,每个IO请求可以表示为一个4元组Li,Si,Ti,Bi.Caper算法的性能预测模型使用IO请求的访问延迟表示最终的性能.

Fig. 4 Example of CART tree.图4 CART树的例子
CART采用自顶向下递归的分治方法构造决策树,假设训练集为Z,根节点的判断条件是Rj≤s,其中s是选中的分裂点.根据训练集中的元素是否满足判断条件,将其进一步划分为2个子集合:Z1(j;s)={R|Rj≤s}和Z2(j;s)={R|Rj>s}.然后分别在新分裂的2个子集合Z1和Z2中采用同样的训练方法,并进一步分裂集合.决策树的层次随着分裂点的增加而不断增长,直到满足停止条件,停止条件一般为决策树的大小或设定的预测误差阈值.最后,为每个叶子节点的子集合中的元素计算访问延迟平均值,并作为该叶子节点的预测性能,文献[10]指出平均值的预测误差最小.
和传统的性能预测模型相比,基于机器学习的CART性能预测模型具有开销更低、适应性更强、构建更方便等优点.传统方法通常在存储系统或存储设备的内部结构基础上基于某种数学方法建立性能预测模型,如排队论.但是这些方法往往受限于存储厂商的信息公开程度,而且内部结构也会随着存储系统或设备的更新而不断更新,因此,这种方法往往会存在一定的滞后性.相反,基于机器学习的CART模型是一种黑盒方法,不需要存储系统或存储设备的内部结构就可以建立性能预测模型,而且对于新系统或新设备,也只需要更新训练集就能够更新模型.此外,CART模型还充分考虑了应用负载特征对性能的影响,从而提高预测准确率.
3.2缓存需求分析
要想通过缓存分配减少性能最差存储设备对整体性能的影响,首先必须要知道缓存大小和性能之间的关系,一方面方便计算提高瓶颈存储设备性能所需的缓存数量,另一方面可以防止其他存储设备因缺少缓存而成为新的性能瓶颈.Caper算法将应用负载分为3种不同的访问特征,并分别分析在这3种负载访问下缓存大小对IO请求访问性能的影响.
3.2.1随机访问负载
对于随机访问的负载,一般难以捕获其访问规律,Caper算法使用基于概率的方法分析缓存大小对随机访问负载的影响.不失一般性,假设在随机访问负载中不同数据被访问的概率相同并且相互独立,那么随机访问负载的缓存命中率跟访问区域和缓存大小相关.负载的访问区域是指访问请求序列中最小逻辑地址和最大逻辑地址之间的逻辑地址范围,用Z表示随机访问负载的访问区域.负载的访问区域越大,就表示数据被重复访问的概率越小,缓存命中率也会越低;相反,负载的访问区域越小,就表示数据被重复访问的概率越大,缓存命中率也会越高.当缓存大小为C时,随机访问负载的平均缓存命中率h≈CZ,那么一个存储设备的平均访问延迟Tavg为
(3)
其中,Tcache是IO请求访问缓存的延迟,Tdisk是IO请求访问存储设备的延迟.因为缓存的访问延迟通常远低于存储设备的访问延迟,为了简化分析,忽略缓存访问延迟对性能的影响,那么存储设备的平均访问延迟可以简化为Tavg=(1-h)×Tdisk.将随机访问负载的缓存命中率表达式h=CZ代入式(3),就可以获得存储设备访问延迟相等时的缓存分配方案,如式(4)所示:
(4)
其中,n是存储设备的数量,Ci是第i个存储设备分配的缓存大小,C是整个缓存的大小.
3.2.2顺序访问负载

Fig. 5 Example of prefetching operation.图5 预取操作示例
(5)
其中,PR是IO请求的平均长度,每个存储设备的预取缓存需求为Ci,Ci=Di+PR.在顺序访问负载中,为使访问延迟相同,存储设备之间的缓存分配如下:
(6)

在实际运行中,预取长度一般不会在一开始就被设置很大,而是随着负载顺序性增强而不断增加,因此,存储设备中的缓存分配也可以看作是对预取长度最大值的一个限制条件.
