基于关键词和支持向量机的财务大数据爬虫
2016-08-12王燕嘉
王燕嘉
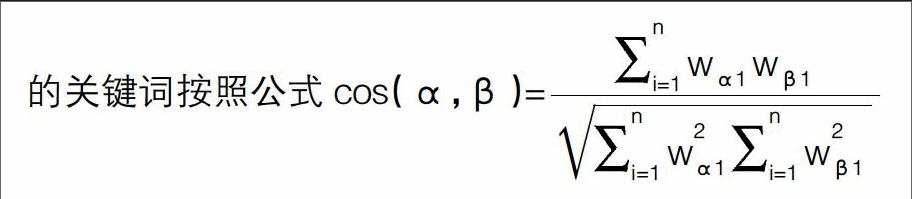

【摘 要】 从互联网上获取信息进行分析,已经成为人们进行决策的重要手段。有效地从海量数据中获取正确的目标信息是当前的重点和难点问题。通用搜索引擎检索的结果由于主题相关性不强,无法满足特定用户的需求。文章在改进SVM参数寻优算法的基础上,提出了结合关键词过滤算法和适用于大数据分类的支持向量机算法,并利用设计的财务管理相关主题信息分类算法,构建了财务管理相关主题爬虫系统。实验结果表明,基于关键词与改进支持向量机的财务管理主题相关爬虫能有效地采集目标信息,能够较好地适用于财务管理舆情管理和财务管理危机管理等相关领域。
【关键词】 大数据; 主题爬虫; 关键词; 支持向量机; 寻优算法
【中图分类号】 C939 【文献标识码】 A 【文章编号】 1004-5937(2016)16-0126-07
一、研究综述
由于网络技术的发展以及互联网服务的提升,大数据的容量得以爆发增长。据国际数据公司(IDC)公司统计,2011年全球被创建和被复制的数据总量为1.8ZB(1021)。远远超过人类有史以来所有印刷材料的数据总量(200PB)[1]。比较通用的搜索引擎如谷歌、百度等,强调搜索覆盖面积大,但结果并不精确。随着人们对各项信息服务的领域细化要求逐步提高,通用搜索引擎无法解决精确定位的问题,只能部分实现资源发现问题[2]。相对而言,主题爬虫能够以较好的方式,专注于抓取Web中与主题相关的网页,能够根据特定的网页分析算法过滤掉不相关的链接[3]。与通用搜索引擎相比,减少了对资源的消耗,并且支持扩张性的检索处理。主体爬虫核心是能够过滤网页中的前向链接,使爬虫聚焦在一个特定主题的Web子集中。通过某种策略获取网络信息的主题爬虫,是近年网络爬虫领域的研究重点[4]。能够高效聚焦的主题爬虫具有重要的实际意义。从财务管理角度看,财务管理为实现高效决策,从互联网上获取大量相关舆情信息来进行预警,已经成为财务管理风险管理的重要手段。目前财务管理采集信息主要还是人工采集为主,不足之处是需要投入一定的人力。提高采集相关信息效率,即在有限的资源条件下,尽可能有效获取财务管理主题相关信息,适应财务管理管理的各维度需求,是财务管理信息采集领域重要的研究内容。
传统的网络爬虫,一般是采取广度优先、深度优先或者两者结合的策略进行网页采集。按照传统的爬虫策略,优点是可以搜集到比较全面的信息,缺点是爬行速度比较慢,而且会采集大量与目标无关的网页。Chakrabarti[5]最先提出基于朴素贝叶斯分类模型的主题爬虫。引入分类器的爬虫可以通过分类算法实现预测主题的相关度,而不止停留在关键词匹配的简单计算上。在获取大量网络数据的过程中,网页分类是一项重要而有效的技术。网页分类技术由计算机根据特定算法自动分析网页文本内容,根据分析结果,网页将被划分到事先定义好的类别中。目前有很多文本分类算法,主要是依据统计学和机器学习方法,而支持向量机(Support Vector Machine,SVM)被普遍认为是一个较理想的分类算法。Gautam Pant[6]通过实验发现,基于SVM分类模型的主题爬虫效果较好。目前国内应用SVM算法的主题爬虫中,已经有林业主题爬虫、机械主题爬虫和化学主题爬虫等。多数采用SVM算法的主题爬虫,为了减少支持向量机工作量,提高效率,只对某一主题判断是非问题,即仅实现二分类。这种情况存在的原因是SVM不适用于大样本数据集,因为SVM参数寻优的时间过长。这就使现有相关主题爬虫的应用范围受到极大限制,无法满足财务管理对目标信息的多维度细化需求。财务管理主题相关爬虫把关键词匹配算法和SVM多分类算法相结合,在利用关键词规律初步减少支持向量机工作量的同时,对grid-search算法加以改进,使SVM能够处理大数据。充分利用SVM算法提高主题爬虫的准确率,从而使公司主题相关爬虫具有信息维度细化的性质,使爬虫具有更高的适用度。
