社会网络中弱关系团队形成问题研究*
2016-05-28孙焕良富珊珊刘俊岭许鸿斐沈阳建筑大学信息与控制工程学院沈阳068东北大学信息科学与工程学院沈阳0006
孙焕良,富珊珊,刘俊岭,,于 戈,许鸿斐.沈阳建筑大学 信息与控制工程学院,沈阳 068.东北大学 信息科学与工程学院,沈阳 0006
社会网络中弱关系团队形成问题研究*
孙焕良1+,富珊珊1,刘俊岭1,2,于戈2,许鸿斐2
1.沈阳建筑大学 信息与控制工程学院,沈阳 110168
2.东北大学 信息科学与工程学院,沈阳 110006
SUN Huanliang,FU Shanshan,LIU Junling,et al.Team formation with weak ties in social networks.Journal of Frontiers of Computer Science and Technology,2016,10(6):773-785.
摘要:随着在线社会网络的迅速发展,社会网络的团队形成问题逐渐成为研究热点。现有的社会网络中团队形成问题目标是寻找一个成员间沟通代价最小的团队。然而,实际应用中团队成员间的不紧密关系使得团队的观点多样化、多角度、无偏见,可以广泛应用于形成专家评审团队、大众评审团等。基于此需求,将社会学的弱关系概念引入团队形成问题中,提出了一种社会网络中弱关系团队形成问题。该问题旨在寻找成员间为弱关系,同时满足技能、经验值要求的一个团队,为NP-hard问题。提出了3类算法解决该问题,分别为贪心算法、精确算法、α-近似算法,每类算法有各自的特点与适用范围。利用ACM和DBLP两类真实的数据集进行实验,综合评估了各类算法的效率与求解质量,证明了提出算法的有效性。
关键词:社会网络;团队形成;弱关系;贪心算法;精确算法;近似算法
ISSN 1673-9418CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(06)-0773-13
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
1 引言
随着在线社交网络平台的兴起,大量用户通过互加好友或相互关注等方式,在平台中建立起社交关系,形成了具有大规模结点的在线社会网络。基于社会网络,研究人员开展了社区发现[1-2]、影响力分析[3-4]、团队形成等研究工作[5-10]。
社会网络中的团队形成问题是找出一个能够满足给定任务需求且关系紧密的一组专家[5-9]。现有的社会网络中团队形成问题均强调专家间的关系紧密性,紧密性可降低成员间的沟通代价,有利于任务的顺利完成。然而,实际应用中存在大量要求成员间为“不紧密”关系的需求,这种成员间的“不紧密”关系称为弱关系[11]。美国社会学家Granovetter指出了弱关系具有许多优点[11],包括弱关系中的成员可以多角度看问题,无偏见性,以及弱关系具有高效能的传播效率。弱关系的这些优点可以满足某些应用领域团队形成需求。例如,在项目评审中,如果评审专家整体具有高经验值的同时,相互间具有弱关系,可以使得评审结果无偏见性;另外,交易纠纷解决与电视节目评选广泛采用大众评审团机制,如“淘宝网”采用大众评审来解决一些买卖双方的问题,若评审团中成员间具有弱关系,则有利于避免评判结果的趋同性,从而保证评判结果的公平性。在传播效率方面,如社交平台上的广告投放,将有限的资源投放在高影响力弱关系的结点上,可以避免信息在关系紧密结点上的局部传播,使得信息传播更加广泛,从而有效提升广告投放效果。
基于以上应用需求,本文提出了一种社会网络中弱关系团队形成问题。该问题旨在寻找一组既能满足任务技能需求又具有弱关系约束的整体经验值最高的团队。弱关系可以采用网络中的结点间跳数或边权和来度量,技能由关键字表示,技能的经验值为关键字上的分值。
运行实例1图1为一个社会网络示例图,图中结点代表评审专家,边表示专家间关系。每个结点包括表示技能的关键字及经验值,如
Fig.1 An example of expert social network图1 专家社会网络示例
对于实例1,可求得一组满足任务需求的弱关系团队T1={v1,v2,v5,v7,v9},其中v1、v7完成子任务(a1,2),v2完成子任务(a2,1),而v5、v9则完成子任务(a3,2),团队T1成员的总经验值为38。还可求得一组弱关系团队为T2={v1,v3,v5,v7,v9},子任务(a1,2)同样由v1、v7完成,v5完成子任务(a2,1),子任务(a3,2)则由v3、v9完成,团队T2中成员总经验值为42。除了T1、T2外,还有其他团队满足实例1要求,并未列出。然而在所有满足任务需求的弱关系团队中,T2的总经验值最高,则T2是弱关系团队查询的一个结果。
弱关系团队查询需要遍历所有成员的组合进行成员间弱关系约束检查,同时还需计算团队总经验值。当团队规模较大时,如大众评审团可达到几百人,搜索过程代价较高,该问题为NP-hard问题。因此,如何快速高效地搜索到社会网络中高质量的弱关系团队具有挑战性。基于上述目标,本文提出3类算法实现弱关系团队查询,分别为贪心算法、精确算法、α-近似算法。其中,贪心算法具有最高的搜索效率;精确算法可获得精确解,适用于小规模的应用需求;α-近似算法可以在保证算法运行效率的同时求得满足α近似率的解。
综上所述,本文的主要贡献如下:
(1)将社会学中弱关系概念引入到团队形成问题中,提出了弱关系团队形成问题,并给出了相关定义及度量方法,证明了该问题为NP-hard问题。
(2)提出了3类算法求解该弱关系团队形成问题,分别为贪心算法、精确算法和α-近似算法。