3.2.3循环负载
在循环负载中,顺序访问序列每隔一个循环周期重复出现,将循环负载中顺序访问序列的长度标记为Sloop.在分析缓存需求时,将循环负载分为顺序访问部分和随机访问部分,并分别参照前面顺序访问负载和随机访问负载的分析方法.在分析循环负载的顺序访问部分负载时,将缓存大小分2种情况:缓存充足和缓存不足.和顺序访问负载不同,循环访问负载中发生预取缓存缺失的概率非常小,因为顺序访问部分的数据每隔一个循环周期重复出现.如果缓存充足,那么顺序访问部分的请求数据可以全部预取在缓存中,因此,顺序访问部分负载的平均访问延迟为
(7)

(8)
对于循环访问负载中的随机访问部分,采用和随机负载类似的分析方法.不同的是,由于循环访问的负载特征,随机访问缓存的效益不如顺序访问缓存.因此,在缓存分配时,总是优先保证顺序访问部分的缓存需求,随机访问部分负载的平均延迟为
(9)
3.3缓存替换策略
Caper算法还改进时钟缓存替换策略,使其更加适应不同类型的负载混合访问.和时钟算法一样,逻辑分区中的缓存块被组织成一个环形链表,有一个指针执行最老的缓存块.和时钟算法不同的是,Caper算法用计数器代替缓存块的状态标志位,并且根据负载类型为计数器设置不同的初值.如果是随机访问负载,那么这类缓存的计数器设置和时钟算法一样,都是为1;如果是顺序访问负载,那么这类缓存的计数器设置为0,因为顺序访问的缓存块在短时间内被再次访问的概率非常低.如果是循环访问负载,那么这部分缓存分2类处理.其中随机部分和随机负载一样,其计数器初值都设置为1;顺序访问部分缓存的计数器设置为p,p是循环负载的循环周期长度.因为这部分数据每隔一个循环周期就被重复访问,所以缓存命中率较高.当执行缓存替换时,Caper算法从指针指向的缓存块开始查找.如果该缓存块的计数器大于0,那么将该计数器减1,然后查找下一个缓存块,直到发现一个缓存块的计数器为0才停止查找,并替换掉该缓存块,然后将指针指向下一个未查找的缓存块.因此,在改进的时钟缓存替换策略中,循环访问负载的顺序访问部分缓存块被赋予较高的优先级,并且循环周期长度越长其在缓存中的停留时间也越久,以保证这些缓存块能够在下次访问中命中;随机访问负载的缓存块优先级次之,但是在缓存中的停留时间要远少于循环访问负载,这是因为循环访问负载的重复访问概率要远远高于随机访问负载;而顺序访问负载的缓存块优先级最低,这是因为顺序访问负载的重复访问概率基本为0,因此,较早释放能够提高缓存整体效益.图6是缓存替换策略示意图,其中Sran表示随机访问,Sseq表示顺序访问,Sloop表示循环访问,括号中的数字表示缓存块计数器的初值.

Fig. 6 Replacement policy of Caper algorithm.图6 Caper算法替换策略
3.4算法开销分析
Caper算法的开销主要包括2个部分:1)将Clock算法的状态标志位扩展为n位的计数器,在算法中n=4 b.一般缓存以4 KB为单位,因此这部分的存储空间开销大约为0.012%,影响非常小.2)缓存逻辑分区的数据结构,和缓存数量相比,与存储设备一一对应的逻辑分区数量非常少,因此,这部分的存储空间开销可以忽略不计.
4 性能测试与分析
4.1实验环境
在缓存仿真器DULO[11]中实现Caper算法,并且和存储设备仿真器Disksim[12]组成完整的存储系统仿真.DULO是韦恩州立大学(WSU)的Zhu等人[13]开发的缓存仿真器,并广泛使用在缓存算法研究中.Disksim是卡内基梅隆大学(CMU)并行数据实验室(PDL)开发的磁盘仿真器,以高精度、配置灵活而著称,并且被许多研究选作为实验平台[14],通过加入微软硅谷研究所Agrawal等人[15]开发的SSD模块,Disksim也可以仿真固态盘.实验选择希捷公司的Cheetah9LP和Cheetah15k.5磁盘作为存储设备,Cheetah9LP磁盘性能较差,Cheetah15k.5磁盘性能较好,具体配置如表1所示.此外,实验的存储设备还包括一款由8个4 GB大小的NAND闪存芯片组成的SLC类型固态盘,具体配置如表2所示,实验用4块存储设备组成一个RAID-0.为了测试算法在不同条带长度下的性能,实验配置了5种不同条带长度的RAID-0:4 KB,8 KB,16 KB,32 KB,64 KB.实验模拟了2组不同的异构磁盘阵列: 一组由1块Cheetah9LP磁盘和3块Cheetah15k.5磁盘组成,其中Cheetah9LP磁盘模拟性能较差的存储设备,Cheetah15k.5磁盘模拟性能较好的存储设备.另一组由1块Cheetah15k.5磁盘和3块固态盘组成,其中Cheetah15k.5磁盘模拟性能较差的存储设备,固态盘模拟性能较好的存储设备.实验的缓存大小为64~512 MB不等,约为存储设备容量的0.2%~1.4%.实验中使用的应用负载包括Financial1,Web-Search1,TPC-C,Cscope,Gcc,Mplayer,Glimpse,File-Server.

