基于数据挖掘的中小学图书馆管理分析
2016-09-06龙懿田馨代倩
◆龙懿 田馨 代倩
基于数据挖掘的中小学图书馆管理分析
◆龙懿田馨代倩
近年来,各地中小学图书馆信息化管理发展迅速。基于教育信息化背景,使用数据挖掘方法,采用聚类分析、关联规则两种算法对真实数据进行探索,从而为图书馆管理提供科学依据、为资源的有效配置提供借鉴。
数据挖掘;中小学图书馆;图书馆信息化
10.3969/j.issn.1671-489X.2016.13.076
1 前言
数据挖掘也称数据库中的知识发现(KDD,Knowledge Discovery in Database)[1],于1989年被正式提出,之后伴随着信息化的迅速发展,数据挖掘作为一门综合学科的技术知识,也获得快速发展。简单地说,数据挖掘就是通过对数据的各种分析,得出有用的信息。然而它又不同于传统的统计分析。传统的统计分析是对数据进行带有某种目的的处理分析,数据挖掘是对数据进行综合处理,发现其中未知的、隐含的知识。这是一种新的分析处理手段,也是目前大数据处理中流行的分析方法,结果往往会超出传统认知,从而发现新的知识。其经典案例有通过对美国超市销售数据的分析,发现每周五晚上买啤酒的男士通常会购买尿不湿这一现象,之后营销学和市场学再对这一结果进行原因分析和营销战略分析。这种分析方式在信息化迅速发展的背景下,应用领域广泛,零售业、金融业、医疗教育行业等。
目前,国内外已经有大量的文献研究将数据挖掘技术应用于图书管理,其中大多数以某个学校、某个图书馆或者某个连锁书店为分析对象,还有一些研究立足于图书阅读与学生综合素质之间的关联分析。本文以一个省级图书管理平台为分析对象,采用数据挖掘中的聚类分析和关联规则两种算法对平台数据进行分析,发现其中未知的隐含信息,力求从更好地服务读者、更方便地管理图书、更有效地配置资源几个方面提供可用信息。
2 数据准备
