基于分布式表示和多特征融合的知识库三元组分类
2016-06-01韩先培
安 波,韩先培,孙 乐,吴 健
(中国科学院 软件研究所 中文信息处理研究室,北京 100190)
基于分布式表示和多特征融合的知识库三元组分类
安 波,韩先培,孙 乐,吴 健
(中国科学院 软件研究所 中文信息处理研究室,北京 100190)
三元组分类是知识库补全及关系抽取的重要技术。当前主流的三元组分类方法通常基于TransE来构建知识库实体和关系的分布式表示。然而,TransE方法仅仅适用于处理1对1类型的关系,无法很好的处理1对多、多对1及多对多类型的关系。针对上述问题,该文在分布式表示的基础上,提出了一种特征融合的方法—TCSF,通过综合利用三元组的距离、关系的先验概率及实体与关系上下文的拟合度进行三元组分类。在四种公开的数据集(WN11、WN18、FB13、FB15K)上的测试结果显示,TCSF在三元组分类上的效果超过现有的state-of-the-art模型。
知识库;深度学习;三元组分类
1 引言
知识库是人工智能和自然语言处理的关键资源,在问答系统、智能检索及情感分析等领域起到重要的作用。目前已经有许多知名的大规模知识库,如FreeBase、WordNet等。然而,考虑到知识的规模和更新速度,现有知识库的覆盖度仍然无法达到要求。因此,知识库补全(Knowledge base completion)在近几年成为了热门国际评测任务。三元组分类是知识库补全的关键技术之一,由Socher[1]等人首先提出。给定三元组(head,relation,tail),head和tail表示头部和尾部实体,relation表示实体之间的关系。三元组分类的目的是计算三元组的置信度,从而判断该三元组所表示的语义关系是否为真,如果该三元组为真,则该三元组(head,relation,tail)将被加入到知识库。
目前大部分三元组分类系统首先将知识库中的实体和关系编码到低维向量空间,并基于这些连续向量构建置信度模型对三元组进行打分。具体地,对于知识库中的任意实体,使用一个实数向量进行表示,知识库中的任意关系也一个实数向量(维度可以与实体向量的不同)来表示。对知识库的分布式表示任务,TransE[2]是目前效果较好的模型,且时间复杂度较低。但是,就像TransM[3]中指出的那样,TransE并不适于处理1对多(1-to-N)、多对1(M-to-1)及多对多(M-to-N)类型的关系。与此同时知识库中的大多数关系都不是1对1(1-to-1)类型的。本文针对知识库补全任务中常用的四个数据集中的关系进行统计分析,分别是WN11[1]、WN18[2]、FB13[1]和FB15K[2],其中WN11和WN18抽取自WordNet*http://www.princeton.edu/wordnet数据集,FB13和FB15K抽取自Freebase*http://www.freebase.com数据集,其结果如表1所示。