面向中文新闻话题检测的多向量文本聚类方法
2016-06-27李欣雨
李欣雨 , 袁 方 , 刘 宇 , 李 琮
(1.河北大学 计算机科学与技术学院 河北 保定071000;学 数学与信息科学学院 河北 保定071000)
面向中文新闻话题检测的多向量文本聚类方法
李欣雨1, 袁 方2, 刘 宇2, 李 琮1
(1.河北大学 计算机科学与技术学院 河北 保定071000;学 数学与信息科学学院 河北 保定071000)
基于多向量模型,给出一种将话题主题信息与话题文本信息相结合的多向量话题表示方式,使用较低的维度来准确表示一个话题.针对传统TFIDF方法在文本分类问题中对特征项在各个类中分布情况考虑不充分的问题,给出了一种TFIDF改进方法.在TDT4的中文语料上,与传统向量空间模型进行了对比实验.实验结果表明,给出的话题表示方法和TFIDF改进算法能够在较低的维度上,使聚类的准确率得到较大提升.
话题检测; 多向量模型; TDT4; 改进TFIDF算法
0 引言
随着互联网的快速发展,网络已逐渐成为人们获取信息的一个主要媒体.网络新闻作为互联网媒体中最重要的信息类型之一,是人们获取新闻消息的一个重要途径.但由于网络上的新闻繁杂冗余,依靠人工来查找新闻话题的工作量巨大,人们希望能够通过计算机自动获取新闻话题,话题检测技术即是自动获取新闻话题的技术.
话题检测的主要任务是在缺乏话题先验知识的前提下,检测出未知的话题,这是一种无监督学习过程[1-2].聚类算法是实现话题检测的一个关键点.一般可以分为基于层次的聚类算法、基于密度的聚类算法、基于平面划分的聚类算法等[3-4].基于层次的聚类算法通常可以达到较高的精度,因此本文采用凝聚层次聚类算法进行聚类.
话题检测的另一个关键点在于话题的向量化表示,表示模型及其使用方法的好坏通常会对整个系统的性能产生较大影响[5].常用的表示模型可以分为概率模型和向量空间模型(vector space model,VSM).一种典型的概率模型如LDA(latent Dirichlet allocation)模型[6],是由文本空间到语义空间的映射.通过LDA模型的迭代过程,可以将文本表示成主题向量,但通常LDA模型中的主题,与最终需要的话题是不同的.这一不同,主要体现在语义的粒度上,LDA得到的主题,通常具有较大的语义粒度,因此并不能精确地表示一篇文档[7-8].使用由文本直接得到的VSM表示文档时,向量维度通常会非常高[9],使计算耗时增加.为了减少时间消耗,通常会选用信息量丰富的词,如:地点词、人物词、事件的代表词等.然而如果仅使用这些重要信息来表示文档,其携带的文本语义信息过少,对文本的表示精度仍然不能满足要求[10-11].
1 多向量模型
多向量模型[5]是由多个子向量组合而成的向量模型,用MV表示n维多向量,SVi表示其子向量,则有:MV={SV1,SV2,…,SVn}.在计算两个多向量的相似度时,通常会分别计算每个子向量的相似度,然后采用某种策略对各个子向量的相似度进行综合,从而得到多向量间的相似度.例如,对于两个n维多向量MV1和MV2,即有
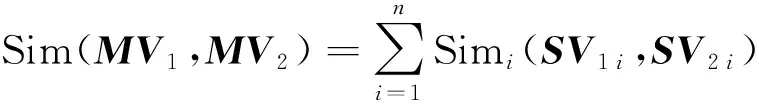
(1)
其中:Sim(·,·)表示计算相似度函数.利用多向量模型,将主题模型和向量空间模型结合.这样做的目的是使这两种模型能够进行优势互补:主题模型为向量空间模型补充其语义上的不足,向量空间模型可以提高主题模型的精度.为了进一步提高多向量的表示精度,将文中的地点和人物提取出来,作为多向量中的一个子向量.最后,文本会被表示为3个子向量:主题子向量、地点人物子向量和关键词子向量.在判断给定两篇文档的话题相似性时,直观上可以理解为对于两篇文档,如果它们的语义相近,并且提到相似的地点人物,又具有相似的关键字,那么两篇文档极有可能是在讨论同一话题.通过与基准方法的对比试验表明,本文给出的这种多向量模型能够提升话题检测的性能.
