基于数据挖掘的财务危机多分类预警研究
2016-08-05赵智繁王世民
赵智繁,王世民,曹 倩
(北京工商大学 计算机与信息工程学院 食品安全大数据技术北京市重点实验室,北京 100048)
基于数据挖掘的财务危机多分类预警研究
赵智繁,王世民,曹倩
(北京工商大学计算机与信息工程学院食品安全大数据技术北京市重点实验室,北京 100048)
目前对财务危机预警模型的研究大多少为二分类研究,其只能对企业是否存在财务危机做出预警,无法对企业的财务危机程度做出警报,因此简单的二分类可能无法揭示企业财务状况逐渐变差的事实。鉴于此,将F分数模型与ST分类法相结合,对企业财务危机程度进行了细化,并使用t-2年的财务数据构建了基于关联规则、决策树等数据挖掘算法的财务危机多分类预警模型。实证结果表明,模型在保证了较高准确率的基础上,能够提供更加精细的警报。
F分数模型;数据挖掘;财务预警;财务危机;多分类
1 引言
面对日趋严峻的市场竞争,不少企业将会面临财务危机的困扰。财务危机又称财务困境,陷入财务危机的企业不但将面临资不抵债、无法偿还到期债务、盈利能力下降、财务指标数据恶化等状况,甚至还有破产的风险。因此,如何提前识别出企业潜在的财务危机状况,及时地进行改善,以避免更为严重的损失,成为了企业管理者、投资者最为关注的问题。
通过大量的、真实的企业财务历史数据,并使用一定的数学建模方法所构建的财务危机预警模型,是用来预测企业是否存在财务危机的重要方法,也是财务危机预警定量研究的重要内容。最早的财务危机预警模型研究是20世纪30年代Fitz Patrick等人使用的单变量预测方法。随着统计理论的普及和计算机技术、数据库应用的兴起,财务危机预警模型得到了不断的推衍与改进,并涌现出了大量的优秀成果,如国外Altman等人的Z值计分模型和国内周首华等人的F分数模型等。
纵观国内外现有的研究成果,大多数研究的重点都集中在建模方法的对比和预测变量的选取这两个方面,却缺乏在财务危机预警中对财务危机进行多分类的探讨。就目前的文献资料来看,大多数的研究依然采取传统的二分类预警模式,即只能预测企业将成为ST企业,或者将成为非ST企业。然而在实际的情况中,有些企业虽然没有被标记为ST,但是其财务状况依然不乐观,现有的二分类预警模型却并不能对这一部分企业给出警报。因此当前的依据ST进行划分的财务危机二分类预警模型很难提升实际应用的价值,同时也掩盖了企业在陷入财务危机前财务状况恶化的过程。
对财务危机的多分类目前还没有公认的标准,同时该问题相对定性,难以在定量研究中通过单一的数值进行表示,这些都为在财务危机预警模型中进行财务危机程度的多分类造成了障碍。
本文将采用目前国内在财务危机预警领域使用较为广泛的F分数模型的判别公式,并与传统研究中的ST分类方式相结合,将企业财务危机程度划分为“财务稳定企业”、“财务不稳定企业”、“财务较危机企业”和“财务危机企业”四个部分。并使用t-2年的财务指标数据,通过关联规则算法筛选出重要的预测变量,再通过决策树模型进行训练生成财务危机多分类预警模型,最后使用测试样本对模型的准确性进行检验。
2 国内外研究综述
财务危机预警模型的研究中,在财务危机的分类方面,最早是依据企业是否破产进行分类的,其中具有代表性的研究是Altman[1]使用多元线性判别方法创立的 Z值计分模型,其使用的研究样本是33家提出破产申请的企业与33家与之配对产生的财务状况良好的企业。在国外的现有研究中,大部分也是依据企业是否破产进行二分类。在抽样的方法上,大多也使用配对抽样的方法。在国内,由于上市企业的财务年报获取较为容易,同时其年报数据的真实性、准确性较高,所以大部分研究选取上市企业作为研究样本。但是由于我国真正破产、退市的上市企业很少,所以在研究中一般以上市企业被特别处理(ST)作为企业陷入财务危机的标志,同样属于一种二分类方式,这主要是为了迎合我国上市企业的实际情况、提升建模实验的可操作性以及便于不同学者的研究相互比较。其中最具影响力的是周首华[2]等人在Z值计分模型的基础上,以我国企业为研究样本进行了修正,并考虑了现金流量因素,提出了F分数模型。对于财务危机多分类预警模型的研究探讨相对较少,但也有一些成果,如张坤[3]以西部四省上市企业为例,在构建财务危机预警模型前使用数据包络分析法将企业财务危机状况分成五类。陈磊[4]则将传统的基于ST的二分类方式扩展为ST、*ST、非ST的三分类。
