藏文复合句的依存句法分析
2016-06-01华却才让赵海兴
华却才让,赵海兴
(青海师范大学 藏文信息处理省部共建教育部重点实验室,青海 西宁 810008)
藏文复合句的依存句法分析
华却才让,赵海兴
(青海师范大学 藏文信息处理省部共建教育部重点实验室,青海 西宁 810008)
为解决藏文复合句引起的依存句法分析性能下降的主要问题,该文提出了一种基于判别式的藏文复合句切分标注方法,先根据藏文固有的虚词语法结构和连词特征,将复合句子切分标注为句法分析的基本单元,然后将句法分析之后的各个部分依据主分句关系进行合并,生成复合句的完整分析结果。实验结果表明该方法在一定程度上降低了藏文复合句依存句法分析的复杂度,最终句法分析的准确率达到88.72%。
句法分析;依存句法;藏文分句;藏文复合句
1 引言
依存句法分析作为自然语言处理的核心问题,主要对句子中的词语语法功能进行有效分析,以备各种上层的应用,但由于文本中句子的长度和结构变化很大,随着句子长度的增加,句法分析的时空复杂度将会急剧上升,导致产生更多的句法歧义,这会严重影响句法分析的质量,为此,句法分析中采用分治策略来处理复杂句型[1],先根据句子中的标点符号和连接词的功能将句子分为不同的部分,然后分别对每个部分进行句法分析,获得局部最优结果后,将合并每个部分的分析结果形成最终的分析结果。对于藏文语料而言,尤其是新闻语料中句子长度大于20个词的比例高达70%以上,句子中只用楔形符号表示陈述句、疑问句、感叹句、祈使句、反问句、停顿和分句等的末尾标点符号。另外,藏文句子中连词除了常用的关联词之外,很多自由和不自由虚词也具有连词的语法功能,甚至长达五六十个词语的句子中分句之间通过虚词连接,句子内部不会出现任何标点符号。这使得藏文复杂句型的分析变得最难处理的问题之一,也是目前和未来一段时间,在藏文信息处理领域急需解决的难题之一。
为解决句法分析中的长句问题,CoNLL-01专门组织完成了英语从句识别的评测任务, 当时最好识别结果的准确率达78.63%[2]。Kim等人使用分治策略来简化英语句法分析的复杂度,应用最大熵的方法对句子进行切分[1]。对汉语长句的分割,Jin等人提出以逗号分为分句之内和分句之间两种情况[3],对逗号进行标注之后,将句子从分句之间的标点处断开。马金山等人提出了一种句子片段切分的思想,根据句子的语法结构[4], 对所有的片段末尾标点进行标注,包括逗号、冒号、分号、句号、问号和叹号等,同时探讨了分句之间的依存关系识别问题,取得了不错的成绩。藏文方面,文献[5]实现了基于最大生成树的依存句法分析方法,文献[6]开发了基于词对依存分类模型的半自动句法标注工具软件,构建了1.1万句藏文依存句法树库,目前还未见到藏文复杂长句研究句法分析结果。
