一种改进的内存索引算法在中药追溯数据处理中的应用*
2016-07-21陈继祥
张 博,盛 魁,陈继祥,董 辉
(1.亳州职业技术学院 信息工程系,安徽 亳州 236800;2.安徽省中医药科学院 亳州中医药研究所,安徽 亳州 236800)
一种改进的内存索引算法在中药追溯数据处理中的应用*
张博1,2,盛魁1,2,陈继祥1,2,董辉1,2
(1.亳州职业技术学院 信息工程系,安徽 亳州 236800;2.安徽省中医药科学院 亳州中医药研究所,安徽 亳州 236800)
摘要:在中药质量追溯系统中,为了保证中药材在流通环节中的数据采集效果,需要部署RFID标签和传感器.在大规模RFID应用中,后台服务器处理的标签数据量巨大,容易造成数据传输的瓶颈.在数据检索时采用改进的遍历索引算法,构建高效的内存数据结构,能够加快RFID标签数据读取速度,提高数据源的稳定性,同时降低后台数据库的负担,确保数据处理的高效性和安全性.
关键词:数据处理;索引结构;RFID
在RFID系统应用中,RFID读写器通过无线射频方式与标签通信,获取标签的感知数据并发送到服务器平台进行处理.在中药材质量追溯系统中,为了保证中药材流通过程中的溯源效果,需要大规模部署RFID标签和传感器,由于读写器需要读写的药材标签数据量较大,这就会产生大量标签数据发送给后台服务器,造成网络数据吞吐量增加,容易导致网络堵塞和服务器负担过重[1].为解决上述问题,目前主流的解决方法是通过设置前置数据处理服务器,将读写器获取的RFID标签数据进行提前分组和筛选,经过前置服务器处理后的数据发送给后台数据库服务器,这样就可以减少网络数据吞吐量,降低了后台数据库服务器的负担.
如何优化前置服务器的数据处理算法和数据结构,是提高前置服务器效率的关键.本文提出一种改进的T+树内存数据结构算法,在传统T树的基础上引入链式存储结构,通过实际环境的测试验证,能够达到预期的目的.
1RFID数据处理基本方法
1.1标签数据状态特性
在 RFID 系统中,标签和读写器通过事先分配的OID识别码,能够自动完成感知和匹配过程[2];当标签和读写器之间完成数据传送后,感知关系将断开.整个感知过程中,标签的状态分别处于感知、相应、断开三个状态,并且这三种状态处于不断的循环过程中[3].
在物联网系统的应用中,感知设备之间通过无线信号进行联系,当标签和读写器的距离处于感知和断开的临界状态时,或者标签的电量不足导致标签收发无线射频信号强度不够时,可能会使标签处于两种状态的交替阶段,这时读写器可能会失去对标签的感知.因此系统判断RFID标签是否处在被感知状态,应该观察标签的连续读写和感知状态[4],而不能凭某一个独立的周期来进行判断.
1.2标签数据处理过程
在RFID系统部署中,每一个标签包含的信息有:标签识别码、标签来源、标签保持状态、标签当前读取序号.RFID系统数据库服务器会对每一个周期的标签状态数据进行读取对比[5],具体操作类型有:①标签数据的插入:RFID读写器读取标签的状态数据后,将其与数据库中已保存的RFID标签数据进行比较,如果重合则该标签已存在,如果比较结果没有重合,则确认该标签为新标签,并更新标签数据库的信息[6].
②事件查询:通过查询标签的当前状态,生成标签汇总信息,同时将汇总信息上传到后台服务器.
③删除标签数据:查询处于非激活状态的标签并进行删除操作,同时更新数据库.
在物联网系统的部署过程中,对于来自于感知层的无线射频标签数据处理,将产生大量的处理任务,如何提高任务处理的效率[7],已经成为RFID应用需要重点关注的地方.
1.3内存数据处理方法
(1)RFID系统部署对数据库的要求.在RFID系统进行部署时,实时处理数据将增加服务器的负荷,由于来自于RFID标签的大量数据需要进行处理,同时大部分情况下无法预测标签的长度和标签数据的长度,因此传统的算法普遍处理效率不高[8],大大影响了RFID系统的部署效果.由于RFID系统的数据主要来自于实时数据读取和采集,因此和传统数据库的结构不同,需要将数据库的活动部分常驻主存,这样才可以提高数据库的访问速度和效率,从而满足RFID系统的运行需求.如何设计合理的内存索引数据结构,提高数据库的访问速度和数据吞吐量,已经成为RFID服务器部署时需要重点考虑的环节[9].