二、适用于大数据的SVM参数寻优策略
传统SVM寻优搜索算法有网格搜索法、梯度法、模拟退火和遗传算法等。网格搜索是参数优化中应用最广的算法。它对多个参数的不同取值的所有组合,采用特定范围内遍历搜索,可以得到最优解,但需要耗费大量时间,以至于无法应用于大规模数据集处理。梯度法收敛速度较快,但又可能陷入局部最优,而且有目标函数对参数可微的限制条件。模拟退火等智能算法条件相对宽松,但在时间上相对太大,得到的解一般是近优结果。如何使SVM能够对大数据集进行训练和预测,解决这个问题无外乎两种途径,一种是加快寻优速度,另一种是缩小参数寻优范围。目前研究中,刘靖旭等的研究采用启发式搜索算法,可以小幅度降低寻优时间。但在大数据情况下,这种寻优时间的优势被淡化,而且有陷入局部最优的缺点。李明山等设计构造均匀试验,并采用偏最小二乘法回归来分析构造评价指标和各影响因素之间的关系,而线性和拟线性算法局限于经验风险最小。
就结果而言,grid-search即网格搜索算法是理想的选择,通过将待搜索指数在一定的空间范围内划分成网格,对网格中的所有参数组合进行遍历。理论上在寻优区间足够大、步距足够小的情况下,可以找出全局最优解。经验表明,在搜索过程中,大多数网格中的参数组合对应的准确率非常低。准确率高的参数组合集中在较小的区间内,遍历的时间绝大多数浪费在无效区间。目前,对SVM参数的选择优化算法的研究主要集中在两个方向,一个方向是避免网格搜索耗费的时间,可以利用具体问题的特点或者启发信息缩小参数搜索的范围,依此缩短参数寻找耗费的时间。另一个方向是采用各种智能算法,进行参数组合的深入挖掘,仍然需要对每一个参数组合进行训练并且检验其学习精度。在实际应用中发现,这种算法会比网格搜索更加费时。
如果在网格搜索算法的基础上,考虑进行多步搜索,可以先在大范围内,快速确定最优参数组合的位置,之后大致获得最优参数组所在的位置,便可以在较小的区域内进行遍历,是提高网格搜索效率的有效途径。根据这种思路,目前研究中有先以大步长在大范围内进行搜索,之后在小范围内详细搜索;也有采用双线性模式进行粗搜,之后在小范围内详细搜的算法。这两种方法都能够一定程度上提高网格搜索的效率,但在很大程度上,容易陷入局部最优的困境。
本文设计的big-data SVM Grid-search算法,采用基于蒙特卡罗随机多重网格搜索算法,它的主要思想是:首先,对惩罚系数c和核函数参数g确定一个较大的区间,之后设定较小的步长,在这个区间内,采用蒙特卡罗随机分布试验,设定n次重复试验;然后,利用K-CV方法对训练集进行测试,根据等高线图看出准确率最高的参数组合所在的位置;最后,在确定出来的小范围内,设定较小的步长,进行遍历搜索,最终确定准确率最高的参数组合。在参数选择过程中,最高的分类精度可能对应多组C和g的组合,在这种情况下,一般选择达到最高验证分类准确率中C最小的组合作为最佳参数组。
算法1:big-data SVM Grid-search算法
输入:区间范围和步长
输出:最优分类精度C、g组合
(1)确定网格搜索区间和搜索步长,在C和g的坐标系上构造二维空间。