从表1中可以看出,WN11数据集中的所有11种关系均为多对多(M-to-N)类型的关系;WN18数据集中的所有18中关系也全都属于多对多(M-to-N)类型的关系;FB13数据集中包含一种多对1(M-to-1)的关系和12中多对多(M-to-N)的关系;FB15K数据集中包含1 345种关系,其中只有247种关系为1对1(1-to-1)类型的关系,其余的均为1对多、多对1及多对多类型的关系。因此,在上述的四种数据集中,绝大多数关系属于非简单的1对1关系。因此,我们认为,TransE模型由于不能很好的编码知识库中的1对多(1-to-N)、多对1(M-to-1)、多对多(M-to-N)类型的关系,仅仅依赖于三元组距离|h+r-t|来计算三元组的置信度的现有模型,无法很好的建模多种复杂的关系。
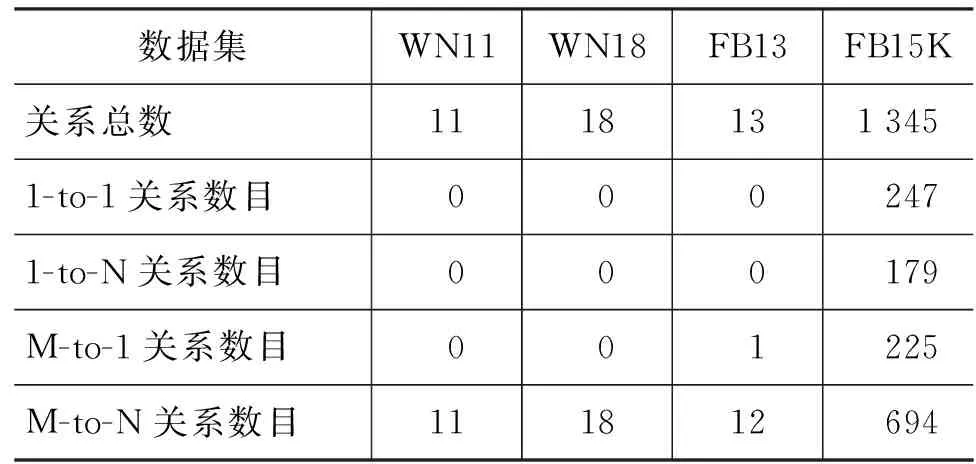
表1 知识库关系分类信息
针对上述问题,本论文在知识库分布式表示的基础上,提出了一种多特征融合的方法—TCSF,综合利用三元组的距离、关系的先验概率及实体与关系上下文的拟合度来进行分类。具体地,TCSF通过两个启发式规则来解决上述问题: 1)先验规则: 一个关系在知识库中出现的次数越多,则给定的实体对(h,t)具有该关系的可能性就越高;2)实体对(h,t)与给定关系r上下文拟合程度越高,则该三元组(h,r,t)的置信度越高。本文提出的方法是在知识的分布式表示基础上利用关系的先验信息和关系的上下文特征针对三元组分类任务进行的优化,该方法不针对具体的模型,可以对TransE、TransH等基于翻译的关系表示模型进行结果优化。
本文在上述四个数据集上进行了实验。实验结果表明,相比于TransE[2]及其他state-of-the-art模型,本文提出的方法能够大幅提升三元组分类的效果。
2 相关工作
目前大部分三元组分类方法包含两个模块: 1)如何将三元组(h,r,t)中的关系和实体映射为低维向量或矩阵表示;2)如何构建损失函数fr(h,t)对三元组的置信度进行打分。以下分别从上述两个模块介绍现有的不同方法。
UnstructuredModel[4]是一个较为朴素的模型,该模型基于头部实体h和尾部实体t共现的信息来对知识库中的实体进行编码,但不对关系进行编码,其损失函数如式(1)所示。
DistanceModel[5]与UM模型类似,但是增加了对关系的编码。该模型将知识库中的每个关系编码为两个矩阵(Wrh,Wrt),其损失函数如式(2)所示。
SingleLayerModel[1]通过单层的神经网络来对DM模型进行改进,该模型的损失函数如式(3)所示,其中g为tanh函数。
BilinearModel[6]通过增强三元组中实体对之间的交互关系来改善DM模型,该模型将关系编码为一个矩阵,实体编码为向量,其损失函数如式(4)所示。
NeuralTensorNetwork[1]是当前较为有效的模型,NTN模型结合SLM和BM模型的优点,其损失函数如式(5)所示。该模型的主要缺点是模型参数较多,时间复杂度高。结合式(3)、式(4)、式(5)可以看出,NTN模型是SLM模型及BM模型的组合优化。
