一种泛化约束的 (K, L)-匿名算法
2016-06-17朱卫红潘巨龙
朱卫红,潘巨龙,时 磊
(中国计量学院 信息工程学院,浙江 杭州 310018)
一种泛化约束的 (K, L)-匿名算法
朱卫红,潘巨龙,时磊
(中国计量学院 信息工程学院,浙江 杭州 310018)
【摘要】针对匿名算法在泛化过程中存在过度泛化从而导致数据可用性降低的问题,提出了一种基于泛化约束的(K,L)匿名算法.为了保证数据的可用性,该算法首先通过MAGVal(maximum alowed generalization value)形成MAM(maximum allowed microdata)来控制准标识属性值的边界范围,然后再进行(K,L)匿名的筛选,从而达到最终匿名保护的目的.实验表明,该算法在保证信息可用性的同时,减小了泛化的时间开销.
【关键词】隐私信息;泛化约束;(K,L)匿名算法
随着互联网时代和信息化时代的来临,我们感知信息和获取信息的能力随之提升,当我们尽情地享受新技术给我们带来的诸多便利的时候,个人隐私信息泄露的风险也在不断增高.大量的个人资料不断地在不同的应用领域被收集:税收、医疗保健、信用卡交易,社会网络等[1].除了它的主要目的是收集和存储以外,数据在没用前会被资源的所有者或第三方随后进行分析.但在各种现有法规规定国家和不同的应用领域,个人的隐私电子数据集必须在他们收集、存储、分配和使用中受到保护[2].因此,对个人隐私保护的研究有着非常重要的现实意义.
在发布数据集(一个数据集元组对应于一个个体)之前,为了执行一个匿名模型,一种常用的解决方案是修改初始数据,即通过对原始数据的准标识符属性中的值属性和分类属性进行泛化达到隐匿的目的,隐私保护算法最终的目的有两个:一是要保护敏感信息不被泄露;二是要让原始信息保持可用性.所以,信息的隐匿过程就是创建一个匿名数据集,同时保留尽可能多的原始数据集的信息内容,而现有的许多研究工作都是在不限制泛化条件的情况下实现匿名模型,在这种假设条件下,即使匿名数据有好的质量,它仍然是没有用的,因为必要的关键数据的属性信息已经丢失.针对这个问题,本文提出了一种基于泛化约束的(K,L)匿名算法,该算法在信息泛化的过程中,通过对准标识符属性设置约束条件(或者称为边界)来达到最终匿名保护的目的.实验表明,该算法有很好的计算效率和匿名质量,可以最大限度地保证数据的可用性.
1匿名和约束
原始数据集IM(initial microdata)通常有三种类型属性描述组成.
1) 标识符属性I(identifier attributes):可以直接表明个体身份的属性,如身份证号等,在匿名过程中通常被移除,因为它们表达的信息可以直接导向一个身份实体,我们用I1,I2,...,Im表示.
2)准标识符属性QI(quasi-identifier)[3]:通过链接可以知道个人身份的属性,如年龄、邮编、工作类型、教育程度等,为了保护身份和敏感属性不被泄露,通常需要改变准标识符属性的值来达到匿名保护的目的,我们用Q1,Q2,...,Qt表示.
3)敏感属性S(sensitive attributes):通常是指不希望被外界知道的的属性,也是我们需要进行匿名保护的属性,如婚姻状况、工资水平、疾病信息等,在数据表中是不能被修改的.
1. 1相关定义
1) 等价类(QI-Cluster)[4]:是指具有相同准标识符属性值的元组簇,通过构造等价类可以使个体身份模糊化,这是匿名算法的常用的手段.
2)K-匿名(K-anonymity):在匿名表MM(masked microdata)中,K-匿名要求等价类中的元组至少有k个.
3) (K,L)匿名[5]((K,L)-anonymity):在匿名表中,(K,L)匿名要求在满足K-匿名的同时,还要求等价类中敏感属性的种类至少包含l个不同的敏感属性.在这些定义的基础上,满足(K,L)匿名的前提下,能正确识别个体身份的概率是1/k,敏感信息被泄露的概率是1/l,通过改变k值和l值的大小可以增加保护程度.对原始数据集的匿名化过程,就是要将数据集转换成符合(K,L)匿名模型,主要是通过泛化准标识符属性和抑制元组[6]的手段来完成,这是匿名保护领域最常用的两种手段.