(3)实验采用真实的数据集测试了不同参数下算法的运行效率,并对查询结果的质量和团队影响力进行了分析。
2 相关工作
传统的团队形成问题只需找出能够提供所需技能的成员集合,不考虑成员间的沟通代价,团队查询为集合数据上的组合优化问题[12-13]。这类问题通常采用模拟退火[12]、分支限界[13]等策略进行求解。
伴随着社交网络的兴起,基于社交网络的团队形成问题得到广泛研究。为了使团队各成员间合作高效,团队形成问题更倾向于寻找一组联系紧密的专家团队。现有的研究工作分为以下3类:不同沟通代价度量的团队形成问题[5-7],考虑团队内各成员工作量平衡的团队形成问题[7-8]、人员花费与沟通花费相结合的双目标问题[9]。
在沟通代价度量方面,Lappas等人[5]首次在团队形成问题中考虑成员间的社会关系,提出了两种沟通代价评价方法——直径和最小生成树评价方法。Kargar等人[6]提出了一种在社会网络中考虑团队领导者的top-k专家团队发现问题,并提出了距离之和与领导者距离两种沟通代价评价方法。Datta等人[7]则提出了新的沟通代价评价方法,即瓶颈代价评价方法。
在考虑团队内各成员工作量平衡关系方面,文献[8]同时考虑了成员间沟通成本及团队成员的工作量。Datta等人[7]提出了能力约束的概念,即为每个专家限定了最大能力范围,分配给各专家的任务不能超过该约束。Kargar等人[9]在原有的团队形成问题中加入成员花费,将该问题转化为同时考虑成员花费与沟通花费的双目标求解问题。
以上团队形成问题均以获得紧密关系团队成员为目标,而本文提出弱关系团队形成问题中希望成员间具有弱关系。因此,现有的团队形成问题研究方法难以适用于本问题的研究。
社会学中的弱关系理论指出社会网络中大部分关系属于弱关系,并提出弱关系虽然不如强关系坚固,却具有低成本和高效能的传播效率,弱关系间的成员看法具有多样性[11]。人类学家Dunbar于2009年提出著名的邓巴数字[14],即150定律。根据该定律,在每个人能够维持的150个成员的社交网络中,强关系约30个,弱关系约120个。本文将社会学中的弱关系理论引入团队形成问题中,并将150定律作为弱关系参数设置的理论基础。
与弱关系相关的另一类相关工作是图结构中的独立集问题。图结构中的独立集问题是指图中两两互不相邻的结点构成的集合,而图中包含结点最多的独立集称为最大独立集[15]。最大独立集问题是图论中经典的组合优化问题,为高效地解决该问题,采用启发式算法[16]或近似算法[17]来提高运行效率。独立子集中的结点只要求结点间不直接相连,而本文所定义的弱关系来源于社会学相关理论,定义弱关系为大于某一跳数或边权和大于某个给定值。
3 问题定义
给定一个无向带权图G=(V,E),其中V为结点集,E⊆V×V是图G的边集。本文结点集中的一个结点代表一名专家,边表示两个专家vi与vj具有合作关系,边上的权值表示专家vi与vj间关系强弱,边权值越大,vi与vj关系越弱。A={a1,a2,…,an},表示包含n个技能的集合。每个结点vi∈V表示为{
定义1(技能的结点候选集)对于任意一个技能ai∈A,S(ai)={v|ai∈Q(v)}表示所有包含技能ai的候选集;而对于子集T⊆V,如果T拥有技能ai,则在T中至少存在一个结点v,使得ai∈Q(v)。
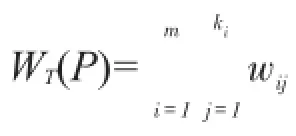
定义3(弱关系约束)给定图G=(V,E)及弱关系约束h。若存在子集T⊆V,对于T中任意两个结点v、v′都有dist(v,v')≥h,则称T满足弱关系约束h。其中,dist()是社会网络上的距离函数,其返回值为结点间的跳数或结点间最短路径上边权和。
本文根据邓巴数字中弱关系与强关系的比例[14],结合具体数据集对弱关系约束参数h进行设定,详见第5章实验结果与分析部分。
问题1(弱关系团队发现问题)给定图G=(V,E)和任务约束P,弱关系约束h。弱关系团队发现就是从图G中找到子集T⊆V,满足P与h约束,并且使得团队的总经验值WT(P)最大。
定理1社会网络中的弱关系团队发现问题是一个NP-hard问题。
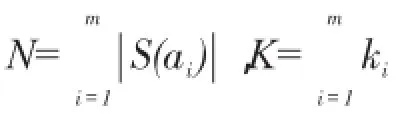
4 查询处理算法
下面研究弱关系团队形成问题查询处理算法。第4.1节介绍处理该问题的贪心算法;第4.2节提出两种精确算法;第4.3节介绍一种α-近似算法。
本文所提出的各种算法均需要进行弱关系与关键字约束检查,为方便表达,将这一检查过程提取出一个过程表示,如过程1。给定一个当前未满足成员数要求的弱关系团队T及当前需要检查的候选元素C[i],判断C[i]是否加入T,需要检查C[i]的关键字是否为对应未完成任务,并且检查C[i]与T中现有元素是否为弱关系。步骤1~2,判断T中是否已找到满足子任务C[i].a需求的人数,若已满足人数需求,则返回0;步骤3~5,判断结点C[i].v是否与T中所有结点满足弱关系,若有一个结点不满足弱关系,则返回0;步骤6,若经上述判断,结点C[i].v与T中所有结点均满足弱关系约束,且子任务C[i].a所需人数还未满足,则返回1。
过程1 IsInsert(T,C[i])
1.if|TC[i].a∩S(C[i].a)|≥kC[i].athen
2.return 0;//子任务C[i].a已满足人数需求
3.for j=1 to|T|do
4.if dist(C[i].v,T[j].v)≤h then
5.return0;//结点C[i].v与T[j].v不满足弱关系约束
6.return 1;
