基于保留部分频域镜像分量的声源定位算法
2016-07-19蔡卫平刘瑞娟
蔡卫平 刘瑞娟 周 琳
1(九江职业技术学院电气工程学院 江西 九江 332007)2(东南大学信息科学与工程学院 江苏 南京 210096)
基于保留部分频域镜像分量的声源定位算法
蔡卫平1刘瑞娟1周琳2
1(九江职业技术学院电气工程学院江西 九江 332007)2(东南大学信息科学与工程学院江苏 南京 210096)
摘要针对传统的SRP-PHAT(Steered Response Power with Phase Transform)声源定位算法容易受噪声影响而导致定位性能降低的问题,提出一种频域补零且保留部分镜像分量的改进算法。该算法首先通过傅里叶变换将接收信号变换到频域,然后在高频端补零至20倍帧长,同时保留部分镜像分量。在此基础上计算麦克风对接收信号的互功率谱密度函数,作傅里叶逆变换得到相位变换加权的广义互相关(GCC-PHAT)函数。保留的镜像分量拓宽了信号频域,使GCC-PHAT函数的峰更为尖锐,累加后得到的SRP-PHAT函数的空间谱峰也就更加尖锐,从而提高定位性能。实验表明,相比于传统算法,改进算法能显著提高定位成功率。
关键词相位变换声源定位镜像分量
0引言
由于噪声和混响的影响,在真实环境中实现较高精度的声源定位仍然是比较困难的,尤其是小型阵列,受阵列孔径及阵元个数的限制,定位精度较低。在已有的声源定位算法中,以多重信号分类MUSIC(MultipleSignalClassification)算法[5]为代表的高分辨率谱估计算法理论上可以达到很高的精度,但是该算法不能处理高度相关的信号,混响将使得定位性能急剧下降。文献[6]提出导引响应功率SRP-PHAT声源定位算法。该算法的定位原理是根据接收信号计算假想声源位置处的导引响应功率,使其取最大值的点即为声源位置估计。SRP-PHAT算法在混响环境中具有较强的鲁棒性,但是计算复杂度较高,为提高算法的实时性,研究人员提出了多种减少其计算量的方法[7-9]。SRP-PHAT算法在低信噪比、强混响条件下的定位性能仍然较低,对此,研究人员也提出了多种改进方法。文献[10]提出了最大似然定位算法,该算法在低信噪比、弱混响条件下能较大幅度提高定位性能,而在高信噪比或强混响条件下定位性能与SRP-PHAT接近。针对分布式阵列的特点,文献[11]提出加权SRP-PHAT算法,利用各阵元接收信号质量的不同,对于信号质量较好的阵元赋予较大权重,从而提高定位性能。文献[12]则提出了更为简单的加权算法。文献[11,12]的算法只能用于分布式阵列,小型阵列中,各阵元接收信号质量几乎没有差别,加权算法不能提高定位性能。文献[13]提出了基于归一化算术平均的宽带SRP算法,该算法改善了噪声环境下的定位性能,但不适用于有混响的室内环境。