数据平台我国教育部在2010年《国家中长期教育改革和发展规划纲要(2010—2020年)》和2012年《教育信息化十年发展规划(2010—2020年)》中均提到了中小学图书馆管理信息化问题,各省中小学图书馆管理信息化快速发展。图书馆信息化带来庞大的数据,要想利用好这些数据来为中小学读者、管理人员带来更加有效的信息,就会面对几个实际的问题:1)由于各地经济发展状况等不完全一致,客观表现不一,中小学图书馆建设情况各不相同;2)中小学图书馆各自归属不一样,数据库建设标准各有不同;3)部分学校图书馆信息化建设平台已经完成,但错误信息较多、使用较少;4)对已经运行较好的图书馆信息化系统积累的大量数据的利用不足。
四川省教育厅于2012年结合全省实际情况,在相关政策的指导下,开始建立省级图书管理平台,涵盖全省所有中小学图书馆的馆藏数据和流通数据。该平台帮助全省各中小学图书馆信息化工作的开展,通过建设管理平台,全省各中小学图书馆一方面统一建设标准,另一方面发现纠正数据库错误,形成真实有效的图书馆数据信息。
数据选取本研究数据均采集于四川省省级图书管理平台,时间窗口定于2012年9月到2014年12月。通过对全省图书信息化的调研分析,决定采用图书信息化实际发展差距不大的区域进行分析挖掘。以省会城市的数据为例采集数据,同时将其按照主城区和周边城区两个部分进行拆分,对两个部分的数据采用相同的数据挖掘算法进行分析,挖掘不同区域的信息,同时可以结合数据挖掘的结果进行对比分析。
本研究将选用图书馆代码、图书馆所属城市、图书分类号、书名、作者、借阅人姓名、借阅人性别、借阅时间、归还时间等19个维度进行挖掘分析,详见表1数据挖掘字段。
图书分类方法采用中图法基本分类:A—马克思主义、列宁主义、毛泽东思想、邓小平理论;N—自然科学总论;B—哲学、宗教;O—数理科学和化学;C—社会科学总论;P—天文学、地球科学;D—政治、法律;Q—生物科学;E—军事;R—医药、卫生;F—经济;S—农业科学;G—文化、科学、教育、体育;T—工业技术;H—语言、文字;U—交通运输;I—文学;V—航空、航天;J—艺术;X—环境科学、安全科学;K—历史、地理;Z—综合性图书。