2 基于多向量的话题检测方法
在基准方法和多向量方法中均使用基于簇中心的凝聚层次聚类方法,初始时每篇文章单独作为一个簇,选择全局最近的两个簇进行合并,更新合并后的簇中心,然后继续选取全局最近的两个簇进行合并,直到所有文章合并为一个簇时,聚类停止.
2.1 基准方法
使用中科院分词工具ICTCLAS对文档进行分词,基于停用词表(509个停用词)删除文档中的停用词,只保留文档中的名词、动词、形容词和副词[12],计算每篇文档中词的TFIDF分值,并保留分值较高的词.以TFIDF分值作为VSM向量的权值,构造出各篇文档的VSM向量.使用凝聚层次聚类方法进行聚类.其中,凝聚层次聚类方法使用簇中心表示法,簇中心由簇中所有文档的VSM向量进行向量加和运算得到.使用两个簇中心VSM向量的cosin值作为簇中心的相似度.
2.2 本文使用的方法
本文给出的方法是基于多向量的聚类算法,文档的表示向量是由3个子向量组成的多向量.3个子向量分别是:主题子向量、地点人物子向量和关键词子向量,每个子向量都设有维度上限值,分别为Lt、Lp和Lk.在凝聚层次聚类方法中使用簇中心表示方法,每个簇的簇中心向量同样由上述多向量表示.两个簇的相似度通过计算这两个簇的簇中心相似度得到,簇中心的相似度为其3个对应子向量的cosin相似度值之和.用Ci表示簇i,Ti,Pi,Ki分别代表Ci中的主题子向量、地点人物子向量和关键词子向量,则有:
Sim(C1,C2)=wt1×cosin(T1,T2)+wt2×cosin(P1,P2)+wt3×cosin(K1,K2),
(2)
2.2.1 主题子向量的构造与更新方法 本文的主题子向量使用的是由LDA模型得到的主题向量.LDA模型是一种3层贝叶斯生成的概率模型[13],模型表示如图1所示[6].M代表所有文档个数;H代表所有隐含主题个数;N代表一篇文档中词的个数;α和β是超参数;θ表示文档的主题分布;φ表示主题的词分布;z代表一个主题h(h∈{1,2,…,H});w代表文档的一个词.该模型假设每篇文档均包含全部H个隐含主题,而每个主题均包含所有文档的不重复词,并通过隐含主题来将文档和词汇进行关联.这一模型生成文档的过程可用图2表示.
根据图2,在生成第m篇文档时,先根据超参数α生成第m篇文档的θm,然后根据θm生成第m篇文档的第n个词的主题zm,n,不妨假设zm,n=h,接着根据超参数β生成的φh来生成第m篇文档的第n个词wm,n.LDA模型中应用了词袋模型[14],这表明LDA模型假设文档中词的顺序是可交换的,同时LDA模型中假设各篇文档独立,因此各篇文档之间的顺序也是可交换的.LDA模型在初始时对所有文档中的词进行随机主题赋值,然后通过不断随机抽样迭代,最终可以得到每篇文档的主题分布的估计向量θ,本文使用这一向量作为多向量的主题子向量.
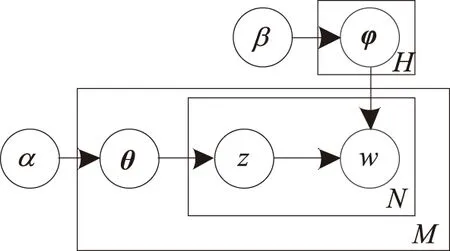
图1 LDA模型Fig.1 LDA model

图2 LDA模型生成文档的过程
Fig.2 Process of generating documents using LDA model
主题向量θ是表示文档的主题分布情况的向量,其含意可解释为,当人们在写一篇文档时,会通过在文档中安排各个主题写多少来表达自己的语义,例如:现有3篇文档和3个主题,这3篇文档分别对应3个主题分布θ1=(0.8,0.1,0.1),θ2=(0.7,0.2,0.1),θ3=(0.1,0.2,0.7),则可以看到,θ1所属文档主要通过主题1表达语义,θ2中主要通过主题2表达语义,θ3主要通过主题3表达语义,则通常可以认为θ1与θ2语义相近.将θ1和θ2对应维度值进行加和求平均,得到θ′=(0.75,0.15,0.1).用θ′来近似表示θ1和θ2共同表达的语义,可以理解为:θ′代表为了表达某一特定语义而对各个主题的平均使用率.因此,簇中心的主题子向量采用如下方式进行更新:簇中各篇文档的主题子向量的对应维度值加和求平均,得到的平均θ′向量作为簇中心的主题子向量.