(2)在二维空间中生成指定数量蒙特卡罗随机点。
(3)计算各随机点分类精度。
(4)If出现理想精度。
{确定较小网格搜索区间和搜索步长}
else return 2)
(5)构造较小网格搜索二维空间。
(6)逐个网格计算参数分类精度。
(7)确定最优分类参数组合。
算法1的目的在于提高SVM在处理大数据多分类时的参数寻优效率,是能够把SVM多分类引入爬虫系统,并且处理大数据的基础。
三、财务管理主题相关爬虫实现策略
财务管理主题相关爬虫采用关键词分析算法和支持向量机算法结合的策略。关键词分析是基于网页内容评价策略中比较常见的一种算法。关键词分析算法由专家或者根据经验给出具有代表性的关键词。根据网页中关键词的出现情况计算相关度。对网页的URLs赋予不同的相关度值,并使爬虫优先爬行相关度值高的网页。关键词法具有计算量小的特点,在判断具有单一关键词的宽泛主题网页时具有较大优势。缺点是在关键词不唯一的情况下,多个关键词所蕴含的真实主题很难被判断。
SVM算法引入爬虫的分类模型中,将使网页的相关度分析不局限于关键词匹配的层面,可以深层次地描述财务管理关注的主题信息,能够获得更加精确的网页主题相关度。支持向量机具有增量学习和自我学习能力,能够有效解决网页内容变化迅速而收集困难的难题。当前的SVM爬虫算法中,由于参数寻优在处理大数据时的效率问题,大多采用二类分类算法,即仅关注一个主题,只能判断是或者不是这个主题。无法对主题所涵盖的更为细化的维度进行分析,难以满足财务管理对信息获取的需要,所以这里将采用SVM多分类算法,实现主题内容的详细过滤分析。
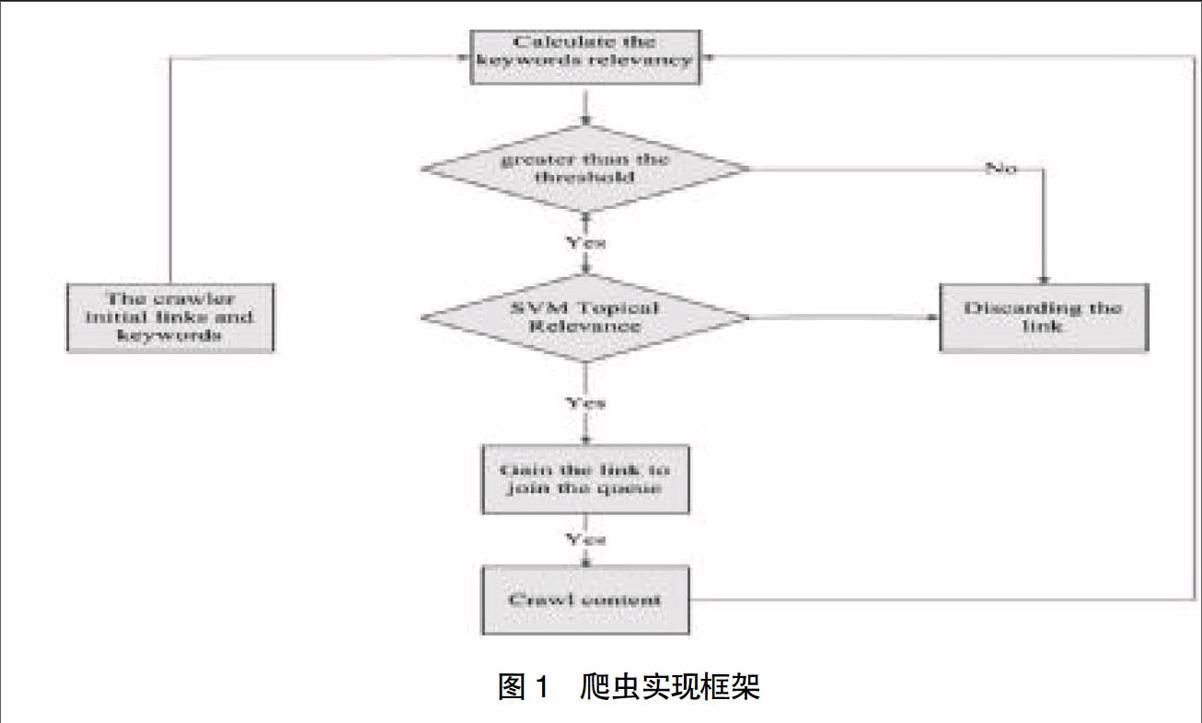
基于关键词和支持向量机的财务管理主题相关爬虫主要由两部分组成,分别是主题相关分析和网页抓取部分。主题相关分析部分决定页面的取舍和爬取的顺序,根据关键词来进行优先级排序,初步避免主题漂移[7],并且减少后续SVM的工作量。之后利用SVM多分类算法分析爬取内容,判断是否属于相关信息类别,最终聚焦关注内容。网页抓取部分从优先级最高的URLs爬取,相对于广度优先和深度优先结合的爬虫,爬取策略变为动态主题相关优先策略。具体实现框架如图1。
为了保证爬虫获取的网页能够尽量向主题靠拢,提高分类效率,必须对网页进行过滤,将主题相关度较低的网页(小于设定的阈值)剔除,这样就不会在下一步爬行中处理该页面中的链接。因为一个页面的主题相关度如果很低,说明该网页很可能只是偶尔出现某些关键词,而页面的主题可能和指定主题几乎没有什么关系,处理其中的链接意义很小,这是主题爬虫和普通爬虫的根本区别。普通爬虫是根据设定的搜索深度,对所有链接进行处理,结果返回了大量无用的网页,而且进一步增加了工作量。主题相关度的计算是采用余弦度量法。具体的做法统计网页中关键词出现的频率,然后与初始的关键词按照公式cos(α,β)=■
求余弦值,即可以得到该网页的相关度。其中把关键词的个数n作为空间向量的维数,每个关键词的权值作为每一维分量的大小,主题用向量表示为α=(α1,α2,…,αn),ai=wi对页面进行分析,统计关键词出现的频率,并求出频率之比,以出现频率最高的关键词为基准,其频率用i表示,通过频率比求出其他关键词的频率,则该页面对应的向量表示为β=(β1,β2,…,βn)。关键词约束仅粗略反映了关注主体的相关特征目标,因为关键词的选择是一个主观的过程,而且关键词有时候会包含在关注的各个主题中,不具有很强的区别性特征,不能保证所选择的关键词精准反映主体的特征,但是这个过滤过程起到了最大程度上减轻支持向量机工作量的作用。为了确保是要关注的相关信息,加入支持向量机,根据财务管理信息相关词典来进行判断。对属于财务管理信息分类的网页,指定一个阈值r,当cos(α,β)>r时就可以认为该页面和主题是比较相关的,r的取值需要根据经验和实际要求确定,如果想获得较多的页面,可以把r设小一点,要获得较少的页面可以把r设大一点。