进行弱关系团队查询时,需要检查两个结点距离是否大于弱关系约束h。本文将社会网络图中的结点距离进行预计算并存储,当需要检查结点距离时访问预计算结果即可。如果图中有n个结点,则需计算并存储n2结点对距离。根据邓巴定律,一个图中强关系只占20%,因此本文只保存距离小于弱关系约束h的关系对,即强关系的结点对,对比将所有结点间关系进行存储的数据量大幅度减少。将这些关系对采用倒排索引存储,当需要检查某一对结点是否为弱关系时,则访问该索引。
4.1贪心算法
贪心算法是解决NP-hard问题的常用方法,本文首先采用贪心算法进行弱关系团队查询。弱关系团队形成问题的目标是最大化成员分数,因此优先搜索高分值的关键字倾向得到较优解。预先建立关键字候选元素排序表C,C中各关键字候选元素按分值从大到小排序,贪心算法即从排序表中分值最大的元素开始依次向后搜索,直至求得满足弱关系和关键字约束的团队为止。
令候选集总数为N,团队人数为K,算法中第一个元素最多需要选择N次,后面K-1个元素最多进行N-1次判断,因此Greedy算法总的时间复杂度为O(N2)。
4.2精确算法
4.2.1回溯搜索算法
回溯搜索算法基本思想为首先利用4.1节提出的贪心算法求得一个初始解T,然后利用初始解T构造最优解搜索空间树,并在该搜索空间树上将T中元素按经验值从小到大进行逐一回溯替换。当求得一组解优于当前解时,再对最优解搜索空间树进行更新,直到将解空间内所有结点替换结束为止。
若对整个解空间树进行回溯,则会造成许多无效搜索,本文结合两种优化搜索策略以提高回溯法搜索效率。第一种策略利用弱关系和关键字约束剪去不满足约束的子树;第二个策略是确定最优团队中每个元素在搜索列表中的下界位置,从而缩减搜索空间。定理2给出最优弱关系团队中元素的下界位置求解方法。
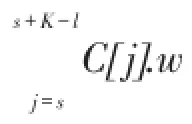
证明略。
由定理2可求得最优弱关系团队中每个元素的下界位置,将每个元素在C中下界位置存入下界列表Lower,Lower[i](1≤i≤K)表示最优团队中第i个元素在C中的下界位置。如实例1中,由Greedy算法求得初始解T总经验值为38,根据定理2可求得Lower= {2,3,7,10,12}。假设在回溯搜索树中,结点i代表元素C[i],若该结点作为团队中第j个元素进行扩展时,其所代表的元素在C中位置i已超过Lower[j],则可断定以结点i为根的子树中不含有最优解,因此可将该子树剪去。
算法1描述了回溯搜索算法细节。步骤1调用算法1求得弱关系团队T;步骤3~6选定T中需要替换的结点T[i],对T[i]以下所有元素进行替换;步骤4 将C[T[i].s+1]作为T[i]的替换元素,并用s记录该元素位置;步骤6调用过程2对T中T[i]及以后元素进行替换。
如过程2所示,步骤1将T中当前要替换的元素位置赋给j;步骤2~5如果当前加入元素C[s]在C中位置未超过Lower[j],调用过程1判断C[s]结点是否与T满足弱关系及关键字约束,若满足将C[s]加入T,并将C[s+1]当作T[j+1]元素的替换元素进行判断,否则将C[s+1]继续作为元素T[j]的替换元素进行判断;步骤6~11,若当前位置s超过Lower[j],则说明继续对T中第j个元素进行替换已找不到最优解,此时若j未超过需要替换的i,则从T中第j-1个元素开始替换,否则递归结束;步骤12~17,若经过替换获得一组满足要求团队T,如果T优于Tbest,则用T替换Tbest,并更新Lower。
算法1 ExactBB
输出:最优弱关系团队Tbest。

过程2 Replace(T,s,i)

回溯搜索算法虽然利用Greedy算法对解空间进行了缩减,同时利用缩减策略降低了查询代价,但在解空间内仍需替换大量的结点,导致运行效率低。在搜索空间内的组合替换仍然是NP-hard问题。因此下面将提出一种基于动态规划思想的精确算法。
4.2.2动态规划搜索算法
本文所提出的团队形成问题,如不考虑弱关系约束,本质上是求解集合中的一个分值和最高的子集,则问题转换为0-1背包问题,可以考虑采用0-1背包问题求解方法求解。但是加入弱关系约束后不满足最优子结构性质,则0-1背包问题的方法不再适用。然而可以保存所有满足关键字与弱关系约束的解,每一个解为一个背包,这样问题即转换为多维背包问题。因此,可以采用求解多维背包问题的动态规划思想,保留多个满足弱关系的候选解,利用候选解的关系设计剪枝条件,从而以空间换时间提高搜索效率。基于此思想,提出了基于动态规划搜索的精确算法。
算法首先创建一个二维数组g[K][S]来存储候选可行解,二维数组的行表示背包的容量,即团队成员数,列表示背包的一个解,并按解的优劣排序。此二维数组g[K][S]随新元素的加入动态更新,g[i][j]表示当前i个成员团队第j个最优解。设g[i][j].w为候选解g[i][j]总经验值。
求解过程访问候选元素,当前加入元素C[s]时,更新g的第i行,且该行的有序解是由以下3种情况的有序解合并所得:
(1)未加入C[s]时,第i行中的解g[i][j];
(2)当C[s]与g[i-1][j]满足弱关系和关键字约束时,在g[i-1][j]基础上加入C[s],所得解为g[i-1][j]+ C[s];
(3)当C[s]与g[i][j]中元素c拥有相同结点时,若g[i][j]中技能C[s].a未达到成员数要求,则以C[s]替换c,替换后所得解用R(C[s],c)表示。
当候选元素表C中所有元素访问结束后,g[K][1]一定为最优弱关系团队。定理3给出不需访问C中所有元素即可判断g[K][1]是否为最优解的条件。