2.2.2 地点人物子向量的构造与更新方法 地点人物子向量使用由中科院分词工具ICTCLAS分词结果中的人名词和地名词组成.地点人物子向量只保留具有较高文档内相对词频的地点词和人名词.考虑到部分文档中可能包含的地点词与人名词非常少,造成在计算多向量的相似度时,地点人物子向量无法提供与主题子向量和关键词子向量对等的信息量.因此,进行相似度计算时,在使用公式(2)中设定的子向量权值wt2之前,首先采用公式(3)对地点人物子向量相似度进行动态加权:
(3)
其中:weight(i,j)表示簇i与簇j的地点人物子向量的动态权重;Pi表示第i个簇的地点人物子向量; dim(Pi,Pj)表示簇i和簇j的地点人物子向量组成的VSM向量的维度;Limit表示地点人物子向量的维度上限.
当两个簇进行合并时,相同词的相对词频相加,不同词则直接并入向量,然后按相对词频对所有词进行排序,保留其中具有较高相对词频的词.用Ci表示簇i,Pi表示Ci的地点人物子向量,合并C1、C2,得到新簇C′及其地点人物子向量P′,P′=(P1∪P2).对C′中的地点词和人名词进行排序,保留相对词频较高的地点词和人名词.当P′中的词数量超过Limit时,以维度上限值的一半作为地点词和人名词的维度警戒线Lm,若地点词和人名词的个数均超过Lm,则各自保留相对词频较高的Lm个词;若它们其中一个的数量超过了Lm,则通过舍去数量较多一方的具有较低相对词频的词来保证P′的词数量在Limit以内.
2.2.3 关键词子向量的构造与更新方法 文档的关键词子向量是对文档分词、去停用词进行词性保留,再去掉文中的人名词和地名词后,对各篇文档剩余词语进行TFIDF计算,最后各篇文档选出其TFIDF分值较高的一部分词作为其关键词子向量.
传统TFIDF算法在计算时,没有充分考虑特征项在各个类中的分布情况.当某一特征项在某个类内大量出现,而在其他类中出现较少时,这样的特征项是具有较强分类能力的,但传统的TFIDF算法无法赋予这样的特征项较高权值.因此本文在传统TFIDF权值的基础上,通过统计类内某一特征的分布情况,将其与其他类中该特征的平均分布情况进行比较后,对原有TFIDF计算分值进行修正.若该特征在当前类内分布广泛,而在其他类中分布较少,则加大其TFIDF分值;若该特征在当前类内分布较少,在其他类中分布较多,则减少其TFIDF分值;若该特征在当前类内的分布与其他类中分布接近,则其TFIDF分值保持不变.根据上述思想,给出计算方法:
(4)
其中:NewTFIDF(t)表示文档中的特征项t新的TFIDF加权值;TF为特征项t的相对词频;IDF为特征项t的逆文档频率;本文定义聚类中文档数量大于1的簇为一个类(也即一个话题),n代表当前系统中类的个数;Ri(t)表示文档所在类i中,特征项t出现的文档数在类i所含文档中占有的比例,即

(5)

在对两个簇进行合并时,首先使用上述公式对两个簇中所有文档的关键词子向量进行更新,即重新计算两个簇内所有文档词的权重,然后每篇文档保留权值最高的一部分词作为新的关键词;再用更新后的簇中所有文档的关键词组成VSM向量,得到的加权VSM向量作为各篇文档的新关键词子向量,至此簇中文档的关键词子向量更新完成;再将簇中所有文档的关键词子向量的对应维度值进行加和求平均,并按求得的平均值进行排序,保留值较高的一部分词.由这些关键词组成的向量作为合并后新簇中心的关键词子向量.
3 评价方法与数据集
使用查全率Rec、查准率Pre以及F值来对实验结果进行评价[15].其中,查全率的定义为:被正确分类的文档数和被测试文档中各类别文档总数的比值;查准率的定义为:被正确分类的文档数与识别出的类别文档总数的比值.计算公式为:

其中:Ce表示在聚类前属于TDT标记的类i,且聚类后仍属于类i的文档个数;Tr1表示聚类前,TDT标记的各个类所包含的总文档数;Tr2表示聚类后获得的所有类包含的全部文档数.本文规定最小类应包含至少2篇文档.