SRP-PHAT函数可表达成所有麦克风对的广义互相关GCC-PHAT(GeneralizedCrossCorrelationwithPhaseTransform)函数之和[6]。由于采用了相位变换PHAT(PhaseTransform)加权,GCC-PHAT函数应该有尖锐的峰,从而SRP-PHAT函数有尖锐的空间谱峰,但是由于噪声,实际的空间谱峰变得较宽,又由于反射声的存在,其产生的虚假谱峰与直达声的谱峰相互叠加,使得SRP-PHAT函数的最大值所在位置偏离了真实声源的位置,导致定位误差。根据上述分析,本文提出一种改进的SRP-PHAT算法。该算法将麦克风对接收信号的互功率谱拓宽,使得其相应的互相关函数更加尖锐,累加后得到SRP-PHAT函数的空间谱峰也就更加尖锐,从而提高定位精度。
1信号模型
假设麦克风阵列的阵元个数为M,用s(n)表示声源信号,则在真实环境中,第m个阵元的接收信号为:
xm(n)=hm(n)*s(n)+bm(n)
(1)
其中hm(n)为声源到第m个阵元的房间冲击响应,“*”表示线性卷积,bm(n)表示第m个阵元的背景噪声。式(1)中的卷积运算表征了阵元接收信号中既有声源信号的直达声也有多次反射声。假设声源信号与噪声不相关,各通道的背景噪声也不相关。
2SRP-PHAT算法
2.1SRP-PHAT的原理
如前文所述,SRP-PHAT函数可表达成所有麦克风对的GCC-PHAT函数之和,即:
(2)
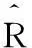
(3)
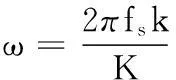
ζ=[cosφcosθ, cosφsinθ, sinφ]T
(4)
用rm=[x,y,z]T表示第m个麦克风的直角坐标矢量,c表示空气中的声速(约为342m/s),则:
(5)
声源位置估计为:
(6)
其中Q为声源空间。
2.2SRP-PHAT的实现
竹林机械化经营是一个全新的课题,不仅要有理念上的转变,也要有模式和方法的创新。目前,虽然对上述3种模式进行了初步的探索与实践,但由于试验时间较短,样地面积和规模都较小,其成果应用仍有许多局限性。为此,需要业界朋友集思广益,群策群力,以期早日形成具有共性的机械化经营模式,为竹产业的振兴和可持续发展做出新贡献。
(7)
3改进的SRP-PHAT算法
如前文所述,由于噪声和混响的影响,SRP-PHAT函数的空间谱峰变宽,容易相互叠加,导致声源位置估计误差。众所周知,互相关函数与互功率谱是一对傅里叶变换,令:
(8)
(9)
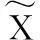
(10)
(11)
相应的真实声源位置估计为:
(12)
4实验与分析
4.1实验环境
为了比较改进算法与原算法的性能,我们利用在真实环境中录制的数据库AV16.3[16]来做声源定位实验。AV16.3是在会议室中录制的,包括多种情景,专门供声源定位研究人员使用。本实验取单个静止声源的一组数据,编号为“seq01_1p_0000”,录制场景如图1所示。
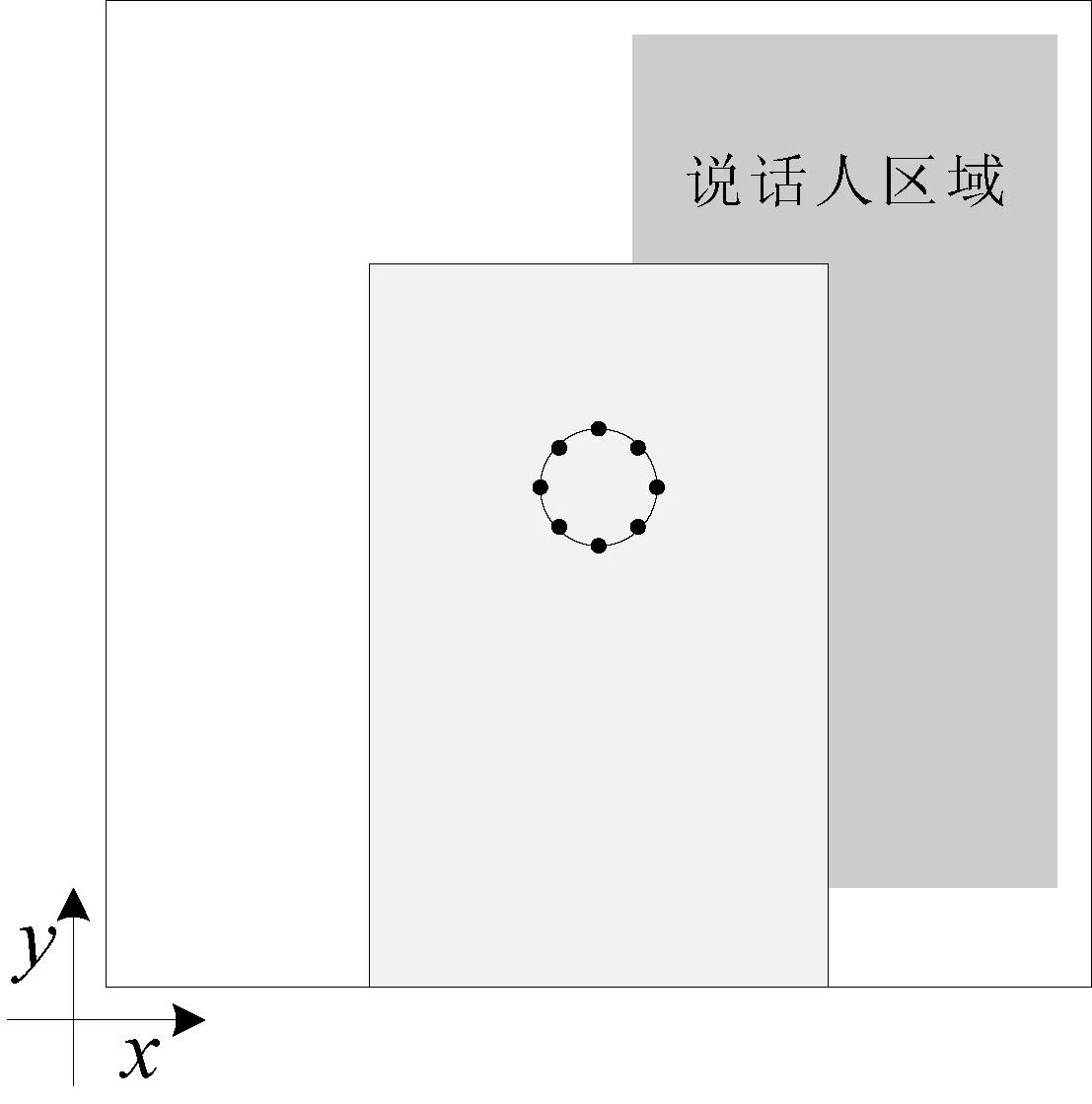
图1 说话人区域与麦克风阵列的位置
图1中的阴影部分为声源所在区域,说话人分别在16个位置说一段话。麦克风阵列为具有八个阵元的均匀圆阵,半径为0.1m,放置于会议桌上。由于阵列孔径较小,满足远场条件,即只估计声源的到达方向角DOA(DirectionofArrival),麦克风阵列与DOA矢量的关系如图2所示。
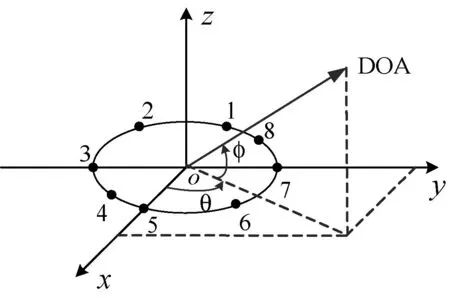
图2 麦克风阵列与DOA矢量
图2中,坐标原点位于阵列圆心,xoy平面就是阵列所在平面,小黑点表示麦克风,DOA矢量由坐标原点指向声源,其单位矢量就是式(4)所描述的ζ。说话人为男性,说英语,信号采样频率fs=16kHz。信号帧长512点(32ms),帧重叠率50%,加汉宁(Hanning)窗,去掉静音间隙后,总计有5646帧信号用于声源定位实验。水平角θ的搜索范围为-180°~180°,仰角φ的搜索范围为0°~90°,步长均为1°。
4.2性能评价准则
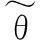
(13)
(14)
(15)
4.3实验结果
我们用传统的SRP-PHAT算法和本文提出的改进算法处理前文描述的真实数据。为便于描述,改进算法记为SRP-PHAT-PZ。IDIAP提供了实现传统SRP-PHAT算法的MATLAB程序,其实现方法如2.2节所述,可直接使用该程序得到传统算法的实验结果。我们修改IDIAP的程序实现改进算法。IDIAP的程序中,设置L=20,为便于比较,本文仍然采用该参数值。对于水平角,γ取1°~180°,对于仰角,γ取1°~90°,步长均为1°。两种算法的定位成功率如图3所示。
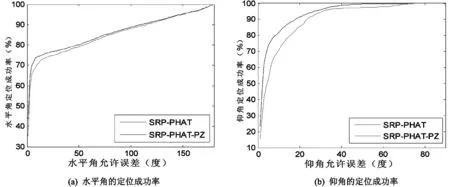
图3 两种算法的定位成功率比较
由图3可见,在不同的允许误差下,改进算法的定位成功率都比传统算法的要高,其中仰角的定位成功率提高幅度更大。比较实用的允许误差角度通常为几度到十几度[10],表1给出了几种典型的允许误差角度下,两种算法定位成功率的具体数据。
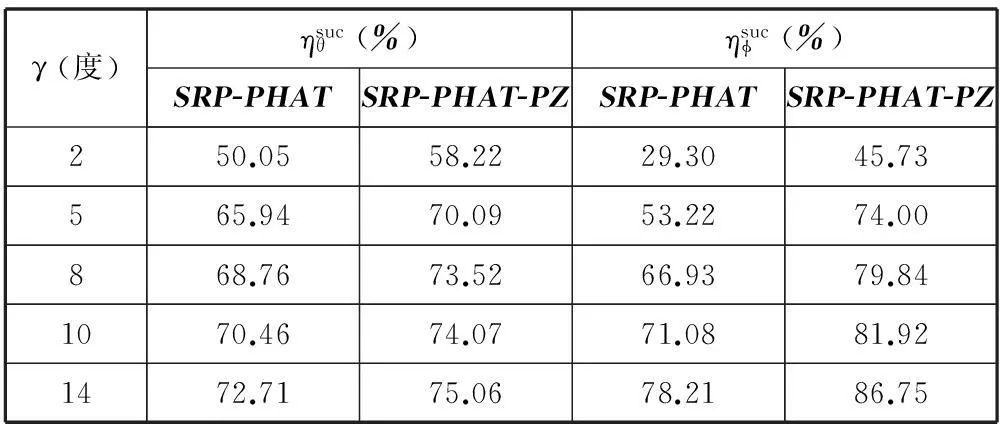
表1 在典型的允许误差角度下,两种算法的定位成功率比较
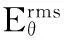