Table 1 Parameters of Disks

Table 2 Parameters of SSD
为了测试算法在不同缓存大小时的性能,在5种不同缓存大小下运行实验:64 MB,128 MB,256 MB,384 MB,512 MB.实验选择Clock缓存替换算法、Forney缓存替换算法和Chakraborty缓存替换算法,以及添加预取功能的Forney-prefetch缓存替换算法和Chakraborty-prefetch缓存替换算法作为Caper算法的对比算法.
4.2不同负载访问时的性能
为了测试算法在不同负载访问时的性能,将负载分为2组并分别测试.其中随机访问负载由Financial1,Web-Search1,TPC-C组成,顺序访问负载由Cscope,Gcc,Mplayer组成.算法运行在由不同性能磁盘组成的异构磁盘阵列.
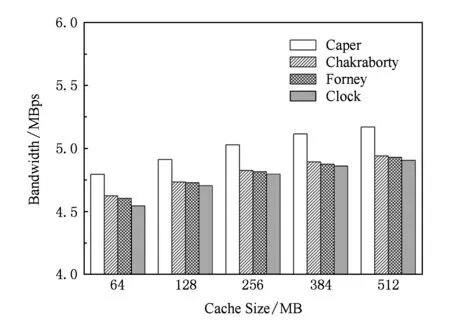
Fig. 7 Performance comparison under mixing of different performance disks.图7 不同性能磁盘混合时的性能对比
图7显示算法在随机访问负载下的性能,因为预取算法主要针对顺序访问负载设计,所以对于随机访问负载只比较Caper算法、Chakraborty算法、Forney算法和Clock算法.如图7所示,Caper算法的平均带宽约为5.01 MBps(最高5.17 MBps),分别超过Chakraborty算法平均约4.17%(最大4.65%)、Forney算法平均约4.46%(最大4.93%)和Clock算法平均约5.08%(最大5.50%).阻碍性能的主要原因是不同设备的访问延迟不一致从而引入额外的等待延迟,导致增加数据在缓存中的停留时间,从而降低缓存命中率.特别是当缓存较小时,这种现象更加明显.从实验结果也证明这一点,在缓存大小只有64 MB时Caper算法的性能提升幅度最大.
图8显示算法在顺序访问负载下的性能,和随机访问负载相反,只有支持预取操作的缓存算法才能够在顺序访问负载中受益,因此对于顺序访问负载只比较Caper算法、Chakraborty-prefetch算法,和Forney-prefetch算法.从图8可以发现,当缓存较小时,Caper算法的性能略低于Chakraborty-prefetch算法和Forney-prefetch算法,分别约低1.2%和1.22%.这主要是因为为了平衡异构存储设备之间的性能差异,性能较差的存储设备在缓存分配时具有较高的优先级,但是在缓存较小时,过长的预取缓存容易在未被访问之前就被淘汰出缓存,从而造成性能降低.当缓存逐渐增加时,Caper算法的效果逐渐显现,这是因为当缓存变大后,预取缓存的停留时间也会增加,特别是性能较差的存储设备的预取缓存更为明显,这无疑显著减少对其进行IO操作,从而获得较大的性能提升.