在预测变量的选择上,目前主要分为财务指标和非财务指标两类。相对而言,财务指标更加容易获取,且构建的财务预警模型具有直观性、稳定性,因此更多的研究选择财务指标作为预测变量。非财务指标相对难以获取且难以量化,但也有相关研究表明非财务指标与财务危机具有一定的关系,如La Porta[5]等人发现企业股权集中度越高,企业越容易出现财务危机。边海荣[6]等人将Web金融信息文本数值化后发现,其也可以作为预测变量用于构建财务危机预警模型。
在建模方法的应用上,传统的方法主要是单变量、多变量预测模型,但随着计算机网络和数据库技术的兴起,数据挖掘技术逐渐成为了构建财务危机预警模型的主要工具。数据挖掘拥有强大的学习能力,可以从大量历史信息中发现潜在的、有价值的知识,辅助管理者进行决策。其中,Odom[7]是使用人工神经网络构建企业财务危机预警模型的最具代表性的学者之一。吴世农[8]等人通过对逻辑回归模型与另外两种方法对比发现,逻辑回归模型拥有最低的误判率。李健[7]通过对逻辑回归、决策树、人工神经网络三种不同的数据挖掘算法进行对比,发现在构建财务危机预警模型时决策树模型训练次数少、速度快,在长期预测和短期预测中都能取得较高的准确率,稳定性更强。
3 研究设计
3.1技术路线
基于数据挖掘的财务危机多分类预警建模的研究,大致可分为四个部分:样本数据的选取和财务指标的计算、财务危机的多分类、预测变量的筛选、数据挖掘算法的训练。
对于财务危机的多分类,由于现有的二分类预警模型存在较为明显的局限性,因此本文将F分数模型的判别公式和ST分类方法相结合,将财务危机细化为“财务稳定企业”、“财务不稳定企业”、“财务较危机企业”和“财务危机企业”四个部分,使得预警模型可以对那些虽然目前没有被标记为ST的风险,但财务状况依旧不乐观的企业做出警报。
对于预测变量的筛选,由于预测变量(财务指标)的多样性,以及不同预测变量间可能存在的关联性,同时也为了能够生成简练易读的财务危机预警模型,因此需要对预测变量进行筛选。本文将使用t-2年的财务指标数据,并通过数据挖掘中的关联规则算法,筛选出与t年财务危机程度关联度较大的财务指标作为预测变量,剔除了弱关联指标。
最后,本文将使用t-2年的预测变量数据,以t年的财务危机程度作为结果变量,并通过数据挖掘中的决策树算法进行训练,生成树状判别模型,并使用测试样本检验模型的准确率。
3.2样本来源和指标体系
本文的样本数据来源于上海证券交易所官网中上市公司定期披露的财务年报,这些年报数据经过了严格的审查,具有较高的真实性和规范性。
由于在财务分析研究中,各类财务指标类型较多,为了避免在选取备用的财务指标时造成的主观性和相关性,本文选取了国内相对较为完善的《企业综合绩效评价实施细则》中财务绩效定量评价指标规定的8个基本指标与14个修正指标作为备选的财务指标,其中舍弃4个外部报表使用者难以获取的指标,分别是不良资产比率、带息负债比率、或有负债比率和技术投入比率,剩余的财务指标如表1所示。

表1备选的财务指标
3.3财务危机的多分类
3.3.1 F分数模型
为了弥补目前二分类预警模型的缺陷,本文采用F分数模型的判别公式与传统ST分类标准相结合,实现了对财务危机程度的多分类。
F分数模型是我国学者在Z值计分模型的基础上,以我国企业财务信息为样本数据所改进的财务危机预测模型。随后,在相关领域的研究中,F分数模型得到了广泛的运用,并保持了很高的准确率。与Z值计分模型相比,它具有如下的优势:首先,F分数模型充分考虑到现金流量的因素;其次,F分数模型通过数据库技术使用了更大的研究样本,拥有更强的稳定性和普遍适用性,同时更加适用于国内企业;另外,F分数模型考虑到了近代企业财务状况相关标准的更新与发展。