采用TDT4的中文语料作为实验数据集.在TDT4语料中,共有两套不重复的话题标注:TDT4-2002话题标注和TDT4-2003话题标注.TDT4-2002是语言数据联盟(linguistic data consortium,LDC)在2002年的话题检测与追踪(topic detection and tracking,TDT)评测中标注并使用的话题,TDT4-2003是LDC在2003年的TDT评测中标注并使用的话题.这两套话题标注之间,不存在话题的重复,也不存在文档的重复,即TDT4-2003的话题不包含TDT4-2002的任何话题,且TDT4-2003标记的文档也不包含TDT4-2002标记的任何文档.在这两套话题标注中,具有明确话题标注的中文语料在TDT4-2002中有723篇,共涉及40个话题;在TDT4-2003中有580篇,共涉及33个话题.TDT4的语料标注存在少数一篇文档对应多个话题的情况;一篇文档只对应一个话题的语料占多数.其中,一篇文档仅对应一个话题的文档,在TDT4-2002中有657篇,涉及37个话题,TDT4-2003中有564篇,涉及31个话题.用Tpc1,Doc1和Tpc2,Doc2分别表示TDT4-2002和TDT4-2003的话题、文档集合,则有Tpc1∩Tpc2=Φ,Doc1∩Doc2=Φ,因此可以将TDT4-2002与TDT4-2003的话题和文档合并,使用Tpc′=Tpc1∪Tpc2,Doc′=Doc1∪Doc2作为实验数据集,共1 221篇文档总计68个话题.其中,若一个话题只有一篇文档,则认为该话题的文档是孤立点,不再当作一个话题,这些文档仍然保留在数据集中,但其话题不再计入话题总数,最终得到61个话题,共计1 221篇文档.
4 实验与分析
4.1 基准方法聚类实验
在由TDT4-2002与TDT4-2003共同组成的语料集上,使用基准方法,按如下过程进行实验:聚类开始,直到只剩下3个簇时,聚类停止,然后对聚类过程中的每一次聚类结果计算出F值,将其中的最大F值及其对应的召回率和准确率作为实验结果.再用NewTFIDF方法替换基准方法中的传统TFIDF方法,按前述过程再次进行实验.使用两种不同权值计算方法得到的实验结果如表1所示.

表1 传统TFIDF与NewTFIDF的实验结果
通过表1的实验结果可以看到,本文给出的NewTFIDF加权算法与传统TFIDF算法相比,聚类结果的召回率提高了2.51个百分点,准确率提高了0.36个百分点,最后F值提高了1.48个百分点,表明本文给出的在传统TFIDF算法基础上引入特征的类内分布情况统计量的方法能够在一定程度上解决传统算法中存在的问题.
4.2 基于多向量模型方法实验
在本文使用的多向量中,每个簇的3个子向量维度上限均取20维.3个子向量的权值设置为:wt1=wt2=wt3=1/3. 在获取主题子向量时,LDA主题模型的主题数H设为20,α和β取经验值分别为0.5和0.01,迭代次数取200次.由于从LDA主题模型获取的主题子向量具有随机性,因此本文进行了10次聚类实验,每次实验重新构造主题子向量,取每次实验能够获得的最高F值对应的召回率和准确率作为当次实验的结果,然后对10次实验获得的10组召回率和准确率进行加和求平均,再通过计算出的平均召回率和平均准确率计算出平均F值,这3个分值一同作为最终聚类评价分数.
将基准方法的 VSM向量分别与传统TFIDF和NewTFIDF加权方法进行组合,再用本文给出的多向量分别与传统TFIDF和NewTFIDF加权方法进行组合.这4组方法分两次在TDT4-2002与TDT4-2003语料上各进行一次实验.实验结果如表2所示.

表2 4组方法在两个语料库上的聚类结果
通过4组实验数据的对比,可以得到,与传统的VSM和TFIDF组合方法相比,多向量模型的使用以及NewTFIDF算法使得在TDT4-2002语料上,聚类结果的召回率提高了4.08个百分点,准确率提高了5.54个百分点,F值提高了4.77个百分点;在TDT4-2003语料上,聚类结果的召回率提高了3.31个百分点,准确率提高了5.2个百分点,F值提高了4.19个百分点.实验表明,本文给出的多向量模型和NewTFIDF加权方法使话题检测的性能得到提升.