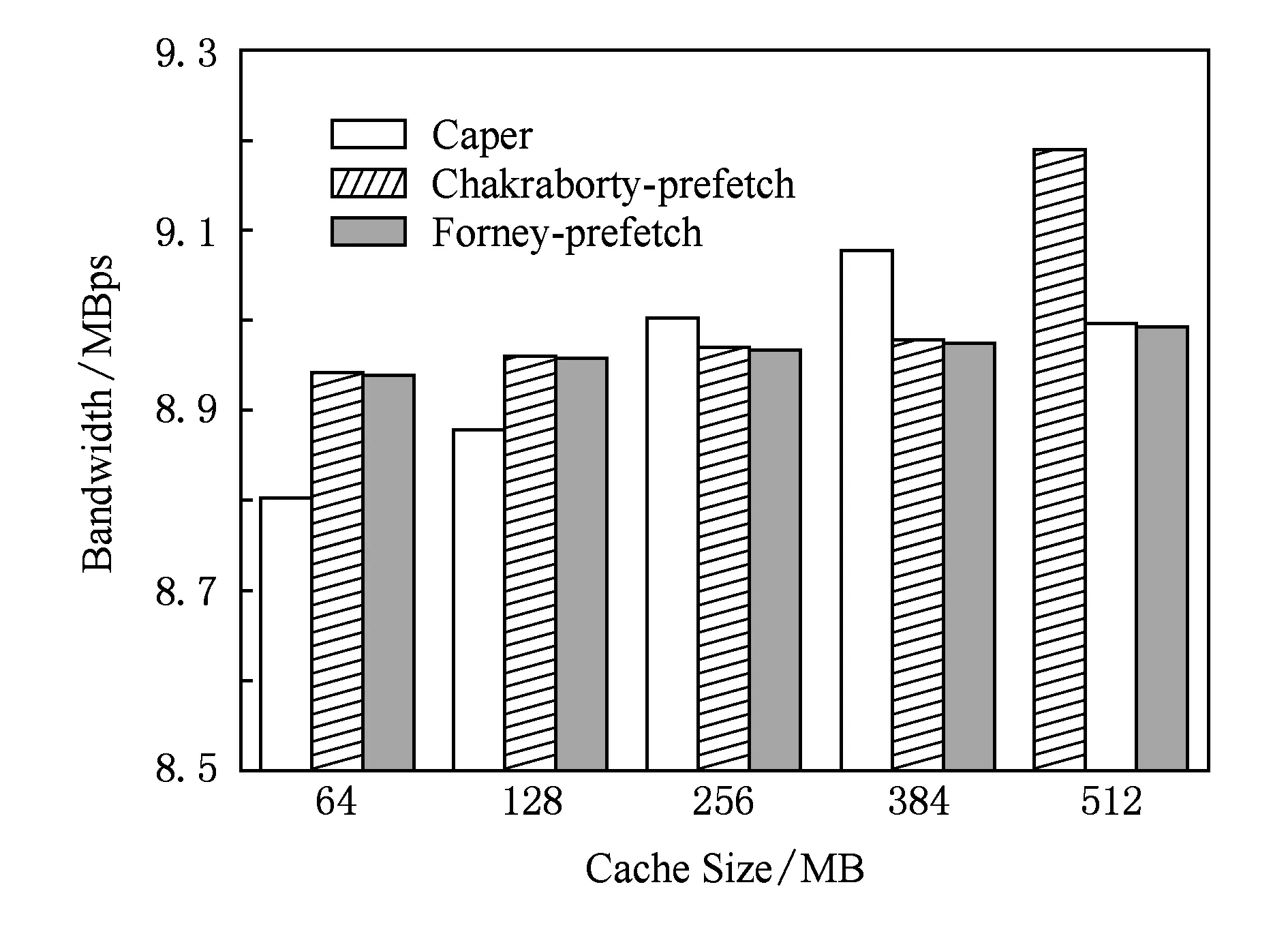
Fig. 8 Performance comparison under mixing of disk and SSD.图8 磁盘和固态盘混合时的性能对比
4.3测试不同缓存大小时的性能
图9和图10显示Caper算法、Chakraborty-prefetch算法、Forney-prefetch算法、Chakraborty算法、Forney算法和Clock算法随缓存大小变化的性能,其中图9是6种算法在不同性能磁盘混合的异构磁盘阵列中的性能,图10是6种算法在磁盘与固态盘混合的异构磁盘阵列中的性能.如图9和图10所示,Caper算法在大部分的情况下性能都要好于其他5个对比算法.在不同性能磁盘混合的阵列中,Caper算法的平均带宽约为8.01 MBps(最高8.79 MBps),分别超过Chakraborty-prefetch算法平均约9.08%(最大17.1%)、Forney-prefetch算法平均约13.6%(最大19.7%)、Chakraborty算法平均约31.0%(最大44.1%)、Forney算法平均约33.7%(最大47.3%)和Clock算法平均约36.1%(最大47.4%).在磁盘和固态盘混合的阵列中,Caper算法的平均带宽约为50.3 MBps(最大54.4 MBps),分别超过Chakraborty-prefetch算法平均约3.94%(最大6.99%)、Forney-prefetch算法平均约6.35%(最大11.6%)、Chakraborty算法平均约21.2%(最大28.8%)、Forney算法平均约22.5%(最大30.3%)和Clock算法平均约24.4%(最大30.8%).Caper算法、Chakraborty-prefetch和Forney-prefetch算法的性能要比其他3个算法高出不少,这是因为这3个算法同时对随机访问负载和顺序访问负载进行优化,从而能够更适应不同特征的负载混合访问.与Chakraborty-prefetch和Forney-prefetch算法相比,Caper算法又针对异构存储系统的特征进行优化,减少性能最差存储设备对系统的影响,从而提高整体性能,特别是当缓存较为紧张的情况下提升更为明显.