F分数模型的判别公式如下:

其中的X1表示的是企业期末流动资产与期末流动负债的差值,占企业期末总资产的比率;X2表示企业期末留存收益与期末总资产的比值;X3表示企业税后纯收益与折旧的总和与平均总负债的比值;X4是期末股东权益的市场价值与期末总负债的比值;X5表示企业税后纯收益、利息、折旧三者总和与平均总资产的比值。与Z值计分模型相比,F分数模型考虑了现金流量方面的情况,如 X3、X5指标的分子项,都是对企业创造的现金流量方面的测量[9]。F分数的计算比较简单,流动资产、流动负债、总负债、总资产等项目均可从资产负债表中直接获取,净利润可从利润表中获取,只有期末股东权益的市场价值需要参考期末股价、未上市流通股份和已上市流通股份等其他会计资料。
F分数模型的临界点被设定为0.027 4,当企业的F分数小于临界点时,则被预测为具有较高的财务危机,被标记为ST的可能性很大;若F分数大于临界点,则被预测为财务状况正常的企业。另外,经过大量的样本检验,当F分数处于[-0.050 1,0.104 9]时,预测的准确率将会下降到仅仅70%左右,一般在研究中我们称之为“灰色区域”。
3.3.2多分类标准
在目前的相关研究中,经常依据上市企业被标记为ST作为企业是否存在财务危机的分类标准。ST(Special Treatment),意为“特别处理”,是证券交易所对财务状况或其他状况出现异常的上市企业股票交易进行的特别处理,这里的异常状况主要包括:最近两个会计年度的审计结果显示的净利润均为负;最近一个会计年度的审计结果显示其股东权益低于注册资本等。可见,上市企业被标记为ST是一种明显的具有较高财务危机的体现。本文也认同这种观点,因此将被标记为ST的企业作为财务危机多分类中的“财务危机企业”样本,并将其被标记为ST的年份称为第t年。但是,由于在实际情况中,部分上市企业虽然没有被标记为ST企业,但财务状况并不乐观,依然存在较高的财务危机风险,仅仅使用传统的ST分类方式是无法将这部分企业筛选出来的。因此,将使用F分数模型,继续对非ST企业进行分类。
由于财务数据的发表具有滞后性,因此使用t-1年的财务报表数据进行F分数的计算。当非ST企业的F分数低于-0.050 1时,我们认为这部分企业虽然没有被标记为ST,但依然存在较高的财务危机风险。而且,当非ST企业的净利润为负数时,近两年成为ST企业的可能性很高。因此我们将这两类企业作为财务危机多分类中的“财务较危机企业”样本。
当非ST企业的F分数处于灰色区域 [-0.050 1,0.104 9]时,F分数模型的预测准确率较低,因此这部分企业的财务状况并不稳定,将这类企业作为财务危机多分类中的“财务不稳定企业”样本。
当非ST企业的F分数高于0.104 9时,F分数模型的预测准确率回升到了较高的水平,这部分企业的财务状况良好,存在财务风险的可能性很低,因此我们将这类企业作为财务危机多分类中的“财务稳定企业”样本。
最终本文在上海证券交易所官网中选取了37家2015年被标记为ST的上市企业作为“财务危机企业”样本,同时通过计算 F分数,选取“财务较危机企业”、“财务不稳定企业”、“财务稳定企业”各37家,共148个研究样本,将其中将98家作为训练样本,50家作为测试样本。
3.4预测变量的筛选
3.4.1财务危机分类结果与财务指标的对应
因为财务数据的发布具有滞后性,因此当我们获取t-1年的财务报表数据时,实际上第t年的财务危机已经发生,因此在构建财务危机预警模型时,使用t-1年的财务数据没有任何预警意义,使用t-2年的财务数据更为合理。