网页数据的结构是半结构化的,较之内容更加注重格式。如果要表示一个网页,需要爬取搜集网页,然后将网页文件转化为文本来处理。向量空间模型就是其中被普遍承认成效较好的一种方法[8]。向量空间模型将文本空间等效为一组由正交相关的词条向量所组成的向量空间模型。设n是文本特征的总和,则可构成一个向量空间,其维数为n,每个文本可用一个n维特征向量来表示:
v(d)=(t1,w1(d);t2,w2(d);…tn,wn(d))
其中词条项的向量用ti来表示,ti在文本d中的权值用wi(d)表示。
在文本分类中,文本集需要通过分词后变成词集,去掉停用词得到特征集。此时的特征集是一个高维的特征空间,一般情况下需要采取文档频率方法、信息增益等进行降维。
四、算法实现
为了实现不同的主题信息获取,要预先建立相应的财务管理相关主题的语料库。一般来说语料库的质量将对信息的分类和过滤产生决定性的影响。财务管理主题相关爬虫算法主要有以下三个部分:
算法2:关键词匹配算法
输入:关键词和阈值
输出:大于阈值的链接
(1)中文分词。
(2)统计关键词词频。
(3)计算关键词网页相关余弦值。
(4)比较阈值与余弦值。
(5)if大于阈值,网页链接插入爬虫队列。
else 过滤掉网页链接
算法2可以初步锁定关注的主题,同时,可以大幅度地减少SVM分类所要处理的数据量。
算法3:SVM模型分类算法
输入:语料库
输出:预测结果
(1)初始化输入语料库。
(2)for all语料库文件生成向量空间模型do。
(3)big-data SVM gridsearch寻优。
(4)选择惩罚因子C和类型权重r,对训练集进行训练。
(5)选择待预测集。
(6)return预测结果D。
算法3对爬虫获取的结果进行多层次的分类,保证最终获得目标主题的准确性。
算法4:基于SVM的主题爬虫算法
输入:初始URLs
输出:主题相关URLs
(1)关键词和初始URLs设置。
(2)根据关键词进行URLs排序。
(3)判断是否大于阈值。
(4)if大于阈值。
{if 经过SVM分类符合目标 jump to 5)
else 过滤掉链接}
else 过滤掉链接
(5)获取URLs,return to 2)。
爬虫中不同的语料库将决定爬取的网页类别,设置的语料库可以根据财务管理所需要爬取的目标进行更换。
五、实验分析
实验设计:SVM分类相关的研究的实验数据是从搜狐网站上提取的网页内容(一共取得3 000篇文章),经过文本向量空间处理,分成13类,经过训练构成分类字典。采用java语言实现爬虫,计算机环境为Windows XP系统。
(一)大数据分类器参数寻优实验分析
为测试SVM分类器分类效果,提取390篇文章进行训练和测试,通过向量空间生成并剔除停用词向量。最终文本向量分布如图2。
390篇文章中35个向量属性值分布如图3。
实践证明,核函数的参数g以及惩罚系数c对SVM的性能有很大影响,因此这里以均方误差最小为评判标准,为能够使big-data SVM grid-search算法和传统算法进行比较,首先采用传统的网格搜索方法遍历SVC模型参数c、g组合(步长均为1),为方便训练模型,采用libsvm工具箱,模型训练采用svmtrain函数建模,以svmpredict预测,搜寻到一组最优参数组合。见图4。
