基于列存储的大规模并行数据库应用技术
2016-08-05吴齐跃
吴齐跃
(北京科技大学 东凌经济管理学院,北京 100083)
基于列存储的大规模并行数据库应用技术
吴齐跃
(北京科技大学 东凌经济管理学院,北京 100083)
大数据分析已经成为当前研究和应用的热点问题,针对当前传统数据库技术对大数据进行分析时系统性能严重下降、查询效率受限的问题,综合比较列存储和MPP数据库技术的特点,重点研究了列存储与大规模并行(MPP)数据库的融合,探讨大数据实时分析方案以提高大数据的存储效率和处理性能。
大数据;列存储;MPP数据库
1 引言
在信息化技术高度发展的今天,大数据应用变得日渐普及而且非常重要。鉴于传统关系型数据库在大数据应用领域应用时遇到的困难,基于分布式的海量数据管理是当前的研究热点,其中就包括如何有效地存储和处理这些增长迅速的海量数据。
现有大数据处理技术主要有对称多处理机架构 (SMP)和大规模并行处理架构(MPP)两大类。在数据量极速增长的大数据背景下,计算分布和存储分布的MPP架构成为主流。MapReduce[1]分布式并行计算是MPP架构的代表。Hadoop[2]是MapReduce分布式计算框架的实现,为大数据处理大型分布式集群,通过分布式存储系统 HDFS(Hadoop Distributed File System)[3]来管理海量数据。本文重点研究了列存储结构在MPP数据库中的应用,概述了列存储技术和MPP数据库,用Vertica为例分析了基于列存储的MPP数据库关键技术,并展望了未来MPP数据库研究的的发展方向。
2 列存储技术的优势
列存储最核心的技术就是基于垂直分区的存储设计和访问模式。列存储数据库完全划分为多个独立的列的集合进行存储,这种技术的特点是对复杂数据的查询效率高,读取磁盘少,存储空间占用少。这些特点使其成为大数据和OLAP应用存储的理想结构。
列存储数据库只需查询读取涉及关系中某些数据列,避免无关列的提取,不像行存储那样需要从磁盘读取整行信息并去除不需要的属性信息,从而减少I/O和内存带宽的占用,提高查询效率。而同一列数据属性相同,可以使用针对性的压缩算法,因此压缩效率高。C-Store[4]和 Monet DB[5]是其中有影响力的代表性成果,它们在存储结构、查询优化、压缩等方面进行了很多技术创新,使得列存储相比较行存储而言更适合大规模的访问和查询。
列存储技术的学术价值和商业价值以及主要关键技术,包括基于其主要存储原理的存储压缩、延时物化、成组叠代、查询优化、索引及加密等。列存储的应用价值来自它对复杂查询的灵活快速以及压缩所带来的存储优势,这使其在数据仓库和商务智能方面具有良好的应用前景,已经有许多分析性数据库引入了列存储技术,其中Vertica以及Greenplunm等都是采用了列存储技术的MPP数据库,在企业决策分析与决策领域有许多成功应用。
列存储数据分析在商务智能领域应用中有着先天的优势:独特的存储方式,能够迅速地执行复杂查询;列数据库的压缩技术,更是能为数据仓库、商务智能应用中巨大的数据节约存储成本;列数据库先进的索引技术也大大提高了数据库的管理。按列存储的结构,便于在列上对数据进行轻量级的压缩,列上多个相同的值只需要存储一份,按列存储和压缩能将更多的数据压缩在一起,则在每次读取时就可以获得更多的数据,压缩能够大量地降低存储成本。按列存储和压缩能将更多的数据压缩在一起,则在每次读取时就可以获得更多的数据。列存储技术在数据分析领域的应用优势主要体现在:对于列的DML (Data Manipulation Language)操作,仅对列所对应的数据扫描,不对全表进行数据访问,可以有效降低DML操作的 I/O,同时按列压缩的特点也同样能减少数据挖掘时的I/O吞吐量[6]。
列存储的关键技术有压缩技术、物化技术、成组迭代等。Abadi DJ[7]在SIGMOD06会议上提出列存储的主要压缩方法有:行程编码算法、词典编码算法、位向量编码算法;延时物化,如Abadi DJ在文献[8]中,详细介绍了提前物化和延迟物化两种物化方式的实验过程,证明延时物化许多性能上的潜力只有在列存储数据库中才能发挥,在文献[9]比较了提前物化和延时物化的优劣,在延时物化引入横向信息传递技术应用,有效解决了溢出连接产生的性能下降问题。
3 大规模并行数据库的列存储技术应用
3.1 MPP数据库
大数据处理的传统方法是使用并行数据库系统。并行数据库系统是在大规模并行处理系统(MPP)和集群并行计算环境的基础上建立的高性能数据库系统。这样的系统是由许多松耦合处理单元组成的,指的是处理单元而不是处理器。每个单元内的CPU都有自己私有的资源,如总线、内存、硬盘等。在每个单元内都有操作系统和管理数据库的实例复本。这种结构最大的特点在于不共享资源。20世纪80年代和90年代初期是大规模并行处理技术的飞速发展时期,Gamma[10]和Teradata[11]正式这一阶段发展起来的MPP数据库项目的先驱。
并行数据库系统的构建有三种架构方案:共享处理器、共享内存、共享磁盘。
在共享内存的架构中[12],所有处理器访问统一的内存和所有的磁盘,这种结构的局限性在于快速访问共享内存的是其瓶颈。在共享磁盘的架构中[8],所有处理器有自己的内存,但是共享对磁盘的访问,这种架构因为连接所有处理器对磁盘访问的复杂性较高使得其比较昂贵。
如图1所示,并行处理Shared-nothing架构各节点拥有自己的处理器和内存以及磁盘,只是共享通讯网络,过去的几十年中,并行处理Shared-nothing架构为学术界和工业界所认可,很多并行处理的原型系统都是基于Shared-nothing架构的,具体包括:Bubba[13],Gamma[6],Greenplum[14],IBM DB2 Parallel Edi-tion[15],Netezza[16],SQL Server Parallel DataWarehouse[17],Teradata[7]等。

