服务发现中的用户偏好模型构建方法分析与比较
2016-07-19段丽君
段丽君
(湖北第二师范学院 计算机学院,武汉 430205)
服务发现中的用户偏好模型构建方法分析与比较
段丽君
(湖北第二师范学院 计算机学院,武汉 430205)
摘要:用户偏好模型能揭示用户的个性化需求,提高服务发现的精度与效率。本文根据构建手段的不同,对目前服务发现研究中各种典型的用户偏好模型方法进行了分类,并详细分析了它们的原理与特点,比较了它们之间的性能,总结了其发展方向。
关键词:用户偏好模型;服务发现;分析;比较
1前言
随着Web技术的快速发展,越来越多的应用程序被封装成Web服务(Web Service)的形式发布到网络上。为实现对特定服务的查找,服务发现(Service Discovery)成为了服务计算研究中的热点问题。随着研究的深入,服务发现中越来越多地通过用户的偏好(User Preference)处理来提高服务发现的精度与效率,满足用户的个性化需求。
用户偏好模型是一种面向应用的特定数据结构形式。它可以根据不同的用户习惯和应用特点,实现不同形式和内容的建模,从而支持个性化的信息服务。在当今服务计算的研究领域,用户个性化模型广泛应用于Web服务发现、选择、组合和推荐等多个方面。
目前,已有研究中提出了多种用户偏好模型建模方法,这些方法虽然目标相同,但手段不一,效果各异。本文通过研究相关文献,对服务发现中出现的多种典型用户偏好建模方法分别进行分析,比较它们的优点与不足,以期为Web服务发现方法设计提供依据和参考。
2用户偏好模型的主要构建方法与形式
目前,在服务发现研究中构建用户偏好模型的方法形式多样,根据构建手段的不同,本文将其分为以下几类。
2.1基于 QoS属性的用户偏好模型
服务的QoS参数描述了Web服务的非功能属性(Non-Functional Property)。一般而言,服务发现的结果列表中会有多个功能属性(Functional Property)高度相似的候选服务,用户往往是根据某些非功能属性来做出最后的选择,如响应时间、可信度和吞吐量等QoS属性参数。因此,通过若干个QoS属性来反映用户的个性偏好就成了构建用户偏好模型的主要方法。
此类方法中,文献[1]直接就通过对QoS 属性排序来构建模型,用户选择这些属性的次序就反映出对这些参数的关注程度的不同,即排名越靠前,表明用户越重视该属性,对其的偏好也越明显。当然,该方法虽然原理简单,但结果的粒度也较粗,因为用户对不同 QoS 属性的偏好程度往往是模糊的,很难精确表示。因此,为解决此问题,文献[2]将偏好权重设置为三角模糊数形式,并采用模糊层次分析法来计算模糊权重值。具体而言,引入基于层次分析法和模糊集理论而提出的模糊多属性决策方法,将之用于解决层次分析法中无法克服的决策过程模糊化问题,文中通过应用模糊根法求得各个QoS 的模糊权重,从而突出用户的偏好。类似地,Ben Lakhal等人[3]提出了一个基于多标准(Multi-Criteria)的用户偏好模型构建方法,该方法允许客户根据他们的需求来分配各个QoS参数的权重值,通过这些权重来反映出用户的偏好。为解决此类方法中的用户偏好的模糊性问题,文献[4]中提出了一种综合考虑主客观权重的Web服务QoS度量算法。该算法将QoS权重分为主观和客观两个类别,分别从自适应用户偏好和保障服务潜能两个角度来给出权重计算方法,同时也根据用户体验中的敏感度不同,将用户偏好划分为主要偏好和次要偏好,基于以上量化结果来保障度量结果既能符合用户偏好又能够准确地反映服务的整体性能。
这类基于QoS属性的构造方法原理简单,容易实现,是服务发现中处理用户偏好最早和最普遍的方法。但需要注意的是,用户在不同应用环境和不同目的背景下对服务QoS参数的需求往往并不是一致的;而且若用户缺乏专业知识背景,不能正确理解QoS参数的意义和区别,那么其做出的排序或者指定的权重就失去意义;更重要的是,此类方法一般将QoS参数视为确定值,不能有效应对QoS不确定的场景。因此,基于QoS属性构建的用户偏好模型可信度往往并不高,适用性也不强。
2.2基于效用函数的用户偏好模型