1. 2泛化约束
匿名化算法对于原始的数据集IM通常试图以最小的变化(较小的信息损失)达到需要保护的水平[7],然而,对应于这种变化,泛化之后的属性值很有可能超过效用阈值,超过这种阈值的元组就变成了无用的信息,这和我们进行匿名保护的初衷是相违背的,在本文中我们通过设置泛化约束值(或者边界值)来防止这种情况发生.我们考虑这样一种情形,现在研究者想验证大部分病人是否在当地(州或者郡级别)的医疗服务点进行医疗保健,此时如果可用的匿名表泛化到了国家的级别,这个研究就无法进行下去了.在这种情况下,位置属性值不应该超过州的级别,如果把泛化的边界值设置到州级别,问题就得到解决.我们把这个泛化边界称为最大被允许的泛化值MAGVal (maximum alowed generalization value),在泛化边界以内的泛化信息都是可用的信息.
1.2.1MAGVal表示
Q表示一个准标识符属性,HQ表示预先定义的泛化层[8],对于每一个叶子值μ,MAGVal(μ)位于叶子值到到根节点值的路径上,在发布的数据中,μ被允许的最大泛化值为MAGVal(μ).图1是对位置属性进行泛化的示例,加*的节点值代表最大允许的泛化值,叶子值“Albany”和“Des Moines”的最大泛化值是分别是“New York”,“Midwest”.这就意味着准标识符属性位置值“Albany”可以泛化到它自身也可以泛化到“New York”,但是不能泛化到“East Coast”,也不能泛化到“United Stated”,而“Des Moines”可以被泛化到它自身,可以泛化到“Iowa”,也可以泛化到“Midwest”,但是它不能被泛化到“United Stated”,当叶子节点的泛化路径上有多个允许泛化的值取第一个最大值.如果只有叶子节点没有根节点,那么最大的泛化值就是它自身.
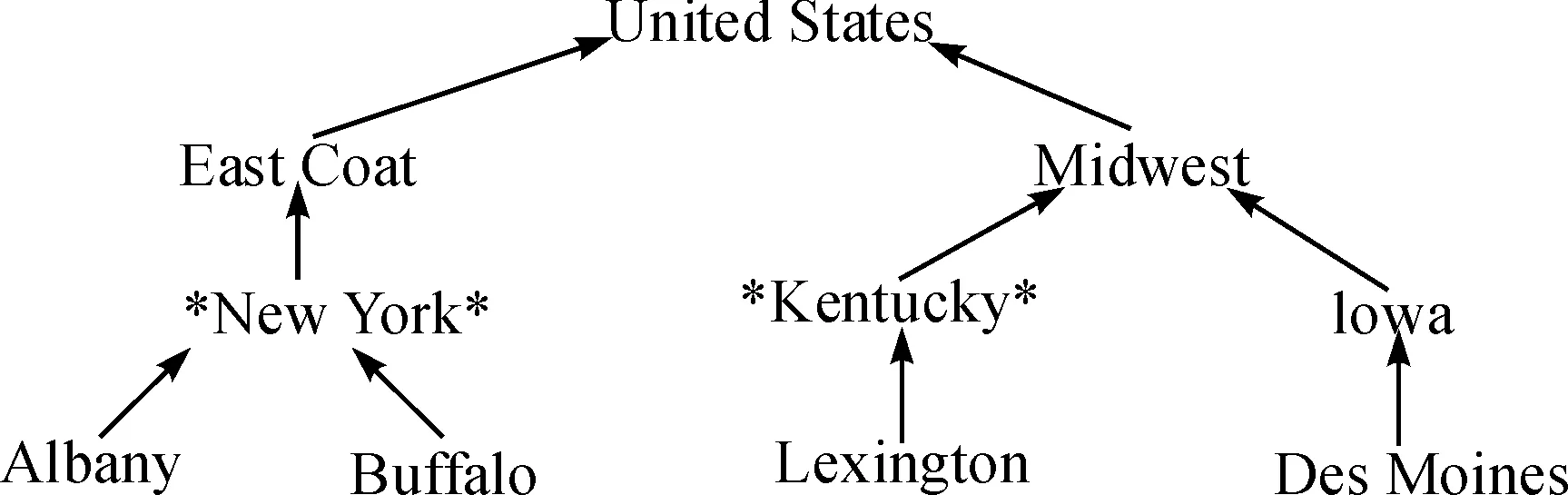
图1 最大允许泛化值的示例Figure 1 Example of maximum alowed generalization value
1. 3基于泛化约束的(K,L)匿名模型
如果匿名数据集不仅满足(K,L)匿名,而且匿名表中准标识符属性值μ的最大泛化值都不超过MAGVal(μ),那么数据集满足泛化约束的(K,L)匿名.如下示例,原始数据集IM中有三个准标识符属性和一个敏感属性,分别是性别、婚姻状况和年龄,疾病是敏感属性,准标识符属性对应的泛化层结构如图2所示,(a),(b),(c)分别对应性别sex,婚姻状况marital_status以及年龄age的泛化结构.年龄age属性值对应的泛化边界如图(c)所示,剩余的准标识符属性没有泛化边界,带*表示最大被允许的泛化值,最后匿名表需要满足泛化约束的(3,2)-匿名.