在数据库中对预测变量进行筛选前,需要将样本企业第t年的财务危机分类结果与第t-2年的财务指标数据进行对应。最简单的方法是,在企业第t-2年的财务指标数据行中添加一个新的属性(列),通过数据库的存储过程写入将该企业第t年的财务危机分类结果。
3.4.2关联规则筛选预测变量
表1中列举了备选的财务指标,但是如果将所列的财务指标全部当作预测变量来构建预警模型,则容易造成预警模型过拟合,同时过于复杂的预警模型不利于实际的应用。因此,需要对财务指标进行筛选,选择出合适的财务指标作为预测变量。
以往的研究在筛选财务指标时常采用的方法包括:K-S检验、配对T检验和主成分分析等方法,但都具有一定的局限性。首先K-S检验、配对T检验对样本数据的分布状况有一定的要求,部分财务数据因其本身的特点往往很难满足要求。其次在使用主成分分析前需要对样本进行KMO检验和Bartlett球形检验,而且最终形成的主成分因子是所有指标在不同权系数下的线性组合,不一定具有合理的财务意义。因此,本文采用了数据挖掘中关联规则算法来筛选预测变量。关联规则算法对样本数据的分布没有要求,同时能够筛选出与财务危机状况关联度较高的财务指标作为预测变量。
关联规则是一种可以在大量数据集中找出项与项之间的关系的数据挖掘技术,Apriori算法是关联规则中最经典的算法,依据每条规则的支持度与置信度,可以得出在规则先导发生的情况下,规则后继发生的可能性。其中规则的支持度用support表示,意为在所有记录中同时包括先导与后继的比率,公式为:

其中X为规则的先导,Y为规则的后继,|D|表示所有记录的条数。
规则的置信度用confidence表示,表达的含义是当一条记录包含先导时,同时也包含后继的概率,公式为:
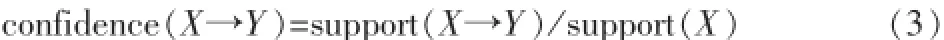
通过设定最小支持度和最小置信度,可以选择出我们需要的关联规则。例如:当规则中指标X1<m推导出“财务危机企业”的支持度与置信度均满足最低标准,那么指标X1将成合格的预测变量。
因此我们将财务危机分类设置成后继属性Y,通过约束规则的最大项数,来考察单一的财务指标数据与财务危机分类的关联程度。经过筛选,当最小置信度设置为0.7时,获得的规则数目与规则先导数量最为合理,分别可以获得9条重要的关联规则和 7个预测变量,分别是 X1、X2、X3、X5、X8、X9、X16,重要的关联规则如表2所示。

表2重要的关联规则
3.5基于决策树的财务危机预警模型
数据挖掘中的决策树算法是一种逼近离散函数值的方法,可用于分类、预测。通过决策树来构建财务危机预警模型具有训练次数少、速度快的优点,同时决策树的分类精度高、生成的模型直观可读、对样本中的噪声数据有很好的健壮性并能取得稳定的预测准确率。
决策树自根节点开始,依据属性的信息增益量进行分裂,优先分裂信息增益量最大的属性,其分类过程具有贪心思想。属性的信息增益量为系统在携带该属性时与不携带该属性时的信息量的差值。信息量(熵)的计算公式为:

其中Pi为变量在取不同的值i的概率。使用98组训练样本,将通过关联规则筛选出的t-2年的财务指标作为决策树的预测变量,以第t年的财务危机分类作为决策树的结果变量,在叶结点处,决策树给出每一个分支的预测分类,如图1所示。

图1决策树预测结果
4 结果检验
本文使用的是 SQL Server数据库及配套的 Business Intelligence Development Studio商务智能套件,在挖掘结果信息栏中选取挖掘准确性图表,可以使用50组测试样本数据对预警模型的准确性进行检验,得到如表3的结果分类矩阵。

表3预测结果分类矩阵
根据预测的结果来看,本文在使用F分数模型与ST分类法相结合的方法将财务危机进行了多分类,并用数据挖掘算法训练生成了预警模型,这使得预警模型的预警结果也是多分类的。与现有的二分类模型相比,多分类的预警模型不但能对可能成为ST的企业进行警报,同时能对那些虽然暂时没有被ST的风险,但是其财务状况依旧不乐观的企业做出警报,增强了实用价值。
