ABC_Kmeans聚类算法的MapReduce并行化研究
2016-09-07袁小艳
袁小艳
(四川文理学院 计算机学院,四川 达州 635000)
ABC_Kmeans聚类算法的MapReduce并行化研究
袁小艳
(四川文理学院 计算机学院,四川 达州635000)
随着数据的海量增长,数据聚类算法的研究面临着海量数据挖掘和处理的挑战;针对K-means聚类算法对初始聚类中心的依赖性太强、全局搜索能力也差等缺点,将一种改进的人工蜂群算法与K-means算法相结合,提出了ABC_Kmeans聚类算法,以提高聚类的性能;为了提高聚类算法处理海量数据的能力,采用MapReduce模型对ABC_Kmeans进行并行化处理,分别设计了Map、Combine和Reduce函数;通过在多个海量数据集上进行实验,表明ABC_Kmeans算法的并行化设计具有良好的加速比和扩展性,适用于当今海量数据的挖掘和处理。
K-means;聚类;人工蜂群;MapReduce
0 引言
聚类分析是当今数据挖掘研究的一个重要领域,其目的是把数据集按照规则分成若干个类别,使得同类别的数据尽量高内聚,不同类别的数据尽量低耦合,它是一种无监督学习技术[1]。
K_means是常用的一种数据聚类算法,具有高效而简单的特性,但其K值要靠经验确定,结果也容易受初始中心点影响,易陷入局部最优解[2],全局搜索能力较差,鲁棒性也低。群体智能优化算法是一种把所有个体信息进行交互,从而得到最优结果的算法,其全局搜索能力较强,效率也较高,因此很多人都将其融入到K_means算法中进行研究,效果都较理想。
人工蜂群(ABC)算法是2005年根据蜂群觅食的行为提出的一种群体智能算法,其结构简单、收敛速度快、容易实现,更适合于计算机编程[3]。本文将一种改进的人工蜂群算法融入到K_means中进行迭代,降低了对初始聚类中心点的依赖,提高了全局寻优能力,但在当今海量数据的情况下,效率还是堪忧,因此将本文提出的ABC_Kmeans算法采用Hadoop平台的MapReduce模型进行并行化实现,因为MapReduce模型本身具有并行化结构,编程人员不需要考虑并行化的细节知识,实现起来也较容易,能够减少节点间的通信时间,这样不仅仅是提高时间效率,同时还可以防止早熟现象。
1 改进的ABC与K_means聚类算法的融合
在基本ABC算法中,蜜蜂有3种类型,即采蜜蜂、观望蜂和侦察蜂,采蜜蜂与蜜源相对应,负责对相应的蜜源采蜜,观望蜂通过采蜜蜂的共享蜜源信息选择最优蜜源,若蜜源被采蜜蜂和观望蜂放弃,则将该蜜源对应的采蜜蜂转化为侦察蜂,进而搜索新的蜜源。本文将改进的ABC算法与K_means迭代相结合,每次迭代都利用改进的ABC算法来优化聚类中心点,再利用K_means迭代更新每个聚类中心点,两种算法交替执行,直到聚类达到最优为止。下面介绍两种算法融合后的聚类过程。
(1)设置参数,并输入样本数据集。采蜜蜂与观望蜂的个数,均为SN,聚类数为K,最大迭代次数为LIN,控制参数为limit。
(2)聚类中心的初始化,本文的聚类中心就是蜜源。在基本ABC算法中,蜜源的初始化随机性太大,不能保证初始蜜源的均匀分布。本文采用混沌算子和反向学习算子对聚类中心进行初始化,从而保证初始聚类中心的多样性,以提高全局搜索的能力。
1)首先生成具有SN个初始解的搜索空间。搜索空间是一个二维矩阵DF=K*d,行数为K,即聚类个数,列数为d,即样本数据集的维数。搜索空间的值计算如下:
df[1,j]=rand(0,1)
