基于数据挖掘技术的制造企业工艺知识发现和集约化管理
2016-06-27杨素明
王 茨 ,彭 静, 刘 雁,杨素明
(1.成都纺织高等专科学校 机械工程学院,成都 611731;2.四川普什宁江机床有限公司,四川 都江堰 611830)
基于数据挖掘技术的制造企业工艺知识发现和集约化管理
王茨1*,彭静1, 刘雁2,杨素明2
(1.成都纺织高等专科学校机械工程学院,成都611731;2.四川普什宁江机床有限公司,四川 都江堰611830)
摘要:制造型企业在日常设计、生产过程中,积累了大量的经验、案例和设计生产数据。为挖掘这些数据中的有用知识和规律,实现知识的充分挖掘和集约化管理,提升企业的核心竞争力,提出一种基于粗糙集的工艺知识发现技术, 并通过具体算例从25条生产数据中挖掘出3条知识,结果显示:该方法是有效的。
关键词:数据挖掘;工艺知识;集约化管理;粗糙集
随着人类步入信息化时代,经济领域的知识经济时代也悄然而至,知识管理作为新兴的战略和经营管理模式越发受到重视。知识管理在企业组织中成为管理与应用的智慧资本,能有效帮助企业做出正确的决策,适应复杂多变的市场。制造企业在设计、生产过程中,日积月累储存了大量的数据、经验[1-2]。但如何从海量的数据中提炼出有用的知识,为设计者和决策者在面对新的问题是提供帮助,传统的资料收集和整理已不能满足要求。数据挖掘技术的引入,可以帮助管理者从海量的数据和信息中提取出有价值的知识数据,帮助企业进行科学有效的知识管理[3-4]。本文基于粗糙集理论,排除数据集中不相关的条件属性,挖掘出条件属性与目标属性间的各种隐含关系。同时对冗余属性进行去除,精简数据库,探明对目标属性起主导作用的条件属性,精简出有效的工艺知识。然后对挖掘出的知识的一致性和有效性进行检验并对其进行评价。
1知识挖掘流程
知识挖掘流程主要有数字化分析数据的预处理、数据挖掘和知识评价,最终形成知识库(如图1所示)。
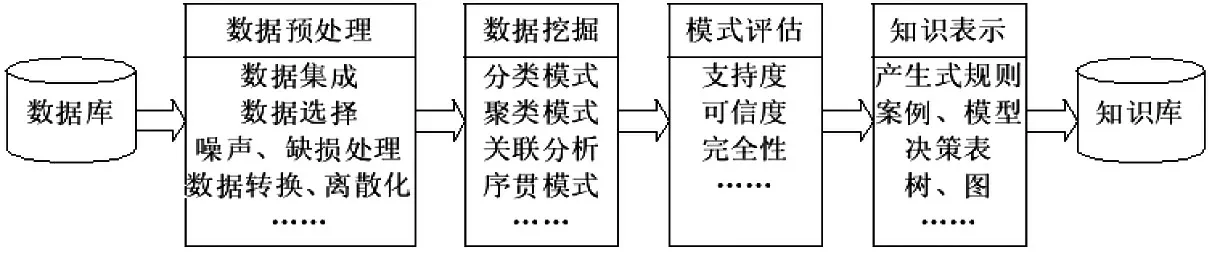
图1 知识发现的流程
采用粗糙集法排除数据库中一些不相关的属性,挖掘隐含于各属性间的隐含关系。然后对精简数据库发现对回弹量(目标属性)起主导作用的条件属性(工艺参数),并根据各参数对回弹量的影响关系归纳出设计规则和工艺规则。
2粗糙集基本理论
粗糙集将研究对象抽象为一个信息系统或知识表达系统,可用信息表表示,而信息表又可由四元组来表示[5]:S=P
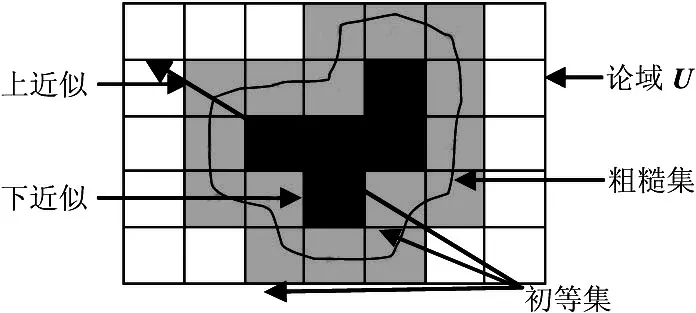
图 2 粗糙集概念示意图
决策表定义为[6]:S=(U,A) 为一知识表达系统,且C,D⊂A是2个属性子集,分别称为条件属性和决策属性。具有条件属性和决策属性的知识表达系统可表达为决策表,记作T=(U,A,C,D)或简称CD决策表。
关系Ind(C)和关系Ind(D)的等价类分别称为条件类和决策类。令X是U中根据条件属性C可定义的分类,Y是U中根据决策属性D定义的分类,对于每个xi,yi∈U,定义一个函数,对于xi∈X,yi∈Y,
dx:DesC(xi)→DesD(yi):xi∩yi≠0。
函数dx称为决策表T中的决策规则。当dx作为决策规则时,dx对于C的约束记作dx|C,对于D的约束记作dx|D。dx|C和dx|D分别称为dx的条件和决策。
对于每个x≠y,dx|C=dx|D则称决策规则是协调的,否则称为不协调的;只有当所有的决策规则都是协调的时候,决策表才是协调的。
1)当且仅当C→D,决策表T=(U,A,C,D)是协调的。
2)每个决策表T=(U,A,C,D)都可以唯一地分解成2个决策表,一个是协调的T1=(U1,A,C,D)和另一个完全不协调的T2=(U2,A,C,D),这样使得表T1中C→1D和表T2中C→2D。这里U1=PosC(D),U2=∪BnC(D),X∈U|Ind(C)。
