基于遗传算法的覆盖率驱动测试产生器
2016-08-01王树朋严晓浪
王树朋,黄 凯,严晓浪
(1.浙江大学 信息与电子工程学系,浙江 杭州 310027; 2. 浙江大学 超大规模集成电路研究所,浙江 杭州 310027)
基于遗传算法的覆盖率驱动测试产生器
王树朋1,黄凯1,严晓浪2
(1.浙江大学 信息与电子工程学系,浙江 杭州 310027; 2. 浙江大学 超大规模集成电路研究所,浙江 杭州 310027)
摘要:为了更好地建立覆盖率和测试产生器之间的联系,产生高质量的测试,提出基于遗传算法的覆盖率驱动测试产生器.该测试产生器利用一种简单、准确的测试编码方法对测试进行编码,并利用基于功能覆盖率的适应度函数评估测试的优劣.通过遗传算法(GA)建立覆盖率与测试产生器之间的联系,分析覆盖率和测试之间的关系,根据分析结果改变测试产生器的约束和限制,驱动测试产生器生成新一代的测试,新一代的测试可以覆盖到上一代的测试无法覆盖的功能点.实验结果表明:在2个高性能的32位多核处理器的验证环境中,该测试产生器可以明显减少仿真时间,提高验证效率.
关键词:覆盖率;测试产生器;遗传算法(GA);覆盖率驱动测试产生器;适应度函数
随着嵌入式系统的规模越来越庞大,功能验证已经成为嵌入式系统设计周期中最主要的挑战,功能验证的方法直接决定了嵌入式系统的面市时间.目前主要使用基于仿真的验证方法验证嵌入式系统的功能,这种方法是通过仿真大量的测试得到期望的覆盖率,其效果和所使用的测试的质量息息相关.测试的质量往往用覆盖率表征,覆盖率可以识别和发现没有验证的功能,从而评估验证工作的进展.覆盖率主要分为代码覆盖率和功能覆盖率,其中代码覆盖率通过评估硬件代码执行的情况得到覆盖率,主要包括语句覆盖率、判定覆盖率和条件覆盖率等;而功能覆盖率是通过评估功能点的覆盖情况得到覆盖率,功能点是用户自己提取的必须要验证的特征和一系列事件的组合[1].
高质量的测试往往可以在短时间内得到较高的覆盖率,而基于仿真的验证方法的最大挑战就在于产生这些可以提高验证效率的高质量测试.测试主要分为人工书写的测试、随机测试和覆盖率驱动测试产生器生成的测试.在实际应用中,人工书写的测试和随机测试的局限性推动了覆盖率驱动测试产生器(coverage direct test generation,CDTG)的发展和应用.CDTG可以在分析覆盖率后,根据算法自动修改测试生成器的限制和约束,从而减少人工参与.CDTG可以分为2种,分别是基于形式方法的和基于反馈的GDTG.不管采用哪种方法,CDTG的最终目的都是产生高质量的测试,从而提高验证效率,减少验证周期.基于形式方法的CDTG需要DUT的一个形式模型(例如:有限状态机),在验证过程中通过分析这个形式模型的状态,修改测试生成器的限制和约束.这个方法的最大限制是随着嵌入式系统越来越复杂,形式模型也会随着越来越庞大.基于反馈的CDTG已经成为了最常用的测试产生器,其中,进行反馈的算法主要分为机器学习以及进化算法,用于反馈的机器学习算法主要包括贝叶斯网络[2-5],马尔可夫模型[6-7]以及归纳逻辑程序设计[8],用机器学习算法进行反馈可以得到较好的结果,但是利用进化算法进行反馈的CDTG可以在较短的时间内得到更好的验证效果,并且需要的领域知识更少,拥有更好的通用性[9],因此基于进化算法尤其是遗传算法(genetic algorithm,GA)的CDTG吸引了越来越多的研究人员.
GA是一种借鉴生物界的适者生存、优胜劣汰遗传机制演化而来的随机化搜索方法,主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定[10].GA采用概率化的寻优方法,不需要确定的规则,而是能够自动获取和指导优化的搜索空间,自适应地调整搜索方向.GA的这些良好的特性使其成为智能计算中的关键技术,已被人们广泛应用于自适应控制[11-14]、组合优化[15-17]、机器学习、信号处理和人工生命等多个领域.
Smith等[18]最早将GA应用于CDTG,实验结果表明采用GA可以减少验证时间.Bose等[19]提出了一种缓冲器的平均利用情况作为功能覆盖率,然后将这个功能覆盖率作为适应度函数用于评估测试的价值和效率. Yu等[20]利用语句覆盖率和路径覆盖率分析测试的效率,此外还提出了一种名为错误覆盖率的覆盖率用于测试缺陷,但是这个方法的缺点在于必须用工具AMLETO将系统设计从超高速硬件描述语言转换成SystemC.Samarah等[21]提出一种基于细胞的遗传算法用于自动产生测试,实验结果显示Samarah等提出的方法比普通的随机测试产生器效率高很多,但是这个方法只能用于验证比较小的系统.Habibi等[22]通过将测试产生器抽象到高抽象层,然后利用GA在这个高抽象层产生测试,这样可以提高仿真速度,但是会牺牲准确度.Shen等[23]用自定义的字符串基因组作为测试产生器的限制和约束,然后在Godson 1处理器上进行大量的实验,实验结果显示这个方法可以得到更高的功能覆盖率,但是没有达到100%.Subedha等[24]提出一种基于GA的CDTG,利用代码覆盖率来评估测试的适应度,然后在JAVE工作平台上进行大量的实验,实验结果显示该方法可以得到更高的覆盖率,缺点在于所用到的适应度函数是基于覆盖的代码行数,无法准确地评估测试的质量.Wang等[25]用功能点的覆盖情况评估测试的质量,在基于C语言的平台和真实的应用(PCIE系统)进行大量的实验,实验结果表明该方法可以显著减少验证时间,但是文中并没有明确地介绍测试编码方法.对于基于GA的CDTG来说,测试的编码方法会直接影响整个遗传过程和验证过程,因此测试的编码方法是至关重要的.因为多核处理器具有高性能、低功耗的特点,所以多核处理器已经发展成为了嵌入式系统的主流,这就要求测试编码方法不仅可以用于单核处理器验证环境中的测试的编码工作,而且可以用于编码多核处理器验证环境中的测试.
