基于Hadoop平台的语义数据查询策略研究*
2016-10-12胡志刚景冬梅陈柏林
胡志刚,景冬梅,陈柏林,杨 柳
中南大学 软件工程学院,长沙 410073
基于Hadoop平台的语义数据查询策略研究*
胡志刚,景冬梅,陈柏林,杨柳+
中南大学 软件工程学院,长沙 410073
HU Zhigang,JING Dongmei,CHEN Bailin,et al.Research on semantic data query method based on Hadoop.Journal of Frontiers of Computer Science and Technology,2016,10(7):948-958.
为了实现对海量RDF(resource description framework)数据的高效查询,研究了RDF三元组在分布式数据库HBase中的存储方法,基于MapReduce设计了海量RDF数据的两阶段查询策略,将查询分为SPARQL(simple protocol and RDF query language)预处理阶段与分布式查询执行阶段。SPARQL预处理阶段设计实现了基于SPARQL变量关联度的查询划分算法JOVR(join on variable relation),通过计算SPARQL查询语句中变量的关联度确定连接变量的连接顺序,根据连接变量将SPARQL子句连接操作划分到最小数量的Map-Reduce任务中;分布式查询执行阶段执行SPARQL预处理阶段划分的MapReduce任务,实现对海量RDF数据的并行查询。在LUBM标准测试数据集中的实验表明,JOVR算法能够高效地实现对海量RDF数据的查询,并具有良好的稳定性与可扩展性。
并行处理;语义信息查询策略;MapReduce;SPARQL;海量RDF
1 引言
全球数据量正以每年超过50%的速度增长[1],而随着语义Web的发展,各领域RDF(resource description framework)[2]语义数据急剧增加,如Wikipedia[3]、生物信息学[4]、媒体数据[5]、社交网络[6]等。以链接开放数据(linked open data,LOD)工程为例[7],截止到2014年4月LOD工程中一共包含1 014个RDF开放数据集,相比2011年的295个RDF开放数据集、310亿个RDF三元组的规模扩大了3倍多。传统的语义Web查询工具能够提供支持RDF数据标准查询语言SPARQL(simple protocol and RDF query language)的查询环境,但都是运行于单机环境中,处理海量RDF数据时的计算性能有待提高。目前RDF数据呈现出大规模性、高速增长性与多样性等大数据(big data)[8-9]特性,因此海量RDF数据对数据存储与数据处理技术在处理速度及可扩展性等方面提出了新的需求,利用并行计算技术处理海量RDF数据已在学术界与工业界达成共识。
Hadoop是一款开源云计算平台,其核心是HDFS(Hadoop distributed file system)和MapReduce框架。HDFS分布式文件系统具有高容错性,能够提供高吞吐量的数据访问,很适合海量数据集上的应用。运行于HDFS之上的HBase分布式数据库性能高,并且具有高可靠性。MapReduce分布式程序开发框架,能够简化分布式程序的设计与实现,高效处理海量数据。因此,研究人员开始将具备大数据处理能力的云计算Hadoop技术引入语义Web研究领域[10]。
近年来研究人员基于云环境提出了一些语义数据存储与查询策略,但是在存储空间和查询效率方面仍需要进一步研究与优化。
本文的主要研究工作如下:
(1)采用文献[10]提出的存储方法,基于“二元组合”行键的SPO存储策略,设计3张HBase表(SP_O, PO_S和OS_P)存储海量RDF数据。
(2)设计实现了SPARQL查询划分算法JOVR(join on variable relation),通过计算SPARQL语句中变量关联度确定连接变量的连接顺序,并根据连接变量将SPARQL子句连接操作划分到最小数量的MapReduce任务中,用以缩短查询大规模RDF数据的时间。
(3)基于MapReduce分布式程序开发框架,高效地实现了RDF数据并行查询。
2 相关概念与研究
2.1相关概念
(1)RDF
RDF用主语S(Subject)、谓语P(Project)、宾语O(Object)的三元组
(2)SPARQL
SPARQL是W3C提出的针对RDF数据的标准查询语言,与SQL的语法相似,通过SELECT查询方式查找满足条件的数据。表1展示的是一个简单的SPARQL查询例子,用于从图书的数据集中查找出书的题目。

Table 1 Example of SPARQL query表1 SPARQL查询实例
该查询中SELECT子句表示查询的内容,WHERE子句表示待查询项满足的三元组模式。语句中带“?”的部分是查询中的未知变量,如“?title”是表示图书题目的未知变量。
(3)HBase
HBase是基于Google的Bigtable开发的一个高可靠性、面向列、可伸缩的分布式存储系统[13]。HBase存储的是松散型数据,介于映射(key/value)与关系型数据之间,存储的数据从逻辑上看就像一张很大的表,其数据列可以根据需要动态增加,由行和列所确定的单元(Cell)中的数据可以由时间戳区分为多个版本。
(4)MapReduce
MapReduce是一个分布式程序开发框架,任务处理分为Map阶段和Reduce阶段,分别通过Map函数和Reduce函数实现。在Map阶段,输入数据经过自定义的Map函数处理后产生
2.2相关研究
RDF分布式存储主要分为HDFS与HBase两种方案,基于这两种存储方式研究人员提出了多种RDF查询算法。
(1)Myung等人[14]从HDFS的RDF数据文件中读取对应的RDF数据,创建多个MapReduce任务迭代处理SPARQL子句连接操作。但该方法将RDF数据直接存放到HDFS上,缺少了高效的索引结构;而且可能导致在SPARQL子句连接过程中创建较多的MapReduce任务。Husain等人[15]证明了在并行环境下随着生成MapReduce任务数量的降低,RDF数据查询时间会减少,但是它们同样采用HDFS存储RDF数据,缺少高效的索引结构,很难实现对海量RDF数据的快速随机访问。
(2)Sun等人[16]基于HBase,采用6张索引表(S_PO,P_SO,O_SP,SP_O,PO_S和SO_P)存储RDF数据,提出了一个迭代生成MapReduce任务的算法实现RDF数据查询。Franke等人[17]设计了两张HBase 表Tsp和Top存储RDF数据,在SPARQL查询过程中优先选取匹配数据量较少的查询子句进行连接。
以上这些算法都只侧重于减少SPARQL查询的中间结果集数量,有可能会导致在SPARQL子句连接过程中创建更多的MapReduce任务,因此在有些情况下并不能明显缩短查询时间。
3 基于HBase的RDF数据存储策略
基于HBase的RDF三元组存储策略目前主要有3类:(1)基于“一二元”行键的SPO存储策略,任意选取三元组