(2)内存索引的构建原理.构建合理的内存数据库的索引结构,是提高数据读写访问效率的重要基础,在业界比较流行的模式是采用B树与T树索引.
①B树.B树结构由R.Bayer和 E.Mccreight提出,B树的关键字在整棵树中均匀分布,适合于顺序查找[10].
假设一棵p阶的B树的结构如下:
a.如果根节点不是叶子节点,则其拥有2个孩子,其余各节点最多拥有 p个孩子[11];
b.除根节点和叶子节点外,其他节点最少拥有p/2 个孩子;
c.所有叶子节点都处于同阶;
d.有q个孩子的节点(除根节点和叶子节点)具备 q-1 个关键字.
在B树中每个节点按照值域顺序生成,由于B树属于平衡多叉树,其完成数据索引的步骤是:先搜索到根节点,然后在根节点拥有的关键字(r1,……,ri)中查询目标关键字,如果找到目标关键字就返回查找成功的结果,若未找到目标关键字则将查找范围扩大至ri到ri+1之间,如果查找结束以后返回指向节点的指针为空,则表示查找过程失败.
B树的关键字均匀分布在树中,并且出现在单个节点中, B树采用二分法对关键字进行查找,其算法复杂度为O(log2n).
②T 树.T树索引结构由TobinJ Lhemna和Mihcael Carye提出,T树结合了AVL树和B树的优点,适合于构建内存数据库的索引结构.T树的每一个节点可以保存多个索引键值,这样提高了节点的空间效率[12],由于T树本质是AVL树,所以各个节点有序排列,左子树比根节点键值小,右子树比根节点键值大.T树特征如下:
a.T树中某一节点的左右子树相差1;
b.T树中的节点拥有多个键值,这些键值按照顺序排列;
c.每个节点包含的键值小于指定值,为小于等于节点中最大键值-2.
一个T树节点包含了一个指向上一级父节点的指针,分别指向左右子节点的指针.在每一个节点中包含L和M两个关键值,L是遍历T树时本节点前的所有节点中最大值,M是遍历T树时在节点后的所有节点中最小值,T树的结构图如图1所示.
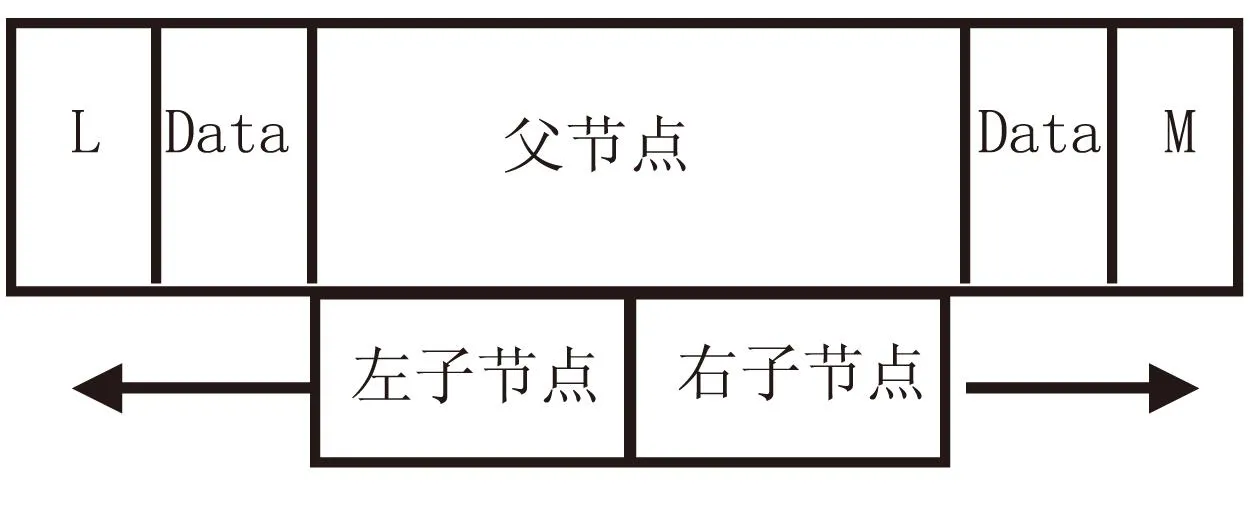
图1 T树节点结构图
T树的主要操作包括查找、插入、删除.