3算例
3.1源数据
本文以一汽车钣金生产部门生产某一钣金件的正交实验工艺数据为例,条件属性a为冲压速度/(mm·s-1);b为凸凹模的间隙/mm;c为摩擦系数;f为总回弹量/mm。借助粗糙集技术对其进行数据挖掘及知识发现,丰富该部门的知识库管理系统。原始数据如表1所示。

表1 源数据
3.2数据离散化
通过聚类分析及经验判断,制定了表2所示的离散化标准,并按此标准对表1各数值进行离散,得到表3所示的用于RST属性相关分析的决策表。

表2 离散化标准
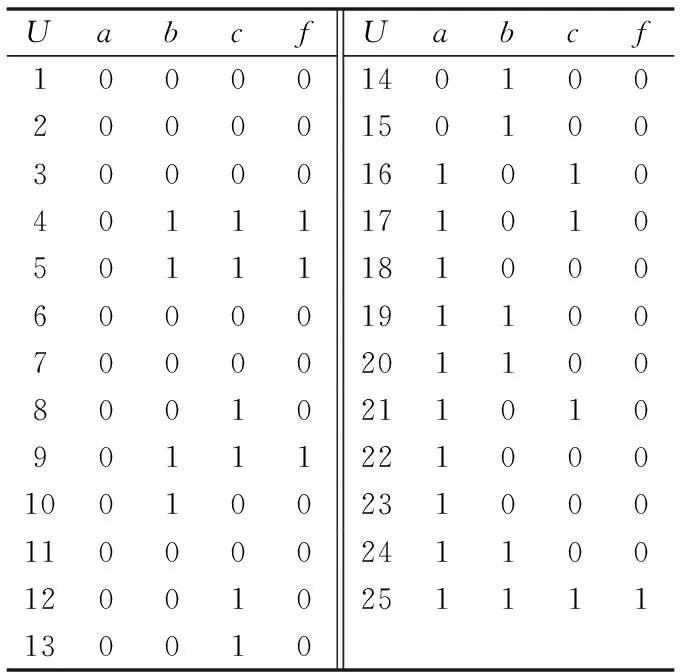
表3 RST方法中采用的决策表
3.3基于决策表的约简
若依赖度rC(D)<1,说明决策表的结果不协调,可以将表分解成2个子表,其中一个完全不协调,依赖度为0,另外一个表完全协调,依赖度为1。
U|C={{x1,x2,x3,x6,x7,x11},{x4,x5,x9},{x8,x12,x13},{x10,x14,x15},{x16,x17,x21},{x18,x22,x23},{x19,x20,x24},{x25}}
U|D={{x1,x2,x3,x6,x7,x8,x10,x11,x12,x13,x14,x15,x16,x17,x18,x19,x20,x21,x22,x23,x24},{x4,x5,x9,x25}}
Posc(D)=C_(x1)UC_(x2)UC_(x3)U…C_(x25)
= {{x1},{x2},{x3},…,{x25}}
rC(D)=25/25=1
因此,表3是协调的。
下面对表3进行约简,根据约简法则:(C,D)为一决策表,a∈C,当且仅当(C-{a},D)为协调时,我们称(C,D)中的属性是可省略的,否则是不可省略的。
根据此法则,对属性b,省略属性b后出现相同的条件产生不同的结果,即:
a0c1→f0a1c1→f0
a0c1→f1a1c1→f1
故条件属性b是不可以省略的,同理可知,属性c也是不能省略的,而属性a则是可以省略的。精简后的决策表见表4。
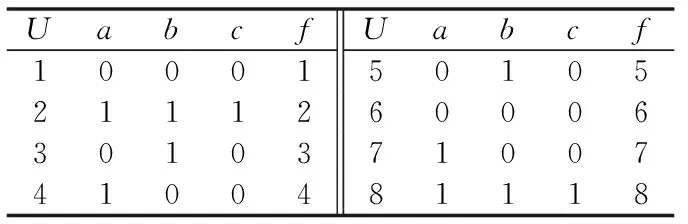
表4 精简后的决策表
从表4中可知:规则1、6相同,规则2、8相同,规则3、5相同,规则4、7相同进一步进行简化,得到如表5所示的最终结果。

表5 约简后的最终决策表
得到如下规则:
R1:IF(b=0)∧(c=0)THEN(f=0)
R2:IF(b=1)∧(c=1)THEN(f=1)
R3: IF(b=0)∧(c=1)THEN(f=0)
R4: IF(b=1)∧(c=0)THEN(f=0)
通过分析这4条规则,可进一步得到:只有当b和c都同时为1时,目标属性f才为1,否则为0。因此通过上述粗糙集分析可以得出以下知识:1)条件属性b和条件属性c是影响目标f属性最重要的因素; 2)当条件属性b数值不宜过大; 3)条件属性a对目标属性f没有明显效果。
参考文献:
[1] LIN C C,CHIU A A,HUANG S Y,et al.Detecting the financial statement fraud: The analysis of the differences between data mining techniques and experts’ judgments[J].Knowledge-Based Systems,2015,4(9):980-989.
[2] KHATIB E J,BARCO R,GMEZ-ANDRADES A,et al.Data mining for fuzzy diagnosis systems in LTE networks[J].Expert Systems with Applications,2015,159(21):7549-7559.
