配网工程项目词库创建及分词探索
2016-05-30张文露谭骞章光东
张文露 谭骞 章光东

摘 要:随着国网公司信息系统的完善和业务数据的积累,公司各业务部门开展了数据探索和分析,以支撑逐年增加投资、扩大规模的配网工程项目建设工作。但是由于各省市公司的管理模式不同,导致配网工程项目相关数据一致性较差,可用于支撑分析的特征值较少。因此论文基于文本挖掘方法创建符合国网公司特性的工程词库,弥补过往历史数据的缺失和不完整,使历史文本数据能够支撑后续数据分析工作。
关键词:文本挖掘;配网工程;词库创建
中图分类号:TP391 文献标识码:A 文章编号:1006-8937(2016)32-0072-02
1 研究背景
配网工程项目具有项目类型众多、物资使用种类集中的特点,随着国网信息化系统建设的逐渐完善,出现联合数据分析的需求,然而由于各网省公司项目管理水平的差异,配网项目在各网省公司的管理模式不同。
部分省公司按照区县对配网项目进行打包管理,部分省公司则按照单体项目进行管理。但是从整体来看,针对配网工程项目的管理是松散的,直接导致了配网工程项目的可用特征较少,无法配合其他数据,以工程项目为对象进行联合数据分析。但是配网工程项目的命名包含一定规律,可以通过文本挖掘的方法从工程项目名称中提取有效的项目属性特征,以描述工程建设性质和建设内容。然而目前较为成熟的分词函数都依赖于对应的专业词库,即基于一本专业“词典”自动完成名词的分解,所以提取配网工程项目特征标签的首要任务就是构建专业的配网电网词库,以支持后期分词函数的应用,完成对配网工程项目名称的分词。
2 词库构建原理
传统的词典创建方法通常认定出现频数超过某个阈值的文本片段即为词典的组成部分,然而并没有考虑到该文本片段是否仅为一个词还是由多个词构成的词组,因此为了克服传统方法的缺点,需要综合分析自然语言的内部凝聚程度和外部自由运用程度两个方面去构建配网专业词库。其中词语的内部凝聚程度指的是一个文本片段成词的概率,凝聚程度越大说明该文本片段越可能成为一个词即进入配网专业词库,如“维修工程”出现的概率为“维修工”出现概率的25倍,这说明“维修工程”更可能是一个具有实际意义的配网专业词汇。
外部自由运用度指的是定义该词语片段与左邻、右邻词语之间的相关程度,计算该文本的左邻字和右邻字所能够提供的信息熵,信息熵越大,说明该文本可提供的信息量越大,该文本的左右邻字越丰富,即可以更加自由地运用于各个语言环境中,如“台区”前后可以添加各类文本片段成词,然而“变电台区”、“新增台区”、“台区布点”等词却仅能够以单独形态成词,即更有可能成为真正有区分度的有实际意义的配网专业词汇。
用p(x)代表词语的凝聚程度,P(AB)代表该文本片段在整个文本中出现的概率,P(A),P(B)代表子文本片段在整个文本中出现的概率,凝聚度公式如下:
如果仅从内部凝聚程度考虑,有可能出现找到部分词的情况,该词内部凝聚程度很高,但并不包含完整的文本片段,如变电、开闭等。同样,如果仅从外部自由程度去考虑,很有可能提取到相当多的连接字,该连接字可以很大程度上自由地运用于文本环境中,如的、了等。因此模型首先需要对输入文本进行预处理,将一列项目名称整合成一段紧密相连的文本片段、去掉字母、数字和特殊符号,将预处理后的文本按从前至后和从后至前两个方向进行单字切割,分别生成单字出现字频表。
然后计算并逐步检验可能成词的文本片段的内部凝聚程度和外部自由运用程度两个指标,结合实际业务需求,在程序中设定合适的内部凝聚度阈值和左右信息熵阈值,按照业务规则最终筛选得到既准确又有现实意义的配网电网专业词库字典,比如针对项目名称中各省地市公司的地理位置词语,由于缺乏能够揭示工程建设性质和建设内容的实际意义,所以即便可以满足内部凝聚程度和外部自由运用程度两个指标的要求,也不能作为最终的词语进入配网电网专业词典。
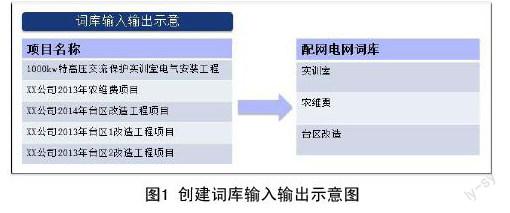
运用R语言实现以上步骤,该阶段的输入数据是一列包含配网电网特征关键词的项目名称,输出是一列可能成词的文本即配网电网专业词库字典,该输入输出的数量并非一一对应的关系,如图1所示。
3 分词原理
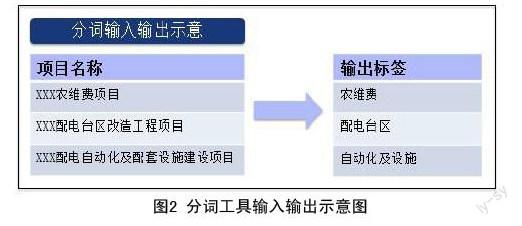