本文提出一个基于功能覆盖率的适应度函数用于评估测试的价值和效率,通过遗传算法建立覆盖率分析结果和测试产生器之间的联系,自动改变测试产生器的限制和约束,从而产生新的测试用于验证,以提高验证效率,减少验证时间.
1遗传算法
遗传算法(GA)是由美国的Holland教授于1975年首先提出的,GA是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法.GA从代表问题可能潜在的解集的一个种群开始,种群由一定数量的个体组成,基因在自然进化中至关重要,种群中的个体可以用多个基因组合而成的染色体表示.在GA中,通过编码组成初始种群以后,基于种群中的染色体对于环境的适应度,通过遗传算子对染色体进行优胜劣汰.遗传算子包括选择、交叉和变异,选择是基于种群中染色体的适应度进行评估,然后将适应度高的优秀染色体直接保留到下一代. GA中最为重要的遗传操作是交叉算子,交叉是指把2个父代染色体的部分结构加以替换重组而生成新染色体的操作,可以使GA的搜索能力得到极大提高.变异算子通过选择群体中的染色体的某些基因位,使得这些基因位上的基因值进行突变.GA引入变异的目的有2个:一是使GA具有局部的随机搜索能力,当GA通过交叉算子已接近最优解邻域时,利用变异算子的这种局部随机搜索能力可以加速向最优解收敛;二是使GA可维持群体多样性,以防止出现未成熟收敛现象.设种群的规模为popsize,迭代次数为gen,最大迭次代数为maxgen,GA的基本流程如下:
Begin
设置算法参数;
随机产生初始种群;
for (gen = 0; gen < maxgen; gen ++)
{
for (i = 0; i < popsize; i ++)
{
计算种群中第i个个体的适应度;
计算种群中第i个个体的目标值;
}
根据适应度,将选择算子作用于群体;
根据交叉概率进行交叉操作;
根据变异概率进行变异操作;
}
End
要将GA用于CDTG中,需要将验证环境中的测试当作种群中的个体,然后找到合适的测试编码方法,用由特征矢量按照一定结构组成的染色体表示测试,要求染色体编码可以准确地表示测试的特征,才能在GA的作用下产生质量越来越高的测试.
2测试编码方法
本文提出的测试编码方法通过提取测试的特征,可以将测试转换为特征矢量,从而得到可以表征测试特征的染色体编码.该测试编码方法不仅可以用于单核处理器的验证环境的测试的编码工作,而且可以对多核处理器的验证环境中的测试进行编码.对于测试来说,其特征主要来自于3个方面:一是控制寄存器的配置情况,控制寄存器的配置情况会显著地影响系统状态;二是测试所包含的每一条指令的信息和特征,例如:操作码和相关的地址.因为不管一个测试多么复杂,也是由一条条简单的指令组成的,所以单条指令的特征会显著影响测试的特征,分析单条指令的特征是必要的;三是多条指令形成的指令流,这些指令流可能会得到很多不同的仿真情景和覆盖情况.
将一个测试转换为一个特征矢量的过程可以分为2个步骤:第一个步骤是将测试中包含的每条指令转换为一个小矢量,第二个步骤是将这些小的矢量结合形成表示测试的完整特征矢量.在第一步中,每条指令可以转换为一个5元素的特征向量,控制寄存器的配置情况用第一个元素表示;指令集中的所有操作码会被编码,然后用第二个元素表示;第三个元素用于表示这条指令的相关地址所在的地址域;第四个元素用于表示这条指令是否和在它之前的指令有依赖关系;这条指令和离其最近的有依赖关系的指令之间的距离用第五个元素表示.这样就可以将每条指令转换为一个5元素的特征向量,将这些特征矢量结合就可以形成表示测试特征的完整特征矢量,从而形成测试的染色体编码.如果一个验证环境中的多个测试的长度不一致,即这些测试包含的指令数目不一致的话,需要将一些零向量添加到比较短的特征矢量后面,使得整个验证环境中的所有特征矢量长度相同.
图1中介绍了一个简单的测试编码过程,假设共有2个测试,分别是测试 1和测试2,其中测试1包含10个指令,而测试2包含8个指令.因为测试1的第3个指令是配置系统控制寄存器,将系统的状态从SLEEP(低功耗状态)修改为ACTIVE(正常工作状态),所以第三个特征矢量的第一个元素置为1;第四个特征矢量的第二个元素置为2,因为测试1的第四个指令的操作码是ldw.这个特征矢量的第三个元素置为2,因为第四个指令相关地址的地址域是可缓存的但是不可共享的.因为第四条指令与第一条指令具有依赖关系,所以第四个特征矢量的第四个元素置为1,表示第四条指令与其之前的指令有依赖关系.与此同时,将第五个元素置为3,表示其与第1条指令有依赖关系.因为测试2只包含8条指令,所以需要在特征矢量后面添加2个零向量以得到1个50元素的特征向量,这样可以和测试1的特征矢量长度相同.通过使用这个编码方法,得到2个测试的染色体编码,而且得到的染色体编码可以准确地表示测试的特征.