本文结合藏文长句中复合句的结构特征,提出基于分句的藏文复合句分析方法,先根据句子的文法结构,对标点进行脚色标注,划分分句类型;然后若句子是复合句则对每个分句独立进行依存句法分析,最后将每个分句的依存树进行合并,完成整个句子的依存分析。经实验,本文的分析器对分析藏文复合句的依存句法树表现出了更好的性能。
2 藏文复合句型
由两个或两个以上结构独立的单句形式构成复合句,复句中每个语法结构独立的成分为单句,藏文复句中每个分句之间通过连词进行连接,表示分句间不同类型的语义关系,与其他语种不同,藏文连词包括虚词和关联词两种类型[7],分句间的虚词一般出现在前一个分句的最后一个音节处,而关联词却根据复合句的类型,可分别在前后分句的末尾或开头部位出现。依据藏文复合句中分句之间出现连词的不同而呈现语义关系,藏文复合句可分为以下几类(表1)。

表1 藏文复合句类型及相关连词
3 藏文复合句的自动标注
3.1 分句划分方案

(1) 完整分句结构: 分句是语法结构完整的片段,分句之间只有语义上的联系,在句法结构上没有联系,标识的方法是将片段末尾标点的词性标注为wp1,例如:

(2) 无主语结构。分句中主语被省略或者位于前面的分句中。将该结构末尾的标点标识为wp2,例如:

(3) 无宾语结构。片段的谓语是及物动词,但是谓语和宾语之间被标点间隔,将该结构末尾的标点标识为/wp3,例如:




图1 完整分句结构实例的依存句法树
3.2 判别式模型
现有许多机器学习方法都可以用于分句类型的识别,如支持向量机(SVM),条件随机场(CRF),神经网络等。由于最大熵模型非常成熟,可以采用开源的最大熵训练工具包来训练,因此本文选择最大熵模型来解决藏文分句的自动识别问题。
如果将一个复合句看作分句的序列,则将分句识别问题视为将复合句划分为子句的随机过程。建立随机过程的联合概率模型p,p∈P,输出值集合Y={wp1,wp2,wp3,wp4}, y∈Y,其中y是片段的类别划分结果,在这个随机过程中,Y受到句子中上下文信息x的影响,上下文集合x∈X,其中x表示此序列中所有可能的上下文特征组合。同时,从训练语料中获得N个样本的集合,S={(x1,y1), (x2,y2), (x3,y3),…,(xn,yn)},其中(x1,y1)是观察到的一个事件,那么可以根据训练样本定义一个事件空间X×Y,对于句子中分句的识别问题,事件信息特征是一个二值函数f: X×Y→(0,1)。对于一个特征f(x0,y0),定义其特征函数如式(1)所示。
对每一个特征f(x,y),其联合概率分布模型p的熵函数如式(2)所示。
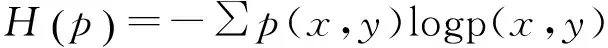
(2)
最大熵模型如式(3)所示。
其中C为满足约束条件的模型集合,P*的具体统计推断形式,即条件熵为[9]式(4)。