3 数据挖掘分析
数据挖掘主要包括两个方面,一是挖掘结构,一个是挖掘算法。需要从挖掘结构中获得相应数据,然后再使用算法进行分析。数据挖掘的算法很多,如决策树算法、聚类分析算法、关联算法、时序算法和线性回归算法等,大多数算法都能达到几种不同的功能,在实际运用中,根据不同需要,采用不同的数据挖掘方法,比如人工神经网络、关联分析、遗传算法、聚类分析等。本文主要采用聚类分析和关联分析两种方法,针对以上选取数据进行分析。
聚类分析聚类分析(Clustering Analysis)是一组将研究对象分为相对同质的群组的统计分析技术,按照它们的属性上的亲疏远近进行分类,也可以说聚类分析是将物理或抽象对象的集合分组成为由类似的对象组成的多个类别的分析过程。
聚类分析在图书馆文献研究中,通常选用年龄、学历、收入等量化指标进行聚类情况,本文将从图书类别、性别和借阅时间(月)三个维度进行聚类,尝试发掘新的知识点。
主城区聚类分析根据主城区数据中性别、借阅时间和图书类别进行聚类,自动分成了10类,从聚类结果的分类剖面图可以看到各个变量的整体情况,比如从性别来看,中小学图书馆的借阅情况中,几乎男女借阅比例是五五比例,全年来看,借书月份按照从多到少排列,依次是12、11、10、3这几个月,12月是借书最多的月份。借书类别按照从多到少,依次是I、J、H、G类,其中最大的则为I类——文学类图书,但是分别看各类的情况,则差异较大,具体如图1所示。
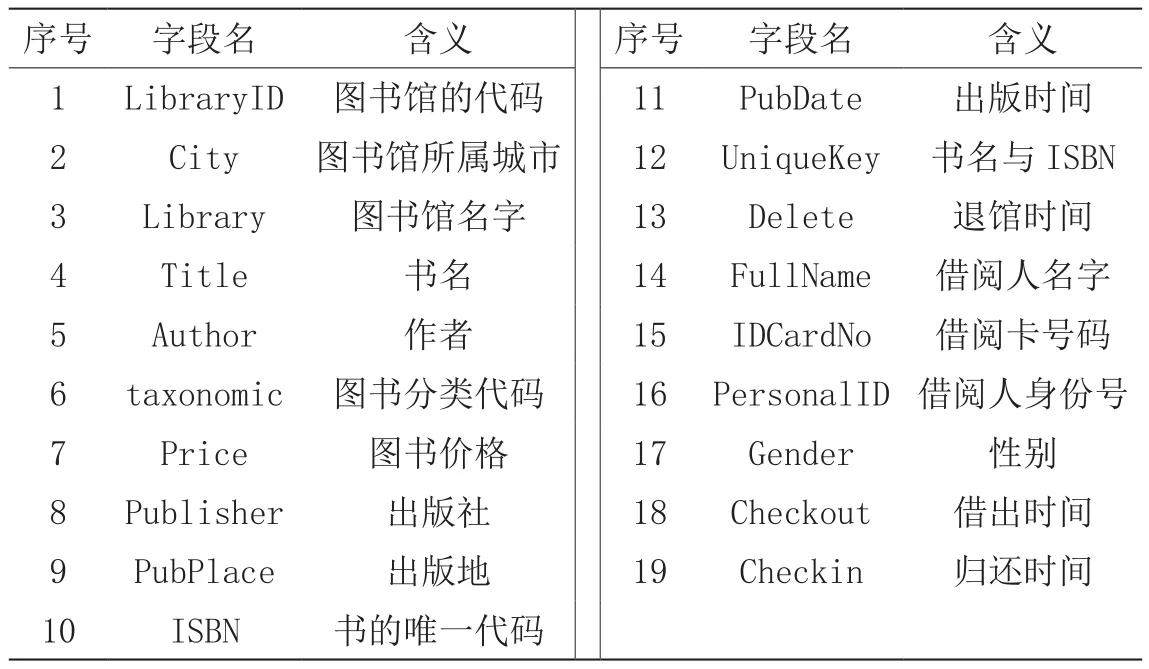
表1 数据挖掘字段

图1 主城区聚类分析分类剖面图
分类1:借阅人性别几乎都为男生,主要集中在10月和12月借书,借阅I类图书最多。
分类2:借阅人性别都是女生,主要集中在11月份借书,借阅书籍I类最多。
分类3:借阅人性别均为女生,主要集中在12月份借书,借阅类型I类最多。