图1 测试编码示例Fig.1 Simple example of test encoding
3基于遗传算法的覆盖率驱动测试产生器
图2介绍了将GA用于CDTG的过程,整个过程从测试产生器随机生成的M个测试组成的初始测试集合开始,当这M个测试经过仿真以后,通过分析覆盖率,得到每个测试的适应度,测试的适应度和覆盖率息息相关.如果此时满足终止条件,那么整个仿真过程终止;如果不满足终止条件,那么根据选择算法进行选择,随后根据交叉率和交叉算法进行交叉操作,最后根据变异率和变异算法进行变异操作,可以得到新的测试集合中每一个测试的染色体编码,反馈给测试产生器.测试产生器可以根据这些染色体编码产生新的测试,新产生的测试往往比原来的测试拥有更高的适应度,可以覆盖到原来的测试无法覆盖的功能点.重复以上过程直到满足终止条件,终止条件一般是功能覆盖率达到要求.

图2 基于遗传算法的覆盖率驱动测试产生器Fig.2 Coverage directed test generation based on genetic algorithm
通常来说,遗传算法可以表示为GA=(C,E,P0,M,F,G,Y,T), 其中C和E分别表示染色体编码方法和适应度函数;P0和M分别表示初始种群和种群大小,在本研究的应用中,P0和M分别表示初始的测试集合和测试集合中测试的个数;F、G和Y分别表示选择算子、交叉算子和变异算子;T表示终止的条件和规则.为了在分析覆盖率以后,用遗传算法驱动测试产生器生成质量更高的测试,需要确定这8个变量.第2章介绍了测试的染色体编码方法C,本章主要介绍其他7个变量.
GA中的适应度函数E用来判断种群中的染色体的优劣,适应度函数直接影响到GA的性能.基于仿真的验证方法的目标是在短时间内得到最大的覆盖率,而多次覆盖功能点可以提高验证的完整性和鲁棒性,因此在本研究的应用中,适应度函数E和功能点的覆盖情况密切相关.首先确定被测试的设计中需要覆盖的功能点,这些功能点是要验证的处理器特征和一系列的事件组成,假设共有g个功能点.当完成一个测试的仿真以后,这个测试的适应度可以表示为
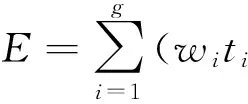
式中:wi表示第i个功能点的权重和重要程度,其值可以根据被测试的设计的特征进行调整,例如:当只测试某一个模块时,可以将其他模块的功能点的权重设置为0;ti表示第i个功能点被覆盖的次数.
需要确定测试集合的大小,即测试集合包含的测试的数目M.当M的取值较小时,算法的计算时间较短,但是算法收敛到最优解的可能性较低,即全局搜索能力较小,可能会得到局部最优解,而非全局最优解.随着M值的增大,算法收敛到最优解的可能性会随之增加,但是算法的计算时间也会随之显著增加.在现实应用中,研究人员往往需要根据应用特点和个人经验设定M的取值.在本研究的应用中,M的取值不宜很大,举一个比较极端的例子来说明这一点.假设一个验证环境中共有5 000个测试,如果将M的值取为5 000,那么这5 000个测试会组成初始测试集合,需要将这5 000个测试都进行仿真,就失去了使用GA的意义.据笔者所知,目前还没有一种大家认可的方法可以通过理论计算确定M的取值,由于在大多数的文献和研究中,M的取值范围为20~100,在本研究的应用中,也将M的取值范围设定为20~100.
选择算子F是从测试集合中淘汰掉劣质的测试,将优良的特征遗传到新一代的测试集合.选择最简单也是最常见的选择方法——轮盘赌选择法作为选择算法,在该方法中,各个测试的选择概率和其适应度值成比例.假设测试集合中的测试个数为M,测试i的适应度是fi,那么i被选择的概率为

显然,选择概率反映了测试i的适应度在整个测试集的测试适应度总和中所占的比例,测试的适应度越大,其被选择的概率越高,反之亦然.计算出每个测试的选择概率以后,可以根据选择概率赋予每个测试一个取值范围.每一轮都会产生一个随机数R,R∈[0, 1).将R作为选择指针来确定被选择的测试,在进行M轮选择以后就可以选择出M个测试,形成新的测试集合.图3显示了一个轮盘赌选择法的示例,假设4个测试被选择的概率分别是36%、28%、21%和15%,根据测试的选择概率可以赋予相应的取值范围,选择范围和选择概率相对应,每轮产生一个随机数R,R在哪个测试的取值范围之中,那么此轮就选中这个测试.例如,在某一轮中R的值为0.4,那么测试 2即被选中.

图3 轮盘赌选择法Fig.3 Roulette wheel selection method


图4 单点交叉的简单示例Fig.4 Simple example of one-point crossover
变异算子Y是根据变异率对测试染色体中的某些特征位的值进行改动,一般来说,变异操作的基本步骤如下:
1) 对测试集合中所有测试以事先设定的变异率判断是否进行变异;
2) 对进行变异的测试的染色体编码随机选择变异位进行变异.