图2 准标识符属性对应的泛化层Figure 2 Generalization hierarchy for quasi-identifier
表2,3,4分别对应原始表1的匿名表MM1,MM2,MM3,表2满足3-匿名模型,因为每个等价类中有三个元组,满足K-匿名的条件,但是由于第二个等价类(X2,X6,X7)中敏感属性值只有一个Flu,那么攻击者很容易就能通过链接两张表知道30~39年龄段的人一定患了感冒,表MM2中,每个等价类中有三个元组,并且每个元组敏感属性值至少有2个,即匿名表满足(3,2)-匿名(其中k=3,l=2),但是等价类(X4,X5,X6)和等价类(X2,X7,X9)中年龄对应的属性值超过了最大被允许的泛化边界值.在匿名表MM3中,数据集满足(3,2)匿名同时,准标识符属性没有一个属性值的泛化值超过MAGVal.
为了更好的描述基于泛化约束的(K,L)匿名模型,我们引入最大被允许的数据集MAM(maximum allowed microdata),MAM是IM的一个匿名集,在这个匿名集中,每一个准标识符属性值μ都被泛化到MAGVal(μ).通过把原始数据集泛化到MAM,可以让所有的准标识符属性值的泛化范围控制在泛化边界以内,从而达到泛化约束的目的,然后再对MAM进行(K,L)-匿名,那么整个数据集就可以满足泛化约束的(K,L)-匿名.在MAM进行(K,L)-匿名的过程中,会产生一些不满足条件的元组,这些是需要抑制的元组,用符号OUT表示.

表1 原始数据集

表2 3-匿名集

表3 没有泛化约束的(3,2)-匿名集

表4 带有泛化约束的(3,2)-匿名
1.4信息损失和多样性的计算
1.4.1泛化信息(generalization information)
cl={X1,X2,...,Xu}是IM中的元组簇,QI={Q1,Q2,...,Qt}是准标识符属性的集合.cl对应于QI的泛化信息为gen(cl),对于每一个准标识符属性Qj,在{X1[Qj],X2[Qj],...,Xu[Qj]}对应的泛化层HQj中,gen(cl)[Qj]有最小的共同祖先节点[9].gen(cl)即cl对应的满足泛化约束的准标识符属性信息.
1.4.2元组的信息损失度计算
cl是来自于IM中的一个元组簇,QI={Q1,Q2,...,Qt}是准标识符属性的集合,gen(cl)是cl的泛化信息,那么从cl泛化到gen(cl)的信息损失为
IL(cl)=

(1)
其中|cl|表示元组簇中元组的数量,σ(μ)表示从叶子节点值μ泛化到根节点值泛化层HQj的子层,height(HQj)表示泛化树层的高度,t表示准标识符属性的数量.
