决策树分类ID3算法在网络教学平台学习策略推荐中的应用
2016-05-16卢小华
卢小华
(山西工商学院计算机信息工程学院,山西 太原 030006)
现代社会,随着Internet 的快速发展,网络教学平台在各大高校已经得到了广泛的应用,但是现有的教学平台在智能化功能上存在缺陷,不能根据登录平台学习的学生特点进行学习策略的个性化推荐,因此在教学平台的设计中加入数据挖据的决策树分类技术是非常有意义的。
1 决策树分类算法的概念
J.Ross Quinlan 于20 世纪70年代末到80年代初研究出了决策树(Decision Tree)算法,又叫迭代的二分器(Iterative Dichotomiser,ID3)[1]。决策树形状是一种类似于二叉或者多叉的倒置树,是一个简单的分类器,其算法是从带有类标号的训练元组中构建决策树,将形成的规则对预测数据分类[2]。具体过程是采用自上到而下的方式,从根节点开始,沿着树的一个分支,一直判定,直到叶节点,在每一个叶节点得到相似的结果。非叶结点代表测试的属性值,每个分支输出的为测试结果,其中叶结点代表类标号。非叶结点用矩形表示,叶结点用椭圆形表示。
2 决策树的构造
2.1 构建模型
通过递归的方式将训练集数据创建节点,当结点属性不可再分时终止递归,生成决策树。
2.2 剪枝
在决策树的创建过程中,有的数据有异常,必须要对创建的树执行剪枝操作,常见的决策树剪枝方法有两种:先剪枝和后剪枝。
2.2.1 先剪枝
在树未完全生成之前剪枝。如果采用这种方法,当前的结点就变成了树叶。因此,通过这种方法会生成简单的子树,但剪枝阂值选择比较困难,值太大会导致树过分简化,值太小又会使树太少简化[3]。
2.2.2 后剪枝
在树完全生成以后再剪子树,把结点的子树剪去而变成树叶[4]。类标号为出现次数最多的类,然而这样可能会降低预测的精度,影响分类的结果。因此在具体的应用中要将先剪枝和后剪枝相结合,可以节省计算量并且可获得较高精度的决策树。
3 决策树分类——ID3算法
3.1 ID3算法描述
算法:
输入:训练集数据。
输出:一颗决策树。
步骤:
Generate_decision_tree (samples,attribute_list)//生成决策树函数,参数为训练数据,候选属性集合。
1)创建结点N;
2)if samples 属于同一个类C then return N 作为叶结点,以类C 标记;
3)if attribut_list 为空then return N 当作树叶结点,标记为samples 中最普通的类;
4) 选择attribute_list 中具有最高信息增益的属性best_attribute;//找出最好的划分属性;
5)标记结点N 为best_attribute;
6)for each best_attribute 中的未知值ai//将样本samples 按照best_attribute 进行划分;
7) 由结点N 长出一个条件为best_attribute=ai的分枝;
8)设x 是samples 中best_attribute=ai 的样本的集合;//a partition;
9)if x 等于NULL then 增加一个叶节点,标记为训练数据中普通的类;
10)else 加上一个由Generate_decision_tree(si,attribute_list-best_attribute)返回的结点。
3.2 ID3算法的构造
假设训练集元组用D 表示,类标号属性的不同值用m 表示,Ci(i=1,…m)代表m 个不同的类,D 中Ci类元组的集合用Ci,D表示,其元祖的个数为|Ci,D|,D中元组的个数为|D|[5]。
其中Pi表示训练集中元组出现在Ci类中的概率,计算公式为|Ci,D|/|D|。
2)决策树根节点的选择
将D 中的元组依据x 属性划分,{a1,a2,…,av}代表训练数据中属性x 的多个不同的值。如果x 的值不是连续的,则这些值与x 上测试的v 个输出相对应。
将D 中的元组用x 属性划分为多个子集{D1,D2,…,Dv},其中,Dj包含D 中的元组,它们的x 值为aj。按x 属性将元组划分的信息熵:
其中项|Cj|/|D|充当第j 个分区的权重。根据x 属性对D 元组分类划分的为Infox(D),Infox(D)的值代表分区的纯度,取值越大,按照其分区的纯度越低。
计算信息增益:Gain(x)=Info(D)-Infox(D)
根据以上步骤计算按各属性划分D 中元祖的信息增益,值最大的作为决策树的根节点。
3)从决策树的根节点按照节点的各个属性的不同值进行树分支的创建,从而形成多个子集。用相同的方法对每个叶节点上的子集选择测试属性,直到没有分枝的属性停止递归操作。
3.3 ID3算法在教学平台学习策略推荐中的应用
ID3 决策树算法可根据平台中学生填写的注册信息(所学专业、性别、自学能力)和学习知识点的难度等级构建决策树[6]。通过决策树分析计算,形成规则,从而在学生进入平台进行学习时根据不同学生的特点进行学习内容难度级别的推荐,从而实现真正的因材施教[7]。
3.3.1 数据收集
在本平台中,以C++课程的学习为例,课程共包含19 章,其初级的学习者只需要学到第8 章,而高级知识就需要全部学完。随机抽取了14 条学生注册和学习的记录作为原始训练数据源用来构造决策树[8],如表1 所示。
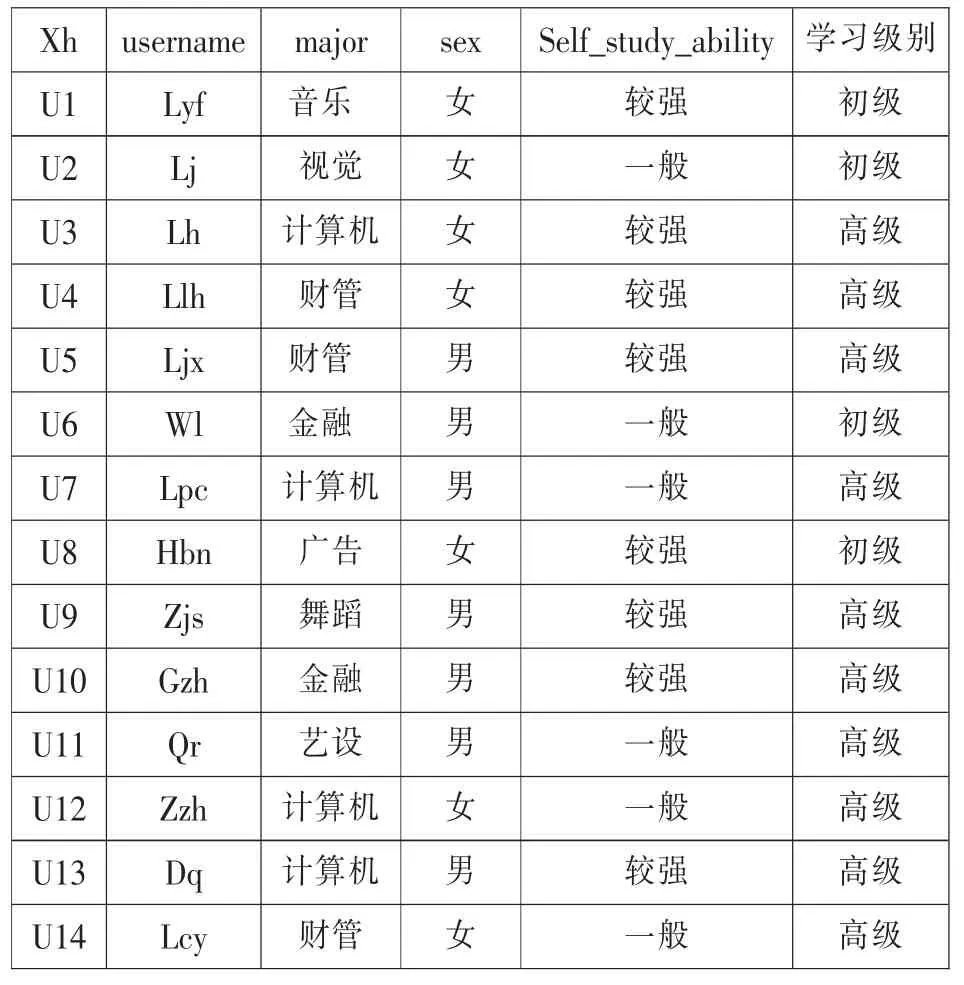
表1 学生登录平台进行注册和学习的原始数据
3.3.2 数据预处理
1) 除去xh、username 不合格数据
2) 将学生按专业分成三类:计算机类(computer)、财经类(finance)、艺术类(art)
3) 将性别用英文分类:男(male)、女(female)
4) 自学能力用英文字母表示:较强(better)、一般(weak)
5) 学习级别用英文字母表示:初级(L)、高级(H)
处理后的表如表2 所示。