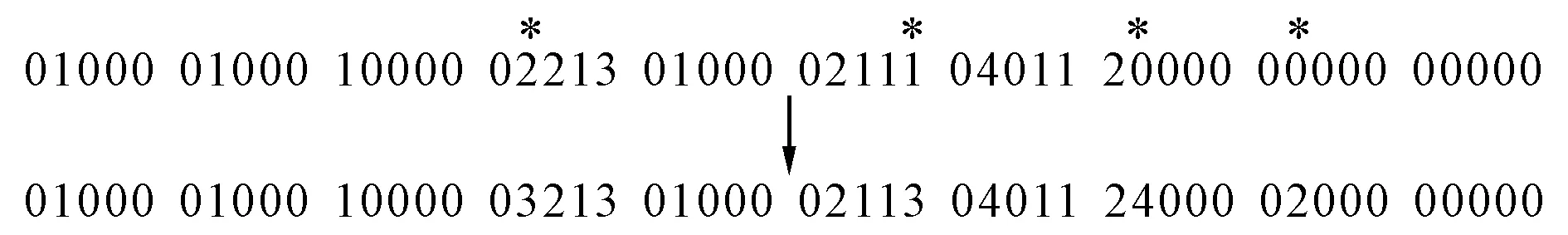
图5 变异的简单示例Fig.5 Simple example of mutation
4实验结果及分析
4.1实验设置
为了评估本文提出的方法的可实行性,选用杭州中天微系统公司的CK810MP多核处理器进行大量的实验.如图6所示,CK810MP多核处理器由修改后的CK810 处理器、核间互连以及主存储单元组成,并支持2~8个处理器的配置,其中CK810是高性能的32位嵌入式处理器.根据设计规则,修改CK810的读写单元的部分逻辑,使其支持缓存一致性协议;将修改后的多个CK810通过核间互连进行通信,核间互连不仅需要维护整个多核处理器系统的缓存一致性,还需要负责处理对共享存储器的请求;为了提高带宽,将数据通道和指令通道分开;再加上主存储单元,从而得到高性能的CK810MP多核处理器.
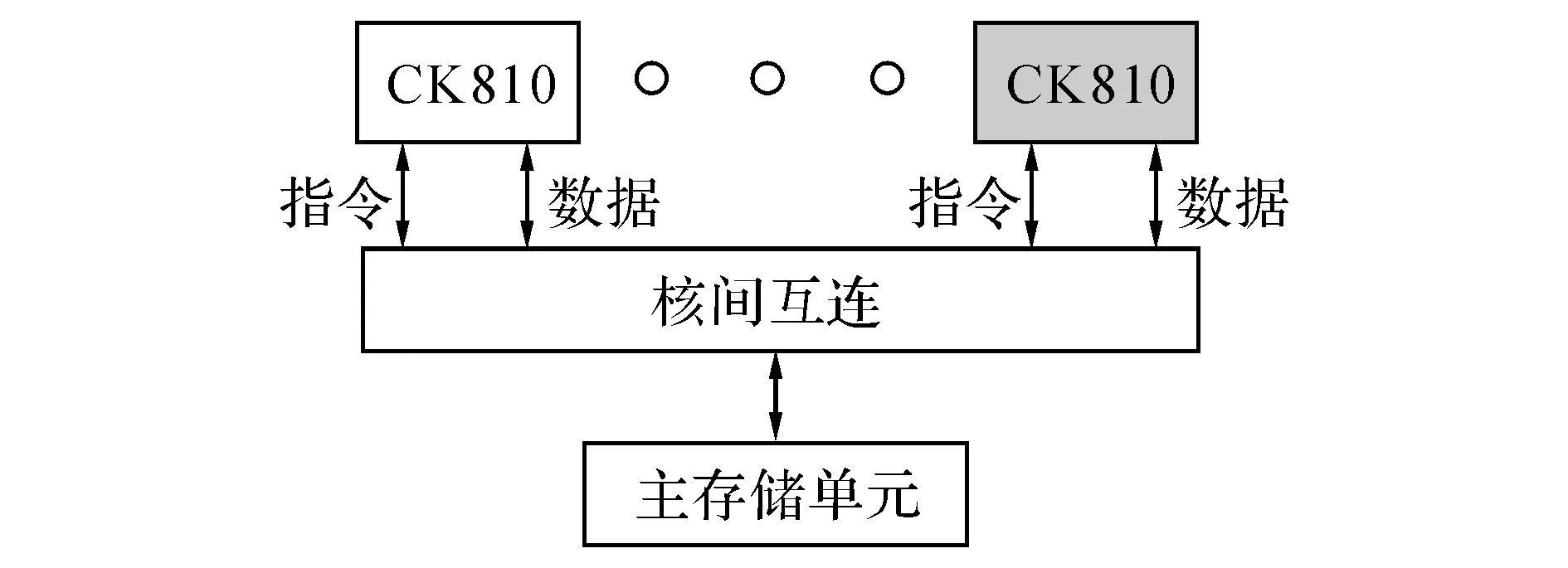
图6 CK810MP多核处理器总体架构Fig.6 Architecture of CK810MP multi-core processor
为了利用GA驱动测试产生器生成高质量的测试,首先需要设置GA的参数.参数设置情况如表1所示,将测试集合的大小M设置为50,交叉率Pc和变异率Pn分别设置为0.9和0.1.
