基于误差校正的能源消费总量预测方法
2016-08-08董明刚
艾 兵, 董明刚
(桂林理工大学 信息科学与工程学院,广西 桂林 541004)
基于误差校正的能源消费总量预测方法
艾兵, 董明刚
(桂林理工大学 信息科学与工程学院,广西 桂林541004)
摘要:鉴于能源消费量具有趋势性、非平稳性等特点, 而差分自回归移动平均模型(ARIMA)只能反映能源消费量的部分信息, 预测结果不太理想。为了提高预测精度, 提出了基于二次误差校正ARIMA模型的能源消费预测方法:首先采用ARIMA模型对能源消费总量进行初步预测, 然后构建偏最小二乘回归支持向量机模型(PLS-SVM)对残差序列数据中未被解释的部分进行分析和拟合, 并对未来的残差进行预测。最后利用所得残差预测值对能源消费总量预测值进行校正。对福建省1978—2012年的能源消费总量数据进行仿真, 实验结果表明, 与ARIMA等方法相比, 本文提出的方法获得了较好的预测结果, 是一种有效的能源消费量预测方法。
关键词:二次误差校正;ARIMA模型;偏最小二乘回归;支持向量机;能源消费量
0引言
能源是人类社会赖以生存和发展的重要物质, 攸关国计民生和国家安全。能源消费量直接影响能源供需缺口, 也关系到国家的能源安全问题[1]。而能源消费量的预测是制定能源发展战略的基础, 其预测结果的好坏直接与国家或地方经济发展息息相关[2]。因此, 对我国历年能源消费量的变化情况进行研究, 并通过构建准确有效的预测模型对未来能源消费量进行科学预测, 为国家能源安全战略规划提供理论依据和决策参考, 对全社会的可持续发展具有十分重要的意义。
为了科学预测能源消费量, 国内外学者进行了大量的研究。Lee等[3]通过引入遗传编程符号估计的误差校正对灰色预测模型予以改进, 利用改进的模型对中国能源消费进行预测;付立东等[4]综合遗传算法和模拟退火算法的各自优势, 提出了一种新的遗传算法和模拟退火算法的混合方法来预测中国能源需求;张松等[5]将经验模式分解分析与支持向量机相结合, 提出新的能源消费预测思路;卫太详等[6]利用差分插值和高阶Newton-Cotes公式构造背景值, 提出基于改进背景值构造方法的GM(1, 1)能源消费预测模型; Uzlu等[7]将人工神经网络(ANN)与教学-学习算法(TLBO)相结合, 建立ANN-TLBO模型对土耳其能源消费进行预测。虽然上述模型对能源消费量的预测具有很好的价值, 但仍存在某些不令人满意的地方。比如,灰色预测模型虽然原理简单, 但它具有适应性不强和难操作等问题;多种模型的组合会增加算法复杂度, 在一定程度上影响建模的精度和效率。神经网络算法是基于经验风险最小的原则, 具有容易陷入局部最优的缺陷,且它需要较多的基础数据对其进行训练和检测。另外, 一般的ARIMA模型[8-10]在预测时没有充分考虑误差的影响因素及其内部规律, 从而使预测结果不太理想。
因此, 本文鉴于能源消费系统的复杂性和非线性等特点, 提出基于二次误差预测校正的差分自回归移动平均(autoregressive integrated moving average, ARIMA) 模型的能源消费量预测方法, 即在文献[11-12]中引入误差思路的基础上, 将二次误差校正思想理念引入本文预测模型中, 以此提高模型的整体预测精度。由于ARIMA模型得到的预测值与实际值所产生的残差呈现趋势性, 其中可能包含未被解释的成分, 因此在对其进行处理的过程中, 必须将其影响因素的内部规律予以挖掘处理。鉴于偏最小二乘回归支持向量机模型(partial least squares regression-support vector machine,PLS-SVM) 较文献[11-12]中的回归分析等方法具有较好处理非线性多因素问题的优点, 故运用PLS-SVM建立残差与其影响因素的回归模型, 充分利用误差值中所蕴含的有价值的信息, 实现利用未来影响因素的变化对残差作精确预测, 从而建立一套基于二次误差校正的PLS-SVM-ARIMA的预测模型体系, 以进一步提高预测精度。能源消费量预测的算例分析表明, 与ARIMA等预测方法相比, 本文所构建的模型能获得较好的预测结果, 进而验证了该模型的可行性和有效性。
1相关技术介绍
1.1ARIMA模型建模原理和步骤
ARIMA模型是一种精度较高的时序短期预测方法, 其基本思想是将预测对象形成的时间序列视为一个随机序列, 可以用相应的数学模型近似描述[8]。通过对其分析研究, 能够根据时间序列的历史数据和现在数据预测未来值, 从而达到最优预测。ARIMA模型的公式定义为
φ(B)(1-B)dxt=θ(B)at。
(1)
式中: d为差分阶数; xt为能源消费量历史数据序列; at为白噪声序列; B为后移算子; φ(B)为自回归算子; θ(B)为移动平均算子。
构建ARIMA(p, d, q)模型一般有以下4个步骤[8-10]:首先,通过观察时序图和严格的单位根检验确定阶数d;然后,由自相关系数等能够描述时间序列特征的统计量初步确定模型类型和滞后阶数p与q;再者, 利用有效统计方法估计模型参数,并根据AIC最小等准则确定最终模型并对模型的拟合效果进行检验;最后, 根据所得到的ARIMA模型对未来信息进行预测。
1.2PLS-SVM残差预测方法
利用高维特征空间里的线性估计函数[13-16]y=f(x, ω)=ωTφ(x)+b(ω为权值矢量,b为偏置项)来拟合训练数据集(xi,yi), 其中:i=1, 2, …,n,xi∈Rn×1为n维训练样本输入,yi∈R为相应的输出变量。
根据结构风险最小化原理, 将回归问题转变成约束优化问题, 可表示为[13-14]