效用函数(Utility Function,UF)最初属于经济学理论中的概念,它是用来表示消费者在消费中所获得的效用与所消费的商品组合之间数量关系的函数。它通常被用以衡量消费者从消费既定的商品组合中所获得满足的程度。从其概念定义可以看出,效用函数能很好地同Web服务的非功能属性结合起来,即用户的偏好就是预期的效用,若干个非功能属性就是商品组合。
文献[5]中提出了一个基于代理的架构来促进基于QoS的服务发现与选择。该架构中设计了一个用户自定义的效用函数,该函数基于负载、成本等参数和权重构成,即所有QoS属性基于它们的重要性来加权,用户对不同的参数加权后所构成的效用函数就反映出了其偏好。为使效用函数不会因具有大值的任何属性被偏置,所有的参数值通过平均值和标准偏差来归一化。文献[6]中把QoS参数分为协商参数和非协商参数两大类,在此基础上设计了目标效用函数,并基于此提出了一种基于并发协商的Web服务发现模型,该模型在服务发现过程中引入并发协商,先从功能相同的 Web服务中发现满足QoS需求的服务,最后使用构建好的目标效用函数来选择最优的服务。文献[7]构建了一个基于动态描述逻辑的主体模型,利用主体之间的协作实现语义Web 服务发现与组合,其中为解决用户QoS偏好的模糊性问题,文中基于四个基本的质量属性定义了一个表示用户对某一服务质量偏好的效用函数。
基于以上分析可以看到,基于UF的方法一般是基于Web服务的QoS属性来构建相关效用函数,从而反映出用户的个性偏好。这类方法相比较基于QoS属性的构造方法而言,提高了模型的针对性和可信度,一定程度上解决了QoS属性不确定情况下的服务发现与选择问题。但在此类方法中,用户偏好模型的性能很大程度上是由系统所采用的效用函数决定的,然而,效用函数的建立需要获取一定的信息,获取信息的过程需要较大资源和代价。因此怎样创建为用户去创建一个有效的效用函数是此类方法中核心问题,也是难点问题。
2.3基于CP-net的用户偏好模型
条件偏好网络(Conditional Preferences networks,CP-net)是一种以图形化的形式直观的表示用户偏好的方法。CP-net本质上可以看成是一个贝叶斯网络,它主要使用ceteris paribus(其它的条件相同)偏好陈述语句来描述用户的偏好[8],是目前广泛使用的方法之一。
文献[9]提出一种定性的服务选择方法来解决服务发现过程中涉及多个用户的Web服务选择问题。该方法将各用户对服务质量的需求都表示为偏好,并利用CP-net来捕获,表示和推理用户的偏好。针对用户的偏好序列中存在环路的问题,文中还提出了具体的算法来将有环CP-net转化为无环CP-net。为解决偏好不完整、偏好冲突的问题,文献[10]首先利用CP-net来对用户的偏好进行建模,然后在总结了 CP-net中出现的不确定性基础上,重新定义了偏好不完整和偏好冲突,并提出了 CP-net对应的结果集合上的最优关系与弱化的最优关系,其次通过分析CP-net与对应最优的关系,提出了CP-net交运算。最后,文中提出基于协同过滤的解决方法来解决CP-net中不确定问题,并且通过聚类对该方法进行了优化。为丰富CP-net的功能,Ronen Brafman等人[11]将CP-net扩展为TCP-net,用以来处理属性之间的相对重要性。TCP-net保持CP-net的基于原理,它仍然使用ceteris paribus偏好陈述语句,但它使用三种类型的边来注释图,分别用来捕获偏好依赖关系、相对重要性关系和条件重要性关系,能更准确地反映出用户的偏好。
和其它表示方法相比,CP-net方法能够以图形化结构来捕捉用户偏好,其表达方式更加简洁,直观和容易理解。但该类方法实用性并不高,主要原因就是CP-net受到偏好陈述语句的严格限制,较少的语句数目和较弱的语句表达能力都会严重影响CP-net的性能,而构建偏好陈述语句并不容易。
2.4基于本体的用户偏好模型
本体(Ontology)是一种描述术语及术语间关系的概念模型。它可以很好地支持知识推理,目前已被广泛地应用于语义Web、机器学习和人工智能等研究领域。基于本体来构建用户偏好模型的方法大体可以分为两类:基于领域本体的建模和基于偏好本体的建模。