1.4.3总的信息损失的计算
原始数据集IM泛化到满足泛化约束的(K,L)-匿名集S过程中会产生若干个等价类簇,这些簇总的信息损失可以表示为

(2)
其中n表示IM中的元组数量,t表示准标识符属性的数量,v表示元组簇cl的数量(cl1,cl2,...,clv,clv+1).
1.4.4元组间的多样性计算
为了使等价类中的敏感属性个数满足l个,必须要通过元组间的多样性来进行筛选,两个元组Xi,Xj的多样性公式可以通过以下公式描述:
(3)
(4)
1.4.5元组和元组簇间的多样性
Xi和元组簇cl间的多样性可以描述为
(5)
(6)
r表示敏感属性的数量,wl表示权重值.
1.4.6算法思想与设计
第一个阶段把所有元组的准标识符属性值泛化到最大值形成最大允许的数据集MAM,这样就得到了若干个等价类簇cl,在此基础上再对这些类簇进行(K,L)匿名条件的筛选,使原始数据集满足泛化约束的(K,L)匿名,形成最终满足条件的匿名集.算法的伪代码如下
Input原始数据集IM,(K,L)值,泛化边界值
Output匿名集S={cl1,cl2,...,clv+1,clv+1}
ComputeMAMANDOUT;
1.S=φForeachcl∈MAM-OUTdo
2.S*=φ;i=1;(XR,X) ∈cldo
3.cli=φ;XR=argmaxdiversity(XR,X);
4.cli=cli∪{XR};cl=cl-{XR};
5.dotemp=argmaxdiversity(X,cli);
6.X*=argminIL(X,cli);cli=cli∪{ X*};
7.While(cliisldiversity)or(cl=φ)
8.If(|cli| 9.doX*=argminIL(cli∪{X*}); cli=cli∪{ X*};cl=cl-{ X*}; 10.While(cliisk-anonymity)or(cl=φ) 11.Endif; 12.If(|cli|≥kandXRisl-diversity)then 13.S*=S∪*{cli};i++; 14.While(cl=φ)returnS*; 15.S=S∪S*; 16.Endfor; 2实验结果分析 2.1实验环境 实验基于匿名保护领域通常采用的Adult数据集,整个数据集共有14个属性,32 256条记录.为了方便说明问题,我们去除相对不重要的部分属性,只保留6个准标识符属性和1个敏感属性,6个准标识符属性分别为age,workclass,marital-status,race,sex和native_country,敏感属性为occupation.整个实验程序采用Java语言编写,实验在Intel(R)Core(TM)i5-3470@3.20GHz,32位Win7操作系统上进行.实验中取k=4,6,8,l=2,4,6,8敏感属性的权重为0.3,age的泛化层如图2(c),剩余的准标识符属性的泛化层如下:workclass-1,sex-1,race-1,marital_status-2,native_country-2. 2.2实验结果及分析 实验通过与没有约束条件的(K,L)-匿名算法(用KLA表示)和基于约束的K-匿名算法(用CKA表示)进行对比分析,基于泛化约束的(K,L)-匿名算法用CKLA表示.算法的质量主要通过信息的损失和执行时间两方面进行说明. 1) 信息的损失度 图3 信息损失度对比Figure 3 Comparision of information loss 2) 执行时间 图4 执行时间对比Figure 4 Comparison of execution time 图3和图4的实验结果表明,随着k,l值的变化,与CKLA和CKA相比,KLA的信息损失度有明显升高的趋势,这是由于KLA没有泛化约束条件的限制,在泛化过程中存在过度泛化的问题,导致信息的可用性降低.在时间开销上,CKLA和CKA的执行时间远远低于KLA,这是因为没有泛化约束的匿名算法在进行泛化时需要进行更多次的元组记录交换与筛选,当数据记录很庞大时,这会大大的降低算法的执行效率.从实验结果来看,CKA的信息损失度和执行时间都要低于CKLA,但是CKA不满足同一等价中有多个敏感属性值要求,很容易受到同质性攻击,达不到很好的匿名保护效果.因此,从保护隐私信息和保证原始信息可用性角度出发,基于泛化约束的(K,L)-匿名算法是一种更好的隐私保护模型. 3总结与展望 本文对数据发布中的隐私保护问题进行了研究和探讨,从个人隐私信息保护中保护原始数据的可用性出发,针对匿名保护模型中过度泛化容易造成数据可用性降低的问题,提出了基于泛化约束的(K,L)-匿名算法,实验表明,在同等条件下,该算法在保护数据可用性和执行效率方面都有了明显的提高.但是算法在提高信息的损失度方面并没有明显提高,这是下一步要继续解决的问题.本算法实验是在单敏感属性条件下进行的,针对多敏感属性[10]的匿名保护也是下一步要考虑的问题,后面要继续对算法进行优化,期望能达到更好的匿名保护效果. 【参考文献】 [1]BAYARDO R J,AGRAWAl R.Data privacy through optimal k- Anonymization[C]//In Proceedings of the IEEE International Conference of Data Engineering.Icde:IEEE,2005:217-228. [2]张新宝.隐私权的法律保护 [M].