运用R语言中的结巴(jiebaR)工具包,利用其支持的最大概率法(Maximum Probability),隐式马尔科夫模型(Hidden Markov Model),索引模型(Query Segment),混合模型(Mix Segment)共四种分词模式的功能,首先引入并应用已经创建完成的配网专业词典,替换掉结巴(jiebaR)工具包中的默认词典,接下来读取项目名称数据集进行分词。该阶段的输入数据是一列包含配网电网特征关键词的文本,输出是对应项目名称的一系列标签,如图2所示。
基于已创建的配网专业词典,可以将复杂的项目名称拆分成为几个关键词的堆叠,并且根据需求,配置个性化选择规则,例如选择几个关键词中出现频率最高的关键词作为标签形成初步标签。由于分词会输出较多标签,为了防止标签冗杂,工程特征指示不清晰,本文通过聚类分析发现并聚合具有相似物资领用特征的项目群,随后结合业务理解对这些项目群进行命名,即完成了標签的合并和删减。此过程使用K-Means聚类方法作为无监督式的机器学习方法,在未知样本类别的情况下,通过计算样本彼此间的欧式距离或余弦距离来估计样本所属类别。
K-Means是一种自下而上的聚类算法,是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离相近的若干对象组成的,因此希望最终得到紧凑的簇。该算法接受参数k,首先将事先输入的n个数据对象随机分成k个簇,为使同一类中的对象相似程度较高,不同类中的对象相似程度较低。具体计算步骤如下:
①随机选定k个中心作为起点;
②将每个数据点归类到离它最近的中心点所代表的簇中;
④重复步骤②~③,直到满足收敛要求,即该k个中心点不再变化。
结合业务理解给定k=44,即给定44个具有不同项目工程建设内容和建设性质的项目群,通过聚类分析的方法,输入对应于各个项目名称的不同物料小类的领料数据和下达预算金额,最终输出得到44个项目群的序号标签,随后结合业务理解,根据项目工程实际特征,对这44个项目群分别进行命名即分别贴标签,对贴好的标签进行人工调整,保留其中能用自然语言表达的并且具有现实意义的标签名称,作为提取构建的新的工程项目特征,完成配网工程项目特征属性的提取和标记,使得即便不同省份对配网项目的管理水平不一致,也可以使用同一维度标尺进行衡量,便于后续与其他数据联合开展关联分析。
4 研究结论
首先通过计算自然语言的内部凝聚程度和外部自由运用程度两个指标可以帮助从冗杂的文本片段中筛选出符合阈值筛选条件的词语,创建出符合国网公司自身业务特点的专业配网电网词典,接下来结合文本挖掘工具即可较为简单地根据个性化选择规则对项目名称实现匹配、分词,提取配网工程项目的特征值,以描述项目特征、建设内容、工程属性等。另一方面,通过聚类方法可以减少提取特征值的数量,使具有相同工程建设性质和建设内容的项目合并成一个项目群,并基于业务理解为44个项目群分别命名,因此该分词结果更为标准清晰,同时也简化了分类维度,有利于支撑后续与其他数据之间的联合分析。
参考文献:
[1] 邓建,李夕兵,古德生.结构可靠性分析的多项式数值逼近法[J].计算力 学学报,2002(11):26-30.
[2] 李庆阳,王能超,李大义.数值分析[M].武汉:华中工学院出版社,1982.
[3] 王淑云,方保镕,王如云.数值分析方法[M].南京:河海大学出版社,1996.
[4] I.Babuska,W.C.Rheinbold.Error estimates of adaptive finite element
computations[J].SLAM Journal of Numerical Analysis,1978(4):
736-737.
[5] B.Moller,M.Beer,W.Graf,etal.Fuzzy finite element method and its
application[M].Trends in computational structural mechanics,2001:
529-538.
[6] 劉信恩,肖世富,莫军.用于不确定性分析的高斯过程响应面模型的设 计点选择方法[J].计算机辅助工程,2011,20(1):101-105.