基于领域本体来构建用户的偏好模型需要有足够的用户操作历史记录。其思路是通过对这些历史信息的挖掘,利用本体的概念层次关系和推理能力,将用户的偏好点映射到本体概念和属性上来。文献[12]就利用旅游本体构建了一个用户偏好模型,其结构形式如图1所示,图中每个方框代表一个本体概念,概念旁的数字代表着用户在此概念上的偏好程度,箭头表示概念之间的层次包含关系。可以看到,这种基于领域本体构建的用户偏好模型本质上就是该领域本体树的一棵子树。
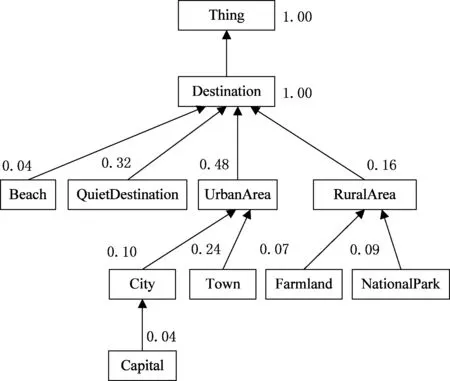
图1 基于领域本体的用户偏好模型示例
基于偏好本体的建模则是直接根据偏好的分类和特点构建一个通用的偏好本体,然后通过此本体概念及约束关系来生成一个具体的用户偏好模型。此类研究中最典型的就是Garcia等人提出的用户偏好顶层本体[13],其结构原理如图2所示。
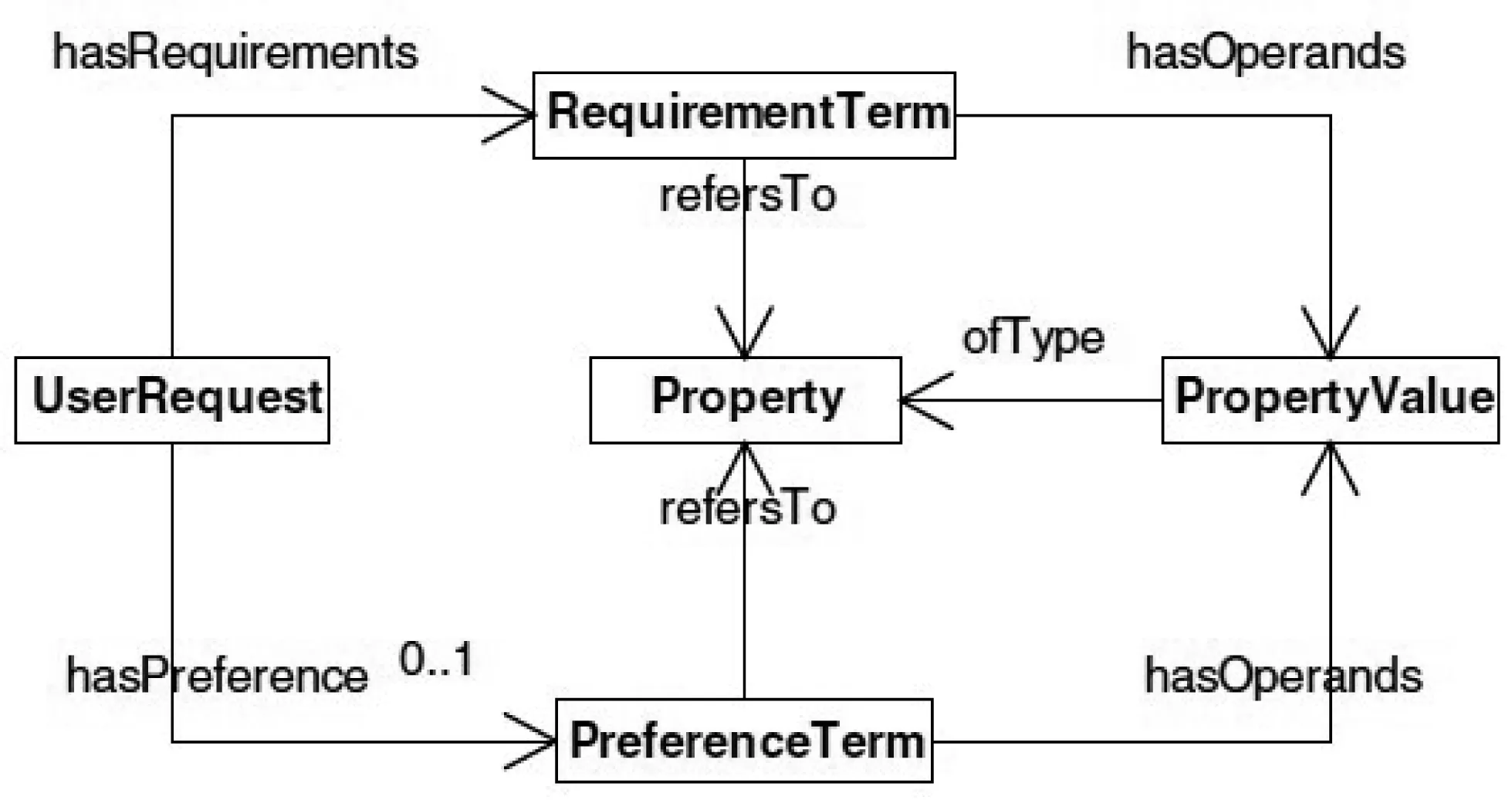
图2 用户偏好顶层本体
在此用户偏好顶层本体中,根节点概念被称之为User Request,它包含了用户的偏好和需求两个方面的内容。而具体偏好和需求可以分别分解为基本偏好项(Requirement Term)和基本需求项(Preference Term)。这些基本项又由若干个属性(Property)和属性值(Property Value)来描述,这些属性和属性值的确定取决与具体的领域本体。由此可见,该用户偏好顶层本体既能协调用户的需求与偏好之间的关系,又能同领域本体有效结合起来。
总的来说,由于采用了本体技术,这类方法构建的用户偏好模型普遍具有较强的推理能力和可信度,能有效挖掘用户的稳定偏好,特别适用于语义Web服务研究。但此类方法的效果严重依赖于本体的性能,而由于目前本体的构建尚无统一标准,不同本体之间性能差异较大。
3典型方法的比较
在以上分析的基础上,对这几种典型方法在方法原理、可信度、实现难点、稳定性和推理能力等几个性能上进行比较与总结,比较的结果如表1所示:
可以看到,在以上四种典型的方法中,基于本体的方法虽然实现难度受到本体建模的约束,但在方法原理、可信度、稳定性和推理能力上都有不错的表现。可以预料,随着本体研究的深入,制约其实现的瓶颈也会逐步消除。因此,可以说,基于本体技术来构建用户偏好模型是目前最可靠的方法之一,也是服务发现中的一个研究趋势。此类方法也是本项目后续研究中准备采用的手段之一。

表1 用户偏好顶层本体
4总结
本文首先根据构建手段的不同,将目前服务发现研究中典型的用户偏好模型方法分成了四类,然后举例分析了这几类方法的实现原理与技术特点,在此基础上比较了它们之间的性能,指出了基于本体的用户偏好建模是服务发现研究中的重点发展方向。
参考文献:
[1]李紧,苏伟,陈敏. 基于QoS和用户偏好的Web服务发现模型[J]. 现代计算机(专业版),2010,(4):49-52.
[2]冯建周,孔令富. 基于模糊QoS和偏好权重的Web服务组合方法研究[J]. 小型微型计算机系统, 2012,(7):1516-1521.
[3] R.B. Lakhal, W.Chainbi. A Multi-Criteria Approach for Web Service Discovery[J]. Procedia Computer Science, 2012, (10): 609-616.
[4]马友,王尚广,孙其博,杨放春. 一种综合考虑主客观权重的Web服务QoS度量算法[J]. 软件学报, 2014, (11):2473-2485.
[5] T Yu, Y Zhang, K Lin. Efficient algorithms for Web services selection with end-to-end QoS constraints[J]. ACM Transactions on the Web (TWEB), 2007, 1(1): 6.
[6]孙天昊,刘洪辉,马辉,朱庆生. 基于并发协商的Web服务发现模型[J]. 北京理工大学学报, 2015, (9): 980-984.
[7] 刘华鹏,刘胜全,刘艳,张华楠,李鹏. 基于主体和QoS的语义Web服务组合方法[J]. 计算机工程,2013, (10):227-231.