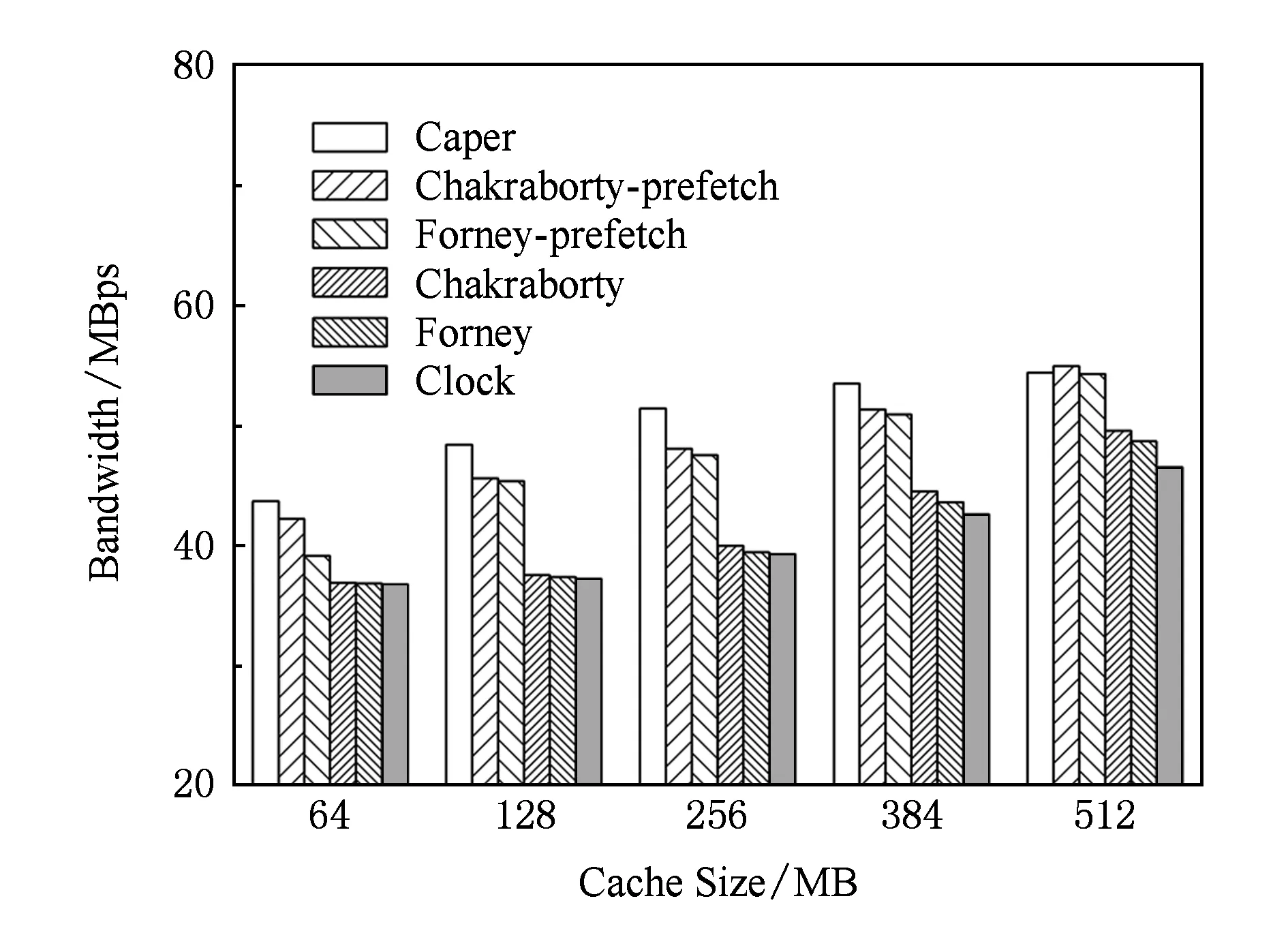
Fig. 10 Performance comparison under mixing of disk and SSD.图10 磁盘和固态盘混合时的性能对比
当缓存从64 MB增加到128 MB时,Caper算法的性能提高幅度比较明显.在不同性能磁盘混合的阵列中,Caper算法的性能提高幅度达到最大值1.16 MBps,比缓存大小为64 MB时的性能提高了17.7%.在磁盘和固态盘混合的阵列中,Caper算法的性能提高幅度达到最大值4.69 MBps,比缓存大小为64 MB时的性能提高了10.7%.当缓存大小从128 MB增加到512 MB时,Caper算法的性能提高幅度逐渐减少,这主要原因是:当缓存较小时,较长的预取缓存容易在未被访问之前就被淘汰出缓存,导致缓存效益较低;当缓存增加时,预取缓存就会大幅度提高;当缓存增加到一定程度,就会逐渐趋于饱和,性能提升幅度逐渐降低.
4.4不同条带长度时的性能
图11和图12显示Caper算法、Chakraborty-prefetch算法、Forney-prefetch算法、Chakraborty算法、Forney算法和Clock算法随条带长度变化的带宽分布,其中图11是6种算法在不同性能磁盘混合的异构磁盘阵列中的性能,图12是6种算法在磁盘与固态盘混合的异构磁盘阵列中的性能.

Fig. 11 Performance comparison under mixing of different performance disks.图11 不同性能磁盘混合时的性能对比

Fig. 12 Performance comparison under mixing of disk and SSD.图12 磁盘和固态盘混合时的性能对比