在准确率方面,多分类的预警模型与传统的二分类模型并不具有直接的可比性。但是从预测准确率上依旧可以看出,多分类预警模型在对财务危机型企业与财务稳定型企业进行预警时,准确率较高,但在对财务较危机型企业和财务不稳定型企业进行预警时准确率不够,只能达到60%左右,这可能是由于难以挖掘到有效的预警指标和预警区间,但这对实际的应用价值影响较小。
在财务危机预警模型的验证中,经常需要检验模型的错误成本,因为Sinkey[10]认为,当预测结果优于实际结果时,其给企业带来的错误成本要高于预测结果劣于实际结果的情况,根据本文的预测结果分类矩阵,错误的预测大部分要劣于实际的结果,因此该模型的错误成本相对较小。
5 结语
本文使用F分数模型,并与传统的ST分类法相结合,将企业财务危机进行了多分类,在财务危机预警建模中,提供了一种新的财务危机多分类预警思路。与传统的二分类预警模型相比,多分类的预警模型在保证了一定准确率的基础上,能够提供更多种类的警报,具有更强的应用价值。
在筛选财务指标时,关联规则算法与K-S检验、配对T检验和主成分分析法相比,拥有更强的适用性,更加适合财务数据本身的数据特点。同时,决策树算法在构建财务危机预警模型时训练次数少、速度快、准确率较为稳定。
就目前的研究结果来看,总资产报酬率、流动资产周转率、资本保值增值率、成本费用利润率、净资产收益率等几个指标在预测企业财务危机时具有较高的稳定性。因此无论是作为企业的管理者还是外部的投资者,都应当重点关注这些指标的变化,相关的财务指标评价体系也可适当调高这些指标的权重,使其获得更准确的评价。
主要文献文献
[1]Altman,E.I.Financial Ratios,Discriminate Analysis and the Prediction of Corporate Bankruptcy[J].The Joural of Finance,1968(4):589-609.
[2]周首华,杨济华,王平.论财务危机的预警分析—F分数模型[J].会计研究,1996(8):8-11.
[3]张坤,丁玉芳,胡敏杰.基于数据包络分析:决策树的企业财务评价与预警——以西部四省上市企业为例 [J].财务与金融,2014(3):36-41.
[4]陈磊,任若恩,曹汉平.公司多阶段财务危机动态预警研究[J].系统工程理论与实践,2008(11):29-35.
[5]N Gennaioli,RL Porta,FLD Silanes,et al.Growth in Regions[J].Journal of Economic Growth,1969,19(3):259-309.
[6]边海容,万常选,刘德喜.考虑Web金融信息的上市企业财务危机预测模型研究[J].计算机科学,2013,40(11):295-298.
[7]Odom M D,Sharda R.A Neural Network for Bankruptcy Prediction[C]// Proceedings of the International Joint Conference on Neural Networks Tool,1990.
[8]吴世农,卢贤义.我国上市公司财务危机困境的预测模型研究[J].经济研究,2001(6):46-55.
[9]李吉林.基于F分数模型的上市公司财务危机预警系统研究[J].中小企业管理与科技,2010(18):72-74.
[10]赵长明.我国二手房地产交易价格风险的核算[J].统计与决策,2014(1):50-52.
10.3969/j.issn.1673-0194.2016.11.032
F275
A
1673-0194(2016)11-0056-06
2016-04-19
北京市教委科学研究项目(KM201410011005);北京市优秀人才培养资助项目(2015000020124G029);北京工商大学教育教学改革项目(jg155225)。