北京 :群众出版社, 2004:11-15. [3]ALANAZI H O,ZAIDAN A A, ZAIDAN B B, et al.Meeting the security requirements of electronic medical records in the ERA of high-speed compuing[J].Journal of Medical Systems,2015,39(1):1-13. [4]KOHLMAYER FPRASSE R,FECKERT C,et al.A flexible approach to distributed data anonymization[J].Journal of Biomedical Informatics,2014,50(8):62-76. [5]LAST M, TASSA T,ZHMUDYAK A,et al.Improving accuracy of classification models induced from anonymized data sets[J].Information Sciences,2014,256:138-161. [6]柴瑞敏,冯慧慧.基于聚类的高效(K,L)-匿名隐私保护 [J].计算机工程 ,2015,41(1):139-142,163. CHAI Ruimin, FENG Huihui. Anonymity privacy protection based on clustering[J].Computer Engeering,2015,41(1):139-142,163. [7]陈磊.医疗数据隐私保护研究综述[J].中国数字医学,2013,8(11):95-98. CHEN Lei.Review of medical data privacy protetion[J].China Digital Medicine,2013,8(11):1-4. [8]GLENN T,MONTEITH S.Privacy in the digital world:Medical and health data outside of HIPAA protections[J].Current Psychiatry Reports,2014,16(11):494. [9]ODERKIRK J,RONCHI E,KLAZINGA N.International comparisons of health system performance among OECD countries:Opportunities and data privacy protection challenges[J].Health Policy,2013,112(2):9-18. [10]王庆飞,方翔,朱根.数据发布中的K-匿名隐私保护机制研究[J].福建电脑,2015,4(4):3-4,17. WANG Qinfei,FANG Xiang,ZHU Gen.Privacy protection mechanisms forK-anonymity study in the data publication[J].FuJian Computer,2015,4(4):3-4,17. A (K,L)-anonymity algorithm with generalization constraints ZHU Weihong, PAN Julong, SHI Lei (College of Information Engineering, China Jiliang University, Hangzhou 310018, China) Abstract:Aiming at the decrease of data availability, (K,L)-anonymity algorithm with generalization constraints was proposed. The algrothm firstly formed MAM(maximum allowed microdata) to control the boundary of quasi-identifier with MAGVal(maximum alowed generalization value) and then conducted screen with(K,L)-anonymity for the purpose of privacy protection.The experiment shows that the algorithm can not only guarantee the availability of information but can also greatly reduce the time for generalization information. Key words:privacy information; generalization constrains; (K,L)-anonymity algorithm 【文章编号】1004-1540(2016)01-0080-06 DOI:10.3969/j.issn.1004-1540.2016.01.015 【收稿日期】2015-12-07《中国计量学院学报》网址:zgjl.cbpt.cnki.net 【作者简介】朱卫红(1987- ),男,湖北省孝感人,硕士研究生,主要研究方向为医疗信息隐私保护.E-mail:563683637@qq.com 【中图分类号】TP399 【文献标志码】A 通信联系人:潘巨龙,男,教授.E-mail:pjl @cjlu.edu.cn