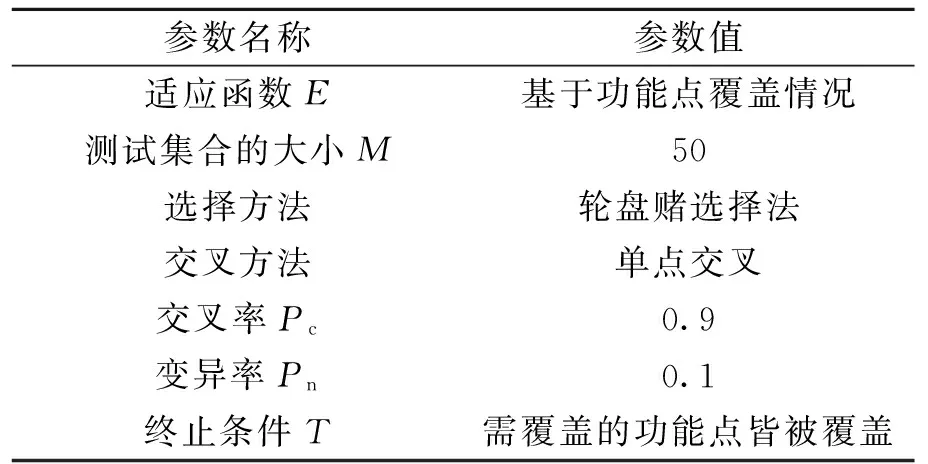
表1 遗传算法的参数设置
为了评估本文所提出的基于GA的CDTG的效率,在CK810MP的验证环境中建立一个随机测试产生器(random test generator,RTG)作对比,并分别基于文献[24]和[25]中提出的适应度函数建立2个CDTG.其中,文献[24]提出的适应度函数是基于代码覆盖率的,可以表示为

式中:L表示被覆盖的代码行数,N表示代码的总行数.另外,文献[25]提出的适应度函数是基于功能覆盖率的,是利用某一个指定的功能点的覆盖情况评估测试的适应度.
4.2基于CK810双核处理器的实验
本节中的第一个实验关注整个双核处理器的功能覆盖率.定义文献[24]的适应度函数为整个双核处理器的语句覆盖率.读写单元和核间互连一起维护多核处理器系统的高速缓存一致性,是CK810MP系统中最复杂也是最重要的单元之一.选定读写单元中的一个非常重要的功能点,用于产生文献[25]的适应度函数,这个功能点的作用是观测缓冲器的使用情况.如图7所示为整个双盒处理器的功能覆盖率的对比情况,其中c表示功能覆盖率,t表示测试的数量.从图7可以看出,使用本文提出的测试产生器大约需要297个测试可以得到100%的功能覆盖率;使用基于文献[24]的适应度函数的CDTG大约需要375个测试可以得到100%的功能覆盖率;使用基于文献[25]的适应度函数的CDTG和随机测试产生器都需要1 000个测试才可以得到大约97%的覆盖率.这表示本文提出的测试产生器可以覆盖到随机测试产生器无法覆盖的功能点,而且验证时间可以减少大约70%.同时,本文提出的适应度函数比文献[24]提出的适应度函数可以更准确地评估测试的质量,因为文献[24]的适应度函数是基于代码覆盖率的.在此,举一个简单的示例来说明这一点,假设测试M可以覆盖7行代码,但是这7代码覆盖不到任何功能点;虽然另一个测试N只能覆盖3行代码,但是这3行代码可以覆盖到一个之前的测试从来覆盖过的重要功能点.显然,测试N比测试M更有价值,但是按照文献[24]提出的适应度函数计算,测试M比测试N的适应度更高.实验结果还说明,相对于随机测试产生器,使用基于文献[25]的适应度函数的CDTG无法明显地减少需要仿真的测试数量,因为文献[25]提出的适应度函数不能很好地用于评估测试的质量,原因在于该函数只关注一个选定的功能点的覆盖情况,但是在庞大的多核处理器系统中,肯定不止有一个需要覆盖的功能点.

图7 基于不同适应度函数的CDTG双核处理器系统覆盖率对比情况Fig.7 Comparison of coverage curves of dual-core processor system based on CDTGs of different fitness functions
本节中的第2个实验只关注读写单元的功能覆盖率.如图8所示为读写单元覆盖率的对比情况.在图8(a)中,将双核处理器所有功能点的权重都设置为1,用于评估测试的质量和价值.同时,文献[24]的适应度函数与第4.2节的第一个实验相同.从图8(a)可以看出,使用随机测试产生器需要1 000个测试才能得到大约95%的覆盖率,验证效率非常低;使用基于文献[25]的适应度函数的CDTG需要1 000个测试可以得到大约96%的覆盖率,这说明相对于随机测试产生器,基于文献[25]提出的适应度函数的CDTG无法明显地提高验证效率;使用基于文献[24]的适应度函数的CDTG大约需要309个测试可以得到100%的功能覆盖率,验证效率得到了极大的提高;而使用本文提出的测试产生器需要大约243个测试就可以得到100%的覆盖率,这表示读写单元的验证效率在使用本文提出的方法以后得到了进一步提高.因为本节只须关注读写单元的功能覆盖情况,而不需要关心其他单元的覆盖情况,所以可以通过调整其他单元的功能点的权重优化适应度函数,进一步提高算法的效率.在图8(b)中,将读写单元中的功能点的权重设置为1,而将其他功能点的权重设置为0,优化适应度函数,对测试的质量进行更加准确地评估.同时,定义文献[24]中提出的适应度函数为读写单元的语句覆盖率.从图8(b)可以看出,使用文献[25]的适应度函数的CDTG和随机测试产生器需要仿真1000个测试,此时读写单元的覆盖率大约是96%;在对适应度函数进行优化以后,使用本文提出的覆盖率驱动测试产生器,大约需要194个测试就可以得到100%的覆盖率;而使用文献[24]提出的适应度函数大约需要237个测试才可以得到100%的覆盖率.这说明当只关注于某一个单元的功能点覆盖情况时,可以对适应函数中的功能点权重进行调整,将不需要关注的单元的功能点的权重设置为0,这样测试的质量的评估情况只会受被测试单元的功能点覆盖情况的影响,而减少甚至屏蔽其他单元的影响,可以更加准确地评估测试的价值和质量,使得反馈的信息更加准确,提高算法的准确度和系统的验证效率.同时,实验结果再次说明,和文献[24]中提出的基于代码覆盖率的适应度函数以及文献[25]提出的适应度函数相比,本文提出的适应度函数的选择效率更高,可以更加准确地选出高质量的测试.