Sun等人[16]基于“一二元”行键的SPO存储策略设计了6张HBase表(S_PO,P_SO,O_SP,SP_O,PO_S 和SO_P),在HBase中的行键分别为S、P、O、SP、PO 和SO,用于在查询中快速匹配各种SPARQL三元组模式。在这种方案中,RDF数据需要被复制6次进行存储,因而增大了空间存储开销和数据冗余。另外由于这种方案中的HBase表属于宽行设计,即在进行查询时,所有查询模式对应的RDF三元组对应到相应数据表中的一行数据,按照HBase表的划分方法,一行数据只对应一个HRegion,所以输入分片最多只有一个,那么对应的Map任务最多也只有一个,每次查询处理都是由一台机器进行查询计算,因此并行度不高。
Franke等人[17]基于“列固定”行键的SPO存储策略设计了两张HBase数据表Tsp和Top,列名存储P对应的值,行键分别为S和O,分别用于匹配主语S或宾语O已知的SPARQL三元组模式,表单元则分别存储O和S值。这种存储策略中HBase表采用了高列设计,即所有查询模式对应的RDF三元组对应表中的多行数据,可以对应多个HRegion和多个Map任务,并行度较高。但是当S和O同时为未知量时,则需要对其中任意一个表进行全表扫描,必然会增加查询过程的时间开销。
综合空间开销、时间开销和并行度方面,本文采用文献[10]中基于“二元组合”行键的SPO存储策略。设计了3个HBase表(SP_O,PO_S和OS_P)存储数据,与基于“一二元”行键的SPO存储策略相比,降低了空间开销;行键分别为SP、PO和OS能够满足所有可能组合形式的SPARQL三元组模式查询匹配条件,与基于“列固定”行键的SPO存储策略相比,降低了时间开销。表SP_O结构如表2所示,其中m和n分别为HBase表中行数和列数,且m,n≥0,行键是主语值和谓语值的有序对
表3描述了SPARQL子句中不同的三元组模式与上述HBase表之间的查询映射关系,其中?S、?P 和?O分别表示主语、谓语和宾语是未知量,不带有“?”的表示已知。
如表3所示,当三元组模式为(S,P,O)或(?S,?P, ?O)时,可以对SP_O、PO_S和OS_P中任意一张表进行检索。当三元组模式中只有1个变量时,如(S,P,?O),将其中2个已知值S和P设为检索条件,对表SP_O的行键进行匹配;当三元组模式中有2个变量时,如(S,?P,?O),利用HBase的Scan区域检索机制,根据已知值S在表SP_O的行键区间内扫描,得到查询结果。
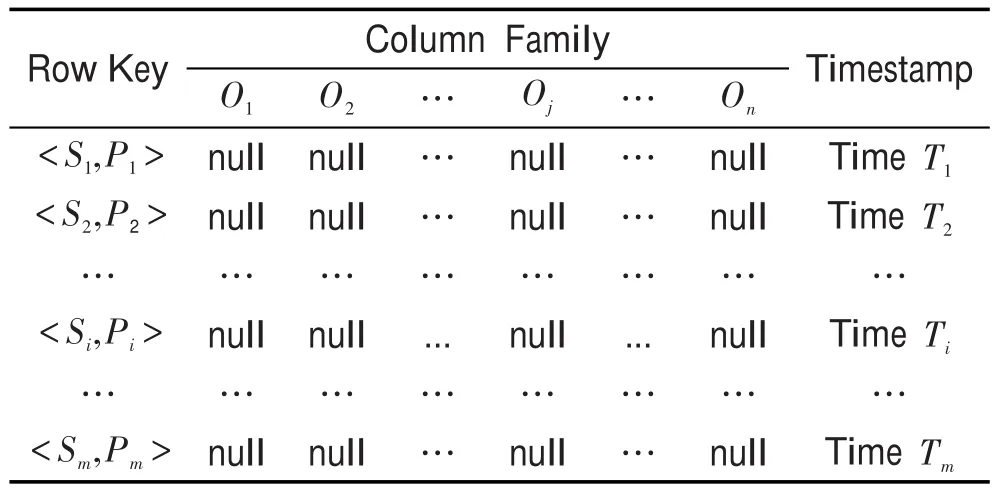
Table 2 Storage structure of table SP_O in HBase表2 表SP_O在HBase中的存储结构
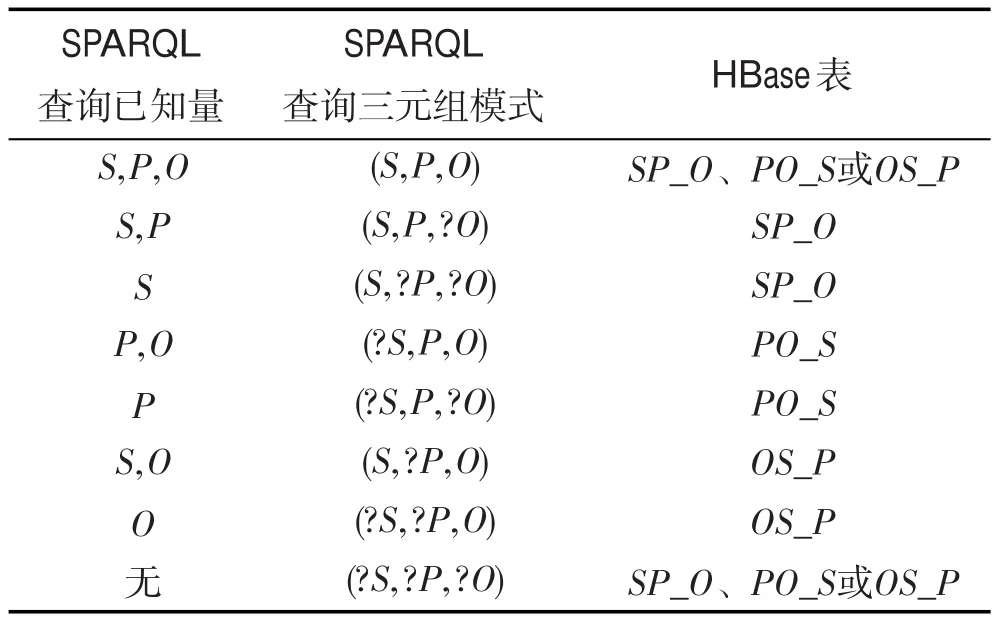
Table 3 Mapping relation between SPARQL triple patterns and HBase tables表3 SPARQL查询三元组与HBase表映射关系
4 RDF数据的两阶段查询策略
本文提出的RDF数据的两阶段查询策略基于SPARQL检索在Hadoop平台中实现海量RDF数据的并行查询。以图1中的SPARQL查询语句为例,详细介绍策略的设计与实现方案。
4.1RDF数据的两阶段查询策略框架
为了方便描述,首先定义以下概念:
定义1TP(U)表示SPARQL查询语句中的三元组模式。其中U是三元组中变量集合,即{X,Y,Z, XY,XZ,YZ}∈U。
TP(U)中的每个组员S、P和O中至少有1个是变量,否则SPARQL查询语句将无意义。图1所示的查询实例query中三元组模式依次表示为TP1(X), TP2(Y),TP3(Z),TP4(XZ),TP5(XY)。

Fig.1 Example of SPARQL—query图1 SPARQL查询实例query
定义2连接变量是在两个或更多个
定义3关联度指与一个连接变量V直接相关的其他连接变量的个数,表示为R(V),{X,Y,Z}∈V。