TransE[2]是近期提出的一种简单高效的编码方式,该模型将关系看作是从头部实体到尾部实体的转移,将知识库中的实体和关系编码到相同维度的向量空间,并假设h+r-t≈0。其损失函数如式(6)所示。TransE以较低的时间复杂度取得了较好的效果,后续的方法大多数是基于TransE的改进。
TransM[3]通过为每个关系增加一个权重因子wr来改进TransE模型,其中wr的计算方法如式(7)所示。该模型的损失函数如式(8)所示。其中hrptr表示:对于每个关系r,其尾部实体t对应的头部实体的h的个数。
TransH[7]通过将知识库中的实体和关系编码到不同维度向量来处理非1对1类型的关系。在该模型中,每个关系使用一个转移向量和一个映射向量来表示。映射向量用于将实体向量映射为与关系向量同维度的向量。其映射函数及损失函数如式(9)、式(10)所示。
TransR[8]与TransH类似,该模型将知识库中的关系用一个转移向量和一个映射矩阵表示。通过映射矩阵与实体向量的运算,完成从实体空间到关系空间的映射,其损失函数如式(11)、式(12)所示。
IIKE[9]将三元组看作实体h、关系r和实体t之间的联合概率,该模型的概率计算函数如式(13)所示。

综上所述,目前大部分模型通过优化TransE[2]的损失函数来改善知识库编码,进而改善三元组分类效果。但是上述模型在三元组分类的时候,只使用了实体和关系的分布式表示。分布式表示存在缺乏先验知识和知识库本身不完整的缺点,导致仅依靠知识库的分布式表示很难取得很好的效果。针对分布式表示的这种问题,本文提出,综合三元组的距离、关系的先验概率及实体与关系上下文的拟合度来提高分类准确率。
3 基于分布式表示和多特征融合的三元组分类方法
为解决前文中提到的问题,我们首先对TransE模型进行分析以得出解决方案。首先,根据TransE的损失函数式(6)可知,当两个实体h1和t1之间存在两种不同关系r1和r2时,有(h1,r1,t1) ∈△+且 (h1,r2,t1) ∈△+,从而可以得到h1+r1-t1≈0和h1+r2-t1≈0。依次可以推出r1≈r2。此时,当知识库中存在三元组(h2,r1,t1) ∈△+,则可以推出h2+r1-t1≈0,结合上面推出的r1≈r2,可以推出h2+r2-t1≈0,推出(h2,r2,t1) ∈△+。但是h2和t1并不一定具有r2关系。具体的例子如下:
(Obama,born_in,USA) ∈△+、 (Obama,president_of,USA) ∈△+
(Justin_Biber,born_in,USA) ∈△+
本文对四个常用的数据集进行统计分析,其结果如表2所示。从表中可以看出,数据集中实体对具有不同关系的情况普遍存在,且在FB13和FB15K特别明显。由上述分析可推出,当一个实体对具有多种不同关系的时候,TransE[2]会将其编码到相似在进行三元组分类时,通过式(6)计算给定(h,r,t)的距离。但当实体对具有关系r′,且r′与r的编码相似时,就会错误的将三元组(h,r,t)判定为真。因此,解决上述问题的关键是如何正确的区分编码相近的关系。针对该问题,本文通过启发式的方法来对相似空间的不同关系进行区分,以提高三元组分类的准确率。本文使用的启发式规则包括关系的先验概率和关系的上下文。在分布式表示模型中,实体或者关系之间语义的相似度通常使用计算向量之间的相似度表示。具体地,TCSF使用欧几里得距离式(14)来计算两个关系的相似度。