df[s+1,j]=n×df[s,j]×(1-df[s,j])
其中j=1,2,3,……,d,s=1,2,3,……,K-1,n是一个调节因子。
2)计算每个初始解的混沌算子和反向学习算子,计算如下:
nc[i,j]=lg[j]+df[s,j]×(hg[j]-lg[j])
rt[i,j]=lg[j]+hg[j]-nc[i,j])
其中i=1,2,3,……,K,hg[j]、lg[j]是搜索空间第j维的上、下限,nc[i,j]为混沌算子,rt[i,j]为反向学习算子,混沌算子组成混沌集合NC,反向学习算子组成反向集合RT。
3)最终的初始聚类中心就是NC和RT两个集合中适应度最高的SN个最优解。本文各聚类中心的适应度采用欧式距离进行计算。
(3)采蜜蜂进行邻域搜索,采用贪婪机制选择适应度高的新聚类中心。基本ABC中,邻域搜索范围的随机性太大,导致全局搜索能力较好,但局部搜索能力欠缺。本文受DE/best/1的启发,邻域搜索方程改为由最优解引导的式子,具体如下:
pi,j=dfbest,j+random(-1,1)×(dfbest,j-dfi,j)
(1)
其中best是适应度最优的采蜜蜂的ID。
(4)采蜜蜂完成邻域搜索后,观望蜂根据轮盘赌机制选择跟随的聚类中心,其选择概率为:
其中:dfit(i)是第i个解的适应度。
观望蜂选择聚类中心后,继续在聚类中心的邻域采用公式(1)进行搜索,查找适应度更高的聚类中心,以替换旧的聚类中心。
(5)若聚类中心经过连续limit次迭代后,没有被新的适应度高的新聚类中心替代,说明其陷入了局部最优,应该舍弃,该聚类中心对应的采蜜蜂也应该转换为侦察蜂,让其搜索新的聚类中心。基本ABC中,新蜜源的随机性太大,很容易被淘汰。受粒子群算法的启示,本文采用一种线性时变检索空间的策略选择新聚类中心,即随着迭代次数的增加而线性减小侦察蜂的检索空间,这样利于扩大探寻边界[3],更利于迭代后期快速找到最优解,公式如下:

(6)对各聚类中心进行一次K_means迭代,重新计算每个类别的聚类中心,并采用贪婪机制更新蜂群。
(7)将找到的最优聚类中心记录下来,若迭代次数小于LIN,则转到(3)执行下一次迭代;否则将此结果作为最优聚类类别进行输出。
2 MapReduce分布式模型
MapReduce模型是一种并行计算模型,主要用于海量数据的并行化处理。该模型能对文件自动分块,能自动处理节点间的传输、节点失效[4]和负载均衡等优点,并有较好的扩展性和容错性[4]。MapReduce模型输入的是一组键值对,输出的是另一组键值对,整个过程分成Map(映射)和Reduce(规约)。
Map映射函数首先利用Partion过程将输入的键值对(key-value)分割成多个键值对,然后对这多个键值对进行处理,将处理的结果输出。Reduce规约函数以Map函数的输出作为输入,并处理这些数据,输出一个较小的键值对集合。数据由Map函数到Reduce函数时,中间还要经过复制、排序、合并等操作,统称为Shuffle过程。合并是将具有相同键(key)的中间结果归并在一起,提供给Reduce处理。MapReduce模型的整个处理过程如图1所示。

图1 MapReduce模型处理流程
3 ABC_Kmeans聚类算法的MapReduce并行化设计
ABC_Kmeans聚类算法的并行化采用MapReduce并行模型设计,输入的数据是以行的形式存储,让数据按行分片。ABC_Kmeans的每一次迭代都对应一次MapReduce过程,完成聚类中心适应度和观望蜂选择概率的计算,以得到新的聚类中心,具体设计如图2所示。