图1查询实例query中与X直接相关的连接变量有Y和Z,分别与Y、Z直接相关的连接变量只有X,那么R(X)=2,R(Y)=1,R(Z)=1。
定义4IRS(U)是查询过程中MapReduce任务产生的含有变量U的中间结果集,{X,Y,Z,XY,XZ,YZ}∈U。
定义5查询时间指执行查询Q过程中所有Map-Reduce任务花费的时间总和,用Cost(Q)表示。每个MapReduce任务花费的时间用Cost(job)表示,则所花费的时间总和用公式表示为:
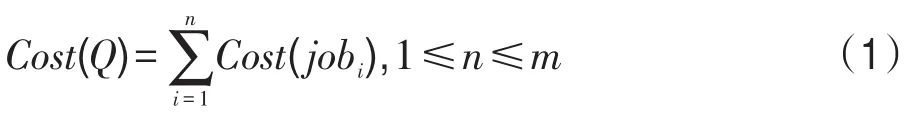
其中,Q代表当前SPARQL查询;jobi表示当前第i 个MapReduce任务;n表示MapReduce任务的数量;m表示连接变量的个数。
RDF数据的两阶段查询策略包含SPARQL预处理和分布式查询执行两个阶段,查询策略框架图如图2所示。
(1)SPARQL预处理阶段提出了基于SPARQL变量关联度的查询划分算法JOVR,JOVR首先根据变量关联度从SPARQL查询三元组中有次序地选取连接变量,然后将SPARQL子句连接操作划分到最小数量的MapReduce任务中。
(2)分布式查询执行阶段中对查询子句进行连接时,需要将数据从对应的HBase表中读出,然后在Map阶段进行数据的过滤与组装,在Reduce阶段完成连接任务。
4.2SPARQL预处理JOVR算法
JOVR算法通过计算SPARQL变量关联度确定连接变量的连接顺序,根据连接变量贪心划分SPARQL查询语句达到分布式查询阶段job(MapReduce任务)数量最少的目标。
算法1 JOVR算法
输入:Q(SPARQL查询)
输出:job(MapReduce任务)集合
1.n←1
2.U←sortOnRel({u1,u2,…um});//按关联度非递减对连接变量排序
3.whileQ≠Empty do
4.jobn←Empty;//当前的job
5.tmp←Empty;//存放中间连接结果
6.fori←1 tomdo
7.if canJoin(Q,ui)=true then//Q中子集能够按照ui进行连接
8.tmp←tmp⋃joinResult(.Q,ui);//保存连接结果
9.Q←Q-TP(Q,ui); //从Q中去掉已连接的子集
10.jobn←jobn⋃(join(Q,ui);//将连接操作加入当前job
11.end if
12.end for
13.if tmp=Empty//不存在可以参与连接操作的三元组
14.break;//结束循环
15.Q←Q⋃tmp;//在Q中加入中间连接产生的新变量集
16.n←n+1;
17.end while
18.return{job1,job2,…,jobn};
算法第2行是对m个连接变量按关联度进行非降序排序。第6~12行采用贪心划分方法确定每个job包含的操作。依次遍历连接变量,如果能够按照当前变量ui进行查询子句连接,则把连接产生的中间结果语句保存在临时变量tmp中,同时从查询语句中去掉已经进行连接的子句,最后还需要把连接操作加入到当前的 jobn中。第13~14行指如果当前不存在可以参与连接操作的子句,即不再会生成新的job,算法结束。第15~16行是指当前剩余的查询语句不能按照任何连接变量进行连接,则在当前Q中加入temp中的语句,开始计算新的job,重复第4~16行的操作,直到不会生成新的job。
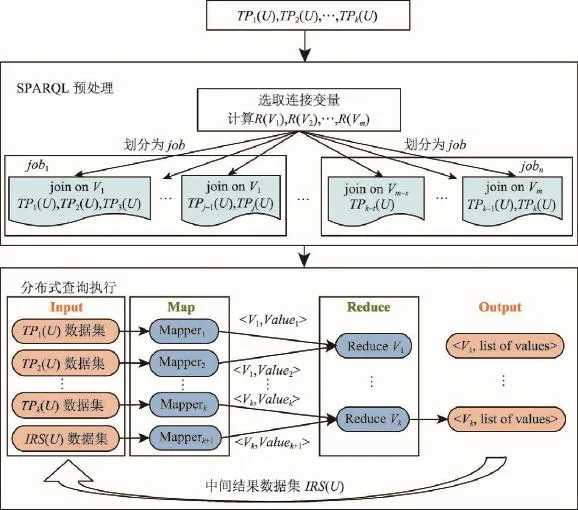
Fig.2 Frame of two-stage query strategy for RDF data图2 RDF数据的两阶段查询策略框架图