a.T树查找操作:首先要检索目标值是否处于当前节点的左右键值之间,如果处于之间,将进行二分法查找;如果目标值大于右键值,将开始检索右子节点;如果小于左键值,则对左子节点进行扫描.
b.T树的插入操作:首先要查找插入位置,当位置检索成功后,需要判断树中存储空间是否充足,如果还有剩余空间,则将目标值插入到检索成功位置,否则将根据目标值与左右键值的大小关系,为目标值分配新的节点,并将该节点关联到上一节点的左子树或右子树.同时对T树进行平衡检查,若不满足平衡调节则进行旋转操作.
c.T树的删除操作:首先搜索删除节点,搜索目标成功后将该节点键值删除,如果删除后该节点变为空节点,则将该节点也删除,同时对T树进行AVL检查,确定是否进行旋转操作.
在T树的使用过程中,为了避免树节点的臃肿,规定T树内的每一个节点的关键字个数都不能大于左右子树之差.当完成插入和删除操作后,必须要对T数进行平衡性检查,以此保证T树的使用效率.
2改进的内存索引结构T+树
2.1T+树的内存索引结构
对于 RFID 应用来说,需要部署大规模感知设备和RFID标签,因此数据处理的负担也随之增加.由于T树的树高较大,导致在树节点进行更新时处理量加大,同时需要进行加锁的节点数量也随之增加,从而影响了T树的遍历过程,降低了内存数据的处理性能,因此针对传统的T树结构进行改进,以适应大规模并发数据处理的情况.
本文提出了一种改进的T+树,在原有T树结构上增加3个指针,F指针指向树的上一级节点,L指针指向包含每个节点的头指针链表,E指针指向包含每个节点的控制域链表,这样可以通过指针将标签数据的节点进行有机链接,从而更好地完成整个树的查找、删除、插入和旋转操作,能够使T+树在构建内存索引结构中的效率更高,其结构图如图2所示.
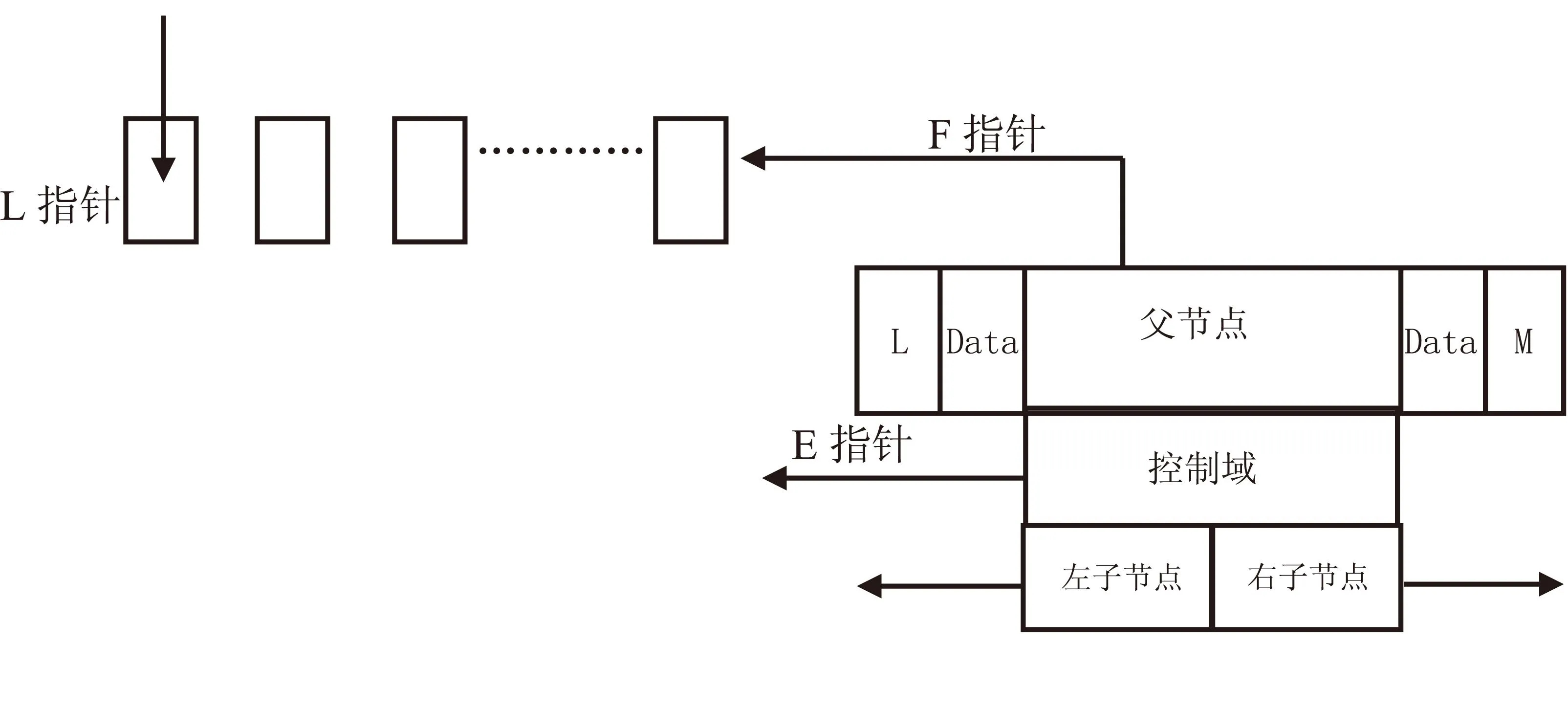
图2 T+树节点结构图
2.2RFID标签数据处理过程实现
RFID数据服务器在对标签数据进行处理时,主要涉及到的状态数据有:标签识别码、标签来源、标签保持状态、标签当前读取序号.在T+树中,每个节点中设置对应的相关数据域,对上述5类数据进行分别保存,同时在T+树中设置3个控制节点,分别用于保存下列链表的指针:查找成功的节点指针、已处理完毕的节点指针和处于被查找状态的节点指针.