图8 基于不同适应度函数的CDTG双核处理器读写单元的覆盖率对比情况Fig.8 Comparison of coverage curves of Load Store Unit in dual-core processor system based on CDTGs of different fitness functions
4.3基于CK810四核处理器的实验
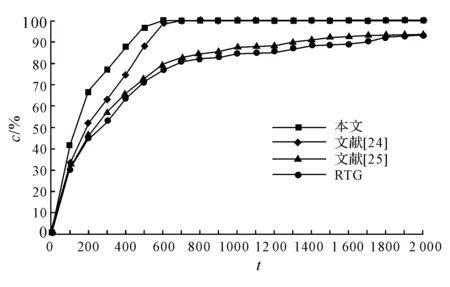
图9 基于不同适应度函数的CDTG系统覆盖率对比情况Fig.9 Comparison of coverage curves of quad-core processor system based on CDTGs of different fitness functions
本节的第一个实验关注一个CK810四核处理器的所有功能点的覆盖情况,定义文献[24]提出的适应度函数为整个四核处理器的语句覆盖率.如图9所示为功能覆盖率的对比情况.从图9可以看出,使用基于文献[25]的适应度函数的CDTG和随机测试产生器都需要2 000个测试才可以得到大约93%的覆盖率;使用基于代码覆盖率的适应度函数的CDTG大约需要633个测试可以得到100%的功能覆盖率;而使用本文提出的测试产生器大约需要552个测试就可以得到100%的功能覆盖率;实验数据说明,在四核处理器的验证环境中,本文提出的适应度函数依旧比文献[24]和[25]提出的适应度函数高效,可以更加准确地选出高质量的测试.而且,在四核处理器的验证环境中,本文提出的方法同样可以覆盖到随机测试产生器无法覆盖的功能点,可以在短时间内得到更高的功能覆盖率,提高验证效率.
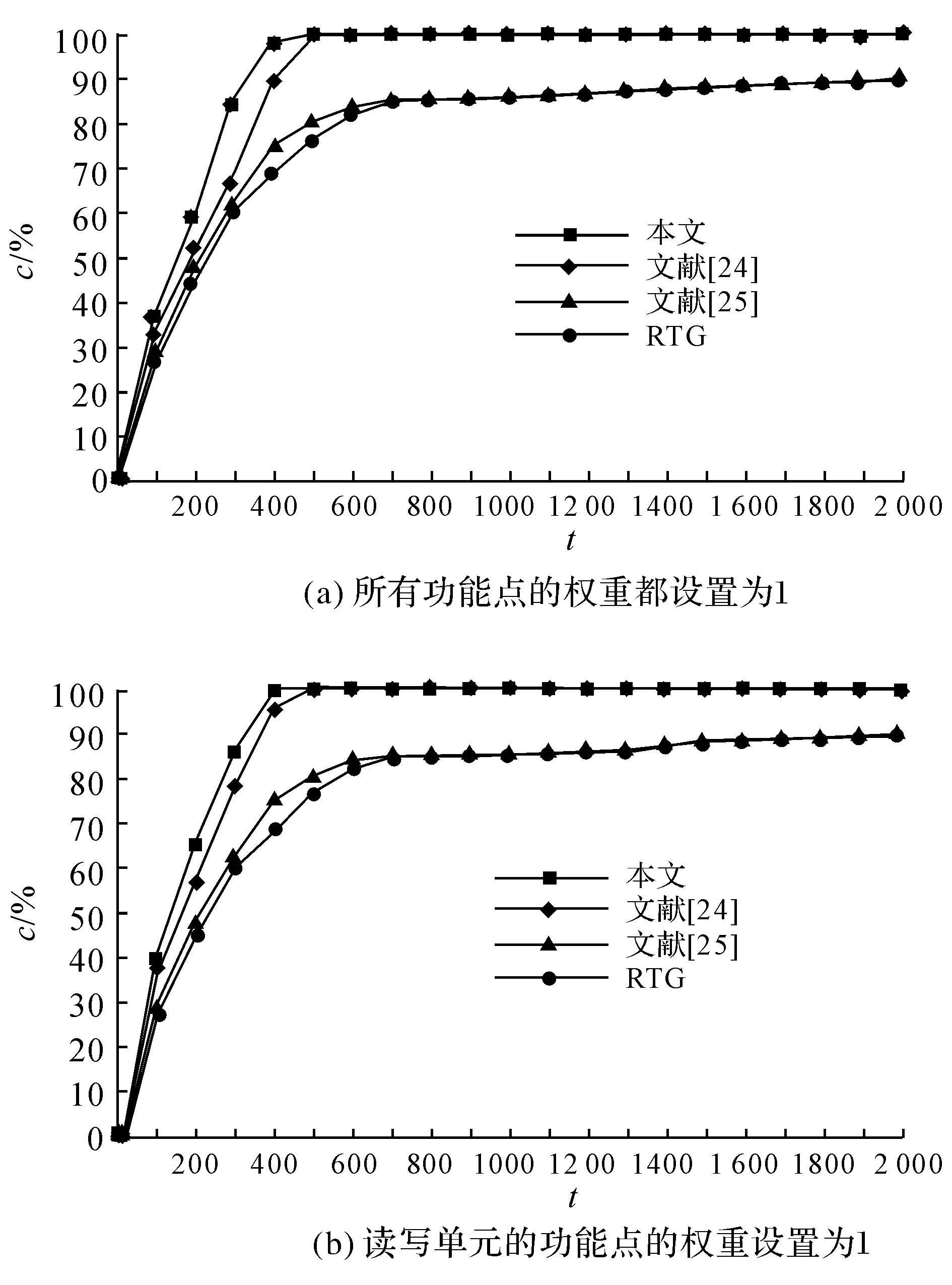
图10 基于不同适应度函数的CDTG四核处理器读写单元的覆盖率对比情况Fig.10 Comparison of coverage curves of load store unit in quad-core processor system based on CDTGs of different fitness functions
本节的第二个实验关注读写单元的功能点的覆盖情况,文献[25]的适应度函数和以上实验相同.如图10所示为读写单元的功能覆盖情况.在图10(a)中,将整个四核处理器的所有功能点的权重都设置为1,用于评估测试的质量和价值.同时,和第3个实验相同,用整个四核处理器系统的代码覆盖比例作为文献[24]提出的适应度函数.从图10(a)可以看出,使用本文提出的方法需要大约419个测试可以得到100%的功能覆盖率;使用基于文献[24]的适应度函数的CDTG大约需要505个测试;而使用基于文献[25]的适应度函数的CDTG和随机测试产生器需要2 000个测试才可以得到大约90%的功能覆盖率.实验数据说明,当只关注读写单元时,本文提出的方法和随机测试产生器相比,本文提出的方法可以明显减少CK810四核处理器的读写单元的验证时间.在图10(b)中,将读写单元的功能点的权重设置为1,将其他单元的功能点的权重设置为0,优化适应度函数.同时,定义文献[24]提出的适应度函数为读写单元的语句覆盖率.从图10(b)可以看出,随机测试测试产生器和基于文献[25]的适应度函数的CDTG最终只能得到大约90%的功能覆盖率;使用基于文献[24]提出的适应度函数的CDTG需要大约437个测试得到100%的功能覆盖率,验证效率得到了极大的提高;而使用本文提出的方法验证效率可以得到进一步提高,得到100%的功能覆盖率只需要大约356个测试.实验数据说明,当根据验证的需要适当调整和优化适应度函数以后,本文提出的测试产生器的效率可以得到进一步提高.
5结语
本文提出了一种基于遗传算法的覆盖率驱动测试产生器,利用一个基于功能覆盖率的适应度函数评估测试的质量和价值,通过遗传算法建立覆盖率分析结果和测试产生器之间的联系,驱动测试产生器生成质量更高的测试,新一代的测试具有更高的适应度,可以覆盖到上一代的测试无法覆盖的功能点.实验结果表明,和随机测试产生器相比,本文提出的测试产生器可以在短时间内得到更高的功能点覆盖率,减少了验证时间,提高了验证效率.另外,本文提出的适应度函数和基于语句覆盖率的适应度函数相比,可以更加准确地评估测试的质量和价值,从而选出高质量的测试.
在本文中,遗传算法的参数是固定不变的,这样容易造成遗传算法陷入局部最优解.今后,将对遗传算法的参数和测试的权重的自适应做进一步的研究,以得到遗传算法的局部最优解,产生质量更高的测试,提高验证效率.