如图11和图12所示,Caper算法的性能在大部分情况下要好于其他5种对比算法.Caper算法在不同性能磁盘混合阵列中的平均带宽约为7.97 MBps(最高8.43 MBps),分别超过Chakraborty-prefetch算法平均约15.3%(最大17.1%)、Forney-prefetch算法平均约17.3%(最大19.7%)、Chakraborty算法平均约40.5%(最大44.0%)、Forney算法平均约43.6%(最大47.3%)和Clock算法平均约43.8%(最大47.5%).在磁盘和固态盘混合的阵列中,Caper算法的平均带宽约为46.8 MBps(最大57.3 MBps),分别超过Chakraborty-prefetch算法平均约3.76%(最大7.92%)、Forney-prefetch算法平均约4.71%(最大9.36%)、Chakraborty算法平均约24.3%(最大34.0%)、Forney算法平均约25.8%(最大35.9%)和Clock算法平均约26.2%(最大36.6%).
和其他算法相比,Caper算法的性能在不同条带长度下虽然也有提升,但是提升幅度明显较低,甚至在条带大小为4 KB时,Caper算法的性能略低于Chakraborty-prefetch算法.和4.3节的实验类似,和其他算法相比,Caper算法的性能提升主要来自于减少性能最差存储设备对系统的影响.不同条带的长度主要影响IO请求的并行性,但是相对于缓存的访问性能,磁盘的访问性能要低很多,所以算法随条带增加的性能提升比较小.特别是当条带较小时,还会使得存储设备上的子请求大小过小而降低读写的顺序性,从而降低性能.