在上述算法中,对m个连接变量进行快速排序的时间复杂度是O(mlbm),外层循环(while循环)最多执行n次,内层循环(for循环)最多执行m次,因此该算法的总时间复杂度是O(m(n+lbm)),m指的是查询语句中连接变量的数量,n指的是job的数量,其中1≤n≤m。
在图1所示的SPARQL查询实例query中,根据4.1节的定义,可以计算出query中连接变量X、Y和Z的关联度分别是R(X)=2,R(Y)=1,R(Z)=1。依据JOVR算法,按照关联度非递减次序选取连接变量分别为Y、Z、X,查询对应2个job。查询划分过程如图3所示。
从JOVR算法的查询划分过程可以分析出query查询用时总和为:
Cost(query)=Cost(job1)+Cost(job2)
已有研究人员基于JOVF(join on variable frequency)算法[15]进行SPARQL查询划分。按照连接变量出现的次数进行非升序排序,贪心选择出现次数最多的连接变量,然后依次根据选取的连接变量划分得到job。基于JOVF算法,图1查询实例query中X、Y、Z出现的次数分别为3、2和2,依次选择连接变量X、Y、Z共划分为3个job,划分过程如图4所示。
从JOVF算法的查询划分过程可以分析出query查询用时总和为:
Cost(query)=Cost(job1)+Cost(job2)+Cost(job3)
由图3和图4对比分析可得,对于图1中的SPARQL查询实例query,JOVR算法比JOVF算法划分的job数量更少,因此查询所用的时间相对更少。
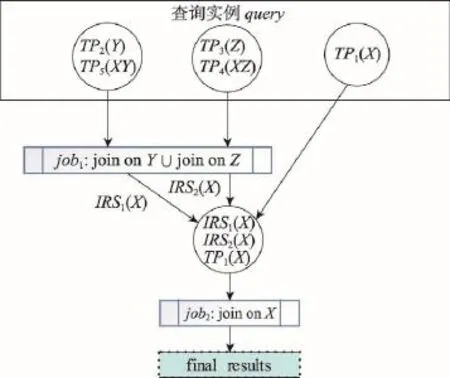
Fig.3 Process of query classification in JOVR algorithm图3 JOVR算法中查询划分过程
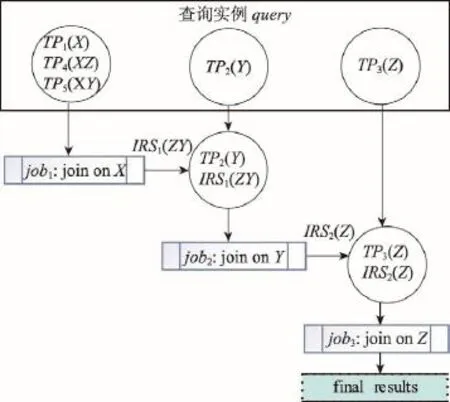
Fig.4 Process of query classification in JOVF algorithm图4 JOVF算法中查询划分过程
4.3分布式查询执行
SPARQL预处理阶段划分得到job后,分布式查询执行阶段基于MapReduce实现对RDF数据的并行查询。本节结合图1中的查询实例query,介绍在每一个job中如何具体进行连接操作,如图5所示。
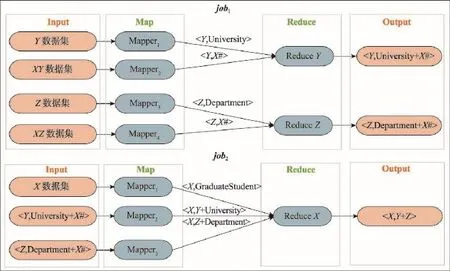
Fig.5 Instance of SPARQL query execution process图5 SPARQL查询执行过程实例图
(1)HBase数据读取:当查询子句中的三元组参与连接操作时,需要将数据从对应的HBase表中读取出来。
(2)Map阶段:将查询子句中三元组对应的数据集以
(3)Reduce阶段:完成同一连接变量对应的多个查询子句的连接。如图5job1中对key为Y值的子句连接后,得到的数据key值仍然是Y,value值是将参与连接操作的数据的value部分合并得来,得到University+X#,最后按照自定义的Reduce函数输出最终结果。
在有多个job的情况下,前一个job的输出是后一个job的输入。如图5所示,job2的输入分别来自于读取的X数据集和 job1的输出数据集,经过Map阶段和Reduce阶段后,输出X、Y、Z最终对应的数据值,即SPARQL的查询结果。
5 实验分析
5.1实验环境
本文采用Hadoop-2.5.2作为运行平台,选取HBase-1.0.0作为RDF三元组存储数据库,并选用4台PC机(具体配置为Pentium IV CPU 3.00 GHz,2 GB内存和160 GB硬盘空间)搭建实验平台。
5.2实验结果对比分析