参考文献(References):
[1] WANG S, HUANG K, XIE T, et al. Hybrid model: an efficient symmetric multiprocessor reference model [J]. Journal of Electrical and Computer Engineering, 2015,2015:23.
[2] FINE S, ZIV A. Coverage directed test generation for functional verification using Bayesian networks [C] ∥Proceeding of the 40th Annual Design Automation Conference. New York: IEEE, 2003: 286-291.
[3] BRAUN M, FINE S, ZIV A. Enhancing the efficiency of Bayesian network based coverage directed test generation [C] ∥ Proceeding of IEEE International Workshop on High-Level Design Validation and Test. New York: IEEE, 2004: 75-80.
[4] FINE S, FREUND A, JAEGER I, et al. Harnessing machine learning to improve the success rate of stimuli generation [J]. IEEE Transaction on Computers, 2006, 55(11): 1344-1355.
[5] BARAS D, FINE S, FOURNIER L, et al. Automatic boosting of cross-product coverage using Bayesian networks [J]. International Journal on Software Tools for Technology Transfer, 2011, 13(3): 247-261.
[6] WAGBER I, BERTACCO V, AUSTIN T. StressTest: an automatic approach to test generation via activity monitors [C]∥ Proceeding of the 42nd annual Design Automation Conference. New York: ACM, 2005: 783-788.[7] WAGBER I, BERTACCO V, AUSTIN T. Microprocessor verification via feedback-adjusted Markov models [J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2007, 26(6): 1126-1138.[8] EDER K, FLACH P, HSUEH H W. Towards automating simulation-based design verification using ILP [C]∥ Proceeding of the 16th International Conference, ILP 2006. Berlin: Springer Press, 2007: 154-168.
[9] IOANNIDES C, EDER K I. Coverage directed test generation automated by machine learning-a review [J]. ACM Transactions on Design Automation of Electronic Systems (TODAES), 2012, 17(1): 1-23.
[10] 马永杰, 云文霞. 遗传算法研究进展[J]. 计算机应用研究, 2012, 29(4): 1201-1210.
MA Yong-jie, YUN Wen-xia. Research progress of genetic algorithm [J]. Application Research of Computers, 2012, 29(4): 1201-1210.