分类4:借阅人性别几乎都为男生,借阅时间几乎都是11月,借阅类型I类最多。
分类5:借阅人性别均为女生,借阅时间主要都为10月,借阅类型I类最多。
分类6:借阅人性别几乎都为男生,但是没有在最集中借阅的3、10、11、12几个月中借阅,借阅类别最多的I类。
分类7:借阅人性别几乎都为男生,但是没有在最集中借阅的3、10、11、12几个月中借阅,借阅类别最多的I类。
分类8:借阅人性别上女生稍微多一些,但是没有在最集中借阅的3、10、11、12几个月中借阅,借阅类别最多的I类。
分类9:借阅人90%为男生,主要集中在3月进行借书,借书类型主要为I类。
分类10:借阅人性别基本为女生,都集中在3月份借书,其I类图书借阅比例也是最高的。
非主城区聚类分析对非主城区进行聚类,根据性别、借阅时间和图书类别聚类结果,也自动聚类成为了10类。从聚类结果的分类剖面图我们可以看到各个变量的整体情况,比如从性别来看,中小学图书馆的借阅情况中,几乎男女借阅比例是均衡的,全年来看,借书月份按照从多到少排列,依次是12、6、11、10几个月,12月是借书最多的月份。借书类别按照从多到少,依次是I、P、H、G类,其中最大的则为I类——文学类图书,但是分别看到各类的情况,则差异较大,具体如图2所示。
图2 非主城区聚类分析分类剖面图
分类1:借阅人性别都为女生,主要集中在12月借书,借阅I类图书最多。
分类2:借阅人性别都是男生,主要集中在12月份借书,借阅书籍I类最多。
分类3:借阅人性别均为女生,主要集中在11月份借书,借阅类型I类最多。
分类4:借阅人性别都为男生,借阅时间以10月为主,借阅类型I类最多。
分类5:借阅人性别都为女生,但是没有在最集中借阅的6、10、11、12几个月中借阅,借阅类别最多的I类。
分类6:借阅人性别都是女生,主要集中在10月份借书,借阅书籍I类最多。
分类7:借阅人性别均为男生,但是没有在最集中借阅的6、10、11、12几个月中借阅,借阅类别最多的I类。