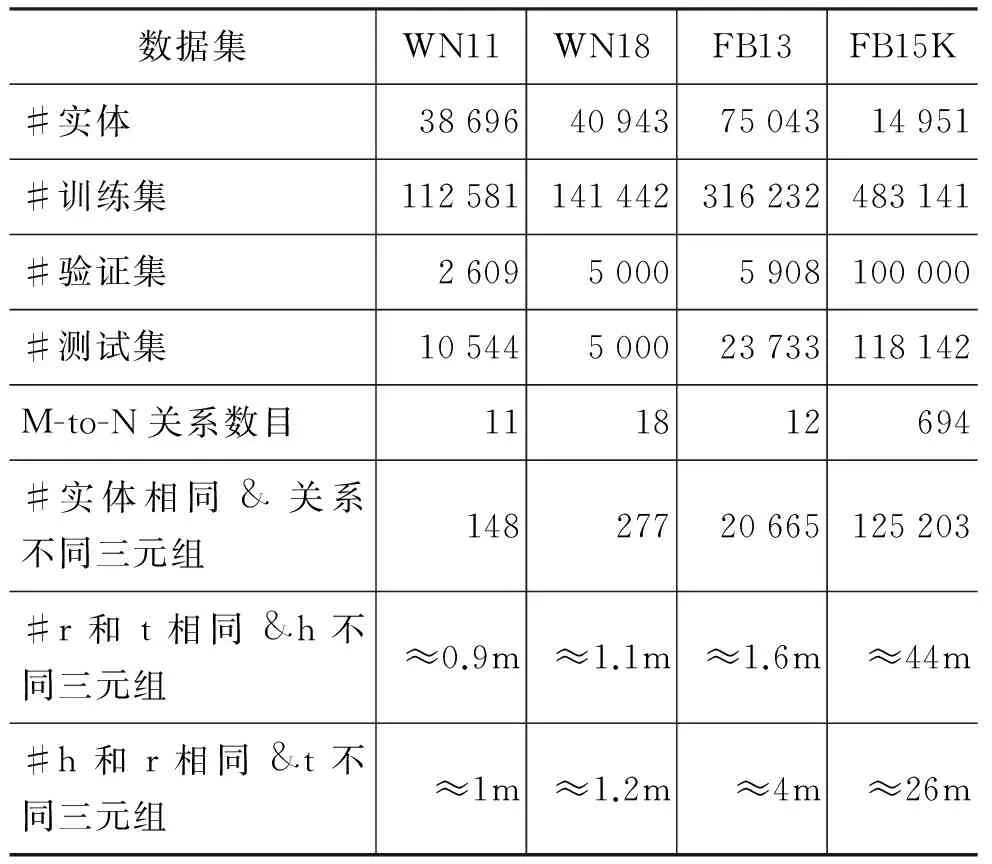
表2 数据集统计信息
注: “#”表示数量;“&”表示“与”关系;的空间,容易引起错误的分类。
3.1 关系的先验概率
本文使用的第一个启发式规则是关系的先验概率,即一个关系出现的次数越多,则实体对(h,t)具有该关系的概率就越大。给定候选三元组(h,r,t),本文通过对比给定关系r最相似的关系r′来确定关系r的先验概率,如式(15)所示。
其中Nr是关系r在训练集中出现的次数,Nr′是与关系r最相似的关系。本文只考虑最相似关系的原因是相似的关系得到损失值较为类似,容易引起错误分类。当关系的表示相似度差别较大的时候,根据式(6)不容易产生误分类。

Algorithm1ThetripleclassificationofTCSFInput:TrainingsetT={(h,r,t)},validsetV={(h,r,t)},testsetS={(h,r,t)},entitiesandrelationssetEandR,marginγ,embeddingdim.d,normL1/L2,stepsizest,epocheep,threshold.RunTransEandgeneratetheembeddingsofentitiesandrelationsforeachr∈R //对于每个关系,计算出其头部实体和尾部实体的均值sim(r)=min{dis(r',r)},r'∈Randr'≠ravgHead(r)=1n∑ni=1h,h∈Hrandn=|Hr|avgTail(t)=1n∑ni=1t,t∈Htandn=|Ht|foreach(h,r,t) ∈Sdo //结合翻译距离及先验概率计算三元组的可信性 iffr(h,t)
3.2 关系的上下文
TransE[2]进行训练时,训练集中的每个三元组(h,r,t)作为正例,负例通过随机替换实体h或t构造。该方法类似于Word Embedding中的训练方法。基于上述讨论,我们认为所有具有关系r的实体对集合{(h1,t1),(h2,t2), …}就构成了关系r表示的上下文。在计算(h,r, t)三元组打分的时候,我们可以不仅仅使用关系r的表示,同时也可以计算实体对(h,t)与r的上下文之间的匹配程度。
具体地,本文将关系r的上下文表示为具有关系r的三元组的头部实体编码向量的均值表示及尾部实体的均值表示。向量的均值反应了该关系对应的头部实体和尾部实体的主要特征,如关系born_in对应的头部实体通常为人名,尾部实体通常为地名。根据TransE[2]得到的结果分析可知,相同类型的实体会编码到比 较相近的区域,如人名会较为集中的分布在一个区域,地名也会被集中的分布式另外一个区域。因此,给定一个三元组(h,r,t),实体对(h,t)与关系r的合理程度可以通过判断头部实体h和尾部实体t与关系r对应的头部实体和尾部实体的均值(关系的上下文)的拟合度来判断。当实体与关系的上下文拟合度较低的时候,则该三元组的置信度较低。上下文的拟合度可以通过式(16)计算得到。