图2 ABC_Kmeans的MapReduce并行化设计
3.1Map函数的设计
Map函数的目标是计算每个蜜源的适应度,由此得到观望蜂的选择概率,并标记出观望蜂属于的新类别,其输入是样本数据或者上一次迭代的聚类中心,输入数据的形式为(行偏移量,记录行)[5]这样的(key,value)键值对,其输出是(key’,value’),key’是选择的聚类中心的索引号,value’是当前样本点的坐标,其函数的伪代码如下:
void mapper(key,value)
{
从value中解析出样本数据,记为foods
For iter=0 to k-1 do{
计算每个蜜源的适应度;
计算每个观望蜂的选择概率;
观望蜂选择聚类中心,并查找更优聚类中心;
侦察蜂查找更优聚类中心;
if(foods[maxoptidx].opttimes>optmaxtime)
{
Sfoodinit(maxoptidx);
}
}
key’=maxoptidx;
value’=value;
Emit(key’,value’)
}
为了降低算法传输过程中的数据量和通信代价,ABC_Kmeans算法在Map操作后设计了一个Combine的函数,把每个Map函数的最终结果进行本地合并。
3.2Combine函数的设计
Combine函数的输入(key’,value’)中,key’是聚类中心的下标,value’是分配给key’类别的样本数据的坐标值组成的字符串链表[6];输出的(key,v)中,key是聚类中心的下标,v是包含了样本总数和key对应的各坐标值组成的字符串,其伪代码如下:
void Combiner(key’,value’)
{
Count=0;
While(value’.hasNext){
Point curret=value’.next();
Count+=current.getNum();
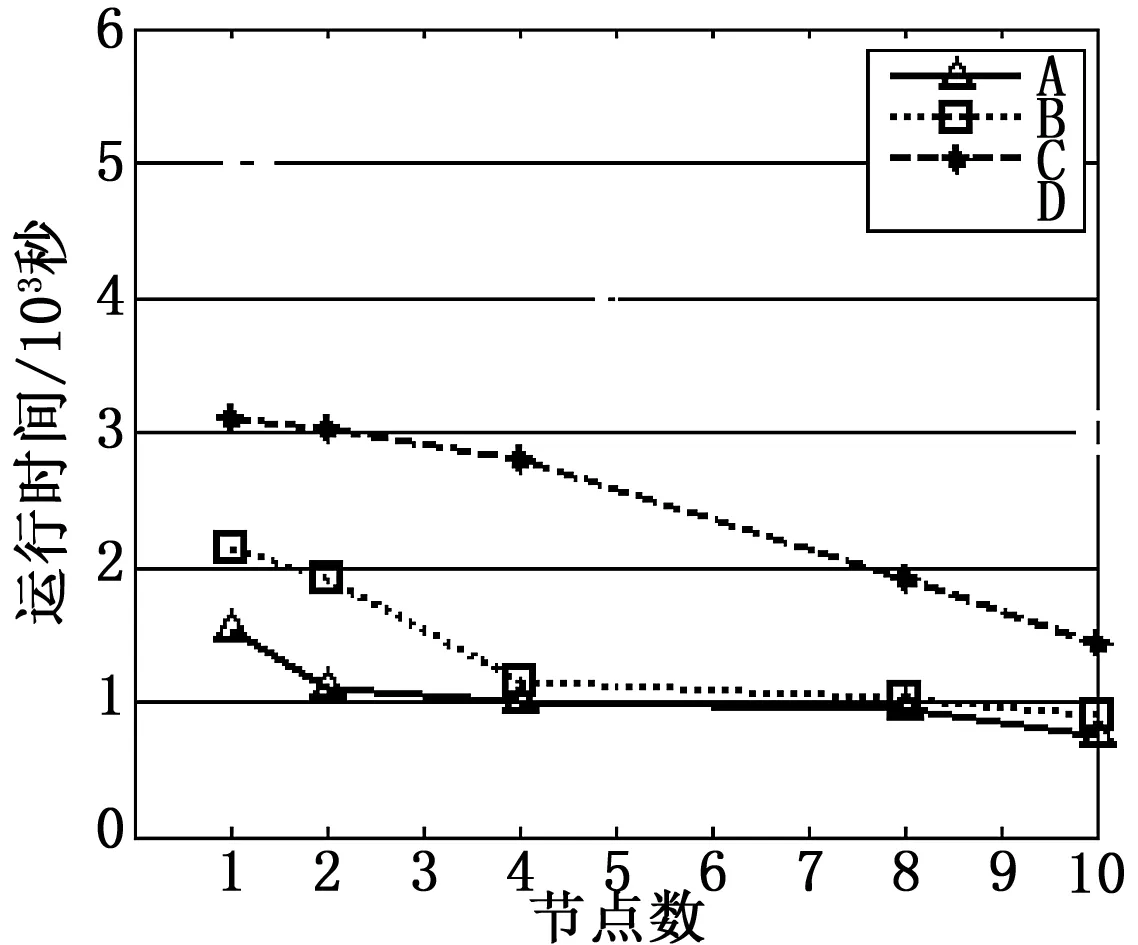
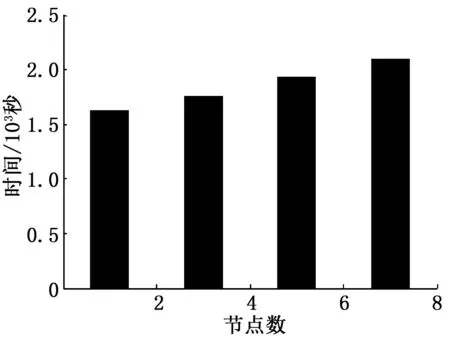
for(i=0;i total[i]+=current.point[i]; } } key=key’; 将前面得到的count和total数组各个分量的信息组成一个字符串,为v; Emit(key,v); } 3.3Reduce函数的设计 Reduce函数输入的(key,v)中,key是聚类类别的下标,v是从所有Combine函数传过来的结果,其作用是将key对应的样本点坐标值相加,再除以样本总数,得到新的聚类中心坐标。函数伪代码如下: void Reducer(key,v) { While(v.hasNext){ Point current=v.next(); total+=current.getValue(); count=current.getCounter(); New=total/count; } } 根据Reduce的结果,得到新的聚类中心坐标,判断迭代次数是否小于LIN,若是的话就进入下一次迭代,否则算法收敛。 4.1实验环境 本文中的实验是在我们的实验室搭建的云平台上运行的。平台由12台机器组成,其中一台是主控节点master,一台是JobTracker服务节点,剩余的10台是slaves,配置DataNode数据节点和TaskTracker服务节点。