分类8:借阅人性别都为男生,大部分借阅时间以11月为主,借阅类型I类最多。
分类9:借阅人性别都是女生,主要集中在6月份借书,借阅书籍P类最多。
分类10:借阅人性别都为男生,大部分借阅时间以6月为主,借阅类型P类最多。
聚类结果分析总体上看,主城区借书的男女总体比例基本均衡,借书的时间集中月份分别是12、11、10、3几个月,12月是借书最多的月份。借书类别主要集中在I、J、H、G类,其中最大的则为I类——文学类图书。非主城区男女借书比例基本均衡,借阅时间和图书种类两个维度不同,如表2所示。
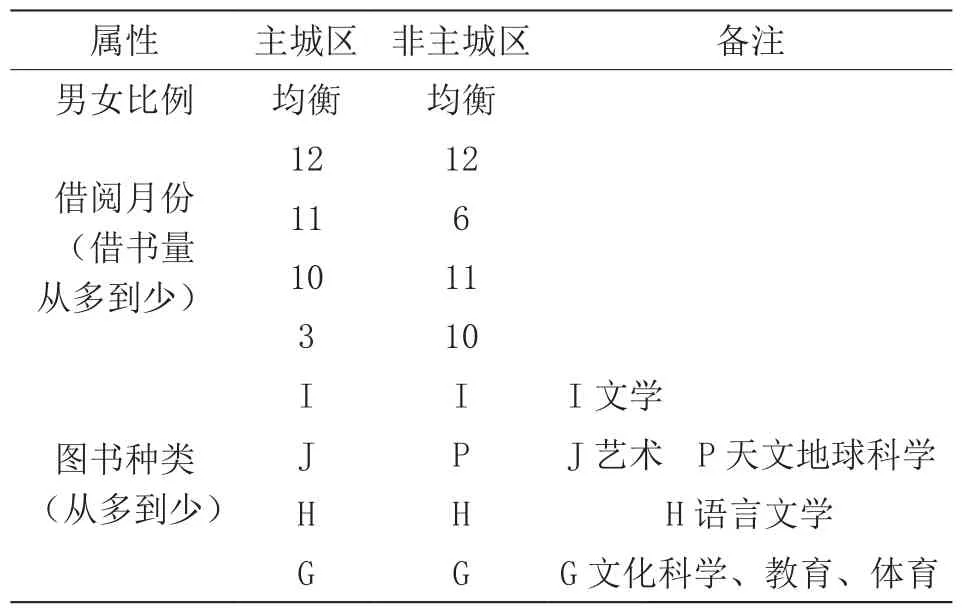
表2 主城区和非主城区聚类分析结果总体对照表
针对他们从总体上展现出来的不一样,尤其是读书的时间,虽然大体上都集中在12、11、10三个月,但是主城区3月借书的集中度排在第四,非主城区10月借书的集中度排在第二。
结合实际抽查访问,学生集中年末借书,跟气候、新的学期都很大关系,而3月和6月这两个数字,分别说明两个问题,主城区3月读书,是因为新学期开学和春天气候适合阅读,而非主城区6月借阅很多,却主要是因为暑假时间长,放假前学生假期阅读计划较多。
从两个结果来看,大致可以推断寒暑假对于主城区学生读书影响不大,但是这个也体现了另外一个问题,寒暑假期间图书馆不对学生开放非常影响学生阅读,也许寒暑假图书馆能够继续开放,我们能够得到完全不一样的结果。
我们再来看看借阅图书的类别情况,其实也很有意思。虽然都是一个城市,但是主城区和非主城区竟然在借阅种类集中度排名第二的类别上发生了不一样,主城区主要借阅类别集中度排名第二是J文艺,而非主城区借阅类别集中度排名第二是P天文、地球、科学。其他都一样,第一名是I文学类,第三名是H语言文学类,第四名是文化科学、教育、体育类。