本实验利用利哈伊大学开发的LUBM(Lehigh University Benchmark)[18]标准测试数据集,分别对10、50、100、300以及500所大学的RDF数据集进行了测试。数据集对应的三元组数目及文件大小如表4所示。
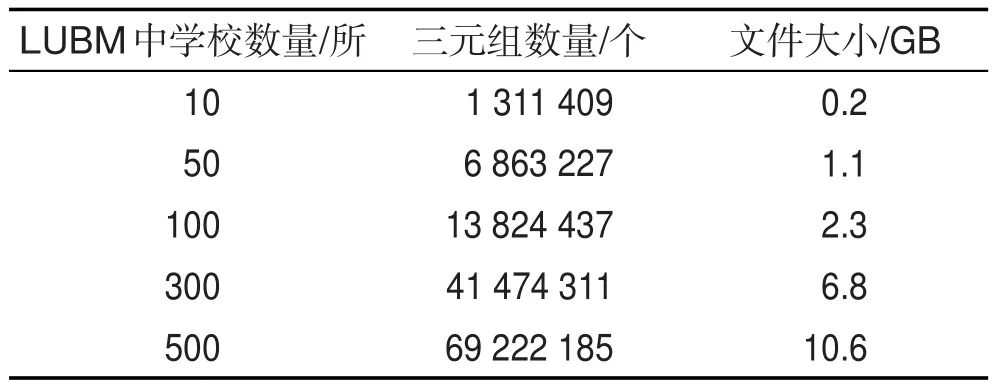
Table 4 Size of LUBM test set表4 LUBM测试集大小
本文在不同大小的数据集下,分别针对JOVF和JOVR算法测试了5条在语句复杂程度上具有代表性的LUBM查询语句,各查询语句与job的对应关系分别如表5所示。为了保证实验结果的准确性,本实验将每条查询语句在不同数据集下分别测试5次,最后取得平均值。各查询花费的平均时间如表6所示。
(1)JOVF和JOVR算法中各查询语句花费的平均时间对比分析。由表6可得,对于Q1和Q4两个查询语句,两种算法的平均时间几乎相同,是因为在这两种算法中Q1和Q4都对应一个job,如表5所示。而对于Q2、Q8和Q9,JOVF算法花费的时间是JOVR算法的1.5倍左右。由表5可知,在JOVF算法中Q2、Q8和Q9对应的job数量分别为3、2、3,在JOVR算法中3者对应的job数量分别为2、1、2,由于job启动相对耗时,查询时间会随着job数量的增多而相应增长。实验表明,JOVR算法在查询效率方面优于JOVF算法。
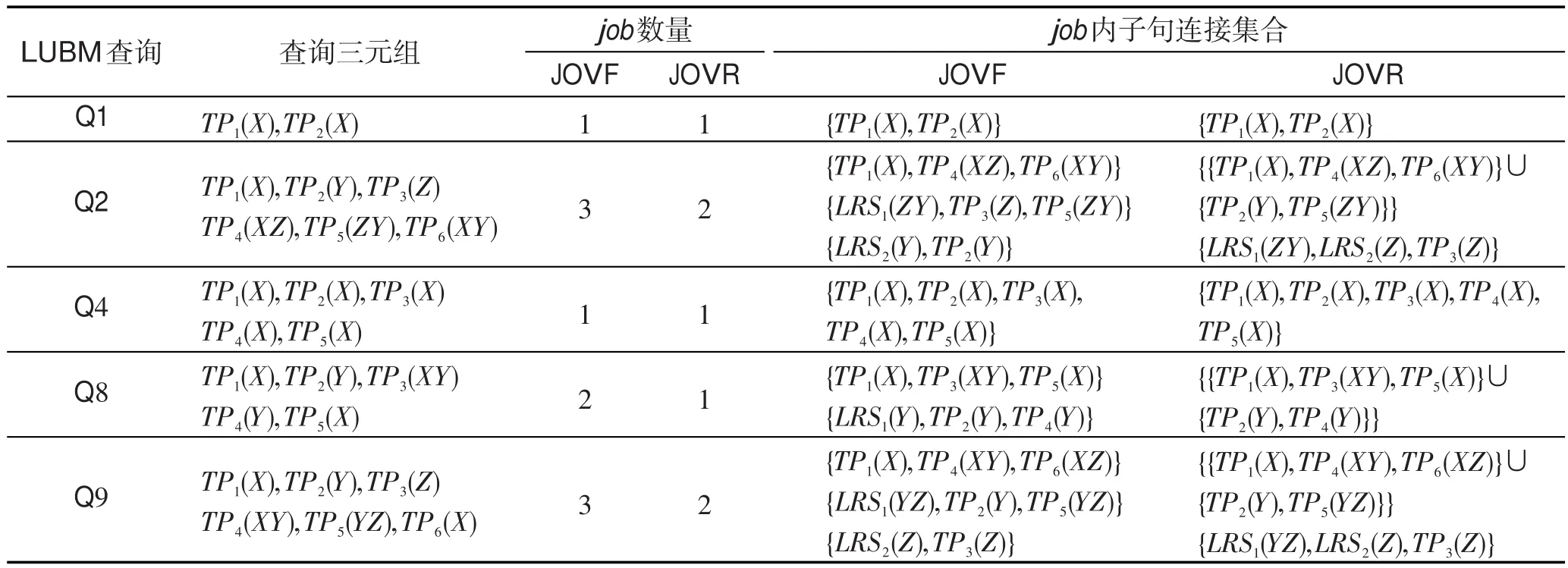
Table 5 Corresponding relation of LUBM query statements and job表5 LUBM查询语句与job的对应关系表
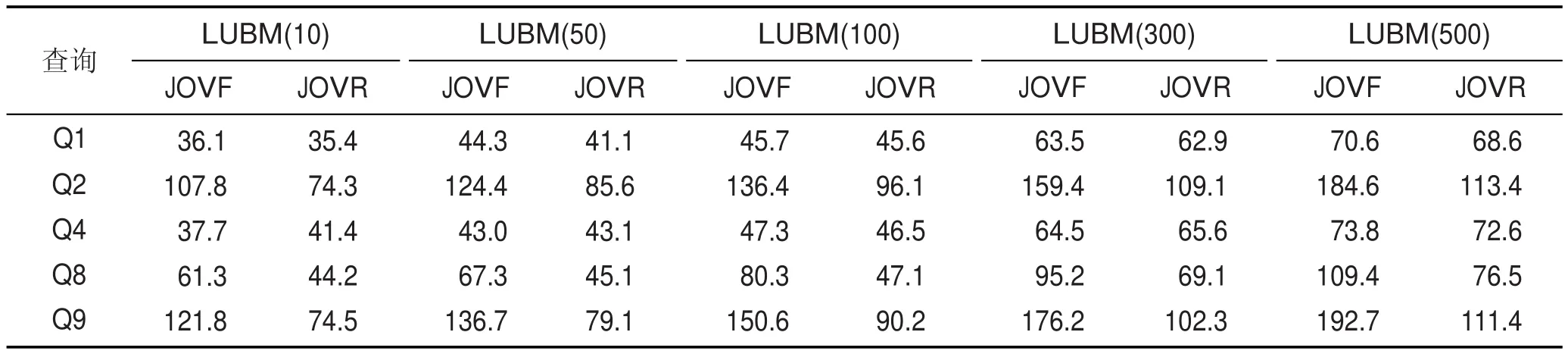
Table 6 Average query time of LUBM表6 LUBM平均查询时间 s
(2)JOVF和JOVR算法平均查询时间随着数据集增大而增长的情况分析。如图6和图7所示,随着测试数据集规模的不断扩大,两种算法的平均查询时间并没有呈现指数增长趋势,而是平缓上升。JOVR算法中平均查询时间的增长率明显更小,表明JOVR算法在查询的稳定性方面优于JOVF算法。
(3)可扩展性分析。由表6可得,当测试数据集扩大了50倍时,JOVF和JOVR算法的平均查询时间分别只扩大了约1.8倍和1.7倍,表明JOVF和JOVR算法都具有良好的可扩展性。
综合以上分析,JOVR算法在查询效率、稳定性及可扩展性方面都取得了较好的结果,能够更好地支持海量RDF数据的查询。
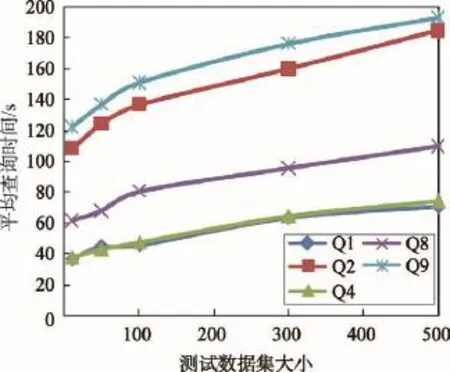
Fig.6 Curve of average query time growth in JOVF图6 JOVF算法平均查询时间增长曲线图
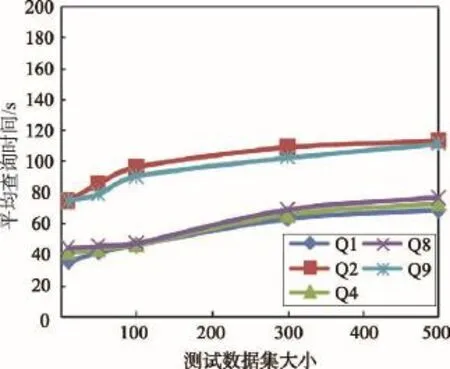
Fig.7 Curve of average query time growth in JOVR图7 JOVR算法平均查询时间增长曲线图
6 结束语
本文提出了一种海量RDF数据两阶段查询策略,设计了基于SPARQL变量关联度的查询划分算法JOVR,达到了分布式查询过程中查询任务数量最少的目标。在LUBM标准数据集中的实验表明了JOVR算法在查询效率与稳定性方面比已有的JOVF算法更优,能够更好地支持海量RDF数据的查询。JOVR算法主要针对SPARQL的简单查询模式,在后续研究过程中,将会对SPARQL复杂组图模式分布式查询方法展开研究。
