大型网站的架构模式研究
2016-06-05郑逸凡
郑逸凡
(福州外语外贸学院福建福州350202)
大型网站的架构模式研究
郑逸凡
(福州外语外贸学院福建福州350202)
随着网站规模的不断扩大,用户的访问量逐渐增加,简单的LAMP架构无法支撑大型网站快速发展的业务需求。为了解决大型网站面临的高并发、大流量等问题,大型互联网企业在实践中提出了很多解决办法。本文从这些解决办法中,归纳出了进行大型网站架构设计时比较常见的模式。
架构模式;分布式;大型网站
随着互联网的普及,人们的生活越来越离不开网络媒体,特别是近些年,像淘宝、京东这类大型电商网站迅速发展,微博、微信等大型社交类媒体用户持续增加。为了提升网站服务性能,提高用户的访问速度,作为这类大型网站的架构师,已经在长期的开发实践中探索出了很多方法,这些解决方法又被更多网站重复使用,从而逐渐形成大型网站常用的架构模式,主要有分层、分割、分布式集群、缓存、异步这几种模式。
1.分层
分层架构模式是最常用的架构模式,也被称为N层架构模式。分层架构模式内部的组件被组织成水平的分层,每一层执行特定的功能。尽管分层架构模式没有指定分层的数量和类型,大部分都会分成四层:展示层(presentation)、业务层(business)、持久层(persistence)、数据库层(database)。某些情况下,业务层和持久层会合并成一个业务层,尤其是当持久化逻辑嵌入在业务层组件中。[1]一个典型的分层架构模式如图1所示:

图1 分层架构模式
分层架构模式的每一层对应着网站的特定功能。例如,持久层负责处理用户交互和浏览器通信逻辑,业务层负责执行特定的与请求相关的业务规则。架构中的每一层将需要完成的工作进行抽象,来满足特定的业务请求。例如,展示层不需要知道也不需要关心如何获取用户数据,它只需要将信息以特定的格式展示到界面上。[2]相似的,业务层不需要关心如何展示数据和数据从哪来,它只需要从持久层获取数据,对数据进行业务逻辑处理(计算、聚合等等),并将结果向上传递给展示层。
2.分割
大型网站的功能复杂、应用众多,如果把这些功能和应用部署在同一台服务器上,那么将给服务器造成很大的压力。因此在实践中,架构师要对整个网站的功能进行拆分,然后分别部署,比如淘宝网就将天猫、聚划算、阿里旅行等不同的功能模块,部署在不同的服务器上。
对于大型网站,如何分割功能模块,分割到什么程度?这是一件比较复杂的事情,首先必须理清网站的业务逻辑,做好网站的功能模块划分,然后编写相应的功能类或函数,形成高内聚、低耦合的应用模块,这里面涉及到面向对象、接口、服务等不同的设计原则,需要架构师在开发过程中不断积累经验。
3.分布式集群
当一个网站的用户访问量不断增加,网站服务器就需要更多的CPU、内存、存储空间等资源,而提高单台服务器的配置(比如升级CPU、提高硬盘容量)所需要的价格是比较昂贵的。因此一方面从经济利益方面考虑,可以采用分布式集群来进行部署,方法是通过在服务器端部署更多数量的、价格相对低廉的PC Server,当用户向网站发出请求时,负载均衡设备会根据当前所有服务器的负载情况,将不同的用户请求转向不同的服务器。另一方面,当网站架构采用分布式集群后,可以有效防止服务器宕机的情况,比如某台服务器突然发生故障,那么系统会自动将用户的请求转给集群中正常运行的其他服务器来处理。
目前大型网站普遍使用Hadoop及其MapReduce分布式计算框架进行批处理计算,其特点是移动计算,将计算程序分发到数据所在的位置以加速计算,典型的Hadoop分布式系统架构如图2所示。

图2 Hadoop分布式系统架构
Hadoop是可扩展的集群,它采用非共享系统处理大规模并行数据。Hadoop的总体概念是单个节点对于整个集群的稳定性和性能来说并不重要。根据这种设计理念,我们可以在单个节点上选择能够高效处理少量(相对于整体的数据量大小)数据的硬件并且在硬件层面也无需过分追求稳定性和冗余性。[3]Hadoop集群由多种类型的服务器所组成。它们中有主节点,比如NameNode、备份NameNode以及JobTracker,还有称为DataNode的工作节点。除了核心的Hadoop成员外,我们通常还会采用多种辅助服务器,比如网关、Hue服务器以及Hive元存储服务器。
4.缓存