从图5和图6中可以发现,不同的参数选择,对SVM的分类效果有较大影响。在一定区间内,对应的分类准确率可以达到很高的水平,而在其他一定区间内,有些分类准确率很低,现实中是无法接受的。
对比图5和图6可以发现,传统的grid-search算法大量时间耗费在分类准确率不高的参数组合区域。而从图7和图8能够看出,采用big-data SVM grid-search算法的运算次数少,因此耗费时间非常短,而且根据算法,只要采取多次蒙特卡罗随机分布点试验,可以取得与传统算法同等的高精度区域。
从粗分等高线图上可以看出,高精度区域集中的区域。在这个区域中,为了防止对最优参数组合的遗漏,可以缩小步长,这里设步长为0.5,进行在好区内的网格搜索。
图4—图7反映了参数寻优的中间确定好区的状态,寻优最终结果通过图8和图9可以发现,Best Cross Validation Accuracy=96.9543% Best c=8 Best g=0.707107,即核函数参数取0.7,惩罚因子取8时,能够获得最佳的分类准确度。当然,核函数参数和惩罚因子在适当的范围内取数所得到的准确率,大体是都可以接受的。在这个过程中,由于大数据造成的大范围搜索已经在之前进行了处理,在好区内的网格搜索由于区间范围已经很小,即使进行步长较小的详细搜索,也能够控制大量的计算过程和时间上的耗费。
参数寻优后,根据最优的参数组合,对训练文档之外的文档集进行预测。检验SVM分类的现实准确程度。
实验中先除去训练用的文档,对剩余的进行预测,学习误差如图10,可以看出,有一部分星点落在了圆圈之外,即有一些预测没有和实际分类符合,但从整体上来看,SVC的预测准确率很高,可以认为在实验样本中,SVM方法可以准确地区分文章的所属类别。
通过实验,可以看出在本文设计的big-data SVM grid-search算法支持下,避免了SVM在处理大数据集分类时效率太低而导致无法适应实际应用的情况。从此把SVM多分类算法引入爬虫系统,提高主题爬虫的效率,成为一种可能。
(二)爬虫实验分析
在根据关键词和支持向量机算法开发的上市主题相关爬虫程序中,假设某财务管理比较关注云计算的新闻有关的具体网页,同时假设该公司在爬虫程序中初始网页地址设置为http://cloud.csdn.net/,一级网址总数设置为100个。关键词主题相关度阈值设置为0.9。关键词采用(架构隐私cloud安全数据中心Hadoop虚拟化黑客MapReduce分布式平台存储云计算数据库),通过这些关键词过滤后再进行SVM分类,然后对符合条件的URLs进行爬取。在程序中设置跟踪变量,可以获取爬取过程中过滤情况。当采用普通爬虫算法时,在限定时间内共可以获得网页4 253个。如果加入关键词相关度算法,可以被过滤掉1 887个网页。因此关键词算法的加入可以提高44%的效率。在关键词过滤的基础上,通过SVM进行维度的细分,最终发现通过关键词检验的网页中,汽车类信息1个网页,商务类信息62个,文化类信息1个,健康类信息1个网页,房产类213个,IT技术类370个,教育类1个,军事类1个,新闻类1 337个网页,运动类370个,旅行类1个,女人话题类1个,娱乐类7个网页,从而经过SVM过滤的爬虫效率再次提高24%。