图1并行处理Shared-nothing架构
图2表示了通过高速网络连接的“share-nothing节点”(具有独立CPU,主存和磁盘)组成的集群的全新并行数据库架构模式。
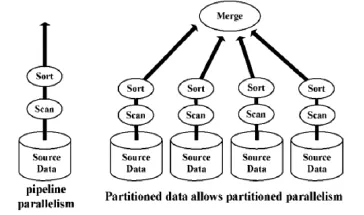
图2并行数据库架构
3.2 HP-Vertica技术和特性分析
作为新一代MPP数据库的代表产品,HP Vertica带来了很多创新,Vertica采用高性能的列式存储和计算技术,支持主动数据压缩,高级分析,对大数据实时分析有较好的支撑。图3展示了Vertica的架构,其融合列存储技术和MPP并行处理架构[18]。

图3 Vertica架构
(1)列式存储和计算
区别于传统的行存储数据库,Vertica将每列数据是独立地存储在连续的硬盘存储块中。支持延迟物化技术,对于大多数的分析查询而言,往往只需要获取所有列数据的一个子集。Vertica采用列式优化器和执行引擎可以在列式存储中跳过无关的列,从而节省了大量的I/O资源消耗,提高查询效率。如图4所示。

图4 Vertica列存储
根据查询的要求和数据的特点主动选择合理的排序方式和压缩算法,降低数据所占的存储空间,从而降低查询的 I/O消耗,进一步提升查询性能,同时通过采用延迟解压缩技术,充分利用列式计算技术,支持在查询条件和关联中直接访问数据编码后的值,而不需要先解码,大大节省在数据查询期间的CPU开销,进而提升整体的查询性能。
(2)压缩技术
Vertica支持超过12种压缩算法,如:行程长度算法(run length encoding),增量编码(delta value encoding),针对整数数据的整数压缩,针对字符数据的块字典编码,针对其他数据类型的Lempel-Ziv编码等,根据每列的数据类型、基数和查询特点,选择适用的排序方式和压缩算法,以尽可能减少数据所占的存储空间,如图5所示。通过降低查询的I/O消耗,从而提升查询性能。从I/O资源消耗节约的角度来看,对I/O是主要瓶颈的分析系统而言,相较于传统的行式数据库,主动压缩技术可以带来约一个数量级的性能提升。