定理3设已求得一组弱关系团队g[K][1],当前要加入元素分值为w,若对任意i(0≤i 证明假设g[K][1]不是最优解,则有g[K-1][j].w+ w>g[K][1].w(1≤j≤S)。又由对于∀i(0≤i 定理3说明将当前各行的最优解与加入元素C [s]进行逐一比较,若加入C[s]后不优于解g[K][1],则g[K][1]为最优解,提前终止对C中元素的访问。 当团队所需人数增多时,解空间所要保存的弱关系组合随之增多,空间需求量增大,运行效率降低。然而在所保存的解中,有大量的中间结果不为最优解的一部分,则可以为每一行求得一个最小值作为g[i][j].w下界,若第i行解小于相应的下界值,则不加入解空间内,从而减少了解的数量。定理4给出了g[i][j].w下界计算方法。 例如,对于实例1,假设团队T中已加入2个元素,当前要加入元素为C[6],则剩余3个元素所能取到的最大值是在不考虑弱关系及关键字约束下,以C[6]开始的连续3个元素,即C[6]、C[7]、C[8],经验值之和为19。又因为有Greedy算法求得弱关系团队经验值为38,所以若C[6]为BT中第3个元素,则团队T中前2个元素之和不能小于19,即LB[2]=19。以此类推,每个子空间都有相应的下界值,可以利用这些下界值提前结束不必要的搜索。 算法2描述了基于动态规划搜索算法。步骤1~4初始化解空间,令g[0][1].w=0,其余候选解分值均设为-1;步骤6~8,每加入一个元素C[i],首先判断当前加入元素的位置i是否超出下界位置Lower[j],若未超出,步骤8调用过程3对各子问题解空间更新;步骤9~12,利用定理4中的条件判断弱关系团队g[K][1]是否为最优解,若为最优解则跳出循环,否则继续对解空间进行更新。 过程3中步骤1初始化堆Heap,用于存储可行解,堆顶元素经验值最大;步骤4~8,将所有可行解存入Heap中;步骤9~12,在满足定理4情况下,首先构造Heap,并将堆顶解Heap[0]存入g[j][i2]中,i2用于记录Heap[0]在g[j]中的存储位置;步骤13,从Heap中移除Heap[0];步骤14,若不满足定理4,则跳出循环。 算法2 ExactDP 输出:最优弱关系团队T。 过程3 SpaceUpdate(j,C[i],S,LB) 算法2假定解空间S可以保存所有的可行解,由于解的数量可能超出空间大小S,本文采用一种动态分配内存的方式增加解空间。在过程3中用i2记录已保存的解的个数,当i2=S时,表示当前解空间大小不足以存储所有解,则将解空间进行扩充,每次扩展sa个空间。 动态规划搜索算法将可行解都保存下来,通过初始解界定可行解最小边界,从而减少了可行解的数量。与回溯法相比,减少了结点的判别与替换次数,运行效率有明显提升。设解空间大小为S,团队人数为K,候选集大小为N,又因为该算法需利用Greedy算法求解进行空间剪枝,所以基于动态规划搜索算法时间复杂度为O(N2+S×K×N)。设在所有人数为K的团队中,同时满足弱关系及关键字约束的团队所占比例为ρ,因为组合问题空间复杂度为O(N!),又因为基于动态规划搜索算法保存了所有满足要求的弱关系组合,所以其空间复杂度为O(ρ×K×N!),当团队查找人数增多,解空间大小急剧增加时,算法求解效率降低,动态规划精确求解算法不再适用。因此,本文提出一种α-近似算法。 4.3α-近似算法 本节提出一种高查询效率的同时可以保证近似率的α-近似算法。该近似算法是在精确的动态规划算法基础上实现的,基本思想是利用较小的解空间只保存满足α近似率的解。 给定参数α与解空间大小,并设定最优解边界值,该边界值可以保证α倍近似率。边界值设置方法为在不考虑成员间弱关系情况下,求得一组满足人数要求和关键字约束的经验值之和最大团队,该团队经验值之和即为最优解边界值。为了充分利用解空间求得满足近似率的解,需要为每个部分解设置边界值使得部分解均可以保证α倍近似率。 如人数i=3时,部分解由C[1]、C[2]、C[3]构成,边界为30。同理,可知C[1]、C[2]、C[3]、C[4]、C[6]构成人数为5的界限为45,由于C[5]的关键字为a2,而实例1中仅需要1个关键字为a2的元素,因此C[5]参与人数为5的边界计算。由此可得各子问题最优解上界值为Bound={11,21,30,38,45}。 算法3给出了近似算法描述,输入近似率α。步骤1,初始化解空间;步骤2~5,在给定解空间K×S内求解子问题,其中K为二维数组的行数,对应团队成员数,S为二维数组的列,对应候选解个数,利用K×S空间保存满足近似率要求的解,即g[i][j].w≥Bound [j]/α(1≤i≤K,1≤j≤S);步骤4,若子问题j的解空间已满,且加入元素C[i]后有可能改变当前解空间,则进行子空间更新计算,反之,则不进行计算;步骤6,若求得一组解,则跳出循环,当前所求解即满足α近似率。 算法3 ApproxDP 输出:弱关系团队T。 定理5 ApproxDP算法所求解为α近似。 该算法仅保存了一部分满足近似率的解进行计算,因此可能求不到解。除了所保存的解外,还有大量满足近似率的解在求解过程中被忽略掉了,因此在求不到解的情况下,可以对被忽略掉的解进行重新计算。处理方法如下:首先在求解过程中记录使得各子空间存满时的元素,同时将各子空间存满时的状态存入文件中,在未求得解情况下,读取文件至解空间g'[K][S],并使用使得各子空间存满时的元素,对所读取的解空间进行组合更新,将未出现在解空间g′中的组合结果存入g[K][S]中,当g[K][S]存储结束后,将g[K][S]作为新的解空间继续进行算法3计算。 α-近似算法时间复杂度为O(S×K×N),其中S为解空间,K为团队人数,N为候选集大小。由于此算法所需空间远小于动态规划精确算法,使得算法的查询效率较高。 本文使用真实数据集对算法运行效率及求解质量进行评估。