每台机器的配置为:CPU是2核,内存是8 GB,硬盘是2TB,网卡为板载千兆以太网卡,操作系统是红帽Linux AS 6.0,Hadoop平台是0.21.0版本,JDK是1.6.0.29版本。 4.2单机处理实验结果分析 本实验是将K-means和ABC_Kmeans聚类算法在相同的数据条件下,完成聚类的各自需要的迭代次数。处理的数据是分为10类且具有30 000个数据集的二维数据,两者数据处理的收敛速度如表1所示。 表1 收敛速度的比较 从表1中可以看出,相较于基本K-means聚类算法,本文 的ABC_Kmeans聚类算法具有更好的收敛速度,并且减小了聚类中心对初始值的依赖。 4.2集群加速比性能实验结果分析 加速比是用来比较并行系统或者并行化程序的性能和扩展性的重要指标,是指相同的任务在单处理器上消耗的时间,与并行处理器系统中消耗的时间的比率。 实验用的数据集是通过程序生成的数据,生成了1 G、2 G、4 G、8 G等4个数据集,编号分别是A、B、C、D,每个数据集由30维数据组成,要求生成10个聚类类别。 实验1 将1、2、4、8、10个节点参与实验,观察节点在逐渐增加时,算法完成聚类任务的时间,如图3所示。从图中可以看到,随着节点的增加,A、B、C、D这4个数据集运行的时间反而降低,同时相同规模的数据集处理时间也呈线性减少,这说明在MapReduce上执行ABC_Kmeans算法的加速比较好,且其加速比随着数据规模的增大,性能也越来越好。 图3并行化ABC_Kmeans算法的加速比实验结果图 实验2 分别选择2、4、6、8个节点,对应采用A、B、C、D这4个数据集计算,实验结果如图4所示。在图中可以看到,当节点数与数据集的规模同比例增长时,MapReduce处理数据的水平也基本上保持一致,这说明了其有良好的扩展性。 图4并行化ABC_Kmeans算法的扩展性实验结果图 鉴于基本K-means聚类算法过于依赖初始聚类中心,全局搜索能力较差的原因,本文将全局搜索能力较好的人工蜂群算法(ABC)融入其中,并改进了人工蜂群算法的初始蜜源,让ABC_Kmeans不再依赖于初始中心。为了提高ABC_Kmeans算法的执行效率,本文将其利用MapReduce并行化模型实现。实验表明ABC_Kmeans并行聚类算法比一般的K-means聚类算法,具有更好的聚类性能和更高的时间效率,数据量越大,时间效率的优势越好。随着云计算的兴起,数据挖掘越演越烈,其中的聚类算法研究也越来越热烈,本文的研究仅仅起到抛砖引玉的作用。 [1]曹永春,蔡正琦,邵亚斌.基于K_means的改进人工蜂群聚类算法[J].计算机应用,2014,34(1):204-208. [2]管玉勇.K-means算法与智能算法融合的研究[D].合肥:安徽大学,2014. [3] 李海生.蜂群算法及其在垂直Web检索中的应用[D].广州:广州大学,2010. [4]杨国营.基于MapReduce模型文本分类算法的研究[D].沈阳:辽宁大学,2013 [5]虞倩倩,戴月明,李晶晶.基于MapReduce的ACO-K-means并行聚类算法[J].计算机工程与应用,2013,49(16):117-121. [6]赵卫中,马慧芳,傅燕翔,等.基于云计算平台Hadoop的并行k-means聚类算法设计研究[J].计算机科学,2011,38(10):166-169 [7]喻金平,郑杰,梅宏标.基于改进人工蜂群算法的K均值聚类算法[J].计算机应用,2014,34(4):1065-1069 [8]张石磊,武装.一种基于Hadoop云计算平台的聚类算法优化的研究[J].