主城区中小学生对于艺术的爱好相对较高,可能跟城市氛围有关,相对主城区的经济会较好,受到城市的艺术熏陶较多,毕竟通常主城区的艺术展会多于非主城区,而非主城区的孩子却对天文、地球、科学产生浓厚兴趣,也许跟他们相对主城区孩子,离自然更近的原因。
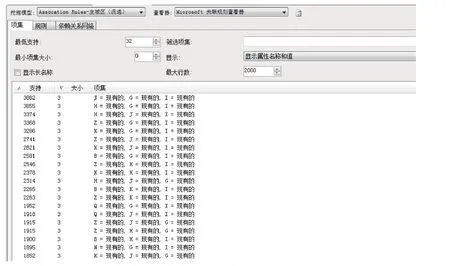
图3 频繁项集的样例图
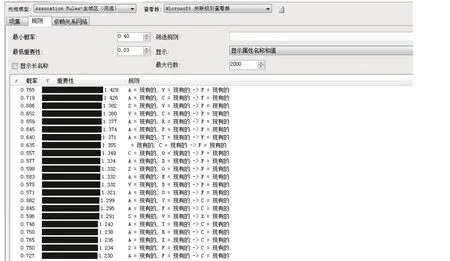
图4 主城区关联规则图(1)
关联规则关联规则主要是挖掘寻找给定数据集中,项之间的关联或相关度,揭示某种数据项间的未知依赖关系,运用关联规则可以从一个对象推断另一个对象。比如之前提到的尿布和啤酒的故事,超市通过这个算法发现买尿布的也会买啤酒,这种情况不是事先能够想到然后进行验证,产生关联规则的方法是找出数据库中的频繁项集,然后由频繁项集产生关联规则,为了判断关联规则的有效性。这种情况不是事先能够想到然后进行验证,产生关联规则的方法是找出数据库中的频繁项集,然后由频繁项集产生关联规则,为了判断关联规则的有效性,通常采用三个指标进行评价,分别是支持度(Support)、可信度(Confidence)和提升度(Lift)。其三个指标的含义分别是,支持度(Support)指的是对象包含的产品同时出现的概念;可信度(Confidence)指的是一个产品出现的同时,另一个产品出现的几率;提升度(Lift)是两种可能性的比较,也就是已知一个产品出现的同时,另外一种产品也出现的可能性,与任意情况下,这两个产品出现的可能性的概率比值或者差值。
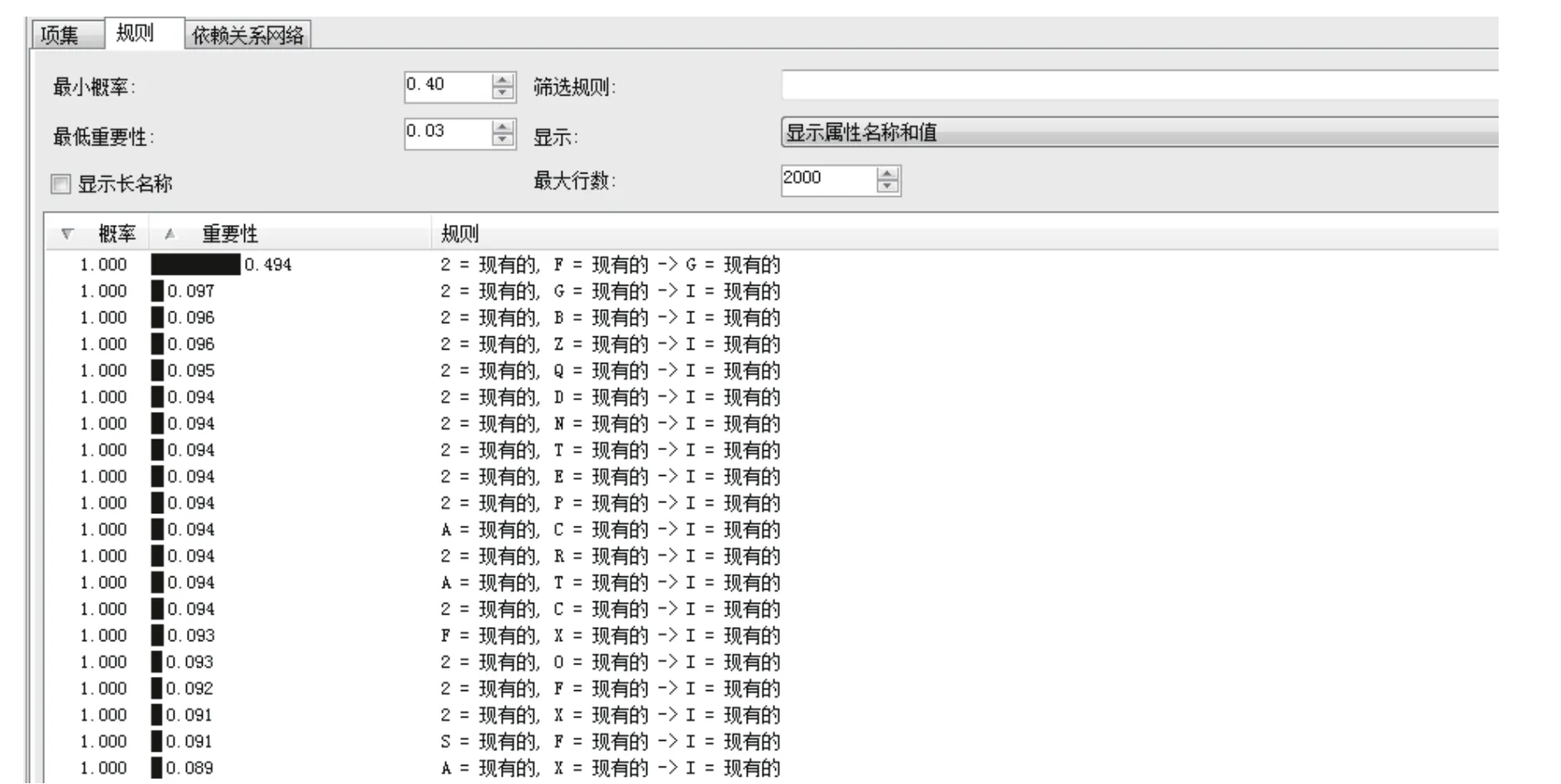
图5 主城区关联规则图(2)
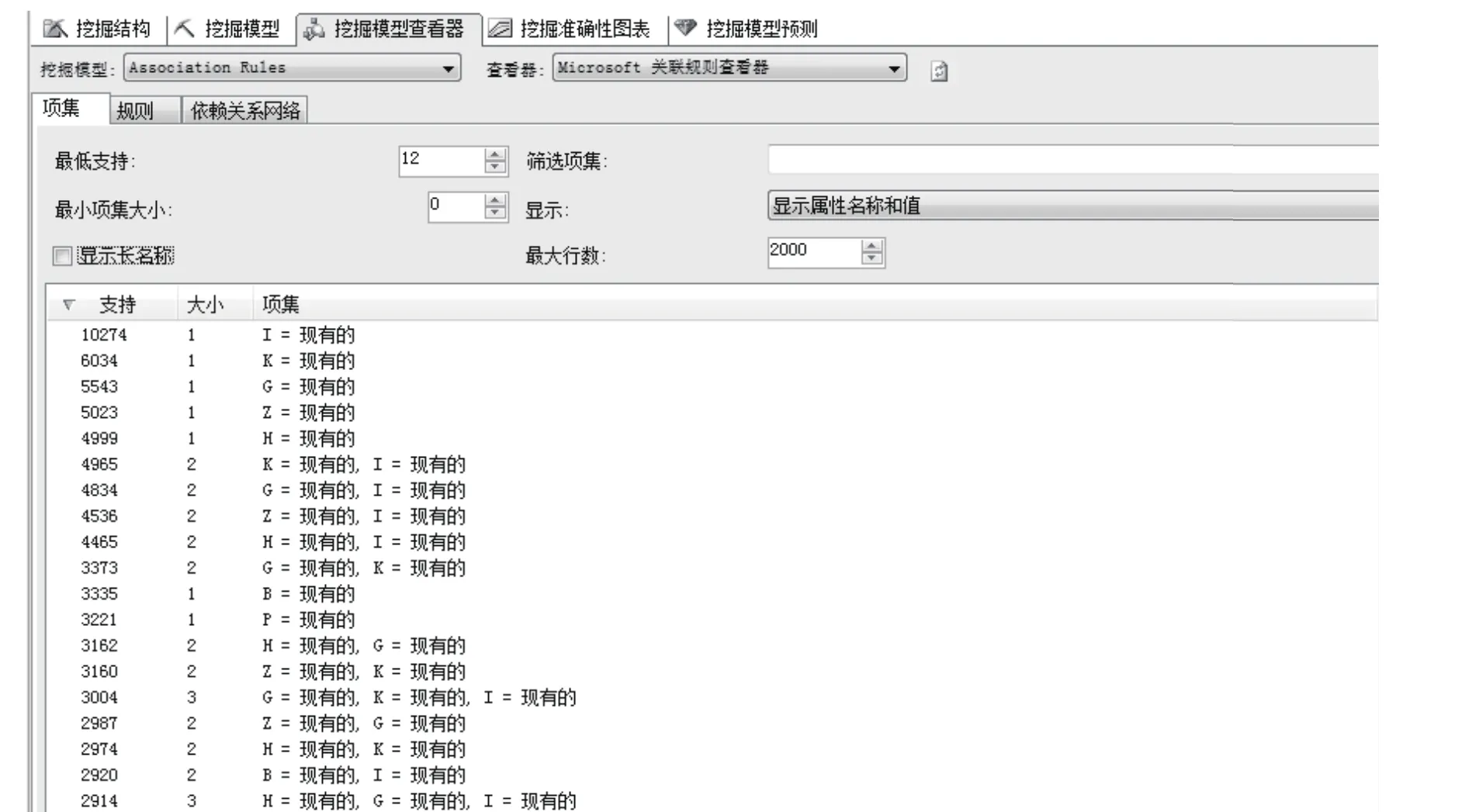
图6 非主城区关联规则项集图
本研究将从以上三个指标挖掘主城区和非主城区图书类别借阅之间的关联关系。
主城区关联分析基于关联规则挖掘模型对主城区的数据分析处理,可以获得复杂的项集及其依赖关系网络,如图3所示。