(4)
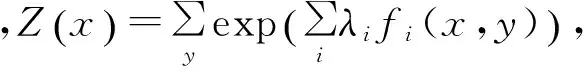
3.3 特征模板
考虑到分句的准确识别问题,本文仅对句子中存在楔形符的复合句做了标注。按照上节给定的四种分类标准,标注分句末尾楔形符号的角色,识别其类型后,进行分句依存句法分析,这样识别分句结构类型,就成了文本分类问题。为此根据藏语分句的独特单词结构和影响分句类型的各种因素,定义了藏语分句识别的特征模板,包括单词词形、词性、长度和楔形符号等特征空间,如表2所示。
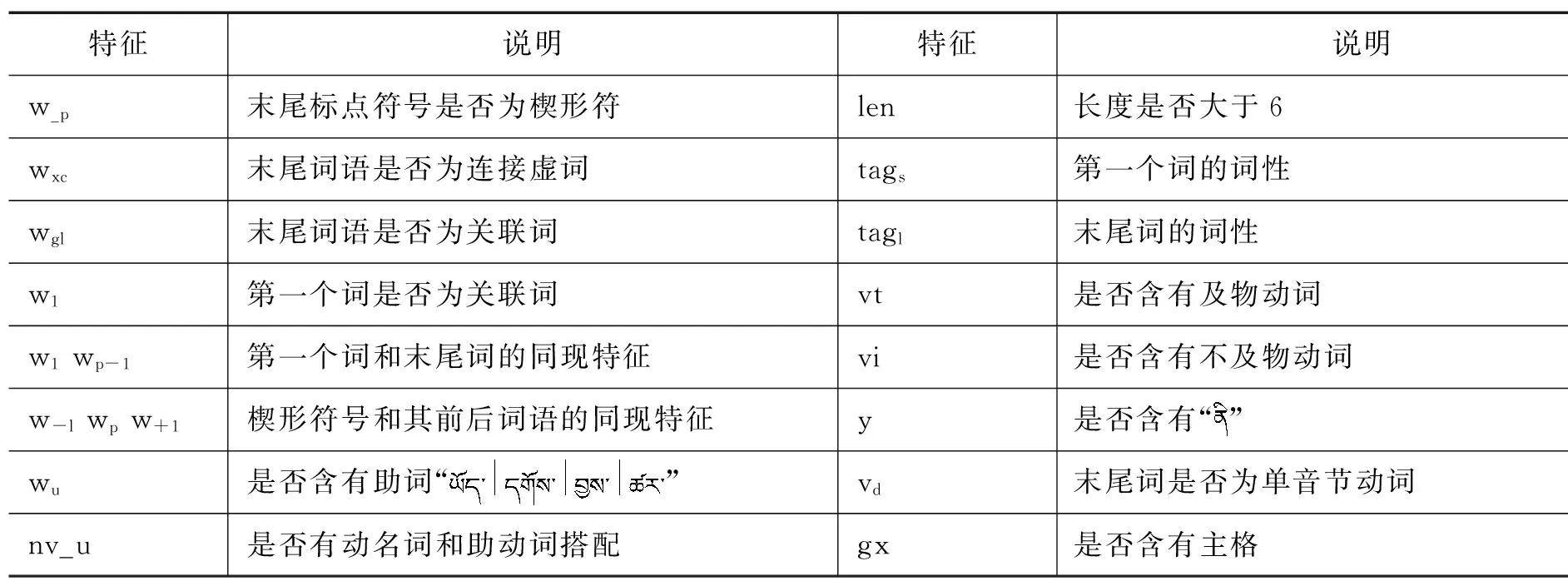
表2 分句类型识别的上下文特征
当特征函数f(x,y)取分句中抽取的特定值时,则改模板被实例化,得到具体特征。当模板的取值确定后就可以产生一个特征,这个特征可以表示为二值函数,如式(5)所示。
用最大熵原理对特征进行参数估计后,可求得基于最大熵的模型,即完成了每个特征的参数估值任务,本文使用了张乐的最大熵工具包。
4 复合句依存分析
对完整复合句的识别结果中,分句楔形分隔符号的类型标识只有wp1、wp2和wp3,而不是完整复合句的标识中会出现wp4,前者中分句为依存句法分析的基本单元,后者将以整句为句法分析单元,在此不予考虑。分句在语法上是独立的,即只有一个核心词同其它分句产生联系,故对于分句本文使用已有的感知机依存句法分析器进行分析[5],之后为得到整句的依存分析结果,还需要将分句的分析结果进行合并。表3给出了分句间的依存关系。
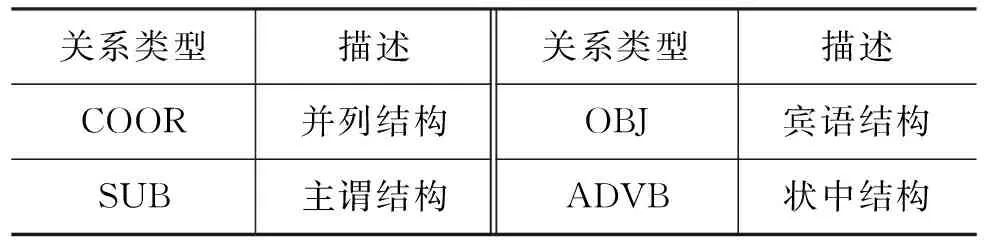
表3 分句间的依存关系类型
虽然分句的分析结果中只有一个中心词,分句间的依存关系像是中心词之间的关系,是词对间关系的分类问题,可以采用已有的词对依存分类模型[6]解决这一问题,但实际上,分句间的依存关系需要确定两棵依存树之间的支配关系,为此本文引入了自底向上的CYK算法,只用方阵主对角线以下元素记录搜索跨度范围内的数据,寻找分句为单位的最佳依存树[10-11],分句整合方法见算法1所示。

算法1 藏文分句合并算法1:输入:分句独立分析后的复合句y2:for(i,j)Í(1,|Y|)按照分句拓扑顺序do //分句个数须大于13: bufφ4: formi..j按照当前分句跨度的拓扑顺序do5: forl∈V[i,m]&&r∈V[m+1,j]do //二分推导6: DERIV(l,r)左推导写入buf7: DERIV(r,l)右推导写入buf8: V[i,j]buf中取前K个推导9:输出:最佳推导结果V[1,|Y|]10: functionDERIV(p,c)11: dp∪c∪{(p.root,c.root)}//生成新的推导12: d.evlEVAL(d) //权重计算函数13:returnd