3.3 算法
TCSF利用关系的先验概率和实体对与关系上下文的拟合度的对相似的关系进行区分,计算方法如式(17)所示。Algorithm 1是模型的简化算法。
4 实验
4.1 实验数据
本文使用四个常用的数据集来测试模型的效果,分别是WN11[1]、WN18[2]、FB13[1]和FB15K[2],这些数据摘自WordNet和FreeBase知识库。在TransE[2]的实验设计中,测试集中的负例是通过随机的替换三元组的头部实体或者尾部实体进行构造。为了构建质量更高的测试数据,本文采用Socher[1]等人提出的方法。在进行实体替换时,替换的实体应该在相应的位置出现过,且不能是已经存在知识库中的三元组。例如,当替换头部实体时,该实体在训练集中作为头部实体出现过。WN11、FB13及FB15K数据集,我们直接使用Fan[3]等人公开的数据。本文根据Fan[3]中的方法构建了WN18的验证集和测试集。四种数据集的统计信息如表2所示。
4.2 实验结果
本文与主流的几种方法进行比较,包括TransE[2]、TransM[3]、TransH[7]、TransR[8]。因为实现和参数调整的问题,我们没有得到相应论文中的最好结果,因此本文直接使用各个模型在相应论文中的最优准确率作为对比依据。为了减少因为参数随机初始化对结果造成的影响,本文对每一组参数都进行十次实验,并取其平均值和最优值作为最终的结果。通过多次实验验证,得到每种数据集的参数,(d=200, γ=2.0, st=0.02, ep =300 for WN11; d=200, γ=1.0, st=0.003, ep =10 for WN18; d=100, γ=2.0, st=0.03, ep =20 for FB13; d=400, γ=3.0, st=0.002, ep =30 for FB15k)。d代表实体和关系的维度、γ是margin值、st为初始的学习率、ep是迭代的次数。
三元组分类任务使用准确率作为评价指标,计算方法如式(18)所示。式中Tp和Tn表示预测正确的正例数和负例数,Npos和Nneg代表训练集中的正例数和负例数。ACC越高表示系统预测的准确率越好,其计算方法如式(18)所示。
实验结果如表3所示,TCSF在四种数据集上的最优结果明显高于其他系统。但平均值在FB15K上略低于IIKE[9]和TransR[8]。本文提出的方法是在TransE[2]上的改进,实验结果显示(表4中第一行TransE的结果来来自文献[8],TransE-avg和TransE-best的结果来自于本文的实现),在四种数据集上的三元组分类的准确率的均值和最高值能提升十个以上的百分点。