从图11、图12可以发现当条带长度从4 KB增加到8 KB时,Caper算法的性能提高幅度都是最显著的.以不同性能磁盘混合的阵列为例,Caper算法在条带大小为8 KB时的性能比条带大小为4 KB时的性能提高了10.7%.在磁盘和固态盘混合的阵列中,Caper算法在条带大小为8 KB时的性能比条带大小为4 KB时的性能提高了32.6%.在条带长度从8 KB增加到64 KB的过程中,虽然性能也有提高,但是性能提高幅度都比条带长度从4 KB增加到8 KB时的性能提高幅度小.在不同性能磁盘混合的阵列中,也是类似的结果.这主要是因为在缓存算法中一般以4 KB为单位进行数据读写,因此,当条带大小只有4 KB时,单个IO请求同时访问多个存储设备的现象就比较频繁.在异构存储系统中,因为IO请求在不同存储设备上的访问延迟不一样,从而引入等待延迟.当条带大小只要4 KB时,这种因为存储系统异构性而导致的等待延迟则非常严重,性能降低也比较明显,因此,Caper算法能够取得较大的性能提升.随着条带长度的增加,一个IO请求同时访问多个存储设备的现象将会逐渐减少,从而,Caper算法的性能提高幅度也逐渐减少.但是,因为Caper算法的缓存分配和替换策略可以减少IO请求在性能较差存储设备上发生缓存缺失的概率,所以随着条带长度的增加,Caper算法的性能仍然能够有所提高.
5 结束语
本文针对异构存储系统设计了一种缓存管理算法.Caper算法主要的出发点是解决异构存储系统中因设备负载和其服务能力不匹配造成的性能降低问题.Caper算法建立CART模型,并预测不同IO请求在存储设备上的访问性能;然后分析不同访问特征负载的缓存需求,通过缓存的过滤作用,减少访问性能较差的存储设备上的负载,从而提高整体性能.同时,Caper算法利用不同访问特征负载之间缓存效益不同这一负载特性,改进时钟缓存替换算法,进一步提高缓存效益.实验测试结果表明,Caper算法能够有效提高异构存储系统的性能,其性能比Chakraborty算法、Forney算法和Clock算法有较大的提高,对添加预取功能的Chakraborty算法、Forney算法也有不少的提高.
[1]Brinkmann A, Salzwedel K, Scheideler C. Efficient, distributed data placement strategies for storage area networks[C]Proc of the 12th Annual ACM Symp on Parallel Algorithms and Architectures. New York: ACM, 2000: 119-128[2]Tanenbaum A S, Woodhull A S. Operating Systems Design and Implementation[M]. Translated by Wang Junhua. 3rd ed. Beijing: Publishing House of Electronics Industry, 2007 (in Chinese)(Tanenbaum A S, Woodhull A S. 操作系统设计与实现[M]. 王俊华, 译. 3版. 北京: 电子工业出版社, 2007)[3]Forney B C, Arpaci-Dusseau A C, Arpaci-Dusseau R H. Storage-aware caching: Revisiting caching for heterogeneous storage systems[C]Proc of the 1st USENIX Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2002: 61-74[4]Chakraborty A, Singh A. Cost-aware caching schemes in heterogeneous storage systems[J]. The Journal of Supercomputing, 2011, 56(1): 56-78[5]Wu Chentao, He Xubin, Cao Qiang, et al. Hint-K: An efficient multilevel cache usingk-step hints[J]. IEEE Trans on Parallel and Distribution Systems, 2014, 25(3): 653-662[6]Ren J, Yang Q. A new buffer cache design exploiting both temporal and content localities[C]Proc of the 30th IEEE Int Conf on Distributed Computing Systems. Piscataway, NJ: IEEE, 2010: 273-282[7]Liu J, Chai Y, Qin X, et al. PLC-Cache: Endurable SSD cache for deduplication-based primary storage[C]Proc of the 30th Int Conf on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2014: 1-12[8]Kim Y J, Kim J. ARC-H: Adaptive replacement cache management for heterogeneous storage devices[J]. Journal of Systems Architecture, 2012, 58(2): 86-97[9]Luo T, Lee R, Mesnier M, et al. hStorage-DB: Heterogeneity-aware data management to exploit the full capability of hybrid storage systems[J]. Proceedings of the VLDB Endowment, 2012, 5(10): 1076-1087[10]Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction[M]. 2nd ed. London: Springer, 2009: 295-335[11]Jiang S, Ding X, Chen F, et al. DULO: An effective buffer cache management scheme to exploit both temporal and spatial locality[C]Proc of the 4th Conf on File and Storage Technologies. Berkeley, CA: USENIX Association, 2005: 101-114[12]Bucy J S, Schindler J, Schlosser S W, et al. The disksim simulation environment version 4.0 reference manual, cmu-pdl-08-101[R]. Pittsburgh, PA: Parallel Data Laboratory, 2008[13]Zhu Y, Jiang H. RACE: A robust adaptive caching strategy for buffer cache[J]. IEEE Trans on Computers, 2008, 57(1): 25-40[14]Wu Suzhen, Chen Xiaoxi, Mao Bo. GC-RAIS: Garbage collection aware and redundant array of independent SSDs[J]. Journal of Computer Research and Development, 2013, 50(1): 60-68 (in Chinese)(吴素贞, 陈晓熹, 毛波. GC-RAIS:一种基于垃圾回收感知的固态盘阵列[J]. 计算机研究与发展, 2013, 50(1): 60-68)[15]Agrawal N, Prabhakaran V, Wobber T, et al. Design tradeoffs for SSD performance[C]Proc of USENIX Annual Technical Conf. Berkeley, CA: USENIX Association, 2008: 57-70

Li Yong, born in 1986. Received his PhD degree from Huazhong University of Science and Technology in 2014. Engineer in the 28th Research Institute of China Electronics Technology Group Corporation. His main research interests include cloud computing, massive storage system and cache algorithm.