本文算法使用C++语言实现,并在PC机上进行实验,处理器为Intel CPU P8700 3.00 GHz,主存为4.0 GB,操作系统为Windows 7。本文比较了两种精确算法(ExactBB、ExactDP)以及α-近似算法(ApproxDP)的运行效率,还对贪心算法与ApproxDP近似算法查询结果进行了分析,分别为查询结果质量分析和团队影响力分析。 5.1实验数据 实验采用两类真实数据集对算法进行了评估。第一个数据集为ACM学者合作关系数据集,该数据抓取自ACM Digital Library网站。图中结点代表学者,边表示学者间的合作关系,每个学者都拥有研究领域属性,共有20 000个结点。根据合作关系生成稠密图,共有边数100 233条。另外通过随机删除一部分边生成稀疏图,边数为80 002。根据ACM的命名规则,第一层为研究领域,本文仅按第一层来提取关键字,并将ACM稠密图和稀疏图中专家结点上各关键字分值相加之和作为该结点的总分值,构成两组无关键字约束数据集,两组数据集分别命名为Dataset1和Dataset2。 根据邓巴数字[14]可知,每个人拥有稳定社交网络的人数大约维持在150个左右,其中强联系有30个,弱联系约120个。若推广至整个社会网络,可得社会网络中弱关系约占整个网络的80%,而强关系仅有20%。根据上述社会网络中弱关系与强关系比例,计算得出ACM中稠密图弱关系约束为3。同理,将ACM稀疏图和DBLP图数据中弱关系约束分别设为4和8.942。 5.2算法运行效率比较 本节测试了团队人数K、解空间大小等参数对各算法运行效率的影响。由于两种精确算法仅适用于小规模的团队形成问题,实验中评价了查询团队人数较少情况时的运行效率。图2为各数据集中两种精确算法运行效率随着团队人数改变时的变化情况。图2(a)比较了数据集Dataset1中算法运行效率,当团队人数大于30时ExactBB算法已无法运行,而ExactDP算法可以将团队人数运行到近100人。ExactDP由于采用动态规则方法保存了候选解,其效率高于回溯法ExactBB。图2(b)(c)为Dataset2和Dataset3中ExactDP与ExactBB运行效率对比,整体趋势与图2(a)相似。 实验表明,当团队人数较小时,ExactDP算法求取精确解所需解空间较小,运行效率较高,当团队人数增多时,ExactDP算法求解所需解空间增大,运行效率也随之降低。而ExactBB算法随着人数增多,其结点替换次数呈指数级增长,运行时间急剧增加。以空间换时间的ExactDP算法能够较大地提高运行效率。 Fig.2 Efficiency comparison between ExactDP and ExactBB图2 ExactDP与ExactBB算法运行效率比较 图3为近似率对ApproxDP算法所需解空间大小的影响,当对ApproxDP算法求解质量要求较高时,需要较大的解空间保存更多可行解。如图3所示,当近似率为1.2时,解空间K×S大小为K×30时才能求得满足近似率要求的解,而当近似率为1.5时,解空间大小为K×10时即可求得解。近似算法的近似率设置α=2,解空间大小设置为K×10。 Fig.3 Effect of approximate ratio to space sizes图3 近似率对解空间大小的影响 图4分析了Dataset3中解空间大小的改变对ApproxDP算法运行效率的影响。实验表明当团队人数较小时,ApproxDP算法求解效率对解空间大小并不敏感。而当团队人数增加至600人时,解空间大小对ApproxDP算法求解效率影响较大。 5.3查询结果分析 本节对查询结果进行分析,包括贪心算法与近似算法的求解质量及查询团队的影响力。 Fig.4 Effect of space sizes to efficiency ofApproxDP图4 解空间大小对ApproxDP运行效率的影响 实验比较近似算法与贪心算法求解质量,求解质量以团队成员的经验值之和衡量。图5为Dataset3 中Greedy与ApproxDP算法求解质量比较。由图5可得,ApproxDP算法求解质量要优于Greedy算法,并且团队成员数越多,优势越明显。原因是团队成员数越多,Greedy算法对结点的排斥性越大,从而降低算法求解质量。实验表明,ApproxDP算法求解质量要优于Greedy算法。 Fig.5 Team quality comparison among Greedy andApproxDP图5 Greedy与ApproxDP算法求解质量比较 本文提出的弱关系团队目标是查询满足弱关系约束的具有最大经验值和的团队。本文通过实验分析弱关系组成的团队的影响力。社会网络中采用传播模型来评价一组结点的影响力,常见的传播模型包括独立级联模型和线性阈值模型[3]。本文采用独立级联模型将弱关系团队的影响力与现有的影响力最大化算法进行比较。独立级联模型在给定初始激活结点下,采用激活概率与影响概率比较方式计算影响力。实验中采用多次模拟求平均值的方法来计算各团队所能影响的结点数目。 在独立级联模型下,设计了3种团队与Approx-DP算法所求弱关系团队TeamADP影响结点数进行比较:一种只考虑最大化团队经验值的团队,即社会网络中不考虑结点间的关系取前K大经验值的结点生成团队,这类团队称为TeamMW;另一种利用最大化影响力算法生成团队,采用两种影响力算法,一种为直接选取前K个度数最大的结点作为团队初始结点,所形成团队为TeamMD;另一种方法使用文献[4]提出的影响力最大化算法SCG生成的团队,所形成团队命名为TeamSCG。图6所示为上述4种团队影响结点数比较。 