[8] C. Boutilier, R. Brafman I., C. Domshlak, et al. CP-nets: A tool for representing and reasoning with conditional ceteris paribus preference statements[J]. Journal of Artificial Intelligence Research, 2004,(21): 135-191.
[9]周宁,谢俊元. 基于定性多用户偏好的Web服务选择[J]. 电子学报,2011,(4):729-736.
[10]王红兵,孙文龙,王华兰. Web服务选择中偏好不确定问题的研究[J]. 计算机学报,2013,(2):275-285.
[11]R Brafman, C Domshlak, S Shimony. On graphical modeling of preference and importance[J]. Journal of Artificial Intelligence Research, 2006: 389-424.
[12] H.Tian, L. Duan, A new user personalization model for web service discovery based on pruning strategy, ICIC Express Letters. Part B, Applications: An International Journal of Research and Surveys, 2016,7(3): 613-619.
[13] J. Garcia, D. Ruiz, A. Ruiz-Cortes, A model of user preferences for semantic services discovery and ranking [C]. Heraklion, GREECE:Natl & Kapodistrian Univ Athens,2010:1-14.
Analysis and Comparison of User Preference Modeling methods in Service Discovery
DUAN Li-jun
(School of Computer Science, Hubei University of Education, Wuhan 430205, China)
Abstract:User preference model can reveal the individual needs of users, and also improve the accuracy and efficiency of service discovery. In this paper, according to different building methods, the author classified the current typical user preference modeling methods in the research of service discovery, analyzed their principles and characteristics in detail, then compared the performance between them, and finally summarized the development direction of user preference modeling methods.
Key words:user preference model; service discovery; analysis; comparison
收稿日期:2016-01-12
基金项目:湖北省教育厅科学技术研究计划项目(B2015017)
作者简介:段丽君(1981-),女,讲师,硕士,研究方向为服务计算及可视化技术。
中图分类号:TP302.7
文献标识码:A
文章编号:1674-344X(2016)02-0061-04