Wang Ran, born in 1983. Engineer in the 28th Research Institute of China Electronics Technology Group Corporation. His main research interests include cloud computing, information system.

Feng Dan, born in 1971. Received her PhD degree from Huazhong University of Science and Technology. Professor and PhD supervisor. Senior member of China Computer Federation. Her main research interests include computer architecture, massive storage systems, and parallel file systems.

Shi Zhan, born in 1976. Received his PhD degree from Huazhong University of Science and Technology. Associate research fellow. His main research interests include storage management and big data.
A Cache Management Algorithm for the Heterogeneous Storage Systems
Li Yong1, Wang Ran1, Feng Dan2, and Shi Zhan2
1(The28thResearchInstituteofChinaElectronicsTechnologyGroupCorporation,Nanjing210007)2(WuhanNationalLaboratoryforOptoelectronics(HuazhongUniversityofScienceandTechnology),Wuhan430074)
The scale of storage system is becoming larger with the rapid increase of the amount of produced data. Along with the development of computer technologies, such as cloud computing, cloud storage and big data, higher requirements are put forward to storage systems: higher capacity, higher performance and higher reliability. In order to satisfy the increasing requirement of capacity and performance, modern data center widely adopts multi technologies to implement the dynamic increasing of storage and performance, such as virtualization, hybrid storage and so on, which makes the storage systems trend more and more heterogeneous. The heterogeneous storage system introduces multiple new problems, of which one key problem is the degradation of performance as load unbalance. That’s because the difference of capacity and performance between heterogeneous storage devices make the parallelism technologies hardly to obtain high performance, such as RAID, Erasure code. For this problem, we propose a caching algorithm based on performance prediction and identification of workload characteristic, named Caper (access-pattern aware and performance prediction-based cache allocation algorithm). The main idea of Caper algorithm is to allocate the load according to the capacity of the storage devices, which aims to alleviate the load unbalance or eliminate the performance bottleneck in the heterogeneous storage systems. The Caper algorithm is composed of three parts: prediction of performance for IO request, analysis of caching requirement for storage device, and caching replacement policy. The algorithm also classifies the application workload into three types: random access, sequential access, and looping access. In order to ensure high caching utility, the algorithm adjusts the size of logic cache partition based on the analysis of the caching requirement. Besides, in order to adapt to the heterogeneous storage system, the Caper algorithm improves the Clock cache replacement algorithm. The experimental results also show that the Caper algorithm can significantly improve the performance about 26.1% compared with Charkraborty algorithm under mixed workloads, 28.1% compared with Forney algorithm, and 30.3% compared with Clock algorithm. Even adding prefetching operation, Caper algorithm also improves the performance about 7.7% and 17.4% compared with Charkraborty algorithm and Forney algorithm respectively.
heterogeneous; storage system; cache; prefetch; solid state drives (SSDs); performance prediction
2015-02-15;
2015-08-11
国家“九七三”重点基础研究发展计划基金项目(2011CB302301);国家“八六三”高技术研究发展计划基金项目(2013AA013203);国家自然科学基金项目(61025008,6123004,61472153)
施展(zshi@hust.edu.cn)
TP303
This work was supported by the National Basic Research Program of China (973 Program) (2011CB302301), the National High Technology Research and Development Program of China (863 Program) (2013AA013203), and the National Natural Science Foundation of China (61025008,6123004,61472153).