5 总结
本文通过对话题表示模型的分析,给出了一种基于多向量模型的话题表示方法,将话题表示为主题子向量、地点人物子向量和关键词子向量.同时针对传统TFIDF加权算法存在的不足,给出了一种改进的TFIDF算法,将特征项在各个类中的文档分布信息引入到TFIDF权值计算当中.通过实验表明,本文给出的方法能有效提高话题检测的召回率和准确率.
[1] 洪宇,张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,21(6):71-87.
[2] 李胜东,吕学强,施水才,等.基于话题检测的自适应增量K-means算法[J].中文信息学报,2014,28(6):190-193.
[3] 金建国.聚类方法综述[J].计算机科学,2014,41(S2):288-293.
[4] 王祥斌,杨柳,邓伦治.一种利用高斯函数的聚类算法[J].河南科技大学学报(自然科学版),2014,35(5):33-36.
[5] 张晓艳,王挺,陈火旺.基于多向量和实体模糊匹配的话题关联识别[J].中文信息学报,2008,22(1):9-14.
[6] JORDAN M I,BLEI D M,NG A Y.Latent dirichlet allocation[J].Journal of machine learning research,2003,3:993-1022.
[7] 张晓艳,王挺,梁晓波.LDA模型在话题追踪中的应用[J].计算机科学,2011,S1:136-139.
[8] 李湘东,巴志超,黄莉.基于LDA模型和HowNet的多粒度子话题划分方法[J].计算机应用研究,2015,32(6):1625-1629.
[9] 谢林燕,张素香,戚银城.基于层叠模型的话题检测方法研究[J].郑州大学学报(理学版),2012,44(2):43-47.
[10]王振宇,吴泽衡,唐远华.基于多向量和二次聚类的话题检测[J].计算机工程与设计,2012,33(8):3214-3218.
[11]常宝娴,陈玮玮,李素娟.一种基于分布式rough本体的语义相似度计算方法[J].扬州大学学报(自然科学版),2014,17(1):60-62.
[12]冀俊忠,贝飞,吴晨生,等.词性对新闻和微博网络话题检测的影响[J].北京工业大学学报,2015,41(4):526-533.
[13]王李冬,魏宝刚,袁杰.基于概率主题模型的文档聚类[J].电子学报,2012,40(11):2346-2350.
[14]蒋玲芳,张伟,司梦.基于词袋模型的电子报图像分类方法研究[J].信阳师范学院学报(自然科学版),2013,26(1):124-127.
[15]张小明,李舟军,巢文涵.基于增量型聚类的自动话题检测研究[J].软件学报,2012,23(6):1578-1587.
(责任编辑:王浩毅)
A Multi-vector Text Clustering Method for Chinese News Topic Detection
LI Xinyu1, YUAN Fang2, LIU Yu2,LI Cong1
(1.CollegeofComputerScienceandTechnology,HebeiUniversity,Baoding071000,China;2.CollegeofMathematicsandInformation,HebeiUniversity,Baoding071000,China)
A multi-vector topic representation method combined with topic information and topic text information was proposed, to accurately represent a topic in a lower dimension. The traditional TFIDF method, during text classification, couldn’t fully cover the distribution of the feature items in each class, so an improved TFIDF method was proposed. Compared with traditional vector space model, the topic representation method and the TFIDF algorithm could effectively improve the accuracy of clustering.
topic detection; multi-vector model; TDT4; improved TFIDF
2015-11-19
河北省软科学研究计划项目(13455317D,12457206D-11).
李欣雨(1989—),男,河北秦皇岛人,硕士研究生,主要从事数据挖掘研究,E-mail:lixinyudm@163.com;通讯作者:袁方(1965—),男,河北安新人,教授,博士,主要从事数据挖掘、社会计算研究,E-mail:yuanfang@hbu.edu.cn.
李欣雨,袁方 ,刘宇,等. 面向中文新闻话题检测的多向量文本聚类方法[J]. 郑州大学学报(理学版),2016,48(2):47-52.
TP391.1
A
1671-6841(2016)02-0047-06
10.13705/j.issn.1671-6841.2015277