图5 Vertica压缩示意图
(3)“横向扩展式”大规模并行处理 (MPP)
Vertica采用无资源共享的大规模并行处理架构。节点间通过TCP/IP网络进行通信。每节点采用本地磁盘来存储数据,也支持通过存储域网络(SAN)方式连接外部存储中的不同LUN。集群中的所有节点完全对等,不需要主节点,数据加载、数据导出和查询都可以并行地在所有节点同时执行。由于没有资源共享,增加节点就可以线性地扩展 Vertica的数据容量和计算能力,可以轻松从几个节点到上千节点、或从几个TB到数10 PB规模扩展和收缩,满足业务规模增长的要求。
(4)高性能和高并发
Vertica的列式存储和计算技术,通过针对列数据特点的主动压缩技术和延迟物化、延迟解压,节省了近2个量级CPU和I/O资源消耗,分析查询性能比传统行式数据库快快50到1 000倍。同时,CPU和I/O资源的大幅节约,也大幅提升了数据装载、数据导出、数据处理和备份恢复等操作的性能。
(5)混合存储和实时分析
Vertica借鉴C-store的设计,如图6所示,除了把数据按列式存储到磁盘中外 (Vertica称这块存储区域为读优化存储,ROS),还专门为实时装载的数据在内存中开辟了一块存储区域(Vertica称这块存储区域为写优化存储,WOS),通过内存的快速读写能力来提升数据实时装载能力。

图6 Vertica混合存储架构
4 结语
MPP数据库在设计上充分考虑和利用了列式存储的优越性,使数据库的整体性能、易用性及可靠性方面都达到了较高的水平,因此这几年的发展速度也很快,值得关注。MPP数据库在Hadoop和大数据时代仍然是个好选择,在未来很长的一段时间内MPP数据库有足够的空间和机会成长和繁荣,MPP数据库和Hadoop/MapReduce技术的融合也将是未来大数据分析领域的重要方向。
主要参考文献
[1]Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].In Proceedings of Operating Systems Design and Implementation(OSDI,2004,51(1):107-113.
[2]White T.Hadoop:The Definitive Guide[M].Sebastopol:O’Reilly,2012.
[3]Borthakur D.The Hadoop Distributed File System:Architecture and Design[J].Hadoop Project Website,2007,11(11):1-10.
[4]Stonebraker M.,Abadi D J.,Batkin A,et al.,C-store:A Column-oriented DBMS.Proceeding of the 31st VLDB Conference,Trondheim,2005.
[5]Boncz P A,Zukowski M,Nes N J.MonetDB/X100:Hyper-Pipelining Query Execution[J].Cidr,2005.
[6]田立中,徐瑞余,周昭涛.列存储在数据挖掘中的应用[J].金融电子化,2008(9).
[7]Abadi D J,Madden S R,Hachem N.Column-stores vs.Row-stores:How Different are They Really?[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data,SIGMOD 2008,Vancouver,BC,Canada,June 10-12,2008.2008:967-980.
[8]Abadi,D.J.,Myers D,S.,et al.,Materialization Strategies in a Column-Oriented DBMS.IEEE International Conference on Data Engineering,2007:466-475.
[9]Shrinivas L,Bodagala S,Varadarajan R,et al.Materialization Strategies in the Vertica Analytic Database:Lessons Learned[C]//2013 IEEE 29th International Conference on Data Engineering(ICDE).IEEE Computer Society,2013:1196-1207.
[10]David J Dewitt,Shahram Ghandeharizadeh,Donovan A.Schneider,et al.The Gamma Database Machine Project.IEEE Trans.on Knowledge and Data Engineering,1990,2(1):44-62.
[11]Teradata,2016,http://cn.teradata.com/
[12]David J.DeWitt,Jim Gray.Parallel Database Systems:The Future of High Performance Database Systems[J].Communications of the ACM,1992,35(6):85-98.
[13]H.Boral,W.Alexander,L.Clay,et al.Prototyping Bubba,a Highly Parallel Database System.IEEE Trans.on Knowledge and Data Engineering,2002,2(1):4-24.
[14]Greenplum,2016,http://pivotal.io/big-data/pivotal-greenplum/
[15]C.K.Baru,G.Fecteau,A.Goyal,H.Hsiao,et al.DB2 Parallel Edition.IBM Systems Journal,1995,34(2):292-322.
[16]IBM Netezza Data Warehouse Appliances,2016.http://www-01.ibm. com/software/data/netezza/.
[17]SQL Server Parallel Data Warehouse,2016.http://www.microsoft.com/ en-us/sqlserver/solutions-technologies/data-warehousing/pdw.aspx.
[18]Vertica,2016,http://www8.hp.com/cn/.
10.3969/j.issn.1673-0194.2016.11.106
TP309.3
A
1673-0194(2016)11-0177-04
2016-03-18