(2)
s.t.yi=ωTφ(xi)+b+ξi,i=1, 2, …,n,
引入拉格朗日乘子αi(αi∈Rn×1)建立拉格朗日函数[13-16]:


(4)
根据Karush-Kuhn-Tucker(KKT)最优条件, 对式(4)求偏导,并令其偏导数为零;再由Mercer条件, 采用径向基核函数(radial basis function, RBF)[13]作为核函数代替非线性映射, 故拟合函数f(x)可描述为[13-16]

i,j=1, 2, …,n。
(5)
其中:σ为径向基核函数参数。
PLS-SVM方法[12-13]主要是基于将经过特征提取得到的各个主成分向量组成的得分矩阵代替原有的输入矩阵, 其建模过程如下:
①根据偏最小二乘回归模型得到训练样本的得分矩阵Ttrain=[t1,t2,…,th], 负载矩阵p=[p1,p2,…,ph]和相关系数矩阵w=[w1,w2,…,wh]。
②用ytrain=[y1,y2,…,yn]T和步骤①中的Ttrain对SVM进行训练, 得到参数最优的拉格朗日乘子αi和偏置项b。建模后可得求解式为

(6)
式中: 1为矩阵元素都为1的n×1矩阵; I为n×n单位矩阵;Ω为核函数; α=[α1,α2, …,αn]T。
③由步骤①中的负载矩阵p, 相关系数矩阵w和待测输入量xtest可计算出测试样本为
Ttest=xtestp(wTp)-1,
(7)
于是, 预测模型为

(8)
式中: ti为训练样本的得分向量, t为测试样本Ttest的得分向量。
2能源消费量预测建模流程


③ 残差校正。利用所得到的二次误差预测值对残差预测值进行校正, 从而形成校正后的残差序列预测值为
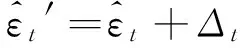
(9)
④ 预测值校正。将校正后的残差序列预测值与步骤②的能源消费量预测值相结合, 最终的能源消费量预测结果为