[11] ARABALI A, GHOFRANI M, ETEZADI-AMOLI M, et al. Genetic-algorithm-based optimization approach for energy management [J]. IEEE Transactions on Power Delivery, 2012, 28(1): 162-170.
[12] CHA Y J, AGRAWAL A K. Decentralized output feedback polynomial control of seismically excited structures using genetic algorithm [J]. Structural Control and Health Monitoring, 2013, 20(3): 241-258.
[13] 方水良, 姚嫣菲, 赵诗奎. 柔性车间调度的改进遗传算法[J]. 浙江大学学报: 工学版, 2012, 46(4): 629-635.
FANG Shui-liang, YAO Yan-fei, ZHAO Shi-kui. Improved genetic algorithm for flexible job shop scheduling [J]. Journal of Zhejiang University: Engineering Science, 2012, 46(4): 629-635.
[14] 寿涌毅, 彭晓峰, 李菲, 等. 抢占式资源受限项目调度问题的遗传算法[J]. 浙江大学学报: 工学版, 2014, 48(8): 1473-1480.
SHOU Yong-yi, PENG Xiao-feng, LI Fei, et al. Genetic algorithm for the preemptive resource-constrained project scheduling problem [J]. Journal of Zhejiang University: Engineering Science, 2014, 48(8): 1473-1480.
[15]TONELLA P, SUSI A, PALMA F. Interactive requirements prioritization using a genetic algorithm [J]. Information and Software Technology, 2013, 55(1): 173-187.[16] MA Y, CUI X. Solving the fuel transportation problem based on the improved genetic algorithm [C] ∥ Proceeding of the 10th International Conference on Natural Computation (ICNC). New York: IEEE, 2014: 584-588.[17] TORRES J, GUARDADO J L, RIVAS-DAVALOS F, et al. A genetic algorithm based on the edge window decoder technique to optimize power distribution systems reconfiguration [J]. Electrical Power and Energy Systems, 2013, 45(1): 28-34.
[18] SMITH J E, BARTLEY M, FOGARTY T C. Microprocessor design verification by two-phase evolution of variable length tests [C] ∥Proceeding of IEEE International Conference on Evolutionary Computation. New York: IEEE, 1997: 453-458.
[19] BOSE M, SHIN J, RUDNICK E M, et al. A genetic approach to automatic bias generation for biased random instruction generation [C] ∥ Proceeding of the 2001 Congress on Evolutionary Computation. New York: IEEE, 2001: 442-448.
[20]YU X, FIN A, FUMMI F, et al. A genetic testing framework for digital integrated circuits [C] ∥ Proceeding of the 14th IEEE International Conference on Tools with Artificial Intelligence. New York: IEEE, 2002: 521-526.
[21] SAMARAH A, HABIBI A, TAHAR S, et al. Automated coverage directed test generation using a cell-based genetic algorithm [C] ∥ Proceeding of the 11th Annual IEEE International High-Level Design Validation and Test Workshop. New York: IEEE, 2006: 19-26.
[22] HABIBI A, TAHAR S, SAMARAH A, et al. Efficient assertion based verification using TLM [C] ∥ Proceeding of Design, Automation and Test in Europe. New York: IEEE, 2006: 1-6.
[23] SHEN H, WEI W, CHEN Y, et al. Coverage directed test generation: godson experience [C] ∥ Proceeding of the 17th Asian Test Symposium. New York: IEEE, 2008: 321-326.
[24]SUBEDHA V, SRIDHAR S. An efficient coverage driven functional verification system based on genetic algorithm [J]. European Journal of Scientific Research, 2012, 81(4): 321-326.
[25] WANG J, LIU Z, WANG S, et al. Coverage-directed stimulus generation using a genetic algorithm [C] ∥ Proceeding of the 2013 International SoC Design Conference (ISOCC). New York: IEEE, 2013: 17-19.
DOI:10.3785/j.issn.1008-973X.2016.03.024
收稿日期:2012-10-17.
基金项目:国家自然科学基金资助项目(61100074),核高基国家科技重大专项资助项目(2012ZX01039-004);中央高校基础研究基金资助项目(2013QNA5008).
作者简介:王树朋(1990-), 男, 博士生, 从事多核处理器验证研究.ORCID: 0000-0003-2322-2856. E-mail: wangsp@vlsi.zju.edu.cn 通信联系人:黄凯, 男, 副教授.ORCID: 0000-0002-5034-7171. E-mail: huangk@vlsi.zju.edu.cn
中图分类号:TN 47
文献标志码:A
文章编号:1008-973X(2016)03-09-0580
Coverage directed test generation based on genetic algorithm
WANG Shu-peng1, HUANG Kai1, YAN Xiao-lang2
(1.DepartmentofInformationScienceandElectronicEngineering,ZhejiangUniversity,Hangzhou310027,China; 2.InstituteofVLSIDesign,ZhejiangUniversity,Hangzhou310027,China)
Abstract:Coverage directed test generation based on genetic algorithm (GA)was proposed to close the loop between coverage analysis and test generation and produce the tests of good quality. A simple and accurate test encoding method was proposed. A fitness function based on functional coverage was used to evaluate the quality of tests. GA was used to close the loop between coverage analysis and test generation. The coverage results were evaluated and the constraints for test generation were modified to direct the test generation to produce the new tests, which can cover the functions that the old tests can’t cover. The experiments were conducted based on the simulation environment for verifying two high-performance 32-bit multi-core processors. Results show that the proposed method can significantly reduce simulation time and improve verification efficiency.
Key words:coverage; test generation; genetic algorithm (GA); coverage directed test generation; fitness function