图3是频繁项集的样例图,显示了关联规则算法所挖掘出来的频繁项集,即是哪些类别的书出现的情况频繁支持度。可以看到,J、G、I类的支持度最大,为3862。根据其支持度从大到小排名,组合前十的为JGI、HGI、HJI、ZGI、KGI、ZJI、KJI、BGI、ZHZ、KHZ。
对于主城区的关联规则图,图4是按照重要性从重到轻进行了排序的,“重要性”指的是其后显示的预测规则可能的重要性。而图5是按照“概率”由大到小进行了排序的,“概率”就是指一个规则为真实的可能性。综合来看,主城区图书借阅不存在明显的关联规则。
非主城区关联分析基于关联规则挖掘模型对主城区的数据分析处理,可以获得复杂的项集及其依赖关系网络,如图6所示。
这幅图是频繁项集的样例图,显示了关联规则算法所挖掘出来的频繁项集,即是非主城区哪些类别的书出现的情况频繁支持度。可以看到I类一直独秀,支持度最大,为10274。

图7 非主城区关联规则图(1)
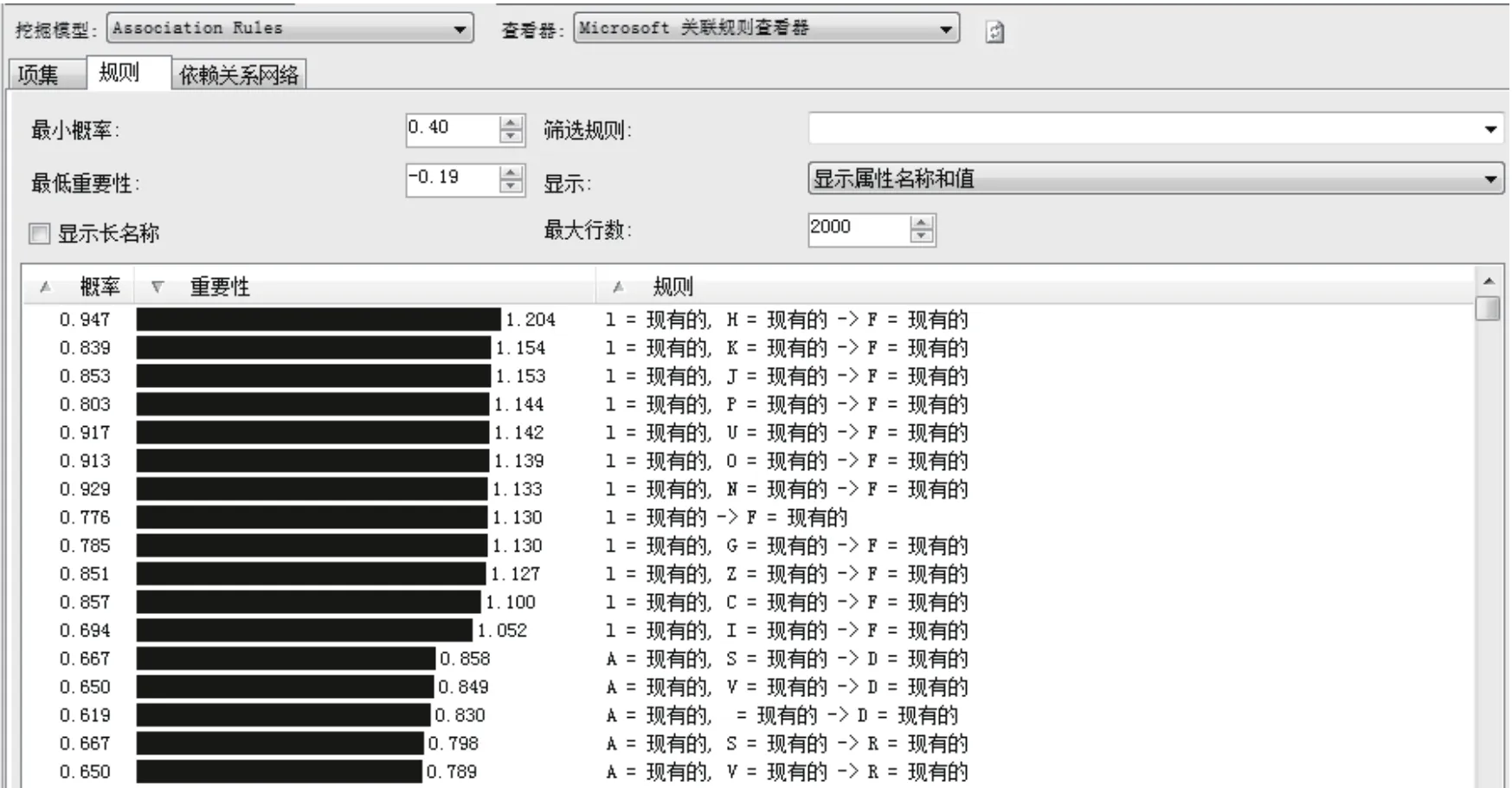
图8 非主城区关联规则图(2)
从非主城区常关联规则中置信度展示图分析,就是图7中的重要性指标,按照从大到小的顺序进行排序,可以清楚地看到每一种置信度的大小(图8)。从数据来看,借阅I类和H类后再去借阅F类图书的置信度是最大的。
关联结果分析关联规则分析需要结合多个指标,对产生的关联规则进行实际分析。我们在概念发生为100%里面重要性最高的规则进行实际分析。
主城区的关联结果显示借了Z综合类图书和F经济类图书的最容易再借G文化科学、教育、体育类图书;非主城区结果显示借了I类文学和H类语言文学类最可能借阅P天文、地球、科学类图书。
从这两个结果来看,非主城区的结果容易与聚类分析结果相联系,因为在非主城区在聚类分析时也显示出一个特点就是:中小学生阅读倾向明显在I、H、P这三类,再结合产生的这个关联规则,说明非主城区中小学的图书借阅类型比较固定,我们可以更加广泛的增加他们的兴趣爱好度。