(10)
综上所述, 基于二次误差预测校正的ARIMA预测模型的建模过程和能源消费预测过程分别如图1和图2所示。
3案例分析
3.1训练样本数据的选取及其预处理
本文以中国经济与社会发展统计数据库中福建省1978—2012年的能源消费量数据(单位:万t标准煤)作为研究对象, 选取前32年的样本数据作为训练集, 构建ARIMA预测模型, 后3年的样本数据作为预测集。
根据能源消费量的历史数据资料, 参考文献[8-10]中的ARIMA的原理和建模方法, 利用Matlab软件进行编程, 通过计算自相关函数和偏相关函数[10], 确定阶数d为1。故可设定ARIMA(p, 1,q)多种匹配方式, 具体见表1。

利用上述模型对福建省1978—2009年能源消费量进行拟合, 结果如图3所示。
根据图3得出福建省能源消费量实际值和拟合值之间的残差值走势图(图4)。
由图4观察知,残差存在波动现象, 其中可能包含未被解释的成分。影响残差的因素较多, 考虑到统计资料在实际情况下的可收集性, 根据文献[17-18],并参考西方经济学的消费需求理论, 以货物进出总额、国内生产总值、重工业和轻工业比例、从业人口数、煤炭占能源消费总量的比重、石油煤炭占能源消费总量的比重、第二产业国内产值占国民经济的比重、第三产业国内产值占国民经济的比重等8个因子作为影响残差因素, 所有数据均来自福建省统计年鉴。
采用偏最小二乘法对影响因素进行预处理,即从8个影响因素中提取对残差解释最强的主成分。根据交叉有效性理论及方法确定成分个数(表2)。

图1 建模过程Fig.1 Procedure chart of modeling
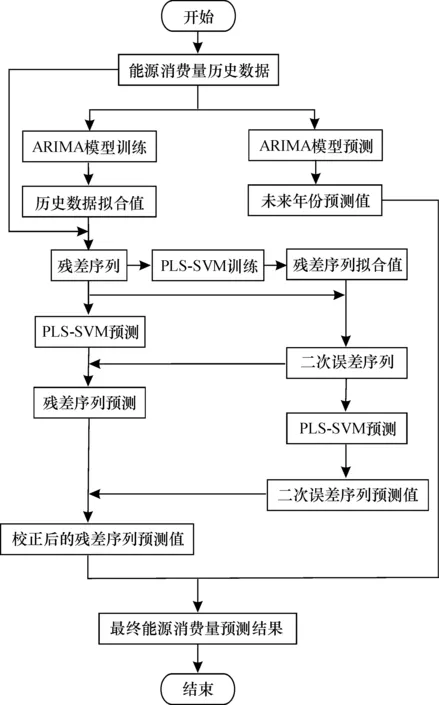
图2 能源消费预测过程Fig.2 Prediction process of energy consumption

序号ARIMA(p,d,q)AICBIC1ARIMA(0,1,0)451.541590454.4095652ARIMA(0,1,1)446.191167450.4931293ARIMA(0,1,2)448.938462454.6744104ARIMA(1,1,0)438.009570442.3115315ARIMA(1,1,1)435.997193441.7331426ARIMA(1,1,2)437.134612444.3045487ARIMA(2,1,0)435.934879441.6708288ARIMA(2,1,1)437.423316444.5932529ARIMA(2,1,2)444.644467453.248390
由表2知,前3个成分自变量累积贡献率为97.850 9%, 故只要取3对即可有效完成成分个数的选定。将主成分提取数据和残差分别作为支持向量机的新样本输入和输出, 采用提出的支持向量机的参数优化方法,计算并确定正则化参数ν和径向基核函数的参数σ2分别为62.1、40.96时可得到较优的训练结果, 并对预测集进行预测, 训练结果和预测结果分别如图5和表3所示。

图3 福建省1978—2009年能源消费量的 ARIMA模型拟合结果Fig.3 Fitting results of energy consumption by ARIMA model in Fujian from 1978 to 2009 using

图4 残差趋势曲线Fig.4 Trend curve of residual

序号贡献率累积贡献率180.199780.199722.801483.0011314.849897.8509

表3 PLS-SVM的残差预测结果Table 3 Residual prediction results by PLS-SVM
3.2校正结果分析
根据表3所得到的校正后的残差预测值对由ARIMA模型得到的2010—2012年能源预测值进行校正, 即得到最终的能源消费量预测值(表4)。