Fig.6 Team influence comparison图6 团队影响力比较 图6为数据集Dataset3中各团队影响力对比,团队TeamADP与TeamSCG影响结点数要高于团队TeamMD与TeamMW,且TeamADP影响结点数比TeamMD提升了10%。实验表明,当团队人数相同时,ApproxDP算法所求弱关系团队具有较强的影响力。 除利用独立级联传播模型对团队影响力进行评价外,本文还通过比较所求非弱关系团队与弱关系团队所占社区数对该问题加以验证。令非弱关系团队为TeamMW,弱关系团队采用ApproxDP算法实现。首先,本文对数据集进行了社区发现计算[1],将DBLP数据集中结点划分为25个社区,然后分析了两个团队中结点所拥有不同社区数的分布情况。实验同样采用多次模拟求平均值的方法。如图7所示为Dataset3中两个团队所占社区数比较。从图中可以看出弱关系团队中结点所影响的不同社区数要多于非弱关系团队。最后,图6、图7表明本文所求得的弱关系团队具有更大的社区影响力。 Fig.7 Communities numbers comparison图7 团队所占社区数比较 本文提出了一种新的团队发现问题——弱关系团队发现,并提出了3类算法解决该问题,分别为贪心算法、精确算法、α-近似算法。贪心算法搜索效率最高,但求解质量难以保证;精确算法分别采用回溯法与动态规划方法实现,适用于问题规模较小时的应用情况;α-近似算法在动态规划精确算法基础上,保留可以保证近似率的候选解,具有较高的查询效率,同时可以保证一定的近似率。最后,本文利用不同的数据集对各算法运行效率及求解质量进行了评价,并对弱关系团队的影响力进行了分析,实验表明所提出的算法可以适用弱关系团队形成问题的不同应用场景。 References: [1]Blondel V,Guillaume J,Lambiotte R,et al.Fast unfolding of communities in large networks[J].Journal of Statistical Mechanics:Theory and Experiment,arXiv:0803.0476. [2]Chai Bianfang,Zhao Xiaopeng,Jia Caiyan,et al.An efficient algorithm for general community detection in content networks[J].Journal of Frontiers of Computer Science and Technology,2014,8(9):1076-1084. [3]Kempe D,Kleinberg J,Tardos E.Maximizing the spread of influence through a social network[C]//Proceedings of the 9th ACM SIGKDD Conference on Knowledge Discovery and Data Mining,Washington,USA,Aug 24-27,2003. New York,USA:ACM,2003:137-146. [4]Estevez PA,Vera PA,Saito K.Selecting the most influential nodes in social networks[C]//Proceedings of the 2007 International Joint Conference on Neural Networks,Orlando, USA,Aug 12-17,2007.Piscataway,USA:IEEE,2007: 2397-2402. [5]Lappas T,Liu Kun,Terzi E.Finding a team of experts in social networks[C]//Proceedings of the 15th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Paris,France,Jun 28-Jul 1,2009.New York,USA:ACM, 2009:467-476. [6]Kargar M,An Aijun.Discovering top-k teams of experts with/without a leader in social networks[C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management,Glasgow,UK,Oct 24-28,2011. New York,USA:ACM,2011:985-994. [7]Majumde A,Datta S,Naidu K.Capacitated team formation problem on social networks[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Beijing,China,Aug 12-16,2012. New York,USA:ACM,2012:1005-1013. [8]Anagnostopoulos A,Becchetti L,Castillo C,et al.Online team formation in social networks[C]//Proceedings of the 21st International Conference on World Wide Web,Lyon, France,Apr 16-20,2012.New York,USA:ACM,2012: 