表2 学生注册信息表
3.3.3 构造决策树
1) 计算给定样本的信息嫡
表一中目标类属性“学习级别”有两个取值{初级,高级},即有两个类,C1=“高级”,C2=“初级”,其中类“高级”有9 个元祖,类“初级”有5 个元组。
则给定样本的信息熵的值为

2) 计算每个属性的熵:
a.计算机专业的熵:专业划分为:Art、Computer、Finance and Economics
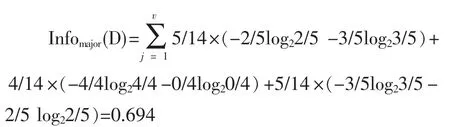
则该划分的信息增益为:Gain(major)=Info(D)-Infomajor(D)=0.94-0.694=0.246
b.计算性别的熵

则该划分的信息增益为:Gain(sex)=Info(D)-Infosex(D)=0.94-0.789=0.151
c.计算自学能力的熵

则该划分的信息增益为:Gain(self_study_ability)=Info (D)- Infoself_study_ability(D)=0.94-0.892=0.048
通过计算分析,专业为信息增益最高的的分类属性,将其作为根节点。用相同的方法和步骤计算每一个划分的属性信息增益,创建树的分枝,一步步完成树的创建,最后生成的完整的决策树如图1 所示。
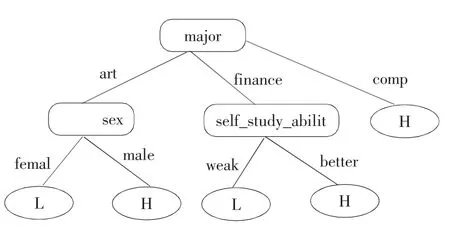
图1 学习难度等级决策图
从决策树的根节点到叶节点形成IF-THEN 分类规:

结果分析:
由分类规则可以得出,选择学习课程高级知识的有三类学生:computer 专业的学生;Finance and Economics 专业并且自学能力较强的学生;male 学生。用测试样本来计算规则的准确率,将精确度较高的规则,添加到学习策略推荐表中。在学生进行注册登录后,利用规则对学生的信息进行分析,给出学习建议,如图2 所示。

图2 学习策略推荐图
4 结束语
网络教学平台的智能化是当下远程教育的需求,ID3 算法在教学平台中的应用使平台的智能化得到了初步的实现,可以为不同学习能力、不同专业学生推荐个性化的学习策略。随着网络教育的迅速发展,数据挖掘技术中的各类算法在网络教学中的应用将更加的深入和广泛,从而可以最大限度的满足不同学习者的学习需求。