标签数据存储在T+树结构的内存索引数据库中,对数据进行读写和存储操作时使用T+树完成,在对标签数据进行状态更新时使用链表指针完成对内存索引结构的遍历操作.
2.3算法的实施
RFID服务器在处理标签数据时,使用T+树建立的内存索引结构对数据进行处理,主要包括查询、插入和删除操作.
(1)查询:当标签进入T+树的读写队列后,首先读取标签的状态指针关键值,然后判断键值是否处于链表关键节点的键值范围,如果处于范围内,则返回查找成功状态,否则依次按照上述步骤查找链表关键节点的左右子树的键值.
(2)插入:首先读取E指针中指向包含每个节点的控制域数据,然后判断和查找插入位置,插入位置确定后,同时要检查该节点中的存储空间是否满足插入标签数据的要求,成功后则将标签数据成功插入到检索位置,否则将继续对下一节点的左右子树控制域进行读取,直到检索到满足标签数据插入的位置,重复上述的插入操作.
(3)删除:通过读取L指针指向当前节点的头指针链表,判断头指针状态,若为空则完成删除节点操作,若不为空,则将L指针移动到左(右)子树节点的链表,再次进行是否为空链表的判断,从而完成删除节点的操作.
在上述操作中,对于标签的每一次数据操作周期,由于E指针和L指针的循环使用,可以更高效地完成对整个内存数据的遍历过程,进一步提高数据处理速度.
2.4性能分析
通过对T+树的算法进行计算验证,与基于T树结构的内存索引结构相比,T+树结构的内存索引数据库在实际使用中,插入、删除等操作的效率更高,同时表现出更好的稳定性.验证平台为使用INTEL I3-4170 3.7Ghz(3M Cache)CPU,4G DDR3内存的计算机,操作系统为WINDOWS 7(64位)系统,数据库版本采用MS-SQL Server 2012 SP2版本,RFID标签数选用13.56M高频电子标签,标签存储容量32B,数量为10个,算法采用C++语言编写,完成对索引结构的遍历、删除、插入操作,节点数为1000个.