839-848. [9]Kargar M,Zihayat M,An Aijun.Affordable and collaborative team formation in an expert network,CSE-2013-01[R]. Department of Computer Science and Engineering,York University,2013. [10]Sun Huanliang,Lu Zhi,Liu Junling,et al.Top-k attribute difference q-clique queries in graph data[J].Chinese Journal of Computers,2012,35(11):2265-2274. [11]Granovetter M.The strength of weak ties[J].American Journal of Sociology,1973,78(6):l-18. [12]Baykasoglu A,Dereli T,Das S.Project team selection using fuzzy optimization approach[J].Cybernetics and Systems, 2007,38(2):155-185. [13]Zzkarian A,Kusiak A.Forming teams:an analytical approach[J].IIE Transactions,1999,31(1):85-97. [14]Dunbar R.How many friends does one person need?:DunbarƳs number and other evolutionary quirks[M].London, UK:Faber and Faber,2010. [15]Garey M R,Johnson D S.Computer and Instractability:a guide to the theory of NP-completeness[M].San Francisco, USA:W H Freeman&Company,1979. [16]Wang Zhaocai,Tan Jian,Zhu Lanwei,et al.Solving the maximum independent set problem based on molecule parallel supercomputing[J].Applied Mathematics&Information Sciences,2014,8(5):2361-2366. [17]Wan Pengjun,Jia Xiaohua,Dai Guojun,et al.Fast and simple approximation algorithms for maximum weighted independent set of links[C]//Proceedings of the 33rd Annual IEEE International Conference on Computer Communications,Toronto,Canada,Apr 27-May 2,2014.Piscataway, USA:IEEE,2014:1653-1661. 附中文参考文献: [2]柴变芳,赵晓鹏,贾彩燕,等.内容网络广义社区发现有效算法[J].计算机科学与探索,2014,8(9):1076-1084. [10]孙焕良,卢智,刘俊岭,等.图数据中Top-k属性差异qclique查询[J].计算机学报,2012,35(11):2265-2274. SUN Huanliang was born in 1969.He is a professor at Shenyang Jianzhu University,and the senior member of CCF.His research interests include spatial database and data mining,etc. 孙焕良(1969—),男,黑龙江望奎人,沈阳建筑大学教授,CCF高级会员,主要研究领域为空间数据库,数据挖掘等。 FU Shanshan was born in 1989.She is an M.S.candidate at Shenyang Jianzhu University.Her research interest is data mining. 富珊珊(1989—),女,辽宁庄河人,沈阳建筑大学硕士研究生,主要研究领域为数据挖掘。 LIU Junling was born in 1972.She is a Ph.D.candidate at Northeastern University,and the member of CCF.Her research interests include spatial database and data mining,etc. 刘俊岭(1972—),女,辽宁沈阳人,东北大学博士研究生,CCF会员,主要研究领域为空间数据库,数据挖掘等。 YU Ge was born in 1962.He is a professor and Ph.D.supervisor at Northeastern University,and the senior member of CCF.His research interests include database,data mining,RFID,XML and Web data management,etc. 