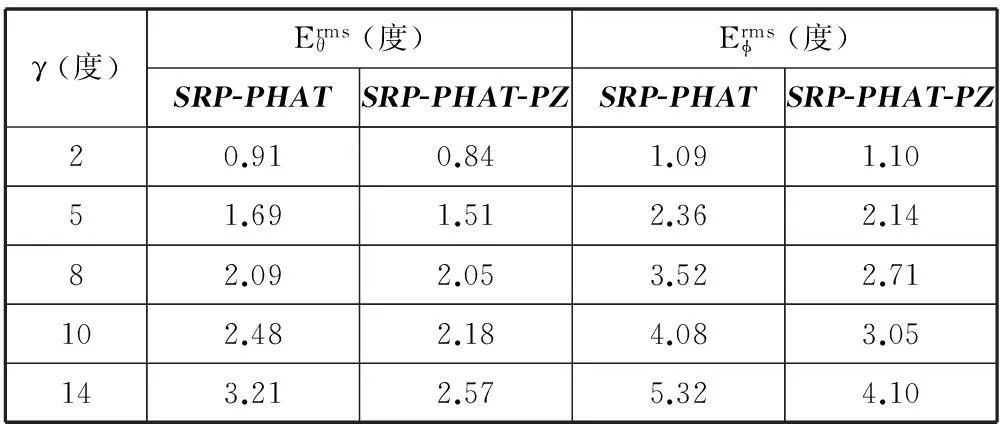
表2 在典型的允许误差角度下,两种算法的均方根误差比较
5结语
SRP-PHAT算法能实现真实环境中的声源定位,但是在信噪比较低、混响较强的环境中,其定位性能仍然不高。本文提出一种保留部分频域镜像分量的改进算法。采用在信号高频端补零的方法来提高时域采样率,在此过程中保留了部分频域镜像分量,从而拓宽了互功率谱的频带宽度,使得互相关函数的峰更加尖锐。SRP-PHAT函数可表示为所有麦克风对接收信号的GCC-PHAT函数之和,更为尖锐的GCC-PHAT函数使得SRP-PHAT函数中真实声源对应的空间谱峰与反射声对应的谱峰不容易重叠,避免谱峰位置偏移。实验表明,本文提出的算法比传统算法的定位成功率有较大幅度提高,同时减小了估计的均方根误差。
参考文献
[1]FaubelF,GeorgesM,KumataniK,etal.Improvinghands-freespeechrecognitionincarthroughaudio-visualvoiceactivitydetection[C]//ProceedingofJointWorkshoponHands-freeSpeechCommunicationandMicrophoneArrays.Edinburgh,UK:IEEE,2011:70-75.
[2]SunL,ChengQ.Real-timemicrophonearrayprocessingforsoundsourceseparationandlocalization[C]//ProceedingofIEEE47thAnnualConferenceonInformationSciencesandSystems(CISS).Baltimore,MD,USA:IEEE,2013:1-6.
[3]TourbabinV,RafaelyB.Theoreticalframeworkforthedesignofmicrophonearraysforrobotaudition[C]//ProceedingofIEEEInternationalConferenceonAcoustics,Speech,andSignalProcessing(ICASSP).Vancouver,Canada:IEEE,2013:4290-4294.
[4]SeewaldLA,JrLG,VeronezMR,etal.CombiningSRP-PHATandtwoKinectsfor3Dsoundsourcelocalization[J].ExpertSystemswithApplications,2014,41(16):7106-7113.