[3] 卢建昌,樊围国.大数据时代下数据挖掘技术在电力企业中的应用[J].广东电力,2014(9):88-94.
[4] 郝媛,高学东,谷淑娟.面向科技管理的流数据聚类算法研究[J].科学管理研究,2012,30(2):24-26.
[5] PAWLAK Z.Rough sets[J].Communications of the Acm,1982,11(5):341-356.
[6] 杨善林.智能决策方法与智能决策支持系统[M].北京:科学出版社,2005:89-135.
Knowledge Discovery and Intensive Management of Manufacturing enterprise Based on Data Mining Technology
WANGCi1*,PENGJing1,LIUYan2,YANGSuming2
(1.School of Mechanical Engineering,Chengdu Textile College, Chengdu 610065, China; 2.Push Ning Jiang Machine Tool Co.,Ltd., Dujiangyan 611830, China)
Abstract:A great deal of useful knowledge and law were hidden in lots of experience, case data in the process of design and production everyday. These knowledge would be wasted if these data were just stored in computers or work packages. In this paper, one knowledge discovery based rough set theory on was proposed. Combined with a case, three pieces of knowledge were dug from 25 production data. the result showed that the way was valid. The data digging technology could help enterprises to realize the knowledge fully dug up and intensive management to avoid that the enterprise had a great volume of data but no useful knowledge, and improved the core competitiveness of the company.
Key words:data mining; process knowledge; intensive management; rough set theory
DOI:10.13542/j.cnki.51-1747/tn.2016.02.013
收稿日期:2016-04-15
作者简介:王茨(1983— ),女(汉族),四川资中人,助教,硕士,研究方向:企业生产管理,通信作者邮箱:ciwang318@126.com。
中图分类号:TP301
文献标志码:A
文章编号:2095-5383(2016)02-0046-03
彭静(1984— ),女(汉族),湖南浏阳人,讲师,硕士,研究方向:机械制造。