表4 二次误差预测校正后的能源消费量预测结果Table 4 Prediction results of energy consumption after twice error adjustment

图5 径向基核函数PLS-SVM预测的误差Fig.5 Error curves of prediction value by PLS-SVM with RBF
3.3 模型性能对比分析
为了验证本文所构建模型的有效性和可行性, 将其与ARIMA模型、基于一次误差的ARIMA模型、AR(2)模型、 文献[19]中的ARMA-PSO-GM(1, 2)模型[19]的预测结果进行比较。
为了从定性方面来评价本文所构建模型的性能, 图6给出了ARIMA模型、 基于一次误差的ARIMA模型、 AR(2)模型,ARMA-PSO-GM(1, 2)模型和本文所构建的预测方法这5种方法的预测值与能源消费量实际值的对比结果。 由图 6可以看出, 本文提出的方法所得到的结果较前3种预测方法更接近能源消费量实际值, 预测精度有了较好的提高。
本文采用MRE(平均相对误差)和RMSE(均方根相对误差)作为定量评价模型的性能指标, 其定义如下:

图6 能源消费量预测结果与实际值对比Fig.6 Comparison of energy consumption between predicted and actual results 注: Ⅰ—能源实际消费量; Ⅱ—ARIMA模型预测值;Ⅲ—一次误差的ARIMA模型预测值;Ⅳ—AR(2)模型预测值;Ⅴ—ARMA-PSO-GM(1, 2))模型预测值;Ⅵ—本文方法预测值。
Table 5Comparison among prediction results of different models

万t标准煤

(11)