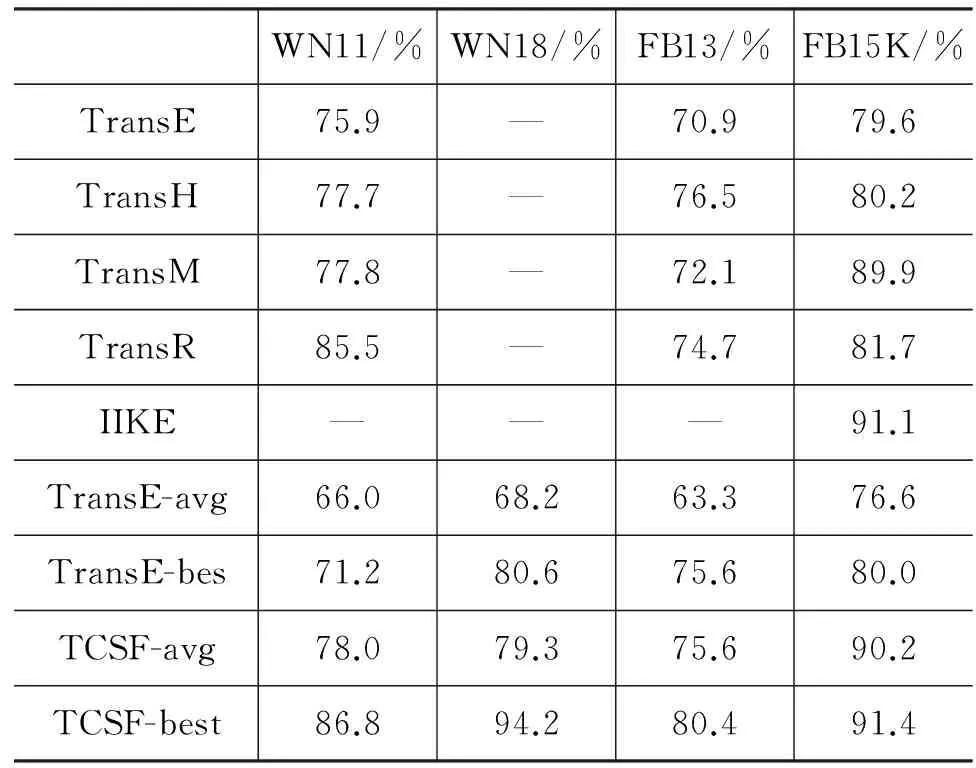
表3 模型在不同数据集上的准确率
注: “avg”表示10次实验的平均值;“best”表示十次实验的最好值。
为了验证我们的方法在不同类型上的关系上的效果,我们在FB15K上针对不同类型的关系进行了三元组分类任务,因为该数据集包含的关系数量较多,且如表1所示,包含全部四种类型的关系。得到的结果如表4所示,从表4中可以看出,我们的方法相对于TransE在1-N、M-1和M-N类型的关系上取得了明显的提升,在1-1类型的关系上的准确率没有变化。因此我们的方法可以有效的提高非1-1类型的关系的分类准确率。

表4 模型在FB15K中不同关系类型上的结果
在本文中,我们主要利用了关系的先验概率和关系的上下文两种特征来增强三元组分类的准确性,为了更好的分析不同的特征在不同类型的关系类型中的效果,本文通过在TransE训练的分布式表示上分别增加不同别的特征在三元组分类任务上进行测试,结果如表5所示。

表5 不同特征在FB15K中不同关系类型上的结果
注: TransE+Prop表示在TransE的基础上增加先验特征;TransE+Context表示在TransE的基础上增加关系上下文特征;
通过表5的结果可以看出,关系的先验特征能够在1对多(1-to-N)、多对1(M-to-1)、多对多(M-to-N)类型的关系上改进三元组分类的效果;关系的上下文特征也可以在1对多(1-to-N)、多对1(M-to-1)、多对多(M-to-N)类型的关系上改进三元组分类的效果。并且通过结果的对比可知,关系的上下文比关系的先验概率对结果的提高更明显,并且两种特征的叠加可以取得更号的结果。
通过表3~表5的结果可知,本文提出的方法基于TCSF能够很大程度上提高三元组分类的效果,我们提出方法有三个关键贡献。
(1) 我们的方法能够很大程度的提高三元组分类的结果,产生新的state-of-the-art的结果。
(2) 我们通过对比不同的特征对不同类型的关系上的分类效果,更直观的反映了不同的特征在三元组分类中的作用。
(3) 本文提出的方法是在知识表示的基础上针对三元组分类任务的扩展,不仅可以在TransE上使用,也可以在TransM、TransH等模型上使用,具有较好的通用性。
5 结束语
本文在知识库分布式表示的基础上提出了一种特征融合的方法,从而有效提高三元组分类的准确率。实验结果显示,TransE[2]等系统无法很好的建模非1对1类型的关系。本文通过加入关系的先验知识和关系的上下文特征,能够有效提高三元组分类上准确率,验证了不同的特征对不同类型关系的分类效果。
[1] R Socher, D Chen, C D Manning, et al. Reasoning with neural tensor networks for knowledge base completion[C]//Proceedings of the Advances in Neural Information Processing Systems,2013:926-934.