图3 插入节点操作
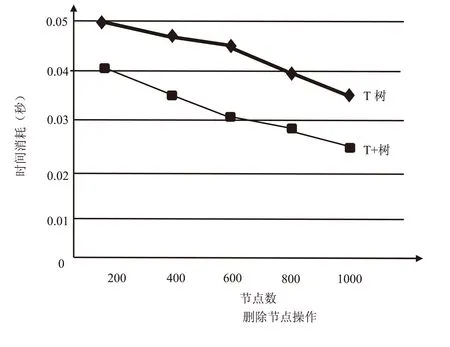
图4 删除节点操作
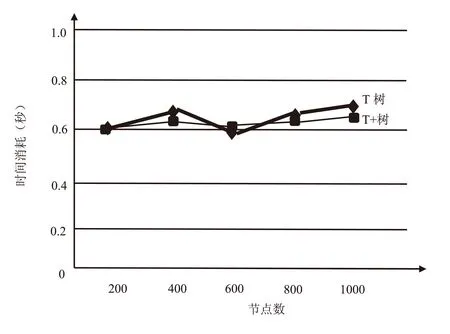
图5 遍历节点操作
上述性能对比结果显示(见图3~图5),T树结构由于其本质属于平衡二叉树,运行效果较好,具备很好的稳定性.T+树具有T树的节点,在节点的控制过程中引入了链表结构,同时利用增加的3个指针,进一步提高了T+树的操作灵活性和稳定性,使整个内存索引的数据操作达到了高效率的目标,两种索引结构在遍历节点的操作性能相差不大,但是T+树在插入和删除操作的时间耗费均低于传统的T树结构,符合内存索引算法的发展方向.在大规模部署中药材溯源系统时,由于所需要的RFID标签数量较大,涉及到的数据量较多,单位时间内存数据库的负担加重,需要考虑到T+树需要搜索整棵树才可以完成处理任务的特点,因此当前的算法可能会对系统的部署造成一定影响,降低内存数据库的运行效率和速度,这是未来需要改进和完善的地方.
3结论
本文针对在大规模部署RFID标签过程中,如何应对事件处理服务器的工作模式进行了探讨,对目前常见的内存数据索引结构进行了比较,在基于T树结构的基础上,提出了改进的T+树内存索引结构,同时将T+树与传统的B树和T树的运行效果进行对比,改进的T+树结构能够较好地处理大规模RFID标签数据的读写任务,为中药材溯源系统的建设提供技术基础.
参考文献:
[1]龚华明,阴躲芬.基于T*树的RFID数据缓存的研究与实现[J].计算机与数字工程,2013,41(12):1967-1969.
[2]陈毅红,冯全源,谈文蓉.物联网中RFID多标签识别技术研究综述[J].西南民族大学学报(自然科学版),2014,40(5):719-723.
[3]董绍婵,周敏奇,张蓉,等.内存数据索引以处理器为核心的性能优化技术[J].华东师范大学学报(自然科学版),2014(5):192-206.
[4]张建华,张楠.基于混沌的RFID双向认证协议[J].铁道学报,2013(7):85-89.
[5]赵海,欧阳元新,熊璋.用于RFID中间件的主存数据库索引结构[J].西南民族大学学报(自然科学版),2014,40(4):531-536.
[6]罗元剑,姜建国,王思叶,等. 基于有限状态机的RFID流数据过滤与清理技术[J].软件学报,2014,25(8):1713-1728.
[7]张博,南淑萍,孟利军. RFID技术在道地中药材质量溯源中的应用研究[J].长沙大学学报,2015,29(2):64-66.
[8]吕鹏,蒋平,吴钦章.一种T-树的优化设计与实现方法[J].计算机工程,2013,29(2):5-8.
[9]薛世帅,刘丹,徐展,等.有源RFID标签安全文件系统的设计[J].计算机工程与应用,2014(24):47-49.
[10]王向前,洪一,郑启龙.分块内存的数据分布优化[J].小型微型计算机系统,2015,4(6):350-352.
[11]唐军,卢正新.支持内存数据库索引缓存优化的CST树的设计与实现 [J].计算机与数字工程,2010,38(1):173-176.
[12]刘勇,奚建清,黄东平,等.图形处理器上内存数据库索引T-树的研究[J].华南理工大学学报(自然科学版),2013,41(3):22-28.
(责任编辑:王前)
DOI:10.13877/j.cnki.cn22-1284.2016.06.022
*收稿日期:2016-03-15
基金项目:2014年度安徽省教育厅自然科学基金重点项目(KJ2014A171);2014年度安徽省高校振兴计划优秀青年人才支持计划(皖教秘人2014(181)号);2014年度亳州市政府创新创业领军人才行动计划(亳组2014(21)号);2015年度亳州市产业创新团队(亳组2015(20)号)
作者简介:张博,男,安徽界首人,副教授.
中图分类号:TP274
文献标志码:A
文章编号:1008-7974(2016)03-0070-04