算法1中,V[i,j]包含分句跨度(i,j)的句法分析结果,跨度的取值为在1和|Y|(分句个数)之间,这时将对整个跨度依顺序二分为左右子跨度的组合,并抽取左右子跨度组合推导生成的依存分支,依据推导分支的权重,生成跨度范围内的K个最佳分值推导树。函数EVAL(d) 计算分句间以中心词为首的所有特征向量的权重之和,其相关的特征模板等在此不再赘述[5]。
5 实验
该实验使用的数据是青海师范大学藏文信息研究中心构建的藏文依存树库TDTreebank V1.1[6],树库数据侧重于日常用语和政府文献,共有1.1万个藏文句法树,每条句子的平均长度为17个藏文词。实验中,以TDTreebank V1.1中藏文句法树对应的词性标注语句1.1万个句子作为训练数据,另构建了300个藏文复合句作为测试集。
5.1 分句类型标注
本文第一个实验是识别每一个候选分句末尾符号的类别,即标注片段末尾的标点符号类型。识别时,根据最大熵训练工具包训练得到的模型和表2所列每个特征模板,得出每一个分句标注类型的概率,取概率最大为分句的类型标记。四类标点的标注结果如表4所示。
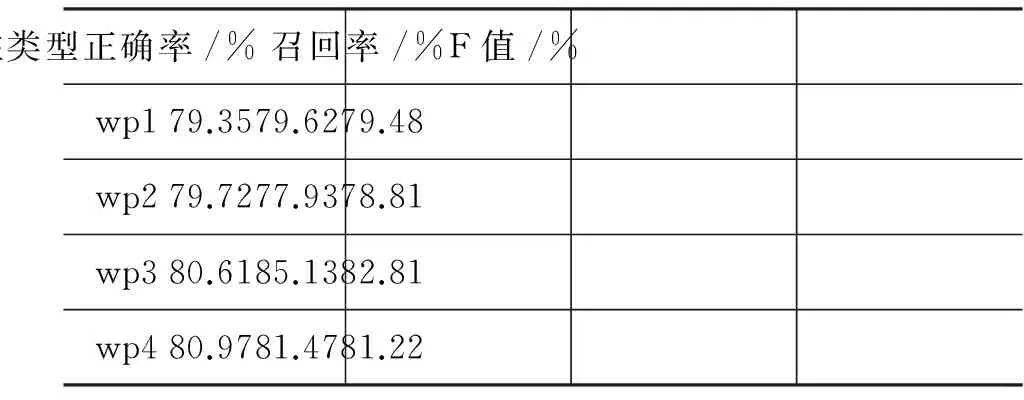
表4 分句类型的识别结果
从表4的结果中,分句识别和标注的F值还算比较理想,其主要原因是本文只标注复合句中用藏文楔形符号分隔的分句。
5.2 整句依存分析
复合句中分句间的依存关系确定后,得到了整句的依存句法分析结果,藏文依存句法分析使用核心词正确率、依存关系正确率和整句完全匹配正确率三个指标对结果进行评价,本文得到的结果如表5所示。

表5 整句的依存分析结果
表中第二行是未对句子进行分句划分,对整句直接进行依存分析的结果;第三行是按照本文所描述基于分句的依存句法分析所得到的结果。通过降低依存句法分析的复杂度,300条复合句中依存关系的正确率得到了明显的提高,达5.07个百分点。
6 结语
本文借用复杂长句的分治策略方法,初步尝试了藏文复合句的依存句法分析研究,首先对结构特征明显的藏文复合句进行了分句划分和角色标注处理,然后对简化后的独立分句进行分析,最后合并独立分句的分析结果,从而简化,并降低了分析藏文长句的复杂度,解决了带楔形符号的藏文复合句的依存分析问题。这对进一步处理藏文从句的自动识别,以及基于从句的整句依存分析等研究具有重要意义。
[1] Kim SD, Zhang BT, Kim YT. Reducing parsing complexity by intra- sentence segmentation based on maximum entropy[C]//Proceedings of EMNLP/VLC-2000, Hong Kong, 2000: 64-171.