[1]Big data white paper in 2014[R].Ministry of Industry and Information Technology,Telecommunications Research Institute,2014.
[2]Manola F,Miller E.RDF primer[EB/OL].W3C Recommendation(2004)[2015-07-17].http://www.w3.org/TR/rdf-syntax/.
[3]Hoffart J,Suchanek F M,Berberich K,et al.YAGO2:a spatially and temporally enhanced knowledge base from Wikipedia[J].Artificial Intelligence,2013,194:28-61.
[4]Belleau F,Nolin M A,Tourigny N,et al.Bio2RDF:towards a mashup to build bioinformatics knowledge systems[J]. Journal of Biomedical Informatics,2008,41(5):706-716.
[5]Kobilarov G,Scott T,Oliver S,et al.Media meets semantic Web—how the BBC uses DBpedia and linked data to make conections[C]//LNCS 5554:Proceedings of the 6th European Semantic Web Conference on Semantic Web in Use Track, Heraklion,Greece,May 31-Jun 4,2009.Berlin,Heidelberg:Springer,2009:723-737.
[6]Mika P.Social networks and the semantic Web[C]//Proceedings of the 2004 IEEE/WIC/ACM International Conference on Web Intelligence,Beijing,China,Sep 20-24,2004. Piscataway,USA:IEEE,2004:285-291.
[7]The linked open data project(LOD)[2015-06-08].http:// www.w3.org/wiki/SweoIG/TaskForces/CommunityProjects/ LinkingOpenData.
[8]Meng Xiaofeng,Ci Xiang.Big data management:concepts, techniques and challenges[J].Journal of Computer Research and Development,2013,50(1):146-169.
[9]Wang Shan,Wang Huiju,Qin Xiongpai,et al.Architecting big data:challenges,studies and forecasts[J].Chinese Journal of Computers,2011,34(10):1741-1752.
[10]Li Ren.Research on key technologies of large-scaled semantic Web ontologies querying and reasoning based on Hadoop[D].Chongqing:Chongqing University,2013.