如果财务管理要关注的主题是13个分类中的其他某一类,将会过滤掉更多的无关网页,比如只关注运动类,最终将只有370个有效网页,其余的无关网页都将被排除。这说明加入了关键词和SVM算法的财务管理主题爬虫准确率要远高于单纯的关键词算法爬虫。同时,通过SVM多分类算法,可以灵活地聚焦于上市所关注主题的13个细化维度,甚至可以根据所建立的字典,扩展至任意多个维度,如表1。
六、结论
作为网络信息获取工具,爬虫技术近年来被越来越多的研究者所重视。通过把关键词过滤算法和big-data SVM grid-search算法加入爬虫程序中,从减少数据集总量和快速实现网格寻优的角度,解决了SVM多分类方法处理大数据效率低下的问题。构造财务管理相关主题爬虫,通过实验表明,基于关键词和big-data SVM grid-search的主题爬虫在爬准率上要明显高于普通爬虫,而且能够通过主题字典的设置,满足财务管理对多层次主题信息的细化维度采集。
【参考文献】
[1] LI Guo-jie. the scientific value of the big data study [J].China computer society communication,2012.(9):103-105.
[2] Du An,et al. A decision tree-based web mining system for Chinese pages. Advances of Search Engine and Web Mining in China[M]. Beijing:Higher Education Press.2003.
[3] HECTOR G M.Crawling the Hidden Web[C]. Proceedings of the 27th International Conference on Very Large Data Bases,September 2001.
[4] MENCZER F, PANT G. Evaluating Topic- Driven Web Crawlers [C] Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York,2001:9-12.
[5] CHAKRABARTI B,et al. Indyk.Enhanced hypertext categorization using hyperlinks[C]. Proceedings of the ACM SIGMOD International Conference on Management of Data,1998.
[6] PANT G,et al. Panorama: Extending digital libraries with topical crawlers[C]. Proceedings of the 2004 Joint ACM/IEEE Conference,2004.
[7] MENCZER F, et al. Evaluating topic- driven web crawlers[C] //Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New York,2001:241-249.
[8] SALTON G, WONG A, YANG C. A vector space model for automatic indexing[J]. Communications of ACM,1995,18(11): 613-620.