[2] A Bordes, N Usunier, A Garcia-Duran, et al. Translating embeddings for modeling multi-relational data[C]//Proceedings of the Advances in Neural Information Processing Systems,2013:2787-2795.
[3] Miao Fan, Qiang Zhou, Emily Chang, et al. Transition-based Knowledge graph embedding with relation mapping properties[C]//Proceedings of the PACLIC,2014:328-337.
[4] Bordes A,Glorot X, Weston J, et al. A semantic matching energy function for learning with multirelational data[J]. Machine Learning,2014,(2):1-27.
[5] A Bordes, J Weston, R Collobert, et al. Learning structured embeddings of knowledge bases[C]//Proceedings of the AAAI,2011:201-306.
[6] I Sutskever, R Salakhutdinov, J B Tenenbaum. Modelling relational data using bayesian clustered tensor factorization[C]//Proceedings of the NIPS,2009:1821-1828.
[7] Wang Z, Zhang J, Feng J, et al. Knowledge graph embedding by translating on hyperplanes[C]//Proceedings of AAAI,2014:1112-1119.
[8] Yankai Lin, Zhiyuan Liu, Maosong Sun, et al. Learning entity and relation embeddings for knowledge graph completion[C]//Proceedings of the AAAI,2015:2181-2187.
[9] Miao Fan, Kai Cao, Yifan He. Jointly Embedding Relations and Mentions for Knowledge Population[J]. arXiv preprint,2015:arXiv:1504.01683.
[10] Socher R, Chen D, Manning C D, et al. Reasoning with neural tensor networks for knowledge base completion[C]//Proceedings of NIPS,2013:926-934.
[11] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. JMLR,2003, 3:1137-1155.
[12] Jenatton R, Roux N L, Bordes A, et al. A latent factor model for highly multi-relational data[C]//Proceedings of NIPS,2012:3167-3175.
Triple Classification Based on Synthesized Features for Knowledge Base
AN Bo, HAN Xianpei, SUN Le, WU Jian
(Laboratory of Chinese Information Processing, Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)
Triple classification is crucial for knowledge base completion and relation extraction. However, the state-of-the-art methods for triple classification fail to tackle 1-to-n, m-to-1 and m-to-n relations. In this paper, we propose TCSF (Triple Classification based on Synthesized Features) method, which can joint exploit the triple distance, the prior probability of relation, and the context compatibility between entity pair and relation for triple classification. Experimental results on four datasets (WN11, WN18, FB13, FB15K) show that TCSF can achieve significant improvement over TransE and other state-of-the-art triple classification approaches.
knowledge base; deep learning; triple classification

安波(1986—),博士研究生,主要研究领域为自然语言处理和知识表示。E-mail:anbo@nfs.iscas.ac.cn韩先培(1984—),副研究员,主要研究领域为信息抽取、知识库构建以及自然语言处理。E-mail:hanxianpei@qq.com孙乐(1971—),研究员,博士生导师,主要研究领域为信息检索和自然语言处理。E-mail:lesunle@163.com
1003-0077(2016)06-0084-06
2016-09-01 定稿日期: 2016-10-16
国家自然科学基金(61540057,61433015,61272324,61572477);青海省自然科学基金(2016-ZJ-Y04,2016-ZJ-740)
TP391
A