[11]Du Xiaoyong,Wang Yan,Lv Bin.Research and development on semantic Web data management[J].Journal of Software, 2009,20(11):2950-2964.
[12]Bechhofer S,Harmelen F V,Hendler J,et al.OWL Web ontology language reference[J].W3C Recommendation,2004, 40(8):25-39.
[13]Shi Hunjun.Research of massive semantic information parallel inference method based on cloud computing[D].Shanghai:Shanghai Jiaotong University,2012.
[14]Myung J,Yeon J,Lee S G.SPARQL basic graph pattern processing with iterative MapReduce[C]//Proceedings of the 2010 Workshop on Massive Data Analytics on the Cloud, Raleigh,USA,Apr 26,2010.NewYork,USA:ACM,2010:6.
[15]Husain M,Mcglothlin J,Masud M M,et al.Heuristicsbased query processing for large RDF graphs using cloud computing[J].IEEE Transactions on Knowledge&Data Engineering,2011,23(9):1312-1327.
[16]Sun Jianling,Jin Qiang.Scalable RDF store based on HBase and MapReduce[C]//Proceedings of the 3rd International Conference on Advanced Computer Theory and Engineering,Chengdu,China,Aug 20-22,2010.Piscataway,USA: IEEE,2010,1:633-636.
[17]Franke C,Morin S,Chebotko A,et al.Distributed semantic Web data management in HBase and MySQL cluster[C]// Proceedings of the 2011 IEEE 4th International Conference on Cloud Computing,Washington,USA,Jul 4-9,2011.Piscataway,USA:IEEE,2011:105-112.
[18]Guo Yuanbo,Pan Zhengxiang,Heflin J.LUBM:a benchmark for OWL knowledge base systems[J].Semantic Web Journal,2005,3(2/3):158-182.
附中文参考文献:
[1]2014年大数据白皮书[R].工业和信息化部电信研究院, 2014.
[8]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(1):146-169.
[9]王珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011,34(10):1741-1752.
[10]李韧.基于Hadoop的大规模语义Web本体数据查询与推理关键技术研究[D].重庆:重庆大学,2013.
[11]杜小勇,王琰,吕彬.语义Web数据管理研究进展[J].软件学报,2009,20(11):2950-2964.
[13]施惠俊.基于云计算的海量语义信息并行推理方法研究[D].上海:上海交通大学,2012.

HU Zhigang was born in 1963.He is a professor and Ph.D.supervisor at Software Engineering Institute,Central South University.His research interests include parallel processing and cloud computing.
胡志刚(1963—),男,山西孝义人,中南大学软件学院教授、博士生导师,主要研究领域为并行处理,云计算。

JING Dongmei was born in 1991.She is an M.S.candidate at Software Engineering Institute,Central South University. Her research interests include semantic Web and cloud computing.
景冬梅(1991—),女,山东聊城人,中南大学软件学院硕士研究生,主要研究领域为语义万维网,云计算。

CHEN Bailin was born in 1992.He is a student at Software Engineering Institute,Central South University. His research interests include semantic Web and signal processing.
陈柏林(1992—),男,四川遂宁人,中南大学软件学院学生,主要研究领域为语义万维网,信号处理。

YANG Liu was born in 1979.She is a Ph.D.and associate professor at Software Engineering Institute,Central South University.Her research interests include semantic Web and semantic information processing.
杨柳(1979—),女,浙江宁波人,中南大学软件学院博士、副教授,主要研究领域为语义万维网,语义信息处理。
Research on Semantic Data Query Method Based on Hadoop*
HU Zhigang,JING Dongmei,CHEN Bailin,YANG Liu+
College of Software Engineering,Central South University,Changsha 410073,China +Corresponding author:E-mail:yangliu@csu.edu.cn
In order to achieve the efficient query for large-scale RDF(resource description framework)data,this paper analyzes the storage method of RDF triples in HBase and designs a two-stage query strategy for large-scale RDF data based on MapReduce,which is divided into two stages:the SPARQL(simple protocol and RDF query language)pretreatment stage and the distributed query execution stage.In the SPARQL pretreatment stage,an SPARQL query classification algorithm—JOVR(join on variable relation)is implemented,which determines the join order of connection variables by calculating the correlation between the variables in an SPARQL query statement,then the join between SPARQL clauses is divided into the minimum number of MapReduce jobs according to the connection variables.The distributed query execution stage accomplishes large-scale RDF data query concurrently based on MapRdecue jobs from SPARQL pretreatment stage.The experimental results on the LUMB benchmark set indicate that JOVR can query large-scale RDF data efficiently with good stability and scalability.
parallel processing;semantic information query strategy;MapReduce;simple protocol and RDF query language(SPARQL);large-scale RDF
2015-08,Accepted 2015-10.
10.3778/j.issn.1673-9418.1509010
A
TP391
*The National Natural Science Foundation of China under Grant Nos.61301136,61272148(国家自然科学基金).
CNKI网络优先出版:2015-10-20,http://www.cnki.net/kcms/detail/11.5602.TP.20151020.1042.014.html