[5]DmochowskiJP,BenestyJ,AffesS.BroadbandMUSIC:opportunitiesandchallengesformultiplesourcelocalization[C]//IEEEWorkshoponApplicationsofSignalProcessingtoAudioandAcoustics.NewPaltz,NY,USA:IEEE,2007:18-21.
[6]DibiaseJH.Ahigh-accuracy,low-latencytechniquefortalkerlocalizationinreverberantenvironmentsusingmicrophonearrays[D].Providence:DivisionofEngineeringatBrownUniversity,2000.
[7]ZhaoY,ChenX,WangB.Real-timesoundsourcelocalizationusinghybridframework[J].AppliedAcoustics,2013,74(12):1367-1373.
[8]OualilY,FaubelF,KlakowD.Afastcumulativesteeredresponsepowerformultiplespeakerdetectionandlocalization[C]//ProceedingofEuropeanSignalProcessingConference(EUSIPCO).Marrakech,Morocco:IEEE,2013:1-5.
[9]NunesLO,MartinsWA,LimaMVS,etal.ASteered-responsepoweralgorithmemployinghierarchicalsearchforacousticsourcelocalizationusingmicrophonearrays[J].IEEETransactionsonSignalProcessing,2014,62(19):5171-5183.
[10]ZhangC,FlorencioD,BaDE,etal.Maximumlikelihoodsoundsourcelocalizationandbeamformingfordirectionalmicrophonearraysindistributedmeetings[J].IEEETransactionsonmultimedia,2008,10(3):538-548.
[11]MungamuruB,AarabiP.Enhancedsoundlocalization[J].IEEETransactionsonSystems,Man,andCybernetics-partB:Cybernetics,2004,34(3):1526-1540.
[12] 蔡卫平,黄印君,陆泽橼.基于分布式麦克风阵列的声源定位算法[J].计算机应用与软件,2014,31(5):132-135.
[13]SalvatiD,DrioliC,ForestiGL.Incoherentfrequencyfusionforbroadbandsteeredresponsepoweralgorithmsinnoisyenvironments[J].IEEESignalProcessingLetters,2014,21(5):581-585.
[14]KnappCH,CarterGC.Thegeneralizedcorrelationmethodforestimationoftimedelay[J].IEEETransactionsonAcoustics,Speech,andSignalProcessing,1976,24(4):320-327.
[15]DmochowskiJP,BenestyJ,AffesS.Ageneralizedsteeredresponsepowermethodforcomputationallyviablesourcelocalization[J].IEEETransactionsonAudio,Speech,andLanguageProcessing,2007,15(8):2510-2526.
[16]LathoudG,OdobezJM,Gatica-perezD.AV16.3:anaudio-visualcorpusforspeakerlocalizationandtracking[R].Martigny:IDIAPResearchInstitute,2004.
SOUND SOURCE LOCALISATION ALGORITHM BASED ON RETAINING PARTIALMIRRORCOMPONENTSINFREQUENCYDOMAIN
Cai Weiping1Liu Ruijuan1Zhou Lin2
1(School of Electrical Engineering,Jiujiang Vocational and Technical College,Jiujiang 332007,Jiangxi,China)2(School of Information Science and Engineering,Southeast University,Nanjing 210096,Jiangsu,China)
AbstractTo deal with the problem of the sound source localisation algorithm of traditional steered response power with phase transform weighting (SRP-PHAT) that its localisation performance is easily degraded due to noise influence, in this paper we propose an improved algorithm which pads the zeros in frequency domain and retains partial mirror components as well. First, the algorithm transforms the received signals to frequency domain through fast Fourier transform (FFT), and then pads the zeros to reach 20 times of the frame length in high-frequency band while preserving part of the mirror components. On this basis, the cross power spectral density function of the microphone pair on received signals can be estimated, and the corresponding generalised cross correlation with phase transform weighting (GCC-PHAT) function can be obtained by taking inverse fast Fourier transform (IFFT). The retained mirror components broaden the signal spectrum so that the peak of GCC-PHAT function becomes sharper. Consequently, the spatial spectrum peak of SRP-PHAT function, which is the accumulation of GCC-PHAT functions for all of the microphone pairs, becomes sharper, thus the localisation performance is improved. Experiments show that compared with conventional algorithms, the proposed algorithm can considerably enhance the success rates of sound source localisation.
KeywordsPhase transformSound source localisationMirror components
收稿日期:2015-01-18。国家自然科学基金青年基金项目(61201 345)。蔡卫平,副教授,主研领域:阵列信号处理。刘瑞娟,讲师。周琳,副教授。
中图分类号TP391.4
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.077