[2] Sang Eftk, Jean H. Introduction to the CoNLL-2001 shared task: clause identification [C]//Proceedings of the CoNLL-200, 2001: 53-57.
[3] Jin M, Mi-Youngk, Kim D, et al. Segmentation of Chinese long sentences using commas[C]//Proceedings of the 3rd ACL S IGHAN Workshop, Spain: Association for Computational Linguistics, 2004: 1-8.
[4] 马金山,李生. 基于统计方法的汉语依存句法分析研究[D]. 哈尔滨工业大学博士学位论文,2007.
[5] 华却才让,赵海兴.基于判别式藏语依存句法分析[J].计算机工程.2013,39(4):300-304.
[6] 华却才让,姜文斌,赵海兴,刘群. 基于词对依存分类的藏语树库半自动构建研究[J].中文信息学报. 2013.9.27(5): 162-172.
[7] 吉太加. 藏语句法研究[M].中国藏学出版社.2013.
[8] 格桑居冕. 实用藏文语法[M]. 成都: 四川民族出版社,1987.
[9] 李素建,刘群,张志勇,程学旗.语言信息处理技术中的最大熵模型方法[J].计算机科学.2002,29(7):108-110.
[10] W. Jiang, Qun Liu. Dependency parsing and projection based on word pair classification[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL). Uppsala, Sweden 2010: 12-20.
[11] R. McDonald. Discriminative learning and spanning tree algorithms for dependency parsing[D]. Ph.D. thesis, University of Pennsylvania, 2006.
Dependency Parsing of Tibetan Compound Sentence
Huaquecairang,ZHAO Haixing
(Key Laboratory of Tibetan Information Processing, Ministry of Education, Qinghai Normal University, Xining, Qinghai 810008, China)
This paper proposes a discriminative method of identifying the clause to solve the performance decrease caused by Tibetan compound sentence. In this method, the complex sentence is first divided into different syntactic analysis units according to the inherent features of conjunctions. Then each clause is parsed independently. Finally the whole dependency tree is generated by merging the parse of each clause. Experimental results show that the method could decrease the complexity of parsing, and boost the parsing accuracy up to 88.72%.
syntactic analysis; dependency parsing; Tibetan sub-clause; Tibetan compound sentence

华却才让(1976—),副教授,博士,主要研究领域为藏语词法分析、句法分析和机器翻译。E-mail:cairanghuaque@aliyun.com赵海兴(1969—),博士,教授,博士生导师,主要研究领域为图理论、复杂网络、理论计算机科学和自然语言处理。E-mail:363422953@qq.com
1003-0077(2016)06-0224-06
2016-09-27 定稿日期: 2016-10-20
国家自然科学基金(61363055);教育部“春晖计划”合作科研项目(Z2012102)
TP391
A