(12)
从表5的比较结果可以看出,本文方法的误差指标MRE和RMSE分别为2.74%和2.86%, 而一般的ARIMA模型的MRE和RMSE分别为4.52%和4.64%, 基于一次误差校正的ARIMA模型的MRE和RMSE分别为2.84%和2.99%, AR(2)模型的MRE和RMSE分别为3.65%和3.93%, ARMA-PSO-GM(1, 2)模型的MRE和RMSE分别为2.82%和2.96%。因此, 本文提出的方法预测效果最好, 一定程度上提高了预测精度。
4结束语
本文在分析一般能源消费量预测方法的基础上, 将二次误差预测校正理念引入ARIMA模型中, 提出了基于二次误差校正ARIMA模型的能源消费量预测方法, 以此提高预测结果的精确性。在处理误差过程中, 由于误差受到诸多因素的影响, 考虑到PLS能够有效地消除影响因素间的多重相关性, 并且SVM具有克服数据的线性和非线性组合的局限的优点, 故将二者相结合对预测过程中产生的误差进行分析和预测, 为能源消费量的预测提供一个新的有效方法。实验结果表明, 本文所建立的模型相对于ARIMA模型、 基于一次误差的ARIMA模型、AR(2)模型及ARMA-PSO-GM(1, 2)模型等具有较好的预测效果。
参考文献:
[1]李红梅, 贺昌政, 肖进.基于Log-GMDH模型的我国能源消费中长期预测[J].软科学, 2012, 26(5):51-54.
[2]孙涵, 杨普荣, 成金华.基于Matlab支持向量回归机的能源需求预测模型[J].系统工程理论与实践, 2011, 31(10):2001-2007.
[3] Lee Y S, Tong L I .Forecasting energy consumption using a grey model improved by incorporating genetic programming[J].Energy Conversion and Management, 2011, 52(1):147-152.
[4]付立东, 张金锁, 冯雪. GA-SA模型预测中国能源需求[J].系统工程理论与实践, 2015, 35(3):780-789.
[5]张松, 金亮.中国能源消费的EMD分析与预测[J].数学的实践与认识, 2011, 41(12):114-119.
[6]卫太详, 马光文.基于改进背景值构造方法的GM(1, 1)能源消费预测模型[J].水电能源科学, 2011, 29(6):190-192.
[7]Uzlu E, Kankal M, Akpinar A, et al.Estimates of energy consumption in Turkey using neural networks with the teaching-learning-based optimization algorithm[J]. Energy, 2014, 75(1):295-303.
[8]张雨浓, 劳稳超, 丁玮翔,等.基于ARIMA与WASDN加权组合的时间序列预测[J].计算机应用研究, 2015, 32(9):2630-2633.
[9]孙佚轩, 邵春福, 计寻,等.基于ARIMA与信息粒化SVR组合模型的交通事故时序预测[J].清华大学学报:自然科学版, 2014, 54(3):348-353.
[10]司守奎, 孙玺菁.数学建模算法与应用[M].北京:国防工业出版社, 2011:157-175.
[11]于志军, 杨善林.基于误差校正的GARCH股票价格预测模型[J].中国管理科学, 2013, 21(S1):341-345.
[12]刘达.基于误差校正的中长期负荷预测模型[J].电网技术, 2012, 36(8):243-247.
[13]Kaytez F, Taplamacioglu M C, Cam E, et al.Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines[J].International Journal of Electrical Power & Energy Systems, 2015, 67(1):431-438.
[14]侯利强, 杨善林, 陈志强.基于遗传优化偏最小二乘支持向量机的税收预测研究[J].科技管理研究, 2014, 34(11):198-200.
[15]吉训生.基于偏最小二乘支持向量机的短期电力负荷预测方法研究[J].电力系统保护与控制, 2010, 38(23):55-59.
[16]Abbasi M, Abduli M A, Omidvar B, et al.Forecasting municipal solid waste generation by hybrid support vector machine and partial least square model[J]. International Journal of Environmental Research, 2013, 7(1):27-38.
[17]Unakitan G, Turkekul B.Univariate modelling of energy consumption in Turkish agriculture[J].Energy Sources Part B:Economics Planning and Policy, 2014, 9(3):284-290.
[18]孟凡生, 李美莹.我国能源消费影响因素评价研究——基于突变级数法和改进熵值法的分析[J].系统工程, 2012, 30(8):10-15.
[19]王瑞庆, 李渝曾.含误差校正的粒子群优化GM(1, 2)短期电价预测方法[J].电力系统保护与控制, 2011, 39(13):41-45.
[20]张善文, 雷英杰, 冯有前.MATLAB在时间序列分析中的应用[M].西安:西安电子科技大学出版社, 2007:130-150.
文章编号:1674-9057(2016)02-0388-07
doi:10.3969/j.issn.1674-9057.2016.02.034
收稿日期:2015-04-03
基金项目:国家自然科学基金项目(61203109);广西自然科学基金项目(2014GXNSFAA118371)
作者简介:艾兵(1990—),男,硕士研究生,研究方向:智能计算,835027279@qq.com。
通讯作者:董明刚,博士,教授,d2015mg@qq.com。
中图分类号:TP301.6
文献标志码:A
Prediction method of total energy consumption based on error adjustment
AI Bing, DONG Ming-gang
College of Information Science and Engineering, Guilin University of Technology, Guilin 541004,China)
Abstract:Autoregressive integrated moving average model (ARIMA) can only reflect part of the information of energy consumption with the characteristics development of trends,non-stabilities and unsatisfactory predictions. In order to improve the prediction accuracy, the prediction method of energy consumption is proposed based on the twice error adjustment ARIMA model. Firstly, ARIMA model has a preliminary forecast on total energy consumption. Then partial least squares regression support vector model (PLS-SVM) is built for unexplained residual sequence data analysis and fitting of parts,to predict the residual error of the future. Finally, total energy consumption will be corrected through the prediction value obtained by the residual error. The total energy consumption data simulation results from 1978 to 2012 of Fujian Province show that the proposed method obtains a better prediction. Comparing with other usual prediction methods such as ARIMA, we find it is an effective prediction method of energy consumption.
Key words:twice error adjustment;ARIMA model;partial least squares regression;support vector machines;energy consumption
引文格式:艾兵, 董明刚.基于误差校正的能源消费总量预测方法[J].桂林理工大学学报,2016,36(2):388-394.