再看看主城区的结果,Z类综合图书和F类经济图书都不在聚类分析的最受欢迎的几种类型图书里面,虽然G类文化、教育、体育图书进入了阅读类型集中度前四,但是也排在第四名,由此可以粗略的得出一个结论,主城区中小学学生图书类别借阅关联并不明显。再次回到主城区关联规则分析图进行分析,从重要性的从大到小到概率的从大到小,均没有出现像非主城区那样与聚类分析的类别集中度重合的类别出现。因此,大概可以得出一个结论,主城区中小学学生借阅图书相对没有太大的关联性,个人阅读集中度不高。
4 结论
数据挖掘技术在国际国内发展都非常迅速,目前在我们国家教育信息化方面的实际应用仍处于起步阶段,本文首次采用这样的方法分析基于一个省级图书平台的真实数据,分析维度不够全面,望能起到抛砖引玉的作用。相信在数据挖掘应用越来越广泛的背景之下,对我国图书教育资源的有效配置和管理,提高学生综合素质,减少工作人员工作强度,加强教育相关部门的管理控制都有重大意义。
[1]陈国青,卫强,商务智能原理与方法[M].北京:电子工业出版社,2009.9.
[2]Mark Levene, George Loizou. Why is the Snowfl ake Schema a good Data Warehouse Design[J].Information System,2003(3):225-240.
[3]徐澜.数据仓库和数据挖掘在成人高校决策中的应用[D].上海交通大学硕士论文,2007:5-6.
[4]王清明.SQL Server 2005数据仓库与Analysis Services [M].北京:清华大学出版社,2008.
[2]郭丽.SQL Server 2005构建数据挖掘解决方案[J].计算机与现代化,2007(5):1.
G258.69
B
1671-489X(2016)13-0076-07
作者:龙懿、田馨、代倩,四川省教育厅技术物资装备管理指导中心(610213)。