于戈(1962—),男,辽宁大连人,东北大学教授、博士生导师,CCF高级会员,主要研究领域为数据库,数据挖掘,RFID,XML,Web数据管理等。 XU Hongfei was born in 1987.He is a Ph.D.candidate at Northeastern University.His research interest is spatial database. 许鸿斐(1987—),男,山西太原人,东北大学博士研究生,主要研究领域为空间数据库。 *The National Natural Science Foundation of China under Grant Nos.61070024,61272180(国家自然科学基金);the Specialized Research Fund for the Doctoral Program of Higher Education of China under Grant No.20120042110028(高等学校博士学科点专项科研基金);the MOE-Intel Special Fund of Information Technology under Grent No.MOE-INTEL-2012-06(教育部-英特尔信息技术专项科研基金). Received 2015-06,Accepted 2015-08. CNKI网络优先出版:2015-08-12,http://www.cnki.net/kcms/detail/11.5602.TP.20150812.1627.003.html +Corresponding author:E-mail:liujl@sjzu.edu.cn 文献标志码:A 中图分类号:TP311 doi:10.3778/j.issn.1673-9418.1507075 Team Formation with Weak Ties in Social Networksƽ SUN Huanliang1+,FU Shanshan1,LIU Junling1,2,YU Ge2,XU Hongfei2 Abstract:As the online social network grows rapidly,the team formation problem becomes more and more popular. Previous research on team formation aimed at finding a team of experts with the lowest communication cost.However, in expert or public jury,as untighten relationship can guarantee diversified attitudes and refrain from prejudice,there are numerous quests which to find a weak connected team.Based on this requirement,this paper proposes the problem of team formation with weak ties in social networks by introducing the concept of weak ties in sociology.This problem aims to find a team with weak ties between members and satisfy the requirement of skills and experience,it is an NP-hard problem.This paper designs three kinds of algorithms for the problem,they are greedy algorithm,exact algorithm and α-approximate algorithm.Every kind of algorithm has distinct property and scope.The experimental results onACM and DBLP real datasets show the quality and confirm the effectiveness and efficiency of proposed algorithms. Key words:social network;team formation;weak ties;greedy algorithm;exact algorithm;approximate algorithm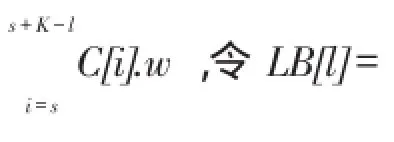




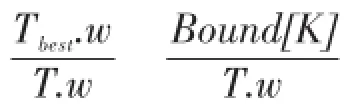
5 实验结果与分析
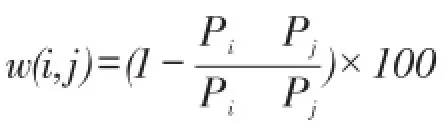

6 结论





1.School of Information and Control Engineering,Shenyang Jianzhu University,Shenyang 110168,China
2.School of Information Science and Engineering,Northeastern University,Shenyang 110006,China