计算机科学,2012,39(10):115-118 [9]莫赞,罗世雄,杨清平,等.基于K-means算法的改进蚁群聚类算法及其应用[J].系统科学学报,2012,20(3):91-94 [10]江小平,李成华,向文,等.k-means聚类算法的MapReduce并行化实现[J].华中科技大学学报,2011,39(6):120-124 Map Reduce Parallel Study of ABC_Kmeans Clustering Algorithm Yuan Xiaoyan (College of computer,Sichuan University of Arts and Science,Dazhou635000,China) With the massive growth of data, data clustering algorithm research is facing the challenge of mass data mining and processing.For K - means clustering algorithm to the dependence of the initial clustering center is too strong, and poor global search ability shortcomings, will be an improved artificial colony algorithm combined with K - means algorithm, ABC_Kmeans clustering algorithm is proposed, in order to improve the performance of clustering.In order to improve the clustering algorithm’s ability to deal with huge amounts of data, uses the MapReduce model for parallel processing to ABC_Kmeans, design the Map, Combine and Reduce function respectively,Through the experiments on several huge amounts of data collection,show ABC_Kmeans parallel design of algorithm has good speedup and scalability, applicable to today's huge amounts of data mining and processing. K-means;clustering;artificial bee colony;MapReduce 2015-07-22; 2015-09-07。 四川省教育厅一般项目(15ZB0318);四川文理学院一般项目(2014Z012Y);四川文理学院智能计算与物联网工程技术中心资助。 袁小艳(1982-),女,重庆永川人,硕士,讲师,主要从事软件技术及开发、云教育、知识工程方向的研究。 1671-4598(2016)01-0252-03 10.16526/j.cnki.11-4762/tp.2016.01.070 TP312 A4 实验结果与分析


5 结束语