缓存就是用来避免频繁的到主存储器(一般来说可能是数据库,结构化的磁盘文件,远程网络接口,程序接口等等提供数据返回的)获取数据而建立的一个存取更快的临时存储器。缓存的主要目的是为了提高数据的读取速度,因为服务器和浏览器之间存在着流量的瓶颈,所以读取大容量数据时,可以将缓存中的数据直接返回给浏览器,以减少浏览器与服务器之间数据交互,从而提高网站的性能。[4]网站缓存的实现方式主要有以下几种:
(1)动态页面的静态化。应用程序把动态生成的页面缓存到文件服务器,以后用户请求该动态页面,直接从文件服务器加载对应的静态缓存的html文件返回给用户,这里面主要节省了应用程序的执行时间和数据库访问时间,但是会增加缓存框架的加载和缓存查找的时间。
(2)把解释执行的开发语言编译成为目标代码。将解释执行的高级语言(如java,php),直接编译成为平台相关的目标代码,在java里面,比较著名的就是即时编译器(JIT)。该方法主要节省了解释执行代码的时间,但会增加即时编译的时间。
(3)利用反向代理服务器的缓存。利用类似nginx的反向代理服务器,对请求的url对应的输出进行缓存。一般情况下,当用户向web服务器发出请求时,首先是经过反向代理服务器,由反向代理服务器根据当前服务器的资源使用情况,将不同用户的请求转发给不同的服务器,当服务器处理完毕,把结果通过反向代理服务器返回给用户。如果把用户最经常访问的数据,缓存在反向代理服务器上,那么当用户发出请求后,直接就可以从反向代理服务器的缓存中获取到数据,这样就加快了网站的响应速度。
(4)客户端浏览器缓存。当客户端发出的http请求中包含If-Modified-Since,如果服务器端代码没有修改,则返回302响应代码的请求响应头(内容不返回);当客户端发现如果上次请求的页面还未过期,通过Expires或者Cache-Control进行辨别,直接显示本机缓存的内容,不与服务器进行通信,节省了服务器执行代码时间以及数据传输时间。
5.异步
在大型网站架构中,采用异步模式可以降低网站的耦合度。当用户向web服务器发出请求,网站应用层要对用户的业务逻辑进行处理,然后将处理的结果返回给用户,若采用同步的架构模式,当业务逻辑处理的时间比较长时,用户将出现长时间的等待,大大降低了网站的用户体验度。如果采用异步的方式,当用户发出请求后就可以继续处理其他的业务,web服务器接收到请求信息并处理完成后,通过异步的方式把执行结果返回给用户。
在大型网站中,一般采用消息队列的方式来实现异步的架构模式。网站的应用层执行完相关业务后,把消息给消息队列然后直接返回客户端,这样就避免了处理复杂的业务逻辑然后同步的插入到数据库后再返回造成的响应延迟,实现了应用解耦。[5]在很多网站上用户提交订单就是这么处理的,如图3所示。
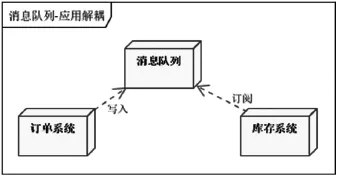
图3 用户订单处理
订单系统生成一个订单号之后,将订单丢给消息队列,然后直接跳转到订单成功页面,此时库存系统对订单还没有处理完毕,因为其中涉及到比较多的数据操作,比如减库存,数据库同步等等,而用户如果想要看到订单详情,需要点击“订单号”才能进入到订单详情页,这种处理也是因为消息队列的非及时性。
6.结束语
大型网站架构从来都不是一个预先定义的架构,而是一个演进式的架构。很少有一个网站从建站开始,就能够因具备大型网站的所有属性而一成不变的,从最简单的LAMP架构,再到基于IOE的大型集中式应用架构,再演变成时下的分布式应用架构,随着网站用户规模的扩大,架构也在不断演进。
[1]韩树河.大型网站应用技术架构演变的研究[J].吉林化工学院学报,2015,01: 53-56.
[2]房辉,常盛.大型网站高性能架构研究[J].信息系统工程,2015,12:76-77.
[3]张建超,张连堂.网站架构演变技术研究[J].现代计算机(专业版),2012,04:53-55.
[4]包立辉,黄彦飞.高并发网站的架构研究及解决方案[J].计算机科学,2012,S2: 184-187.
[5]刘敏娜,解争龙.基于SSI框架的高性能网站服务器端优化技术[J].计算技术与自动化,2014,03:139-144.
TP393
A
2095-7327(2016)-12-0151-02
2014年福建省大学生创新训练项目,项目名称为基于PC和移动终端的校园生活服务网站和APP设计,项目编号为201413762044。
郑逸凡(1983—),男,讲师,软件设计师,主要研究方向为web开发、软件设计。
